
码字不易,如果对您有用,求各位看官点赞关注~
原创/朱季谦
目前的Mybatis-Plus版本是3.0,至于最新版本是否已经没有这个问题,后续再考虑研究。
某天检查一位离职同事写的代码,发现其对应表虽然设置了AUTO_INCREMENT自增,但页面新增功能生成的数据主键id很诡异,长度达到了19位,且不是从1开始递增的——
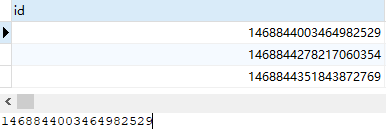
我检查了一下,发现该表目前自增主键已经变成从1468844351843872770开始递增了——
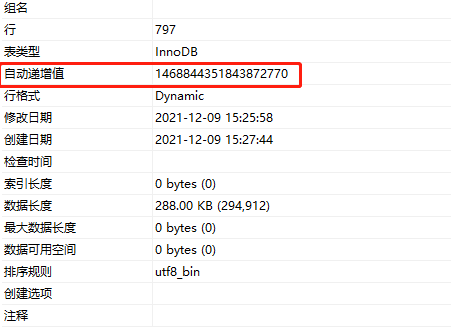
这就很奇怪了,目前该表数据量很少,且主键是设置AUTO_INCREMENT,正常而言,应该自增id仍在1000范围内,但目前已经变成一串长数字。
底层ORM框架用的是Mybatis-Plus,我寻思了一下,这看起来像是在插入数据库就自动生成的id,导致并非默认使用MySql的自增AUTO_INCREMENT来生成id。
因此,决定一步步定位,先给Mybatis-Plus打印出sql日志,看下其insert语句是否自动生成了一个id后才插入数据库。
按照网上的教程,我在yaml文件里对应的mybatis-plus配置处设置了开启sql打印日志——
mybatis-plus:mapper-locations: classpath*:mapper/*.xmlconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
然而,很诡异的是,执行操作时并没有打印出sql日志,故而,某一瞬间,我忽然觉得,这群家伙可能都是互相抄的,没有验证当springboot集成了logback时,单纯这样设置并没有效果。
最后额外在yaml加了以下配置,才能正常打印MP的sql日志信息——
logging:level:com:zhu:test:mapper: debug
接下来,验证一番后,发现,Mybatis-Plus在做insert操作时,确实自动生成一条长19的数字当做该条数据的id插入到MySql,导致虽然MySql表设置了自增,但被Mybatis-Plus生成的id为1468844351843872769所影响,导致下一条数据自动递增值变成1468844351843872770,这种过长的id值,在做索引维护时,是很影响效率,占用空间过大,故而,这个问题必须得解决。

到这里,就确定,这个长数字的id,是在代码层次就自动生成了,最后进入对应的实体类中,发现该映射数据表的id字段,并没有显示设置对应的主键生成策略。
@Data
@TableName("test")
public class Test extends Model<Test> implements Serializable {private Long id;......
}
Mybatis-Plus主要有以下几种主键生成策略——
@Getter
public enum IdType {/*** 数据库ID自增*/AUTO(0),/*** 该类型为未设置主键类型*/NONE(1),/*** 用户输入ID* 该类型可以通过自己注册自动填充插件进行填充*/INPUT(2),/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 *//*** 全局唯一ID (idWorker),根据雪花算法生成19位数字,long类型*/ID_WORKER(3),/*** 全局唯一ID (UUID)*/UUID(4),/*** 字符串全局唯一ID (idWorker 的字符串表示),根据雪花算法生成19位字符串,String*/ID_WORKER_STR(5);private int key;IdType(int key) {this.key = key;}
}
这里验证了一下,当设置成这样时,就能正常生成数据库自增的id了,使用数据库AUTO_INCREMENT从1开始自增的效果了,当然,其实使用IdType.AUTO也是可以的——
@Data
@TableName("test")
public class Test extends Model<Test> implements Serializable {@TableId(value = "id", type = IdType.INPUT)private Long id;......
}
百度网上的说法,当Mybatis-Plus实体类没有显示设置主键策略时,将默认使用雪花算法生成,也就是IdType.ID_WORKER或者IdType.ID_WORKER_STR,具体是long类型的19位还是字符串的19位,应该是根据字段定义类型来判断。
snowflake算法是Twitter开源的分布式ID生成算法,结果是一个long类型的ID 。其核心思想:使用41bit作为毫秒数,10bit作为机器的ID(5bit数据中心,5bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每个毫秒可以产生4096个ID),最后还有一个符号位,永远是0。
接下来,先验证Mybatis-Plus默认主键策略是如何的。
Mybatis-Plus项目在启动时,会对注解实体类进行初始化,然后缓存到系统Map中。
这里,只需要关注Mybatis-Plus源码TableInfoHelper类中的initTableInfo方法即可,这个方法在项目启动时会被调用,然后初始化所有注解@TableName的实体类。与主键根据哪种策略来设置的逻辑在方法initTableFields(clazz, globalConfig, tableInfo)当中——
public synchronized static TableInfo initTableInfo(MapperBuilderAssistant builderAssistant, Class<?> clazz) {TableInfo tableInfo = TABLE_INFO_CACHE.get(clazz.getName());if (tableInfo != null) {if (tableInfo.getConfigMark() == null && builderAssistant != null) {tableInfo.setConfigMark(builderAssistant.getConfiguration());}return tableInfo;}/* 没有获取到缓存信息,则初始化 */tableInfo = new TableInfo();GlobalConfig globalConfig;if (null != builderAssistant) {tableInfo.setCurrentNamespace(builderAssistant.getCurrentNamespace());tableInfo.setConfigMark(builderAssistant.getConfiguration());tableInfo.setUnderCamel(builderAssistant.getConfiguration().isMapUnderscoreToCamelCase());globalConfig = GlobalConfigUtils.getGlobalConfig(builderAssistant.getConfiguration());} else {// 兼容测试场景globalConfig = GlobalConfigUtils.defaults();}/* 初始化表名相关 */initTableName(clazz, globalConfig, tableInfo);/* 初始化字段相关 */initTableFields(clazz, globalConfig, tableInfo);/* 放入缓存 */TABLE_INFO_CACHE.put(clazz.getName(), tableInfo);/* 缓存 Lambda 映射关系 */LambdaUtils.createCache(clazz, tableInfo);return tableInfo;
}
在初始化字段相关的initTableFields方法里,会判断是否有@TableId 注解,如果没有,就执行initTableIdWithoutAnnotation方法,连续前文提到的,如果实体类id没有加@TableId(value = "id", type = IdType.INPUT),那么就会取默认的主键策略。这里的判断是否有@TableId 注解,就是判断是否需要取默认的主键策略,至于具体是如何设置默认主键的,我们可以直接进入到initTableIdWithoutAnnotation方法当中。
public static void initTableFields(Class<?> clazz, GlobalConfig globalConfig, TableInfo tableInfo) {/* 数据库全局配置 */GlobalConfig.DbConfig dbConfig = globalConfig.getDbConfig();List<Field> list = getAllFields(clazz);// 标记是否读取到主键boolean isReadPK = false;// 是否存在 @TableId 注解boolean existTableId = isExistTableId(list);List<TableFieldInfo> fieldList = new ArrayList<>();for (Field field : list) {/** 主键ID 初始化*/if (!isReadPK) {if (existTableId) {isReadPK = initTableIdWithAnnotation(dbConfig, tableInfo, field, clazz);} else {isReadPK = initTableIdWithoutAnnotation(dbConfig, tableInfo, field, clazz);}if (isReadPK) {continue;}}......}......
}
initTableIdWithoutAnnotation方法——
private static final String DEFAULT_ID_NAME = "id";
/*** <p>* 主键属性初始化* </p>** @param tableInfo 表信息* @param field 字段* @param clazz 实体类* @return true 继续下一个属性判断,返回 continue;*/
private static boolean initTableIdWithoutAnnotation(GlobalConfig.DbConfig dbConfig, TableInfo tableInfo,Field field, Class<?> clazz) {//获取实体类字段名String column = field.getName();if (dbConfig.isCapitalMode()) {column = column.toUpperCase();}//当字段名为idif (DEFAULT_ID_NAME.equalsIgnoreCase(column)) {if (StringUtils.isEmpty(tableInfo.getKeyColumn())) {tableInfo.setKeyRelated(checkRelated(tableInfo.isUnderCamel(), field.getName(), column))//设置表策略.setIdType(dbConfig.getIdType()).setKeyColumn(column).setKeyProperty(field.getName()).setClazz(field.getDeclaringClass());return true;} else {throwExceptionId(clazz);}}return false;
}
Debug到这里,可以看到,如果没有 @TableId 注解显示设置主键策略情况下,默认设置的是 ID_WORKER(3),即会根据雪花算法生成19位数字,long类型。
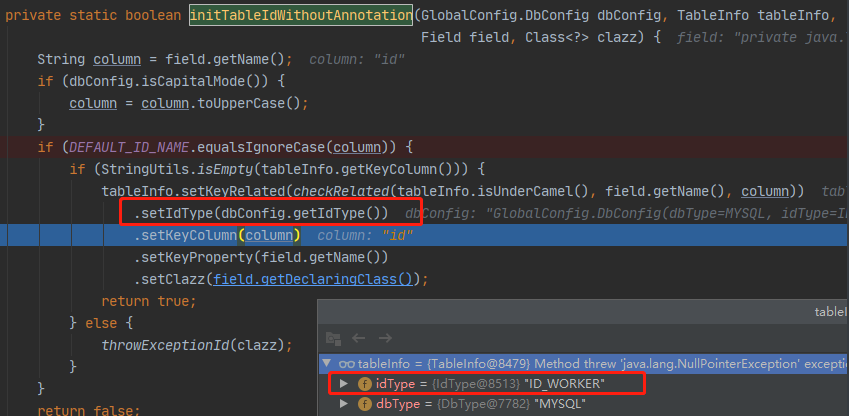
可以进一步发现,这里的 dbConfig是GlobalConfig.DbConfig实例,进入到DbConfig类,可以看到原来实体类映射的数据库设置在这里,主键类型默认是IdType.ID_WORKER。
@Data
public static class DbConfig {/*** 数据库类型*/private DbType dbType = DbType.OTHER;/*** 主键类型(默认 ID_WORKER)*/private IdType idType = IdType.ID_WORKER;/*** 表名前缀*/private String tablePrefix;/*** 表名、是否使用下划线命名(默认 true:默认数据库表下划线命名)*/private boolean tableUnderline = true;/*** String 类型字段 LIKE*/private boolean columnLike = false;/*** 大写命名*/private boolean capitalMode = false;/*** 表关键词 key 生成器*/private IKeyGenerator keyGenerator;/*** 逻辑删除全局值(默认 1、表示已删除)*/private String logicDeleteValue = "1";/*** 逻辑未删除全局值(默认 0、表示未删除)*/private String logicNotDeleteValue = "0";/*** 字段验证策略*/private FieldStrategy fieldStrategy = FieldStrategy.NOT_NULL;
}
至于如何生成雪花算法id,这里就不一一详细介绍,具体逻辑是在MybatisDefaultParameterHandler类populateKeys方法里,核心代码如下——
protected static Object populateKeys(MetaObjectHandler metaObjectHandler, TableInfo tableInfo,MappedStatement ms, Object parameterObject, boolean isInsert) {if (null == tableInfo) {/* 不处理 */return parameterObject;}/* 自定义元对象填充控制器 */MetaObject metaObject = ms.getConfiguration().newMetaObject(parameterObject);// 填充主键if (isInsert && !StringUtils.isEmpty(tableInfo.getKeyProperty())&& null != tableInfo.getIdType() && tableInfo.getIdType().getKey() >= 3) {Object idValue = metaObject.getValue(tableInfo.getKeyProperty());/* 自定义 ID */if (StringUtils.checkValNull(idValue)) {if (tableInfo.getIdType() == IdType.ID_WORKER) {metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.getId());} else if (tableInfo.getIdType() == IdType.ID_WORKER_STR) {metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.getIdStr());} else if (tableInfo.getIdType() == IdType.UUID) {metaObject.setValue(tableInfo.getKeyProperty(), IdWorker.get32UUID());}}}......
}
前边提到,默认的主键策略是IdType.ID_WORKER,这里有一个判断tableInfo.getIdType() == IdType.ID_WORKER,对代码Debug可以看到,metaObject的setValue(tableInfo.getKeyProperty(), IdWorker.getId())代码的作用,是对注解id进行了值填充。

填充的值为IdWorker.getId()返回的1468970800437465089,刚好是19位长度,这就意味着,这里产生的id值,就是我们最后要找的。
IdWorker.getId()实现本质,正好是基于Snowflake实现64位自增ID算法,而Snowflake,正是引用了雪花算法——
/*** <p>* 高效GUID产生算法(sequence),基于Snowflake实现64位自增ID算法。 <br>* 优化开源项目 http://git.oschina.net/yu120/sequence* </p>** @author hubin* @since 2016-08-01*/
public class IdWorker {/*** 主机和进程的机器码*/private static final Sequence WORKER = new Sequence();public static long getId() {return WORKER.nextId();}public static String getIdStr() {return String.valueOf(WORKER.nextId());}/*** <p>* 获取去掉"-" UUID* </p>*/public static synchronized String get32UUID() {return UUID.randomUUID().toString().replace(StringPool.DASH, StringPool.EMPTY);}}




之hwclock)







:为APP程序添加命令)






 完整版)