1. CMD命令
1.1 数据库启动与停止
(1) 启动数据库:net start mysql80
(2) 停止数据库:net stop mysql80
1.2 数据库连接与退出
(1) 连接数据库:mysql [-hlocalhost -P3306] -uroot -p[123456] // 本地数据库可省略-h -P
(2) 退出数据库:exit | quit
1.3 数据库备份与还原
(1) 全数据库备份:mysqldump -uroot -p[123456] -A > D:\\备份文件名.sql
(2) 多数据库备份:mysqldump -uroot -p[123456] --databases db1 db2 > D:\\备份文件名.sql
(3) 单数据库备份:mysqldump -uroot -p[123456] 数据库名 > D:\\备份文件名.sql
(4) 数据库还原:mysql -uroot -p[123456] < D:\\备份文件名.sql
(5) 表备份:mysqldump [-d] -uroot -p[123456] 数据库名 表名 [表名...] > 备份文件名.sql
(6) 表还原:mysql -uroot -p[123456] 数据库名 < D:\\备份文件名.sql
注释:-d只备份表结构,不备份数据。mysqlpump同dump一样,pump更快更可靠。mysql --help查看指令

2. SQL语言
2.1 DCL-用户权限
查询用户:select * from user;
创建用户:create user 用户名@主机名 identified by 密码
修改密码:alter user 用户名@主机名 identified with mysql_native_password by 密码
删除用户:drop user 用户名@主机名
用户权限:all,select,insert,update,delete,create,alter,drop
查询权限:show grants for 用户名@主机名
授予权限:grant 权限 [, 权限...] on 数据库名.表名 to 用户名@主机名; // 数据库.*,*.*
撤销权限:revoke 权限 [, 权限...] on 数据库名.表名 from 用户名@主机名;
2.2 DDL-数据库与表
2.2.1 数据库操作
显示数据库:show databases;
当前数据库:select database();
切换数据库:use 数据库名;
创建数据库:create database [if not exists] 数据库名 [default charset 字符集];
删除数据库:drop database 数据库名;
注释:UTF-8编码格式,对应的是mysql数据库的utf8md4(4字节),而不是utf8(3字节)
2.2.2 表操作
显示所有表:show tables;
查建表语句:show create table 表名;
显示表结构:desc 表名; // describe 表名
创建表:create table 表名(字段名 类型 [comment 注释 约束], ...) [comment = 表注释]
快速创建:create table 表名 [as] select * from 表; // 结构数据一致,※
快速创建:create table 表名 [as] select * from 表 where 1=2; // 结构一致,无数据,※
快速创建:create table 表名 (like 表2); // 赋值表结构,无数据。可不加括号,※
重建表:truncate table 表名; // 清空数据,需要用户有删除表建表权限
删除表:drop table [if exists] 表名;
修改表名:alter table 表名 rename to 新表名;
添加字段:alter table 表名 add [column] 字段名 类型 [comment 注释 约束];
删除字段:alter table 表名 drop [column] 字段名;
改字段名:alter table 表名 change 字段名 新字段名 类型 [comment 注释 约束];
改字段属性约束:alter table 表名 modify 字段名 类型 [comment 注释 约束];
修改字段顺序:alter table 表名 modify 字段 类型 [first | after 字段名]; // 将指定字段放在表中第一位或某个字段后。
注释:列注释和约束不分先后顺序
2.3 DML-数据增删改
插入数据:insert into 表名 [(字段1, 字段2, ...)] values (值1, 值2, ...) [,(值1, 值2...)];
修改数据:update 表名 set 字段1=值1 [, 字段2=值2, ...] [where 条件];
删除数据:delete from 表名 [where 条件];
注释:insert into 表1 select * from 表2; // 将表2查出数据复制到表1,不可加 as,※
插入项目可填写null或default
2.4 DQL-数据查询
2.4.1 查询(select)
全部查询:select * from 表名 [where 条件];
字段查询:select 字段1 [, 字段2...] from 表名 [where 条件];
去重查询:select distinct 字段1 [, 字段2...] from 表名 [where 条件];
注释:去重查询,去除全部字段都相同的数据
2.4.2 查询条件(where)
逻辑运算符:not > and > or
等于(=)(<=>),不等于(!=)(<>), // <=> 可以取到null数据,null<=>null返回true
大于(>),大于等于(>=)
小于(<),小于等于(<=)
范围:between 最小值(包含) and 最大值(包含)
包含(in),不包含(not in)
相似(like),不相似(not like)
为空(is null),不为空(is not null)
存在(exists),不存在(not exists)
注释:不等取不到null值
2.4.3 分组(group by)
分组查询:select 字段... from 表 where 条件 group by 分组字段 having 分组后条件;
根据查询字段分组:select 字段1, 字段2 from 表 group by 1,2;// 根据查询的第一第二个字段分组
注释:查询的字段必须在groupby或having中,having可指定groupby以外字段(分组后保留的默认值)存在数据不确定性,顺序值先where过滤然后groupby分组然后having过滤,然后查询。一般条件放到where中避免无用数据进行分组,having中一般放集合函数的条件。
2.4.4 排序(order by)
select * from 表名 where 条件 order by 排序字段 [asc]; // 升序
select * from 表名 where 条件 order by 排序字段 desc; // 降序
select * from 表名 where 条件 order by 字段1 desc, 字段2 asc;
根据查询字段排序:select 字段1, 字段2 from 表 order by 1,2;// 根据查询的第一第二个字段排序
注释:每个项目都需指定升序或降序,未指明的项目默认都是ASC。
指定Null字段在前或在后 if(isnull(字段), 1, 0) desc
2.4.5 分页(limit)
select * from 表名 where 条件 limit [起始索引, ] 查询记录数; // 起始索引默认0
select * from 表名 where 条件 limit 查询件数 offset 开始位置; // 开始位置默认0
注释: 查询SQL执行顺序,from 决定表, where 决定条件,group by 分组 having 过滤分组后的数据,select决定项目, order by排序(排序可以指定查询项目外的字段),limit 分页。
2.4.6 表关联(join)
隐式内联:select * from 表1, 表2 where 条件; // 内连接
显示内联on:select * from 表1 [inner|full] join 表2 on 关联条件 where 条件; // full 的on无法使用表名.字段 , 表别名.字段
显示内联using:select * from 表1 [inner|full] join 表2 using(同名字段) where 条件;//同名字段合并结果为1列
显示内联natural:select * from 表1 natural join 表2; //不可写on条件,同名字段合并1个结果
交叉连接:select * from 表1 cross join 表2; // 笛卡尔积,可写on或using链接条件,可用where
左外联结:select * from 表1 left [outer] join 表2 on 关联条件 where 条件;
右外联结:select * from 表1 right [outer] join 表2 on 关联条件 where 条件;
全外联结:mysql没有全外,可以用左联union右联实现。
注释:左联,右联必须指定on条件。
2.4.7 联合查询(合并查询)
(1) 并集
select * from 表1 union select * from 表2; // 合并后去重排序
select * from 表1 union all select * from 表2;
(2) 交集
intersect 不支持
(3) 差集
except 不支持
2.4.8 嵌套子查询
标量子查询:select * from 表1 where 字段 = (select 字段 from 表2); // 单条
行子查询:select * from 表1 where (字段, 字段) = (select 字段, 字段 from 表2);// 单条
列子查询:select * from 表1 where 字段 [in|>=<any|><all] (select 字段 from 表2); // 集合
表子查询:select * from 表1 where (字段, 字段) [in|=any] (select 字段, 字段 from 表2); // 集合
注释:子查询位置可写在 where from select后。in与=any相同。>any(大于任意), <any(小于任意)>=all(大等所有)<all(小于所有)。子查询,单条用=多条用in,any,all。
2.4.9 临时表(WITH)mysql8.0新增
with 临时表1(字段别名,...) as ( select * from 表 where 条件), 临时表名2 as (...from 表 | 临时表);
3. 约束
3.1 主键约束(primary key)
列约束:字段 类型 PRIMARY KEY; // 字段无引号
表约束:[constraint] [约束名] primary key(字段 [, 字段...])); //约束名指定也是空值
追加约束:alter table 表名 add primary key(字段 [, 字段...]); // 只能没有主键时追加
删除约束:alter table 表名 drop primary key; // 只能全部主键删除
3.2 外键约束(foreign key)
列约束:无
表约束:[constraint] [约束名] foreign key(字段) references 主表(主字段)
追加约束:alter table 表名 add [constraint] [约束名] foreign key(字段) references 主表(主字段)
删除约束:alter table 表名 drop foreign key 约束名; // 约束名无引号
更新删除行为:
no action 不可删除更新,
restrict 不可删除更新(更新删除,默认)
cascade 同时删除更新子表,
set null 子表更新成null
建表或追加约束语句后追加 on update cascade on delete set null; // 更新主表,同时更新子表。删除主表,子表设置为null
注释:主表字段必须是主键或索引项目,外键约束名不可重复。默认约束名 表名_ibfk_连番
3.3 唯一约束(unique)
列约束:字段 类型 UNIQUE,
表约束:[constraint] [约束名] unique(字段 [, 字段...])
追加约束:alter table 表名 add [constraint] [约束名] unique(字段 [, 字段...])
删除约束:alter table 表名 drop index 约束名; // 约束名(也是索引名)
注释:默认约束名是字段名,多列唯一默认名是第一个字段名。多个单列唯一每一列单独验证是否唯一。一个多列唯一,值合并做唯一验证(允许某一列重复)。
3.4 检查约束(check)
列约束:字段 类型 check(age >0 && age <20), // 或者 (age =18 or age=20)
表约束:[constraint] [约束名] CHECK (字段1 >= 字段2)); // 默认名 表_chk_连番
添加约束:alter table 表名 add [constraint] [约束名] check( 数值字段 > 值 | 字段 );
删除约束:alter table 表名 drop check 约束名;
注释:只能用于数值,日期类型
3.5 非空约束(not null)
列约束:字段 类型 NOT NULL,
表约束:无
修改表字段追加约束:alter table 表名 modify 字段 类型 not null;
修改表字段删除约束:alter table 表名 modify 字段 类型;
3.6 默认值(default)
列约束:字段 类型 DEFAULT 值,
表约束:无
修改默认值:alter table 表 modify [column] 字段 类型 defalut 值;
删除默认值:alter table 表 modify [column] 字段 类型 default null;
3.7 自增关键字(auto_increment)
列自增:字段 类型 约束 auto_increment, // 只能给1列定义自增,必须是主键唯一索引列
初始值:create table 表(字段 类型 auto_increment, ...) auto_increment = 5;
修改自增初始值:alter table 表 auto_increment = 10;
4. 事务与锁
原子性:事务更新删除,全变更或全不变更
一致性:事务结束,与数据保持一致
隔离性:事务处理在另一个事务之前或之后
持久性:事务完成,永久改变
4.1 事务提交方式
查询事务:select @@autocommit;
设置事务:set @@autocommit = 0;
注释:1自动提交(默认),0手动提交
4.2 开启事务
开启事务1:start transaction;
开启事务2:begin;
注释:不能用delimiter货币改结束符,否则sql没有执行,必须返回OK才是开启事务。
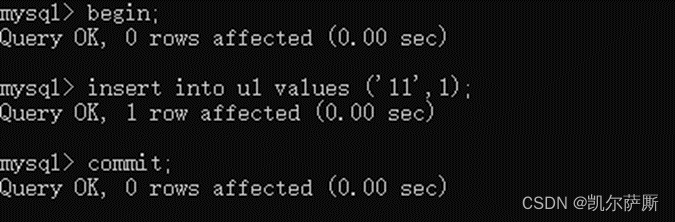
4.3 事务提交回滚
提交:commit;
回滚:rollback;
4.4 事务隔离级别
4.4.1 隔离级别分类
(1) 读未提交, read uncommitted
(2) 读已提交,read committed
(3) 可重复读,repeatable read
(4) 串行化,serializable
4.4.2 查看隔离级别
select @@transaction_isolation;
4.4.3 设置隔离级别
set [session | global] transaction isolation level 隔离级别; //不写默认session
注释:session 当前窗口生效,global 所有客户端窗口生效
4.4.4 并发问题
(1) 脏读,
(2) 不可重复读(非重复性读取),
(3) 幻读

4.5 全局锁
全局锁库:flush tables with read lock; // 全局锁,做数据备份用,只能查询数据,
释放全局锁:unlock tables;
注释:全局锁特别重,而且影响主库同步数据,innodb引擎可以在备份语句中在mysqldump后加 --single-transation用来完成不加锁的数据一致性备份。
乐观锁:使用时间戳,版本号控制,悲观锁手动控制
4.6 表级锁
4.6.1 表锁
表共享读锁(读锁):lock tables 表名 [, 表名...] read; // 任何人只能读不能写,包括自己
表独占写锁(写锁):lock tables 表名 [, 表名...] write; // 自己能读写,其他人不能读不能写
释放锁,unlock tables; // 断开客户端也会释放锁
4.6.2 元数据锁
系统自动控制的加锁解锁
事务对表有增删改,加元数据读锁,可以查看表结构,不可以更改表结构
事务对表结构有变更,加元数据写锁,不可查看不可 更改表结构
4.6.3 意向锁 (innodb新加的锁)
意向共享锁,事务有查询,加的锁,不可加表写锁,可以与表读锁兼容。
意向排他锁,事务有增删改,加的锁,与表读写锁都互斥。
作用:意向锁之间不互斥,避免加的行锁与表锁冲突,例如会话1加行锁,会话2加表锁之前要检查全表有没有行锁,影响效率。意向锁是 会话1加了行锁之后给表加意向锁,会话2加表锁前只需判断表有没有意向锁。
4.7 行级锁
4.7.1 行锁
锁定单行记录,防止其他事务更改删除数据,条件为非索引项目会锁全表。
共享锁:select ... lock in share mode [nowait | skip locked];查询手动加共享锁, for share;
注释:查询默认不加锁。nowait使加不上锁不等待直接报错。skip locked查询到行锁以外记录。
排他锁:增删改自动加排他锁。select ... for update;查询手动加排他锁
注释:共享锁之间兼容,排它锁与排它锁或共享锁都互斥。
4.7.2 临键锁
索引字段固定值:无数据,锁两个索引的期间,和一个索引。
4.7.3 间隙锁
索引字段固定值:无数据,锁两个索引的期间。不含真实数据可加多个锁。
使其他事务不能插入数据。
5. 索引
5.1 索引简介
5.1.1 索引特性
优点:无索引查询会全表扫描,提高查询,排序效率
缺点:增删改效率低
5.1.2 索引结构
(1) b+tree索引结构:innodb myisam memary都支持 b+tree,叶子节点保留所有数据。
(2) btree索引结构:中间元素向上分裂
(3) hash索引:只有memary支持,只能精确匹配,不能范围查询
5.1.3 存储引擎
索引基于存储引擎
MyISAM(mysql5.5及以前默认存储引擎)
InnoDB(mysql5.6及以后默认存储引擎)
注释:MyISAM支持表级锁,InnoDB支持外键,事务,表级锁,行级锁
5.2 索引分类
5.2.1 按字段类型分
(1) 主键索引:随表主键自动创建,默认索引
(2) 唯一索引:随唯一约束自动创建,可以有多个
(3) 常规索引:快速定位数据,可以有多个
(4) 全文索引:查找文本关键字,不是文本数据。
5.2.2 按特性分
(1) 聚集索引:索引与数据保存在一起,保存了行数据,每个表必须有且只能有一个。
注释:聚集索引选取规则,按主键选取,没有主键按第一个唯一字段,没唯一字段生成rowid作为索引。
(2) 二级索引:索引与数据分开保存,存放的是关联的主键。
注释:二级索引会调用聚集索引,进行回表查询(因为没有存储实际数据)
5.3 索引命令
查看索引:show index from 表名;
创建索引:create [ unique | fulltext ] index 索引名 on 表名(字段1 [, 字段2, ...]);
注释:可指定unique唯一或fulltext全文索引类型,不指定则为常规索引,指定一个字段为单列索引,指定多个为联合索引
删除索引:drop index 索引名 on 表名;
注释:索引命名一般以 (idx_表名_字段名) 命名
5.4 索引优化
5.4.1 索引优化原则
联合索引(一个索引对应多个字段)遵循最左前缀法则:
(1). 固定值查询:where条件由左到右必须存在,按索引字段的顺序,与where条件顺序无关。最左侧字段不在条件里则不用索引,中间字段不在条件里则不用右侧索引。
(2). 范围查询:如果出现 大于 或 小于 则索引失效,尽量使用 大于等于或小于等于作为条件
(3). 函数查询:不能在等号左侧条件的索引列上加函数或运算法则,否则索引失效。
(4). 模糊查询:值后模糊有效,值开头模糊 则索引失效
(5). 或者条件:只有OR条件两侧都有的索引才有效,任意一侧没有索引字段则索引失效
(6). 类型转换:字符串字段 值不加 单引号,则索引失效
(7). 数据分布:mysql自主判断(检索结果 会超过全表数据的 一半左右 或 一半以上)则索引失效,全表扫描。(因为判断结果是走索引还没有全表扫描快)。
注释:索引列,is null,is not null, 不会使索引失效 ※
5.4.2 索引使用提示
查询时mysql会自动分配索引(多个索引),可通过下记SQL进行索引的指定。
select * from 表 use index(索引名) where 条件 // 提示用指定索引,未必采用建议
select * from 表 ignore index(索引名) where 条件 // 提示不用指定索引,未必采用建议
select * from 表 force index(索引名) where 条件 // 强制使用指定索引,必须使用
5.4.3 前缀索引
前缀所以只支持字符串字段,目的是为了避免 字段数据太大,浪费索引的磁盘空间。
创建前缀索引:create index 索引名 on 表名(字段名(n)); // n代码前缀长度
注释:前缀长度的选择:select count(distinct substring(字段, 1, n)) / count(*) from 表; // 得到的值越接近1,n效率越高
5.4.4 覆盖索引
覆盖索引:查询项目都是索引列,所有数据在索引已经得到,直接返回结果,效率高。
非覆盖索引:查询结果有索引列以外字段,根据二级索引进行回表查询,效率略低。
注释:所以,检索SQL,不要使用*查询。
单列索引:检索条件包含多个单列索引,只会使用一个,无法覆盖索引,导致回表查询。
联合索引:多条件查询,建议使用联合索引,同时考虑联合索引的字段顺序以满足最左前缀法则。
注释:索引设计原则,1.查询量大的SQL建立索引,2. 超过100万以上的数据建立索引,3.要控制索引的数量,避免影响增删改的效率,4.选择区分度高的列建立索引(例如唯一字段)
6. SQL优化
6.1 SQL性能分析
6.1.1 查看SQL执行频率
show [session | global] status; // 查看CRUD执行频率,只坑看到总次数看不到具体SQL
show global status like 'com_______';// 7个下滑,代表_select,_update,_delete,_insert
6.1.2 慢查询日志
查看日志开启状态:show variables like 'slow_query_log'; // mysql5.7及以后默认开启
查看超时记录时间:show variables like 'long_query_time';
查看日志输出方式:show variables like '%log_output%';
查看日志存放路径:show variables like 'slow_query_log_file';
修改查询日志状态:set global slow_query_log = ON | OFF;
最高查询日志时间:set global long_query_time = 秒;
修改日志输出方式:set global log_output = 'FILE | TABLE';
查看TABLE日志内容:select * from mysql.slow_log;
查看FILE日志内容:日志路径/数据库-slow_log;
日志路径:linux(var/lib/mysql/localhost-show.log), windows(C:\ProgramData\MySQL\MySQL Server 8.0\Data)
6.1.3 profile详情
(1) 查看是否支持:select @@have_profiling; // YES支持,NO不支持
(2) 查看是否开启:select @@profiling; // 默认是0关闭的
(3) 设置开启:set [session | global] profiling = 1; // 实验global设置未生效,session可用
(4) 开启后查看耗时:
show profiles; // 查看每条指令耗时,获取query_id 耗时时间
show profile for query query_id; // 查看指定id的SQL各个阶段耗时
6.1.4 explain查看执行计划
用法:在select语句之前 加 explain 或 desc
id:表示表的执行顺序,值大的先执行,相同值由上到下执行。
type:访问类型,性能由好到差顺序是,
null(不访问表),
system(系统表),
const(主键访问),
eq_ref(唯一访问),
ref(非唯一索引访问),
range(范围索引),
index(全索引扫描),
all(全部扫描)
possible_key:可能用到的索引
key:实际用到的索引
key_len:索引最大使用长度(数值 字节数+1, 字符型 长*3+2。可为null字段 再+1),越小越好
ref:显示索引中,使用到的索引列名
rows:预估查询行数
filtered:查询到行数占查询总行数的百分比,越大越好
6.2 SQL性能优化
6.2.1 插入优化(主键优化)
批量插入,按主键顺序插入,手动提交事务,可以提高插入效率
注释:存储分为:表空间(64段),段(64区),区(64页-1M),页(16KB),行。
主键顺序插入,一页写满,按顺序开新页。
主键乱序插入,插入数据在两个满页之间,将一个页分裂成两个,插入新页(页分裂)。
删除数据,是将数据标记为删除,页不满50%会找前后两个页,与另一个50%页合并(页合并)。
主键设计原则:降低长度,选择自增属性,避免修改主键
6.2.2 大批量插入数据(优化为加载文件数据)
(1). 连接数据库 mysql --local-infile -u用户名 -p密码 // 此方式可加载本地文件
(2). 查询本地文件加载状态 select @@local_infile;
(3). 设定开启本地文件加载 set global local_infile=1;
(4). 加载本地文件到表 load data local infile 'D:\\xx.log' into table 数据库.表名 [fields terminated by ',' lines terminated by '\n'] ;// 代表加载文件 log 到表,默认按逗号分割字段,按换行符换行
注释:导出文件数据 select * into outfile '文件名' from 表名 [fields terminated by ',' lines terminated by '\n'],默认地址 show variables like 'secure_file_priv'(C:\ProgramData\MySQL\MySQL Server 8.0\Uploads\)不能导出。
6.2.3. 排序优化(order by)
(1). 根据索引顺序排序,效率最高(通过索引获取数据就是排好的顺序)。
(2). 排序的顺序,与联合索引创建时的字段顺序不一致(违背最左前缀法则),不完全按索引排序
(3). 创建索引默认都是升序,排序按联合索引字段顺序都升都降是索引排序。一升一降(违背最左前缀法则)
(4). 可以创建索引时指定排序规则:create index 索引名 on 表名(字段 asc, 字段 desc);
6.2.4. 分组优化(group by)
(1). 与排序优化一样,按索引顺序分组,效率最高(满足最左前缀法则)
(2). 可以将最左前缀(联合索引字段)写在where中,之后的(联合索引字段)写在group by中。(是满足最左前缀法则的)
6.2.5. 分页优化(limit)
大数据(1千万条以上)查询页越往后越慢,
网上查询给的解决办法是:关联id排序过的子查询,能优化大数据后面排序的效率
6.2.6. 总件数函数优化(count函数)
(1). count(*) mysql做了优化,性能最好。
(2). count(1) 不取数据,性能与count(*)一样,性能最好。
(3). count(主键) 主键与唯一字段的count性能第二。
(4). count(普通字段) 性能最差,字段如果有null取到的是不为Null的数据的件数
6.2.7. 更新优化(update)
更新条件如果不是索引,事务会进行表锁,导致其他事务不能更新数据。避免非索引更新条件。
7. 视图
7.1. 视图作用
(1). 简化业务,将多个复杂条件改为视图。避免基本表变更,影响业务。
(2). mysql对用户授权,只能控制表权限,通过视图可以控制用户字段权限。
7.2. 视图命令
(1). 创建视图:create [or replace] view 视图名 as select * from 表;
(2). 修改视图:alter view 视图名 as select * from 表;
(3). 删除视图:drop view 视图名;
(4). 查询视图语句:show create view 视图名;
(5). 查询视图数据:select * from 视图名;
7.3. 视图(插入,更新,删除数据)
视图中的行数据,必须与基本表的行一一对应。不能用group, with ,union ,limit ,distinct,聚合函数
注释:创建视图时,用函数,分组,去重等,则不能通过视图插入更新数据。表中视图没有查询的项目必须可以为空或者有默认值,才可以通过视图插入数据。
7.4. 视图检查选项
(1). create view 视图名 as select * from 表 where 条件 with [cascaded] check option;
(2). create view 视图名 as select * from 表 where 条件 with local check option;
(3). create view 视图名 as select * from 视图 where 条件 with [cascaded] check option;
(4). create view 视图名 as select * from 视图 where 条件 with local check option;
注释:加了视图检查选项,会对where条件进行检查,不能插入不满足where条件的数据。with check option 默认是cascaded级别,基于表创建的视图cascaded和local没有却别,都是只做自己视图的检查。基于视图创建的视图,父视图有检查选项的都会做检查,父视图没有检查选项时,子视图local不检查无检查选线的父视图where条件,子视图cascaded时会检查无检查选项的父视图where条件。
检查选项的作用:避免通过视图插入的数据,视图查询不到。
8. PL/SQL
8.1 变量
8.1.1 系统变量
全局global重启mysql失效,会话session当前会话有效。
显示系统变量:show [global | session] variables; //默认会话级别,可like模糊查询
查看系统变量:select @@系统变量名; // select @@[global|session].变量名
设置系统变量:set [global | session] 系统变量名 = 值; // set @@[global|session].变量名=值;
注释:global多个窗口共用一个变量,默认的session每个窗口用自己的变量
8.1.2 自定义变量:
设置:set @变量名 [:]= 值; select @变量名 := 值;
查看:select @变量名;
使用:@变量名 // 在存储过程中可直接使用
注释:自定义变量与session变量一样只在当前窗口有效,不分过程内外
8.1.3 局部变量
声明:declare 变量名 类型 [default 值];
设置:set 变量名 = 值;
8.2 分歧条件
if 条件 then ...; [elseif 条件 then ...;] else ...; end if;
case 变量 when 值 then sql...; [when 值 then sql...;] else sql...; end case;
case when 条件 then sql...; [when 条件 then sql...;] else sql...; end case;
注释:sql和end之后要加分号结束语句
8.3 循环
while 条件 do sql...; end while; // 先判断后执行
repeat sql...; until 条件 end repeat; // 先执行后判断
循环名: loop sql...; end loop; leave 循环名; // 退出循环,iterate 循环名; // 跳过本次循环
注释:sql和end之后要加分号结束语句
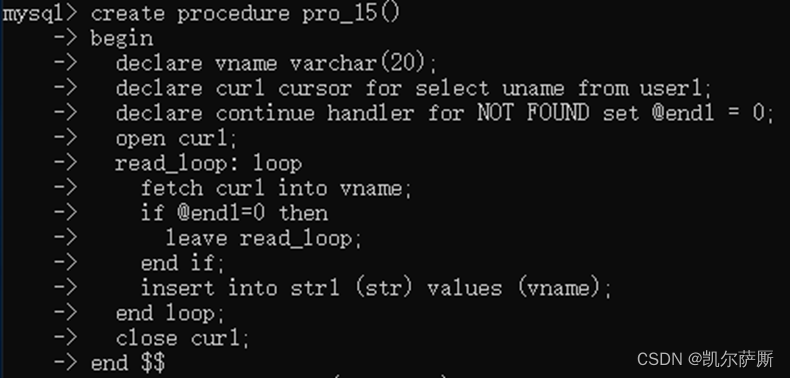
8.4 游标
声明游标:declare 游标名 cursor for 查询语句;
打开游标:open 游标名;
循环游标:fetch 游标名 into 变量 [,变量...];
条件处理:declare exit | continue handler for SQLSTATE '02000' set 变量 = 值;
关闭游标:close 游标名;
注释:02000没有数据,exit满足条件退出, continue满足条件继续执行
以01开头代码简写(SQLWARNING) 02开头简写(NOT FOUND) 以外(SQLEXCEPTION)
8.5 过程化SQL
无
8.6 存储过程
(1) 创建:create procedure 过程名() begin ... end
(2) 参数:create procedure 过程名(in 参数 类型, out 返回值 类型) // in, out, inout
(3) 查看:select * from information_schema.routines where routine_schema = 数据库
(4) 显示:show create procedure 过程名
(5) 删除:drop procedure 过程名
(6) 调用:call 过程名(参数..., 返回值...)
注释:创建过程前将结束符改为(DELIMITER 双货币) ,过程执行完改回 (DELIMITER ;)
返回值out用(set 返回值=值)的形式赋值
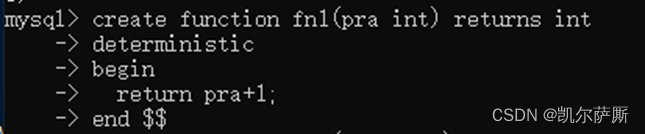
8.7 存储函数
创建:create function 函数名(参数 类型) returns 类型 [函数类型] begin return sql...; end;
注释:开启了bin-log需要指定函数类型(deterministic不确定, nosql 不改数据,reads sql data 读数据, modifies sql data 改数据, contains sql 含sql语句)
删除:drop funciton 函数名;
显示:show create function 函数名;
调用:select 函数名(参数);
8.8 触发器
触发器是,与表有关的数据在增删改之前或之后执行的语句集合。
Mysql只支持行级触发器(影响一行数据执行一次)
创建触发器:
create trigger 触发器名
before/after insert/update/delete // 之前/之后 插入/更新/删除,各选一个,例如 before insert
on 表名 for each row // 行级触发器
begin
sql..
insert into 表名 values(old.id, new.id); // old.id 更新前id,new.id更新后id
end;
注释:insert只有new属性,delete只有old属性,update 既有new 又有old
查看触发器:show triggers;
删除触发器:drop trigger [数据库名.]触发器名;
注释:触发表1插入只写删除表2不影响表1插入结果。改结果需要before时 set new.字段=值。※
9. 数据类型与函数
9.1 数据类型
9.1.1 数值型
整形:tinyint //1字节, smallint // 2字节, mediumint // 3字节, int // 4字节, bigint // 8字节。
注释:类型后加空格unsigned为正数取值。
浮点型:float(6, 3) // 4字节, double(6, 3) // 8字节。
注释:浮点型不能精确计算。
定点精确值:decimal(5, 2) // 3位整数, 2位小数,全长5位。全长<65, 小数<30
9.1.2 字符型
定长字符串:char // (255)指定位数 0~255bytes, 插入数据自动补齐长度
变长字符串:varchar // (65535)指定位数 0~65536bytes,按插入数据实际位数存储
二进制:tinyblob // 255byte, blob// 64k, mediumblob // 16M, longblob // 4G
文本:tinytext // 255byte(255个字符), text // 64k(6万..), mediumtext // 16M , longtext // 4G
注释:文本类型不能有默认值。创建索引需指定前面位数。
9.1.3 日期时间
日期:date // 3字节,'1000-01-01'~'9999-12-31'
时间:time // 3字节, '-838:59:59'~'838:59:59'
日期时间:datetime // 8字节, '1000-01-01 00:00:00'~'9999-12-31 23:59:59'
时间戳:timestamp // 4字节, '1970-01-01 00:00:01'~'2038-01-19 03:14:07' 其他字段修改刷新
年:year // 1字节 'YYYY'
9.2 函数
9.2.1 聚合函数
count, max, min, sum
9.2.2 流程函数
if (表达式|字段, 字段1|值, 字段2|值); // 如果表达式成立或字段不为null,则字段1,否则字段2
ifnull(字段1, 字段2|值); // 如果字段1是null则用字段2,否则字段1
case when 表达式 then 字段1|值 [...] else 字段|值 end [as 别名]; // 表达式成立则返回字段1
case 字段 when 值1 then 字段1|值 [...] else 字段|值 end [as 别名]; // 当字段是值1则返回字段1
coalesce(数据, 数据...) // 返回第一个不为null的值
9.2.3 类型转换函数
数值转字符:cast(数值 as char(n)) // ②convert(数值, char) , ③数值+''
字符转数值:cast(字符 as decimal(n,m)) // ②字符+0
字符转日期:str_to_date('日期', '%Y%m%d'); // Y(4位年),y(2位年),M(1-12月),m(01-12),d(01-31),H(24),h(12),i(60), S(60)s(60) f(000000-999999)
日期转字符:date_format(日期, '%Y%m%d')
9.2.4 数值函数
向上取整:ceil(值) // ceiling(数值) 向上取整,小数有值进1
向下取整:floor(值) // 向下取整,小数舍弃
四舍五入:round(x, y) // 四舍五入x留y个小数。round(x) 留整数=round(x,0)。y可以是负数。
9.2.5 字符函数
拼接:concat(s1, s2,...) // 有null则返回Null, concat_ws(x, s1, s2...) x分割后续字符的拼接
补齐:lpad(s1, n, pad) rpad(s1, n, pad) // 将s1用pad补到n个字符。(l和r)原s1超n长截去右侧字符
去空:trim(s1) // 前后去空格 ltrim(s1), rtrim(s1)
截取:substring(s1, start, len) // 从start(最小1)开始截取len个字符,指定位数没有返回空串
截掉:left(s1, len), right(s1, len) // len时字符个数
取长:char_length(s1) // 字符个数(汉字=1),length(s1) // 字节个数(汉字=3)
9.2.6 日期函数
当前日期:curdate()
当前时间:curtime()
当前日期时间:now()
获取年,月,日:year(date), month(date), day(date)
日期计算:date_add(日期, INTERVAL 值 类型[年|月|日] )
其他:数据库设计规范
第一范式:同一列不能有多个值(同一个字段不能,既存姓名,又存年龄),
第二范式:每一列与所有主键相关(姓名字段,与 主键【学校,班级,学号】,都相关),
第三范式:避免主键从属于列(不要将,学校字段,放在主键【学号】的数据行上)










![[Python学习笔记]Requests性能优化之Session](http://pic.xiahunao.cn/[Python学习笔记]Requests性能优化之Session)








