解决Vision Transformer在任意尺寸图像上微调的问题:使用timm库
文章目录
- 一、ViT的微调问题的本质
- 二、Positional Embedding如何处理
- 1,绝对位置编码
- 2,相对位置编码
- 3,对位置编码进行插值
- 三、Patch Embedding Layer如何处理
- 四、使用timm库来对任意尺寸进行微调
一、ViT的微调问题的本质
自从ViT被提出以来,在CV领域引起了新的研究热潮。理论上来说,Transformer的输入是一个序列,并且其参数主要来自于Transformer Block中的Linear层,因此Transformer可以处理任意长度的输入序列。但是在Vision Transformer中,由于需要将二维的图像通过Patch Embedding Layer映射为一个一维的序列,并且需要添加pos_embedding来保留位置信息。因此当patch_size和img_size发生改变时,会造成pos_embbeding的长度和Patch Embedding Layer的参数发生改变,从而导致预训练权重无法直接加载。更多有关ViT的实现细节和原理,可以参考Vision Transformer , 通用 Vision Backbone 超详细解读 (原理分析+代码解读)。
二、Positional Embedding如何处理
在Vision Transformer中有两种主流的编码方式:相对位置编码和绝对位置编码。
1,绝对位置编码
绝对位置编码依据token每个的绝对位置分配一个固定的值,其本质上是一组一维向量,有两种实现方式:
# 可学习的位置编码,ViT中使用, +1是因为有cls_tokenself.pos_embedding = nn.Parameter(torch.randn(1, num_patches+1, dim))# 根据正余弦获取位置编码, Transformer中使用
def get_positional_embeddings(sequence_length,dim):result = torch.ones(sequence_length,dim)for i in range(sequence_length):for j in range(dim):result[i][j] = np.sin(i/(10000**(j/dim))) if j %2==0 else np.cos(i/(10000**((j-1)/dim)))return result
在forward过程中,绝对位置编码会在最开始直接和token相加:
tokens += self.pos_embedding[:, :(n + 1)]
2,相对位置编码
相对位置编码,依据每个token的query相对于key的位置来分配位置编码,典型例子就是swin transformer,其本质是构建一个可学习的二维table,然后依据相对位置索引(x,y)来从table中取值,具体可以参考:有关swin transformer相对位置编码的理解
不过,在swin transformer中,query和key都是来自于同一个window,因此query和key的数量相同,构建位置编码的方式相对来说比较简单。如果query和key的数量不同,例如Focal Transformer中多层次的self-attention,其位置编码的方式可以参考:Focal Transformer。
对于相对位置编码的构造,还有一种方式是CrossFormer中提出的Dynamic Position Bias。其核心思想为构建一个MLP,其输入是二维的相对位置索引,输出是指定dim的位置偏置。这个和根据正余弦获取位置编码有点类似,只不过一个是依据一维的绝对坐标来生成位置编码,一个是依据二维的相对坐标来生成位置编码。
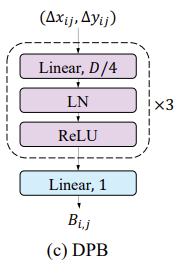
在forward过程中,相对位置编码不会在一开始与token相加,而是在Attention Layer中以Bias的形式参与self-attention计算,核心代码如下:
attn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)
3,对位置编码进行插值
综上,我们可以依据实现方式将位置编码分为两大类:可学习的位置编码(例如,ViT、Swin Transformer、Focal Transformer等)和生成式的位置编码(例如,正余弦位置编码和CrossFormer中的DPB)。更多有关位置编码的内容,可以参考论文:Rethinking and Improving Relative Position Encoding for Vision Transformer。对于生成式的位置编码而言,其编码方式与序列长度无关,因此当patch_size和img_size改变而造成num_patches改变时,仍然可以加载与位置编码有关的预训练权重。
但是,对于可学习的位置编码而言,num_patches改变时,无法直接加载与位置编码的预训练权重。以ViT为例,其参数一般是一个shape为[N+1, C]的tensor。与cls_token有关的位置编码不用改变,我们只需要关心与img patch相关的位置编码即可,其shape为[N, C]。当num_patches变为n时,所需要位置编码shape为[n, C]。这显然无法直接加载预训练权重。
Pytorch官方提供了一种思路,通过插值算法,来获取新的权重。我们不妨将原始的位置编码想象为一个shape为[ N , N , C \sqrt{N}, \sqrt{N}, C N,N,C]的tensor,将所需要的位置编码想象为一个shape为[ n , n , C \sqrt{n}, \sqrt{n}, C n,n,C]。这样我们就可以通过插值算法,将原始的权重映射到所需要的权重上。核心代码如下:
# (1, hidden_dim, seq_length) -> (1, hidden_dim, seq_l_1d, seq_l_1d)pos_embedding_img = pos_embedding_img.reshape(1, hidden_dim, seq_length_1d, seq_length_1d)new_seq_length_1d = image_size // patch_size# Perform interpolation.# (1, hidden_dim, seq_l_1d, seq_l_1d) -> (1, hidden_dim, new_seq_l_1d, new_seq_l_1d)new_pos_embedding_img = nn.functional.interpolate(pos_embedding_img,size=new_seq_length_1d,mode=interpolation_mode,align_corners=True,)# (1, hidden_dim, new_seq_l_1d, new_seq_l_1d) -> (1, hidden_dim, new_seq_length)new_pos_embedding_img = new_pos_embedding_img.reshape(1, hidden_dim, new_seq_length)# (1, hidden_dim, new_seq_length) -> (1, new_seq_length, hidden_dim)new_pos_embedding_img = new_pos_embedding_img.permute(0, 2, 1)
不过,Pytorch官方的这个代码,只能适配当num_patches是一个完全平方数的情况,因为需要开根号操作。实际上,num_patches一般是通过如下方式计算获得,理论上来说通过插值算法是可以适配到任意尺寸的num_patches的。
n u m _ p a t c h e s = i m g _ s i z e h p a t c h _ s i z e h i m g _ s i z e w p a t c h _ s i z e w (1) num\_patches=\frac{img\_size_h}{patch\_size_h}\frac{img\_size_w}{patch\_size_w} \tag{1} num_patches=patch_sizehimg_sizehpatch_sizewimg_sizew(1)
从上式可以看出,pos_embedding主要与img_size/patch_size有关,因此当把img_size和patch_size等比例缩放时,是不需要调整pos_embedding的。
在timm库中,提供了resample_abs_pos_embed函数,并将其集成到了VisionTransformer类中,所以我们在使用时无需自己考虑对位置编码进行插值处理。
三、Patch Embedding Layer如何处理
Patch Embedding Layer用于将二维的图像转为一维的输入序列,其实现方式通常有两种,如下所示:
### 基于MLP的实现方式patch_dim = in_channels * patch_height * patch_widthself.patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width), # 使用einops库nn.LayerNorm(patch_dim),nn.Linear(patch_dim, dim),nn.LayerNorm(dim),)### 基于Conv2d的实现方式self.patch_embedding = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size, bias=bias)
从这两种实现可以看出,Patch Embedding Layer的参数主要与patch_size和in_channels有关,而与img_size无关。Pytorch官方和Timm库都采用基于Conv2d的方式来实现,当patch_size和in_channels改变时,无法直接加载预训练权重。
Pytorch官方并未给出解决方案,timm库通过resample_patch_embed来解决这一问题,并且也集成到了VisionTransformer类中。在使用时,我们也不需要考虑手动对Patch Embedding Layer的权重进行调整。
四、使用timm库来对任意尺寸进行微调
首先需要安装timm库
pip install timm
# 如果安装的Pytorch2.0及以上版本,无需考虑一下步骤
# 如果是其他版本的Pytorch,需要下载functorch库
pip install functorch==版本号
# 具体版本号,需要依据自己环境中的pytorch版本来
# 例如:0.20.0对应Pytorch1.12.0,0.2.1对应Pytorch1.12.1
# 对应关系可以去github上查看:https://github.com/pytorch/functorch/releases
代码示例如下:
import timm
from timm.models.registry import register_model@register_model # 注册模型
def vit_tiny_patch4_64(pretrained: bool = False, **kwargs) -> VisionTransformer:""" ViT-Tiny (Vit-Ti/16)"""# 在model_args中对需要部分参数进行修改,此处调整了img_size, patch_size和in_chansmodel_args = dict(img_size = 64, patch_size=4, in_chans=1, embed_dim=192, depth=12, num_heads=3) # vit_tiny_patch16_224是想要加载的预训练权重对应的模型model = _create_vision_transformer('vit_tiny_patch16_224', pretrained=pretrained, **dict(model_args, **kwargs)) return model# 注册模型之后,就可以通过create_model来创建模型了
vit = timm.create_model('vit_tiny_patch4_64', pretrained = True)
不过,由于预训练权重在线下载一般比较慢,可以通过pretrained_cfg来实现加载本地模型,代码如下:
vit = timm.create_model('vit_tiny_patch4_64')cfg = vit.default_cfgprint(cfg['url']) # 查看下载的url来手动下载cfg['file'] = 'vit-tiny.npz' # 这里修改为你下载的模型vit = timm.create_model('vit_tiny_patch4_64', pretrained=True, pretrained_cfg=cfg).cuda()

)









![BUUCTF--[ACTF2020 新生赛]Include](http://pic.xiahunao.cn/BUUCTF--[ACTF2020 新生赛]Include)







