1.链表介绍
链表是一种物理储存上非连续、非顺序的存储结构。数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。

对于上图,每一个结点都是一个结构体,这个结构体内存储的成员是值和下一个结点的地址。所以plist存储的是第一个结点的地址(即plist为一个结构体指针),而后续每个节点都会存储对于自己下一个结点的地址。由于链表的结点是通过malloc一个个申请出来的,所以其存储空间是不连续的,也是由于这个原因我们才需要通过一个结构体指针来访问逻辑上的下一个结点。
2.链表的分类
链表具有三个特征,根据这三个特征的排列组合得知链表有8种组合。
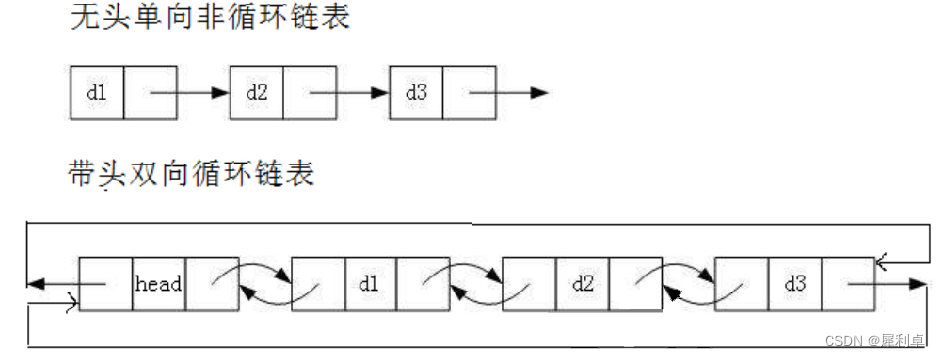
2.1 单向和双向

单向链表的每个结点成员只有指向下一个结点的指针,而没有指向上一个结点的指针。双向链表则二者皆有,所以单向链表就像“过河的卒”,不可以回头访问自己的上一个结点,而双向链表则既可以访问自己的上一个结点,也可以访问自己的下一个结点。
2.2 带头和不带头

带头链表和不带头链表的区别就在于带头链表有一个“头结点”。
总结下来,带头链表会有一些优势:
① 避免空指针的访问:因为头结点又名哨兵位,所以它起到一个放哨的作用。无论链表结构是否为空,都可以放心的访问链表,因为有头结点的存在,就算链表为空也不会访问到空指针,更加安全。
② 函数传参不需要传递二级指针:如果没有头结点,当我对链表增删查改操作时,由于手上拿的是链表的第一个结点,所以如果操作到链表第一个位置,可能会涉及到链表第一个结点指针的变化,而传一级指针的参数是不会使该操作生效的,所以需要二级指针。但是有了头结点后无论做什么操作,头结点一旦生成直至链表销毁都不会改变,所以不需要传递二级指针,更加方便。
2.3 循环和非循环

非循环链表的尾结点由于是最后一个结点,其后没有结点,所以它的next指针是指向NULL的。循环链表的尾结点则是指回了链表的第一个结点,使得整体结构体现出循环的功能。
尽管有八种链表的组合形式,但是我们常用的的只有两种形式的链表。即单向不带头不循环链表和双向带头循环链表。
3.单链表工程
对于一个单链表工程,我们一般模式需要分为三部分。
SList.h 为头文件,其中包含库函数头文件的包含,顺序表结构体的定义与声明,接口函数的声明。
SList.c 包含接口函数的定义。
Test.c 是我们的测试源文件,从这里进入main函数。
3.1 单链表的定义
建立一个单链表需要多个结点共同构成,我们针对单链表一个结点进行定义,将其定义为一个结构体,包含数据和下一个结点的指针。
typedef int SLNDataType;typedef struct SListNode
{SLNDataType val;struct SListNode* next;
}SLNode;3.2 单链表的函数接口
对一个单链表,我们需要一些函数来方便我们管理数据。因此我们所要实现的基本的函数接口需要包含增删查改等功能。
3.2.1 单链表结点插入
单链表常用的插入数据方式有:头插,即在链表最前端插入数据结点;尾插,即在链表最后端插入数据结点;随机插入,即在指定的结点前或者后插入结点。
单链表由于没有头结点,所以在插入时很有可能需要改变头结点,例如头插或链表为空时插入。所以在参数传递时我们不得不以二级指针的形式进行传参,这样可以在函数内部修改头结点,从而成功插入结点。
3.2.1.1 单链表创建结点
因为在单链表的函数接口中有多个结点需要插入结点,需要频繁创建结点并以不同的方式插入,所以我们将创建节点的过程封装成一个函数,在需要创建结点时调用函数即可,避免代码冗余。
SLNode* CreateNode(SLNDataType x)
{SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));if (newnode == NULL){perror("malloc");exit(-1);}newnode->val = x;newnode->next = NULL;return newnode;
}3.2.1.2 单链表头插
单链表头插时只需要将原来的第一个结点链接在新结点之后即可。
void SLTPushFront(SLNode** pphead, SLNDataType x)
{assert(pphead);SLNode* tmp = CreateNode(x);tmp->next = *pphead;*pphead = tmp;
}3.2.1.3 单链表尾插
单链表尾插需要先找到尾结点,但由于单链表的单向不循环的特性,我们只能从头遍历链表找到尾结点,才能将新结点链接在尾结点之后。
void SLTPushBack(SLNode** pphead, SLNDataType x)
{assert(pphead);if (*pphead == NULL){*pphead = CreateNode(x);}else{SLNode* tail = *pphead;while (tail->next != NULL){tail = tail->next;}tail->next = CreateNode(x);}
}3.2.1.4 单链表在指定结点前插入
在指定节点前插入需要这个结点前一个结点的指针指向新结点,所以我们就需要先遍历找到这个结点的前一个结点。
//在pos节点前插入
void SLTInsert(SLNode** pphead, SLNode* pos, SLNDataType x)
{assert(pphead);assert(*pphead);assert(pos);SLNode* tmp = CreateNode(x);if (pos == *pphead){tmp->next = *pphead;*pphead = tmp;}else{SLNode* prev = *pphead;tmp->next = pos;while (prev->next != pos){//if (prev->next == NULL)//{// printf("插入节点有误\n");// exit(-1);//}prev = prev->next;}prev->next = tmp;}
}3.2.1.5 单链表在指定结点后插入
在指定节点后插入就可以不用遍历链表,直接链接即可。
void SLTInsertAfter(SLNode** pphead, SLNode* pos, SLNDataType x)
{assert(pphead);assert(pos);SLNode* tmp = CreateNode(x);tmp->next = pos->next;pos->next = tmp;
}3.2.2 单链表结点删除
单链表常用的删除结点的方式有:头删,即删除在链表最前端的结点;尾删,即删除在链表最后端的结点;随机删除,即删除在指定的结点前或者后的结点。
3.2.2.1 单链表头删
头删只需要将第一个结点释放掉,然后将原来指向链表第一个结点的变量赋值第二个结点即可。
void SLTPushFront(SLNode** pphead, SLNDataType x)
{assert(pphead);SLNode* tmp = CreateNode(x);tmp->next = *pphead;*pphead = tmp;
}3.2.2.2 单链表尾删
尾删需要遍历链表找到尾结点,然后将尾结点释放并将尾结点的前一个结点的next指针赋值为空指针。需要警惕只有一个结点的链表,需要将链表置为空。
void SLTPopBack(SLNode** pphead)
{assert(pphead);//0个节点assert(*pphead);//1个节点SLNode* prev = NULL;SLNode* tail = *pphead;if (tail->next == NULL){free(tail);tail = NULL;*pphead = NULL;}else{while (tail->next != NULL){prev = tail;tail = tail->next;}free(tail);tail = NULL;prev->next = NULL;}
}3.2.2.3 单链表删除指定结点
想要删除一个指定结点,需要找到其前一个结点,将前一个结点与后一个结点链接起来。
//删除pos节点
void SLTErase(SLNode** pphead, SLNode* pos)
{assert(pphead);assert(*pphead);assert(pos);if (pos == *pphead){SLNode* tmp = *pphead;*pphead = (*pphead)->next;free(tmp);tmp = NULL;}else{SLNode* prev = *pphead;while (prev->next != pos){/*if (prev->next == NULL){printf("删除节点有误\n");exit(-1);}*/prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;}
}3.2.2.4 单链表在指定结点后删除
删除指定结点后一个结点,只需要将这个结点和它的下下个结点链接起来即可。
//在pos位置后删除
void SLTEraseAfter(SLNode** pphead, SLNode* pos)
{assert(pphead);assert(pos);assert(pos->next);SLNode* tmp = pos->next;pos->next = tmp->next;free(tmp);tmp = NULL;
}3.2.3 单链表打印
依次遍历所有结点即可,由于不需要改变链表的值,所以可以传递一个一级指针。
void SLTPrint(SLNode* phead)
{while (phead != NULL){printf("%d->", phead->val);phead = phead->next;}printf("NULL\n");
}3.2.4 单链表查找
用于查找链表中指定值的结点,会返回该结点的地址。所以,只需要遍历链表并且比较即可。
SLNode* SLTFind(SLNode* phead, SLNDataType x)
{SLNode* tmp = phead;while (tmp != NULL){if (tmp->val == x){return tmp;}else{tmp = tmp->next;}}printf("未找到节点\n");return NULL;
}3.2.5 单链表销毁
销毁单链表只需要遍历链表,依次释放所有结点即可。
void SLTDestroy(SLNode** pphead)
{while (*pphead != NULL){SLNode* tmp = *pphead;*pphead = (*pphead)->next;free(tmp);tmp = NULL;}
}4.单链表总结反思
无头单向不循环链表,这种链表虽然结构简单但是应用广泛。在最近的学习过程中,我发现不少与链表有关的题目多用单链表来设题,除此之外,一些更加复杂的结构也需要用单链表作为支撑,所以可以看出其重要性。
除此之外,恰恰是因为其结构简单,所以对特殊情况的限制较少,这就需要我在写代码时充分考虑可能会发生的所有情况,以便做出合理控制。毫无疑问,单链表是很重要的,我感觉它就像“原汁原味”的链表,需要反复品尝,并且一切上层建筑都是源于这看似简单的结构。









:1008. 前序遍历构造二叉搜索树)


)
:015榧树、秋枫、滇合欢、锥栗、红豆树、刺槐、余甘子、黑荆、槐树、黄檀)

】)



)