5.4. InnoDB 中的统计数据
我们前边唠叨查询成本的时候经常用到一些统计数据,比如通过 SHOW
TABLE STATUS 可以看到关于表的统计数据,通过 SHOW INDEX 可以看到关于索引
的统计数据,那么这些统计数据是怎么来的呢?它们是以什么方式收集的呢?
5.4.1. 统计数据存储方式
InnoDB 提供了两种存储统计数据的方式:
永久性的统计数据,这种统计数据存储在磁盘上,也就是服务器重启之后这些统计数据还在。
非永久性的统计数据,这种统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了,等到服务器重启之后,在某些适当的场景下才会重新收集这些统计数据。
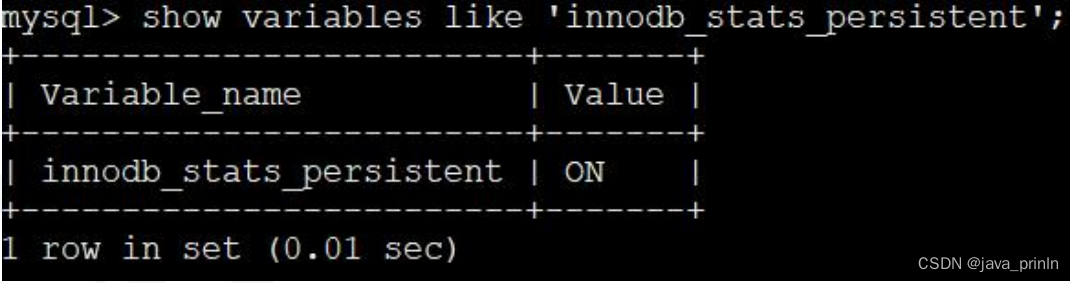
MySQL 给我们提供了系统变量 innodb_stats_persistent 来控制到底采用哪种方式去存储统计数据。在 MySQL 5.6.6 之前,innodb_stats_persistent 的值默认是OFF,也就是说 InnoDB 的统计数据默认是存储到内存的,之后的版本中 innodb_stats_persistent 的值默认是 ON,也就是统计数据默认被存储到磁盘中。
SHOW VARIABLES LIKE 'innodb_stats_persistent';
不过最近的 MySQL 版本都基本不用基于内存的非永久性统计数据了,所以我们也就不深入研究。
不过 InnoDB 默认是以表为单位来收集和存储统计数据的,也就是说我们可以把某些表的统计数据(以及该表的索引统计数据)存储在磁盘上,把另一些表的统计数据存储在内存中。怎么做到的呢?我们可以在创建和修改表的时候通过指定 STATS_PERSISTENT 属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_PERSISTENT = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_PERSISTENT = (1|0);
当 STATS_PERSISTENT=1 时,表明我们想把该表的统计数据永久的存储到磁盘上,当 STATS_PERSISTENT=0 时,表明我们想把该表的统计数据临时的存储到内存中。如果我们在创建表时未指定 STATS_PERSISTENT 属性,那默认采用系统变量 innodb_stats_persistent 的值作为该属性的值。
5.4.2. 基于磁盘的永久性统计数据
当我们选择把某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
SHOW TABLES FROM mysql LIKE 'innodb%';
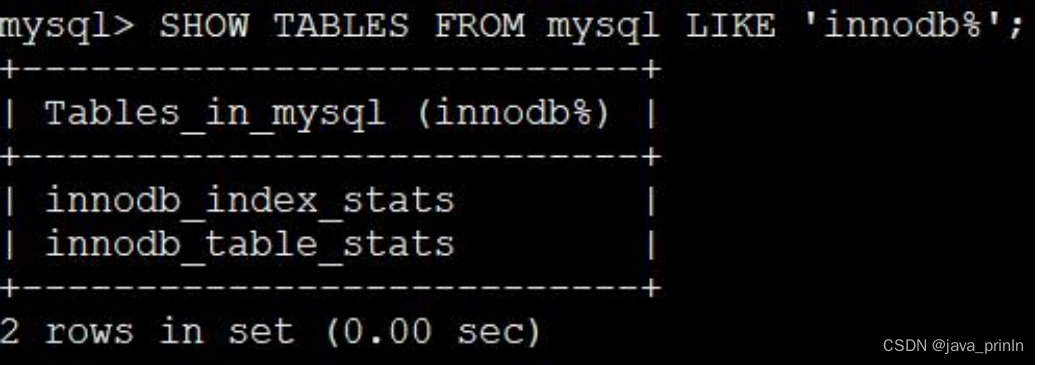
可以看到,这两个表都位于 mysql 系统数据库下边,其中:
innodb_table_stats 存储了关于表的统计数据,每一条记录对应着一个表的统计数据。
innodb_index_stats 存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据。
5.4.2.1. innodb_table_stats
直接看一下这个 innodb_table_stats 表中的各个列都是干嘛的:
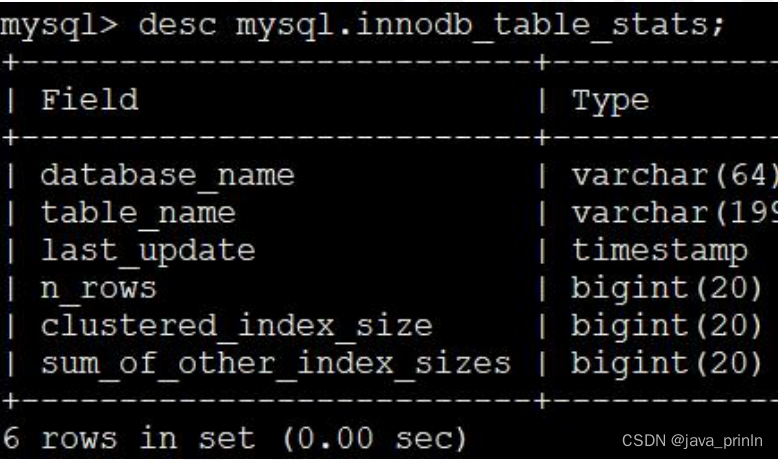
database_name 数据库名
table_name表名
last_update 本条记录最后更新时间
n_rows 表中记录的条数
clustered_index_size 表的聚簇索引占用的页面数量
sum_of_other_index_sizes 表的其他索引占用的页面数量
我们直接看一下这个表里的内容:
SELECT * FROM mysql.innodb_table_stats;
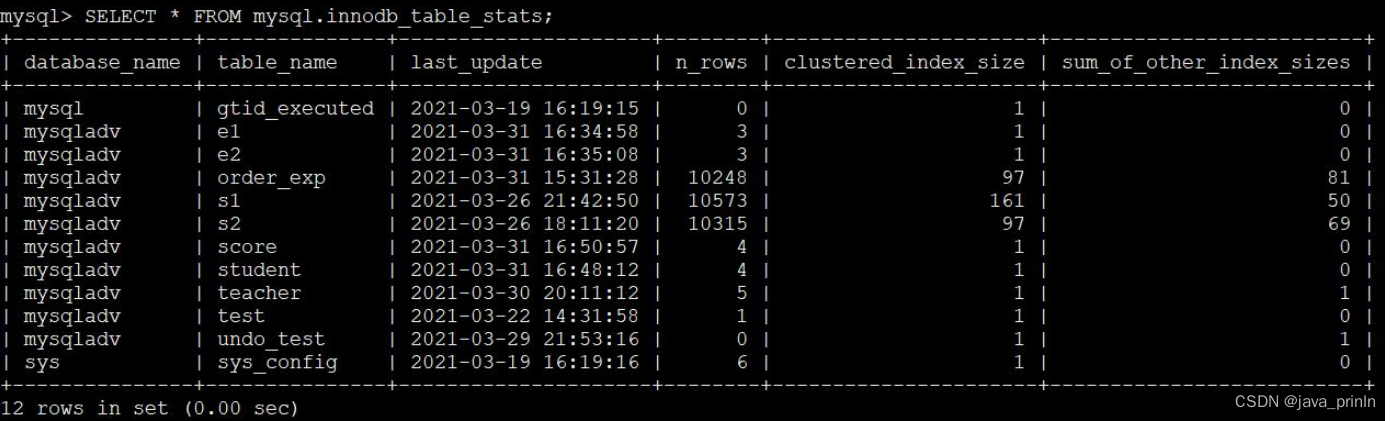
几个重要统计信息项的值如下:
- n_rows 的值是 10350,表明 order_exp 表中大约有 10350 条记录,注意这个数据是估计值。
- clustered_index_size 的值是 97,表明 order_exp 表的聚簇索引占用 97 个页面,这个值是也是一个估计值。
- sum_of_other_index_sizes 的值是 81,表明 order_exp 表的其他索引一共占用81 个页面,这个值是也是一个估计值。
n_rows 统计项的收集
InnoDB 统计一个表中有多少行记录是这样的:
按照一定算法(并不是纯粹随机的)选取几个叶子节点页面,计算每个页面中主键值记录数量,然后计算平均一个页面中主键值的记录数量乘以全部叶子节点的数量就算是该表的 n_rows 值。
可以看出来这个 n_rows 值精确与否取决于统计时采样的页面数量,MySQL用名为 innodb_stats_persistent_sample_pages 的系统变量来控制使用永久性的统计数据时,计算统计数据时采样的页面数量。该值设置的越大,统计出的 n_rows值越精确,但是统计耗时也就最久;该值设置的越小,统计出的 n_rows 值越不精确,但是统计耗时特别少。所以在实际使用是需要我们去权衡利弊,该系统变量的默认值是 20。
InnoDB 默认是以表为单位来收集和存储统计数据的,我们也可以单独设置某个表的采样页面的数量,设置方式就是在创建或修改表的时候通过指定STATS_SAMPLE_PAGES 属性来指明该表的统计数据存储方式.
CREATE TABLE 表名 (…) Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
ALTER TABLE 表名 Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
如果我们在创建表的语句中并没有指定 STATS_SAMPLE_PAGES 属性的话,将默认使用系统变量 innodb_stats_persistent_sample_pages 的值作为该属性的值。
clustered_index_size 和 sum_of_other_index_sizes 统计项的收集牵涉到很具体的 InnoDB 表空间的知识和存储页面数据的细节,我们就不深入讲解了。
5.4.2.2. innodb_index_stats
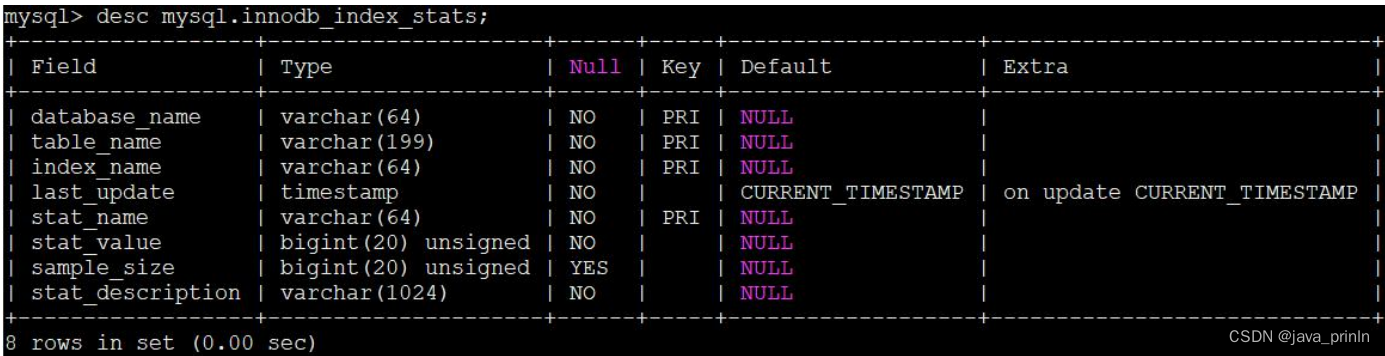
直接看一下这个 innodb_index_stats 表中的各个列都是干嘛的:
desc mysql.innodb_index_stats;
字段名 描述
database_name 数据库名
table_name表名
index_name 索引名
last_update 本条记录最后更新时间
stat_name 统计项的名称
stat_value 对应的统计项的值
sample_size为生成统计数据而采样的页面数量
stat_description对应的统计项的描述
innodb_index_stats 表的每条记录代表着一个索引的一个统计项。可能这会 大家有些懵逼这个统计项到底指什么,别着急,我们直接看一下关于 order_exp 表的索引统计数据都有些什么:
mysql> SELECT * FROM mysql.innodb_index_stats WHERE table_name =
'order_exp';
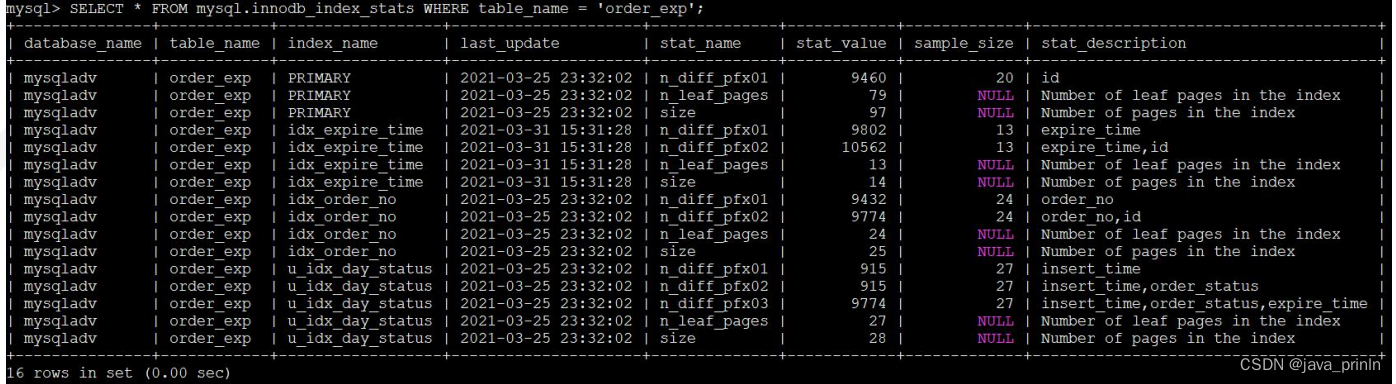
先查看 index_name 列,这个列说明该记录是哪个索引的统计信息,从结果中我们可以看出来,PRIMARY 索引(也就是主键)占了 3 条记录,idx_expire_time 索引占了 6 条记录。
针对 index_name 列相同的记录,stat_name 表示针对该索引的统计项名称,stat_value 展示的是该索引在该统计项上的值,stat_description 指的是来描述该 统计项的含义的。我们来具体看一下一个索引都有哪些统计项:
- n_leaf_pages:表示该索引的叶子节点占用多少页面。
- size:表示该索引共占用多少页面。
- n_diff_pfxNN:表示对应的索引列不重复的值有多少。其中的 NN 长得有点儿怪呀,啥意思呢?
其实 NN 可以被替换为 01、02、03… 这样的数字。比如对于 u_idx_day_status来说:
n_diff_pfx01 表示的是统计 insert_time 这单单一个列不重复的值有多少。
n_diff_pfx02 表示的是统计 insert_time,order_status 这两个列组合起来不重复的值有多少。
n_diff_pfx03 表示的是统计 insert_time,order_status,expire_time 这三个列组合起来不重复的值有多少。
n_diff_pfx04 表示的是统计 key_pare1、key_pare2、expire_time、id 这四个列组合起来不重复的值有多少。
对于普通的二级索引,并不能保证它的索引列值是唯一的,比如对于
idx_order_no 来说,key1 列就可能有很多值重复的记录。此时只有在索引列上加上主键值才可以区分两条索引列值都一样的二级索引记录。
对于主键和唯一二级索引则没有这个问题,它们本身就可以保证索引列值的不重复,所以也不需要再统计一遍在索引列后加上主键值的不重复值有多少。比如 u_idx_day_statu 和 idx_order_no。
在计算某些索引列中包含多少不重复值时,需要对一些叶子节点页面进行采样,sample_size 列就表明了采样的页面数量是多少。
对于有多个列的联合索引来说,采样的页面数量是:
innodb_stats_persistent_sample_pages × 索引列的个数。
当需要采样的页面数量大于该索引的叶子节点数量的话,就直接采用全表扫描来统计索引列的不重复值数量了。所以大家可以在查询结果中看到不同索引对应的 size 列的值可能是不同的。
5.4.2.3. 定期更新统计数据
随着我们不断的对表进行增删改操作,表中的数据也一直在变化,
innodb_table_stats 和 innodb_index_stats 表里的统计数据也在变化。MySQL 提供了如下两种更新统计数据的方式:
开启 innodb_stats_auto_recalc
系统变量 innodb_stats_auto_recalc 决定着服务器是否自动重新计算统计数据,它的默认值是 ON,也就是该功能默认是开启的。每个表都维护了一个变量, 该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表 大小的 10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新 innodb_table_stats 和 innodb_index_stats 表。
不过自动重新计算统计数据的过程是异步发生的,也就是即使表中变动的记录数超过了 10%,自动重新计算统计数据也不会立即发生,可能会延迟几秒才会进行计算。
再一次强调,InnoDB 默认是以表为单位来收集和存储统计数据的,我们也可以单独为某个表设置是否自动重新计算统计数的属性,设置方式就是在创建或修改表的时候通过指定 STATS_AUTO_RECALC 属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
当 STATS_AUTO_RECALC=1 时,表明我们想让该表自动重新计算统计数据,
当 STATS_AUTO_RECALC=0 时,表明不想让该表自动重新计算统计数据。如果我们在创建表时未指定 STATS_AUTO_RECALC 属性,那默认采用系统变量 innodb_stats_auto_recalc 的值作为该属性的值。
手动调用 ANALYZE TABLE 语句来更新统计信息
如果 innodb_stats_auto_recalc 系统变量的值为 OFF 的话,我们也可以手动调用 ANALYZE TABLE 语句来重新计算统计数据,比如我们可以这样更新关于 order_exp 表的统计数据:
mysql> ANALYZE TABLE order_exp;
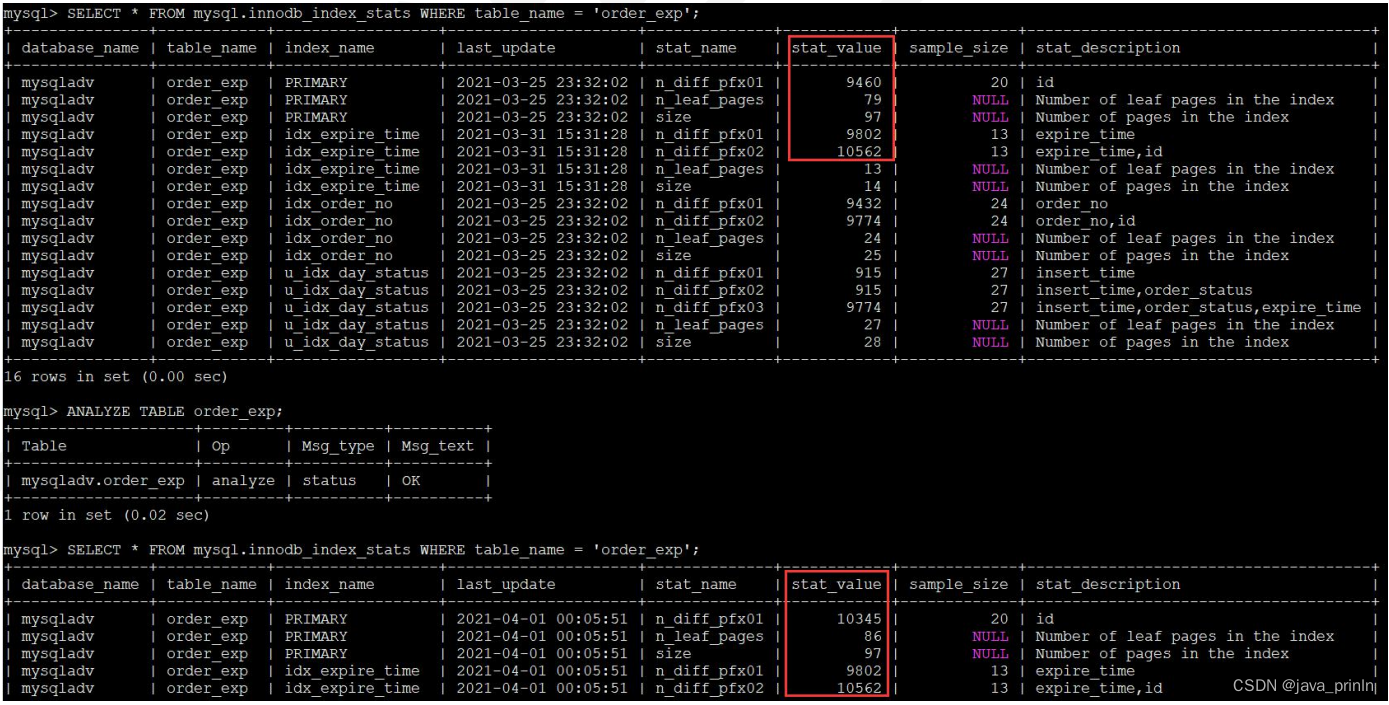
ANALYZE TABLE 语句会立即重新计算统计数据,也就是这个过程是同步的,在表中索引多或者采样页面特别多时这个过程可能会特别慢最好在业务不是很繁忙 的时候再运行。
5.4.2.4. 手动更新 innodb_table_stats 和 innodb_index_stats 表
其实 innodb_table_stats 和 innodb_index_stats 表就相当于一个普通的表一样,我们能对它们做增删改查操作。这也就意味着我们可以手动更新某个表或者索引的统计数据。比如说我们想把 order_exp 表关于行数的统计数据更改一下可以这么做:
步骤一:更新 innodb_table_stats 表。
步骤二:让 MySQL 查询优化器重新加载我们更改过的数据。
更新完 innodb_table_stats 只是单纯的修改了一个表的数据,需要让 MySQL.
查询优化器重新加载我们更改过的数据,运行下边的命令就可以了:
FLUSH TABLE order_exp


)






)
:核心类VisualizerApp)

)




-set介绍)

