⭐ 使用大语言模型构建一个能够回答关于给定文档和文档集合的问答系统是一种非常实用和有效的应用场景。与仅依赖模型预训练知识不同,这种方法可以进一步整合用户自有数据,实现更加个性化和专业的问答服务。 例如,我们可以收集某公司的内部文档、产品说明书等文字资料,导入问答系统中。然后用户针对这些文档提出问题时,系统可以先在文档中检索相关信息,再提供给语言模型生成答案。
这样,语言模型不仅利用了自己的通用知识,还可以充分运用外部输入文档的专业信息来回答用户问题,显著提升答案的质量和适用性。构建这类基于外部文档的问答系统,可以让语言模型更好地服务于具体场景,而不是停留在通用层面。这种灵活应用语言模型的方法值得在实际使用中推广。
基于文档问答的这个过程,我们会涉及 LangChain 中的其他组件,比如:嵌入模型(Embedding Models)和向量储存(Vector Stores)等;
文章目录
- 01、给LLM引入外部知识库的流程
- 02、初始化openai环境
- 03、本章内容采用以下两种方式实现
- 一、方式1:直接使用向量存储查询
- 1.1 导入数据
- 1.2 基于文档加载器创建向量存储
- 1.3 查询创建的向量存储
- 二、 方式2:结合表征模型和向量存储
- 2.1 导入数据
- 2.2 文本向量表征模型
- 2.3 基于向量表征创建并查询向量存储
- 2.4 使用查询结果构造提示来回答问题
- 2.5 使用检索问答链 RetrievalQA 来回答问题
- Reference
01、给LLM引入外部知识库的流程
引入外部知识的主要流程如下(引用 LangChain-Chatchat (原 Langchain-ChatGLM) 项目的图):
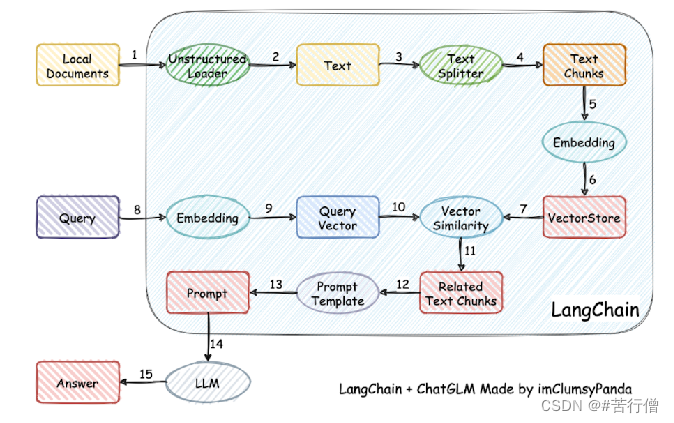
- (1)加载文件
- (2)读取文本
- (3)文本分割
- (4)文本向量化
- (5)问句向量化
- (6)在文本向量中匹配出与问句向量最相似的 top k个
- (7)匹配出的文本作为上下文和问题一起添加到 prompt中
- (8)提交给 LLM生成回答。
匹配出的文本作为上下文和问题一起添加到 prompt中。从文档处理角度来看,实现流程如图所示。核心技术主要是向量 embedding,将用户知识库内容经过 embedding 存入向量知识库,然后用户每一次提问也会经过 embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 prompt 提交给 LLM 回答。

02、初始化openai环境
from langchain.chat_models import ChatOpenAI
import os
import openai
# 运行此API配置,需要将目录中的.env中api_key替换为自己的
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
03、本章内容采用以下两种方式实现
:
疑问点:
我们可以看到章节1中的index.query()的结果和第2章节中用检索问答链RetrievalQA的方法实现的结果是一样的,也许有读者会问,既然index.query()可以只用一行代码就完成了文档问答功能又何必要舍近求远搞一个RetrievalQA这样的对象来实现,并且增加很多繁琐的步骤(有5个步骤)来实现同样的效果呢?Langchain框架的作者Harrison Chase在课件视频中是这么解释的,通过index来进行文档问答,只需一行代码,但是这其中其实隐藏了很多的实现细节,如果我们使用的是RetrievalQA对象来实现文档问答功能,那么我们就可以了解其中的细节比如Embeddings,向量数据库等内容,反正各有各的好处吧。
一、方式1:直接使用向量存储查询
1.1 导入数据
from langchain.chains import RetrievalQA #检索QA链,在文档上进行检索
from langchain.chat_models import ChatOpenAI #openai模型
from langchain.document_loaders import CSVLoader #文档加载器,采用csv格式存储
from langchain.vectorstores import DocArrayInMemorySearch #向量存储
from IPython.display import display, Markdown #在jupyter显示信息的工具
import pandas as pd# 某平台电商数据库
file = './data/kg.csv'# 使用pandas导入数据,用以查看
data = pd.read_csv(file, encoding='gbk')
data.head()

1.2 基于文档加载器创建向量存储
# 使用langchain文档加载器对数据进行导入
loader = CSVLoader(file_path=file)
创建了文档加载器loder以后,我们需要创建一个用于检索文档内容的索引器,这里我们需要指定指定一个向量数据库,我们使用DocArrayInMemorySearch作为向量数据库,DocArrayInMemorySearch是由Docarray提供的文档索引,它将会整个文档以向量的形式存储在内存中,对于小型数据集来说使用DocArrayInMemorySearch会非常方便,接下来我们还要指定一个数据源loder。
这里我们需要说明的是当加载文档后将执行三个主要步骤:
- 1、将文档分割成块
- 2、为每个文档创建embeddings
- 3、将文档和embeddings存储到向量数据库中
#导入向量存储索引创建器
from langchain.indexes import VectorstoreIndexCreator # 创建指定向量存储类, 创建完成后,从加载器中调用, 通过文档加载器列表加载
# VectorstoreIndexCreator可以设置embedding参数,指定embedding的方式
index = VectorstoreIndexCreator(vectorstore_cls=DocArrayInMemorySearch).from_loaders([loader])
1.3 查询创建的向量存储
query ="请用markdown表格的方式列出所有手机品牌,并对其描述进行总结。"#使用索引查询创建一个响应,并传入这个查询
response = index.query(query)
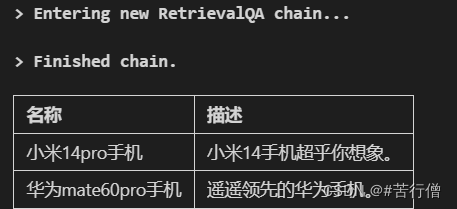
# ' \n\n| 手机品牌 | 描述 |\n| -------- | ---- |\n| 小米14pro | 超乎你想象 |\n| 华为mate60pro | 遥遥领先 |'#查看查询返回的内容
display(Markdown(response))

二、 方式2:结合表征模型和向量存储
这种方式主要为了方便学习其内部细节组成
2.1 导入数据
由于语言模型的上下文长度限制,直接处理长文档具有困难。为实现对长文档的问答,我们可以引入向量嵌入(Embeddings)和向量存储(Vector Store)等技术:
首先,使用文本嵌入(Embeddings)算法对文档进行向量化,使语义相似的文本片段具有接近的向量表示。其次,将向量化的文档切分为小块,存入向量数据库,这个流程正是创建索引(index)的过程。向量数据库对各文档片段进行索引,支持快速检索。这样,当用户提出问题时,可以先将问题转换为向量,在数据库中快速找到语义最相关的文档片段。然后将这些文档片段与问题一起传递给语言模型,生成回答。
通过嵌入向量化和索引技术,我们实现了对长文档的切片检索和问答。这种流程克服了语言模型的上下文限制,可以构建处理大规模文档的问答系统。
#创建一个文档加载器,通过csv格式加载
file = './data/kg.csv'
loader = CSVLoader(file_path=file)
docs = loader.load()#查看单个文档,每个文档对应于CSV中的一行数据
docs
[Document(page_content='name: 耐克跑鞋\ndescription: 男子运动鞋为鞋款匠心融入经典设计,打造复古潮鞋佳选。', metadata={'source': './data/kg.csv', 'row': 0}),Document(page_content='name: chanel 可可小姐香水\ndescription: 清新感性的东方香调,清新活力的柑橘瞬间唤醒感官。', metadata={'source': './data/kg.csv', 'row': 1}),Document(page_content='name: 安踏运动跑鞋鞋\ndescription: 安踏星云轻质慢跑鞋,精心调教的中底材料搭配四大设计亮点,轻松解锁解锁软弹脚感。', metadata={'source': './data/kg.csv', 'row': 2}),Document(page_content='name: 华为mate60pro手机\ndescription: 遥遥领先的华为手机。', metadata={'source': './data/kg.csv', 'row': 3}),Document(page_content='name: 小罐茶彩多泡特级茉莉花茶\ndescription: 一口茶汤落喉间茉莉开,馥郁的花香扑鼻而来,像是沐浴在夏日的茉莉花田瞬间感到清新凉爽。', metadata={'source': './data/kg.csv', 'row': 4}),Document(page_content='name: 小米14pro手机\ndescription: 小米14手机超乎你想象。', metadata={'source': './data/kg.csv', 'row': 5})]
2.2 文本向量表征模型
看一看embedding向量的样子
# 使用OpenAIEmbedding类
from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings() #因为文档比较短了,所以这里不需要进行任何分块,可以直接进行向量表征
#使用初始化OpenAIEmbedding实例上的查询方法embed_query为文本创建向量表征
embed = embeddings.embed_query("你好呀,我的名字叫小可爱")#查看得到向量表征的长度
print("\n\033[32m向量表征的长度: \033[0m \n", len(embed))#每个元素都是不同的数字值,组合起来就是文本的向量表征
print("\n\033[32m向量表征前5个元素: \033[0m \n", embed[:5])
向量表征的长度: 1536向量表征前5个元素: [-0.01954011514905696, -0.006576854850604859, -0.007268821433052672, -0.024199778786441622, -0.02676449759650871]
2.3 基于向量表征创建并查询向量存储
# 将刚才创建文本向量表征(embeddings)存储在向量存储(vector store)中
# 使用DocArrayInMemorySearch类的from_documents方法来实现
# 该方法接受文档列表以及向量表征模型作为输入
db = DocArrayInMemorySearch.from_documents(docs, embeddings)query = "请推荐一部华为手机"
#使用上面的向量存储来查找与传入查询类似的文本,得到一个相似文档列表
docs = db.similarity_search(query, k=3)
print("\n\033[32m返回文档的个数: \033[0m \n", len(docs))
print("\n\033[32m第一个文档: \033[0m \n", docs[0])
返回文档的个数: 4第一个文档: page_content='name: 华为mate60pro手机\ndescription: 遥遥领先的华为手机。' metadata={'source': './data/kg.csv', 'row': 3}
2.4 使用查询结果构造提示来回答问题
llm = ChatOpenAI(temperature = 0.0) #合并获得的相似文档内容
qdocs = "".join([docs[i].page_content for i in range(len(docs))]) #将合并的相似文档内容后加上问题(question)输入到 `llm.call_as_llm`中
#这里问题是:以Markdown表格的方式列出所有具有防晒功能的衬衫并总结
response = llm.call_as_llm(f"{qdocs} 问题:请用markdown表格的方式列出所有手机,并对每种手机的描述进行总结。") display(Markdown(response))

2.5 使用检索问答链 RetrievalQA 来回答问题
通过LangChain创建一个检索问答链,对检索到的文档进行问题回答。检索问答链的输入包含以下:
1、llm: 语言模型,进行文本生成。
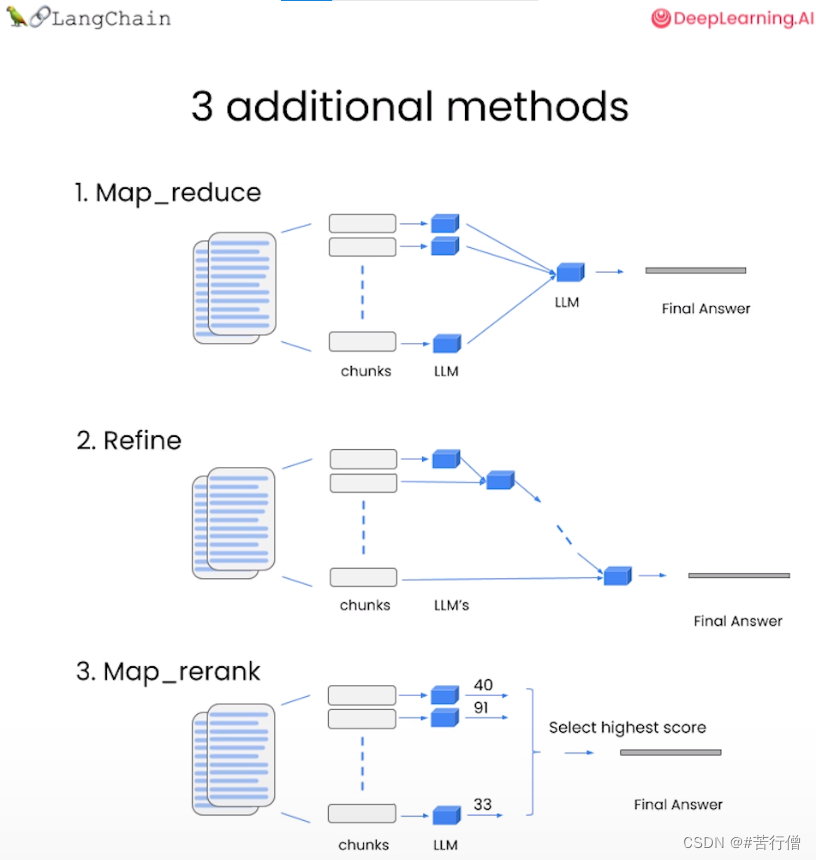
2、chain_type: 传入链类型,这里使用stuff,将所有查询得到的文档组合成一个文档传入下一步。其他的方式包括:
- Map Reduce: 将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的
- Refine: 用于循环许多文档,际上是迭代的,建立在先前文档的答案之上,非常适合前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。它通常需要更长的时间,并且基本上需要与Map Reduce一样多的调用
- Map Re-rank: 对每个文档进行单个语言模型调用,要求它返回一个分数,选择最高分,这依赖于语言模型知道分数应该是什么,需要告诉它,如果它与文档相关,则应该是高分,并在那里精细调整说明,可以批量处理它们相对较快,但是更加昂贵。
3、retriever: 检索器
# 以下方法和上面方法一样,这里一步到位了,检索出来后组合在一起和query一起输入llm。
# 基于向量储存,创建检索器
retriever = db.as_retriever() qa_stuff = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, verbose=True
)#创建一个查询并在此查询上运行链
query = "请用markdown表格的方式列出所有手机,并对每种手机的描述进行总结。"response = qa_stuff.run(query)display(Markdown(response))
Reference
- [1] 吴恩达老师的教程
- [2] DataWhale组织



)
![Mybatis-Plus 自定义SQL注入器,实现真正的批量插入![MyBatis-Plus系列]](http://pic.xiahunao.cn/Mybatis-Plus 自定义SQL注入器,实现真正的批量插入![MyBatis-Plus系列])


-map介绍)

![[uni-app]记录APP端跳转页面自动滚动到底部的bug](http://pic.xiahunao.cn/[uni-app]记录APP端跳转页面自动滚动到底部的bug)




海贼王人物识别)




