
一、说明
在这篇文章中,我们将了解一种旗舰的光流深度学习方法,该方法获得了 2020 年 ECCV 最佳论文奖,并被引用超过 1000 次。它也是KITTI基准测试中许多性能最佳的模型的基础。该模型称为 RAFT:Recurrent All-Pairs Field Transforms for Optical Flow,可在 PyTorch 或 GitHub 上轻松获得。这些实现使其具有高度可访问性,但模型很复杂,理解它可能会令人困惑。在这篇文章中,我们将把 RAFT 分解成它的基本组件,并详细了解它们中的每一个。然后我们将学习如何在 Python 中使用它来估计光流。在第 2 部分中,我们将探索晦涩难懂的细节并可视化不同的块,以便我们可以更深入地了解它们的工作原理。
- 介绍
- RAFT的基础
- 视觉相似性
- 迭代更新
- 如何使用 RAFT
- 结论
二、基本概念介绍
2.1 光流的概念
光流是图像序列中像素的表观运动。为了估计光流,场景中物体的运动必须具有相应的亮度位移。这意味着一张图像中移动的红球在下一张图像中应该具有相同的亮度和颜色,这使我们能够确定它在像素方面移动了多少。图 1 显示了一个光流示例,其中逆时针旋转的吊扇被一系列图像捕获。

最右边的彩色图像包含从第 1 帧到第 2 帧的每个像素的表观运动,它是用颜色编码的,使得不同的颜色表示像素运动的不同水平和垂直方向。这是密集光流估计的一个例子。
密集光流的估计为每个像素分配一个 2D 流向量,描述其在时间间隔内的水平和垂直位移。在稀疏光流中,此矢量仅分配给与强特征(如角和边缘)相对应的像素。为了使流矢量存在,像素在时间 t 时的强度必须与在时间 t+1 时具有相同的强度,这称为亮度一致性假设。时间 t 处位置 (x,y) 的图像强度或亮度由 I(x,y,t) 给出。 让我们通过图 2 中已知像素位移的示例来可视化这一点,其中 dx 和 dy 是水平和垂直图像位移,dt 是帧之间的时间差。
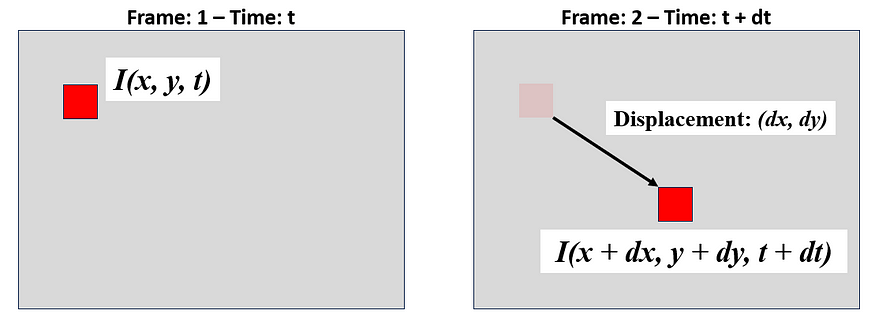
亮度一致性假设意味着 (x,y,t) 处的像素在 (x+dx, y+dy, t+dy) 处具有相同的强度。因此:I(x, y, t) = I(x+dx, y+dy, t+dt)。
2.2光流方程和推导
根据亮度一致性假设,我们可以通过用大约 (x, y, t) 的一阶泰勒近似展开右侧来推导出光流方程 [1]。

水平和垂直梯度 Iₓ 和 Iγ 可以用 Sobel 算子和时间梯度近似 这是已知的,因为我们在时间 t 和 t+1 处有图像。流动方程有两个未知数 u 和 v,它们是随时间变化的水平和垂直位移 dt。单个方程中的两个未知数使得这是一个未确定的问题,并且已经进行了许多尝试来求解 u 和 v。
RAFT 是一种用于估计 u 和 v 的深度学习方法,但它实际上比仅仅基于两帧预测流量更复杂。它经过精心设计以准确估计光流场,在下一节中,我们将深入探讨其复杂的细节。
三、RAFT的基础
3.1 整体架构
RAFT 是一个深度神经网络,能够在给定一对连续图像 I₁ 和 I₂ 的情况下估计密集光流。它估计一个流动位移场 (f¹, f²),该场将 I₁ 中的每个像素 (u, v) 映射到 I₂ 中相应的像素 (u', v'),其中 (u', v') = (u + f¹(u), v + f²(v)) .它的工作原理是提取特征,找到它们的相关性,然后以模仿优化算法的方式迭代更新流程。初始流量可以初始化为全部 0,也可以使用前向预测的先前流量估计值进行初始化,这称为热启动。整体架构如下所示。

请注意它有三个主要块:Feature Encoder 块、Visual Similarity 块和 Iterative Update 块。RAFT 架构有两种尺寸,一种是 4 万个参数的大型架构,另一种是 8 万个参数的小型架构,在这篇文章中,我们将重点介绍大型架构,但是一旦我们了解了大型架构,了解小型架构将变得无关紧要。
3.2 特征提取
RAFT 使用卷积神经网络 (CNN) 对两个输入图像执行特征提取,该网络由六个残差块组成,并使用 D 特征图将每个图像下采样到 1/8 分辨率。
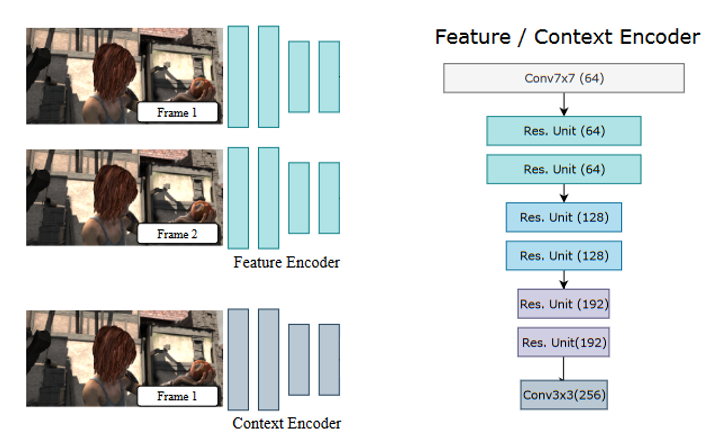
特征编码器网络 g 对具有共享权重的两个图像进行操作,而上下文编码器网络 f 仅在 I₁ 上运行并提取作为流量估计主要参考的特征。除了细微的差异外,两个网络的整体架构几乎相同。上下文网络使用批量归一化,而特征网络使用实例归一化,上下文网络提取 C = c + h 特征图,其中 c 是上下文特征图的数量,h 是将初始化迭代更新块隐藏状态的隐藏特征图的数量。

要素网络 f 和上下文网络 g 的函数映射。 资料来源:作者。
注意:原始论文经常使用简写符号 H/8xW/8 引用特征图尺寸:HxW。这可能会令人困惑,因此我们将遵循 H' = H/8 的约定,使特征图大小为 H'xW'。我们还参考了从 I₁ as g¹ 中提取的特征图张量,同样用于 I₂。
四、视觉相似性
4.1 相关体积
视觉相似度是 4D H'xW'xH'xW' All-Pairs Correlation Volume C,通过取特征图的点积计算得出。
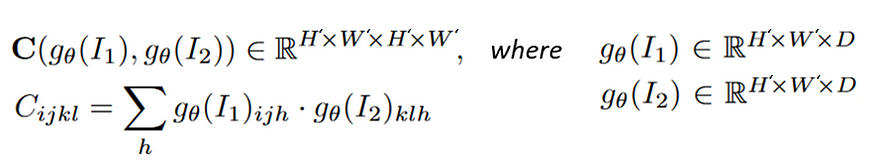
在相关体积中,特征图 g¹ 中的每个像素都与特征图 g² 中的每个像素具有计算的相关性,我们将这些相关性中的每一个称为 2D 响应图(见图 5)。在 4D 中思考可能具有挑战性,因此想象一下将体积的前两个维度展平:(H'xW')xH'xW',我们现在有一个 3D 体积,其中 g¹ 的每个像素都有自己的 2D 响应图,显示它与 g² 的每个像素位置的相关性。 由于特征是从图像派生的,因此响应映射实际上指示给定的 I₁ 像素与每个 I₂ 像素的相关程度。
视觉相似度是一个全对相关体积,它通过计算每个像素位置的每个特征图的相关性,将 I₁ 的像素与 I₂ 的每个像素相关联
4.2 相关性金字塔
相关体积有效地为小像素位移提供了信息,但可能难以捕获较大的位移。为了捕获大像素位移和小像素位移,需要多级相关性。为了解决这个问题,我们构建了一个相关金字塔,其中包含多个级别的相关体积,其中通过平均汇集相关体积的最后两个维度来产生不同级别的相关体积。平均池化操作在体积的最后两个维度中产生粗略的 I₂ 相关特征,这使得 I₁ 的精细特征能够与 I₂ 的逐渐粗略特征相关联。 每个金字塔级别都包含越来越小的 2D 响应图。

图 5 显示了不同级别平均池化的不同 2D 响应图。相应相关体积的维度堆叠在一起形成一个 5D 相关金字塔,其中包含四个具有内核大小的级别:1、2、4 和 8。 金字塔提供了关于大位移和小位移的可靠信息,同时保持了相对于 I₁ 的高分辨率。
4.3 关联查找
Correlation Lookup Operator L꜀ 通过对每个级别的相关金字塔中的特征进行索引来生成新的特征图。给定当前的光流估计值 (f¹, f²),I₁: x = (u, v) 的每个像素都映射到 I₂ 中的估计对应关系:x' = (u + f¹(u) + v + f²(v))。我们围绕 x' 定义一个局部邻域:
![]()
半径 r 围绕像素 x' = (u', v') 的邻域。资料来源:作者。
对应关系是像素在 I₂ 中的新位置,基于其流量估计
所有金字塔级别的半径恒定意味着将在较低级别中合并更大的上下文。即半径为 4 对应于原始分辨率下的 256 像素。
在实践中,这个邻域是一个以每个精细分辨率像素为中心的方形网格,当 r = 4 时,我们得到一个围绕每个像素的 9x9 网格,其中每个维度的长度为 (2r + 1)。我们通过对网格定义的位置(边缘位置为零填充)的每个像素周围的相关特征进行双倍重采样来获得新的特征图。由于流动偏移和平均池化,邻域格网值可能是浮点,双线性重采样通过获取附近像素的 2x2 子邻域的加权平均值来轻松处理此问题。换句话说,重采样将为我们提供亚像素精度。我们在金字塔每一层的所有像素位置重新采样,这可以通过 PyTorch 的 F.grid_sample() 有效地完成。这些重采样的特征称为关联特征,它们被输入到更新模块中。
4.4 高效的相关性查找(可选)
相关性查找以 O(N²) 缩放,其中 N 是像素数,这可能是大图像的瓶颈,但有一个等效的操作随 O(NM) 缩放,其中 M 是金字塔级别数。此操作将相关金字塔与查找相结合,并且该操作利用了内部积的线性和平均池化。2mx2m 网格上的平均相关响应 Cm(金字塔水平 m)如下所示。

等效相关性实现。 来源。
对于给定的金字塔级别 m,我们不需要对特征图 g¹ 求和,这意味着可以通过将特征图 g¹ 的内积与平均合并特征图 g² 来计算相关性,其复杂度为 O(N)。由于这仅对单个金字塔级别 m 有效,因此我们必须计算每个级别的内积,使其按 O(M) 缩放,总复杂度为 O(NM)。我们没有预先计算金字塔的相关性,而是只预先计算池化的特征图,并在查找发生时按需计算相关性值。
五、迭代更新
更新运算符从初始起点 f₀ 估计一系列流量:{f₀, f₁ ,..., fn},该起点可以是所有 0,也可以是前向预测的先前流量估计(热启动)。在每次迭代 k 中,它都会产生一个流动更新方向 Δf,该方向被添加到当前估计值中:fk₊₁ = fk + Δfk。更新算子模拟优化算法,并经过训练以提供更新,以便估计的流序列收敛到一个固定点:fk → f*。
5.1 更新块
更新模块将相关特征、电流估计、上下文特征和隐藏特征作为输入。下面显示了其带有突出显示子块的架构。

图6.RAFT 更新块,用于突出显示不同子块的大型架构。蓝色 - 特征提取块,红色 — 循环更新块,绿色 - 流头。修改自源。
更新块内的子块是:
- 特征提取模块 — 从相关性、流和 I₁(上下文网络)中提取运动特征。
- Recurrent Update Block — 重复计算流更新
- 流头 — 将流量估计值调整为高/8 x 宽/8 x 2 的最终卷积层
如图 6 所示,Recurrent Update 模块的输入是流、关联和上下文特征的串联。潜在隐藏状态使用上下文网络中的隐藏特征进行初始化。(上下文网络提取一堆 2D 特征图,然后将其分离到上下文和隐藏的特征图中)。循环更新模块由 2 个可分离的 ConvGRU 组成,可在不显着增加网络规模的情况下增加感受野。每次更新时,循环更新块中的隐藏状态都会传递到流头,以获得大小为 H/8 x W/8 x 2 的流量估计值。然后使用凸上采样对该估计值进行上采样。
5.2 凸上采样
RAFT的作者对双线性和凸上采样进行了实验,发现凸上采样提供了显着的性能提升。

图7.双线性与凸上采样的比较。来源。
凸上采样将每个精细像素估计为其相邻的粗像素 3x3 网格的凸组合
让我们来分析一下凸上采样的工作原理,下面的图 8 提供了一个很好的视觉效果。

图8.单个全分辨率像素(紫色)的凸上采样示例。来源。
首先,我们假设一个高分辨率像素是它最近的粗邻居的 3x3 网格的凸组合。此假设意味着粗略像素的加权总和必须等于真正的精细分辨率像素,但权重总和为 64 且为非负。由于我们上采样的系数为 8 倍,因此每个粗略像素必须分解为 8 (8x64) 个精细像素(图 3 中的视觉效果不是按比例缩放的)。我们还注意到,3x8 网格中心的 8 个像素中的每一个都需要自己的权重集,因此所需的权重总数为:(H/8 x W/8 x (9x<>x<>))。
在实践中,权重使用神经网络进行参数化,凸上采样模块使用两个卷积层来预测 (H/8 x W/8 x (8x8x9)) 掩码,然后对九个相邻的权重进行 softmax,留下形状的掩码 (H/8 x W/8 x (8x8))。然后,我们使用此掩码获得邻域上的加权组合,并重塑以获得 HxWx2 流场。
5.3 训练
RAFT 的目标函数能够捕获所有迭代流预测。从形式上讲,它是流动预测和地面实况之间的加权 l1 距离之和,权重呈指数增长。
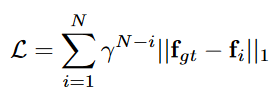
RAFT 的损失,γ = 0.8。来源。
六、如何使用 RAFT
我们可以使用 RAFT 来估计我们自己的图像上的密集光流。首先,我们需要克隆 GitHub 存储库并下载模型。本教程的代码位于 GitHub 上。
!git clone https://github.com/princeton-vl/RAFT.git%cd RAFT
!./download_models.sh
%cd ..根据作者的说法,预训练的 RAFT 模型有几种不同的风格:
- 木筏椅 — 在 FlyingChairs 上训练
- raft-things — 在 FlyingChairs + FlyingThings 上训练
- raft-sintel — 在 FlyingChairs + FlyingThings + Sintel + KITTI 上训练(用于提交的模型)
- raft-kitti — 仅在 KITTI 上微调的 raft-sintel
- raft-small — 接受过 FlyingChairs + FlyingThings 训练
接下来,我们将 RAFT 的核心添加到路径中
sys.path.append('RAFT/core')现在,我们需要一些辅助函数来与 RAFT 类进行交互。 注意:这些帮助程序仅针对 CUDA 编写,但您可以使用 Colab 轻松访问 GPU。
import torch
from raft import RAFT
from utils import flow_viz
from utils.utils import InputPadderdef process_img(img, device='cuda'):return torch.from_numpy(img).permute(2, 0, 1).float()[None].to(device)def load_model(weights_path, args):""" Loads model to CUDA only """model = RAFT(args)pretrained_weights = torch.load(weights_path, map_location=torch.device("cpu"))model = torch.nn.DataParallel(model)model.load_state_dict(pretrained_weights)model.to("cuda")return modeldef inference(model, frame1, frame2, device='cuda', pad_mode='sintel',iters=12, flow_init=None, upsample=True, test_mode=True):model.eval()with torch.no_grad():# preprocessframe1 = process_img(frame1, device)frame2 = process_img(frame2, device)padder = InputPadder(frame1.shape, mode=pad_mode)frame1, frame2 = padder.pad(frame1, frame2)# predict flowif test_mode:flow_low, flow_up = model(frame1,frame2,iters=iters,flow_init=flow_init,upsample=upsample,test_mode=test_mode)return flow_low, flow_upelse:flow_iters = model(frame1,frame2,iters=iters,flow_init=flow_init,upsample=upsample,test_mode=test_mode)return flow_itersdef get_viz(flo):flo = flo[0].permute(1,2,0).cpu().numpy()return flow_viz.flow_to_image(flo)注意 inference() 中的输入填充,我们需要确保所有图像都能被 8 整除。raft.py 代码可以很容易地从命令行访问,但是如果我们想与它交互,我们将需要重写其中的一些代码,或者我们可以创建一个特殊的类来向它传递参数。
# class to interface with RAFT
class Args():def __init__(self, model='', path='', small=False, mixed_precision=True, alternate_corr=False):self.model = modelself.path = pathself.small = smallself.mixed_precision = mixed_precisionself.alternate_corr = alternate_corr""" Sketchy hack to pretend to iterate through the class objects """def __iter__(self):return selfdef __next__(self):raise StopIterationArgs 类的默认初始化将直接与任何大型 RAFT 模型交互。为了演示 RAFT,我们将使用缓慢旋转的吊扇视频中的帧。现在我们可以加载一个模型并估计光流。
model = load_model("RAFT/models/raft-sintel.pth", args=Args())
flow_low, flow_up = inference(model, frame1, frame2, device='cuda', test_mode=True)测试模式将返回 1/8 分辨率流和凸上采样流。

图 9.上图:RAFT的输入图像序列。底部:1/8 分辨率和上采样光流估计值。图片来自作者。资料来源:作者。
再一次,我们可以看到凸上采样的显着好处,现在让我们看看额外迭代的好处。图 10 显示了吊扇图像上 20 次迭代的 gif。
flow_iters = inference(model, frame1, frame2, device='cuda', pad_mode=None, iters=20, test_mode=False)
图 10.光流估计的渐进迭代。
我们可以从前几次迭代中看到明显的好处,在这种情况下,模型能够在大约 10 次迭代中收敛。现在我们将尝试热启动,为了使用热初始化,我们将之前以 1/8 分辨率的流量估计传递给推理函数。
# get previous estimate at 1/8 res
flow_lo, flow_up = inference(model, frame1, frame2, device='cuda', pad_mode=None, iters=20, test_mode=True)# 0 initialization
flow_lo_cold, flow_up_cold = inference(model, frame2, frame3, device='cuda', pad_mode=None, flow_init=None, iters=20, test_mode=True)# warm initialization
flow_lo_warm, flow_up_warm = inference(model, frame2, frame3, device='cuda', pad_mode=None, flow_init=flow_lo, iters=20, test_mode=True)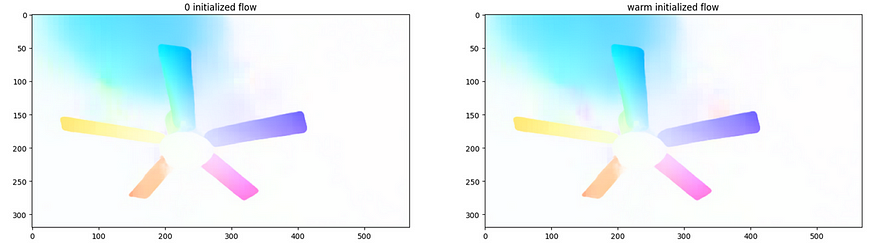
图 11.在第 0 帧和第 2 帧之间使用 3 VS 热初始化进行光流估计。
在这种情况下,我们没有看到任何改进,右侧的热启动实际上看起来比 0 初始化的流程更糟糕。对于此视频序列,热启动的好处似乎微乎其微,但它可能对不同的环境有用。
七、结论
在这篇文章中,我们了解了 RAFT,这是一种能够估计精确流场的高级模型。RAFT 能够通过从提取的特征图中计算全对相关体积来捕获所有像素之间的关系。构建相关金字塔以捕获大像素位移和小像素位移。查找运算符根据当前流量估计值从相关性金字塔中提取新的相关性特征。Update 模块使用相关特征和当前流量估计值来提供迭代更新,这些更新会收敛到最终的流量估计值,该估计值通过凸上采样进行上采样。在第 2 部分中,我们将解压缩网络并了解一些关键块的工作原理。
艾萨克·贝里奥斯


图像描述1)

)

)








)



