在信息时代,海量的文本数据不断地涌现。如何从这如山如海的文本中提取有意义的信息,成为了一项关键任务。Python语言提供了许多优秀的库和工具来处理文本数据,其中一款备受推崇的工具就是Gensim库。Gensim是一个开源的Python库,它是构建主题模型和进行文本相似度计算的先进工具。本文将介绍Gensim库,解释其基本原理和功能,并通过实例演示如何使用Gensim库进行文本处理和主题建模。
一、Gensim库简介
Gensim是一个用于主题建模、文档相似度和文本处理的成熟库,其设计目标是提供一种简单、高效的工具来处理大型文本语料库。它在Python语言中实现了许多用于处理文本数据的算法和模型,例如词向量模型、主题模型和文档相似度计算等。Gensim库的强项在于处理大型数据集时的高效性能和灵活性。

二、基本原理和核心功能
1. 词向量模型
Gensim库的一个重要功能是训练词向量模型。词向量是将单词转换为实数向量表示的方法,它能够捕捉单词之间的语义关系。Gensim库通过实现Word2Vec和FastText等算法来训练词向量模型。这些模型可用于计算单词之间的相似度、查找与给定单词最相关的单词以及对文本语义进行建模。
2. 主题建模
Gensim库还实现了一些著名的主题模型算法,如Latent Dirichlet Allocation (LDA)和Latent Semantic Analysis (LSA)等。这些算法能够从文本语料中提取主题,并将文档映射到主题空间中。主题模型可以帮助我们理解大规模文本语料的结构和主题分布,从而发现潜藏在数据中的信息。
3. 文档相似度计算
另外,Gensim库提供了一些方法来计算文档之间的相似度。它支持余弦相似度、欧氏距离和Jaccard相似度等不同度量方式。这些计算方法可以应用于文本分类、信息检索和推荐系统等应用场景。
三、示例应用
为了更好地理解Gensim库的使用方法,我们将通过一个示例来演示其在文本处理和主题建模中的应用。
假设我们有一个包含大量新闻文章的文本语料库,我们希望从中提取主题并计算文档之间的相似度。首先,我们可以使用Gensim库训练一个LDA主题模型,从语料库中提取出潜在的主题。然后,我们可以使用训练好的模型对每篇新闻文章进行主题推断,得到每篇文章在主题空间中的分布。接下来,我们可以计算不同文章之间的相似度,以找出与给定文章最相似的文章。
四、总结
本文介绍了Python中强大的文本处理和主题建模工具——Gensim库。Gensim库为用户提供了词向量模型、主题模型和文档相似度计算等功能,使得处理大型文本语料库变得简单高效。通过使用Gensim库,我们可以更好地理解文本数据中的信息,并从中提取有意义的知识。希望本文能为读者提供一个入门理解Gensim库的指南,鼓励读者进一步探索和应用Gensim库在文本处理和主题建模相关任务中的潜力。
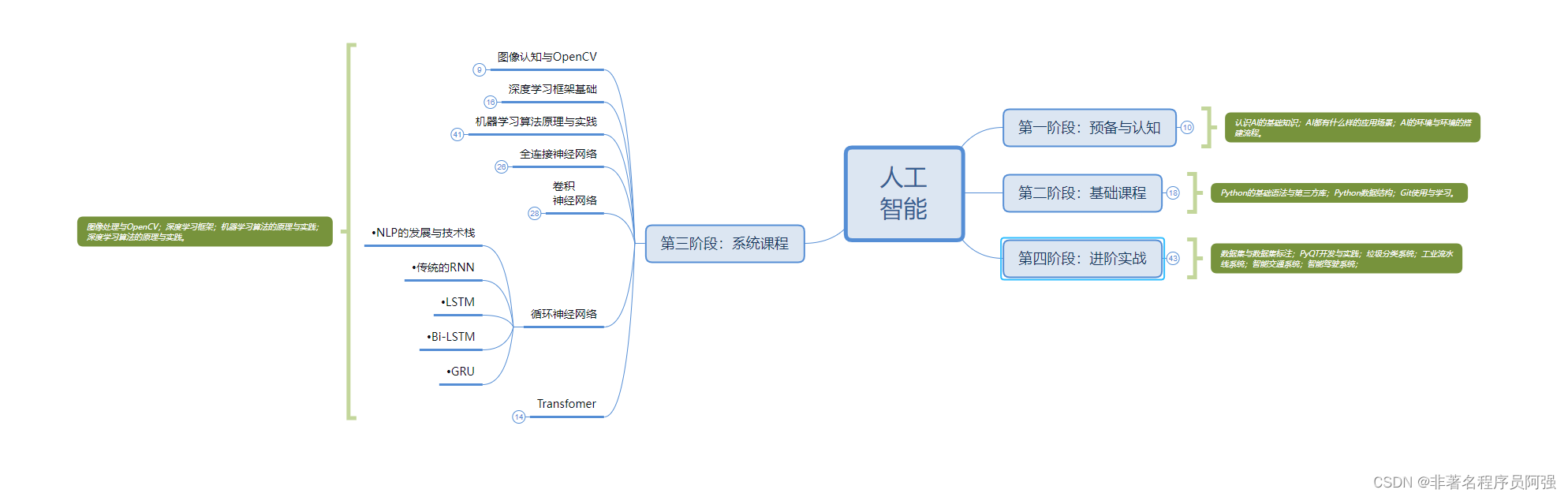
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得点赞、关注、收藏、转发哦!扫码进群领资料