10月24日程序员节,「大模型数据计算系统」2023拓数派年度技术论坛在上海圆满落幕,拓数派大模型数据计算系统(PieDataComputingSystem,缩写:πDataCS)如约而至!πDataCS 以云原生技术重构数据存储和计算,一份存储,多引擎数据计算,让 AI 模型更大更快,全面升级大数据系统至大模型时代。作为 πDataCS 的云存储底座,简墨存储系统的目标是打造满足各种云场景下的高性能计算系统的数据管理和存储底座。
1 πDataCS:一份数据存储,多引擎数据计算
πDataCS 旨在助力企业优化计算瓶颈,充分利用和发挥数据规模优势,构建核心技术壁垒,更好地赋能业务发展,使得自主可控的大模型数据计算系统保持全球领先,让大模型技术全面赋能各行各业。
计算平台从大型机、PC 机到如今的云平台经历了三代大的变更。云平台代表了目前最大的计算能力、存储能力和水平扩展能力。在 PC 机年代,元数据和用户数据映射在本地硬盘,计算映射在本地 CPU,存储和计算紧密耦合在同一个服务器上。
πDataCS 以云原生技术重构数据存储和计算,先将数据计算系统中的计算和数据分离,增强系统的弹性。接着,考虑到未来数据治理和交易,拓数派把元数据和用户数据再次分离,实现了全新的 eMPP 架构。元数据被映射到块存储,由元数据管理系统「木牍」进行管理;用户数据被映射到对象存储,由「简墨」存储系统来管理;计算被映射到容器或者虚拟机,由计算系统来管理。
πDataCS 通过 Data Mesh,升级数据治理,实现数据价值。πDataCS 深入考虑了全球数据交易和数据治理的要求。数据作为一种新的生产要素,是模型发展的重要燃料。在隐私和安全的前提条件下,数据所有者可以把含数据目录的元数据对其他用户共享,数据经营者通过元数据来访问所有者的用户数据,并根据需要,通过授权来有偿访问所有者的用户数据。数据经营者在访问所有者的数据的时候,需要调用数据加工者提供的数据计算引擎。
πDataCS 的整体架构被分为四层,如下图所示:

最上层是 πDataCS 所支持的计算引擎。目前 πDataCS 支持以下几种计算引擎:
- PieCloudDB:作为拓数派首款云原生数仓计算引擎,支持 SQL 语言模型,兼容 HTAP
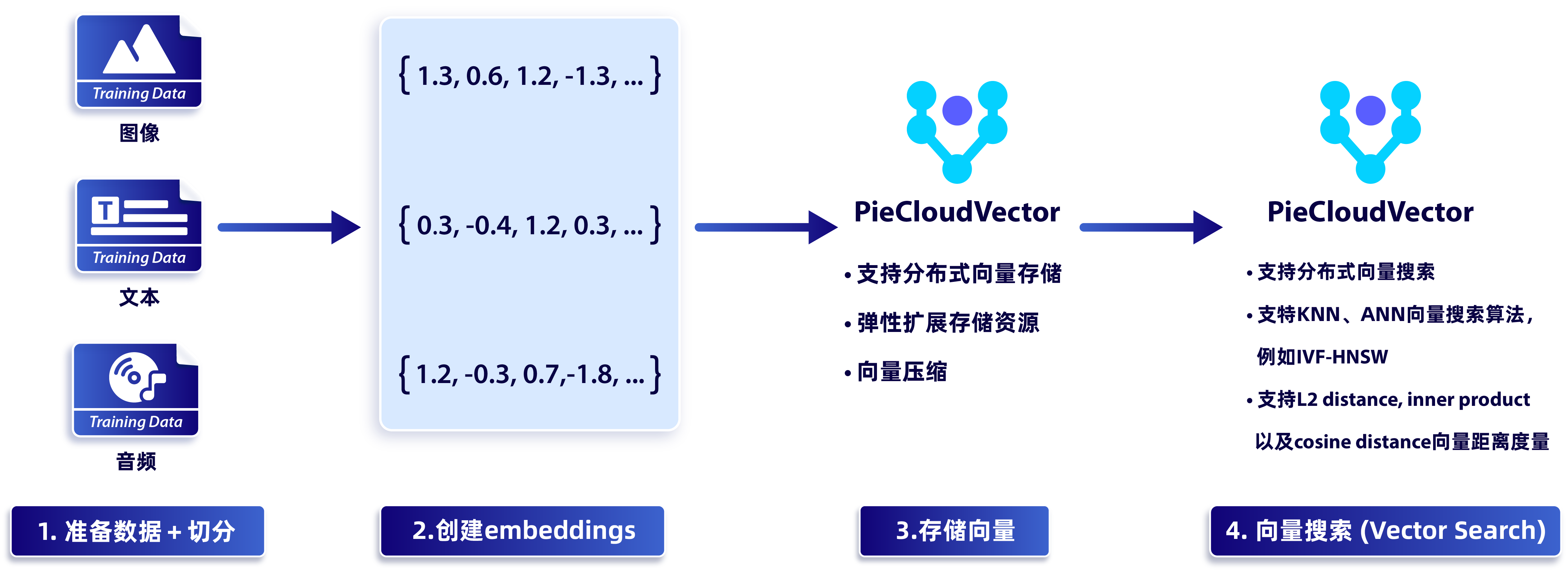
- PieCloudVector:为支持和大模型配合的向量计算而建立的云原生向量计算引擎
- PieCloudML:为支持 Python 和 R 等机器学习语言而建立的云原生机器学习引擎
1.1 PieCloudDB:首款云原生数仓计算引擎
作为 πDataCS 的首款计算引擎,PieCloudDB 云原生虚拟数仓全面支持 πDataCS 公有云版、社区版、企业版及一体机多个产品版本,提供公有云、私有云以及裸硬件三种部署方式,通过数仓虚拟化技术,帮助企业打破数据孤岛,整合所有结构化数据资源,轻松应对强逻辑计算。
云原生存算分离架构运用元数据-计算-数据分离的三层架构,实现云上存储资源与计算资源的独立管理。在云上,PieCloudDB database 利用 eMPP(elastic Massive Parallel Processing)专利技术,实现多集群并发执行任务。企业可灵活进行扩缩容,随着负载的变化实现高效的伸缩,轻松应对 PB 级海量数据。
1.2 PieCloudVector:云原生向量计算引擎
向量数据库是一种专门用于存储、查询和分析向量数据(比如特征向量)的数据库系统。
在对比了 pgvector,pgembedding 的实现和性能之后,我们并没有使用开源的实现,而是完全独立自研了 PieCloudVector 以使其满足我们用户的使用场景。PieCloudVector 具备高效存储和检索向量数据、相似性搜索、向量索引、向量聚类和分类、高性能并行计算、强大可扩展性和容错性等功能。
1.3 PieCloudML:云原生机器学习引擎
然而随着人工智能的日益发展,未来越来越多的经济活动将由 AI 来推动。πDataCS 中建立了云原生机器学习引擎 PieCloudML,通过 PieCloudML 内置的各种 ML、图和大模型的算法,数据科学家可通过 python/R 等熟悉的方式,利用数据计算系统来完成各项任务,生成所需的模型。
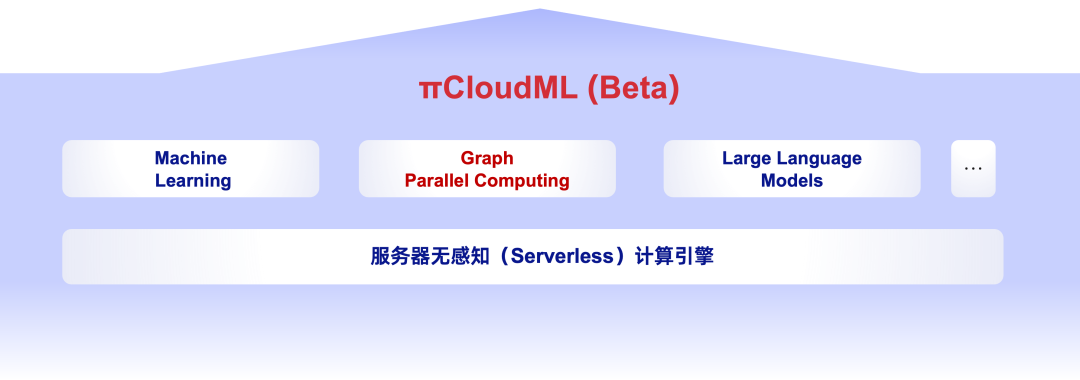
为了加速大数据处理和计算的性能,πDataCS 中充分依赖新的硬件来进行异步计算,例如 GPU、FPGA 等。并通过统一的元数据管理层 ——「木牍」,让这三大计算引擎共享一个数据存储底座 ——「简墨」,实现一份数据,多引擎计算。
接下来我们将详细介绍简墨,这款大数据计算系统的云存储底座。
2 简墨:大数据计算系统的云存储底座
作为 πDataCS 的云存储底座,简墨存储系统的目标是打造满足各种云场景下的高性能计算系统的数据管理和存储底座。简墨将基于现代化的硬件和设施,充分使用云的潜力,绝对的数据安全保证,致力于简化大数据处理过程中的数据加载、读取和计算的整个流程,并提供对数据的自适应治理、ACID 的事务支持等功能,保证绝对的数据安全,做到极致的性能优化,以完成各种场景下的数据计算和分析任务。
为了实现这一目标,简墨的进化主要经历三大阶段:
- 阶段一:新一代云原生存储
- 阶段二:大数据计算系统的云存储底座
- 阶段三:统一的大数据计算系统存储引擎
2.1 进化阶段一:新一代云原生存储
第一阶段的简墨主要作为云原生虚拟数仓 PieCloudDB 的云原生存储,目前研发工作已完成。
简墨基于不同的云环境兼容公有云、私有云和混合云,使用对象存储作为持久化存储层,并充分考虑到了 eMPP(elastic MPP)架构下的数据分布和弹性,使用一致性哈希(hash)来保证分布式环境中的每个节点访问大致相同的数据,即使扩缩容也可以尽可能的减少实现的缓存数量。简墨充分考虑到了数据的安全性,结合云原生虚拟数仓 PieCloudDB 中的透明加密在存储落盘时即完成对数据进行加密。透明加密使用了三级密钥,保证了数据的绝对安全。此外,简墨也针对读写性能进行了大量优化,大大提升了数据加载和查询的效率。
2.1.1 全新的文件格式:janm
「简墨」新一代云原生存储围绕 janm 文件格式打造。janm 文件格式使用了行列混合存储设计。行列混合存储让系统在重组数据时,既具备了行存所具有的高效性能,又具备了列存的高压缩比、cache line 友好等优势。同时,jamn 文件格式也能支持向量化(SIMD)计算和并行计算。在设计时,简墨也充分考虑到了内外存的存储表达方式,重新定义了数据在磁盘和内存中的表数据格式,使表中的数据在磁盘上和内存中的数据转换没有额外的开销。
在文件格式内,简墨也会收集文件内数据统计信息来加速查询,支持预计算等性能优化特性。为了加速 I/O,janm 文件格式内置多种压缩算法,例如 zstd、lz 等。针对不同的类型,简墨可以自适应选择不同的编码方式,包括 delta encoding、dictionary encoding 等。
通过块(block)文件级别的 MVCC,使简墨具备完整的事务支持。每个文件块中的数据是否可见,简墨将通过其所在文件的 MVCC 信息,根据当前的事务隔离级别来判断。在 PieCloudDB 中,简墨对访问层进行了深度定制,以确保 PieCloudDB 充分使用简墨中提供的各项优化。
目前,简墨针对数据的读取与查询进行了大量优化,实现了包括数据裁剪(Data Skipping)、预计算加速聚集查询、Smart Analyze、TOAST 的支持等众多功能:
-
数据裁减:在查询时,依据查询条件尽可能减少要读取的数据量,以达到节省 I/O,提升查询性能的效果。
-
预计算:对于聚集查询,当简墨收集到每个数据块的聚集数据时,可之间通过使用该数据库的数据来加速数据聚集计算
-
Smart Analyze:通常来说,查询优化器通过对整个表进行 analyze 收集来的表的数据分布信息来生成查询执行计划。对于分析场景来说,当数据量过大时,通过普通 analyze 收集来的表数据分布信息有较大误差,导致产生较差的执行计划。Smart Analyze 通过加载数据时计算每个数据块的分布信息,再通过 merge 算法合并全部数据块的统计信息来生成较为准确的表数据分布信息,其根本思想是在不影响性能的情况下尽可能多的对用户数据进行采样。
-
超大字段存储的支持:简墨对超大字段存储的支持早已实现基本的读写操作。在全新版本中,PieCloudDB JAMN 已进一步优化,全面支持超大字段存储的 UPDATE/DELETE 和 VACUUM 功能。
…
随着这一阶段的完成,结合 πDataCS 的需求,研发团队对简墨进行了第二阶段的设计和实现,目标是将简墨成为大数据计算系统的云存储底座。
2.2 进化阶段二:大数据计算系统的云存储底座
在这一阶段,简墨将作为 πDataCS 的云存储底座,目标是能够真正做到「一份数据,多引擎计算」,相应的研发工作正在进行中。
为实现这一目标,简墨计划实现以下特性:
- 更多文件格式的支持
- 数据互通
- 更高效的外部数据提取和加载
- 流式数据处理
- 高性能的 ACID 事务处理
- 自适应数据管理
- CDC 场景的支持
- 更多云原生的 Index 支持
…
下图详细绘制了简墨表格式(JANM Table Format)的所有层级,其中每个层级都依赖于其下面一层,并从中汲取所需的能力,用户将数据以对应的文件格式存储在极具扩展性的云存储中来为上层计算提供数据。

2.2.1 存储访问抽象(Storage Access Abstract)层
最底层的是简墨的存储访问抽象层,简墨利用抽象 API 与任何类型的存储进行交互,包括云对象存储(例如 S3)、HDFS 等。通过这种方式,简墨确保了所有存储引擎的兼容性。此外,简墨对文件系统进行了包装,以进一步优化存储功能,例如提供监控和各种读写策略等。
2.2.2 数据文件格式抽象(File Format Abstract)层
简墨会在这一层支持多种文件格式,并具备统一的访问接口来简化对数据的访问操作,从而让用户的数据可自由的选择不同的文件格式来存储,用户数据。同时,在更高的层面上,简墨独特的文件布局方案涉及将对每个文件的所有更改进行记录,这使简墨能够创建一个独立的 redo 日志,可用于实现更多丰富的功能。
2.2.3 表格式(Table Format)的核心层
表格式的核心层提供各项特性的功能封装和实现。核心层包括以下5个子系统:
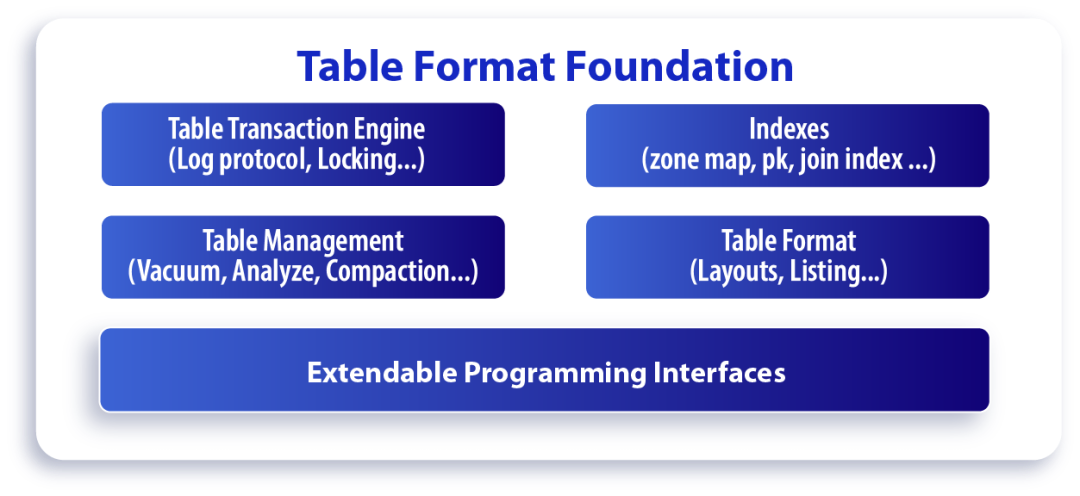
- 表的事务引擎(Table Transaction Engine)
核心层包含有表的事务引擎,实现了文件级别 MVCC,支持根据隔离级别进行数据库的可见性判断,保证一定的并发控制。对于事物保证,简墨的基本思路是日志即数据,该数据指的是事务可见性信息。
- 索引(Index)
索引可帮助数据库规划更好的查询,减少 I/O 总量并提供更快的响应时间。有关文件列表和列的索引信息在 OLAP(分析型)场景下,足以让 OLAP 引擎快速生成高效的查询计划。目前 janm 中支持数据裁剪(Data Skipping)所需的索引,未来我们将持续探索更多的索引实现,甚至是行级索引。
- 表数据的自适应管理(Table Management)
简墨所支持的表数据的自适应管理功能,主要包含:
➢ VACCUM:数据清理,回收操作留下的垃圾空间
➢ Smart Analyze:数据分布信息采样
➢ Compaction:将小文件进行合并,提升 I/O 效率
➢ Cluster:将相近的数据尽可能聚集在相同文件,以提升数据裁减的效率,提升查询速度
➢ Sort:根据指定的字段或条件对数据排序
…
- 表格式的相关操作和控制的封装
在这一层,简墨会支持对表的组成和布局控制,支持表文件的遍历,和表数据大小的统计等功能的封装。在对象存储中,对文件进行 list 是开销很大的操作,简墨通过表格式层提供的功能来进行快速的文件遍历和数据大小统计。
2.2.4 可扩展的编程接口
针对上层接口,简墨提供了统一的 API 与外部服务交互,方便第三方应用的接入。简墨支持扩展服务的不同实现,而无需额外的应用开发,节省用户成本工作量。提供数据访问的入口,提供了表的访问服务,基于快照的操作,以及包括 Time Travel 在内的丰富功能。

针对表的应用服务,简墨提供了无状态数据管理的应用,可注册到任意服务中,从而实现自适应数据管理。
在第二阶段完成后,拓数派「简墨」计划拥抱开源,实现数据在不同服务之间的真正互通,全面支持包括 Spark,Clickhouse 在内的众多服务,实现一份数据,多引擎计算。
2.3 进化阶段三:统一的大数据计算系统存储引擎(展望)
未来,在演进的第三阶段,简墨期待打造成为一款统一的大数据计算系统存储引擎。打造统一的访问协议,将表格式、数据湖、表引擎等统一到协议下,简化用户的访问操作。希望大家能持续关注简墨的进展!






)










Java+ssm+MYSQL酒店大数据资源管理系统的设计与实现02029)



