
迈向光明之路,必定荆棘丛生。
文章目录
- 一、Elasticsearch概述
- 二、初识ES倒排索引
- 1. 正向索引
- 2. 倒排索引
- 三、ES环境搭建
- 1. 安装单机版ES
- 2. 安装Kibana
- 3. 安装ik分词器
- 3.1 在线安装ik插件
- 3.2.离线安装ik插件(推荐方式)
- 3.3 自定义词典
- 四、ES核心概念
- 五、ES基本操作(DSL)
- 1. DSL介绍
- 2. 索引库相关操作
- 2.1 创建索引库
- 2.2 查看所有索引库
- 2.3 查看指定索引库
- 2.4 删除索引库
- 3. 文档相关操作
- 3.1 创建文档
- 3.2 查询文档
- 3.3 修改文档
- 3.4 修改指定字段的值
- 3.5 删除文档
- 3.6 批量操作
- 3.6.1 批量创建文档
- 3.6.2 批量删除文档
- 3.7 Mapping映射
- 3.7.1 查看映射
- 3.7.2 Mapping映射的常见属性
- 3.7.3 创建索引库和映射
- 六、ES高级查询(DSL)
- 1. 查询所有(match_all)
- 2. 匹配查询(match)
- 3. 多字段匹配(multi_match)
- 4. 前缀匹配(prefix)
- 5. 关键字精确查询(term)
- 6. 多个关键字精确查询(terms)
- 7. 范围查询(range)
- 8 返回指定字段(_source)
- 9. 组合查询(bool)
- 9.1 must(并且)
- 9.2 should(或者)
- 9.3 must_not(非)
- 9.4 filter
- 10. 聚合查询(aggs)
- 10.1 max
- 10.2 min
- 10.3 avg
- 10.4 sum
- 10.5 stats
- 10.6 terms(分组)
- 11. 分页查询(from、size)
- 12. 高亮查询(highlight)
- 13. 近似查询(fuzzy)
- 七、Java操作ES
- 1. API介绍
- 2. 使用RestHighLevelClient操作ES
- 2.1 环境准备
- 2.2 索引库相关操作
- 2.2.1 创建索引库
- 2.2.2 获取所引库
- 2.2.3 删除索引库
- 2.3 文档相关操作
- 2.3.1 数据准备
- 2.3.2 添加文档
- 2.3.3 修改文档
- 2.3.4 根据id查询文档
- 2.3.5 删除文档
- 2.3.6 批量新增
- 2.4 高级查询
- 2.4.1 查询所有文档
- 2.4.2 匹配查询
- 2.4.3 高亮查询
- 2.4.4 聚合查询
- 3. 使用Spring Data Elasticsearch 操作ES
- 3.1 Spring Data概述
- 3.2 Spring Data Elasticsearch 概述
- 3.3 环境准备
- 3.4 使用ElasticsearchRestTemplate操作ES
- 3.4.1 添加文档
- 3.4.2 根据ID查询文档
- 3.4.3 修改文档
- 3.4.4 删除文档
- 3.4.5 查询所有文档
- 3.4.6 高亮查询
- 3.4.7 分页查询
- 3.4.8 聚合查询
- 3.5 使用ElasticsearchRepository接口操作ES
一、Elasticsearch概述

Elasticsearch(简称ES)是一个分布式、RESTful 风格的搜索引擎、数据分析引擎。ES底层是基于Apache Lucene搜索引擎库实现的,但是ES的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。ES可以提供实时的数据存储和检索能力,并且拥有很好的可扩展性。它可以扩展到上百台服务器,处理PB级别的数据(海量数据—千万级以上)。
ES被广泛应用于各种场景,例如:搜索引擎、日志管理、电商推荐、监控和报告等。其强大的搜索和分析能力使得数据的处理变得简单、高效和可扩展。
官网地址:https://www.elastic.co/cn/elasticsearch/
数据库搜索存在的问题:
1、常见数据库特点:
- MySQL:事务
- Redis:内存/读写效率高
- MongoDB:最接近关系型的nosql
- Elasticsearch:分布式搜索引擎,提供了Restful接口,ES也可以看做分布式文档数据库(通过DSL语句操作ES)。
2、普通数据库可以实现搜索,为什么还要用ES?
- 海量数据搜索效率低(逐行扫描方式)
- 解决方案:针对要搜索的字段建立索引、对数据库进行分库分表处理(查询效率提升了,但是添加效率会受到影响)
- 搜索数据不够全面。例如MySQL模糊查询:like %联想电脑% (只能搜索包含联想电脑的内容,没有实现分词效果)
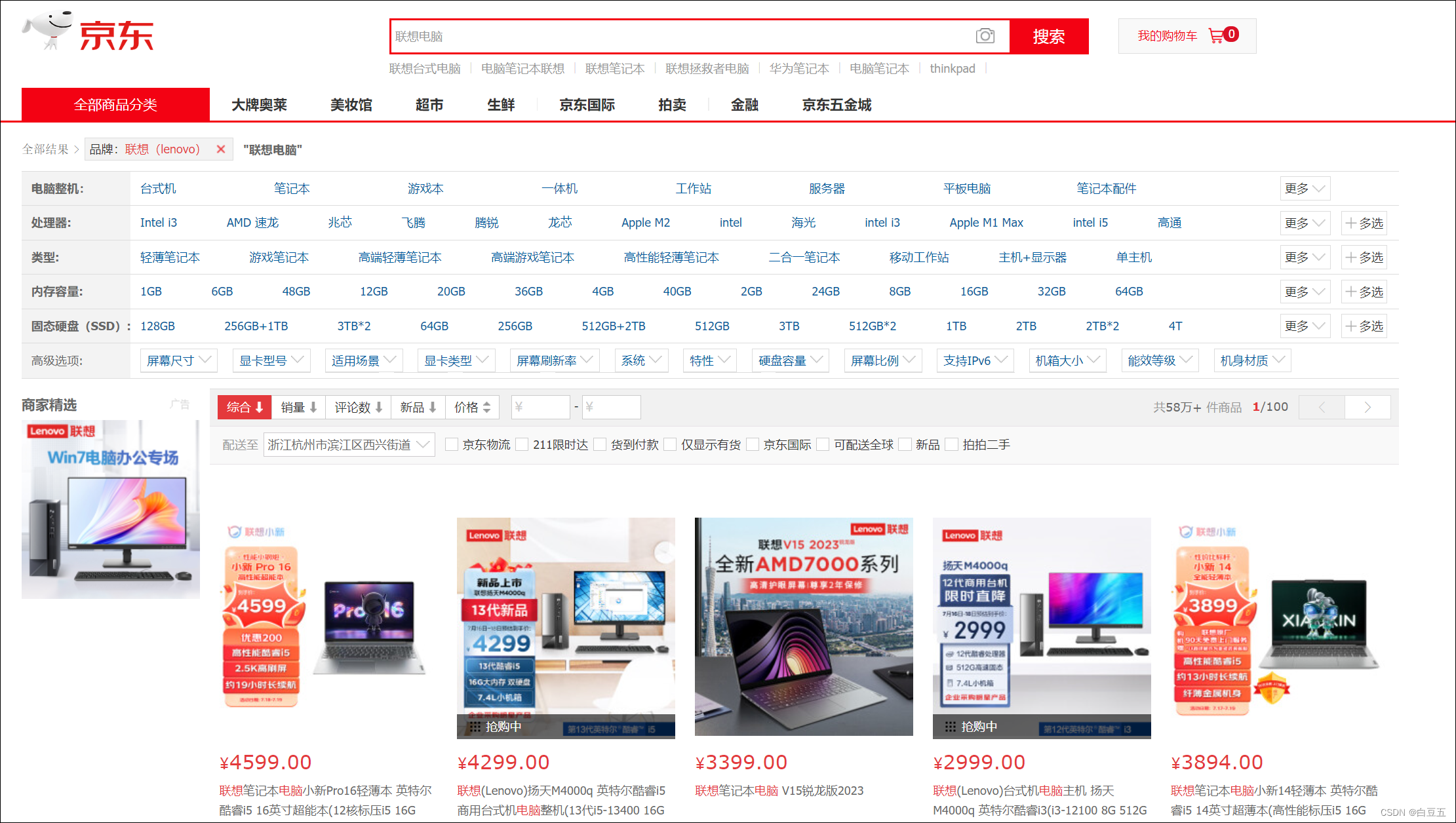
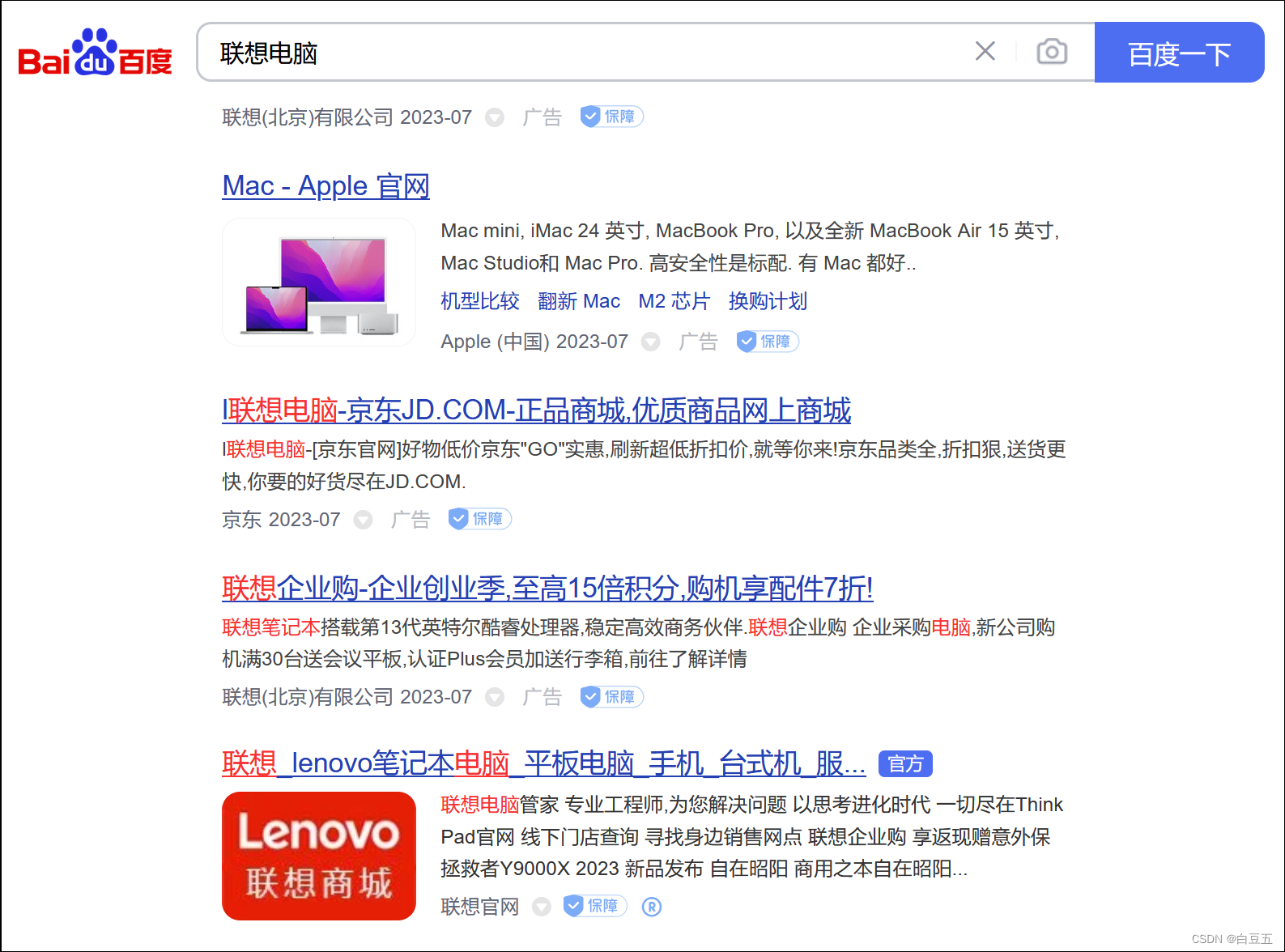
Lucene、ElasticSearch相关概述:
1、Lucene介绍:
-
Lucene是基于Java语言开发的搜索引擎类库,是Apache基金会的顶级项目,由DougCutting于1999年研发。
-
官网地址:https://lucene.apache.org/
-
优点:易扩展、高性能(基于倒排索引)。
-
缺点:只限于Java语言开发、学习曲线陡峭、不支持水平扩展(搭集群)。
2、ElasticSearch介绍:
-
2004年Shay Banon基于Lucene开发了Compass。
-
2010年Shay Banon重写了Compass,取名为ElasticSearch。
-
官网地址:https://www.elastic.co/products/elasticsearch
-
目前最新版本:7.17.9、8.8.2(本文以7.12.1为例)
-
相比Lucene,ElasticSearch具备下列优势:
- 支持分布式,可水平扩展。
- 提供Restful接口,可被任何语言调用。
ElasticSearch小故事:

多年前,一个刚结婚不久的失业开发者Shay Banon(谢巴农),由于妻子要去伦敦学厨师,他便跟着去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,于是他开始使用Lucene进行尝试。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。于是他决定闭门造车重写Compass库使其成为一个独立的服务叫做ElasticSearch。
第一个公开版本出现在2010年2月,在那之后ElasticSearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立(Elastic),他们一边提供商业支持一边开发新功能,不过Elasticsearch将永远开源且对所有人可用。
而Shay的妻子依旧等待着她的食谱搜索引擎……
ES 与 Apache Solr 搜索引擎对比:
1、ES基本是开箱即用,非常简单。Solr安装略微复杂。
2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑。
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
目前比较知名的搜索引擎技术排名:https://db-engines.com/en/ranking/search+engine
二、初识ES倒排索引
ES基于倒排索引提高查询效率。
1. 正向索引
正向索引:建立文档id和词之间的对应关系。

在正向索引中,每个文档都会维护一个关键词列表,记录了该文档包含的所有关键词。当用户发起搜索时,搜索引擎会遍历索引库中的所有文档,并检查每个文档的关键词列表,找出匹配程度最高的文档。
存在的问题:如果正向索引中的数据量较大,就需要遍历所有文档才能找到匹配的结果,效率比较低。为了提高搜索效率,搜索引擎通常使用倒排索引来加速搜索过程。
2. 倒排索引
倒排索引:也称之为反向索引,建立单词和文档id之间的对应关系。即把文档→单词的形式变为单词→文档的形式。(借助于分词器)
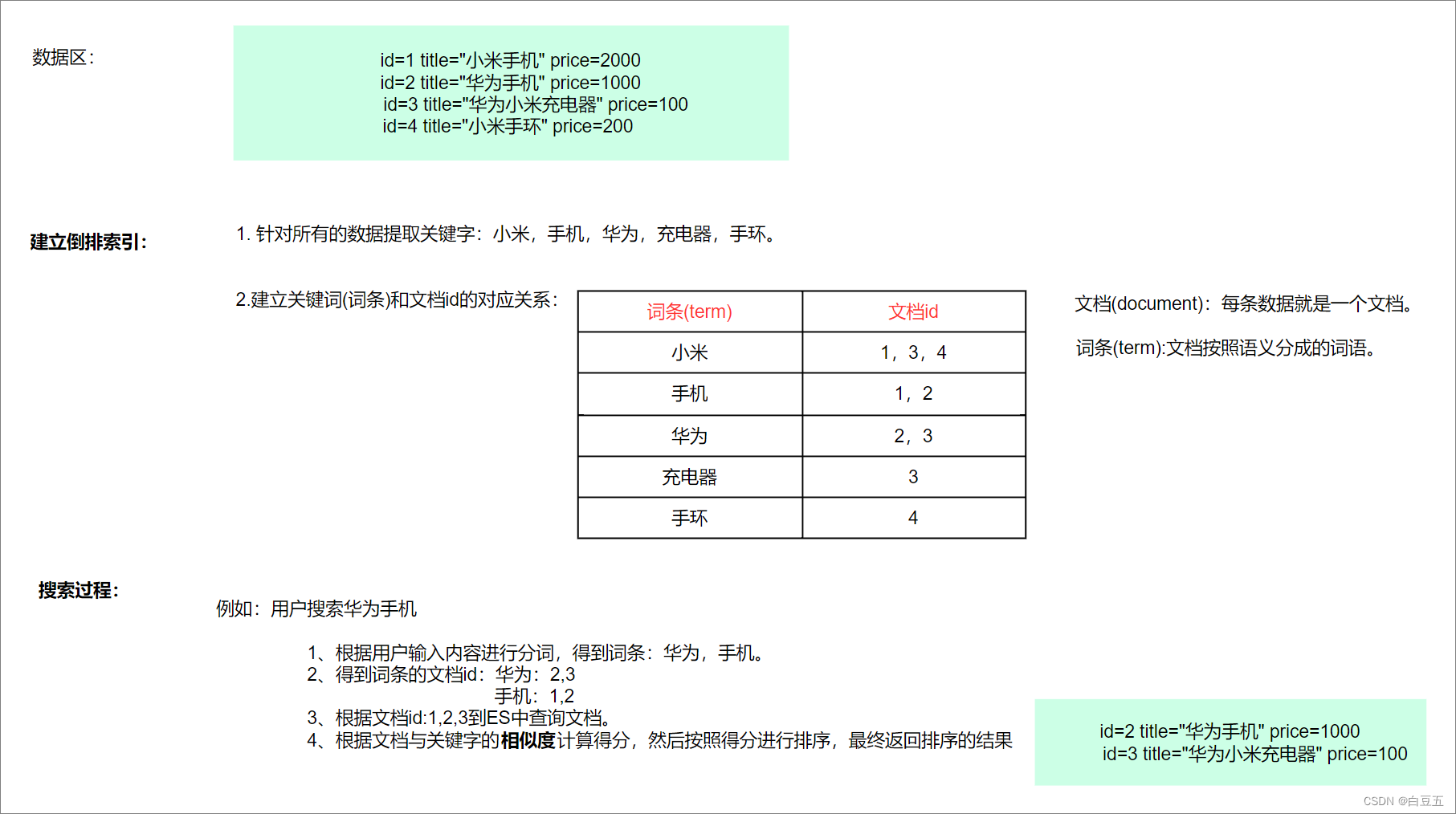
倒排索引建立过程:先对数据(文档)进行分词,得到一个个的词条,然后将词条与文档id的对应关系保存起来。
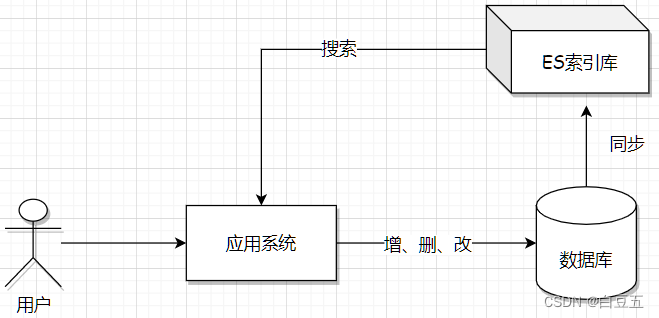
那有了ES以后就不需要数据库了嘛?
- ES主要实现数据的搜索,并且ES还不支持事务,因此要保证数据一致性,还需要结合关系型数据库使用。
三、ES环境搭建
基于Docker安装单机版ES。(ES版本为7.12.1)
1. 安装单机版ES
1、创建Docker网络(也就是一个标识,创建网络的目的是让es和kibana容器互联)
# 创建一个网络
docker network create es-net#查看docker本机的网络
docker network ls #删除网络
# docker network rm es-net

2、下载elasticsearch镜像。(这个镜像体积非常大,接近1个G)
docker pull elasticsearch:7.12.1
下载成功后,别忘了导出镜像,方便以后使用。
docker save -o es.tar elasticsearch:7.12.1
3、启动es容器(单机版es)

docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-e TZ=Asia/Shanghai \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--network es-net \
--privileged \
--restart=always \
-d elasticsearch:7.12.1
-e "cluster.name=es-docker-cluster":设置集群名称。-e "http.host=0.0.0.0":监听的地址,可以外网访问。-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":设置容器内存大小。-e "discovery.type=single-node":非集群模式。-v es-data:/usr/share/elasticsearch/data:挂载es数据目录。-v es-logs:/usr/share/elasticsearch/logs:挂载es日志目录。-v es-plugins:/usr/share/elasticsearch/plugins:挂载es插件目录。--privileged:授予数据卷访问权。--network es-net:加入一个名为es-net的网络中。-p 9200:9200:端口映射配置, 9200是es与外部机器通讯的端口,9300是es集群节点之间通讯的端口。
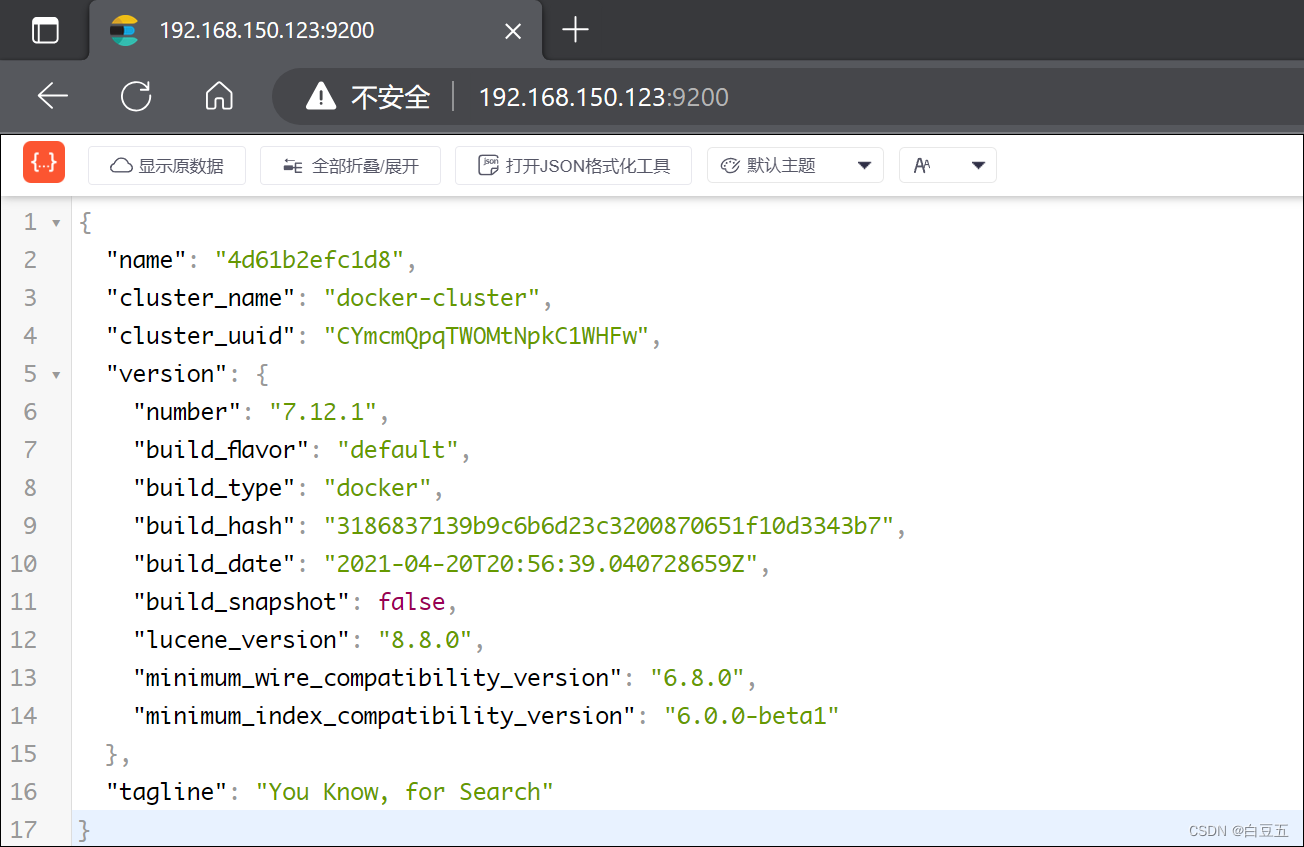
4、浏览器测试访问:http://192.168.150.123:9200/
2. 安装Kibana
Kibana是一个开源的数据分析可视化平台,主要和ElasticSearch搭配使用。
可以对ES索引库中的数据进行可视化(柱状图、饼状图、散点图等)的数据展示,在Kibana中也提供了开发者工具(devtools),我们可以直接编写DSL脚本请求ES的restful接口操作ES。
DSL(Domain Specific Language)领域专用语言,Elasticsearch提供了基于JSON的DSL来定义查询。
Kibana是ES的可视化工具,帮助用户实时分析和数据可视化,通过界面可以更方便学习ES。安装Kibana时要与ES版本保持一致。
1、下载镜像(与ES版本保持一致)
docker pull kibana:7.12.1
2、启动kibana容器
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中。-e ELASTICSEARCH_HOSTS=http://es容器名:9200":设置elasticsearch的访问地址,因为kibana已经与elasticsearch容器在同一个网络,因此可以用容器名直接访问elasticsearch。-p 5601:5601:kibana容器外部访问端口。
kibana启动一般比较慢,需要多等待一会,可以通过命令查看是否启动成功:
docker logs -f kibana
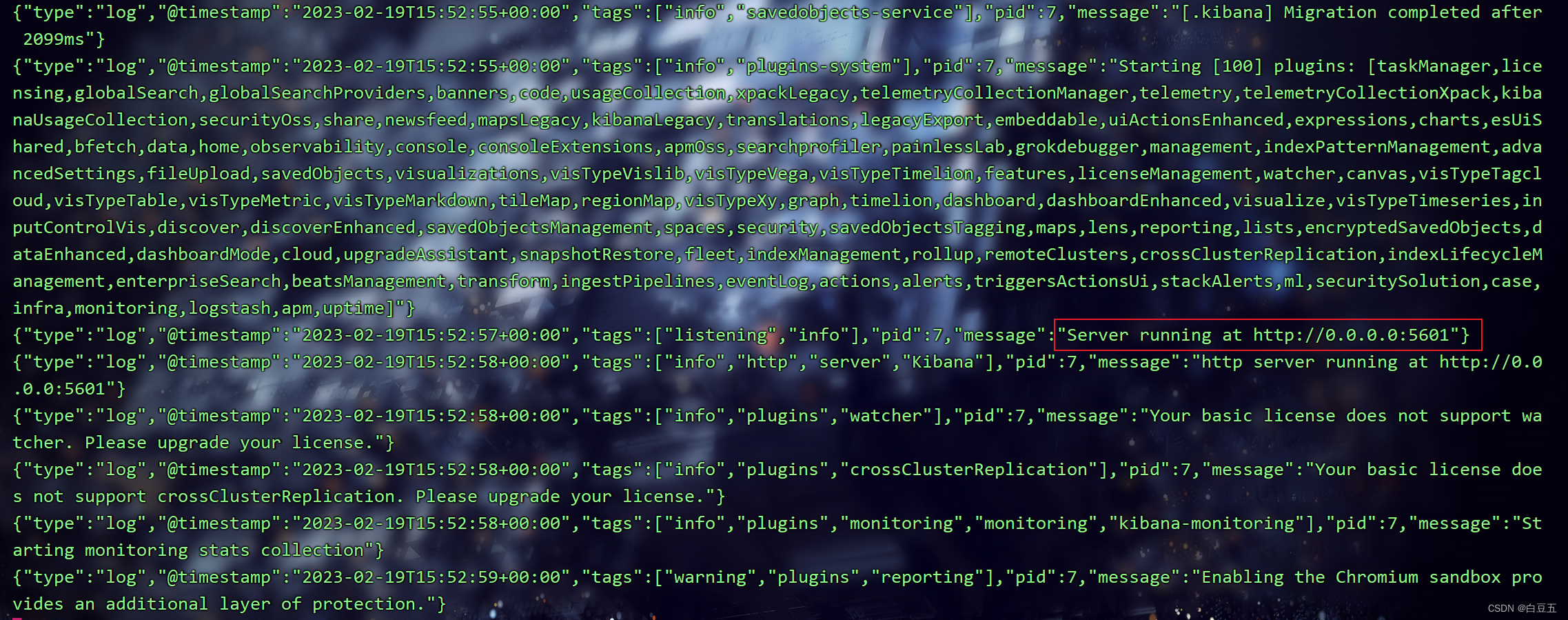
3、浏览器测试访问:http://192.168.150.123:5601/(点击Explore on my own:独自探索)
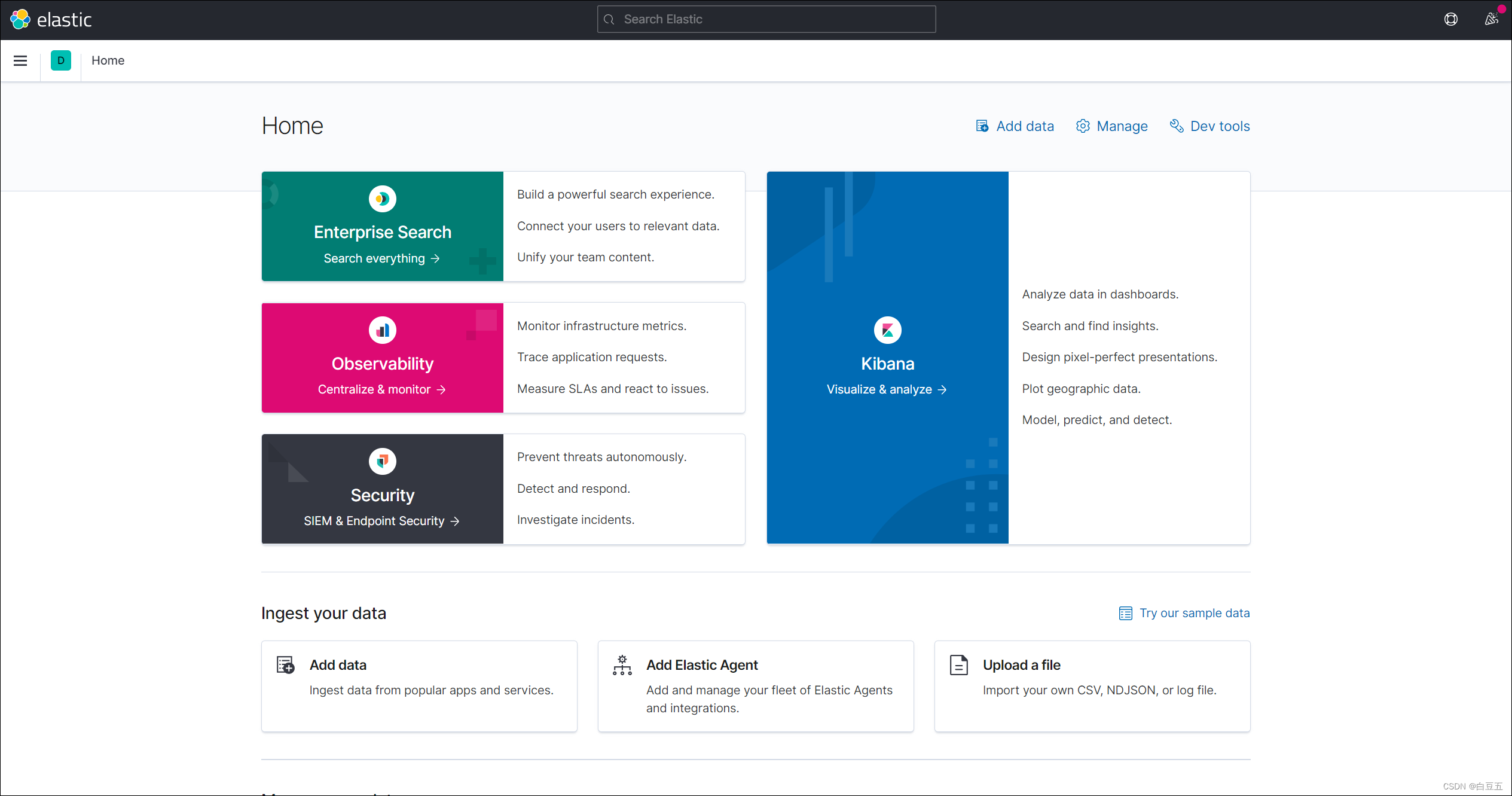
DevTools:在这个界面中可以编写DSL(DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD)。并且对DSL语句有自动补全功能。
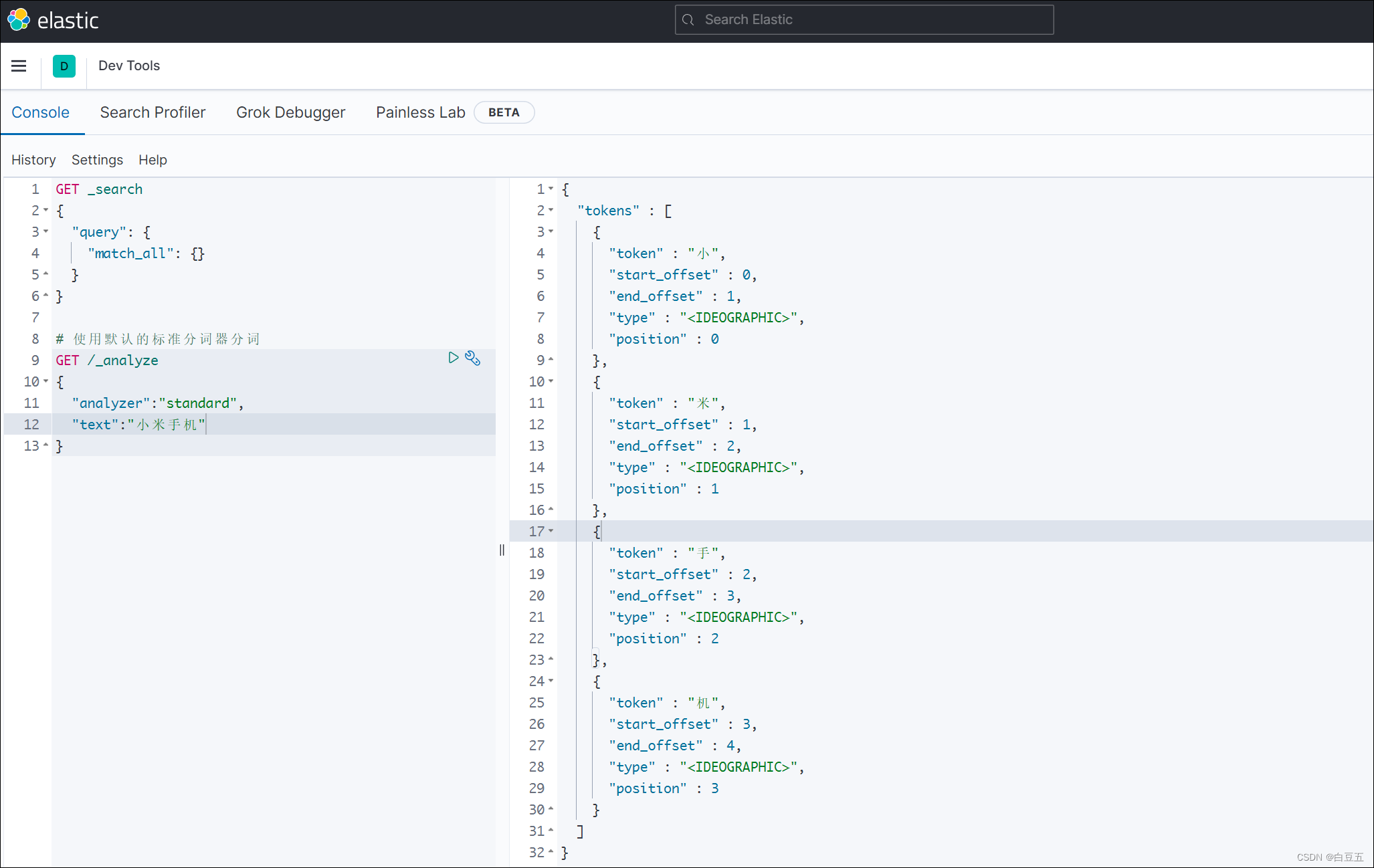
示例:使用默认的标准分词器(StandardAnalyzer),按词切分,对中文不太友好。
# 使用默认的标准分词器分词
GET /_analyze
{"analyzer":"standard","text":"小米手机"
}
3. 安装ik分词器
IK分词器:一款开源的中文分词器。项目地址:https://github.com/medcl/elasticsearch-analysis-ik
3.1 在线安装ik插件
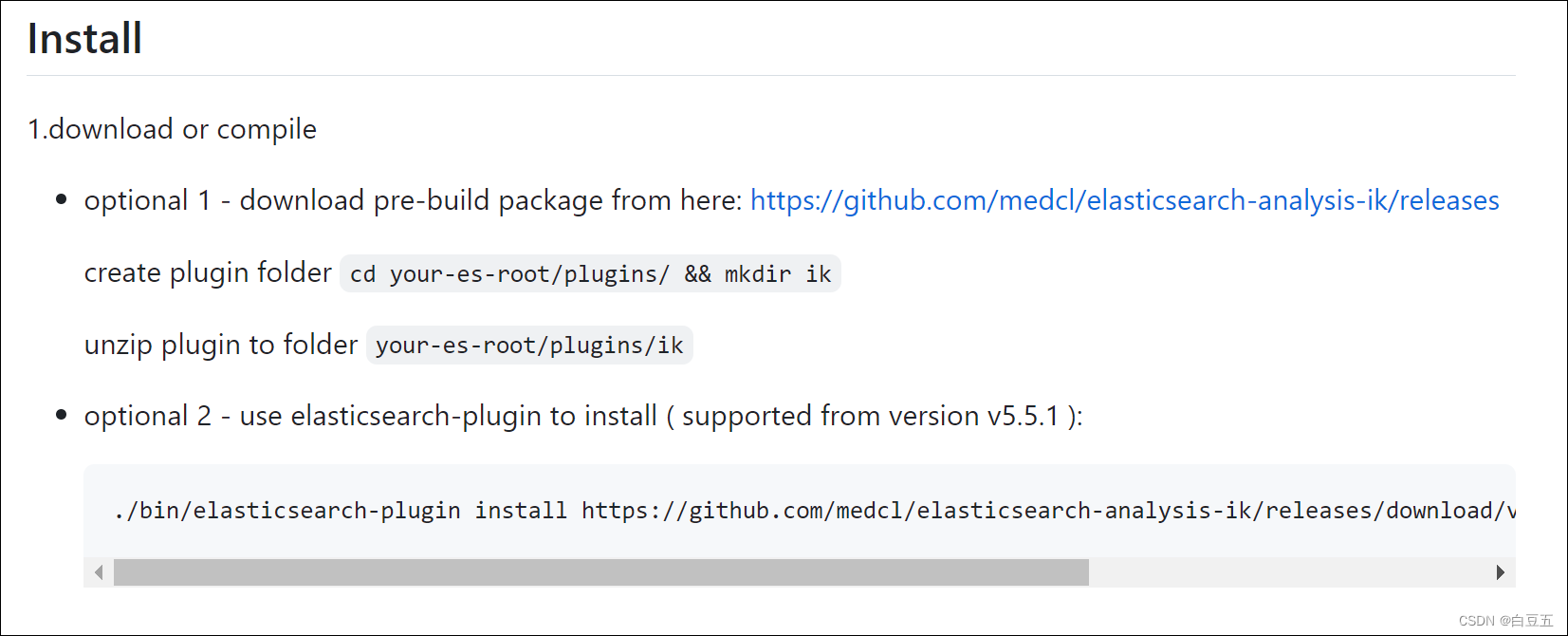
# 进入es容器内部
docker exec -it elasticsearch /bin/bash# 在线下载ik分词器插件并安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip#退出容器
exit#重启es容器
docker restart elasticsearch
3.2.离线安装ik插件(推荐方式)
1、下载ik分词器插件:https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip

然后将文件解压缩,修改文件夹名为:ik
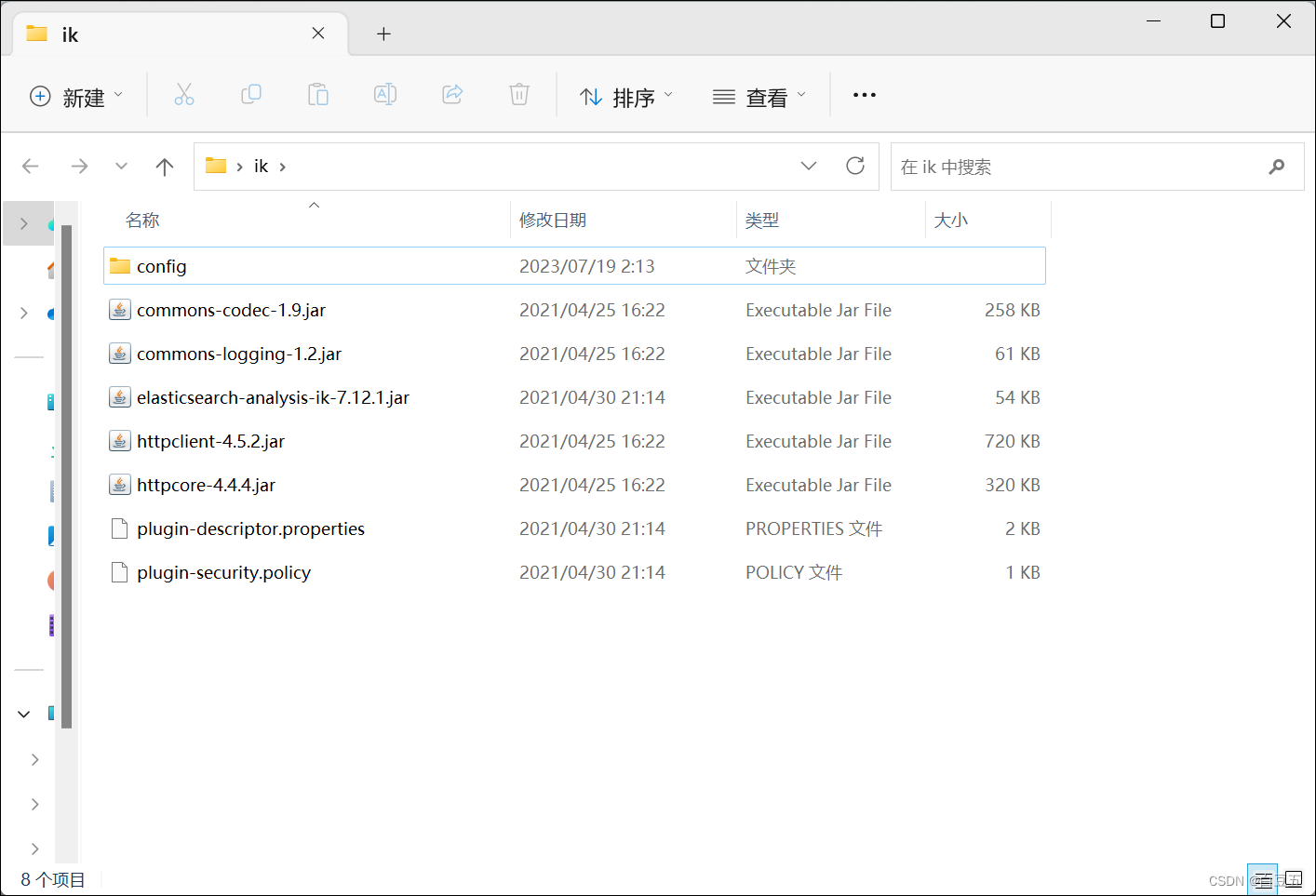
2、查看数据卷目录
安装插件需要知道es的plugins目录位置,而我们在启动容器时配置了挂载数据卷,所以通过下面命令查看即可:
# 查看es-plugins数据卷的详细信息
docker volume inspect es-plugins
显示结果:
说明plugins目录被挂载到了:/var/lib/docker/volumes/es-plugins/_data 这个目录。
3、将ik分词器上传到es容器的插件数据卷中: /var/lib/docker/volumes/es-plugins/_data
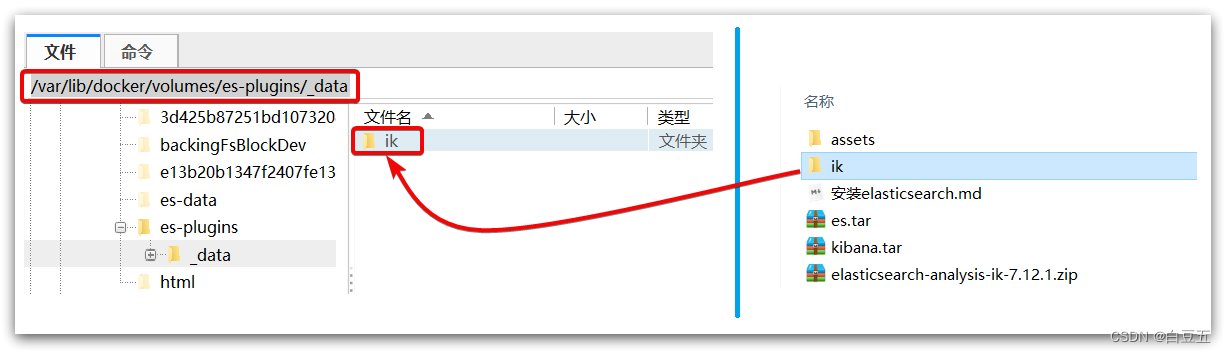

4、重启容器
# 4、重启容器
docker restart elasticsearch
5、测试ik分词器:
IK分词器提供了两种分词算法:
ik_smart:粗粒度分词,分出的词比较少。ik_max_word:细粒度分词,分出的词比较多。
示例1:测试ik分词器ik_max_word细粒度分词
GET /_analyze
{"text": "中华人民共和国","analyzer": "ik_max_word"
}
执行结果:
{"tokens" : [{"token" : "中华人民共和国","start_offset" : 0,"end_offset" : 7,"type" : "CN_WORD","position" : 0},{"token" : "中华人民","start_offset" : 0,"end_offset" : 4,"type" : "CN_WORD","position" : 1},{"token" : "中华","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 2},{"token" : "华人","start_offset" : 1,"end_offset" : 3,"type" : "CN_WORD","position" : 3},{"token" : "人民共和国","start_offset" : 2,"end_offset" : 7,"type" : "CN_WORD","position" : 4},{"token" : "人民","start_offset" : 2,"end_offset" : 4,"type" : "CN_WORD","position" : 5},{"token" : "共和国","start_offset" : 4,"end_offset" : 7,"type" : "CN_WORD","position" : 6},{"token" : "共和","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 7},{"token" : "国","start_offset" : 6,"end_offset" : 7,"type" : "CN_CHAR","position" : 8}]
}
示例2:测试ik分词器ik_smart粗粒度分词
GET /_analyze
{"text": "中华人民共和国","analyzer": "ik_smart"
}
执行结果:
{"tokens" : [{"token" : "中华人民共和国","start_offset" : 0,"end_offset" : 7,"type" : "CN_WORD","position" : 0}]
}
3.3 自定义词典
IK分词器之所以可以对中文进行合理的分词,是因为在IK分词器中提供了一个中文词典(extra_main.dic),在这个词典中定义了很多的词。

但是IK分词器并不能把所有的词全部考虑进去,比如网络热词:内卷、躺平、奥利给等。
因此为了满足开发的一些特殊化的需求,此时就需要自定义词典,可以自定义两类词典:
-
扩展词词典:定义自定义的词
-
停用词词典:定义不希望出现的词
操作如下:
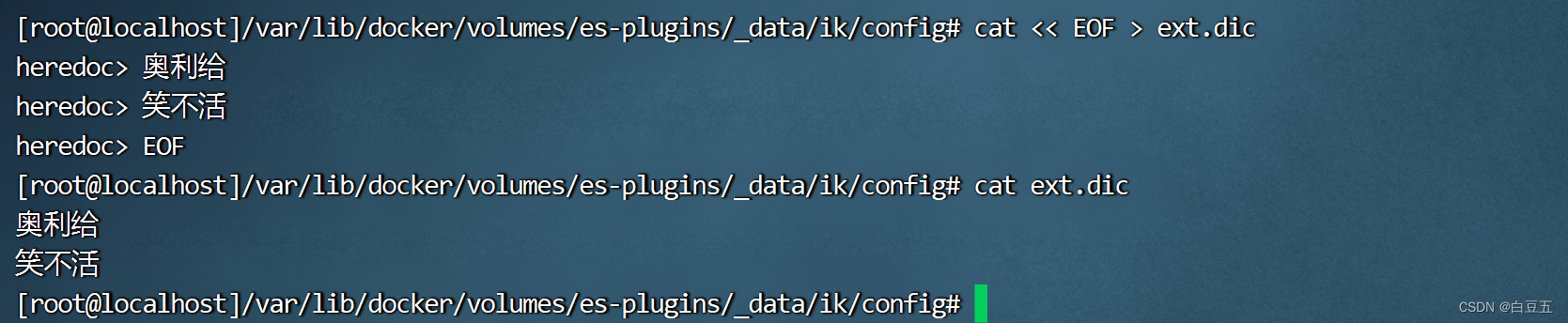
1、在/var/lib/docker/volumes/es-plugins/_data/ik/config目录下创建一个ext.dic文件
# 创建自定义词
cat << EOF > ext.dic
奥利给
笑不活
EOF
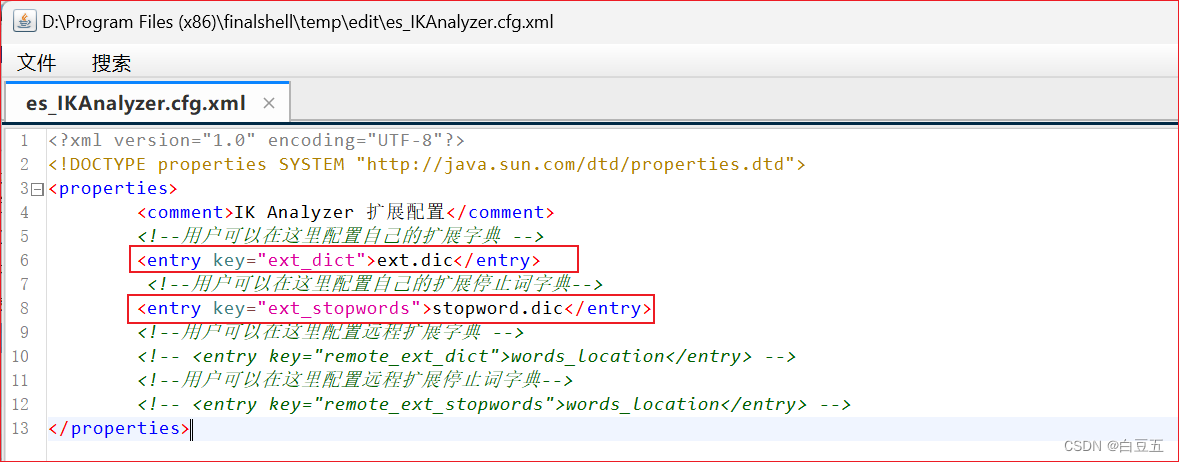
2、修改IKAnalyzer.cfg.xml文件配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3、重启es容器
docker restart elasticsearch
4、测试:
GET /_analyze
{"analyzer":"ik_max_word","text":"加油奥利给"
}
执行结果:
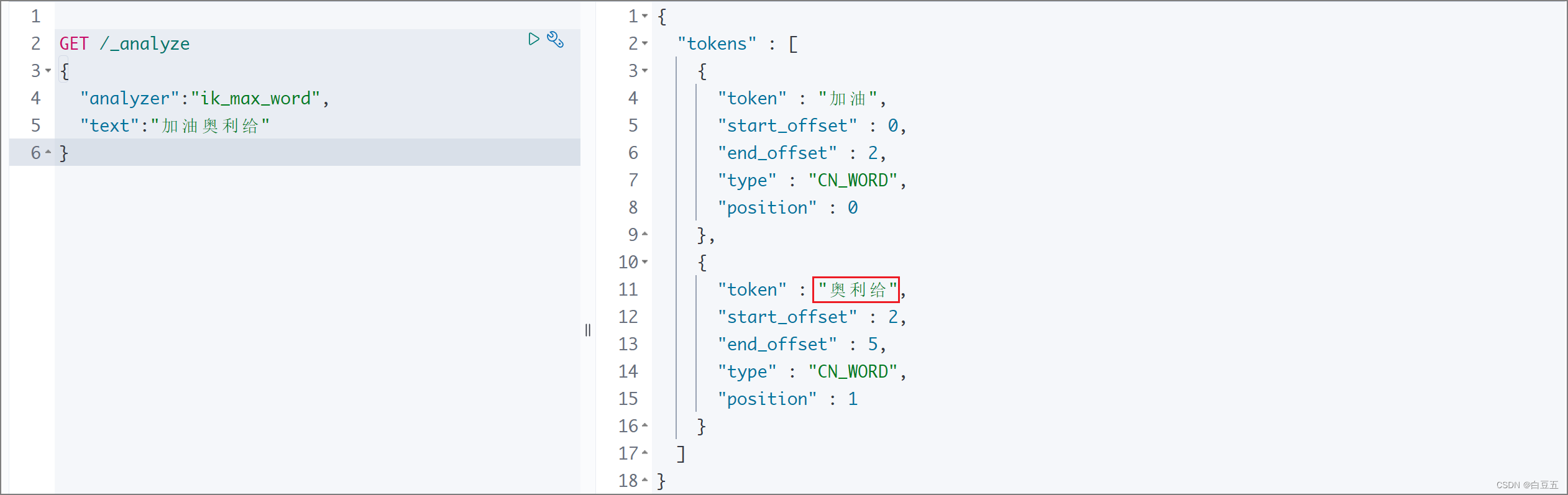
ok,扩展词典已经配置成功了。
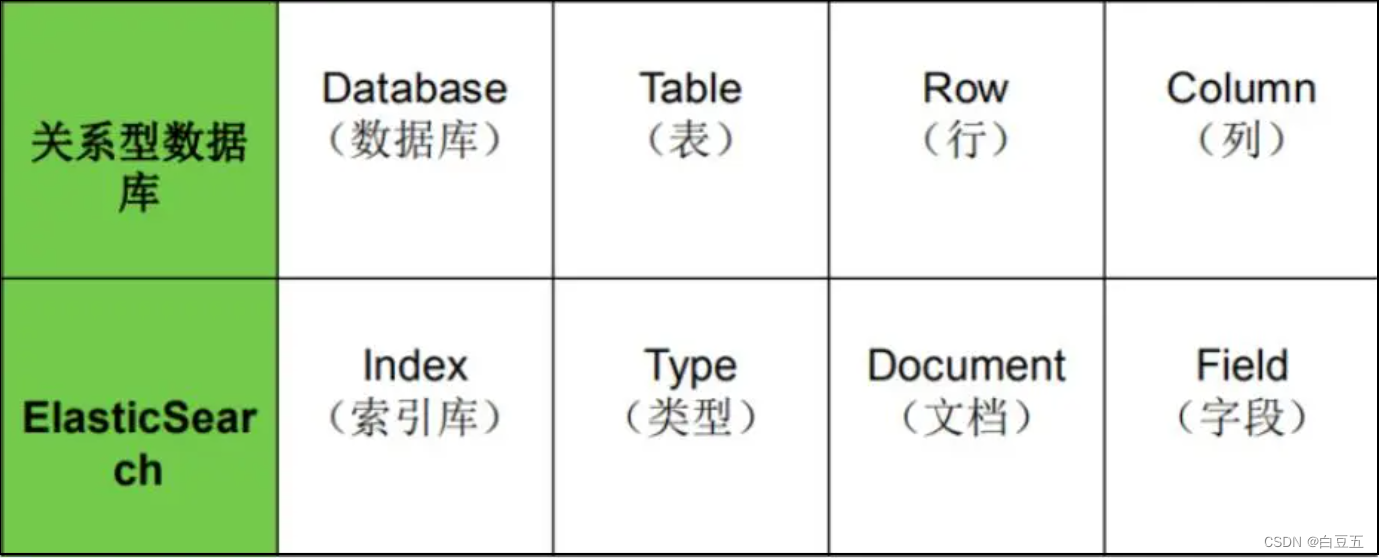
四、ES核心概念
ES和关系型数据库相关概念对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Database | Index | 索引库,类似mysql中的数据库 |
| Table | Type | 类型,就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{"name" : "John","sex" : "Male","age" : 25,"birthDate": "1990/05/01","about" : "I love to go rock climbing","interests": [ "sports", "music" ]
}
在一个索引库中,你可以定义一种或多种类型(文档集合)。
一个类型(Type)是索引的一个逻辑上的分类或分区,用于对文档进行组织和分类。每个索引可以包含多个类型,而每个类型又可以包含多个文档。类型的语义完全由你来定义,它可以代表不同的实体、数据类型或者业务逻辑。例如,如果你有一个名为 “products” 的索引,你可以定义不同的类型来表示不同种类的产品,如"electronics"、 “clothing”、"books"等。
通常,会为具有一组共同字段的文档定义一个类型。
不同版本的ES,类型会有一些变化:
| 版本 | Type |
|---|---|
| 5.x | 支持多种type |
| 6.x | 只能有一种type |
| 7.x | 默认不再支持自定义索引类型(默认类型为:_doc) |
五、ES基本操作(DSL)
1. DSL介绍
DSL(Domain Specific Language):领域专用语言,Elasticsearch提供了基于JSON的DSL来定义查询。
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/query-dsl.html
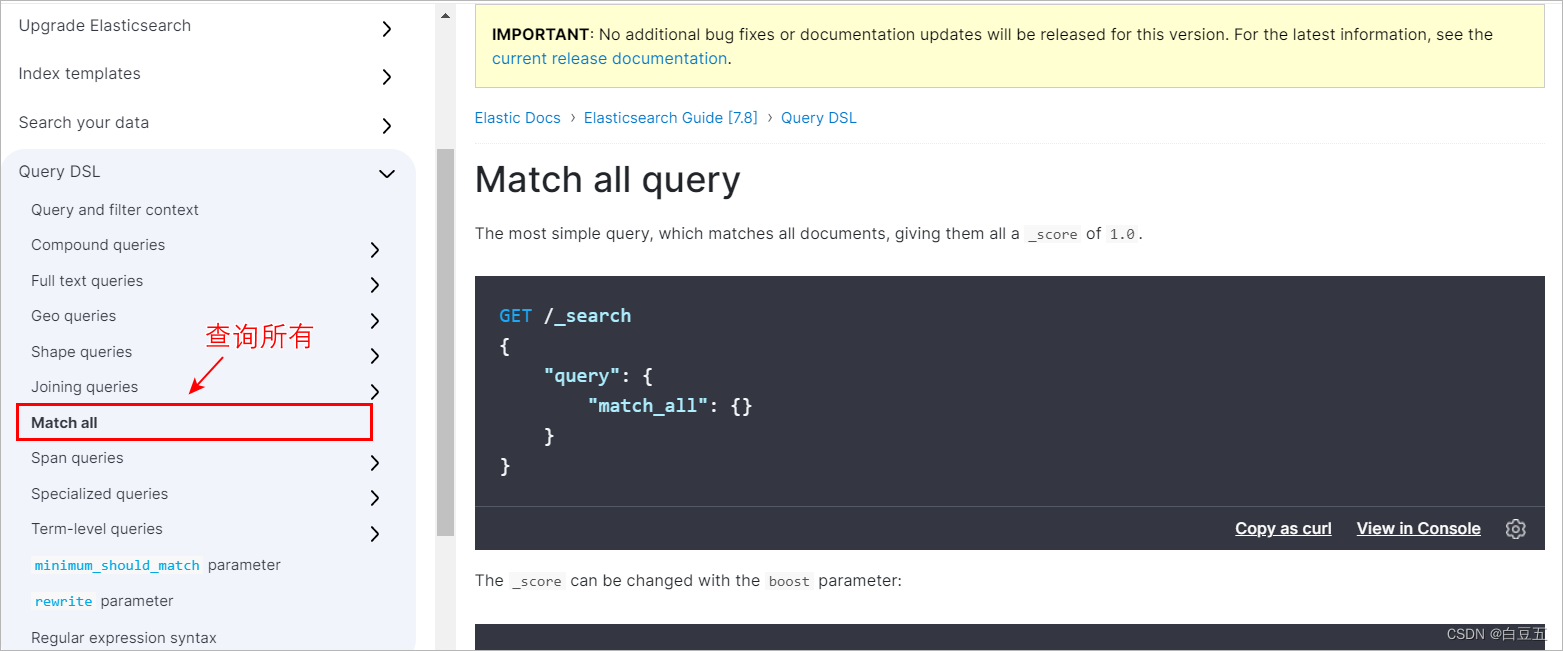
2. 索引库相关操作
2.1 创建索引库
语法: PUT /{索引名称}
PUT /my_index执行结果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my_index"
}

2.2 查看所有索引库
语法: GET /_cat/indices?v
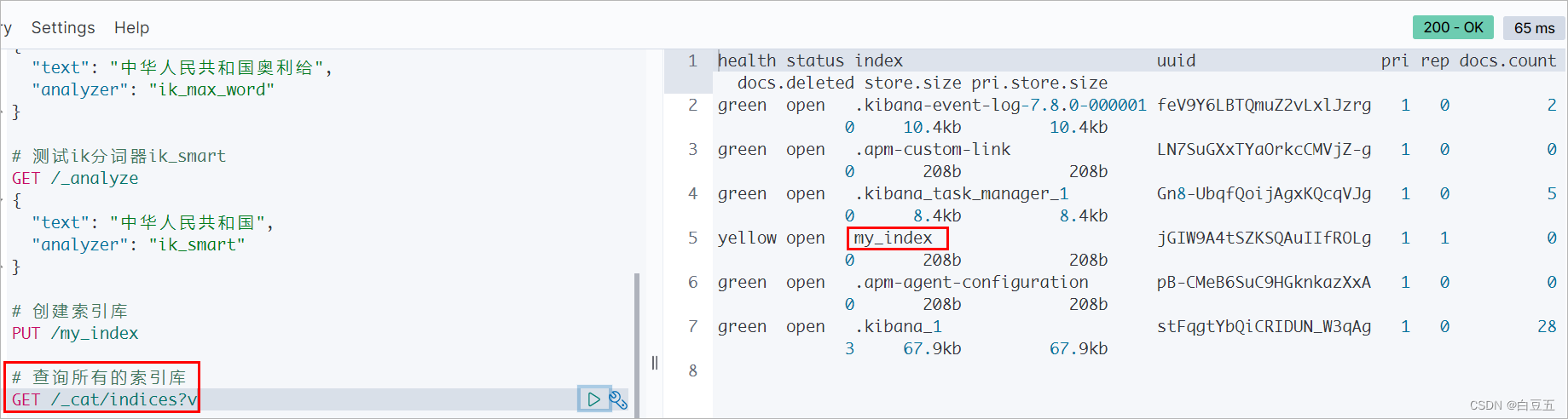
2.3 查看指定索引库
语法: GET /{索引名称}
GET /my_index执行结果:
{"my_index" : {"aliases" : { },"mappings" : { },"settings" : {"index" : {"creation_date" : "1633499968211","number_of_shards" : "1","number_of_replicas" : "1","uuid" : "bclHUdHrS4W80qxnj3NP0A","version" : {"created" : "7080099"},"provided_name" : "my_index"}}}
}
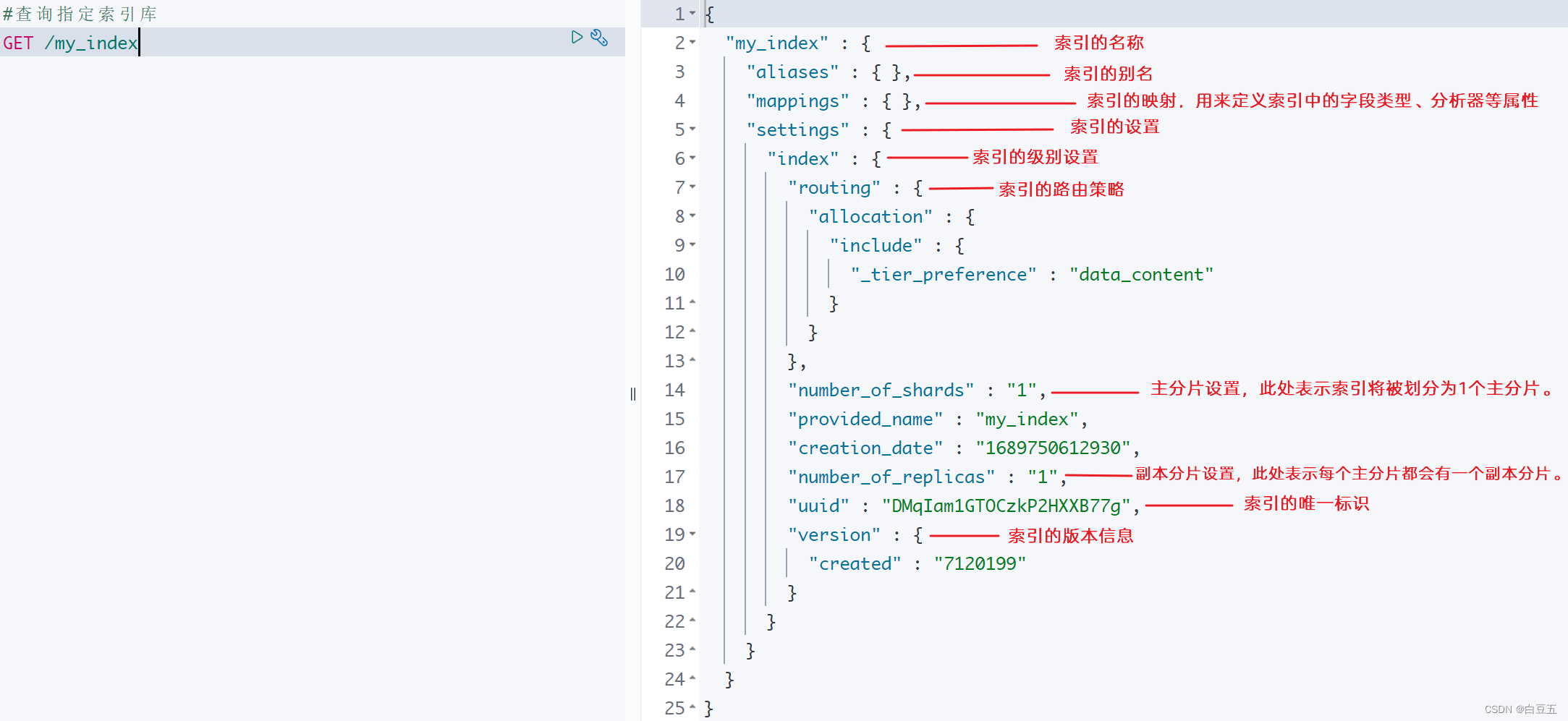
lasticsearch在默认情况下为每个索引创建了两个分片(一个主,一个备份),可以在创建索引库时指定分片个数。
2.4 删除索引库
语法: DELETE /{索引名称}
DELETE /my_index执行结果:
{"acknowledged" : true
}

小节:
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
3. 文档相关操作
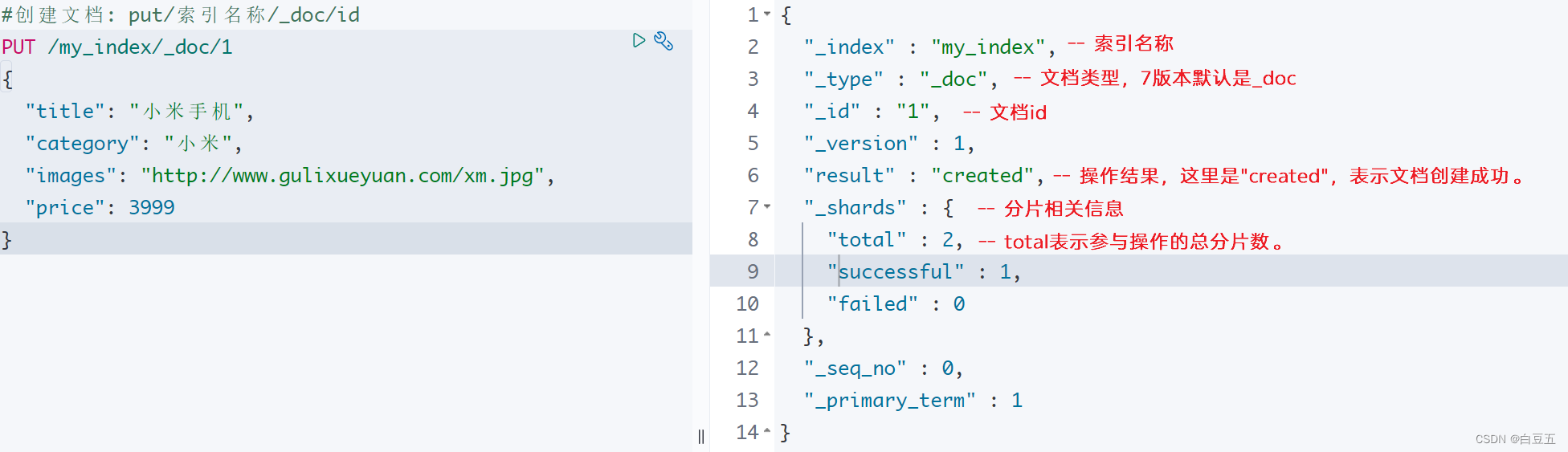
3.1 创建文档
语法格式如下:
PUT /{索引名称}/类型/{id}
{jsonbody
}
在ES7以后的版本中,关于类型使用默认的值:_doc
#创建文档
PUT /my_index/_doc/1
{"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999
}返回结果:
{"_index" : "my_index","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MghBptiu-1690304845291)(assets/image-20230719180214808.png)]
3.2 查询文档
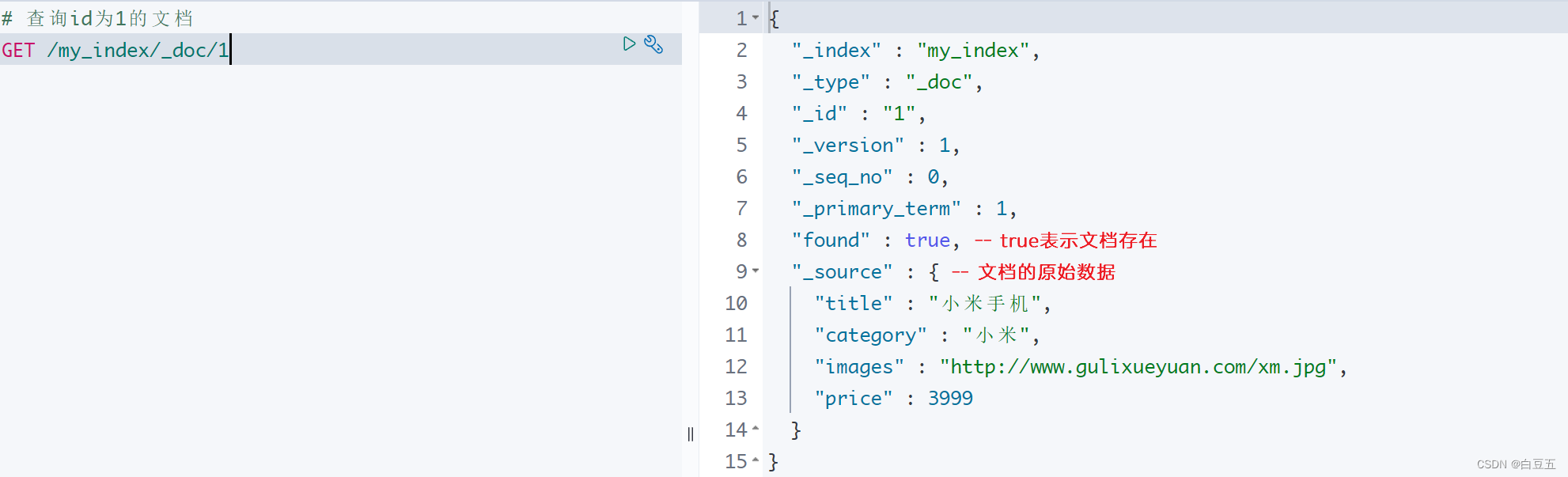
① 根据id查询索引库下的文档:GET /{索引名称}/{类型}/{id}
# 查询id为1的文档
GET /my_index/_doc/1返回结果:
{"_index" : "my_index","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"title" : "小米手机","category" : "小米","images" : "http://www.gulixueyuan.com/xm.jpg","price" : 3999}
}
② 查索引库下的全部文档:
GET /{索引库名}/_search
{"query":{"match_all":{}}
}
3.3 修改文档
语法格式如下:
PUT /{索引名称}/{类型}/{id}
{jsonbody
}
PUT /my_index/_doc/1
{"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg"
}
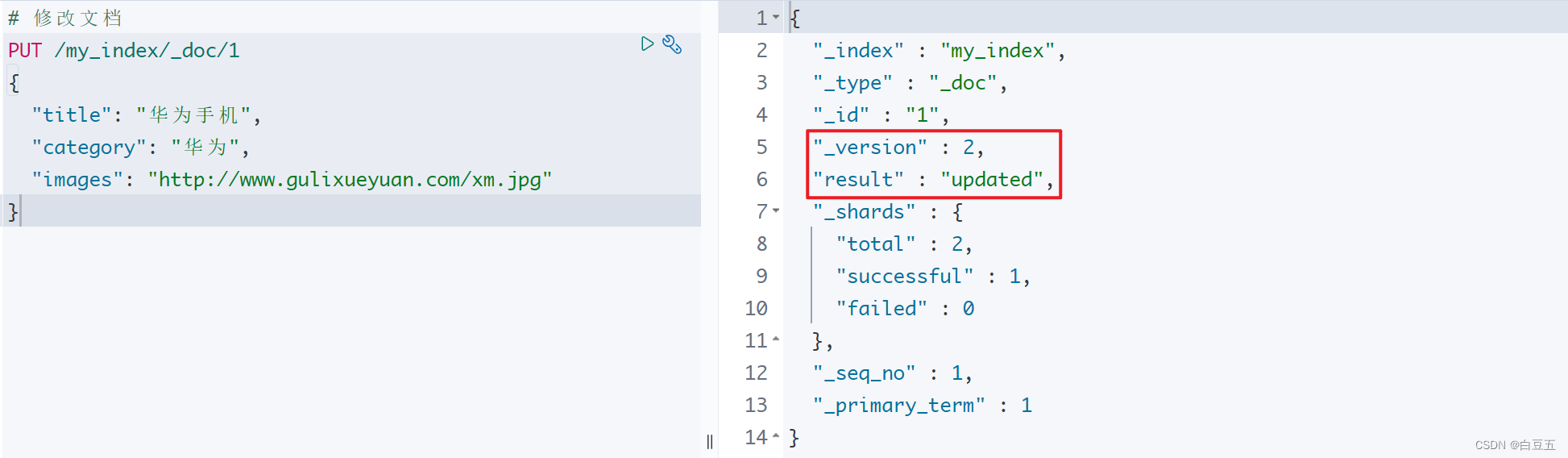
注意:修改文档是先根据id把文档删除掉,然后重新添加文档
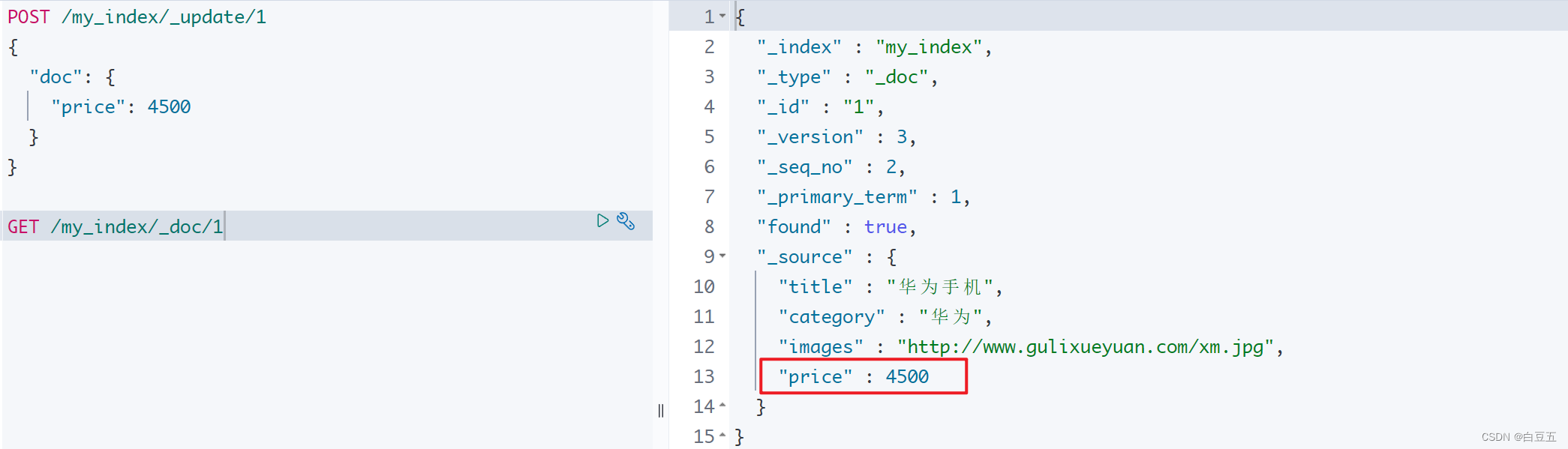
3.4 修改指定字段的值
语法格式如下: (注:这种更新只能使用post方式)
POST /{索引名称}/_update/{docId}
{"doc": {"属性": "值"}
}
示例:修改文档id为1的商品价格
POST /my_index/_update/1
{"doc": {"price": 4500}
}
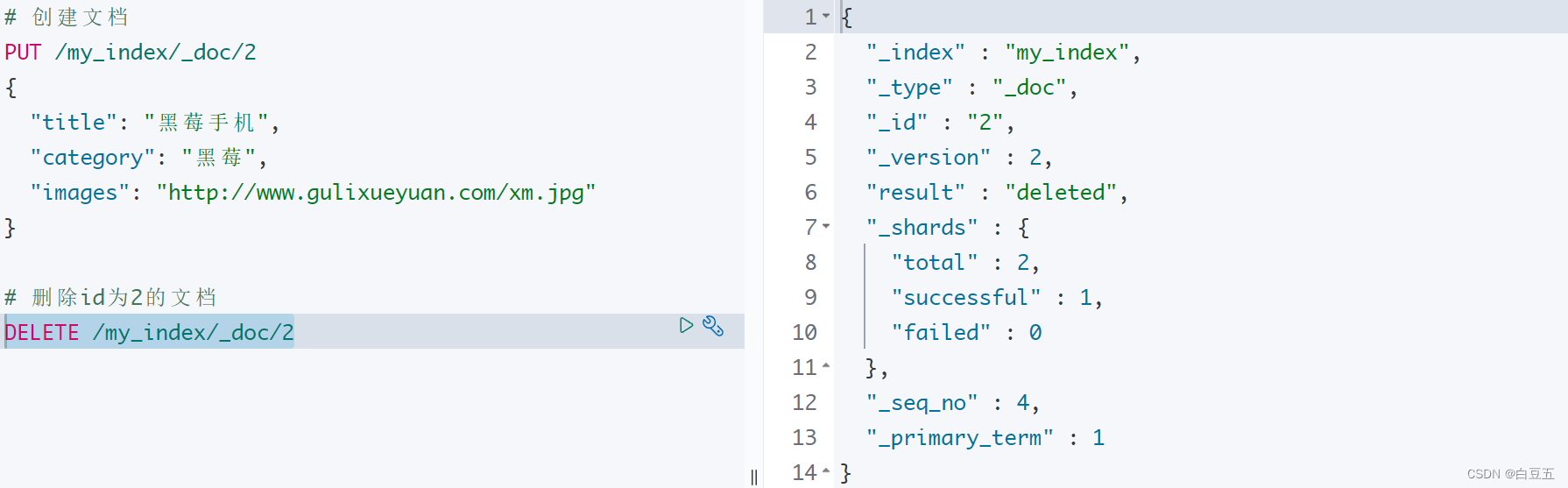
3.5 删除文档
语法: DELETE /{索引名称}/{类型}/{id}
# 创建文档
PUT /my_index/_doc/2
{"title": "黑莓手机","category": "黑莓","images": "http://www.gulixueyuan.com/xm.jpg"
}# 删除id为2的文档
DELETE /my_index/_doc/2
3.6 批量操作
通用语法:
POST
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}
actionName可以有CREATE、DELETE(批量添加or批量删除)等。
3.6.1 批量创建文档
POST _bulk
{"create":{"_index":"my_index","_id":2}}
{"id":2,"title":"华为手机","category":"华为","images":"http://www.gulixueyuan.com/xm.jpg","price":5500}
{"create":{"_index":"my_index","_id":3}}
{"id":3,"title":"VIVO手机","category":"vivo","images":"http://www.gulixueyuan.com/xm.jpg","price":3600}
3.6.2 批量删除文档
POST _bulk
{"delete":{"_index":"my_index","_id":2}}
{"delete":{"_index":"my_index","_id":3}}
小节:
- 创建文档:POST /{索引库名}/_doc/文档id { jsonbody}
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { jsonbody }
- 增量修改(修改指定字段的值):POST /{索引库名}/_update/文档id { “doc”: {字段}}
- 批量创建、删除文档
3.7 Mapping映射
在ES中,Mapping映射是用来定义索引库中文档的结构和字段类型。它类似于关系型数据库中的表结构定义,可以设置每个字段的数据类型、分词器、索引选项等。(Mapping映射更接近于定义表结构而不是整个数据库结构)
在ES中可以不用先定义Mapping映射(即关系型数据库的表、字段等),如果插入文档时没有事先定义Mapping映射,它会根据文档字段的值自动推断出字段的类型,并生成相应的映射。
3.7.1 查看映射
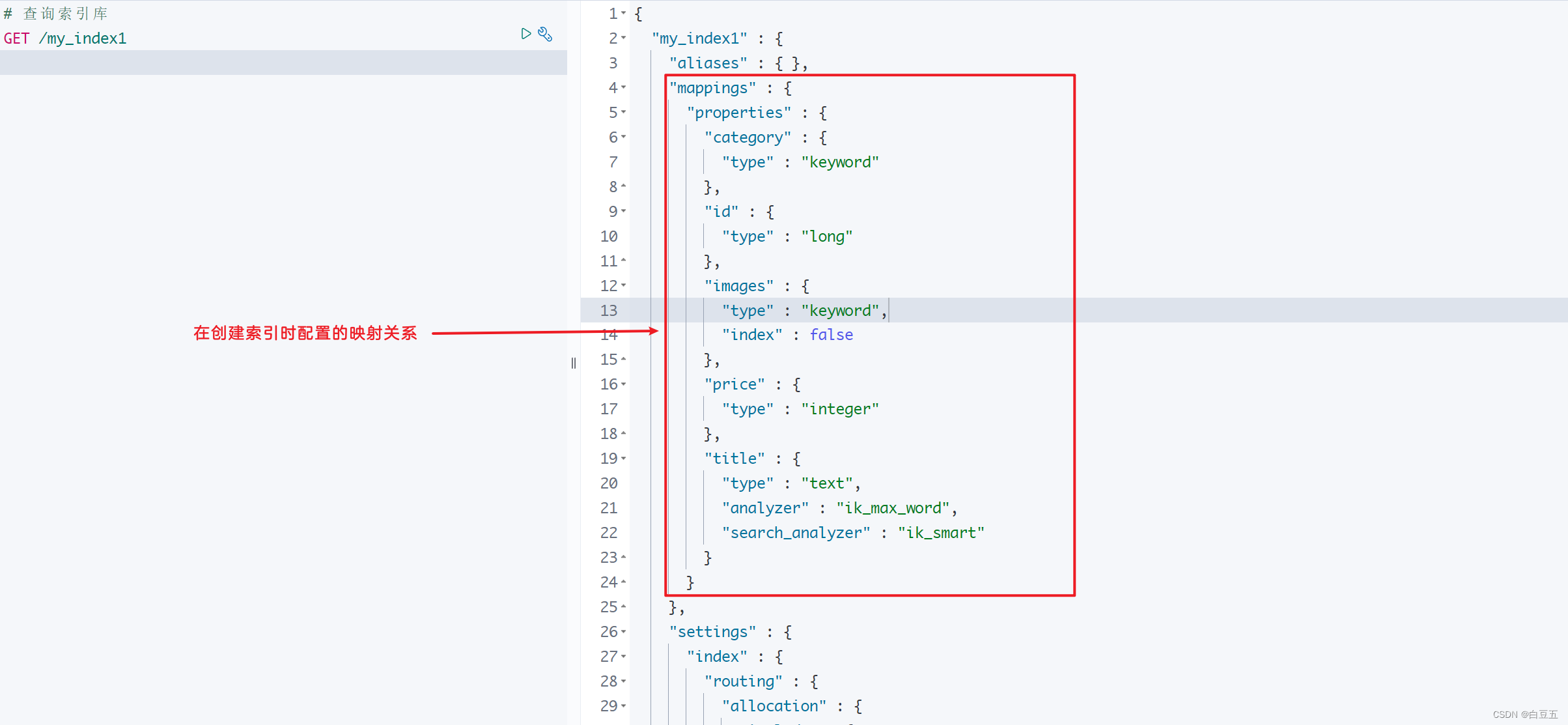
语法:GET /{索引库名称}/_mapping
GET /my_index/_mapping执行结果:
{"my_index" : {"mappings" : {"properties" : { "category" : { //字段名称"type" : "text", //字段类型},"id" : {"type" : "long"},"images" : {"type" : "text",},"price" : {"type" : "long"}}}}
}
3.7.2 Mapping映射的常见属性
mapping是对索引库中文档的约束,mapping的常见属性有:
- type:用于指定字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值, 例如:品牌、国家、ip地址,keyword不能分词)
- 数值:long、integer、short、byte、double、float、…
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否为字段创建索引(倒排索引),默认为true
- analyzer:为指定字段配置分词器
- search_analyzer:配置该字段在搜索的时候所使用的分词器(如果没有指定该分词器,那么搜索的时候使用analyzer所指定的分词器)
- properties:该字段的子字段
例如下面的json文档:
{"title": "海尔冰箱","category": "海尔","images": "http://www.haier.com/bx.jpg","price": 1999
}
对应的每个字段映射(mapping):
1、title:字符串类型(text,可以分词),需要索引(建立倒排索引提高查询效率)
2、category:字符串类型(keyword), 需要索引
3、images:字符串类型(keyword) , 不需要索引 (该字段只用于存储数据,不需要进行搜索)
4、price:integer类型, 需要索引
3.7.3 创建索引库和映射
静态映射:就是可以事先定义好的映射,即手动配置映射,包含文档的各个字段类型、分词器等属性。
在Elasticsearch中,一旦索引创建后,字段的映射是固定的,默认情况下是不可更改的。(注意:重新创建索引会数据丢失)
创建索引和映射语法如下:
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}
示例:创建索引库并配置字段映射
#创建索引库,并同时指定映射关系和分词器等属性
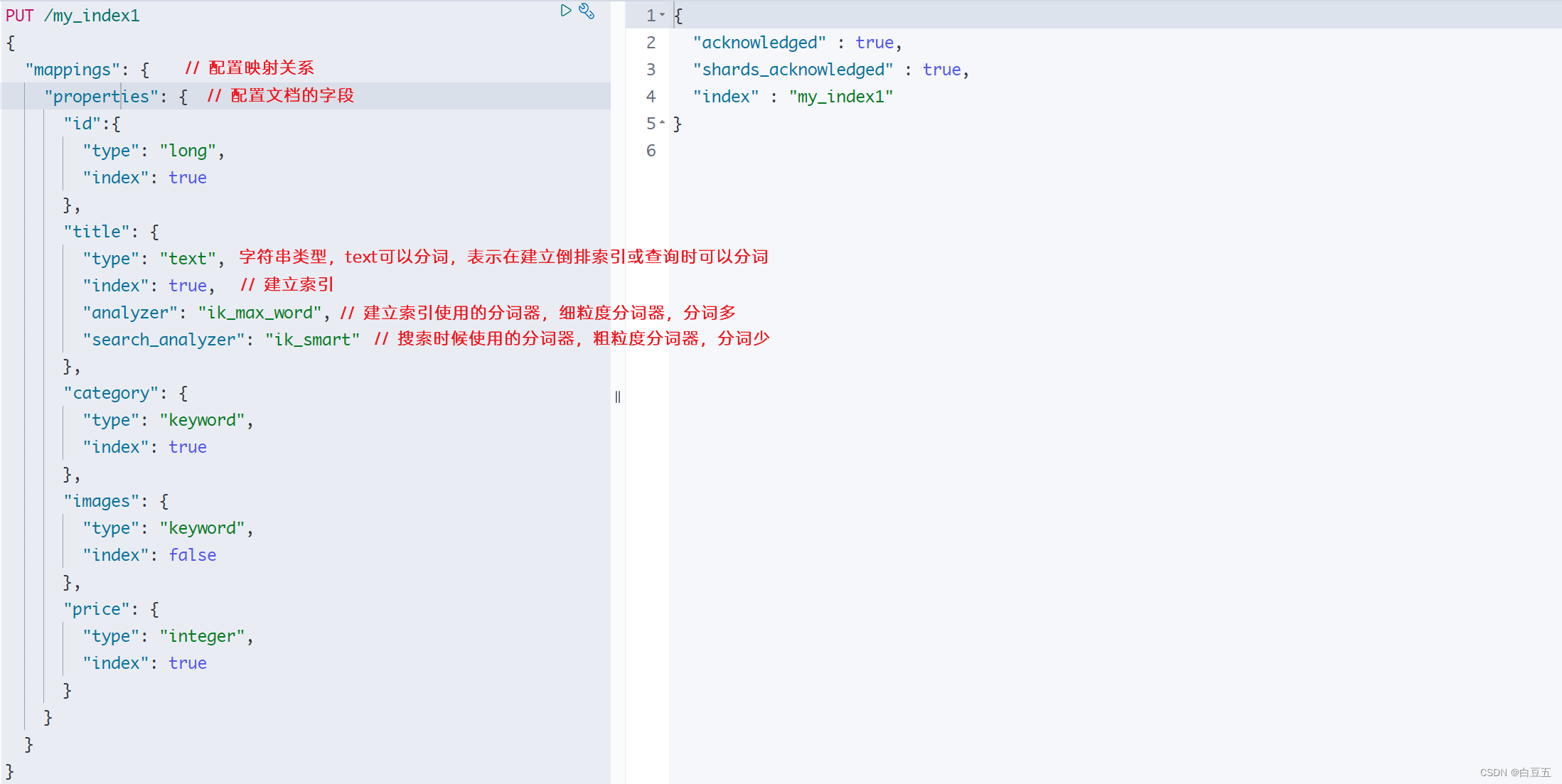
PUT /my_index1
{"mappings": { // 配置映射关系"properties": { // 配置文档的字段"id":{"type": "long","index": true},"title": {"type": "text","index": true, // 建立索引"analyzer": "ik_max_word", //建立索引使用的分词器"search_analyzer": "ik_smart" },"category": {"type": "keyword","index": true},"images": {"type": "keyword","index": false},"price": {"type": "integer","index": true}}}
}返回结果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "my_index"
}
查看索引库:
小节:
- 查看映射:GET /索引库名/_mapping
- 创建索引并指定映射(定义表结构):PUT /索引库名{mappings->properties->filed}
六、ES高级查询(DSL)
DSL查询文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.12/query-dsl.html
准备数据:
# 创建索引库,并配置mapping映射
PUT /product
{"mappings": {"properties": {"id":{"type": "long","index": true},"title": {"type": "text","index": true,"analyzer": "ik_max_word","search_analyzer": "ik_smart"},"category": {"type": "keyword","index": true},"images": {"type": "keyword","index": false},"price": {"type": "integer","index": true}}}
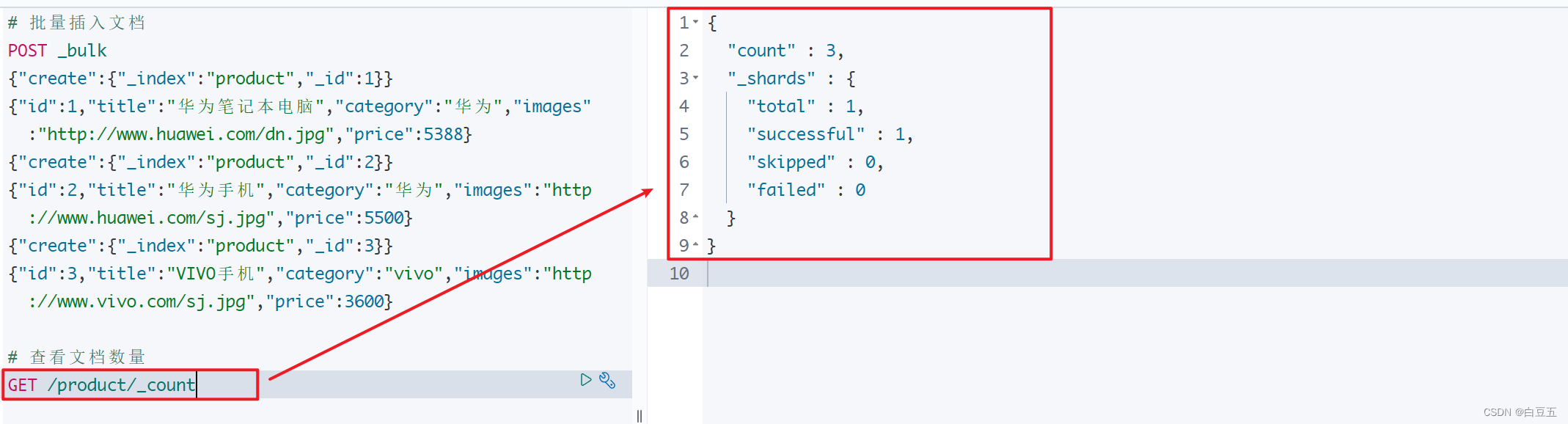
}# 批量插入文档
POST _bulk
{"create":{"_index":"product","_id":1}}
{"id":1,"title":"华为笔记本电脑","category":"华为","images":"http://www.huawei.com/dn.jpg","price":5388}
{"create":{"_index":"product","_id":2}}
{"id":2,"title":"华为手机","category":"华为","images":"http://www.huawei.com/sj.jpg","price":5500}
{"create":{"_index":"product","_id":3}}
{"id":3,"title":"VIVO手机","category":"vivo","images":"http://www.vivo.com/sj.jpg","price":3600}
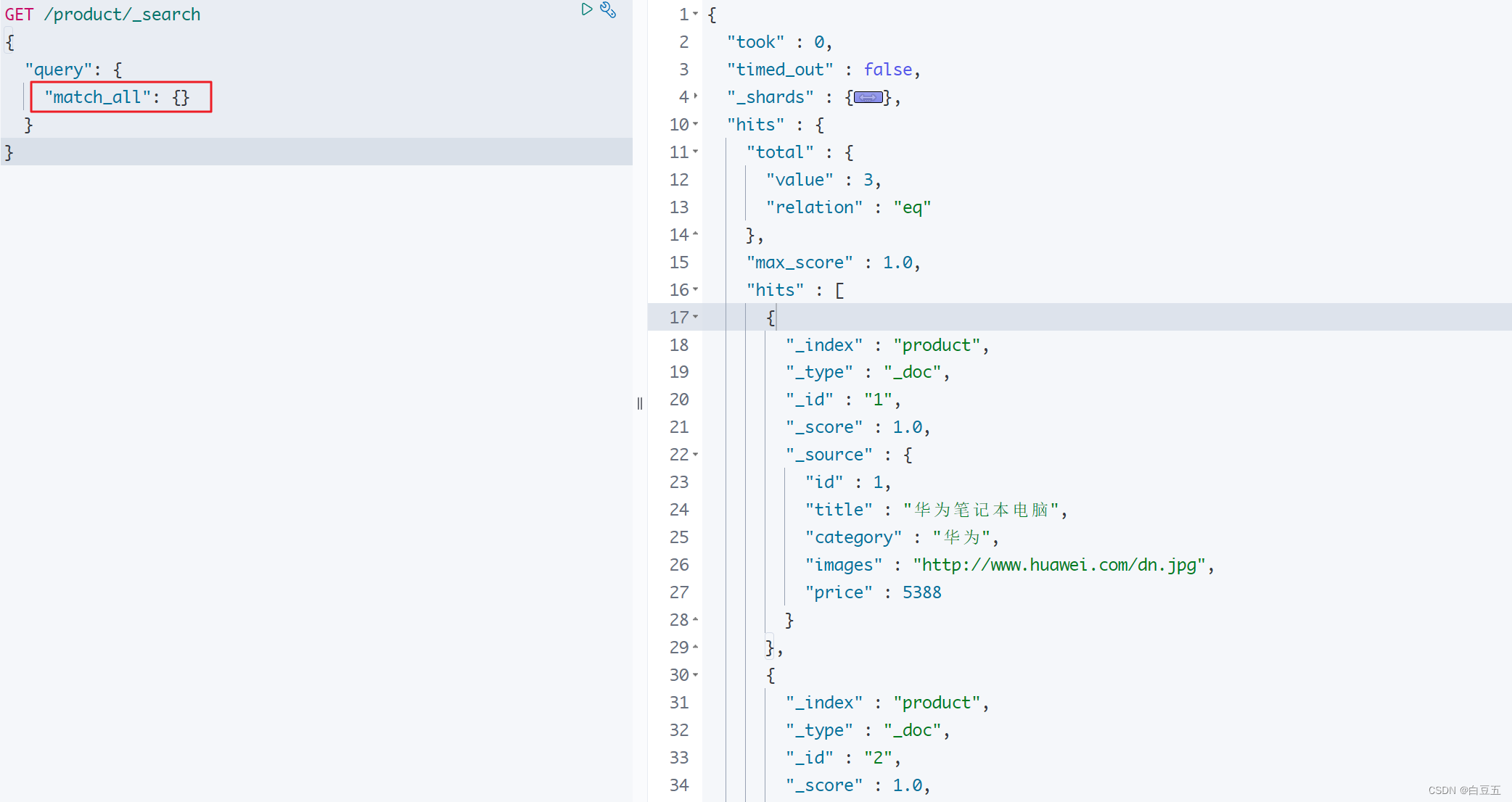
1. 查询所有(match_all)
match_all :表示查询所有文档,一般测试用。(无条件查询,类似 select * from table)
GET /product/_search
{"query": {"match_all": {}}
}
2. 匹配查询(match)
match:它可以根据指定的字段和搜索词进行匹配查询。(单字段)
match查询会对搜索的关键词进行分词处理,然后将各个词条从对应的倒排索引表中进行匹配。
match查询语法如下:
GET /{索引名称}/_search
{"query": {"match": {"FIELD": "TEXT"}}
}
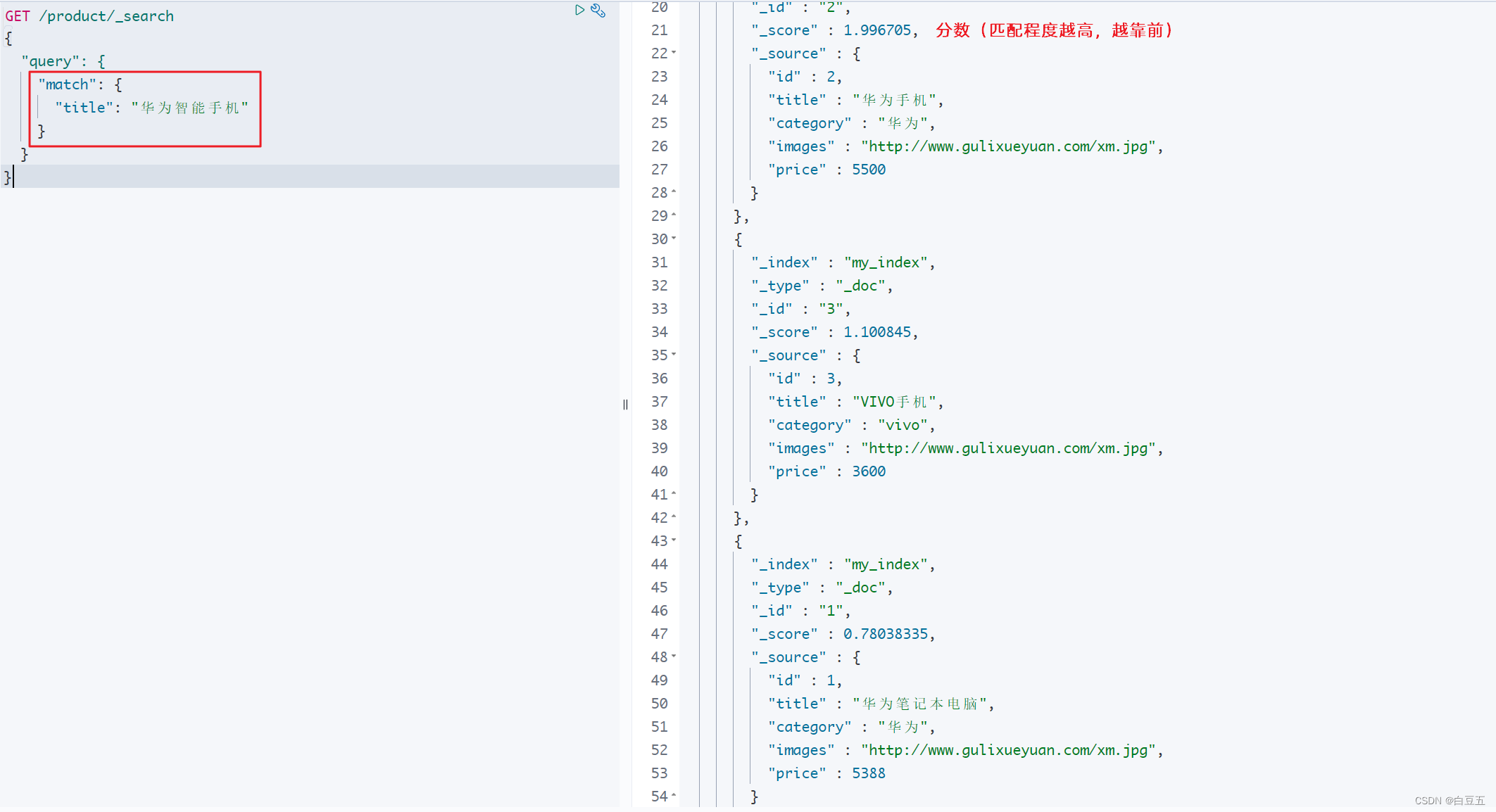
示例:全文检索title字段
GET /product/_search
{"query": {"match": {"title": "华为智能手机" # 会对搜索的关键字进行分词,然后将各个词条从对应的倒排索引表中进行搜索}}
}
对搜索关键字进行分词:华为,智能手机,智能,能手,手机。然后根据字段title的倒排索引表中进行匹配。
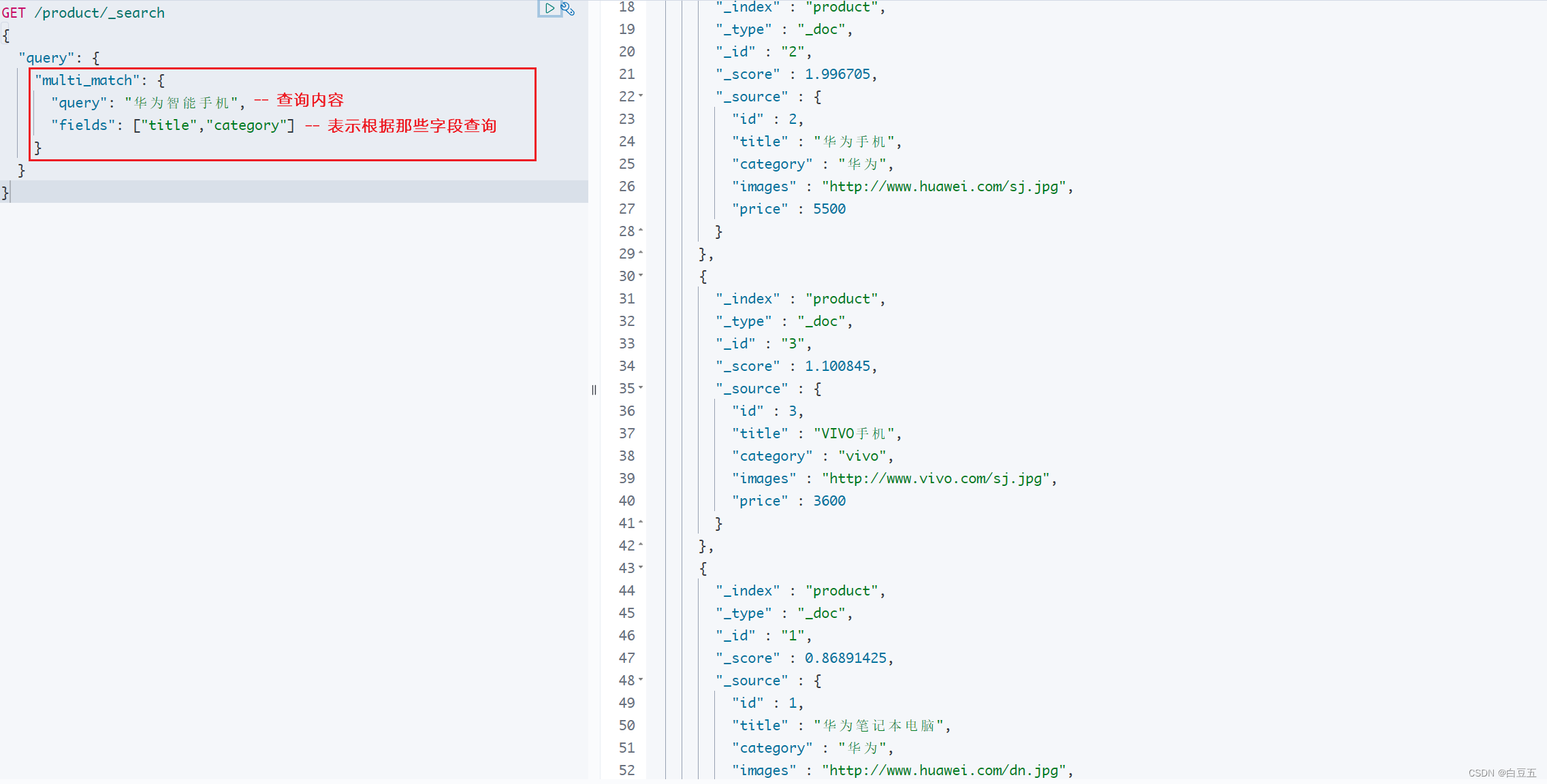
3. 多字段匹配(multi_match)
multi_match多字段匹配语法如下:
GET /{索引名称}/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["FIELD1", " FIELD12"]}}
}
示例:
GET /product/_search
{"query": {"multi_match": {"query": "华为智能手机","fields": ["title","category"]}}
}
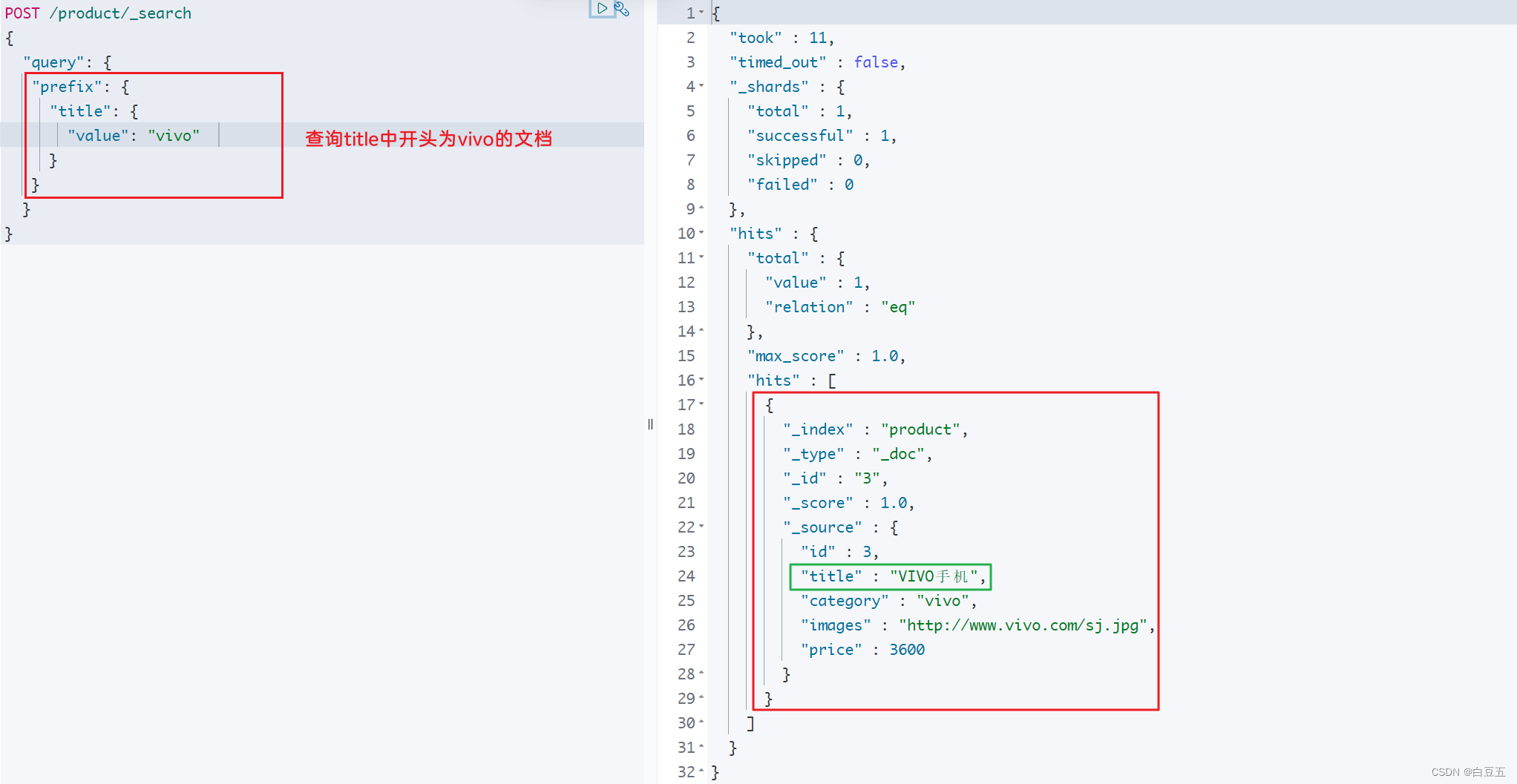
4. 前缀匹配(prefix)
prefix前缀匹配语法如下:
GET /{索引名称}/_search
{"query": {"prefix": {"FIELD": {"value": "指定前缀"}}}
}
示例:查询字段title中以vivo开头的文档:(类似mysql中的 like ‘vivo%’)
GET /product/_search
{"query": {"prefix": {"title": {"value": "vivo" // 小写查询,大写无结果}}}
}返回结果:
{"took" : 11,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"id" : 3,"title" : "VIVO手机","category" : "vivo","images" : "http://www.vivo.com/sj.jpg","price" : 3600}}]}
}
5. 关键字精确查询(term)
因为精确查询的字段是不分词的(keyword),因此查询的条件也必须是不分词的词条。
精确查询要求输入的内容与字段的值完全一致才能匹配成功。如果用户输入的内容过多或与字段的值不完全一致,可能导致无法找到匹配的数据。
term查询语法如下:
GET /{索引名称}/_search
{"query": {"term": {"FIELD": {"value": "VALUE"}}}
}
示例1:根据title字段做精确查询
GET /product/_search
{"query": {"term": {"title": {"value": "华为手机"}}}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sqIcuiPA-1690304845296)(assets/image-20230721165258197.png)]
示例2:根据category字段做精确查询
GET /product/_search
{"query": {"term": {"category": {"value": "华为"}}}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2uOvLhE1-1690304845296)(assets/image-20230722142451229.png)]
6. 多个关键字精确查询(terms)
terms 查询用于匹配多个关键字。我们使用 terms查询来匹配字段 field 的值是否与给定数组中的任何一个值相匹配。如果有匹配的文档,它们将被返回。
terms查询语法如下:
GET /{索引名称}/_search
{"query": {"term": {"FIELD":[value1,value2]}}
}
示例:根据title字段多个关键字精确查询 华为手机,华为
GET /product/_search
{"query": {"terms": {"title": ["华为手机","华为"]}}
}返回结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"id" : 1,"title" : "华为笔记本电脑","category" : "华为","images" : "http://www.huawei.com/dn.jpg","price" : 5388}},{"_index" : "product","_type" : "_doc","_id" : "2","_score" : 1.0,"_source" : {"id" : 2,"title" : "华为手机","category" : "华为","images" : "http://www.huawei.com/sj.jpg","price" : 5500}}]}
}
7. 范围查询(range)
通过range查询限定字段查询的范围:
- gte: 大于等于
- lte: 小于等于
- gt: 大于
- lt: 小于
range查询语法如下:
GET /{indexName}/_search
{"query": {"range": {"FIELD": {//范围条件"xxx":value}}}
}
示例:查询价格为3000到5000的产品
GET /product/_search
{"query": {"range": {"price": {"gte": 3000,"lte": 5000}}}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cc01b8xJ-1690304845296)(assets/image-20230722172425023.png)]
8 返回指定字段(_source)
通过_source属性来指定需要返回的字段。 它的位置与query属性平级。
返回指定字段语法:
GET /{索引库名称}/_search
{"query": {},"_source": ["field1","field2"]
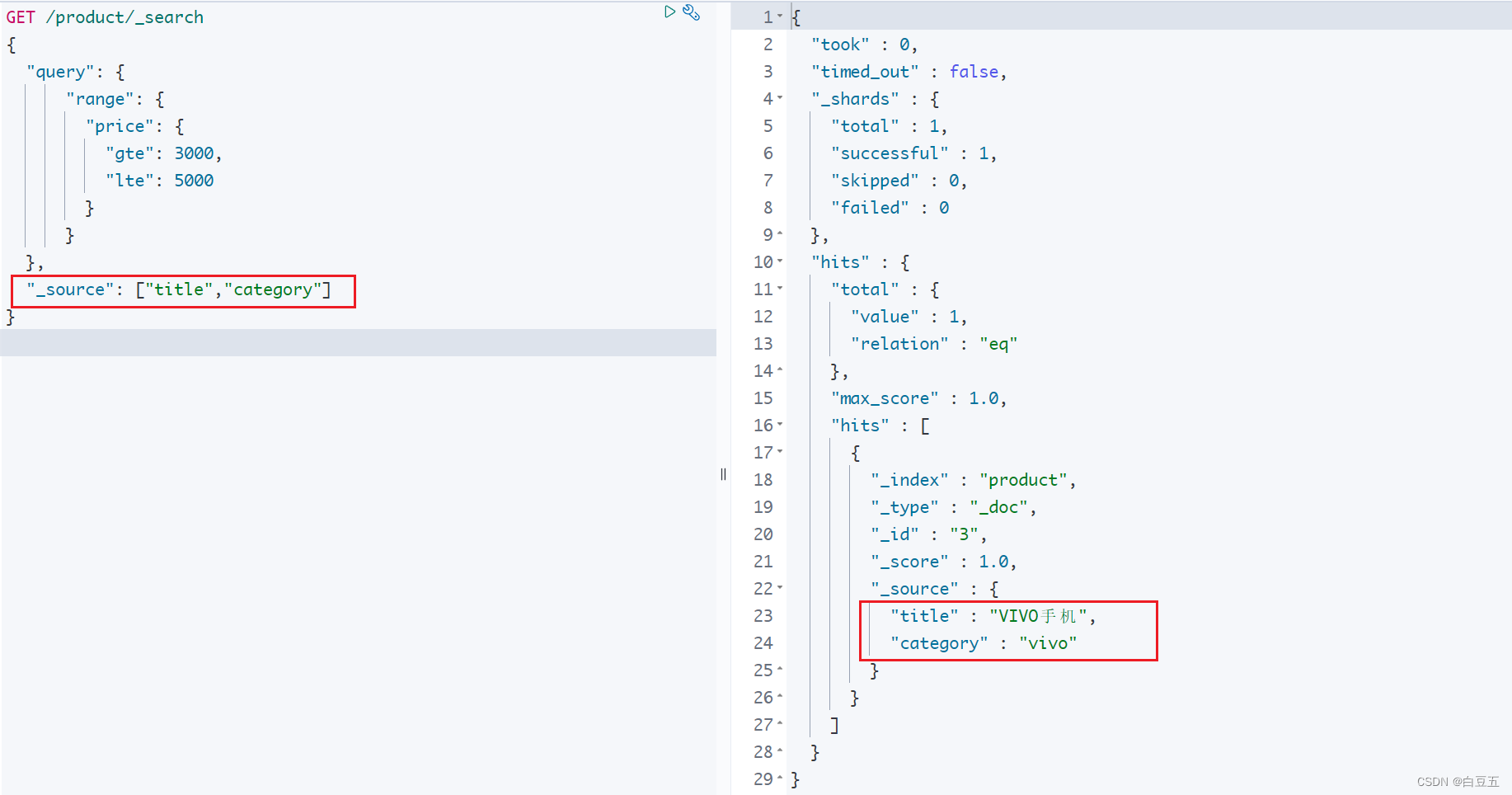
}示例:返回title和category字段数据(类似 select title,category from product where price between 3000 and 5000 )
GET /product/_search
{"query": {"range": {"price": {"gte": 3000,"lte": 5000}}},"_source": ["title","category"]
}
9. 组合查询(bool)
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。
以下是对四种布尔操作符的总结:(他们之间可以组合使用)
must: 所有条件都必须满足,即它们之间是 “与”(AND)关系。(会相关性算分)should: 至少有一个条件满足即可,即它们之间是 “或”(OR)关系。must_not: 所有条件都不能满足,即它们之间是 “非”(NOT)关系。filter: 该操作符和must的效果相同,但它不计算得分,仅用于过滤文档,因此效率更高。
示例:
GET /my_index/_search
{"query": {"bool": {"must": [{ "term": { "field1": "value1" } },{ "range": { "field2": { "gte": 10, "lte": 20 } } }],"should": [{ "term": { "field3": "value3" } },{ "term": { "field4": "value4" } }],"must_not": [{ "term": { "field5": "value5" } }],"filter": [{ "term": { "field6": "value6" } }]}}
}
在上面的示例中,must 布尔子句指定了字段 field1 的值必须是 “value1”,并且字段 field2 的值必须在 10 到 20 之间。
should 布尔子句指定了字段 field3 的值应该是 “value3”,或者字段 field4 的值应该是 “value4”,其中满足任意一个条件即可。
must_not 布尔子句指定了字段 field5 的值不能是 “value5”。
filter 布尔子句是一个与 must 相同的过滤条件,它也要求字段 field6 的值必须是 “value6”,但它不计算得分。
9.1 must(并且)
在ES中,你可以使用must关键字来表示查询条件的与操作。must子句中的所有条件都必须满足才能匹配文档。
语法如下:
GET /{索引库名称}/_search
{"query": {"bool": {"must": [{ 查询条件1 },{ 查询条件2}]}}
}
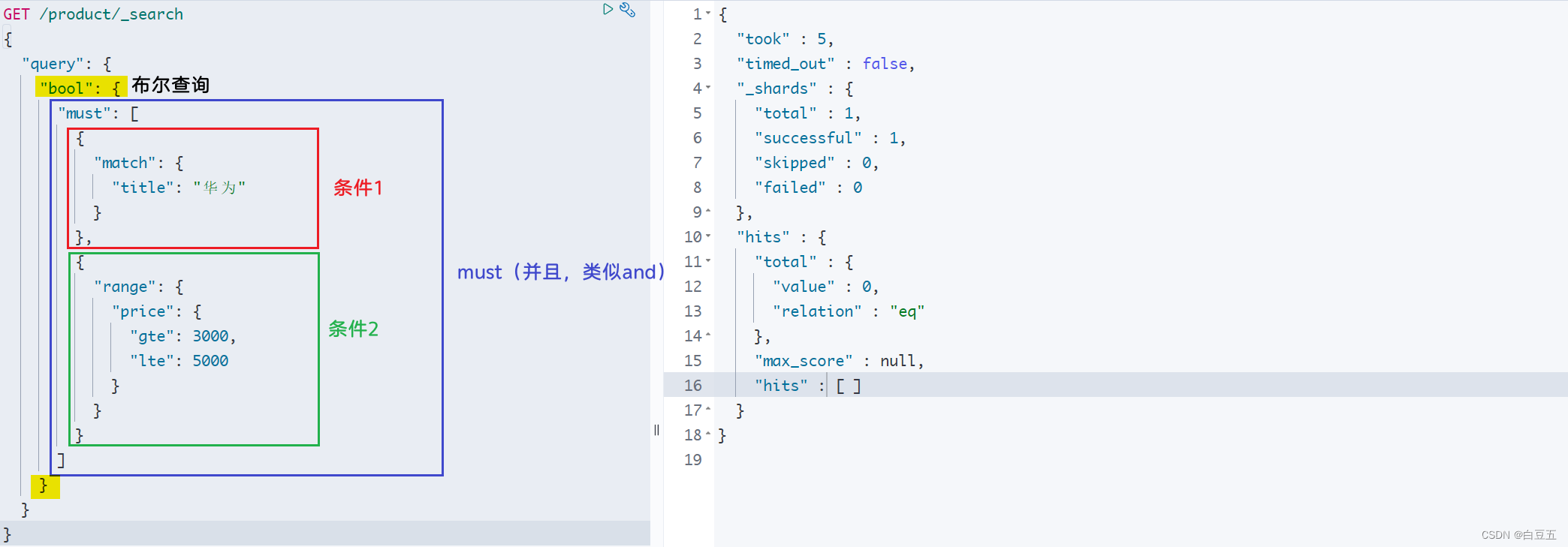
示例:布尔查询title字段包含华为,并且价格在[3000, 5000]之间的数据
GET /product/_search
{"query": {"bool": {"must": [{"match": {"title": "华为"}},{"range": {"price": {"gte": 3000,"lte": 5000}}}]}}
}
9.2 should(或者)
示例:布尔查询title字段包含华为,或者价格在[3000, 5000]之间的数据
GET /product/_search
{"query": {"bool": {"should": [{"match": {"title": "华为"}},{"range": {"price": {"gte": 3000,"lte": 5000}}}]}}
}返回结果:
{"took" : 3,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 3,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"id" : 3,"title" : "VIVO手机","category" : "vivo","images" : "http://www.vivo.com/sj.jpg","price" : 3600}},{"_index" : "product","_type" : "_doc","_id" : "2","_score" : 0.5619608,"_source" : {"id" : 2,"title" : "华为手机","category" : "华为","images" : "http://www.huawei.com/sj.jpg","price" : 5500}},{"_index" : "product","_type" : "_doc","_id" : "1","_score" : 0.35411233,"_source" : {"id" : 1,"title" : "华为笔记本电脑","category" : "华为","images" : "http://www.huawei.com/dn.jpg","price" : 5388}}]}
}
9.3 must_not(非)
must_not:必须不匹配,不参与算分,类似“非”。
需求:布尔查询title字段不包含华为,并且价格在不在[2000, 3000]之间的数据
GET /product/_search
{"query": {"bool": {"must_not": [{"match": {"title": "华为"}},{"range": {"price": {"gte": 2000,"lte": 3000}}}]}}
}返回结果:
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "3","_score" : 0.0,"_source" : {"id" : 3,"title" : "VIVO手机","category" : "vivo","images" : "http://www.vivo.com/sj.jpg","price" : 3600}}]}
}
9.4 filter
filter: 与must的效果相同(and),但它不计算得分,仅用于过滤文档,因此效率更高。(计算得分会影响查询性能)
_score的分值为0
GET /product/_search
{"query": {"bool": {"filter": [{"match": {"title": "华为"}}]}}
}返回结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "product","_type" : "_doc","_id" : "1","_score" : 0.0,"_source" : {"id" : 1,"title" : "华为笔记本电脑","category" : "华为","images" : "http://www.huawei.com/dn.jpg","price" : 5388}},{"_index" : "product","_type" : "_doc","_id" : "2","_score" : 0.0,"_source" : {"id" : 2,"title" : "华为手机","category" : "华为","images" : "http://www.huawei.com/sj.jpg","price" : 5500}}]}
}
10. 聚合查询(aggs)
Elasticsearch的聚合查询是一种强大的功能,可以对文档进行统计分析和数据聚合。聚合查询可以帮助你从大量的数据中提取有用的信息和洞察。它提供了许多不同类型的聚合,可以用于计算最大值、最小值、平均值、求和等等。
以下是一些常见的聚合类型:
avg:计算一个字段的平均值。sum:计算一个字段的总和。min:找到一个字段的最小值。max:找到一个字段的最大值。cardinality:计数一个字段的唯一值数量。stats:计算一个字段的统计数据,包括最小值、最大值、平均值和总和。extended_stats:在stats的基础上,还提供方差、标准差和其他分位数等更详细的统计数据。percentiles:计算一个字段的百分位数。bucket(桶)聚合:将文档分组为不同的桶,并对每个桶内的文档应用其他聚合函数。
10.1 max
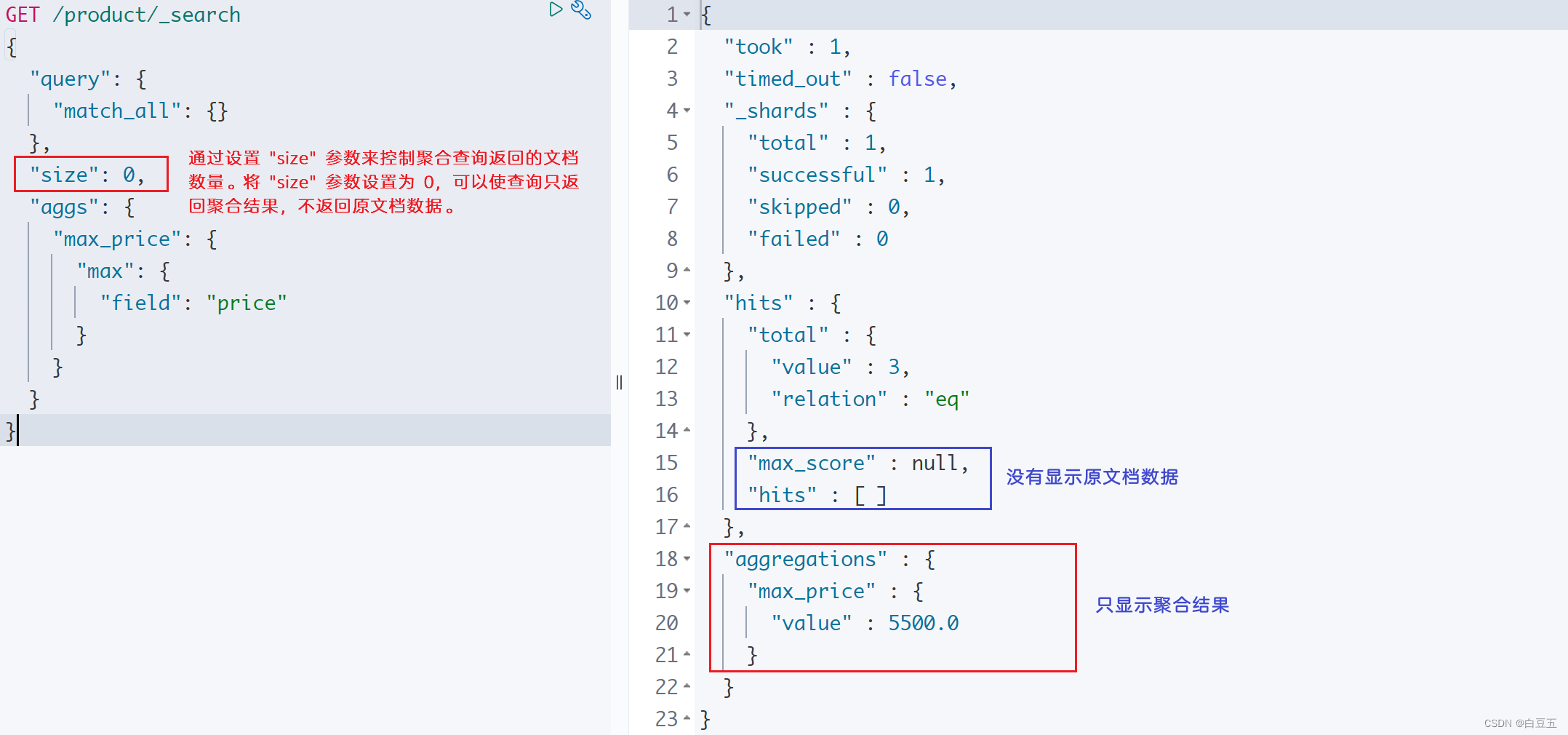
示例:计算 price字段的最大值。
GET /product/_search
{"query": {"match_all": {}},"aggs": {"max_price": { //给聚合结果指定一个名字"max": {"field": "price"}}}
}

上面查询的结果携带着原始文档数据,我们可以通过设置 "size" 参数来控制聚合查询返回的文档数量。将 "size" 参数设置为 0,可以使查询只返回聚合结果,不返回原文档数据。(如果size为100,则表示返回前100个原文档)
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"max_price": {"max": {"field": "price"}}}
}
10.2 min
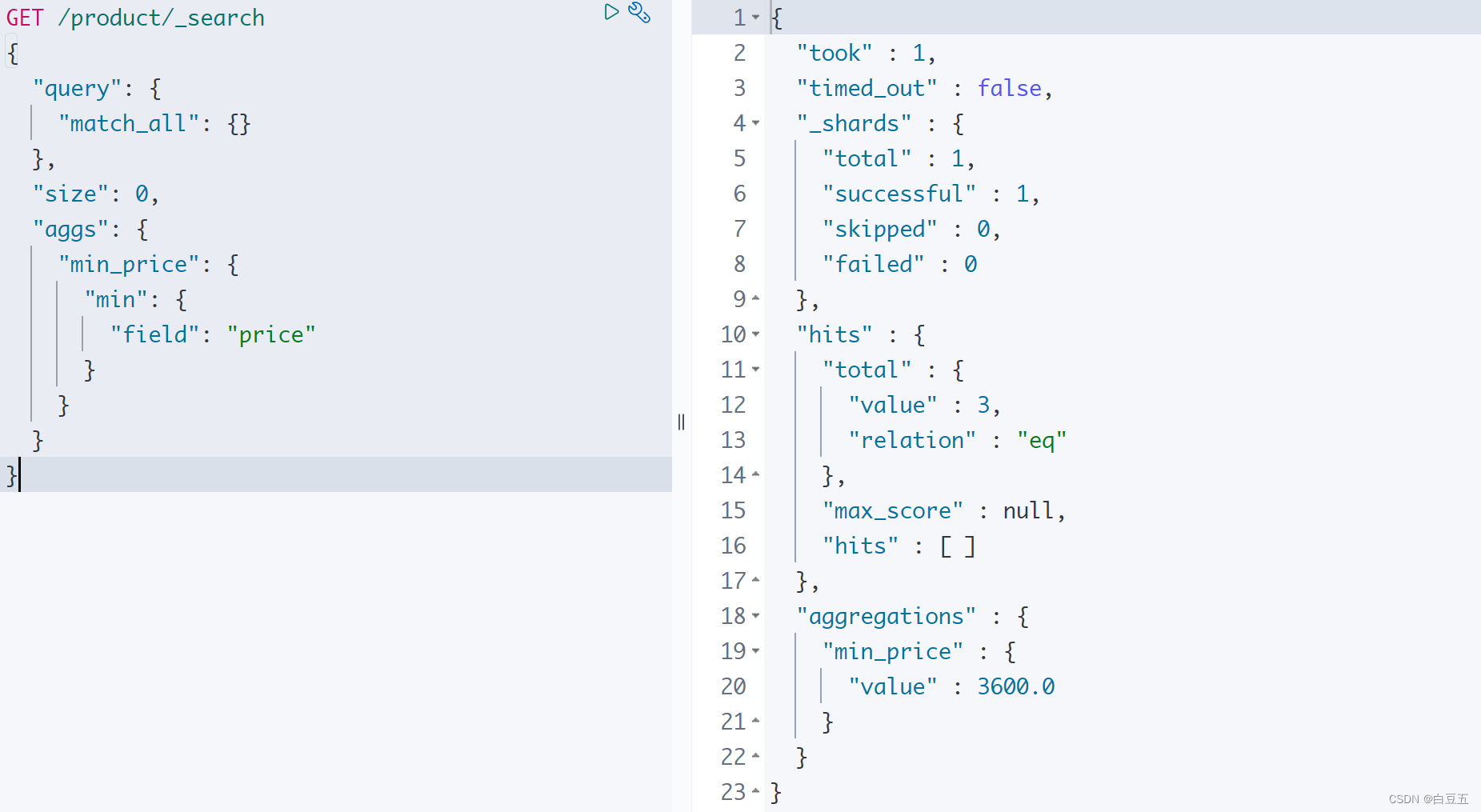
示例:计算 price字段的最小值。
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"min_price": {"min": {"field": "price"}}}
}
10.3 avg
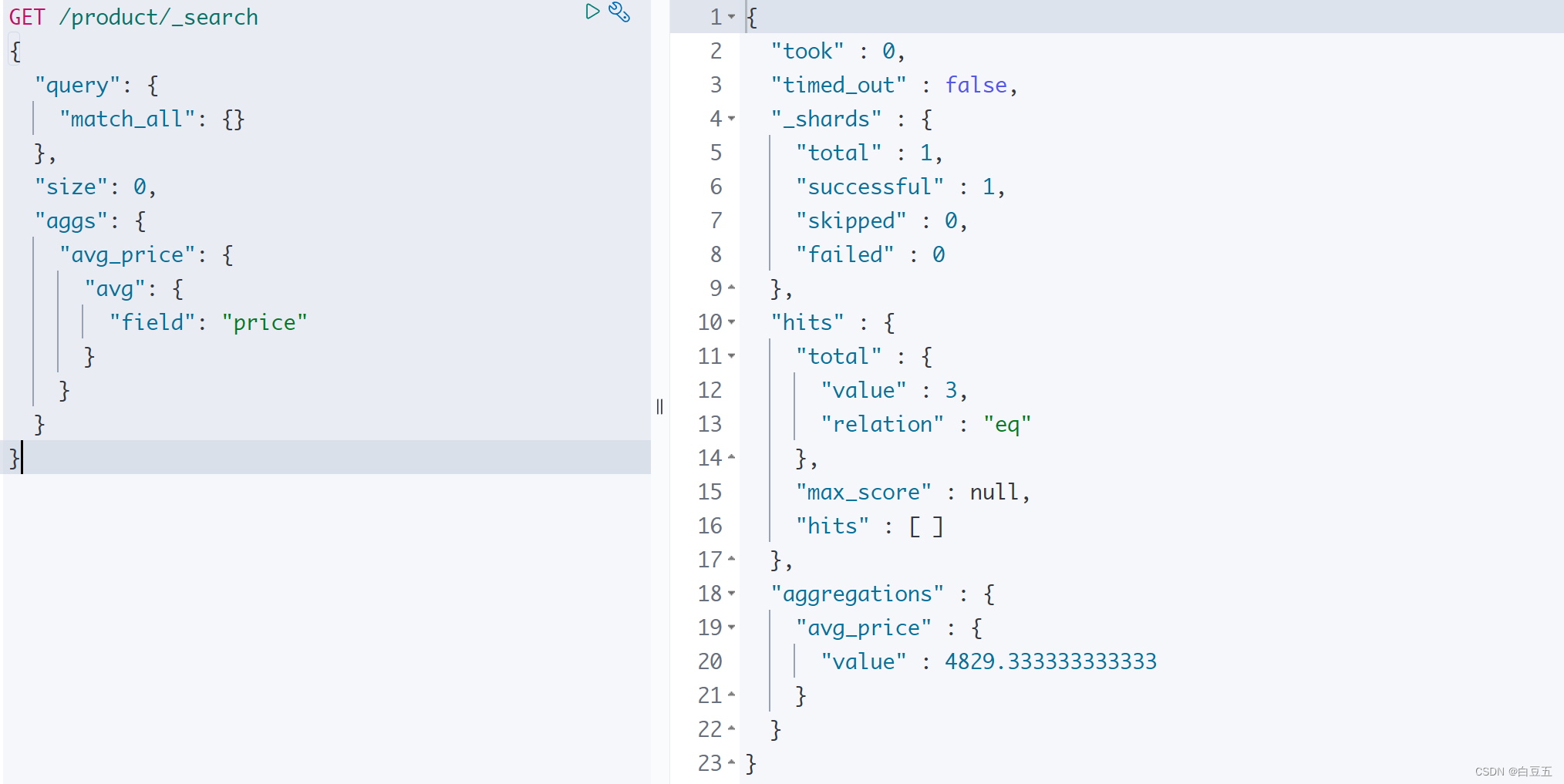
示例:计算 price字段的平均值。
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"avg_price": {"avg": {"field": "price"}}}
}
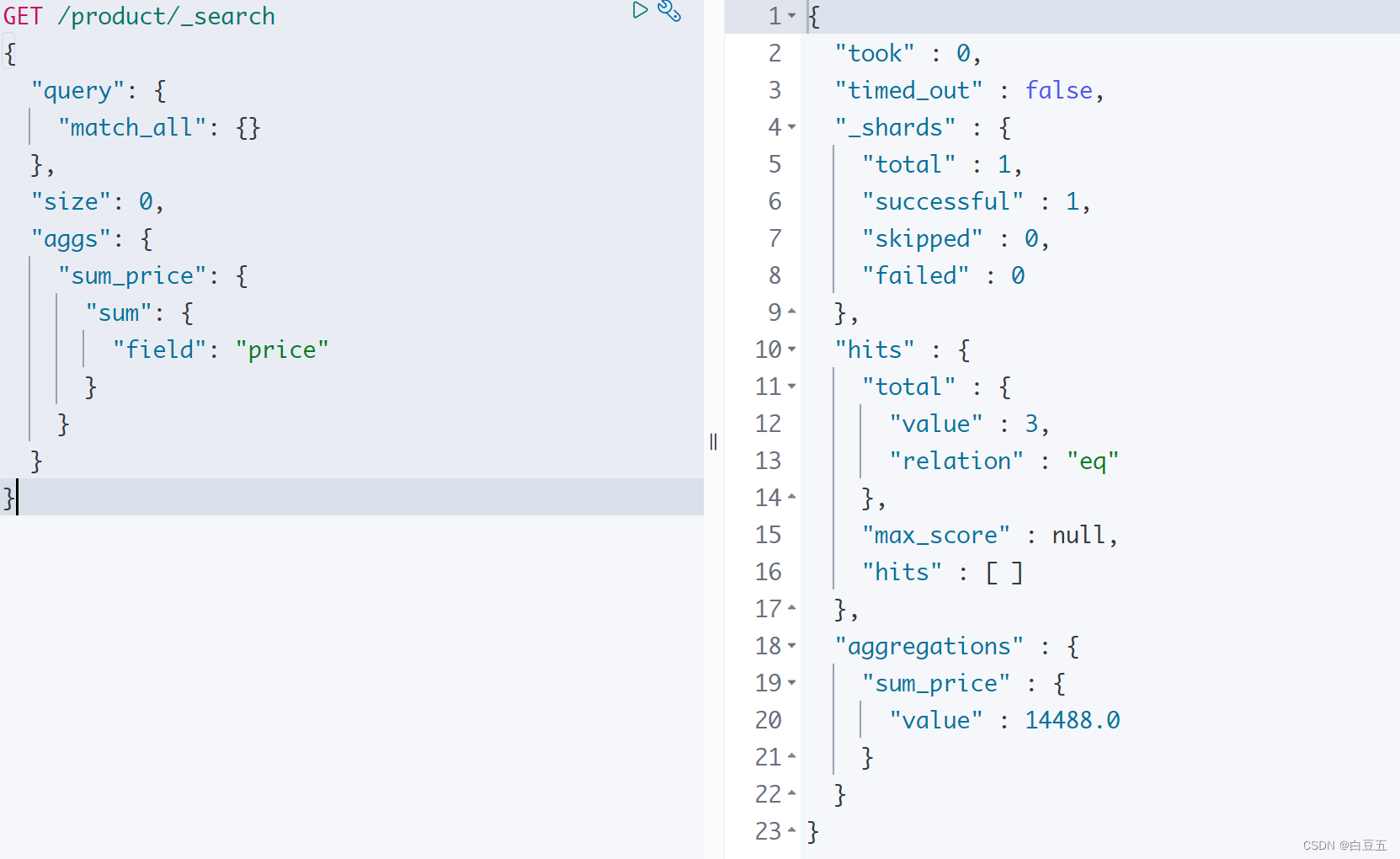
10.4 sum
示例:计算 price字段的总和。
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"sum_price": {"sum": {"field": "price"}}}
}
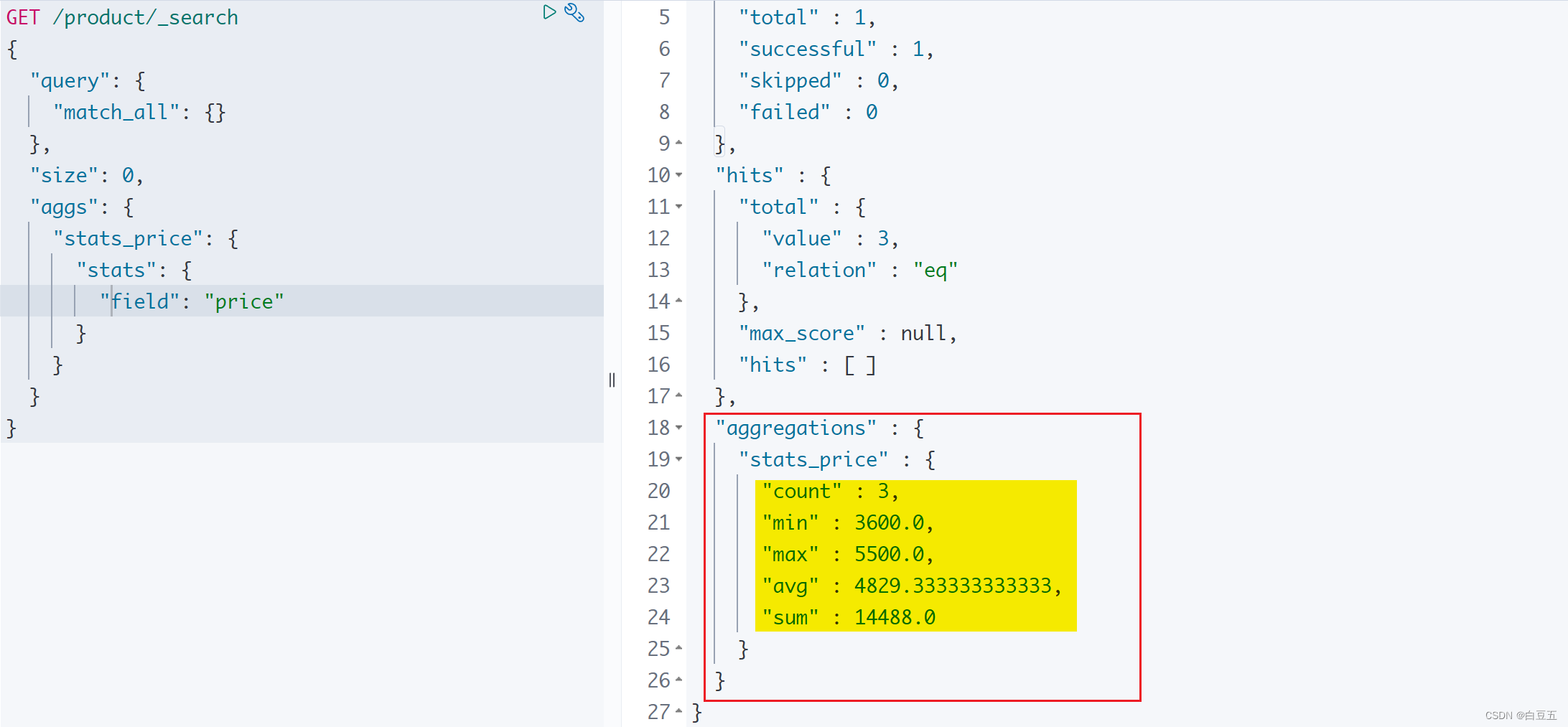
10.5 stats
stats聚合用于计算一个字段的统计数据,包括:最小值、最大值、求和、平均值和数据数量。
示例:统计price字段的数据
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"total_stats": {"stats": {"field": "price"}}}
}
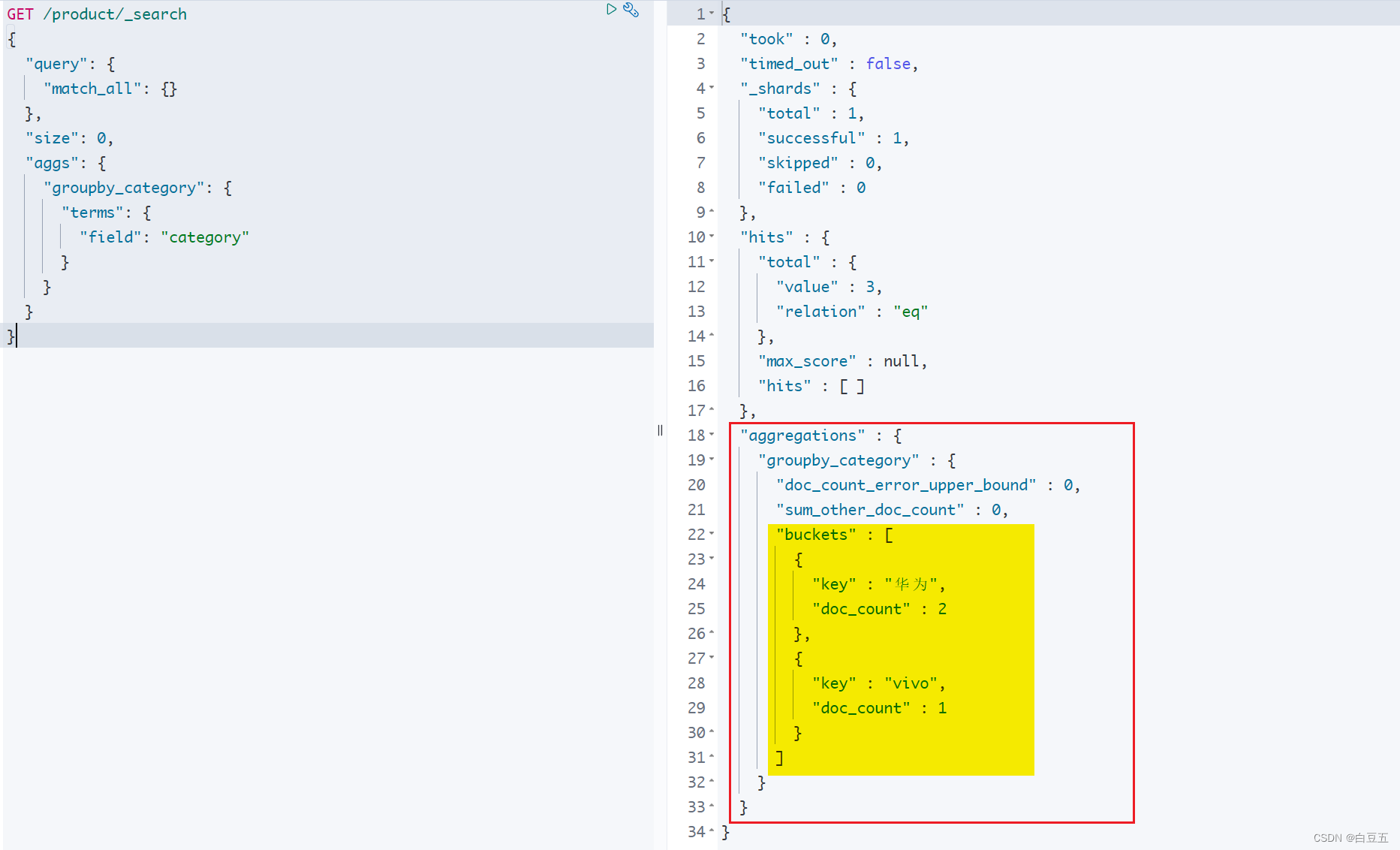
10.6 terms(分组)
terms(桶聚合)用于对字段进行分组统计(类似mysql中的group by)。它将文档按照指定字段的值进行分组,并计算每个分组的文档数量或其他指标。
示例:按照category分组,统计文档个数。(对比sql:select category,count(*) as count from product group by category)
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"stats_price": {"terms": {"field": "category"}}}
}
示例:按照category字段进行分组,只拿到前两个分组数据,并对每组的price计算总和。
GET /product/_search
{"query": {"match_all": {}},"size": 0, "aggs": {"terms_category": {"terms": {"field": "category","size": 2},"aggs": {"agg_sum": {"sum": {"field": "price"}}}}}
}
11. 分页查询(from、size)
分页的两个关键属性:from、size。
- from: 当前页的起始索引,默认从0开始。 from = (pageNum - 1) * size
- size: 每页显示多少条
分页查询语法如下:
GET /{indexName}/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 每页显示多少条"sort": [ //根据filed字段进行排序{"filed": "asc或desc"}]
}
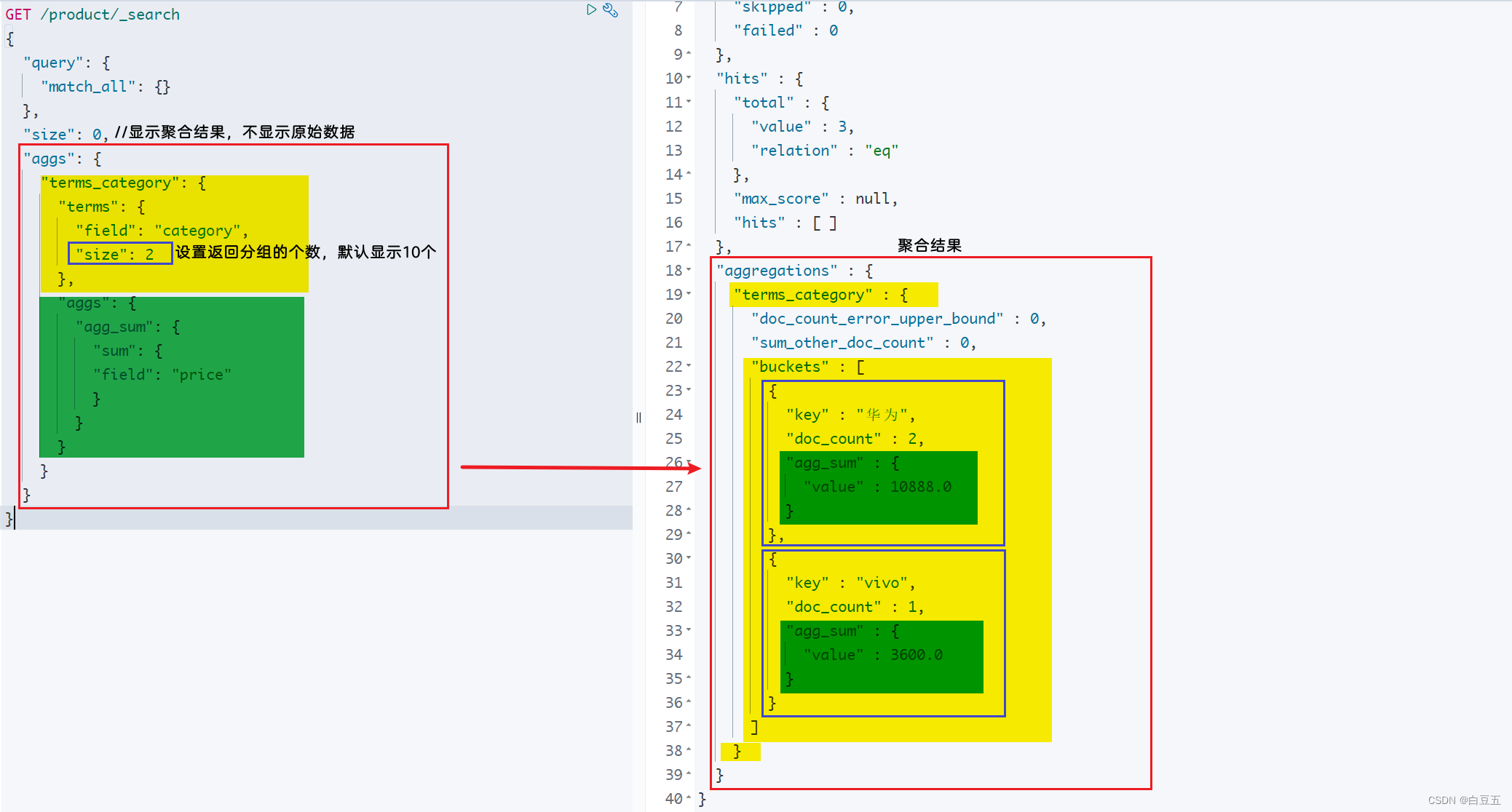
示例:全文检索华为手机,然后对price字段做倒排序,并实现分页。
GET /product/_search
{"query": {"match": {"title": "华为手机"}},"sort": [{"price": {"order": "desc"}}],"from": 0,"size": 2
}
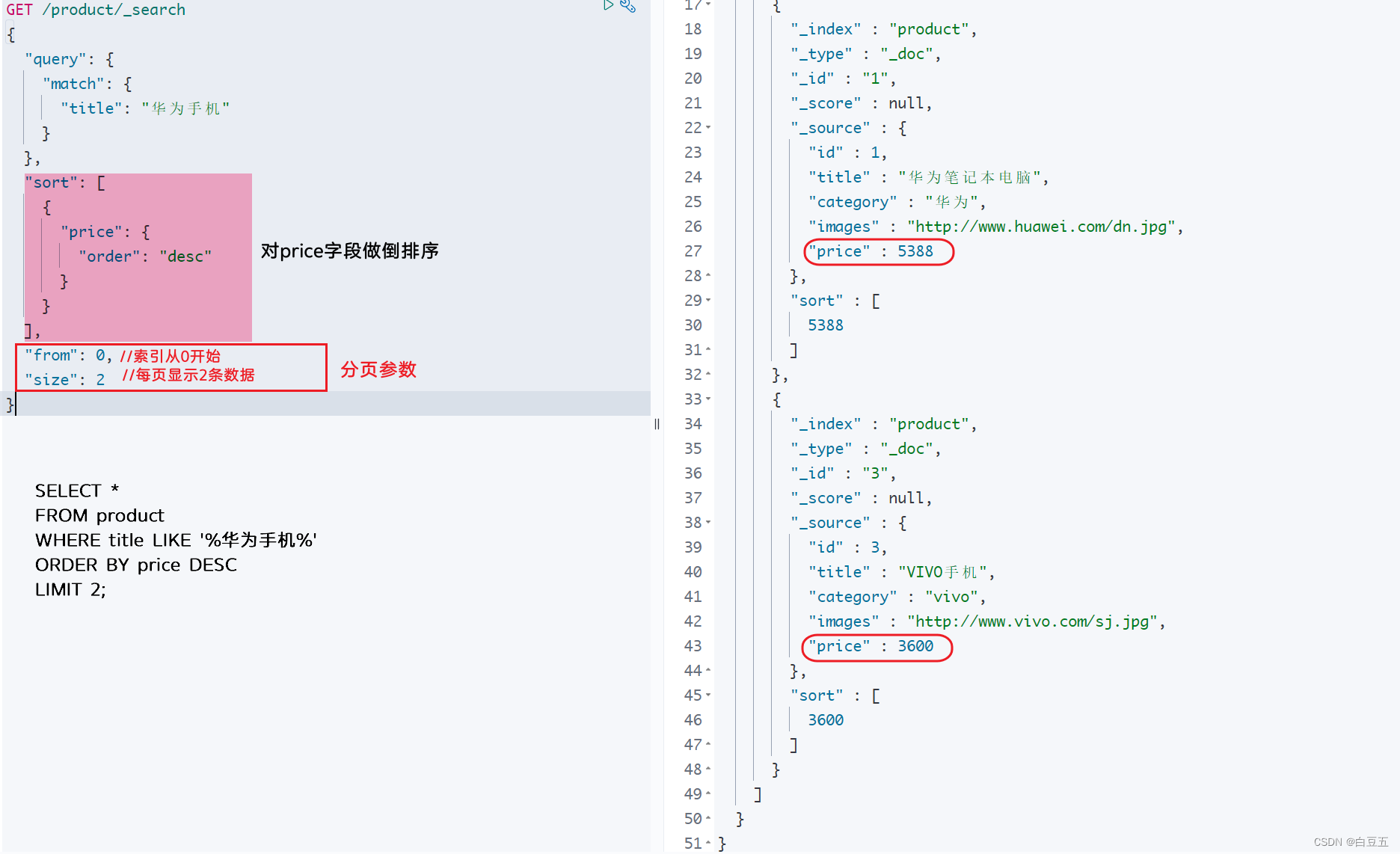
12. 高亮查询(highlight)
高亮原理:
比如我们在百度上搜索资料时,命中关键字的文档会变成红色,比较醒目,这就是高亮显示。
高亮显示的实现分为两步:
-
给文档中的所有关键字都添加一个标签,例如
<em>标签; -
页面给
<em>标签编写CSS样式。
在es中实现高亮:
高亮显示语法:
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询}},"highlight": {"fields": { "FIELD": {// 指定要高亮的字段"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
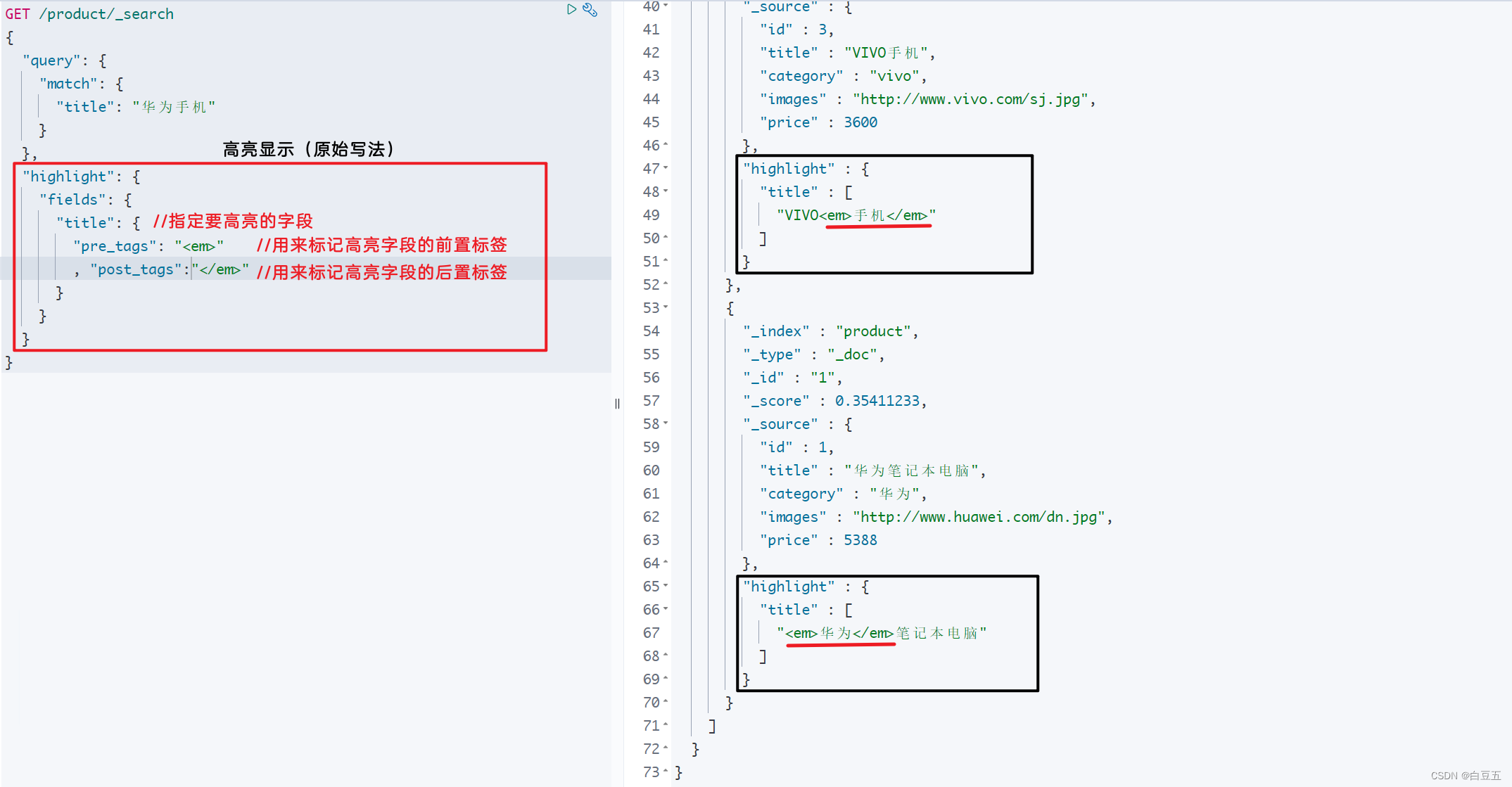
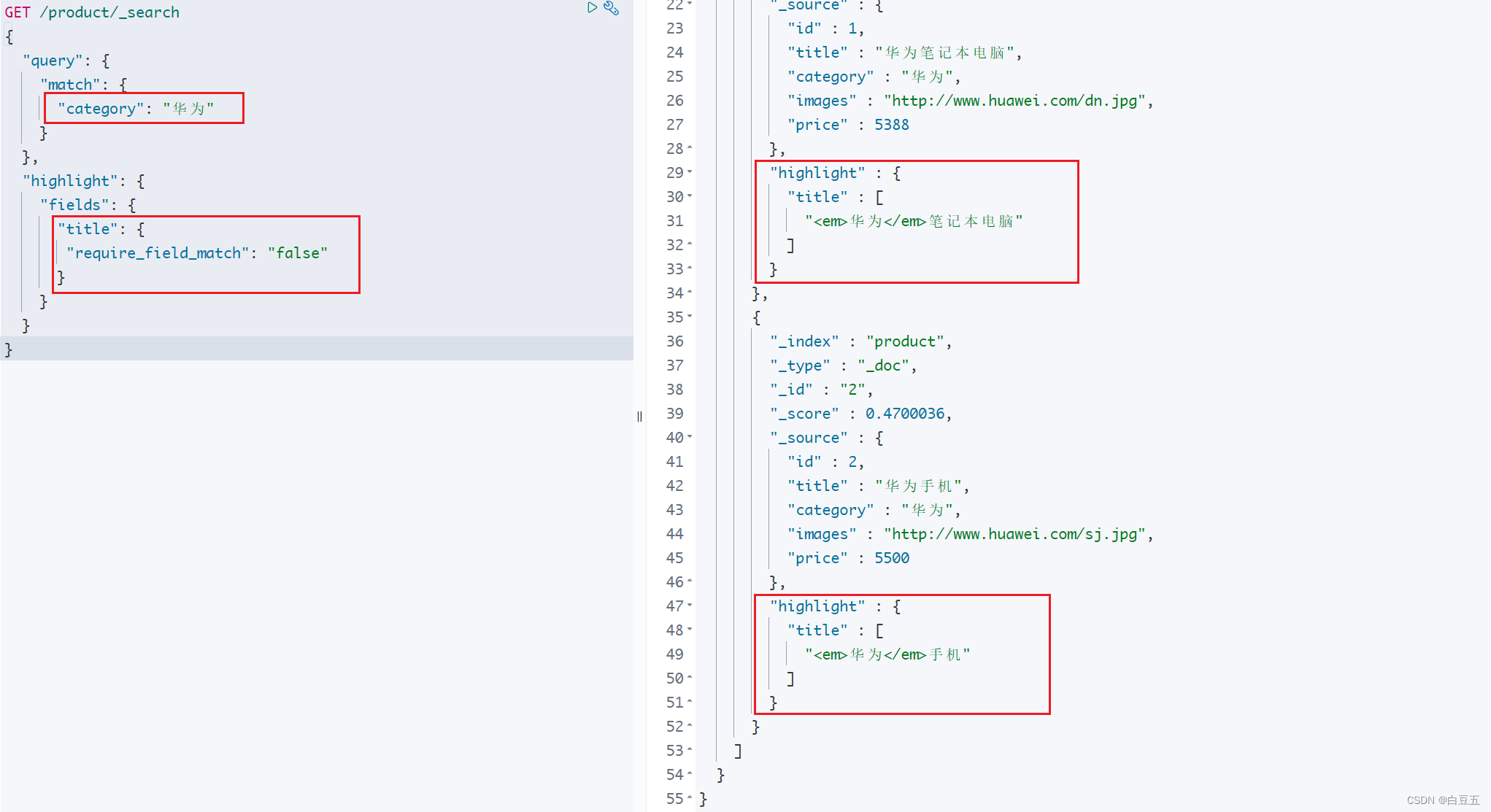
示例:全文检索查询华为手机,对title字段进行高亮处理。
GET /product/_search
{"query": {"match": {"title": "华为手机"}},"highlight": {"fields": {"title": {"pre_tags": "<em>","post_tags":"</em>"}}}
}
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮。
- 如果要对非搜索字段高亮,则需要在高亮字段中添加一个属性:
required_field_match=false
13. 近似查询(fuzzy)
fuzzy查询是一种纠错查询,通常用于英文的纠错。它可以返回与搜索词相似的词的文档。
编辑距离是衡量两个词之间差异程度的指标,表示将一个词转换为另一个词所需的最小操作次数。
这些操作包括:
-
更改字符(box → fox)
-
删除字符(black → lack)
-
插入字符(sic → sick)
-
转置两个相邻字符(act → cat)
在fuzzy查询中,我们可以通过调整fuzziness参数来修改编辑距离。默认值为AUTO(根据单词的长度匹配对应的编辑距离),fuzziness参数其它取值为0,1,2 表示最大编辑距离。
- 当单词长度为0到2之间时,必须精确匹配。编辑距离为0。(不会进行变化)
- 当单词长度为3到5个字母时,最大编辑距离为1。(例如 hallo->hello)
- 当单词长度大于5个字母时,最大编辑距离为2(最多允许两次编辑)。
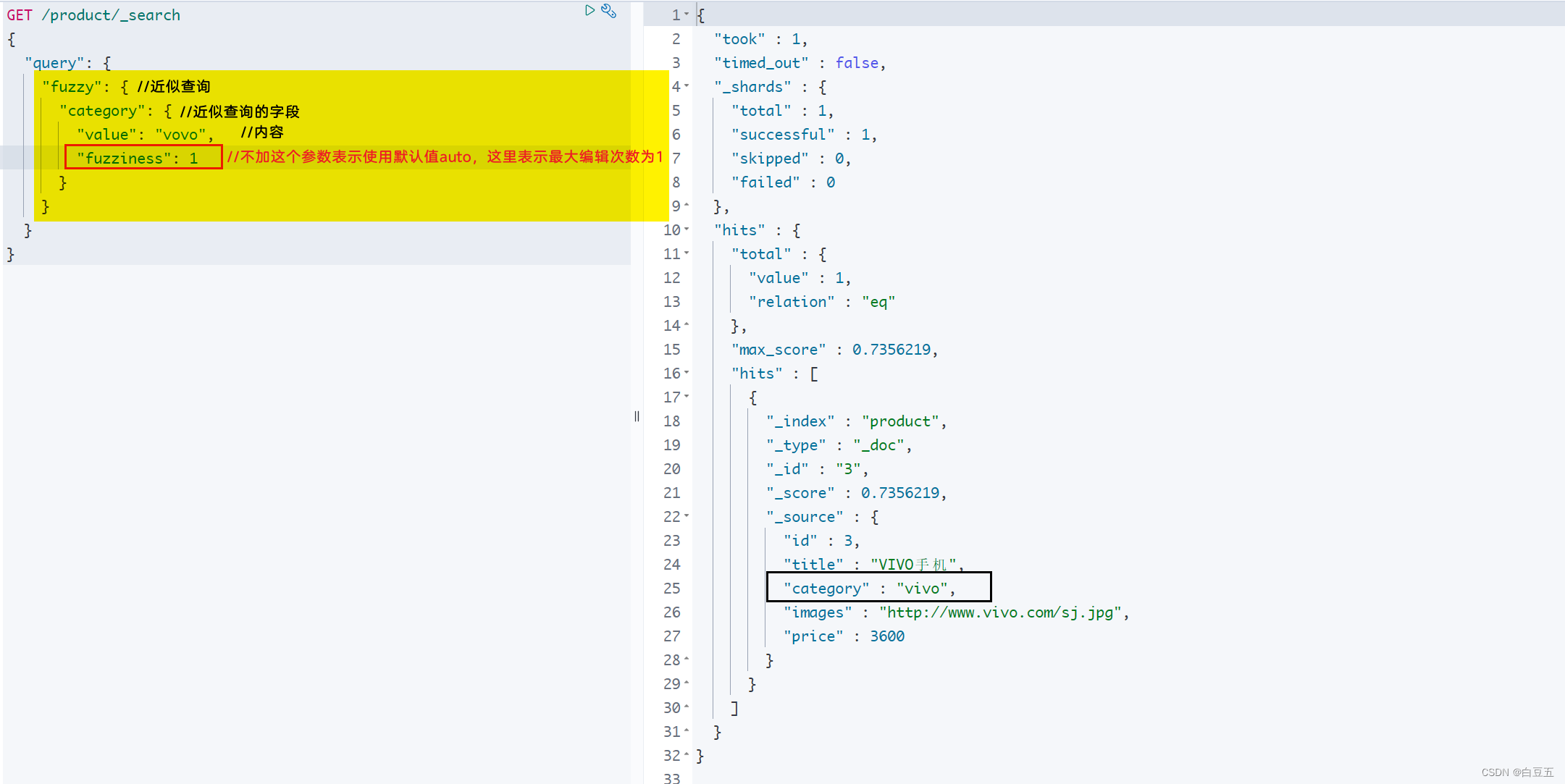
示例:近似查询categroy字段值为vovo的文档
GET /product/_search
{"query": {"fuzzy": {"category": {"value": "vovo", "fuzziness": 1}}}
}
七、Java操作ES
1. API介绍
文档地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-getting-started.html
(1)使用官网提供的API操作ES: (RestHighLevelClient)
maven坐标:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependency>
(2)Spring Data ElasticSearch: 是Spring针对ElasticSearch提供的一个模块,底层是对ES官方所提供的Java API进行了封装,用来简化ES的操作。
maven坐标:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2. 使用RestHighLevelClient操作ES
RestHighLevelClient是ES官网提供的API。
2.1 环境准备
1、创建maven项目
2、导入依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.aopmin</groupId><artifactId>RestHighLevelClient-demo</artifactId><version>1.0-SNAPSHOT</version><!-- springboot工程 --><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.4.5</version><relativePath/> <!-- lookup parent from repository --></parent><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!--Spring Data Elasticsearch由于Spring Data Elasticsearch底层封装了Elasticsearch官方的Java API,因此把这个依赖加入进来以后,关于RestHighLevelClient已经由SpringBoot进行自动配置了--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency><!-- junit --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><!-- fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.80</version></dependency><!-- lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>
3、创建启动类:
package cn.aopmin;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class MyApp {public static void main(String[] args) {SpringApplication.run(MyApp.class, args);}
}
4、在application.yml中配置ES:
spring:elasticsearch:rest:uris: http://192.168.150.123:9200 # 配置es服务器的地址
5、测试
package cn.aopmin.test;import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.web.client.RestClientTest;
import org.springframework.boot.test.context.SpringBootTest;/*** 测试类* @author 白豆五* @version 2023/07/23* @since JDK8*/
@SpringBootTest
public class ElasticSearchTest {@Autowiredprivate RestHighLevelClient restHighLevelClient;@Testpublic void test() {System.out.println(restHighLevelClient);}
}

2.2 索引库相关操作
2.2.1 创建索引库
package cn.aopmin.test;import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;/*** 测试索引库相关操作** @author 白豆五* @version 2023/07/23* @since JDK8*/
@SpringBootTest
@Slf4j
public class IndexTest {@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** 测试创建索引库*/@Testpublic void testCreateIndex() throws IOException {// 1.拿到创建索引的请求对象,并指定索引名// org.elasticsearch.client.indices.CreateIndexRequest;CreateIndexRequest createIndexRequest = new CreateIndexRequest("goods");// 2.添加请求参数(内容是定义索引库的DSL语句,json格式)// 也可以把DSL语句提取到常量类中createIndexRequest.source("{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"long\",\n" +" \"index\": true\n" +" },\n" +" \"title\": {\n" +" \"type\": \"text\",\n" +" \"index\": true,\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"search_analyzer\": \"ik_smart\"\n" +" },\n" +" \"category\": {\n" +" \"type\": \"keyword\",\n" +" \"index\": true\n" +" },\n" +" \"images\": {\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\": {\n" +" \"type\": \"integer\",\n" +" \"index\": true\n" +" }\n" +" }\n" +" }\n" +"}", XContentType.JSON);// 3.发送请求// IndicesClient indices = restHighLevelClient.indices(); // 拿到操作索引的客户端// indices.create(createIndexRequest, RequestOptions.DEFAULT); // 执行创建索引的请求// CreateIndexResponse对象中包含了创建索引的返回结果CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);// 4.输出结果log.info("索引名称:{}", createIndexResponse.index());log.info("操作是否成功:{}", createIndexResponse.isAcknowledged());log.info("分片是否被确认:{}", createIndexResponse.isShardsAcknowledged());}
}

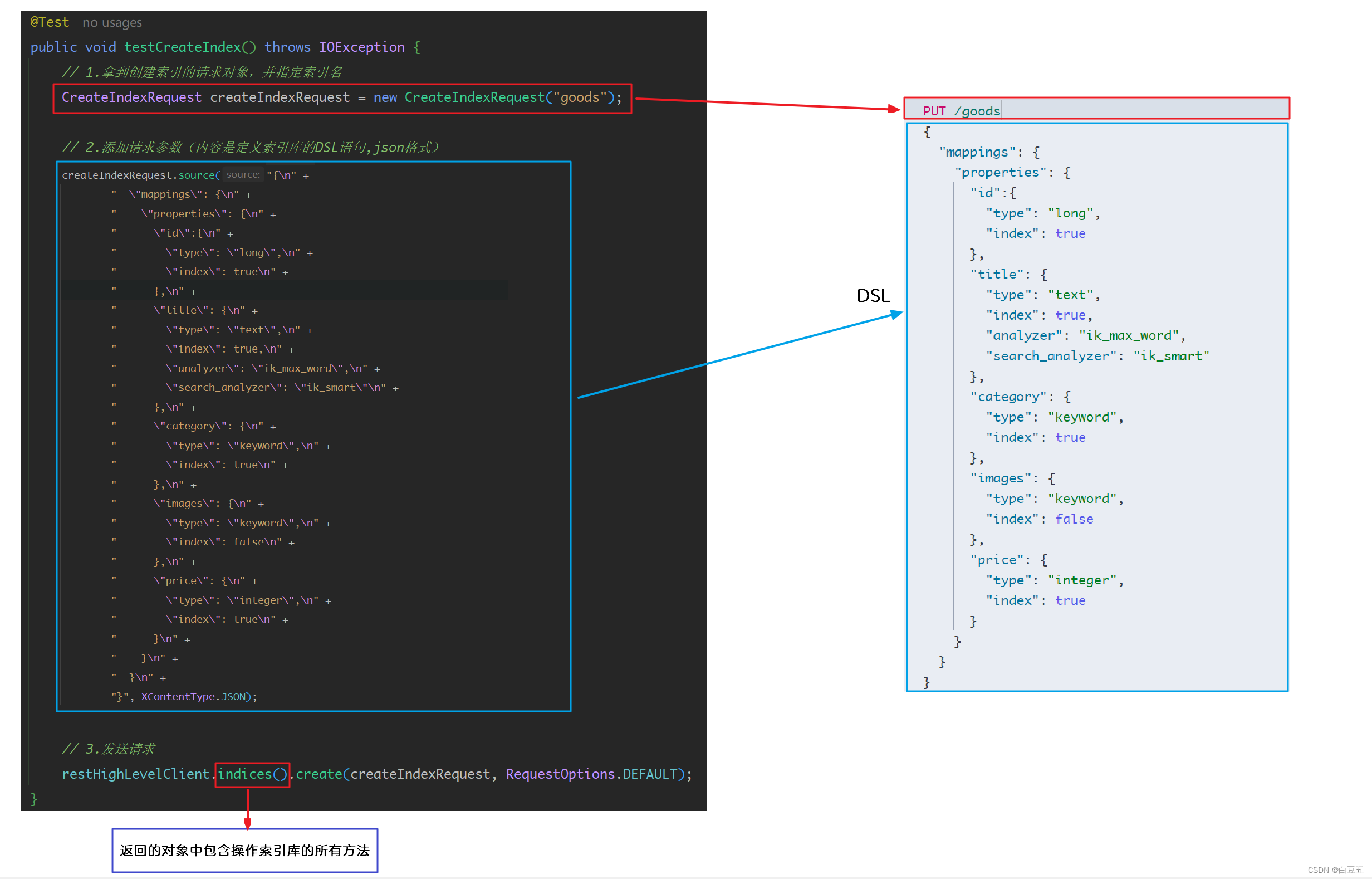
2.2.2 获取所引库
/*** 测试获取索引库*/
@Test
public void testGetIndex() throws IOException {// 1.创建Request对象GetIndexRequest getIndexRequest = new GetIndexRequest("goods");// 2.发起请求, exists()方法返回true表示索引库存在,false表示不存在boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);log.info("索引库是否存在:{}", exists);
}

2.2.3 删除索引库
/*** 测试删除索引库*/
@Test
public void testDeleteIndex() throws IOException {DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("goods");AcknowledgedResponse response = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);System.out.println("索引库是否删除成功: "+response.isAcknowledged());
}
小节:
RestHighLevelClient操作ES索引库的流程基本类似。核心都是通过restHighLevelClient.indices()方法获取索引库的操作对象。
索引库操作的基本步骤如下:
- 依赖注入RestHighLevelClient。(Spring Data Elasticsearch依赖提供的)
- 创建XxxIndexRequest。(Xxx是Create、Delete、Get。)
- 准备DSL( 只有在Create时需要准备DSL)
- 发送请求。(调用RestHighLevelClient.indices().xxx()方法,xxx是create、exists、delete、get)
2.3 文档相关操作
2.3.1 数据准备
1、sql脚本:
CREATE DATABASE IF NOT EXISTS `es-db` DEFAULT CHARACTER SET utf8mb4;use `es-db`;CREATE TABLE `goods`
(`id` BIGINT(20) PRIMARY KEY AUTO_INCREMENT COMMENT '商品ID',`title` VARCHAR(255) NOT NULL COMMENT '商品标题',`category` VARCHAR(32) NOT NULL COMMENT '分类',`image` VARCHAR(255) NOT NULL COMMENT '图片',`price` INT(10) NOT NULL COMMENT '价格'
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 COMMENT '商品表';insert into goods values (1, '华为笔记本电脑', '华为', 'http://www.huawei.com/dn.jpg', 5388),(2, '华为手机', '华为', 'http://www.huawei.com/sj.jpg', 5500),(3, 'VIVO手机', 'vivo', 'http://www.vivo.com/sj.jpg', 3600);
2、引入mp相关依赖:
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version>
</dependency>
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version>
</dependency>
3、在application.yml中配置数据库:
spring:# 数据源配置datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql:///es-db?useSSL=false&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456# ES配置elasticsearch:rest:uris: http://192.168.150.123:9200 # 配置es服务器的地址
4、使用插件生成pojo、mappe、service基础代码
1)数据源配置:
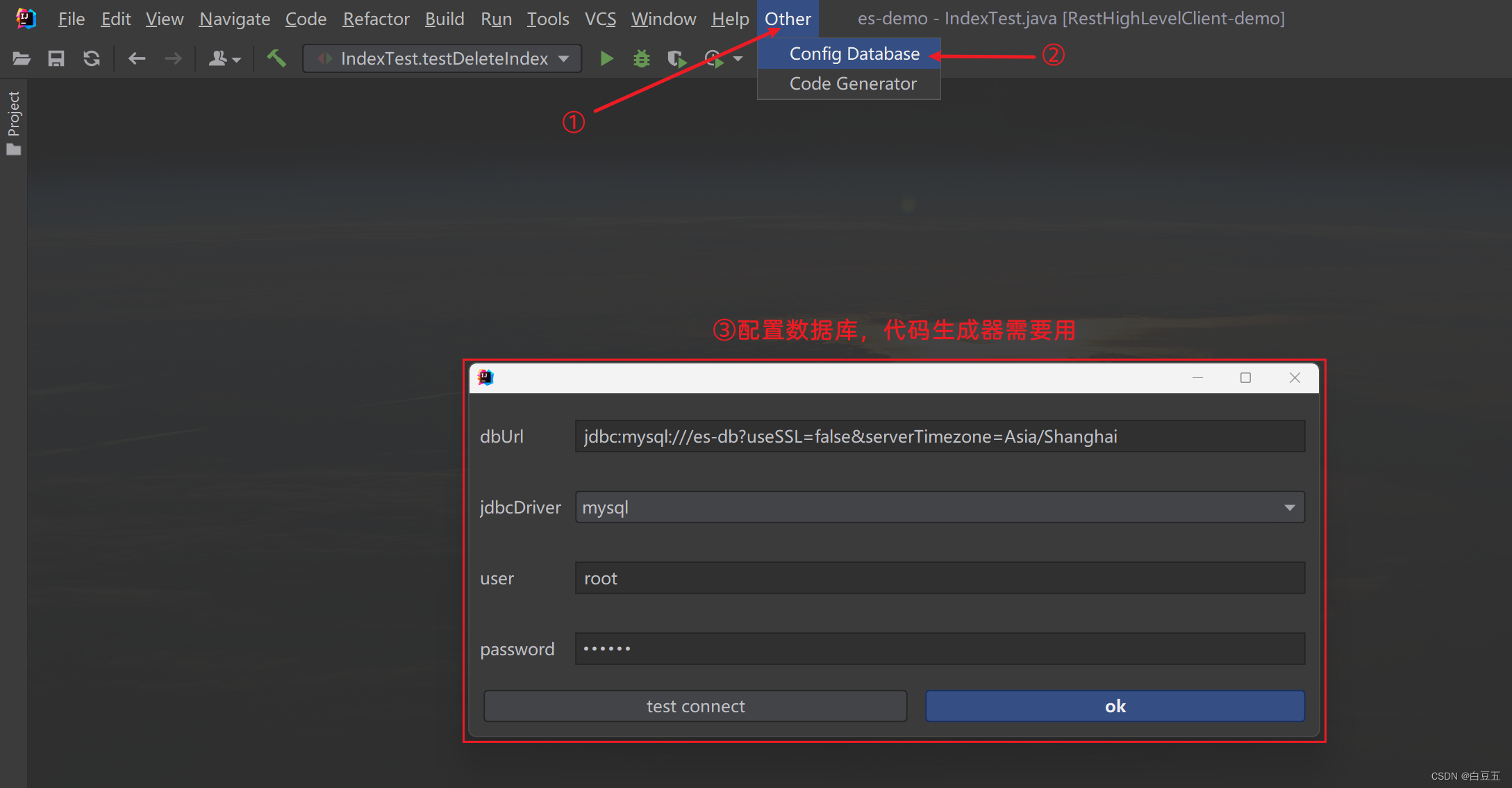
2)使用代码生成器:
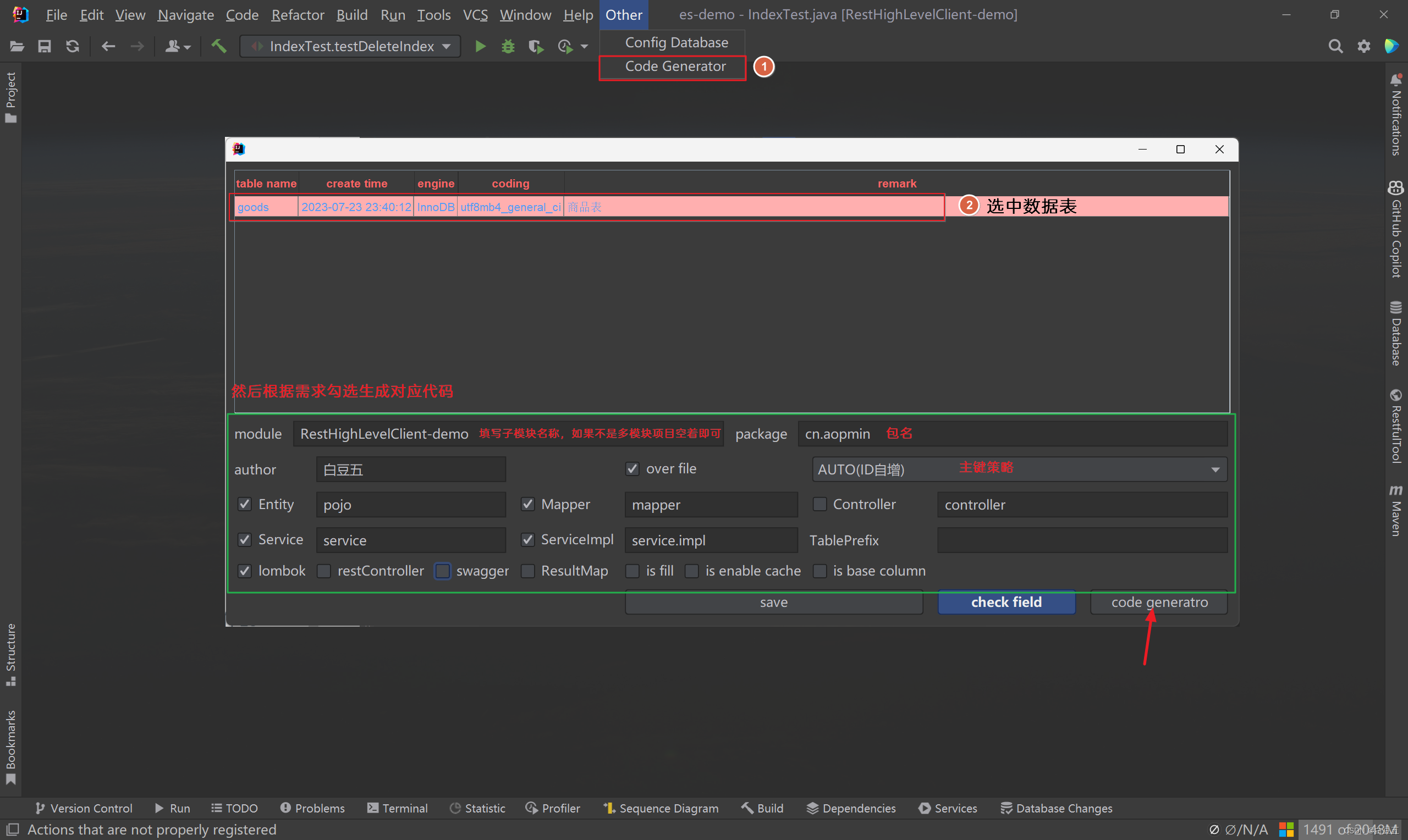
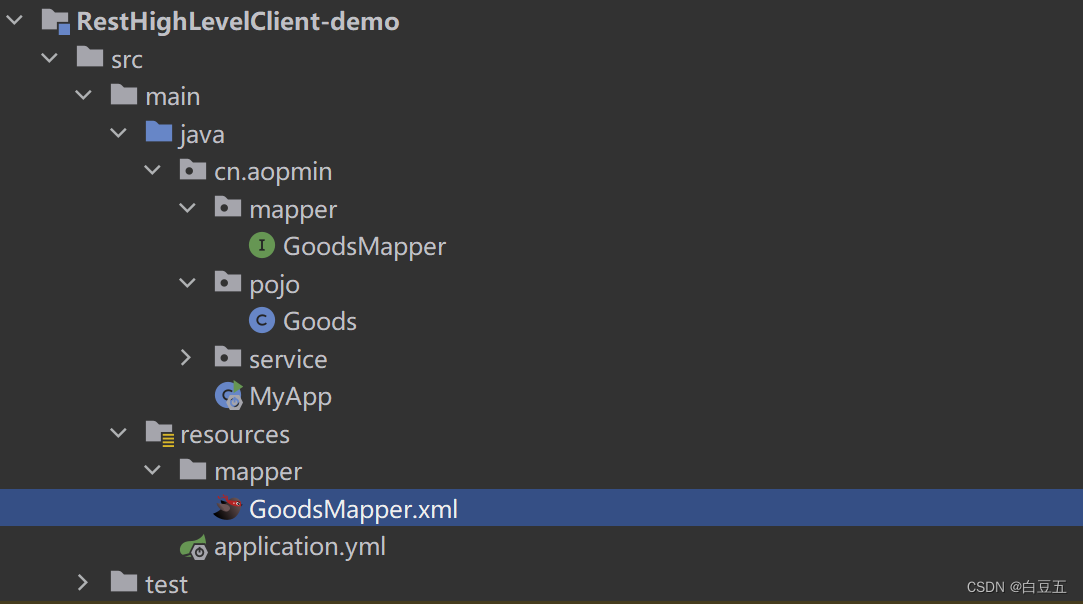
5、在启动类上配置mapper扫描:
package cn.aopmin;import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@MapperScan("cn.aopmin.mapper") //mapper扫描
@SpringBootApplication
public class MyApp {public static void main(String[] args) {SpringApplication.run(MyApp.class, args);}
}2.3.2 添加文档
package cn.aopmin.test;import cn.aopmin.pojo.Goods;
import cn.aopmin.service.IGoodsService;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;import javax.annotation.Resource;
import java.io.IOException;/*** @author 白豆五* @version 2023/07/23* @since JDK8*/
@SpringBootTest
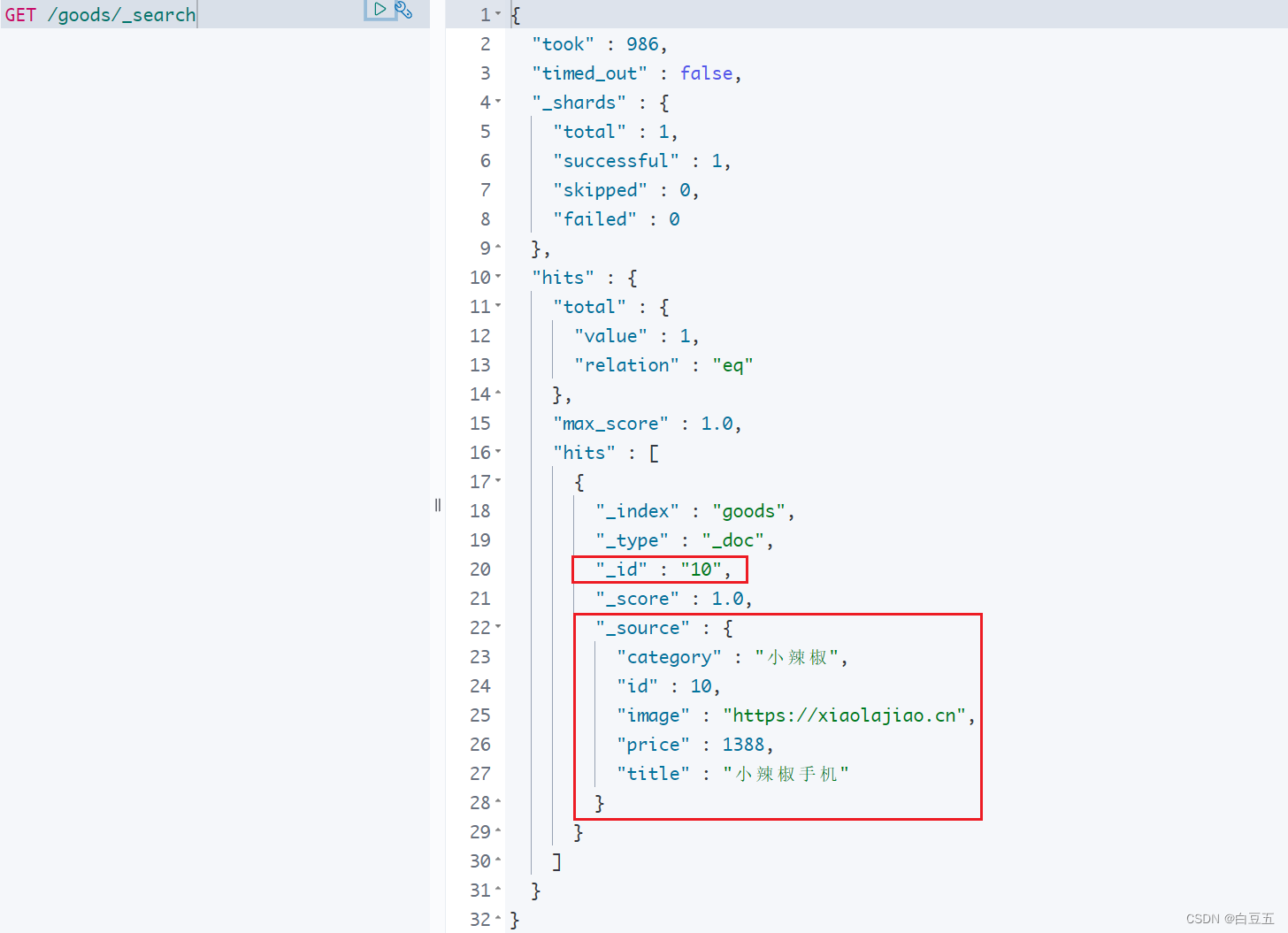
public class DocumentTest {@Resourceprivate IGoodsService goodsService;@Resourceprivate RestHighLevelClient client;/*** 测试创建文档*/@Testpublic void testAddDocument() throws IOException {// 1.创建Request对象// IndexRequest: 创建文档的请求对象IndexRequest request = new IndexRequest("goods"); //指定索引库名称// 设置文档id,如果不设置的话,ES会自动生成一个唯一的字符串作为文档IDrequest.id("10");// 2.准备json文档数据// Java对象转JSON字符串String json = JSON.toJSONString(new Goods().setId(10L).setTitle("小辣椒手机").setCategory("小辣椒").setImage("https://xiaolajiao.cn").setPrice(1388));request.source(json, XContentType.JSON);// 3.发送请求创建文档IndexResponse response = client.index(request, RequestOptions.DEFAULT);// 输出结果System.out.println(response.getResult());}}
执行结果:

2.3.3 修改文档
修改文档有两种方式:
- 全量修改:本质是先根据id删除,再新增(语法与插入文档类似)
- 增量修改:修改文档中的指定字段值
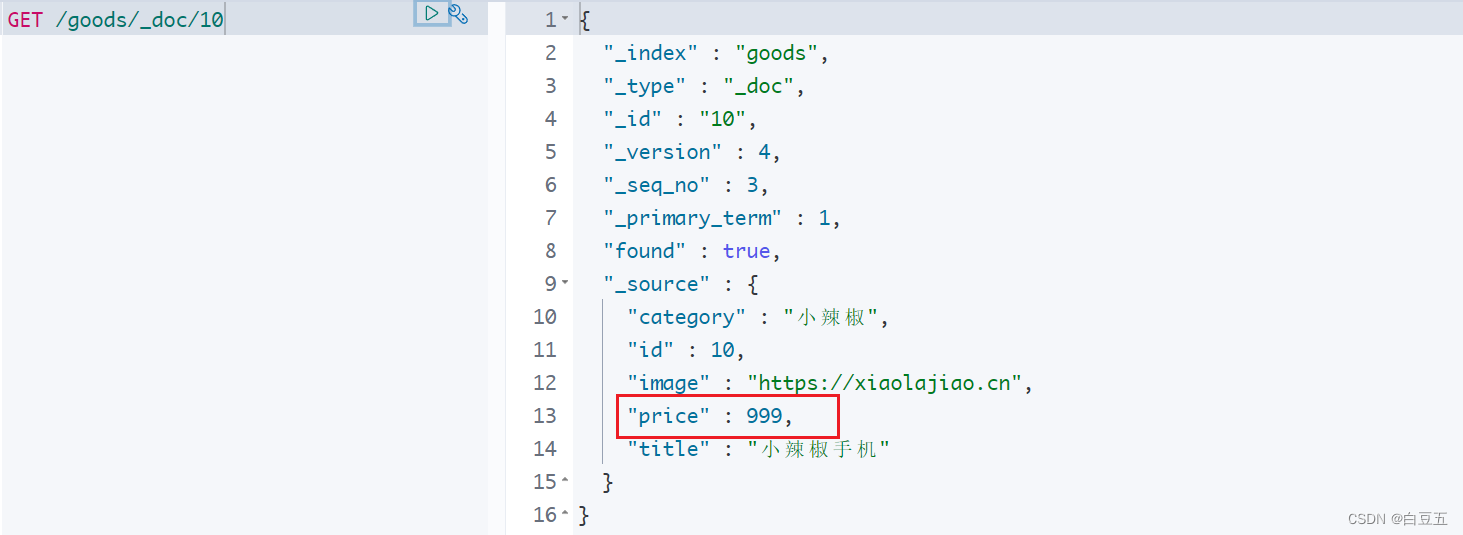
/*** 测试修改文档*/
@Test
public void testUpdateDocument() throws IOException {// 构建数据Goods goods = new Goods();goods.setPrice(999);String jsonString = JSON.toJSONString(goods);// 1.创建Request对象// UpdateRequest: 修改文档的请求对象。参数:索引库、文档id。如果文档id不存在,则会新增一个文档。UpdateRequest request = new UpdateRequest("goods", "10");// 2.准备Json文档,里面包含要修改的字段request.doc(jsonString, XContentType.JSON);// 3.发送请求UpdateResponse response = client.update(request, RequestOptions.DEFAULT);// 4.输出结果System.out.println(response.getResult());
}
输出结果:

2.3.4 根据id查询文档
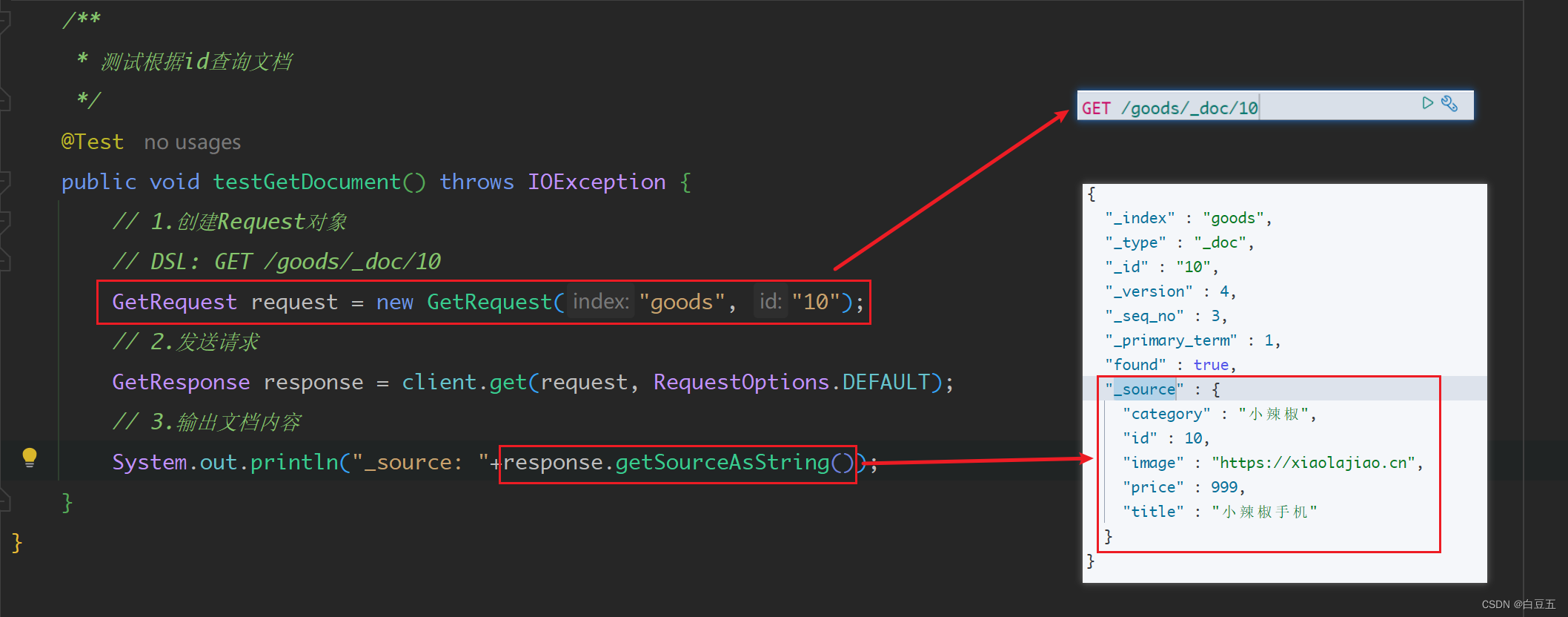
/*** 测试根据id查询文档*/
@Test
public void testGetDocument() throws IOException {// 1.创建Request对象// DSL: GET /goods/_doc/10GetRequest request = new GetRequest("goods", "10");// 2.发送请求GetResponse response = client.get(request, RequestOptions.DEFAULT);// 3.输出文档内容System.out.println("_source: "+response.getSourceAsString());
}
执行结果:

2.3.5 删除文档
/*** 测试根据id删除文档*/
@Test
public void testDeleteDocument() throws IOException {// 1.创建Request对象// DSL: DELETE /goods/_doc/10DeleteRequest request = new DeleteRequest("goods", "10");// 2.发送请求client.delete(request, RequestOptions.DEFAULT);
}
2.3.6 批量新增
批量处理BulkRequest,其本质就是将多个普通的CRUD请求组合在一起发送。
其中提供了一个add方法,用来添加其他Request请求:
- IndexRequest,新增文档的请求
- UpdateRequest,修改文档的请求
- DeleteRequest,删除文档的请求
示例:将数据库中的数据添加到
/*** 测试批量新增*/
@Test
public void testBulkAddDocument() throws IOException {// 准备数据List<Goods> goodsList = goodsService.list();// 1.创建Request对象// BulkRequest: 批量操作请求对象。可以批量执行增删改操作BulkRequest bulkRequest = new BulkRequest();// 2.准备参数:把多个IndexRequest添加到BulkRequest中goodsList.forEach(goods -> {//对象转Json字符串String json = JSON.toJSONString(goods);//创建单个请求对象/*IndexRequest request = new IndexRequest("goods");request.id(goods.getId().toString()); //文档idrequest.source(json, XContentType.JSON);//Josn文档内容bulkRequest.add(request);//放入批量请求对象中*/// 简化写法bulkRequest.add(new IndexRequest("goods").id(goods.getId().toString()).source(json, XContentType.JSON));});// 3.发送批处理请求BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
}
批量新增操作步骤:
- 创建Request对象,这里是BulkRequest。
- 准备参数。批处理的参数,把多个IndexRequest添加到BulkRequest中。
- 发送批处理请求。调用的方法为client.bulk()方法。
小节:
文档操作的基本步骤:
- 注入RestHighLevelClient对象
- 创建XxxRequest。如 IndexRequest、GetRequest、UpdateRequest、DeleteRequest、BulkRequest
- 准备参数(Index、Update、Bulk时需要提供)
- 发送请求。调用RestHighLevelClient.xxx()方法,xxx是index、get、update、delete、bulk
- 解析结果(Get时需要)
2.4 高级查询
2.4.1 查询所有文档
package cn.aopmin.test;import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
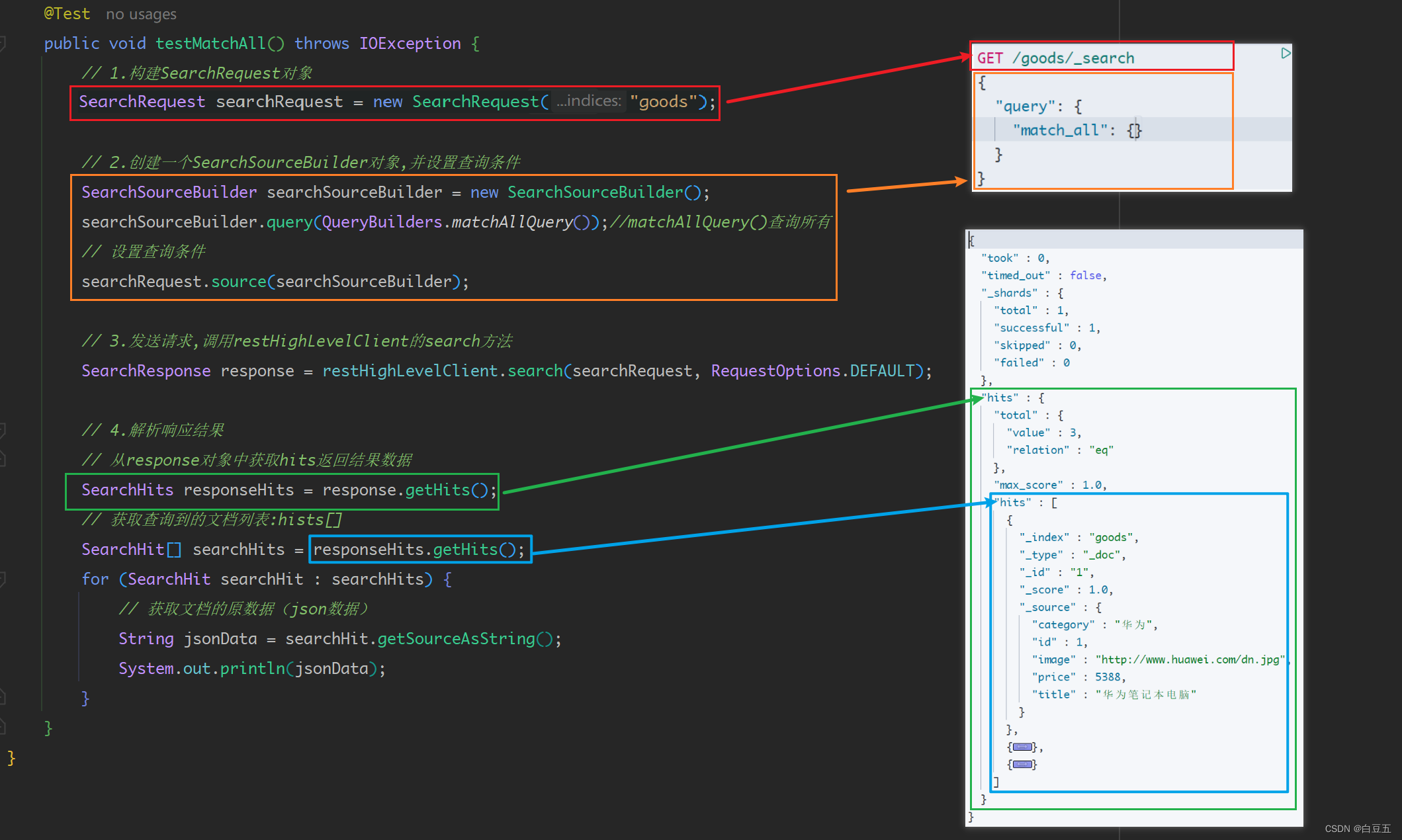
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;/*** 高级查询** @author 白豆五* @version 2023/07/24* @since JDK8*/
@SpringBootTest
public class DSLTest {@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** 测试查询所有文档*/@Testpublic void testMatchAll() throws IOException {// 1.构建SearchRequest对象SearchRequest searchRequest = new SearchRequest("my_index");// 2.创建一个SearchSourceBuilder对象,并设置查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());//matchAllQuery()查询所有// 设置查询条件searchRequest.source(searchSourceBuilder);// 3.发送请求,调用restHighLevelClient的search方法SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);// 4.解析响应结果// 从response对象中获取hits返回结果数据SearchHits responseHits = response.getHits();// 获取查询到的文档列表:hists[]SearchHit[] searchHits = responseHits.getHits();for (SearchHit searchHit : searchHits) {// 获取文档的原数据(json数据)String jsonData = searchHit.getSourceAsString();System.out.println(jsonData);}}
}
返回结果:

2.4.2 匹配查询
/*** 测试匹配查询(全文检索,单字段)*/
@Test
public void testMatch() throws IOException {// 1.构建SearchRequest对象SearchRequest searchRequest = new SearchRequest("goods");// 2.创建一个SearchSourceBuilder对象,并设置查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("title", "华为"));//matchQuery()匹配查询// 设置查询条件searchRequest.source(searchSourceBuilder);// 3.发送查询请求SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);// 4.解析响应结果// 从response对象中获取hits返回结果数据SearchHits responseHits = response.getHits();// 获取查询到的文档列表:hists[]SearchHit[] searchHits = responseHits.getHits();for (SearchHit searchHit : searchHits) {// 获取文档的原数据(json数据)String jsonData = searchHit.getSourceAsString();System.out.println(jsonData);}
}
返回结果:

2.4.3 高亮查询
/*** 高亮查询*/
@Test
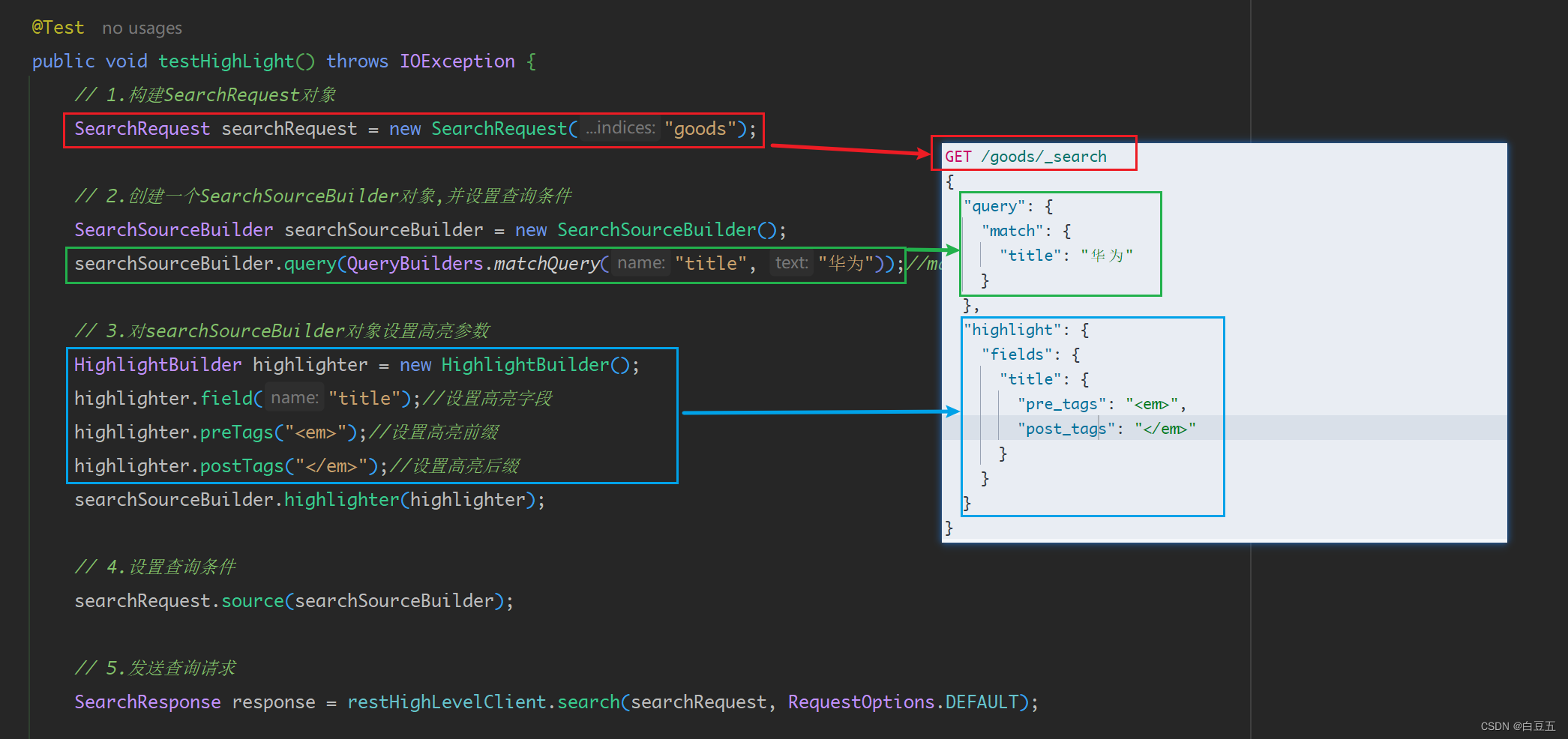
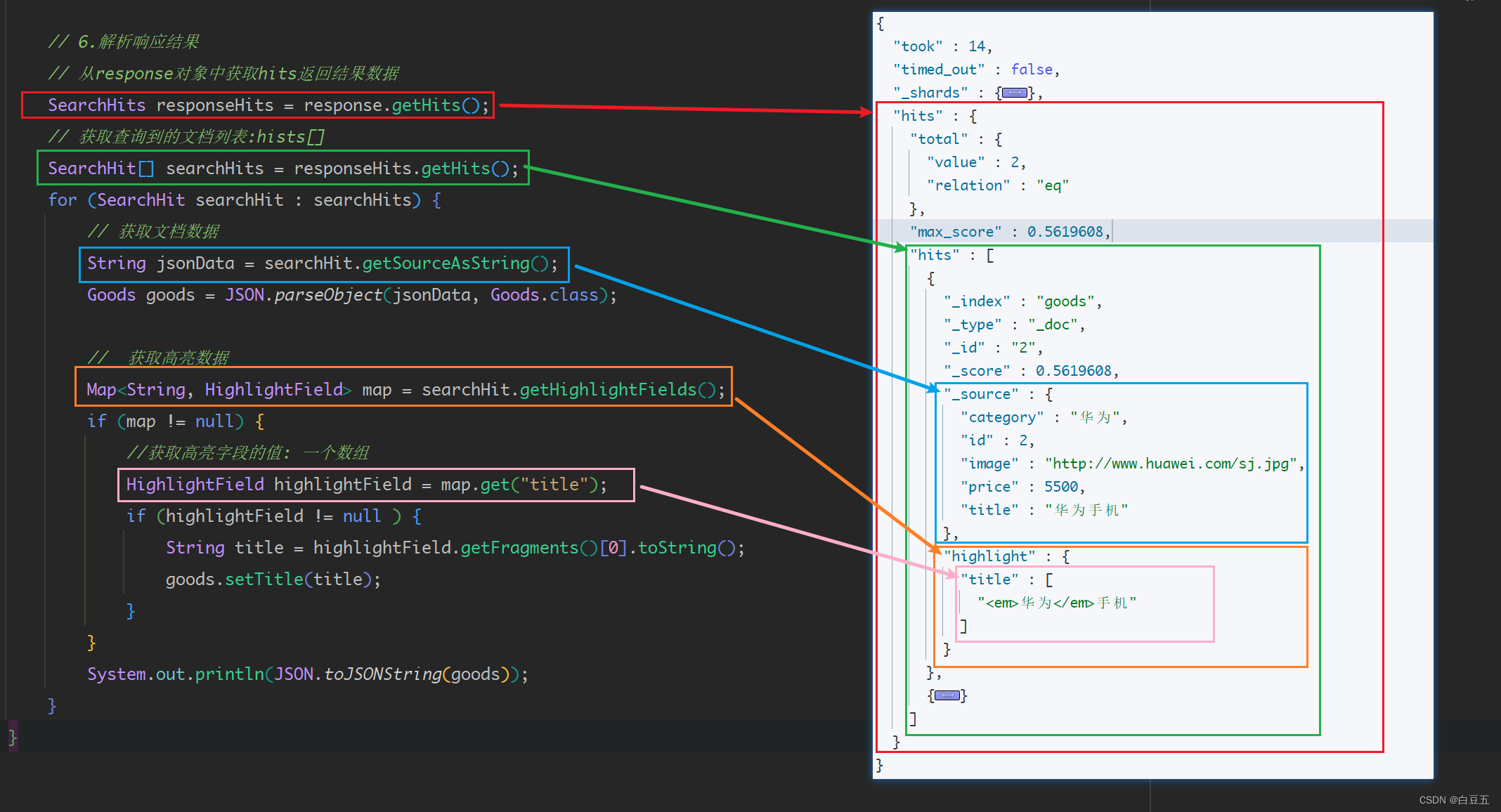
public void testHighLight() throws IOException {// 1.构建SearchRequest对象SearchRequest searchRequest = new SearchRequest("goods");// 2.创建一个SearchSourceBuilder对象,并设置查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("title", "华为"));//matchQuery()匹配查询// 3.对searchSourceBuilder对象设置高亮参数HighlightBuilder highlighter = new HighlightBuilder();highlighter.field("title");//设置高亮字段highlighter.preTags("<em>");//设置高亮前缀highlighter.postTags("</em>");//设置高亮后缀searchSourceBuilder.highlighter(highlighter);// 4.设置查询条件searchRequest.source(searchSourceBuilder);// 5.发送查询请求SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);// 6.解析响应结果// 从response对象中获取hits返回结果数据SearchHits responseHits = response.getHits();// 获取查询到的文档列表:hists[]SearchHit[] searchHits = responseHits.getHits();for (SearchHit searchHit : searchHits) {// 获取文档数据String jsonData = searchHit.getSourceAsString();Goods goods = JSON.parseObject(jsonData, Goods.class);// 获取高亮数据Map<String, HighlightField> map = searchHit.getHighlightFields();if (map != null) {//获取高亮字段的值: 一个数组HighlightField highlightField = map.get("title");if (highlightField != null ) {String title = highlightField.getFragments()[0].toString();goods.setTitle(title);}}System.out.println(JSON.toJSONString(goods));}
}
简化写法:
@Test
public void testHighLight2() throws IOException {// 1.构建SearchRequest对象SearchRequest searchRequest = new SearchRequest("goods");// 2.准备DSL/*// 2.1设置查询条件searchRequest.source().query(QueryBuilders.matchQuery("title", "华为"));// 2.2设置高亮参数searchRequest.source().highlighter(new HighlightBuilder().field("title").preTags("<em>").postTags("</em>"));*/searchRequest.source()// 设置查询条件.query(QueryBuilders.matchQuery("title", "华为"))// 设置高亮参数.highlighter(new HighlightBuilder().field("title").preTags("<em>").postTags("</em>"));// 3.发送查询请求SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);// 4.解析响应结果// 从response对象中获取hits返回结果数据SearchHits responseHits = response.getHits();// 获取查询到的文档数组:hists[]SearchHit[] searchHits = responseHits.getHits();// 4.1获取总条数long total = searchHits.length;System.out.println("共搜索到" + total + "条数据");for (SearchHit searchHit : searchHits) {// 4.2获取文档数据(_source)String jsonData = searchHit.getSourceAsString();Goods goods = JSON.parseObject(jsonData, Goods.class);// 4.3获取高亮数据Map<String, HighlightField> map = searchHit.getHighlightFields();if (map != null) {//根据字段名获取高亮结果HighlightField highlightField = map.get("title");if (highlightField != null) {// 获取高亮值String title = highlightField.getFragments()[0].toString();// 覆盖内容goods.setTitle(title);}}System.out.println(JSON.toJSONString(goods));}
}

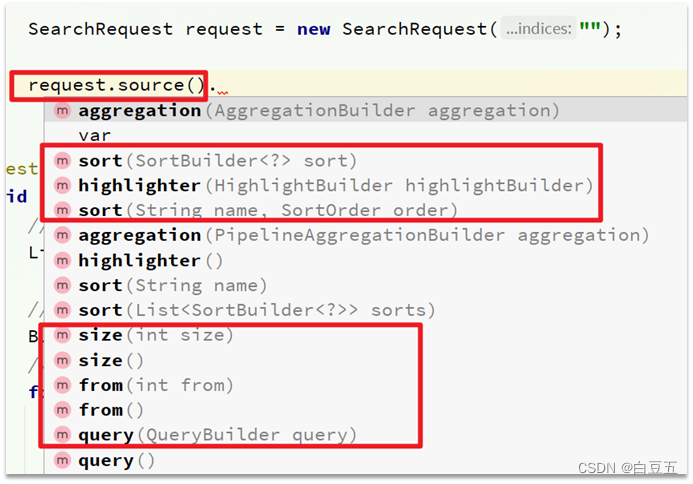
这里面有两个关键的API,一个是request.source(),提供了查询、排序、分页、高亮等功能:
另一个是QueryBuilders工具类,可以进行match、term、function_score、bool等查询:

2.4.4 聚合查询
/*** 测试聚合查询*/
@Test
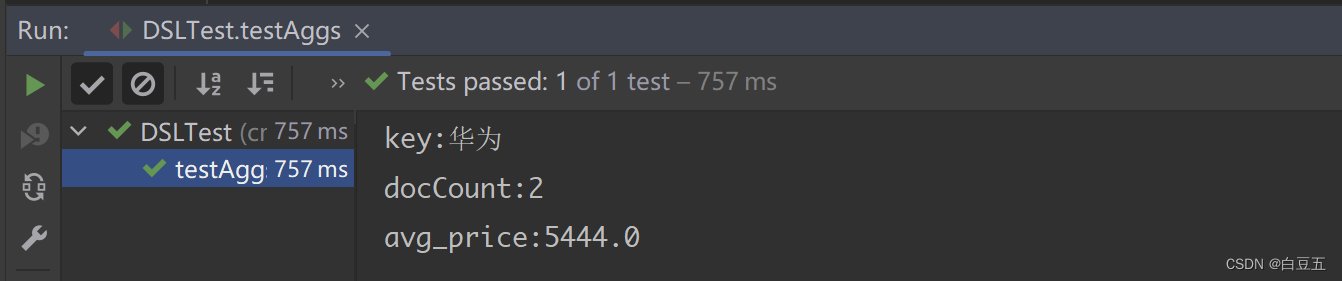
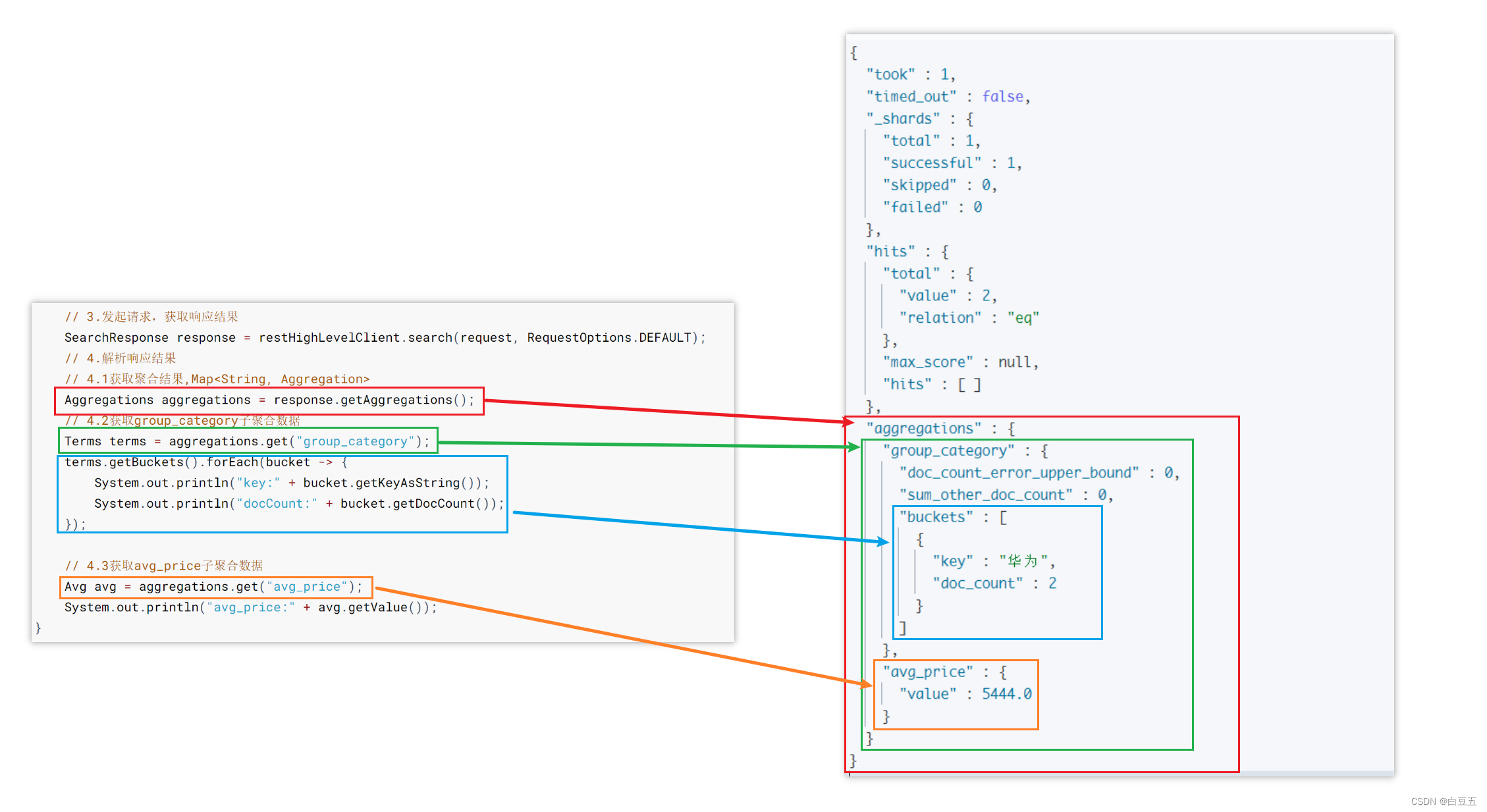
public void testAggs() throws IOException {// 1.创建Request对象SearchRequest request = new SearchRequest("goods");// 2.准备DSL// 2.1设置查询条件request.source().query(QueryBuilders.matchQuery("title", "华为")).size(0) //不需要返回文档数据,只需要返回聚合结果// 2.2设置聚合参数.aggregation(AggregationBuilders.terms("group_category").field("category")) //根据category字段进行分组.aggregation(AggregationBuilders.avg("avg_price").field("price"));//根据price字段求平均值// 3.发起请求,获取响应结果SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 4.解析响应结果// 4.1获取聚合结果,Map<String, Aggregation>Aggregations aggregations = response.getAggregations();// 4.2获取group_category子聚合数据Terms terms = aggregations.get("group_category");terms.getBuckets().forEach(bucket -> {System.out.println("key:" + bucket.getKeyAsString());System.out.println("docCount:" + bucket.getDocCount());});// 4.3获取avg_price子聚合数据Avg avg = aggregations.get("avg_price");System.out.println("avg_price:" + avg.getValue());
}
输出结果:
3. 使用Spring Data Elasticsearch 操作ES
ElasticsearchRestTemplate是Spring Data Elasticsearch框架提供的API。
3.1 Spring Data概述
Spring Data是Spring家族的一个子项目,其目的:用于简化持久层的开发(如 关系型数据库、非关系型数据库、索引库的访问),并且它提供统一的API以访问各种数据存储技术。
Spring Data可以极大的简化JPA(Java Persistence API,Java持久层API)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
SpringData提供了一些XxxTemplate对象,用于简化各种数据库的操作,如:
- JdbcTemplate:JdbcTemplate是Spring Data对关系型数据库(如MySQL、Oracle等)进行操作的模板对象。它提供了一组方法,用于执行SQL语句、处理结果集、事务管理等。
- MongoTemplate:MongoTemplate是Spring Data对MongoDB进行操作的模板对象。它提供了一组方法,用于执行CRUD操作、查询、更新等。
- RedisTemplate:RedisTemplate是Spring Data对Redis进行操作的模板对象。它提供了一组方法,用于执行常见的Redis操作,如存储、获取、删除数据等。
- ElasticsearchRestTemplate:ElasticsearchRestTemplate是Spring Data对Elasticsearch进行操作的模板对象。它提供了一组方法,用于执行CRUD操作、搜索、聚合等。
3.2 Spring Data Elasticsearch 概述
Spring Data Elasticsearch基于Spring Data API对Elasticsearch进行了封装,使开发者能够更高效地使用Elasticsearch进行数据存储和搜索。
Spring Data Elasticsearch版本选择:(不同版本会存在差异)
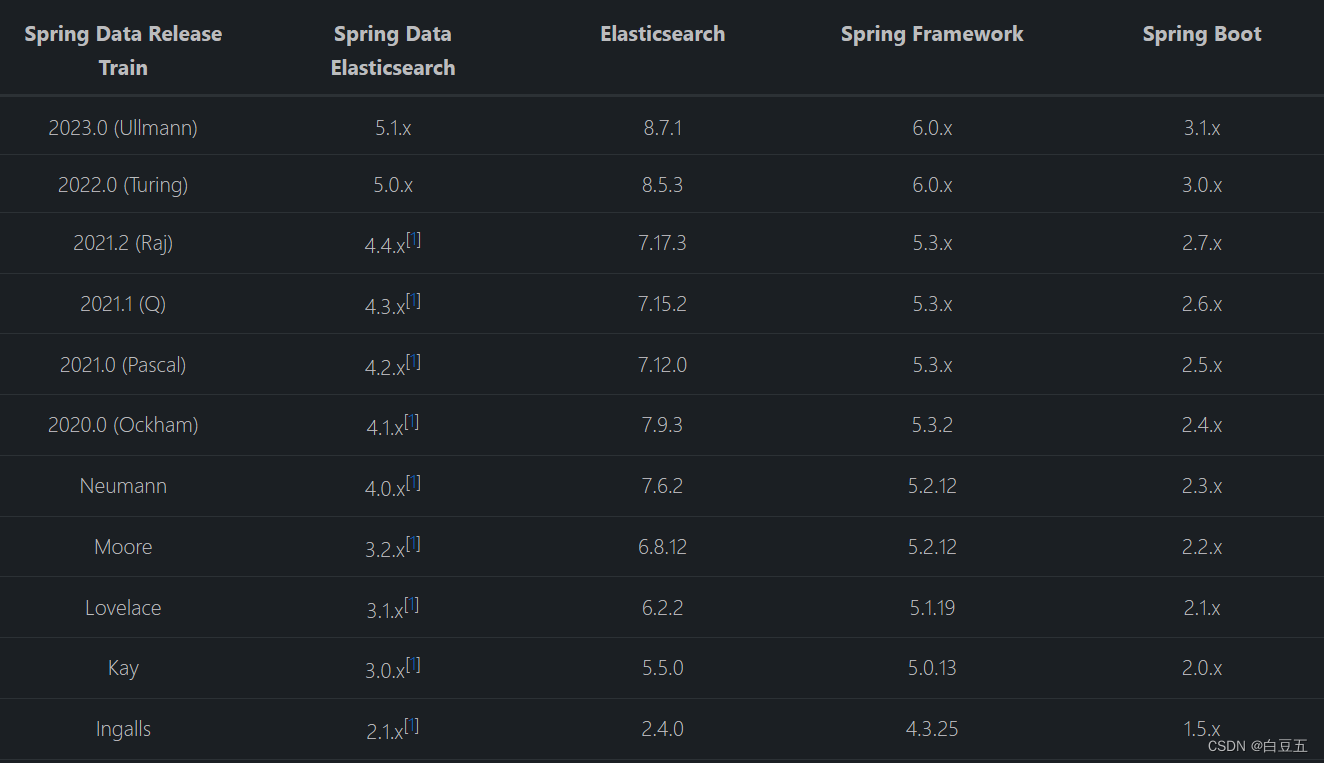
springboot2.3.x版本可以兼容elasticsearch7.x版本。
3.3 环境准备
1、创建maven项目
2、导入依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.aopmin</groupId><artifactId>SpringDataElasticsearch-demo</artifactId><version>1.0-SNAPSHOT</version><!-- springboot工程 --><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.10.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!-- Spring Data Elasticsearch --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency><!-- junit --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><!-- fastjson --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.80</version></dependency><!-- lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
3、创建启动类:
package cn.aopmin;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class SpringDataElasticsearchApplication {public static void main(String[] args) {SpringApplication.run(SpringDataElasticsearchApplication.class, args);}
}
4、在application.yml中配ES:
spring:elasticsearch:rest:uris: http://192.168.150.123:9200 # 配置es服务器的地址
5、创建实体类:(通过注解与es进行绑定)
package cn.aopmin.pojo;import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "product", // 索引库名称shards = 1, // 主分片个数replicas = 1 // 备份分片个数
)
public class Product {/*** 主键id*/// ES主键id@Idprivate Long id;/*** 商品名称*/// ES普通字段@Field(type = FieldType.Text, // 字段类型analyzer = "ik_max_word", // 建立索引用的分词器searchAnalyzer = "ik_smart", //查询时用的分词器store = true // 是否额外存储一份 (ES默认把文档字段存储在源文档_source中))private String productName;/*** 库存数量*/@Field(type = FieldType.Integer, store = true)private Integer store;/*** 价格*/@Field(type = FieldType.Double, store = true)private Double price;
}
注解含义:
1)@Document:作用在类,标记实体类为文档对象,一般有三个属性:
-
indexName:对应索引库名称
-
shards:分片数量
-
replicas:副本数量
2)@Id:作用在成员变量,标记一个字段作为id主键。
3)@Field:作用在成员变量,标记为文档的字段,并指定字段映射属性:
-
type:字段类型,取值是枚举:FieldType.xxx
-
index:是否建立索引,布尔类型,默认是true
-
store:是否存储,布尔类型,默认是false 不额外存储一份 (场景:只返回某个特定字段,此时可以提高查询效率。但是对写入效率会有影响)
-
analyzer:分词器名称:ik_max_word(建立倒排索引时所使用的分词算法)
store 的意思是:是否在 _source 之外在独立存储一份(提高查询效率,对写入会有点影响)
_source 表示源文档,当你索引数据的时候, elasticsearch 会保存一份源文档到 _source ,
如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储。这么做的目的主要是针对内容比较多的字段,放到 _source 返回的话,因为_source 是把所有字段保存为一份文档,命中后读取只需要一次 IO,包含内容特别多的字段会很占带宽影响性能。
通常我们也不需要完整的内容返回(可能只关心某个字段),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)。
6、测试
@SpringBootTest
public class SpringDataElasticsearchTest {@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate;@Testpublic void test() {System.out.println(elasticsearchRestTemplate);}
}

3.4 使用ElasticsearchRestTemplate操作ES
ElasticsearchRestTemplate是Spring Data Elasticsearch中所提供的一个操作ES的核心类,并且已经被Spring Boot实现了自动化配置。
ElasticsearchRestTemplate模板对象常用方法:
-
createIndex:创建索引
-
deleteIndex:删除索引
-
save:添加文档
-
get:根据文档ID获取文档
-
update:更新文档
-
delete:根据文档ID删除文档
-
search:执行查询操作
-
exists:检查文档是否存在
-
count:统计文档数量
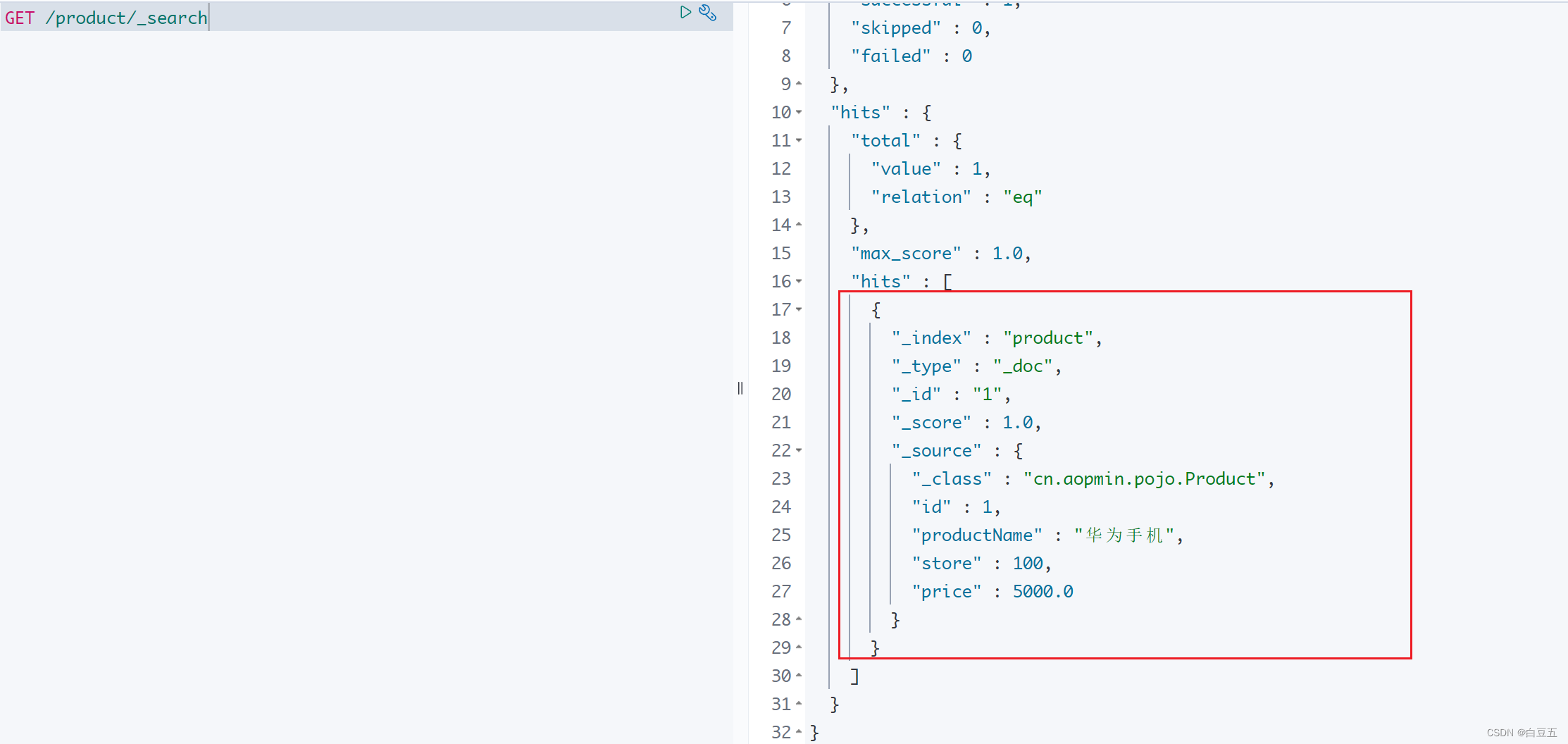
3.4.1 添加文档
package cn.aopmin.test;import cn.aopmin.pojo.Product;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;/*** 测试使用ElasticsearchRestTemplate操作ES* @author 白豆五* @version 2023/07/25* @since JDK8*/
@SpringBootTest
public class SpringDataElasticsearchTest {@Autowiredprivate ElasticsearchRestTemplate elasticsearchRestTemplate;/*** 测试添加文档*/@Testpublic void testAddDocument() {// 构造数据Product product = new Product();product.setId(1L);product.setProductName("华为手机");product.setStore(100);product.setPrice(5000.00);// 添加文档// 注意:不用提提前创建索引,Spring Data ES会根据实体类映射关系自动创建索引库elasticsearchRestTemplate.save(product);}
}
3.4.2 根据ID查询文档

/*** 测试查询文档*/
@Test
public void testGetDocument() {// 查询文档// get方法:需要指定文档id和文档所在索引库的类型_classProduct product = elasticsearchRestTemplate.get("1", Product.class);System.out.println(product);
}

3.4.3 修改文档
/*** 测试修改文档*/
@Test
public void testUpdateDocument() {// 准备数据Document document = Document.create();document.put("price", 1899);// 构造一个更新对象UpdateQuery// 参数1:文档id// 参数2:修改的文档数据UpdateQuery updateQuery = UpdateQuery.builder("1").withDocument(document).build();// 修改文档// 参数1:updateQuery对象// 参数2:指定文档所在的索引库elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of("product"));
}

3.4.4 删除文档
/*** 测试删除文档*/
@Test
public void testDeleteDocument() {// 删除文档// delete方法:需要指定文档id和文档类型elasticsearchRestTemplate.delete("1", Product.class);
}
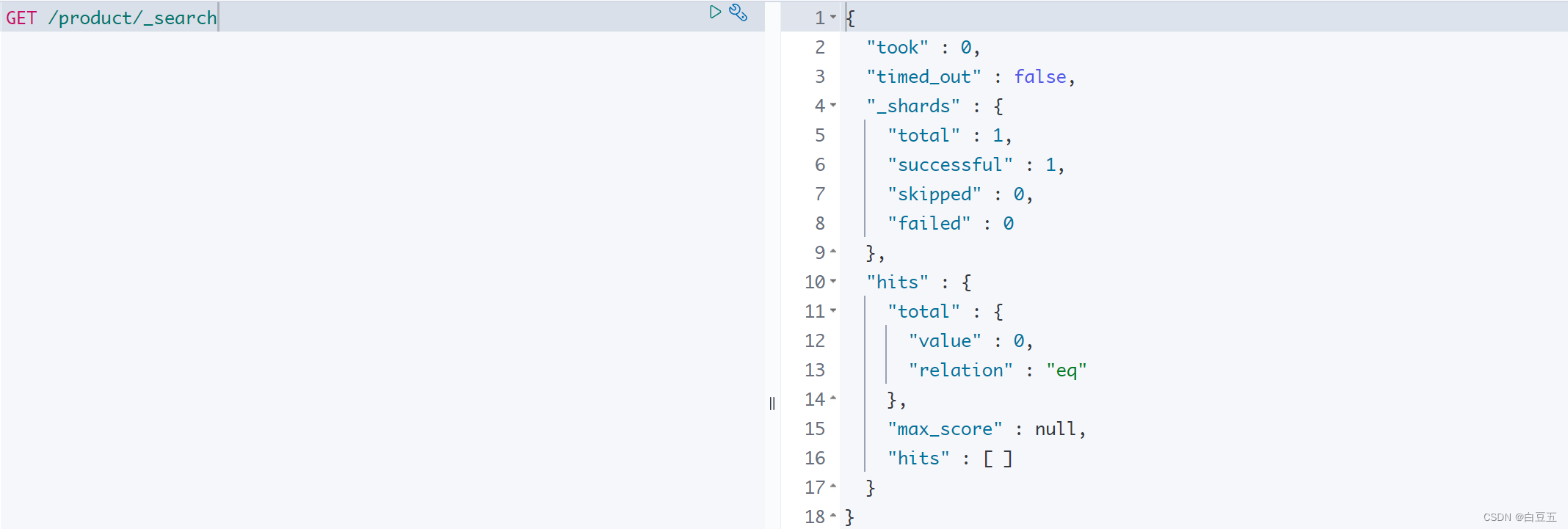
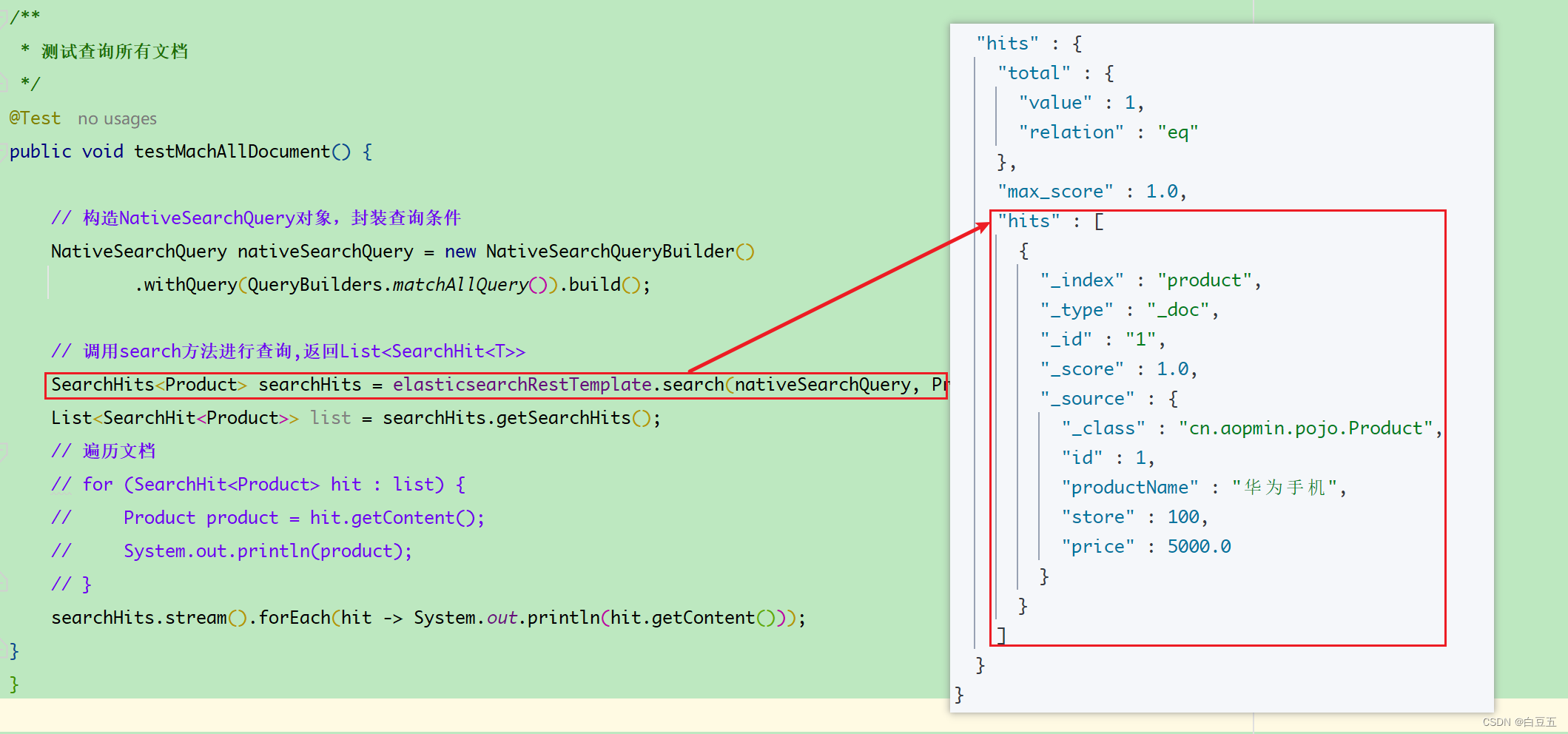
3.4.5 查询所有文档
/*** 测试查询所有文档*/
@Test
public void testMachAll() {// 构造NativeSearchQuery对象,封装查询条件NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).build();// 调用search方法进行查询,返回List<SearchHit<T>>SearchHits<Product> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Product.class);List<SearchHit<Product>> list = searchHits.getSearchHits(); //get方法// 遍历文档// for (SearchHit<Product> hit : list) {// Product product = hit.getContent();// System.out.println(product);// }searchHits.stream().forEach(hit -> System.out.println(hit.getContent()));
}

3.4.6 高亮查询
/*** 测试高亮查询*/
@Test
public void testHighlight() {// 构造高亮参数HighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("productName"); // 设置高亮字段highlightBuilder.preTags("<em>"); // 设置高亮字段的前缀highlightBuilder.postTags("</em>"); // 设置高亮字段的后缀// 创建NativeSearchQuery对象,封装查询条件NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchQuery("productName", "华为")).withHighlightBuilder(highlightBuilder) // 设置高亮参数.build();// 调用search方法进行查询SearchHits<Product> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Product.class);// 遍历操作searchHits.stream().forEach(productSearchHit -> System.out.println(productSearchHit));
}

3.4.7 分页查询
/*** 测试分页查询*/
@Test
public void testPage() {// 构造NativeSearchQuery对象,封装查询条件NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).withPageable(PageRequest.of(0, 2)) // 设置分页参数.build();// 调用search方法进行查询SearchHits<Product> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Product.class);// 遍历操作searchHits.stream().forEach(productSearchHit -> System.out.println(productSearchHit));
}
3.4.8 聚合查询
1、向Product实体类中添加新字段,类型设置为keyword(完整的单词,不进行分词):
/*** 分类*/
@Field(type = FieldType.Keyword)
private String category;
2、在kibana中执行DSL命令删除索引库:DELETE /product
3、添加数据
/*** 测试批量插入数据*/
@Test
public void testBulkAddDocument() {// 准备数据Product product1 = new Product(1L, "华为手机", 200, 2000.00, "华为");Product product2 = new Product(2L, "华为笔记本电脑", 100, 5699.00, "华为");Product product3 = new Product(3L, "VIVO手机", 200, 3600.00, "vivo");// 构造IndexQuery对象List<IndexQuery> indexQueryList = new ArrayList<IndexQuery>();indexQueryList.add(new IndexQueryBuilder().withObject(product1).build());indexQueryList.add(new IndexQueryBuilder().withObject(product2).build());indexQueryList.add(new IndexQueryBuilder().withObject(product3).build());// 批量添加文档elasticsearchRestTemplate.createIndex(Product.class); // 创建索引库elasticsearchRestTemplate.putMapping(Product.class); // 创建映射关系elasticsearchRestTemplate.bulkIndex(indexQueryList, IndexCoordinates.of("product"));
}

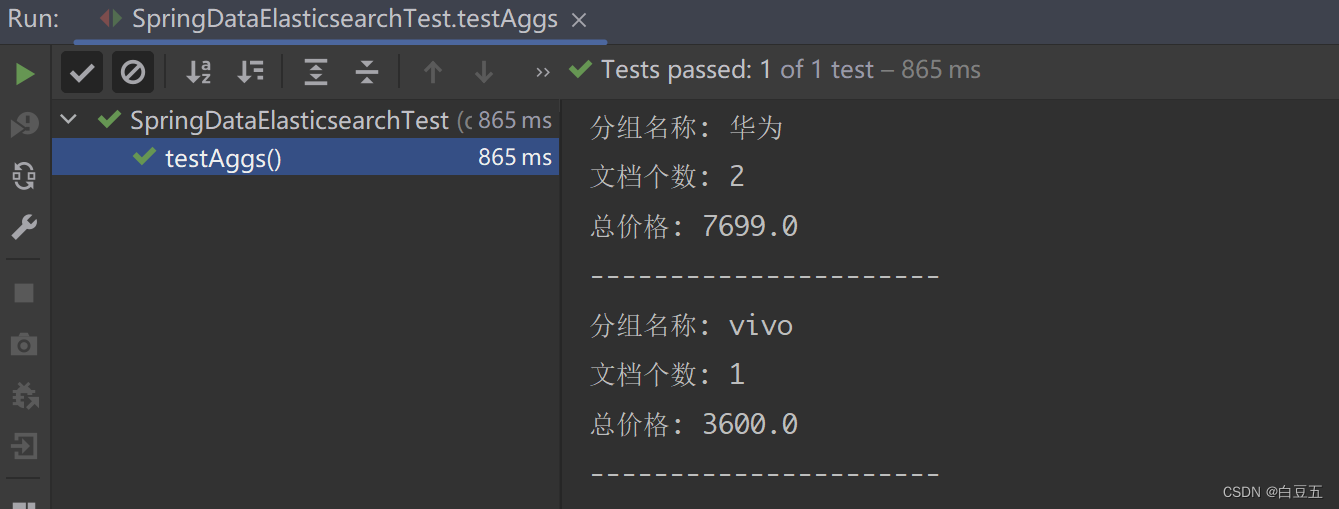
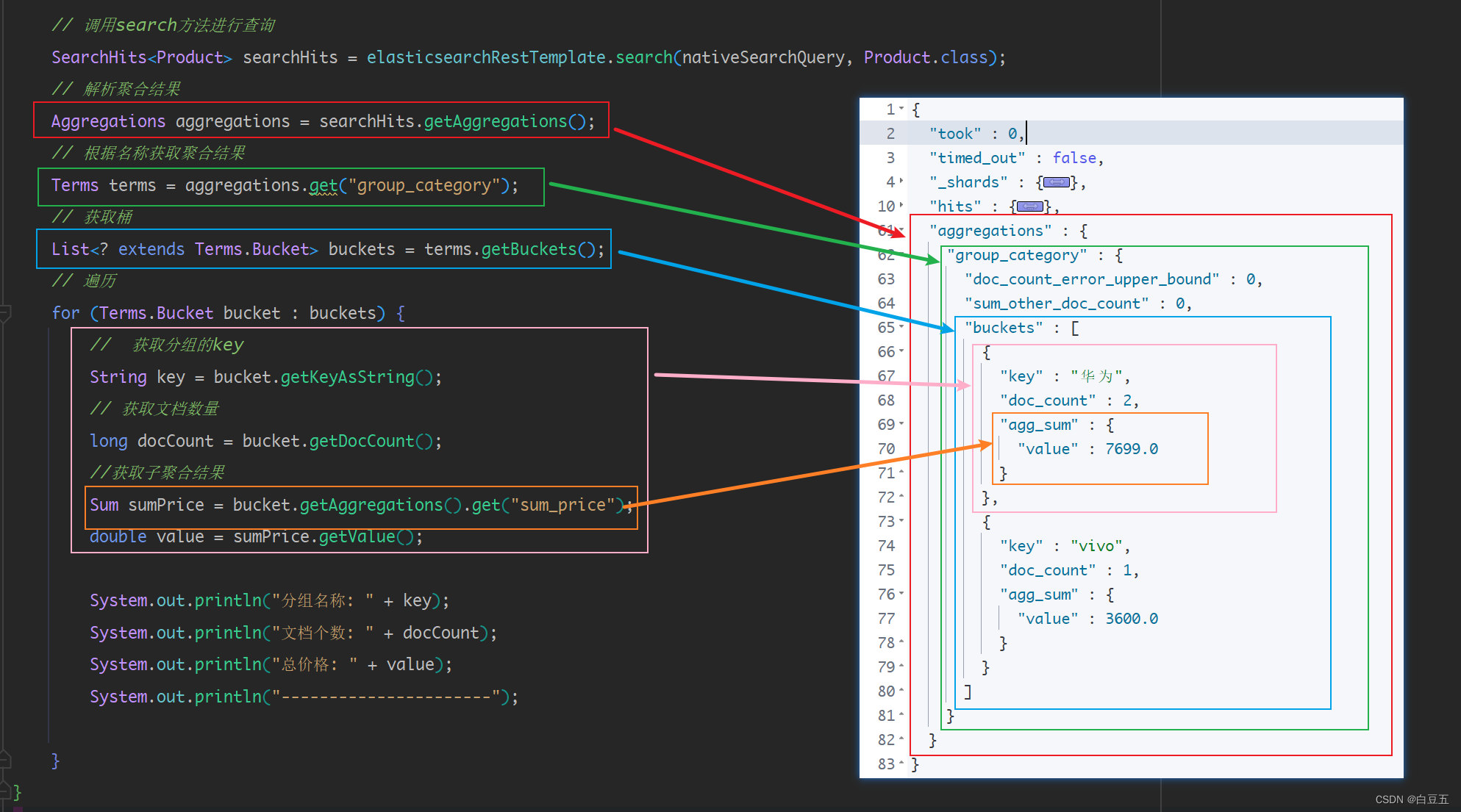
4、聚合查询(terms、sum)
/*** 测试聚合查询*/
@Test
public void testAggs() {// 构造聚合查询对象AbstractAggregationBuilder aggregationBuilder = AggregationBuilders// 分组查询,size=2表示查询前两个分组.terms("group_category").field("category").size(2)// 子聚合查询.subAggregation(AggregationBuilders.sum("sum_price").field("price"));// 构造NativeSearchQuery条件查询对象NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()) // 设置查询条件.addAggregation(aggregationBuilder) // 设置聚合查询参数// 各种查询条件.....build();// 调用search方法进行查询SearchHits<Product> searchHits = elasticsearchRestTemplate.search(nativeSearchQuery, Product.class);// 解析聚合结果Aggregations aggregations = searchHits.getAggregations();// 根据名称获取聚合结果Terms terms = aggregations.get("group_category");// 获取桶List<? extends Terms.Bucket> buckets = terms.getBuckets();// 遍历for (Terms.Bucket bucket : buckets) {// 获取分组的keyString key = bucket.getKeyAsString();// 获取文档数量long docCount = bucket.getDocCount();//获取子聚合结果Sum sumPrice = bucket.getAggregations().get("sum_price");double value = sumPrice.getValue();System.out.println("分组名称: " + key);System.out.println("文档个数: " + docCount);System.out.println("总价格: " + value);System.out.println("----------------------");}
}
3.5 使用ElasticsearchRepository接口操作ES
ElasticsearchRepository接口常用方法:
- 保存单个文档:
void save(T entity) - 保存多个文档:
Iterable<T> saveAll(Iterable<T> entities) - 根据 ID 获取文档:
Optional<T> findById(String id) - 判断文档是否存在:
Boolean existsById(String id) - 获取所有文档:
Iterable<T> findAll()- 方法参数:Sort :自定义排序
- 方法参数:Pageable:分页对象
- 获取多个ID 的文档:
Iterable<T> findAllById(Iterable<String> ids) - 获取文档数量:
long count() - 删除单个文档:
void deleteById(String id) - 删除多个文档:
void deleteAll(Iterable<? extends T> entities) - 删除所有文档:
void deleteAll() - 条件查询:
search()
定义持久层接口:
package cn.aopmin.dao;import cn.aopmin.pojo.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;/*** 自定义接口去继承ElasticsearchRepository接口,实现对ES的操作* ElasticsearchRepository<Product, Long> Product:实体类 Long:主键类型*/
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {}
示例1:根据文档id查文档(findById)
package cn.aopmin.test;import cn.aopmin.dao.ProductRepository;
import cn.aopmin.pojo.Product;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.Optional;/*** 测试ElasticsearchRepository接口* @author 白豆五* @version 2023/07/25* @since JDK8*/
@SpringBootTest
public class ElasticsearchRepositoryTest {@Autowiredprivate ProductRepository productRepository; //自定义持久层接口/*** 测试根据id查询文档*/@Testpublic void test() {Optional<Product> optional = productRepository.findById(1L);Product product = optional.get();System.out.println(product);}
}

示例2:查询所有(findAll)
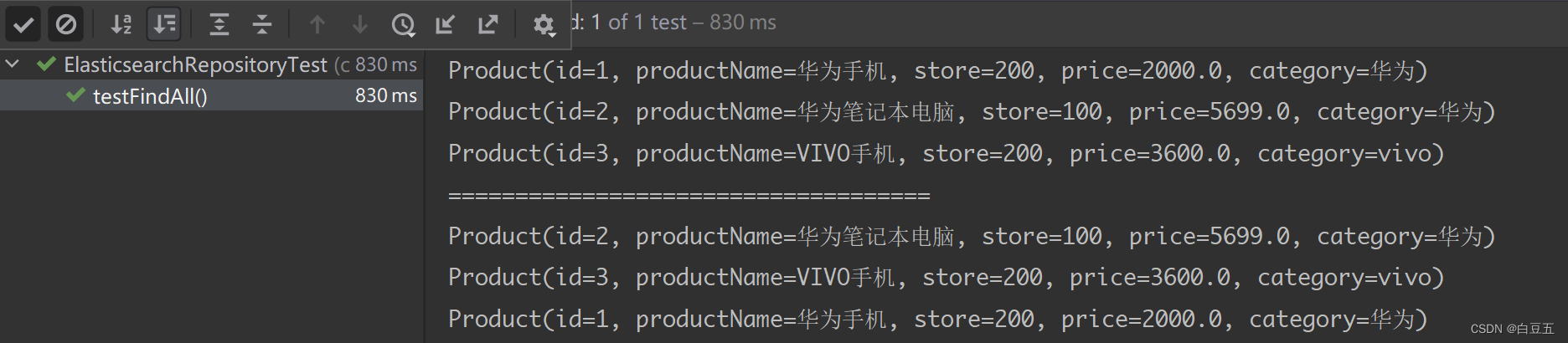
/*** 测试查询所有文档*/
@Test
public void testFindAll() {// 查询所有文档Iterable<Product> iterable = productRepository.findAll();// 遍历迭代器对象for (Product product : iterable) {System.out.println(product);}System.out.println("====================================");// 查询所有,对查询结果按照price字段进行排序Iterable<Product> iterable2 = productRepository.findAll(Sort.by(Sort.Direction.DESC, "price"));iterable2.forEach(System.out::println);
}
示例3:条件查询(调用search方法,通过QueryBuilders构建查询条件)
/*** 测试条件查询*/
@Test
public void testMatchAll(){Iterable<Product> iterable = productRepository.search(QueryBuilders.matchAllQuery());iterable.forEach(System.out::println);
}

示例4:分页查询
/*** 测试分页查询*/
@Test
public void testPage() {// 分页对象Pageable Pageable = PageRequest.of(0, 2);// 分页查询// productRepository.search(QueryBuilders.matchAllQuery(), Pageable);Page<Product> page = productRepository.findAll(Pageable);// 获取总记录数System.out.println("total:" + page.getTotalElements());// 获取当前页码System.out.println("当前页码:" + (page.getNumber() + 1));// 获取总页数System.out.println("总页数:" + page.getTotalPages());// 获取当前页数据page.forEach(System.out::println);
}

示例5:自定义查询方法(findByXxx)
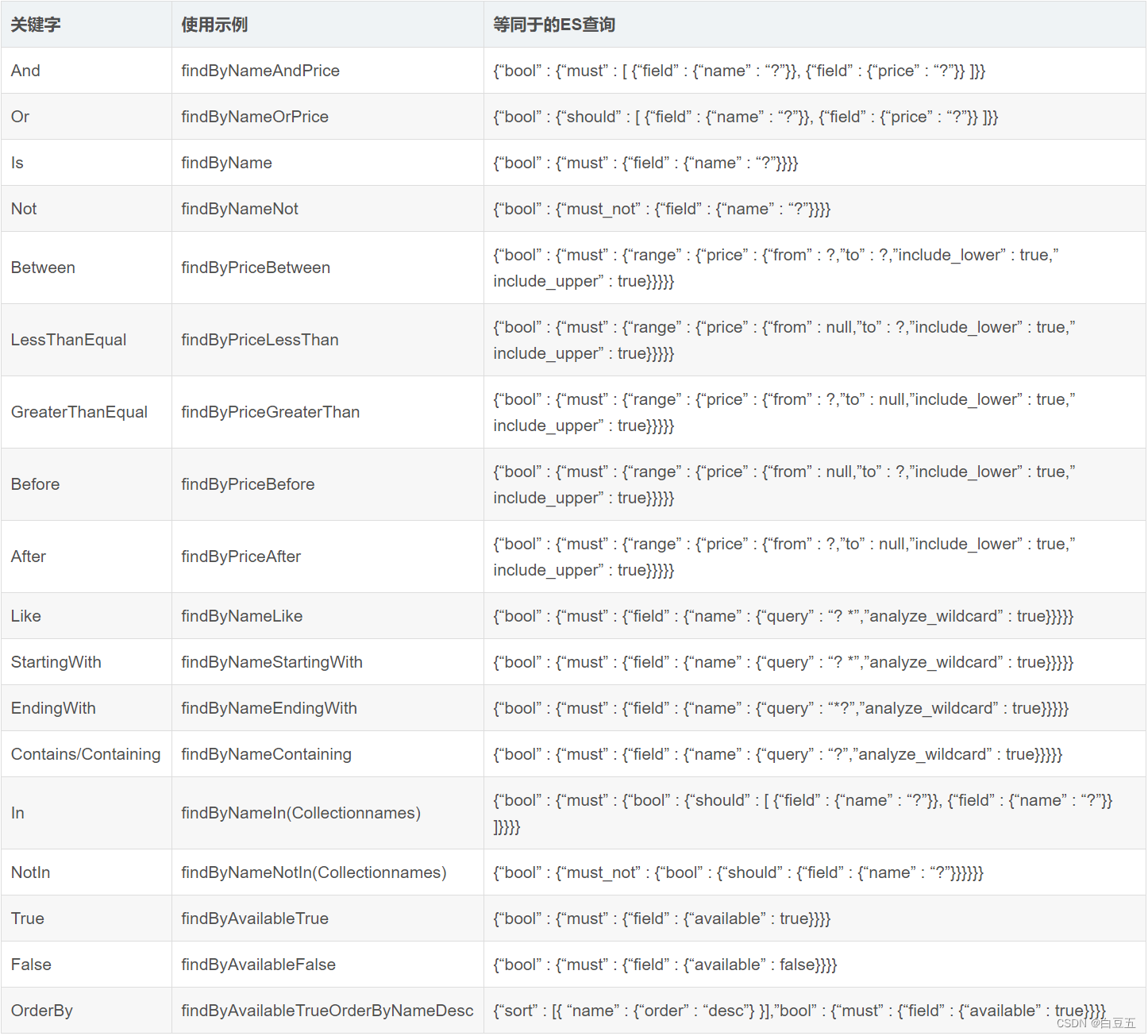
Spring Data 支持自定义查询方法,但是方法命名需要遵循一定的命名规范,这样SpringData框架才会根据方法名自动实现相关查询操作。
比如:findByName,表示根据字段name进行查询,它会自动帮你完成,无需写实现类。
方法命名规范:(参考:https://blog.csdn.net/hzj_java/article/details/118096157)
① 在持久层接口中定义方法(方法名会自动提示)
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {// 查询指定价格区间的文档public Iterable<Product> findByPriceBetween(Double begin, Double end);
}
②测试
/*** 测试自定义查询*/
@Test
public void testFindByPriceBetween() {Iterable<Product> iterable = productRepository.findByPriceBetween(1000.0, 3000.0);iterable.forEach(System.out::println);
}

小节:
操作es有两种技术方案:
方案一:使用原生API(RestHighLevelClient),可以更灵活地操作Elasticsearch。(底层代码)
方案二:使用Spring Data Elasticsearch,可以通过ElasticsearchRestTemplate和ElasticsearchRepository 接口操作ES。
- ElasticsearchRestTemplate
- ElasticsearchRepository 接口
- 使用默认的crud方法
- 自定义查询方法 findByXxx




)


)
|ACM模式)

)




【数学公式(基础)、矩阵、多行公式】)


)
