
Hi,你好。我是茶桁。
之前两节课的内容,我们讲了一下相关性、显著特征、机器学习是什么,KNN模型以及随机迭代的方式取获取K和B,然后定义了一个损失函数(loss函数),然后我们进行梯度下降。
可以说是又帮大家回顾了一下深度学习的相关知识,但是由于要保证整个内容的连续性,所以这也没办法。
那么接下来的课程里,咱们要来看一下神经网络,怎么样去拟合更加复杂的函数,什么是激活函数,什么是神经网络,什么是深度学习。
然后我们还要来学习一下反向传播,以及如何实现自动的反向传播,什么是错误排序以及怎么样自动的去计算元素的gradients。梯度怎么样自动求导。
从简单的线性回归函数到复杂的神经网络,从人工实现的求导到自动求导。那我们现在来跟大家一起来看一下。
上一节课结束的时候我们说过,现实生活中绝大多数事情的关系都不是线性的。
比方说,我工作的特别努力,然后就可以升职加薪了。但是其实有可能工作的努力程度和升职加薪程度之间的关系可能并不是一条直线的函数关系。
可能一开始不管怎么努力,薪水都没有什么大的变化,可是忽然有了一个机会,薪水涨的幅度很大,但是似乎没怎么努力。再之后,又趋于一条平行横轴的线,不管怎么努力都无法往上有提升。这是不是咱们这些社畜的真实写照?
在现实生活中有挺多这样的问题,这样的对应关系。比如艾宾浩斯曲线,再比如细菌生长曲线,很多很多。
经过刚刚的分析我们知道了除了线性函数(kx+b),还有一种常见的函数关系式,是一种s型的一种函数,这种s形的函数在我们整个计算机科学里我们称呼它为sigmoid函数:
S i g m o i d : f ( x ) = σ ( x ) = 1 1 + e − x \begin{align*} Sigmoid: f(x) = \sigma (x) = \frac{1}{1+e^{-x}} \end{align*} Sigmoid:f(x)=σ(x)=1+e−x1
这是一个非常常见的函数。我们可以节用NumPy库来用代码将它实现出来:
def sigmoid(x):return 1 / (1 + np.exp(-x))
把它的图像描述出来:
sub_x = np.linspace(-10, 10)
plt.plot(sub_x, sigmoid(sub_x))
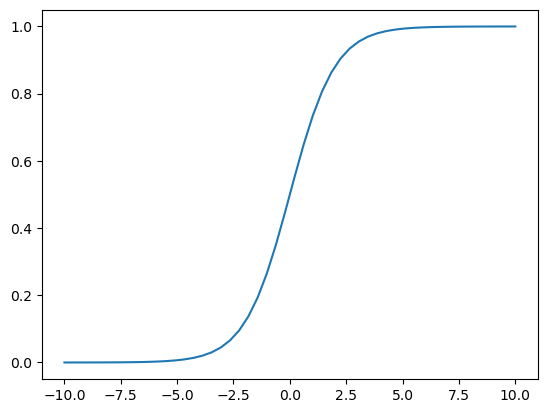
然后我们来利用一下这个函数,我们定义一个随机线性函数, 然后和sigmoid函数一起应用画5根不同的线:
def random_linear(x):k, b = random.random(), random.random()return k*x + bfor _ in range(5):plt.plot(sub_x, random_linear(sigmoid(random_linear(sub_x))))
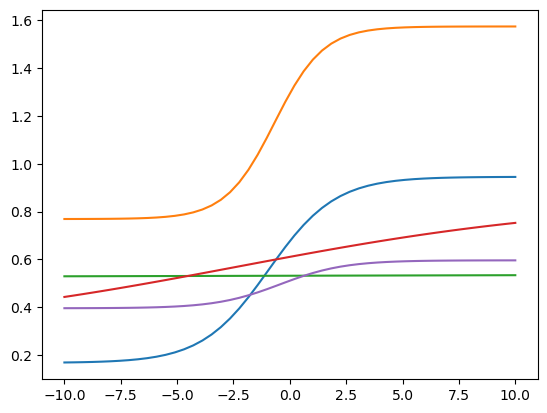
这个里面起变化的就是k和b这两个参数,那我们来调节k和b的画,就可以变化这条曲线的样式。
除了以上这些函数,我们生活中还会遇到更复杂的函数,甚至很有可能是一个复杂的三维图像。
那这个时候,我们该如何去拟合这么多复杂的函数呢?
一个比较直接的方法,当然就是我们人为的去观察,比如这个类似于sin(x):
还有这个k*sin(kx+b)+b:
当然,这样理论上是可以的,每当我们遇到一个场景之后就自己去提出来一个函数模型,然后把函数模型让机器去拟合出来。
但是这样就会有一个问题,大家就会发现假如你是那个工作者,那你熊猫眼会很严重,因为我们要看到很多这样的场景。现实生活中的问题实在太多了,每一天我们都可能会遇到新的函数。
如果我们每观察一个情况就要去考察,去思考它的这个函数模型是什么,你就会发现你的工作量无穷无尽。而且你会发现一个问题:现在函数能够可视化的,但是如果在现实生活中有很多场景的函数是无法可视化的。
那么这个时候我们就需要其他的一些方法能够拟合更加复杂的函数,这个时候我们怎么样不通过去观察它就能够拟合出复杂的函数呢?其实很简单。
有一个老头子叫做Hinton,他是2018年图灵奖的获得者。

他在一九八几年的时候发了一篇文章,经过他多年的研究,发现人的脑能够做出非常复杂的一些行为,其实我们这个神经元的类型都是很有限的,并没有很多奇怪的东西,就是有很多不同的节点,其实就那么几种。人类就能够进行复杂行为,背后其实就是一些基本的神经元的一些组合。
只不过这些基本的在组合还有一种形式,就是输入进来的会经过一个叫做activate neurons,就是激活单元,去做一个非线性变化。然后经过不断的这种非线性变化,最后就拟合出来非常复杂的信号。
那非线性变化的这些函数其实都是一样的,就他们背后的逻辑都是一样。只不过有的时候非线性变化的多,有的时候非线性变化的少。
讲了这么多不直观的东西,我们来看点实际的。
for _ in range(5):i = random.choice(range(len(sub_x)))output_1 = np.concatenate((random_linear(sub_x[:i]), random_linear(sub_x[i:])))plt.plot(sub_x, output_1)
然后我们来做两件事,第一个是将k,b随机方式改成normalvariate(), 第二个在上面的基础上再做一次拆分:
def random_linear(x):k, b = random.normalvariate(0,1), random.normalvariate(0,1)return k * x + bfor _ in range(5):i = random.choice(range(len(sub_x)))linear_output = np.concatenate((random_linear(sub_x[:i]), random_linear(sub_x[i:])))i_2 = random.choice(range(len(linear_output)))output = np.concatenate((sigmoid(linear_output[:i_2]), sigmoid(linear_output[i_2:])))plt.plot(sub_x, output)
我们来看,这个时候你会发现他生成的这个图像比较奇怪。它生成了很多奇怪的函数,每一次根据不同的参数就形成了不同的函数图像。
迄今为止就两个函数,一个sigmoid,一个random linear,但是它生成了很多奇怪的函数。
面对这种函数,这么多层出不穷列举都列举不完的函数,我们怎么样能够每次遇到一个问题就得去提出它这个函数到底是什么样。而且关键是有可能函数维度高了之后都观察不到它是什么关系。
所以我们就会去考虑,怎么样能够让机器自动的去拟合出来更复杂的函数呢?
我们可以用基本模块经过组合拼接,然后就能够形成复杂函数。而在组合拼接的过程中,我们只需要让机器自动的去把K1、K2、B1、B2等等这些参数给它拟合出来就行。
也就是说我们可以通过参数的变化来拟合出来各种各样的函数。
这其实就是深度神经网络的一个核心思想。就是用基本的模块像大家玩积木一样,并不会有很多积木类型给你,只有一些基本的东西,但是通过这些基本的可以造出来特别多复杂的东西。
这个就是背后的原理,通过函数的复合和叠加。这种变化的引起都是由一个线性函数加上一个非线性函数。
其实很大程度上由我们大脑里边这种简单东西可以构成复杂东西得到了启示。只不过人的大脑里边,在脑神经科学里面把这种非线性变化呢叫做activate neurons,叫做激活神经元。在程序里,我们把这种非线性函数叫activation function,激活函数。
激活函数的作用就是为了让我们的程序能够拟合非线性关系。如果没有激活函数,咱们的程序永远只能拟合最简单的线性关系,而现实生活中绝大多数关系并不是并不是线性关系。
让机器来拟合更加复杂函数的这种方法,和我们的神经网络很像,就是咱们现在做的这个事情,我们就把它命了个名叫做神经网络.
早些年的时候科学家们有一个理论,人们把一组线性和非线性变化叫做一层。在以前的时候科学家们发现这个层数不能多于三层,就是神经网络的层数不能多于三层。
为什么不能多于3层?其实最主要的不是计算量太大的问题,最核心的原因是什么?
假设我们有一个f(x)和一个x组成一个平面坐标系,在其中有无数的点,当我们在做拟合的时候,发现了一条直线可以拟合,但是实际上呢,当我们将数据量继续放大的时候,才发现我们的拟合的直线偏离的非常厉害。
我们之前在机器学习的课程里说过,我们要有高精度,就需要有足够的数据量。如果这个时候变成一个三维问题,就需要更多的数据量。没有更多的数据的话,就好比有一个平板在空中,它会摇来摇去,你以为拟合了一个正确的平板,但其实完全不对。
那这个时候,每当我们所需要拟合的参数多一个,多少数据量认为是足够的?这个不一定。这个和整个问题的复杂程度有关系。
后来科学家们发现一个规律,在相似的问题下,我们需要拟合的参数多一个,需要的数据就要多一个数量级。
当变成三层的时候,会发现参数就更多了,而参数变得特别多就会需要特别多的数据量。而早在一九八几年、一九九几年的时候并没有那么多的数据量,就会产生数据量不够的情况,所以模型在现实生活中没法用。
但是随着到二零零几年,再到二零一几年之后,产生了大量的数据。就给我们做函数拟合提供了数据资源,所以数据量是最重要的,数据量决定了这个东西能不能做。而其他的一些,比方说计算、GPU啊等等,它是加速这个过程的,是让它更方便。
那么后来我们把层数超过3层的就叫深度神经网络,机器学习就简称深度学习。这是为什么深度学习在二零一几年的时候才开始火起来。
那现在我们把上一节课的这个问题再拿过来,现在来想想,如果我们把房价的函数关系也写成类似的,linear和sigmoid之间的关系,那会怎么样呢?
首先,我们的k和b就会多加一组:
for t in range(total_times):k1 = k1 + (-1) * loss对k1的偏导b1 = b1 + (-1) * loss对b1的偏导k2 = k2 + (-1) * loss对k2的偏导b2 = b2 + (-1) * loss对b2的偏导loss_ = loss(y, model(X_rm, k1, b1, k2, b2))...
然后我们的model也会多接受了一组参数,并且我们要将其内部函数关系做一个叠加:
def model(x, k1, k2, b1, b2):linear1_output = k1 * x + b1sigmoid_output = sigmoid(linear1_output)linear2_output = k2 * sigmoid_output + b2return linear2_output
在这个时候我们要求解的时候就会发现有个问题,我们现在的loss是这样的:
l o s s = 1 N ( y i − y ^ ) 2 = 1 N [ y 1 − ( k 2 1 1 + e − ( k 1 x + b 1 ) + b 2 ) ] 2 \begin{align*} loss & = \frac{1}{N}(y_i - \hat y)^2 \\ & = \frac{1}{N} \begin{bmatrix} y_1 - (k_2 \frac{1}{1+e^{-(k_1x+b_1)}}+b_2) \end{bmatrix} ^2 \end{align*} loss=N1(yi−y^)2=N1[y1−(k21+e−(k1x+b1)1+b2)]2
似乎变得有点过于复杂。当前情况下,我们是可以复杂的去求导,但是当函数继续复杂下去的时候,怎么把这个导数求出来呢?
函数还可以继续叠加, 层数还可以写的越来越多。那么怎么样才能给它求出它的导数呢?
我们再将上面的式子做个变化:
1 N [ l 2 ( σ ( l 1 ( x ) ) ) − y 1 ] 2 \frac{1}{N}[l_2(\sigma(l_1(x))) -y_1]^2 N1[l2(σ(l1(x)))−y1]2
这样我们就可以将问题进行简化,我们上面代码里loss对k1的偏导就可以写成:
∂ l o s s ∂ l 2 ⋅ ∂ l 2 ∂ σ ⋅ ∂ σ ∂ l 1 ⋅ ∂ l 1 ∂ k 1 \frac{\partial loss}{\partial l_2} \cdot \frac{\partial l_2}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial l_1} \cdot \frac{\partial l_1}{\partial k_1} ∂l2∂loss⋅∂σ∂l2⋅∂l1∂σ⋅∂k1∂l1
同理,loss对b1的偏导就是:
∂ l o s s ∂ l 2 ⋅ ∂ l 2 ∂ σ ⋅ ∂ σ ∂ l 1 ⋅ ∂ l 1 ∂ b 1 \frac{\partial loss}{\partial l_2} \cdot \frac{\partial l_2}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial l_1} \cdot \frac{\partial l_1}{\partial b_1} ∂l2∂loss⋅∂σ∂l2⋅∂l1∂σ⋅∂b1∂l1
这个时候,问题就变成一个可解决的了。
∂ l o s s ∂ l 2 \frac{\partial loss}{\partial l_2} ∂l2∂loss其实就等于 2 N ( l 2 − y 1 ) \frac{2}{N}(l_2 - y_1) N2(l2−y1)。
我们继续往后看第二部分,那么这个时候我们可以得到 l 2 = k 2 ⋅ σ + b 2 l_2 = k_2 \cdot \sigma + b_2 l2=k2⋅σ+b2,那 ∂ l 2 ∂ σ \frac{\partial l_2}{\partial \sigma} ∂σ∂l2就等于 k 2 k_2 k2。
再来看第三部分, σ ′ ( x ) = σ ( x ) ⋅ ( 1 − σ ( x ) \sigma'(x) = \sigma(x) \cdot (1- \sigma(x) σ′(x)=σ(x)⋅(1−σ(x), 所以 ∂ σ ∂ l 1 = σ ⋅ ( 1 − σ ) \frac{\partial \sigma}{\partial l_1} = \sigma \cdot (1 - \sigma) ∂l1∂σ=σ⋅(1−σ)。
最后第四部分, ∂ l 1 ∂ k 1 = x \frac{\partial l_1}{\partial k_1} = x ∂k1∂l1=x。
这样,我们整个式子就应该变成这样:
2 N ( l 2 − y 1 ) ⋅ k 2 ⋅ σ ⋅ ( 1 − σ ) ⋅ x \begin{align*} \frac{2}{N}(l_2 - y_1) \cdot k_2 \cdot \sigma \cdot (1 - \sigma) \cdot x \end{align*} N2(l2−y1)⋅k2⋅σ⋅(1−σ)⋅x
这样的话,我们就把loss对于K1的偏导就求出来了,这里算是一个突破。本来看起来是很复杂的的一个问题,我们将其拆分成了这样的一种形式。那这种形式,我们把它称作「链式求导」。
但是现在其实还有个问题,这整个一串链式求导的东西是我们通过眼睛求出来的,但是现在怎么样让机器自动的把这一串东西写出来?就是机器怎么知道是这些数字乘到一起?
换句话说,我们现在把这个问题再形式化一下,定义一个问题。
给定一个模型定义,这个模型里边包含参数{k1, k2, b1, b2},我们要构建一个程序,让它能够求解出k1,k2,b1,b2的偏导是多少。
如果我们想解决这个问题,我们首先要思考一下, k 1 , k 2 , b 1 , b 2 , l 1 , l 2 , σ , y t r u e , l o s s k_1, k_2, b_1, b_2, l_1, l_2, \sigma, y_{true}, loss k1,k2,b1,b2,l1,l2,σ,ytrue,loss, 它们之间是一种什么样的关系。
观察一下我们会发现它们之间的关系是这样的:
{ k 1 , b 1 , x } → l 1 → σ , { σ , k 2 , b 2 } → l 2 , { l 2 , y t r u e } → l o s s → 表示的 是 ′ 输出 到 ′ 的关系。 \begin{align*} & \{k_1, b_1, x\} \to l_1 \to \sigma, \\ & \{\sigma, k_2, b_2\} \to l_2, \\ & \{l_2, y_{true}\} \to loss \\ & \to 表示的是'输出到'的关系。 \end{align*} {k1,b1,x}→l1→σ,{σ,k2,b2}→l2,{l2,ytrue}→loss→表示的是′输出到′的关系。
要用计算机去表示这种关系,是典型的一个数据结构问题,怎么样让计算机合理的去存储它,你会发现这个是一个图案。
这种节点和节点之间通过关系连接起来的就把它叫做图,我们把它先表示成图的样子。
computing_graph = {'k1': ['L1'],'b1': ['L1'],'x': ['L1'],'L1':['sigmoid'],'sigmoid': ['L2'],'k2': ['L2'],'b2': ['L2'],'L2': ['loss'],'y': ['loss']
}nx.draw(nx.DiGraph(computing_graph), with_labels = True)
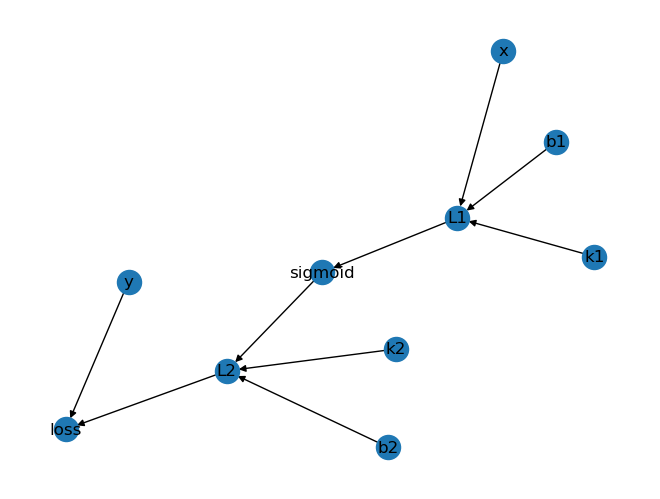
这个就是我们要表达的一个关系, 我们把这个变成图。
现在我们将给定的一个model,这样一个函数变成了这样一张图。计算机里有现成的各种各样的图算法,我们就可以来计算这个图之间的关系了。
现在我们就要根据这个图的表示来思考我们如何求loss对K1的偏导。那其实,我们可以发现k1在末尾出,一直在向前输入直到loss。换句话说,我们可以通过k1一直往图的终点去寻找来找到它求导的这个过程。
也就是说,只要我们的能把模型变成一个图,然后我们就可以根据这些点去找到它们之间节点的对应关系,我们就可以通过这个节点关系来获得它的求导过程了。
那下一节课呢,我们就继续来看一下,如何将这个图的关系,变成一个自动求导的过程。









)









