文章目录
- 一、Hive建表SQL
- 二、Hive函数
- 三、函数
- 1、查看内置函数
- 2、空字段赋值(nvl)
- 3、CASE WHEN THEN ELSE END
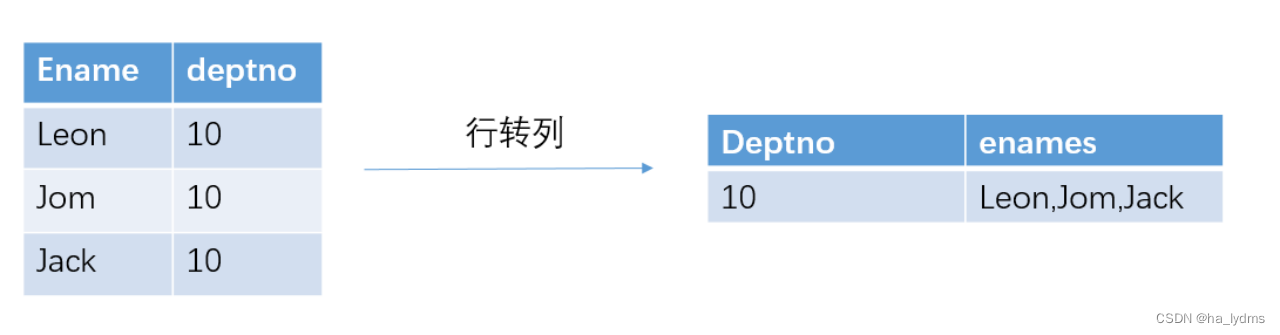
- 4、行转列
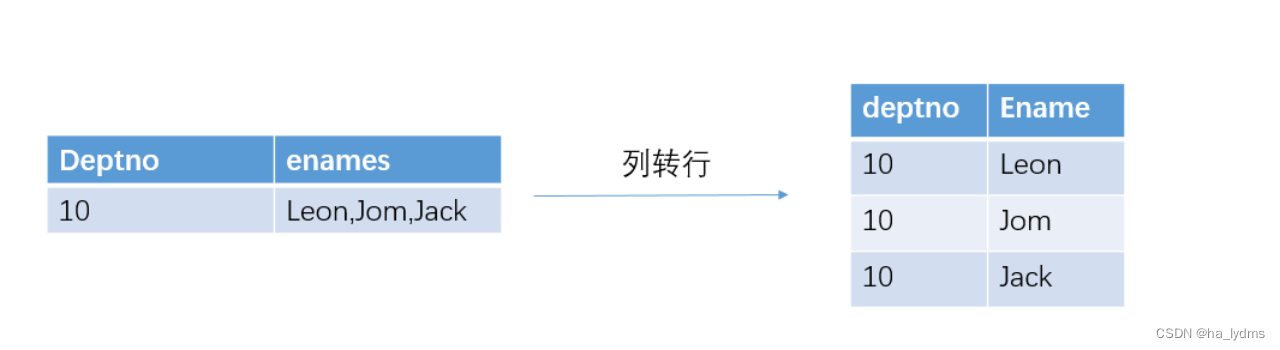
- 5、列转行
- 6、开窗函数
- 6.1 简介
- 6.2 语法
- 6.3 案例
- 6.4 LAG函数
- 6.5 Ntile函数
- 6.6 Rank
- 7、自定义函数
- 四、压缩和存储
- 1、简介
- 2、压缩简介
- 3、Map输出阶段压缩
- 4、开启Reduce输出阶段压缩
- 5、文件存储格式
- 5.1 列式存储和行式存储
- 5.2 TextFile_行存储
- 5.3 Orc_列存储
- 5.4 Parquet_列存储
- 5.5 数据存储大小对比
- 6、存储和压缩结合
- 四、企业级调优
- 1、查看执行计划
- 2、Hive建表优化
- 3、HQL语法优化
- 3.1 列裁剪和分区裁剪
- 3.2 Group By
- 3.3 CBO优化
- 4、数据倾斜
- 4.1 现象
- 4.2 单表数据倾斜优化
- 4.3 Join数据倾斜优化
- 5、Hive Job优化
一、Hive建表SQL
Hive建表SQL
二、Hive函数
Hive函数
三、函数
1、查看内置函数
查看系统自带函数
show functions;
查看自带函数用法
# 显示简单用法
desc function !=;
# 显示详细用法
desc function extended !=;
2、空字段赋值(nvl)
| NVL: | 给值为NULL的数据赋值,它的格式是NVL( value,default_value)。 |
|---|---|
| 功能: | 如果value为NULL,则NVL函数返回default_value的值,否则返回value的值如果两个参数都为NULL ,则返回NULL。 |
# 当common为空时,返回age
SELECT nvl(name,'age') FROM user;
# 当name为空时候,用full_name替代
SELECT nvl(name,full_name) FROM user;
3、CASE WHEN THEN ELSE END
根据不同数据,返回不同逻辑
SELECTCASE deptnoWHEN 1 THEN EngineeringWHEN 2 THEN FinanceELSE adminEND,CASE zoneWHEN 7 THEN AmericasELSE Asia-PacENDFROM emp_details/** 当a=b时,返回c;当a=d时,返回d;当a=e时,放回e;其他情况返回f。*/
CASE a WHEN b THEN cWHEN d THEN eELSE f
END
案例:
SELECT name,CASE sex WHEN '男' THEN 1 ELSE 0 END
FROM default.user01 uSELECT name,SUM(CASE sex WHEN '男'THEN 1 ELSE 0 END )
FROM default.user01 u
GROUP BY name ;
4、行转列
将多行数据进行汇总成1条数据、多行转为单行
CONCAT(string A/col, string B/col…):多个字段拼接CONCAT_WS(separator, str1, str2,...):多字段拼接(指定拼接符号)COLLECT_SET(col):接受分组数据,汇总为Array(去重)COLLECT_LIST(col):接受分组数据,汇总为Array(不去重)
SELECT deptno AS Deptno,CONCAT_WS(',' , COLLECT_LIST(Ename)) AS enames
FROM user
GROUP BY deptno
CONCAT
# 字符串拼接
# 返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT(string A/col, string B/col…):
案例:
SELECT CONCAT(name,age) FROM default.user01 u ;
# 结果:
悟空12
大海14
**CONCAT_WS(separator, str1, str2,...):**多字符串拼接
-
它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。
-
分隔符可以是与剩余参数一样的字符串。
-
如果分隔符是 NULL,返回值也将为 NULL。
-
这个函数会跳过分隔符参数后的任何 NULL 和空字符串。
-
分隔符将被加到被连接的字符串之间;
-
注意:
CONCAT_WS must be "string or array<string>
# `separator`:连接符
# `str1`:参数1
# `str2`:参数2
# :字符串拼接(CONCAT_WS('+','a','b')=>a+b)
CONCAT_WS(separator, str1, str2,...)
案例:
SELECT concat_ws('.', 'www', 'facebook', 'com') FROM default.user01;
www.facebook.comSELECT concat_ws('.', 'www', array('facebook', 'com')) FROM default.user01;
www.facebook.com
www.facebook.com
COLLECT_SET(col)
- 函数只接受基本数据类型
- 它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
- 去重
# 将分组后数据汇总为Array
collect_list(name)
案例:
# ["宋宋","凤姐","婷婷"]
select collect_set(name)from default.user01 group by age;
# 宋宋+凤姐+婷婷
select concat_ws('+',collect_set(name))from default.user01 group by age;
COLLECT_LIST(col):
- 不去重
- 函数指接收基本数据类型
- 它的主要作用是将某字段的值进行不去重汇总,产生array类型字段。
# 将分组后数据汇总为Array
collect_list(name)
案例
# ["宋宋","宋宋","凤姐","婷婷"]
select collect_list(name)from default.user01 group by age;
# 宋宋+宋宋+凤姐+婷婷
select concat_ws('+',collect_list(name))from default.user01 group by age;
5、列转行
EXPLODE(col):将hive表的一列中复杂的array或者map结构拆分成多行。SPLIT(string str, string regex): 按照regex字符串分割str,会返回分割后的字符串数组。LATERAL VIEW:侧视图LATERAL VIEW udtf(expression) tableAlias AS columnAlias- 用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。lateral view首先为原始表的每行调用UDTF,UDTF会报一行拆分成一行或者多行,lateral view再把结果组合,产生一个支持别名表的虚拟表。
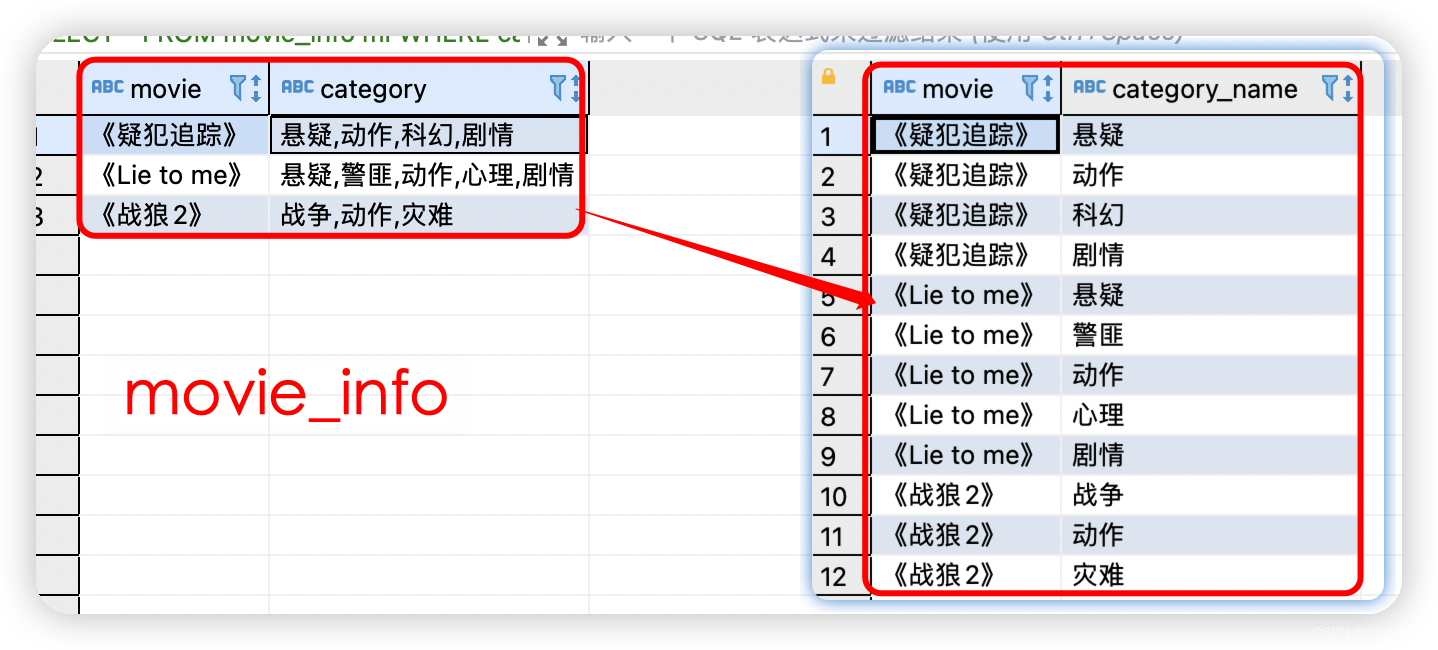
SELECT split(category,",") FROM movie_info ;

SELECT explode(split(category,",")) FROM movie_info mi;
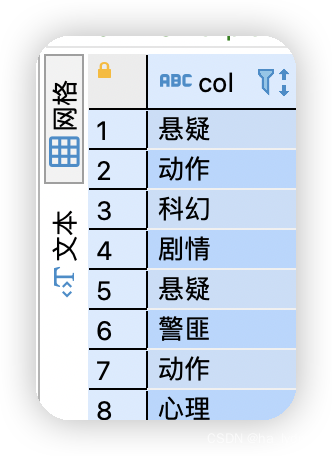
split:将category列中数据,拆分为多条,以Array类型。explode:将单列中Array存储的转为多行数据。lateral VIEW:将Array中数据整合为可被查询的列。
SELECT movie,category_name FROM movie_info
lateral VIEW
explode(split(category,",")) movie_info_tmp AS category_name ;
6、开窗函数
6.1 简介
- 窗口函数不同于我们熟悉的常规函数及聚合函数,它输入多行数据(一个窗口),为每行数据进行一次计算,返回一个值。
- 灵活运用窗口函数可以解决很多复杂的问题,如去重、排名、同比及和环比、连续登录等。
6.2 语法
语法:
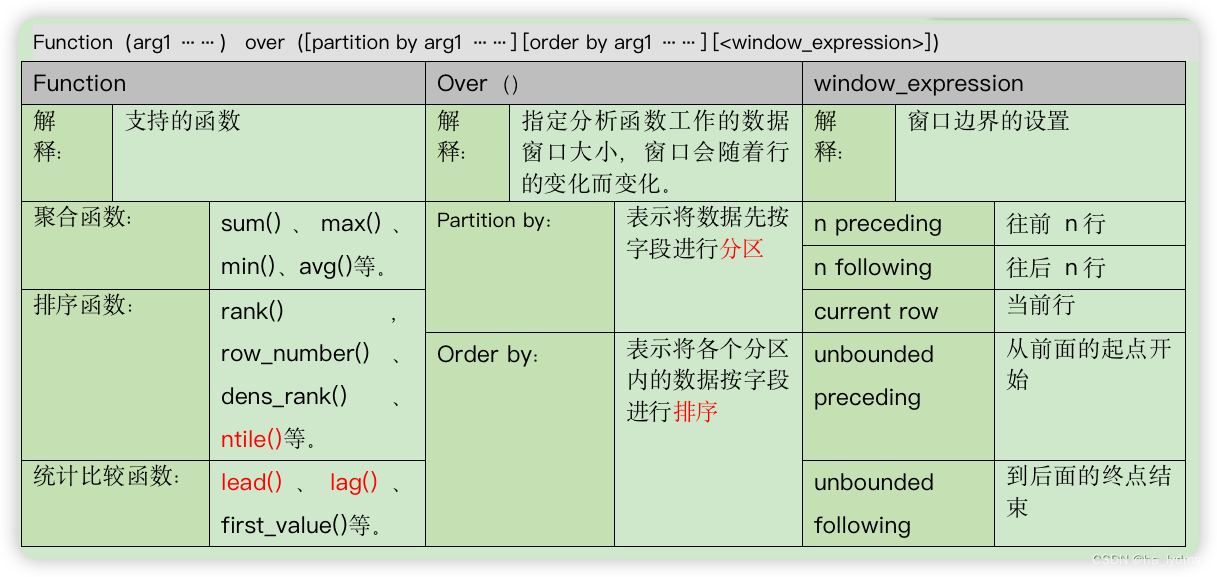
Function(arg1 ……) over([partition by arg1 ……] [order by arg1 ……] [<window_expression>])
-
rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量
-
如果不指定partition by,则不对数据进行分区,换句话说,所有数据看作同一个分区。
-
如果不指定order by, 则不对各分区进行排序,通常用于那些顺序无关的窗口函数,如sum()。
-
如果不指定窗口子句:
- 不指定order by,默认使用分区内所有行,等同于
Function() over(rows between unbounded precedeing and unbounded following)- 如果指定order by,默认使用分区内第起点到当前行,等同于
Function() over(rows between unbounded preceding and current row) -
Over()语法
| 语法 | 解释(添加) | 解释(不添加) |
|---|---|---|
| Partition by: | 表示将数据先按字段进行分区 | 不对数据进行分区,换句话说,所有数据看作同一个分区 |
| Order by: | 表示将各个分区内的数据按字段进行排序。 不指定默认所有行。 | 则不对各分区进行排序,通常用于那些顺序无关的窗口函数。 指定后:从开头行至当前行。 |
partition by:
不指定:则不对数据进行分区,换句话说,所有数据看作同一个分区。order by:
不指定order by:默认使用分区内所有行,等同于
指定order by: 默认使用分区内第起点到当前行,等同于
window_expression语法
| 语法 | 解释 |
|---|---|
| n preceding | 往前n行 |
| n following | 往后n行 |
| current row | 当前行 |
| unbounded preceding | 从前面的起点开始 |
| unbounded following | 到后面的终点结束 |
# 从开头到当前行
ROWS BETWEEN unbounded preceding AND current row# 昨天至今天
rows between 1 preceding and current row# 当天到最后一天
rows between current row and unbounded following
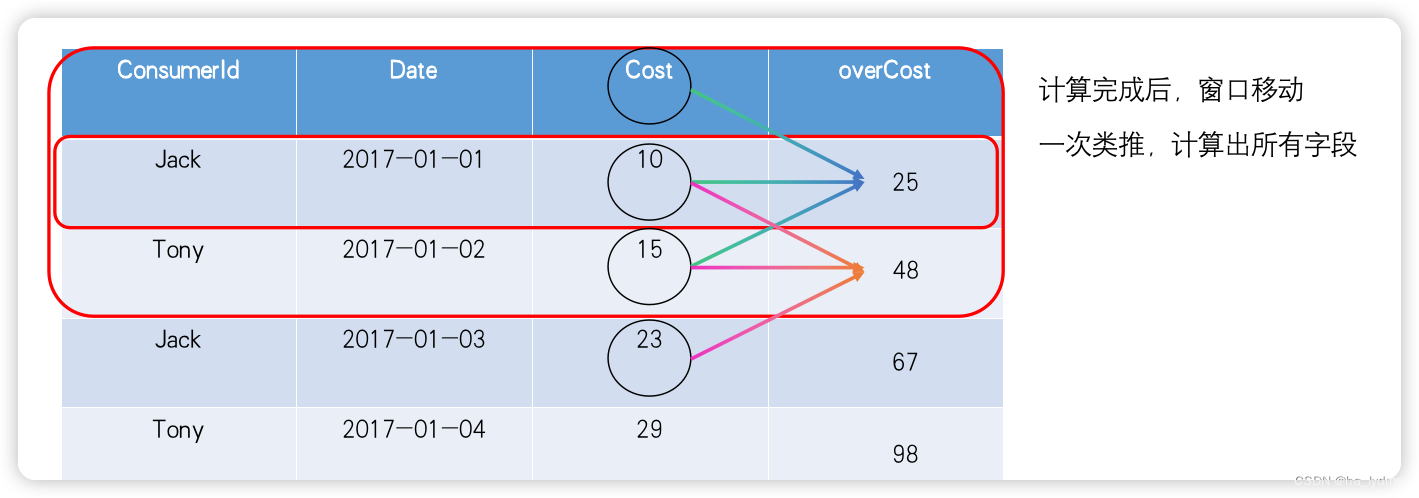
6.3 案例
数据表
- 查询在2017年4月份,到店购买的人,及到店次数
selectname ,count(name) over()
frombusiness
wheresubstring(orderdate, 1, 7)= '2017-04'
group by name;
- 查询顾客的购买明细,及到当前日期为止的购买总金额
selectname,orderdate,cost,sum(cost)over(partition by name
order byorderdate)
from business;
执行结果
jack 2017-01-01 10 10
jack 2017-01-05 46 56
jack 2017-01-08 55 111
jack 2017-02-03 23 134
jack 2017-04-06 42 176
mart 2017-04-08 62 62
- 每一行数据都新增一列,即消费总额
selectname,orderdate,cost,sum(cost) over() sample1
from business;
执行结果:
mart 2017-04-13 94 661
neil 2017-06-12 80 661
mart 2017-04-11 75 661
neil 2017-05-10 12 661
mart 2017-04-09 68 661
mart 2017-04-08 62 661
jack 2017-01-08 55 661
- 计算每个人的销售总额
- 以name分区计算,每行数据新增一列,即每人消费总额
selectname,orderdate,cost ,sum(cost)over(partition by name)
from business;
执行结果:
jack 2017-01-05 46 176
jack 2017-01-08 55 176
jack 2017-01-01 10 176
jack 2017-04-06 42 176
jack 2017-02-03 23 176
mart 2017-04-13 94 299
mart 2017-04-11 75 299
mart 2017-04-09 68 299
- 计算每个人截止到当天的销售总额
- 以name分区、日期排序计算,每行数据增一列,即截止到当前的消费总额,也就是从起点到当前行做聚合。
- 如果指定order by,默认使用分区内第起点到当前行。
selectname,orderdate,cost,sum(cost)over(partition by name order by orderdate)as sum_now
frombusiness;
selectname,orderdate,cost,sum(cost)over(partition by name order by orderdate
# 固定写法,表明从开头到当前行rows between unbounded preceding and current row )as sum_now
frombusiness;
执行结果:
jack 2017-01-01 10 10
jack 2017-01-05 46 56
jack 2017-01-08 55 111
jack 2017-02-03 23 134
jack 2017-04-06 42 176
mart 2017-04-08 62 62
mart 2017-04-09 68 130
- 每个人连续两天的消费总额
- 以name分区、日期排序计算,每行数据增一列,即连续两天的消费总额也就是前一行和当前行聚合。
- 当天的值,为当天值与昨天值相加。
select name,orderdate,cost, sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row ) as sample5
from business;
执行结果
jack 2017-01-01 10 10
jack 2017-01-05 46 56 (10+46=56)
jack 2017-01-08 55 101 (46+55=101)
jack 2017-02-03 23 78 (55+23=78)
jack 2017-04-06 42 65
mart 2017-04-08 62 62
mart 2017-04-09 68 130
- 每个人从当天到最后一天的消费总额
- 以name分区、日期排序计算,每行数据增一列,即当前天到最后一天的消费总额,也就是当前行聚合最后一行。
- 行,从当前行至最后一行总和。
select name,orderdate,cost,sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING )
from business;
计算结果:
jack 2017-01-01 10 176
jack 2017-01-05 46 166
jack 2017-01-08 55 120 (120=42+23+55)
jack 2017-02-03 23 65 (65=42+23)
jack 2017-04-06 42 42 (42=42)
mart 2017-04-08 62 299
mart 2017-04-09 68 237
6.4 LAG函数
- Lag函数用于统计窗口内往上第n行值。
scalar_pexpression:列名。offset:为往上几行。default:是设置的默认值(当往上第n行为NULL时,取默认值,否则就为NULL)
LAG (scalar_expression [,offset] [,default]) OVER ([query_partition_clause] order_by_clause);
- 查看顾客上次的购买时间
selectname,orderdate,cost,lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as last_time
from business ;
执行结果:
jack 2017-01-01 10 1900-01-01
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 1900-01-01
mart 2017-04-09 68 2017-04-08
mart 2017-04-11 75 2017-04-09
6.5 Ntile函数
- 为已排序的行,均分为指定数量的组,组号按顺序排列,返回组号,不支持
rows between
selectname,orderdate,cost,ntile(5) over( order by orderdate) sorted
from business;
执行结果:(分为了5组,下面取第1组数据即可)
jack 2017-01-01 10 1
tony 2017-01-02 15 1
tony 2017-01-04 29 1
jack 2017-01-05 46 2
tony 2017-01-07 50 2
jack 2017-01-08 55 2
jack 2017-02-03 23 3
jack 2017-04-06 42 3
mart 2017-04-08 62 3
mart 2017-04-09 68 4
mart 2017-04-11 75 4
mart 2017-04-13 94 4
neil 2017-05-10 12 5
neil 2017-06-12 80 5
取第一组数据
selectt1.name,t1.orderdate,t1.cost
from(selectname,orderdate,cost,ntile(5) over( order by orderdate) sortedfrom business ) t1
wheret1.sorted = 1;
执行结果:
OK
jack 2017-01-01 10
tony 2017-01-02 15
tony 2017-01-04 29
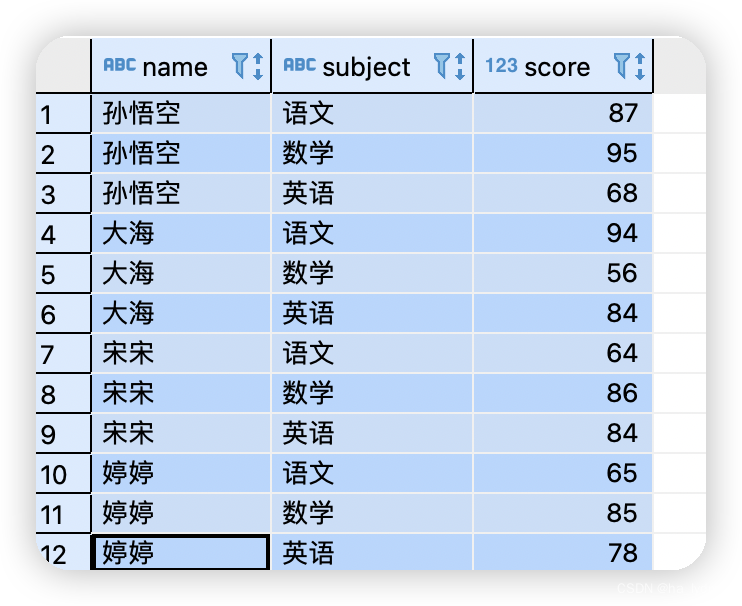
6.6 Rank
Rank():排序,值相同时会重复,总数不会变(1、1、3、4)。DENSE_RANK():排序,值相同时会重复,总数会较少(1、1、2、3)。ROW_NUMBER():根据顺序计算。字段相同就按排头字段继续排(1、2、3、4)。
源数据:

7、自定义函数
-
**内置函数:**Hive自带的函数。
-
**自定义函数:**当Hive提供的内置函数无法满足你的业务处理需要时。可以自己定义一些函数。
-
UDF(User-Defined-Function): 一进一出。 -
UDAF(User-Defined Aggregation Function):聚合函数,多进一出,类似:count/max/min -
UDTF(User-Defined Table-Generating Functions):炸裂函数,一进多出,如:explode()
-
四、压缩和存储
1、简介
- Hive不会强制要求将数据转换成特定的格式才能使用。利用Hadoop的InputFormat API可以从不同数据源读取数据,使用OutputFormat API可以将数据写成不同的格式输出。
- 对数据进行压缩虽然会增加额外的CPU开销,但是会节约客观的磁盘空间,并且通过减少载入内存的数据量而提高I/O吞吐量会更加提高网络传输性能。
- 原则上Hadoop的job时I/O密集型的话就可以采用压缩可以提高性能,如果job是CPU密集型的话,那么使用压缩可能会降低执行性能。
2、压缩简介
常用压缩算法
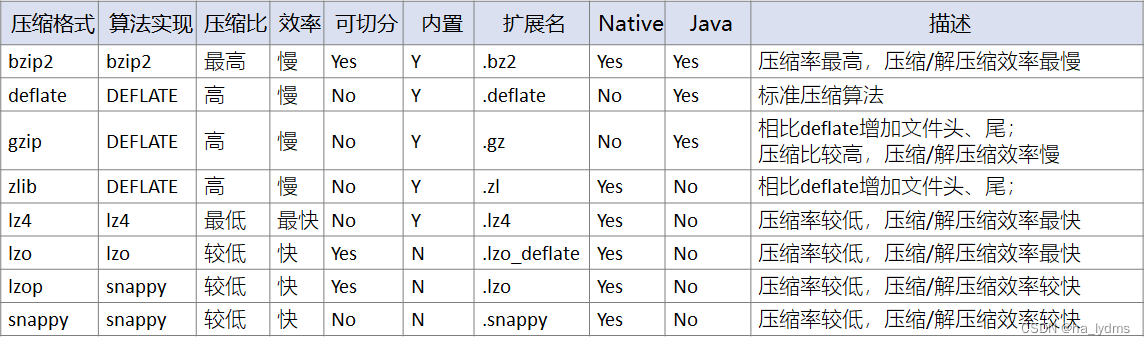
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码/解码器 |
|---|---|---|---|---|
| Deflate | Deflate | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | Deflate | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | Bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| Lzo | Lzo | .lzo | 是 | com.hadoop.compression.lzo.LzopCodec |
| Snappy | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
压缩效率对比
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
要在Hadoop中启用压缩,可以配置如下参数(mapred-site.xml文件中):
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO、LZ4或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
3、Map输出阶段压缩
开启map输出阶段压缩可以减少job中map和Reduce task间数据传输量。
(1)开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate =true;
(2)开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
(3)设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
(4)执行查询语句
select count(ename) name from emp;
查看历史日志中,有压缩方式.snappy
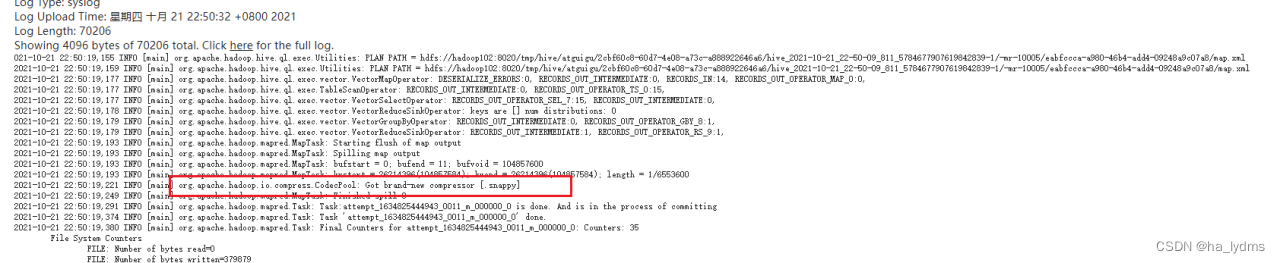
4、开启Reduce输出阶段压缩
当Hive将输出写入到表中时可以通过属性hive.exec.compress.output,对输出内容进行压缩。
将hive.exec.compress.output = false,这样输出就是非压缩的纯文本文件了。
将hive.exec.compress.output = true,来开启输出结果压缩功能。
(1)开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
(2)开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
(3)设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
(4)设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
(5)测试一下输出结果是否是压缩文件
insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from score distribute by name sort by score desc;

5、文件存储格式
5.1 列式存储和行式存储
Hive支持的存储数据的格式主要有:
- TEXTFILE:行存储
- SEQUENCEFILE:行存储
- ORC:列存储
- PARQUET:列存储
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
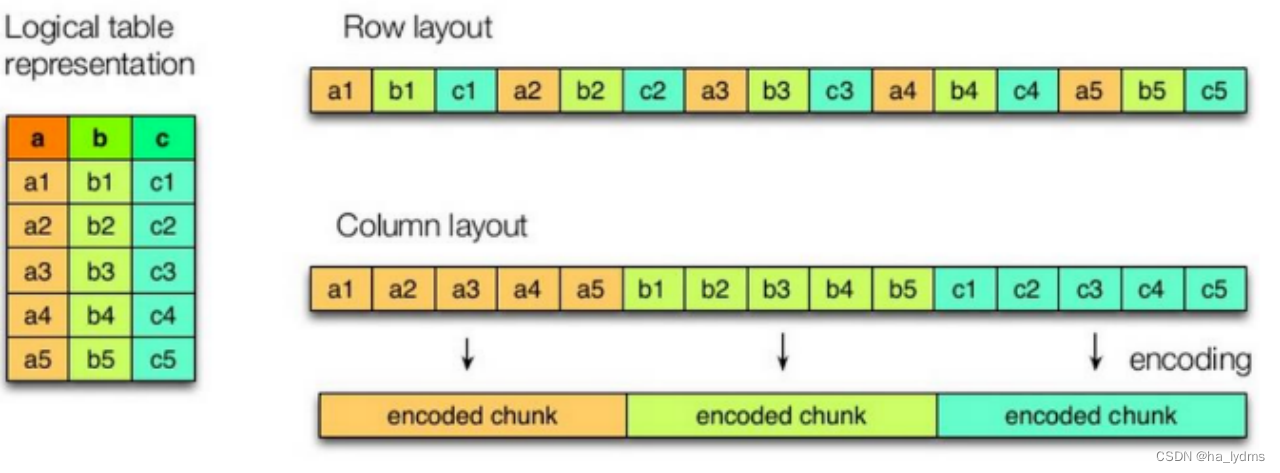
- 行存储的特点
查询满足条件的一整行数据的时候
列存储则需要去每个聚集的字段找到对应的每个列的值
行存储只需要找到其中一个值,其余的值都在相邻地方
所以此时行存储查询的速度更快。
- 列存储的特点
每个字段的数据聚集存储,查询只需要少数几个字段的时候,能大大减少读取的数据量;
每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
5.2 TextFile_行存储
- 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
- 可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
5.3 Orc_列存储
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
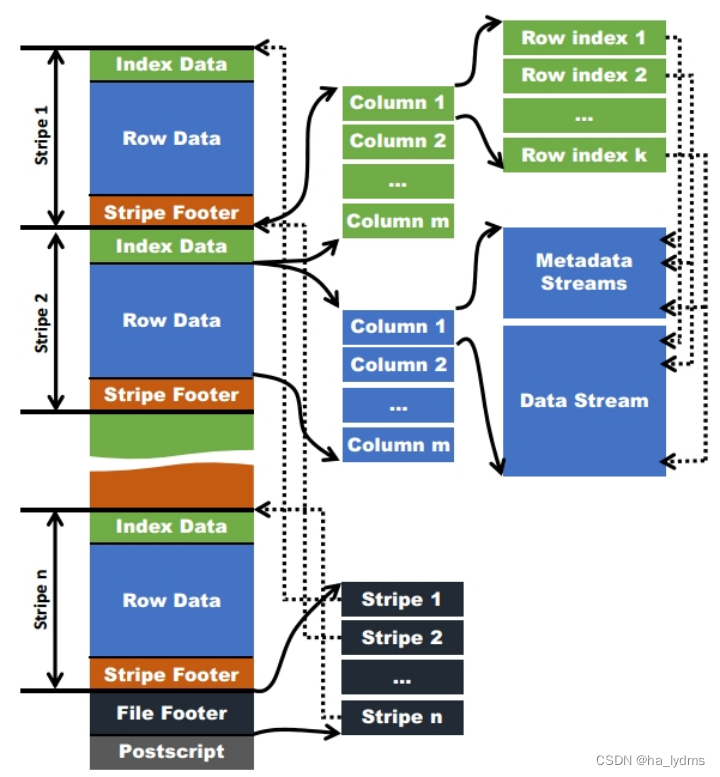
如下图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
-
每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
-
Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。 -
Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。 -
Stripe Footer:存的是各个Stream的类型,长度等信息。每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
-
ORC中压缩:
Zlib:压缩比高,效率低。压缩ORC的默认压缩格式。Snappy:压缩比低,效率高。
5.4 Parquet_列存储
Parquet文件是以二进制方式存储的,所以是不可以直接读取的文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
- (1)行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
- (2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
- (3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
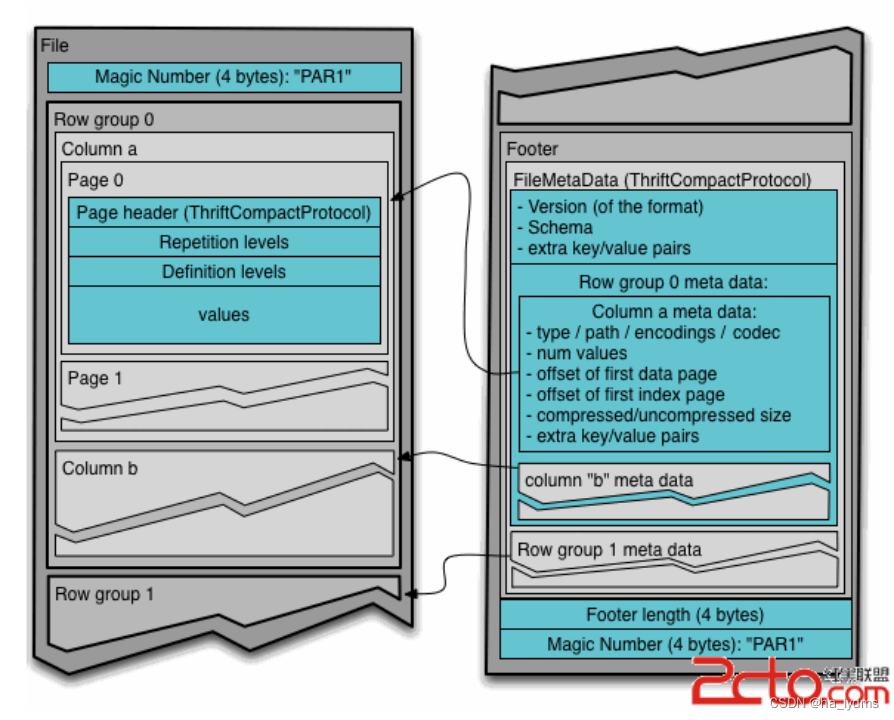
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。
除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
5.5 数据存储大小对比
- TextFile
create table log_text (track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
row format delimited fields terminated by '\t'
stored as textfile;
- ORC
create table log_orc(track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="NONE"); // 由于ORC格式时自带压缩的,这设置orc存储不使用压缩
- Parquet
create table log_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet ;
同样数据文件存储后大小:
- TextFile:18.1M
- ORC:7.7 M
- Parquet:13.1M
存储的大小对比:ORC > Parquet > textFile
查询速度:速度接近
6、存储和压缩结合
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268,435,456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
| orc.bloom.filter.columns | “” | comma separated list of column names for which bloom filter should be created |
| orc.bloom.filter.fpp | 0.05 | false positive probability for bloom filter (must >0.0 and <1.0) |
注意:所有关于ORCFile的参数都是在HQL语句的TBLPROPERTIES字段里面出现。
- ZLIB压缩的ORC存储方式(2.8 M)
create table log_orc_zlib(track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
- SNAPPY压缩的ORC存储方式(3.7 M)
create table log_orc_snappy(track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
- SNAPPY压缩的parquet存储方式(6.4 MB)
create table log_parquet_snappy(track_time string,url string,session_id string,referer string,ip string,end_user_id string,city_id string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
- hive表的数据存储格式一般选择:orc或parquet。
- 压缩方式一般选择snappy,lzo。
- ORC默认压缩:
Zlib。
四、企业级调优
1、查看执行计划
EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query
- 没有生成MR任务的
explain select * from emp;
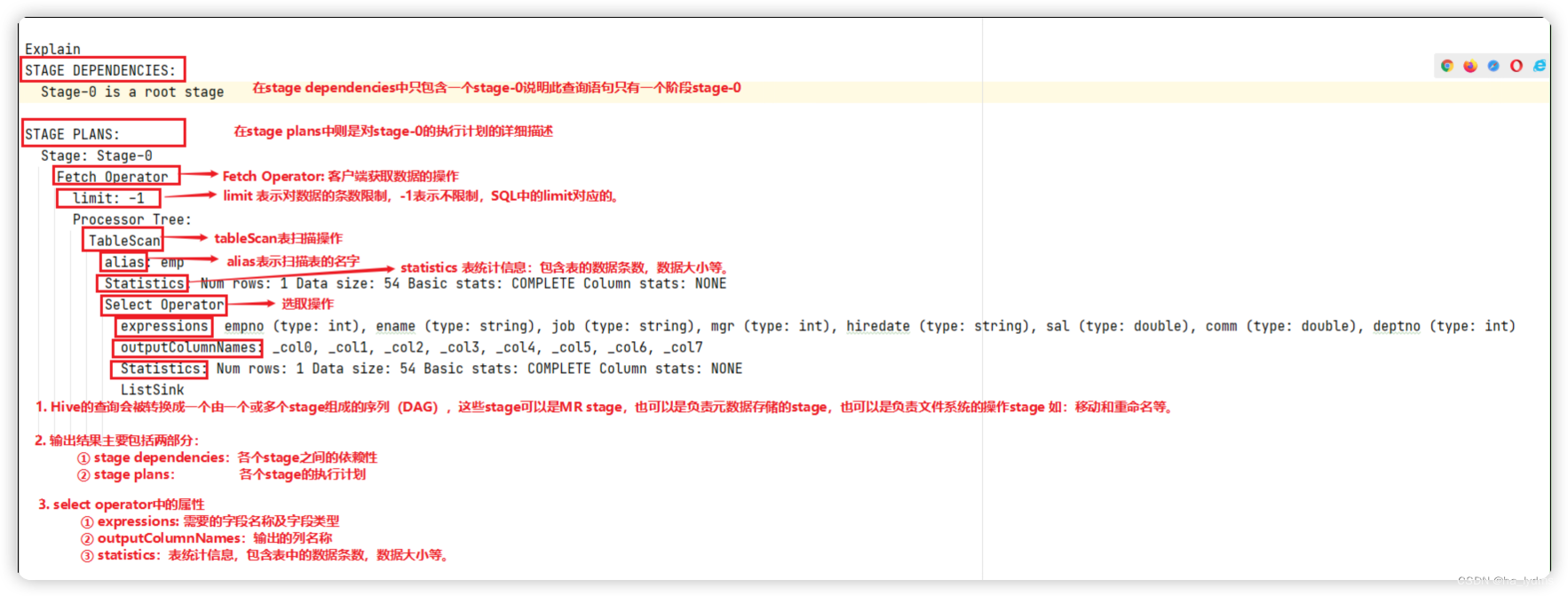
- 生成MR任务的
explain select deptno, avg(sal) avg_sal from emp group by deptno;
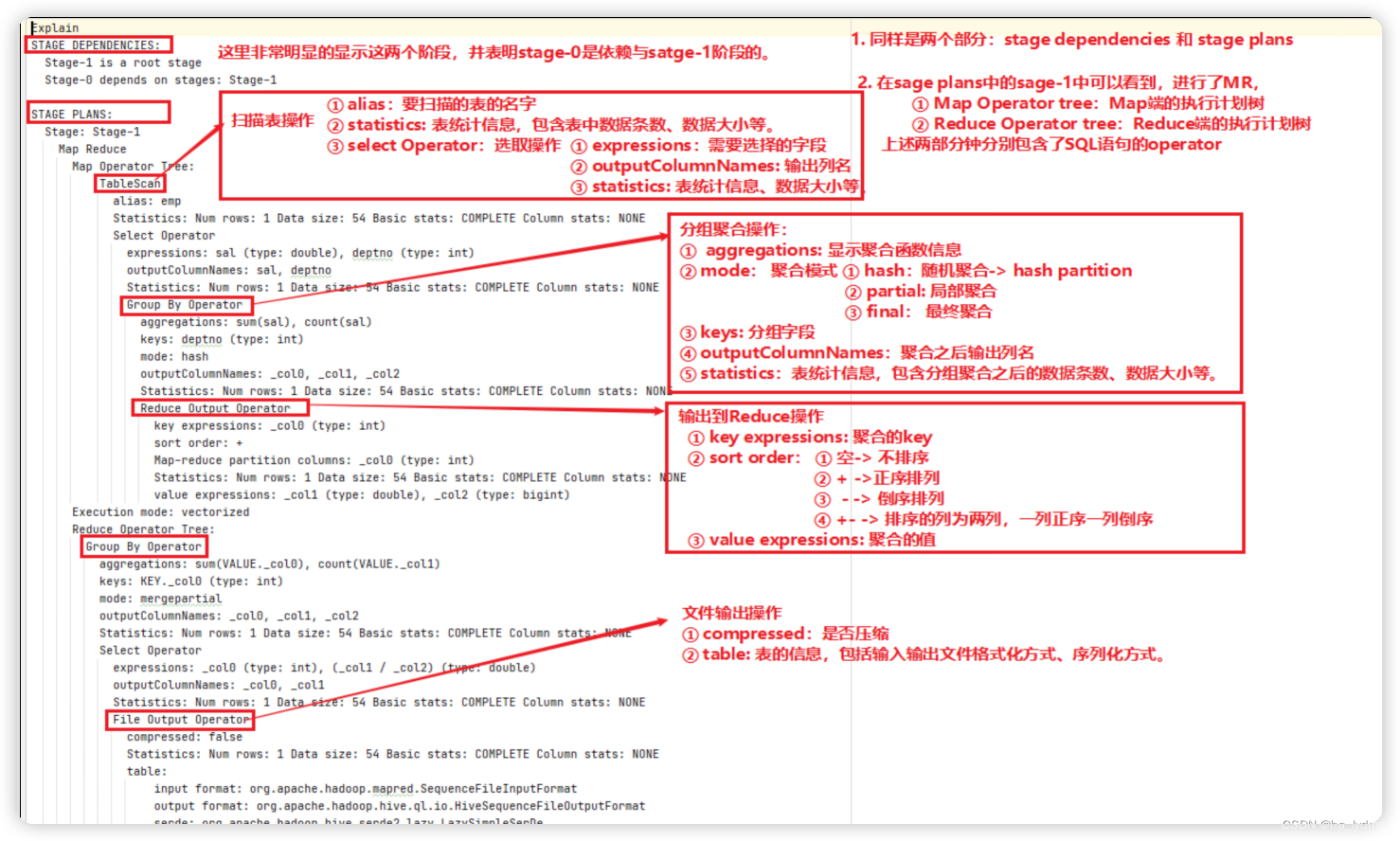
查看详细执行计划
explain extended select * from emp;
2、Hive建表优化
- 分区表
- 分桶表
- 合适的文件格式
3、HQL语法优化
3.1 列裁剪和分区裁剪
在生产环境中,会面临列很多或者数据量很大时,如果使用select * 或者不指定分区进行全列或者全表扫描时效率很低。Hive在读取数据时,可以只读取查询中所需要的列,忽视其他的列,这样做可以节省读取开销(中间表存储开销和数据整合开销)
- 列裁剪:在查询时只读取需要的列。
- 分区裁剪:在查询中只读取需要的分区。
3.2 Group By
- 默认情况下,Map阶段同一Key数据分给一个Reduce,当一个Key数据过大时就倾斜了。
- 并不是所有的聚合操作都需要再Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。

参数配置
- 开启Map端聚合设置
# 开启在Map端聚合
set hive.map.aggr = true
# Map端聚合条目数目
set hive.groupby.mapaggr.checkinterval = 100000
# 开启数据倾斜时,进行负载均衡
set hive.groupby.skewindata = true
-
当开启数据负载均衡时,生成的查询计划会有2个MRJob。
第一个MRJob中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
第二个MRJob再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
3.3 CBO优化
4、数据倾斜
4.1 现象
数据倾斜:绝大多数任务很快完成,只有1个或者几个任务执行的很忙甚至最终执行失败。
数据过量:所有的任务执行都很慢。这时候只有提高执行资源才能优化HQL的执行效率。
原因:
按照Key分组后,少量的任务负载着绝大部分的数据的计算,也就是说。产生数据倾斜的HQL中一定存在着分组的操作,所以从HQL的角度,我们可以将数据倾斜分为单表携带了Group By字段的查询和2表(多表)Join的查询。
4.2 单表数据倾斜优化
1)使用参数优化
当任务中存在Group By操作同时聚合函数为count或者sum。可以设置参数来处理数据倾斜的问题。
# 是否在Map端进行聚合,默认为True
set hive.map.aggr = true
# 在Map端进行聚合操作的条目数目
set hive.groupby.mapaggr.checkinterval = 100000
# 有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
2)增加Reduce数量
当数据中多个key同时导致数据倾斜,可以通过增加Reduce的数量解决数据倾斜问题。
- 方式一(动态调整):
# 每个Reduce处理的数据量默认为 256M(参数1)
set hive.exec.reducers.bytes.per.reducer=256000000
# 每个任务最大的Reduce数,默认为1009(参数2)
set hive.exec.reducers.max=1009
# 计算Reducer数的公式
N = min(参数2 ,总数入数据量/参数1)
- 方式二(直接指定):
# 直接指定Reduce个数
set mapreduce.job.reduces = 15;
4.3 Join数据倾斜优化
1)使用参数
在编写Join查询语句时,如果确定是由于join出现的数据倾斜:
# join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
# 如果是join过程出现倾斜应该设置为true
set hive.optimize.skewjoin=false;
如果开启了,在Join过程中Hive会将计数超过阈值hive.skewjoin.key(默认100000)的倾斜key对应的行临时写进文件中,然后再启动另一个job做map join生成结果。通过 hive.skewjoin.mapjoin.map.tasks参数还可以控制第二个job的mapper数量,默认10000。
set hive.skewjoin.mapjoin.map.tasks=10000;
2)大小表join
可以使用MapJoin,没有Reduce阶段就不会出现数据倾斜。
3)大表大表Join
使用打散加扩容的方式解决数据倾斜问题,选择其中较大的表做打算操作
SELECT * ,concat(id,'_' , '0 or 1 or 2')FROM A; t1
选择其中较小的表做扩容处理
SELECT *,concat(id,'-','0') from B
UNION ALL
SELECT *,concat(id,'-','1') from B
UNION ALL
SELECT *,concat(id,'-','2') from B;t2
5、Hive Job优化
1
1
1
1
1
1
1
1











的生产者与消费者使用案例)

)





