ONNX格式模型量化
深度学习模型量化支持深度学习模型部署框架支持的一种轻量化模型与加速模型推理的一种常用手段,ONNXRUNTIME支持模型的简化、量化等脚本操作,简单易学,非常实用。
ONNX 模型量化常见的量化方法有三种:动态量化、静态量化、感知训练量化,其中ONNXRUNTIME支持的动态量化机制非常简单有效,在保持模型精度基本不变的情况下可以有效减低模型的计算量,可以轻松实现INT8量化。
1. 动态量化:此方法动态计算激活的量化参数(刻度和零点)。
2. 静态量化:它利用校准数据来计算激活的量化参数。
3. 量化感知训练量化:在训练时计算激活的量化参数,训练过程可以将激活控制在一定范围内。
当前ONNX支持的量化操作主要有:

Opset版本最低不能低于10,低于10不支持,必须重新转化为大于opset>10的ONNX格式。模型量化与图结构优化有些是不能叠加运用的,模型开发者应该意识这点,选择适当的模型优化方法。
ONNXRUNTIME提供的模型量化接口有如下三个:
1. quantize_dynamic:动态量化
2. quantize_static:静态量化
3. quantize_qat:量化感知训练量化
FP16量化
首先需要安装好ONNX支持的FP16量化包,然后调用相关接口即可实现FP16量化与混合精度量化。安装FP16量化支持包命令行如下:
pip install onnx onnxconverter-common实现FP16量化的代码如下:
import onnx
from onnxconverter_common import float16model = onnx.load("path/to/model.onnx")
model_fp16 = float16.convert_float_to_float16(model)
onnx.save(model_fp16,"path/to/model_fp16.onnx")INT8量化
最简单的量化方式是动态量化与静态量化。选择感知训练量化机制,即可根据输入ONNX格式模型生成INT8量化模型,代码如下:
import onnx
from onnxruntime.quantization import quantize_qat, QuantTypemodel_fp32 = "path/to/model.onnx"
model_quant = "path/to/model.quant.onnx"# 加载FP32模型
onnx_model = onnx.load(model_fp32)# 进行量化
quantized_model = quantize_qat(model=onnx_model,quantization_type=QuantType.QInt8,force_fusions=True
)# 保存量化模型
onnx.save_model(quantized_model, model_quant)案例说明
YOLOv8自定义模型ONNXINT8量化版本对象检测演示
以作者训练自定义YOLOv8模型为例,导出DM检测模型大小为,对比导出FP32版本与INT8版本模型大小,相关对比信息如下:
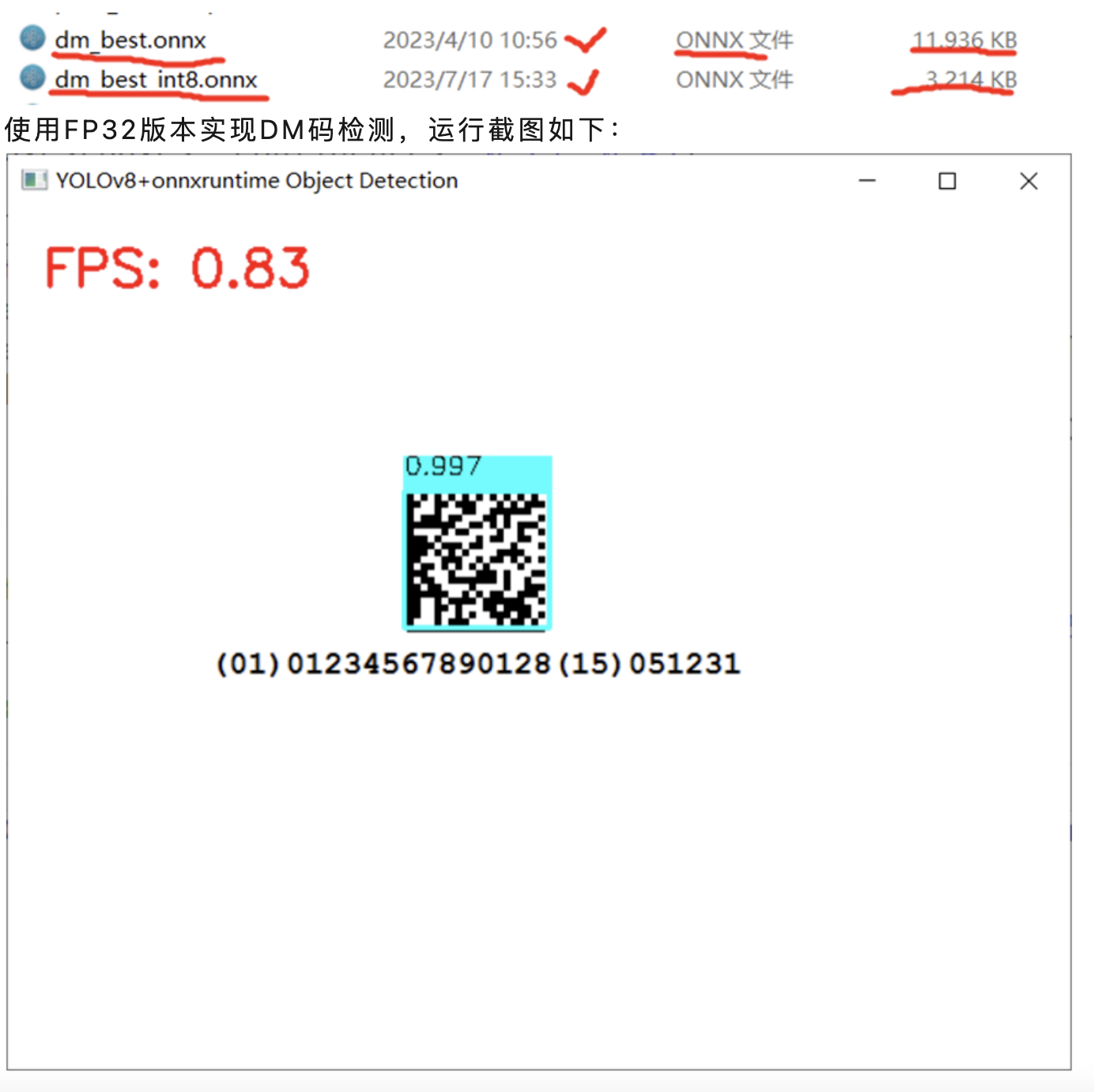
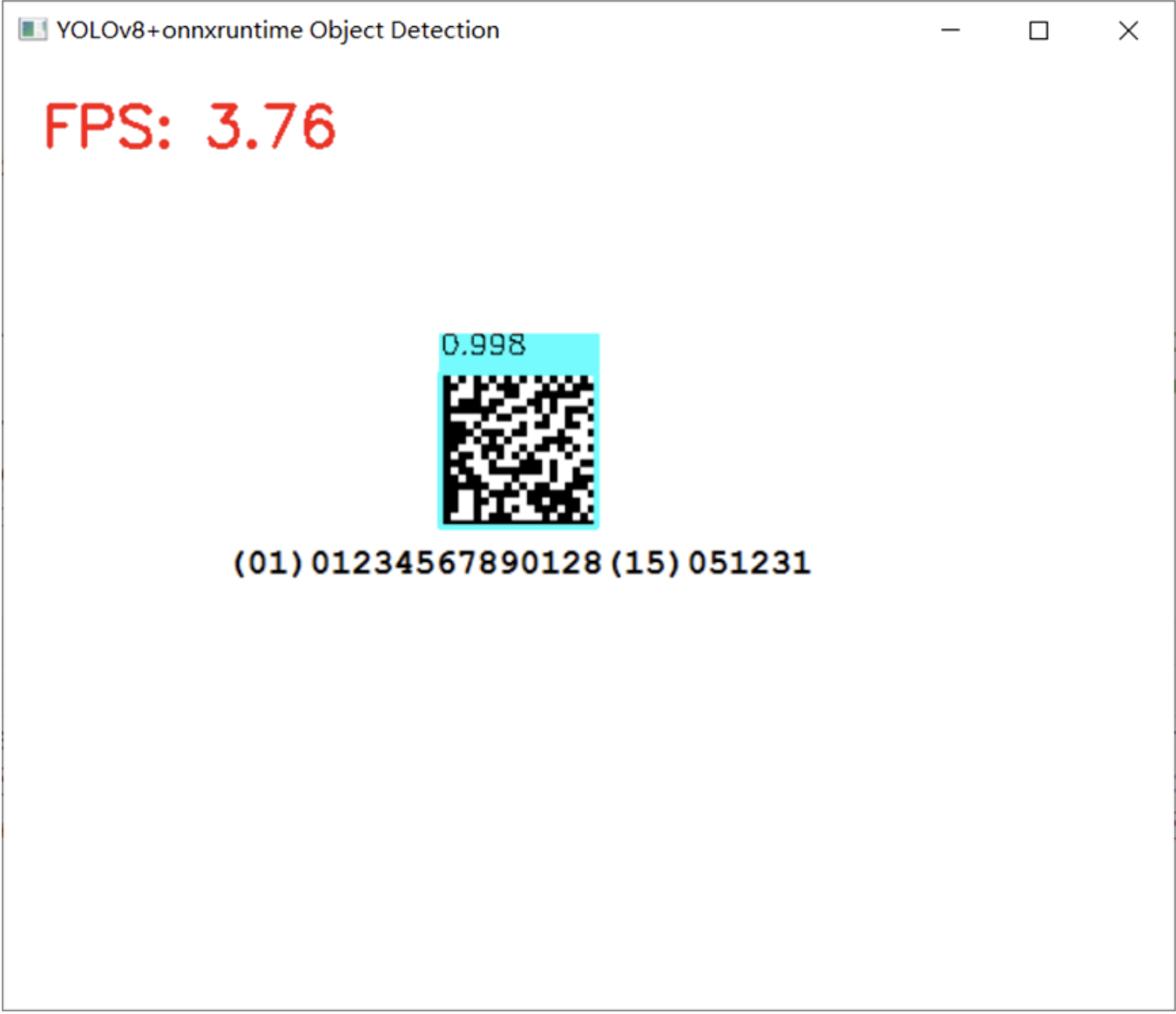
使用INT8版本实现DM码检测,运行截图如下:
ONNXRUNTIME更多演示
YOLOv8 对象检测 C++

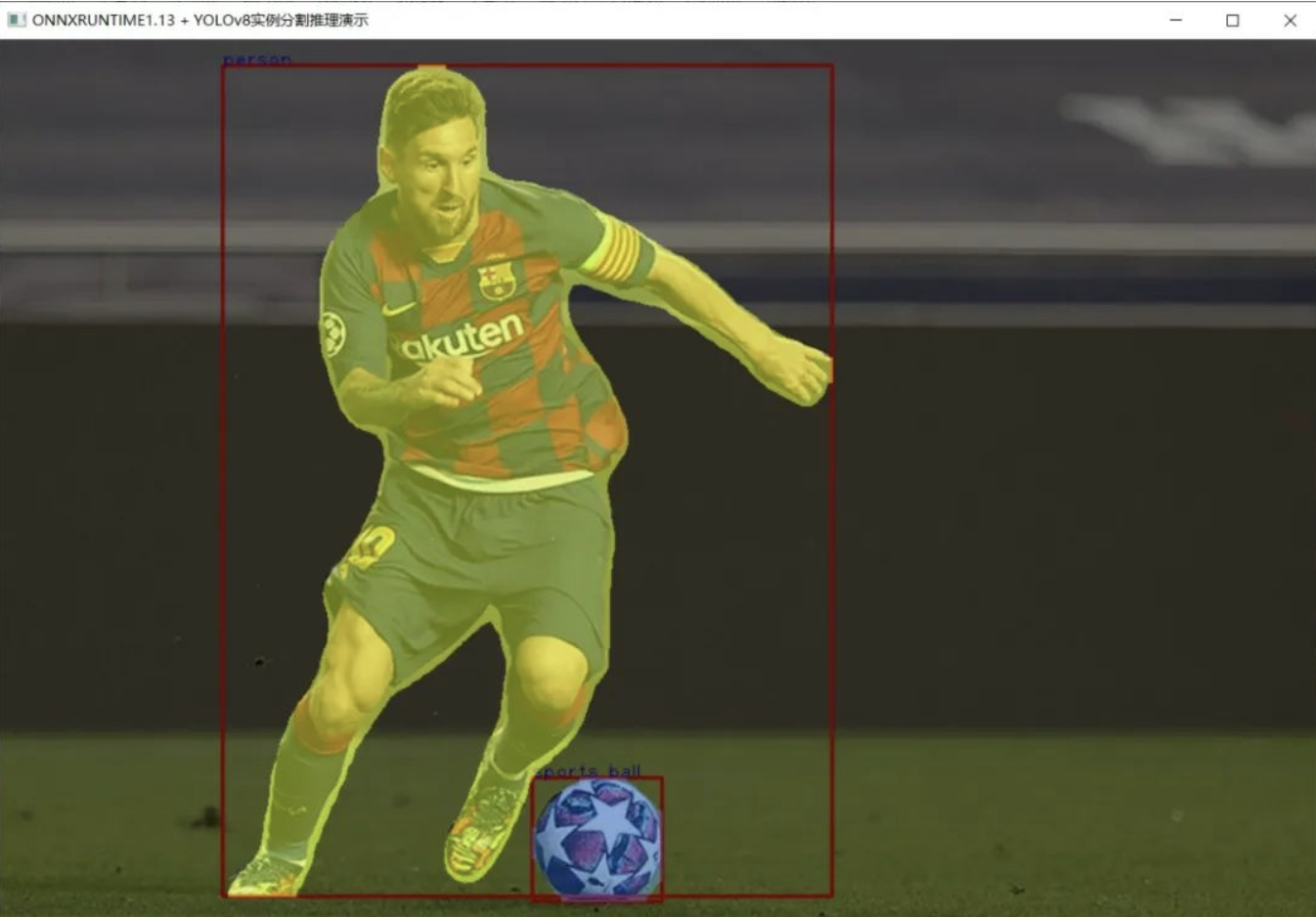
YOLOv8实例分割模型 C++ 推理:
UNet语义分割模型 C++ 推理:

Mask-RCNN实例分割模型 C++ 推理:

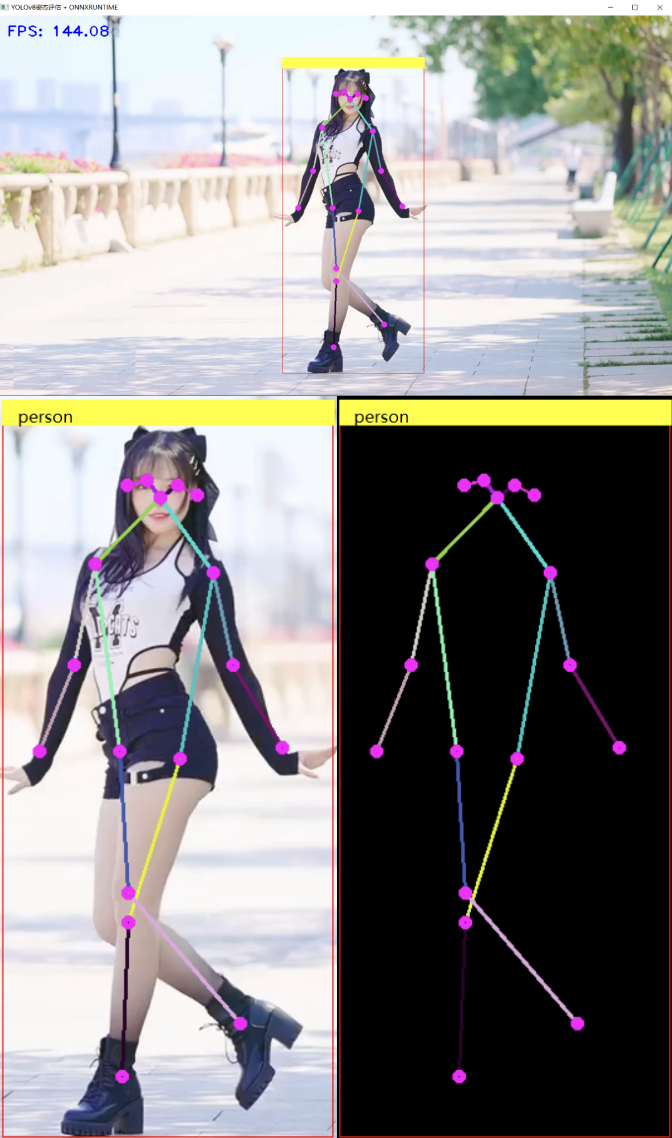
YOLOv8姿态评估模型 C++ 推理:
人脸关键点检测模型 C++ 推理:

人脸关键点检测模型 Python SDK 推理:

学会用C++部署YOLOv5与YOLOv8对象检测,实例分割,姿态评估模型,TorchVision框架下支持的Faster-RCNN,RetinaNet对象检测、MaskRCNN实例分割、Deeplabv3 语义分割模型等主流深度学习模型导出ONNX与C++推理部署,轻松解决Torchvision框架下模型训练到部署落地难题。




)






 -1- C++输入与输出)







