【腾讯云 TDSQL-C Serverless 产品体验】以TDSQL-C Mysql Serverless 作为数据中心爬取豆瓣图书数据
文章目录
- 【腾讯云 TDSQL-C Serverless 产品体验】以TDSQL-C Mysql Serverless 作为数据中心爬取豆瓣图书数据
- 背景
- TDSQL-C Serverless Mysql介绍
- 以TDSQL-C Mysql Serverless 作为数据中心爬取豆瓣图书数据
- 1、TDSQL-C Mysql Serverless环境构建
- 2、登录DMC进行数据表构建
- 3、搭建爬虫项目
- 3.1 、基础scrapy框架搭建
- 3.2 、根据数据表构建ORM
- 3.3 、集成TDSQL-C ServerLess Mysql
- 3.4 、开发 DoubanBookCommentTDSQLPipeline
- 3.5 、开发豆瓣图书爬虫
- 3.6 、开发豆瓣图书评论爬虫
- 3.7 、CCU的扩缩
- 体验总结
背景
最近我一直在研究 python 爬虫,公司需要很多数据源的数据,但遇到一个很大的障碍,就是没有合适的数据库储存这些数据,因为普通的机器的性能瓶颈非常明显,而且爬虫数据性能的要求也不是非常稳定,如果购买一台高配按月付费的机器,那无疑浪费了没有使用到的性能,最近不小心看到了CSDN首页的推荐,发现正在在进行"腾讯云TDSQL-C Serverless Mysql 数据库体验活动",我发现 Serverless 这个特性非常符合这个场景,它的serverless 数据库可以按需启动,不需要时可关闭,而且缩放对应用程序无影响,接下来让我们一起来体验一下 TDSQL-C Serverless Mysql 吧。
TDSQL-C Serverless Mysql介绍
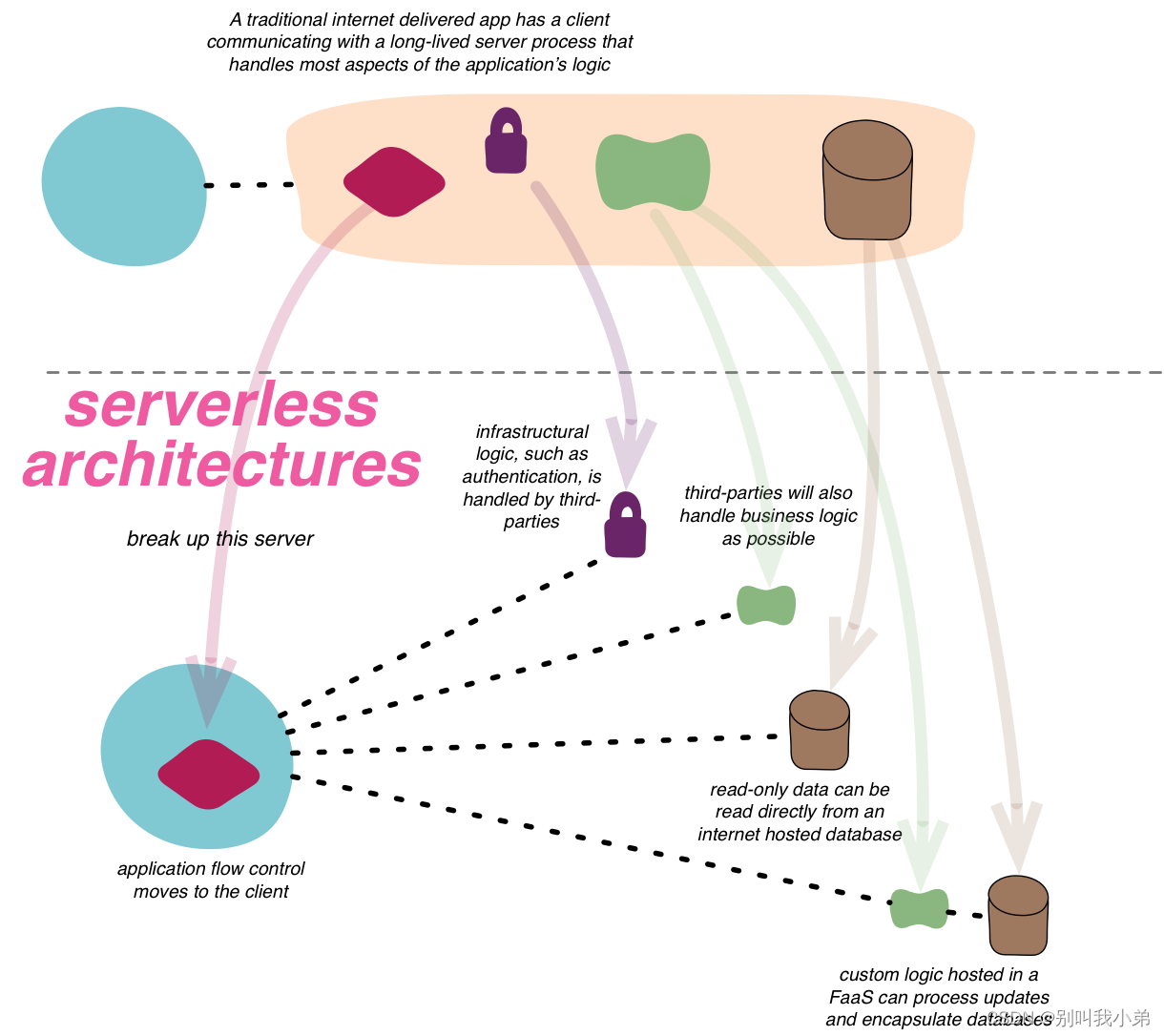
Serverless 服务是腾讯云自研的新一代云原生关系型数据库 TDSQL-C MySQL 版的无服务器架构版,是全 Serverless 架构的云原生数据库。Serverless 服务支持按实际计算和存储资源使用量收取费用,不用不付费,其架构如下:
TDSQL-C Serverless Mysql服务架构图
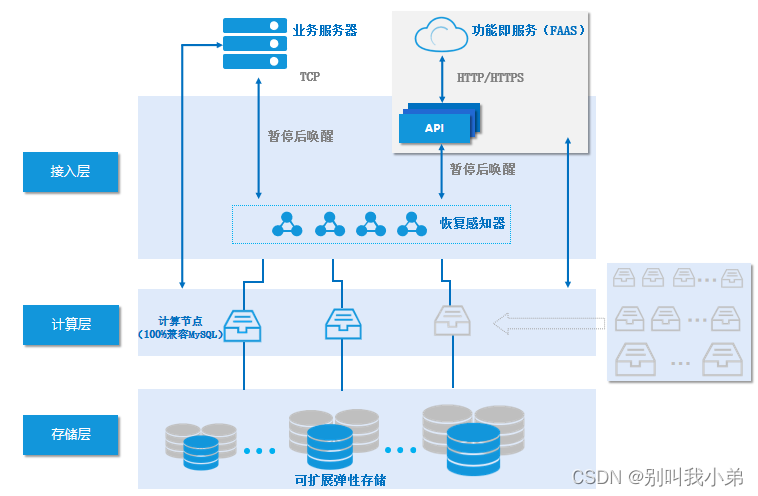
从架构可以看出,他有感知器对我们的数据库节点进行状态感知,数据库可以根据业务负载自动启动停止,无感扩缩容,扩缩容过程不会断开连接,并且整个使用是按实际使用的计算和存储量计费,不用不付费,按秒计量,按小时结算。
官方也给出了一些适用场景,我发现和我的需求还比较类似:

以TDSQL-C Mysql Serverless 作为数据中心爬取豆瓣图书数据
既然是体验,那必然要深入使用一下,这里我通过构建一个 TDSQL-C Mysql Serverless 单节点,进行豆瓣图书的数据存储,使用的是 scrapy 框架,主要是对 top250 和评论的数据进行爬取,然后转存,最后也对整个 CCU 的扩缩进行了监测,发现确实可以非常丝滑进行实例的扩缩,并且对上层程序没有任何影响,接下来跟着我的步骤一起来体验吧~
1、TDSQL-C Mysql Serverless环境构建

这里我们采用最小配置就可以了,我的配置如下:
- 版本:mysql8.0
- 类型:serverless
- 架构:单节点
- 算力:min 0.5 max2
不需要我们和原始一样自己在服务器上进行mysql下载和安装了,直接购买会自动生成一个高可用高性能的云数据库,非常的便捷!!
2、登录DMC进行数据表构建
数据库管理(DMC)是一个高效、可靠的一站式数据库管理平台,是腾讯云专门研发的 web 数据库管理平台,可以更加便捷、规范地管理多种数据库实例。
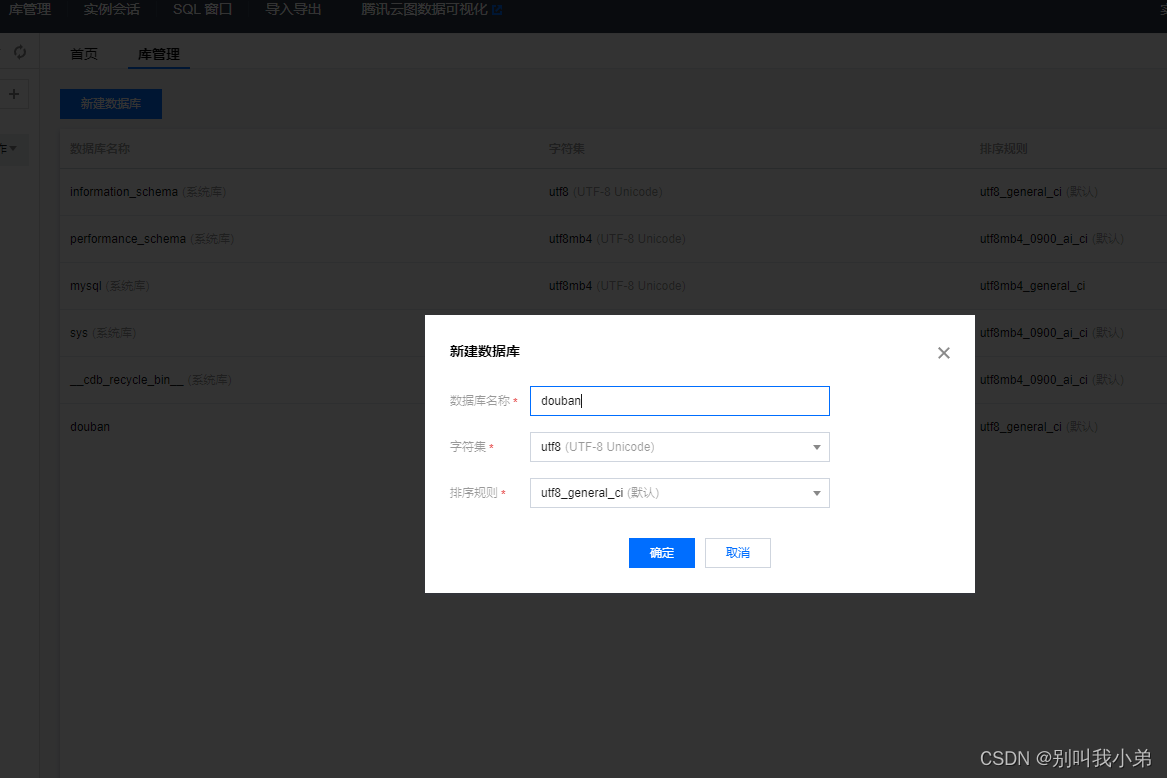
- 新建一个
douban的数据库
- 建立 book 表和 book_comment 表
CREATE TABLE `book_comments` (`id` int NOT NULL AUTO_INCREMENT,`book_id` int NOT NULL,`book_name` varchar(100) NOT NULL,`username` varchar(30) NOT NULL,`rating` int DEFAULT NULL,`comment_time` datetime DEFAULT CURRENT_TIMESTAMP,`useful_count` int DEFAULT '0',`content` text,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ciCREATE TABLE `books` (`id` int NOT NULL AUTO_INCREMENT,`book_id` int DEFAULT NULL,`title` varchar(100) NOT NULL,`cover` varchar(200) DEFAULT NULL,`is_try_read` varchar(1) DEFAULT NULL,`author` varchar(30) NOT NULL,`publisher` varchar(50) DEFAULT NULL,`publish_date` varchar(30) DEFAULT NULL,`list_price` varchar(30) DEFAULT NULL,`rating` float DEFAULT NULL,`ratings_count` int DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=206 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
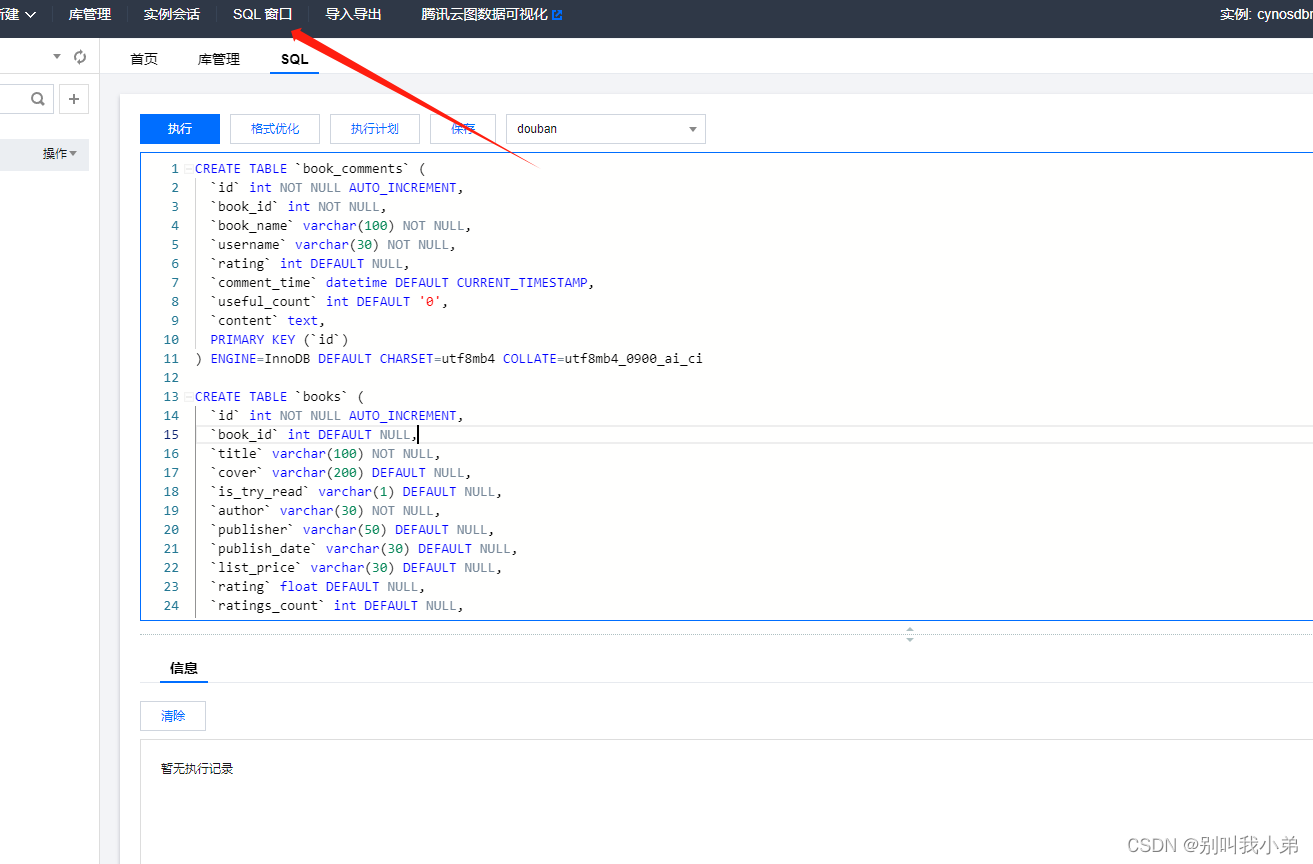
点击SQL窗口即可唤出,有了基础数据表之后,我们就需要进一步去搭建我们的开发环境,因为数据库很多参数、调优等腾讯云已经帮我们处理了,我们只需要使用即可,我们首先把数据库的公网访问打开,在节点详情中
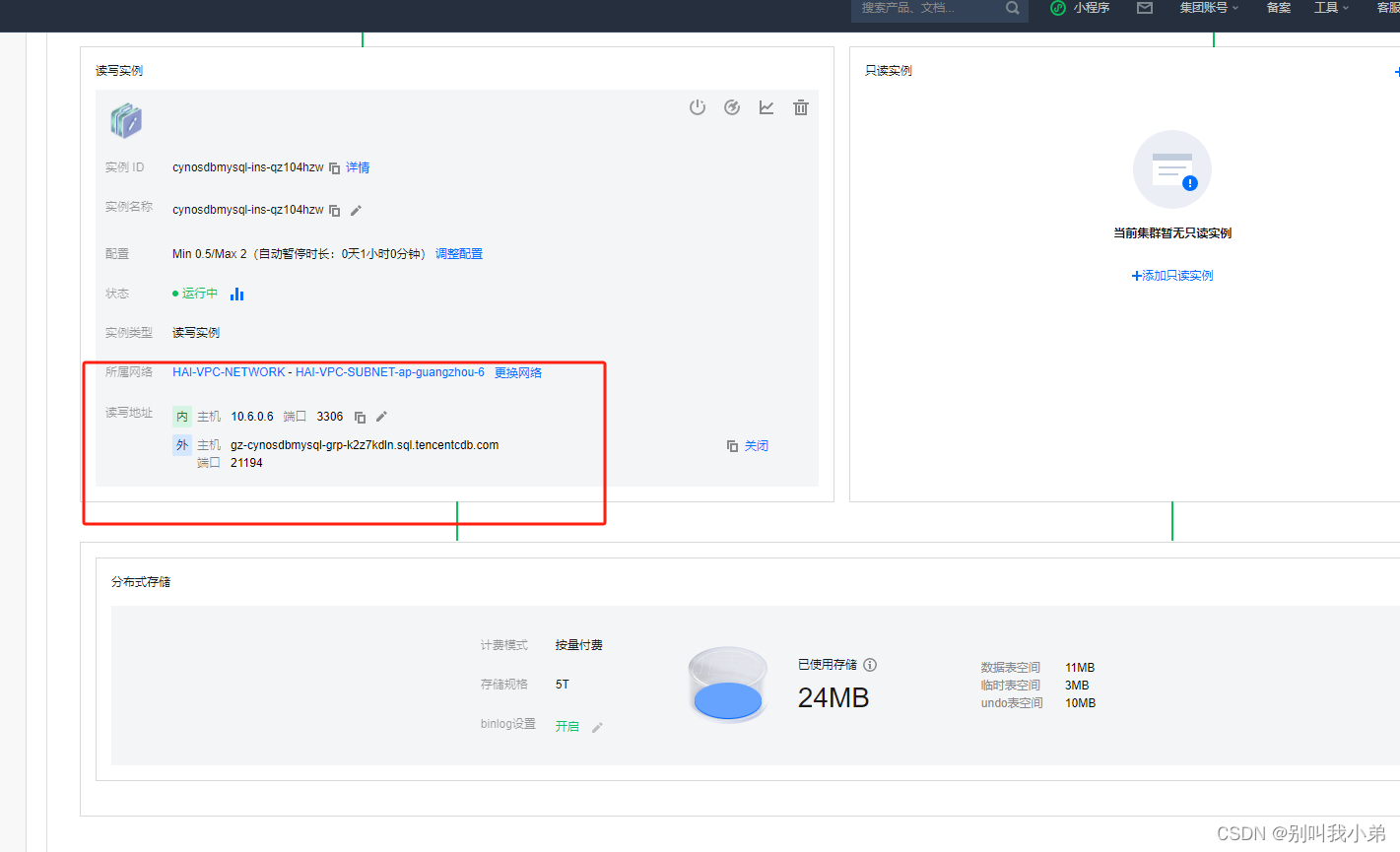
这样就是打开的状态,我们在开发环境中就可以使用这个 主机+端口以及自己购买时的账号密码 进行连接
3、搭建爬虫项目
3.1 、基础scrapy框架搭建
- 安装 scrapy
pip install scrapy
- 创建scrapy工程
scrapy startproject 项目名称
- 创建图书爬虫和评论爬虫
scrapy genspider 爬虫名 域名
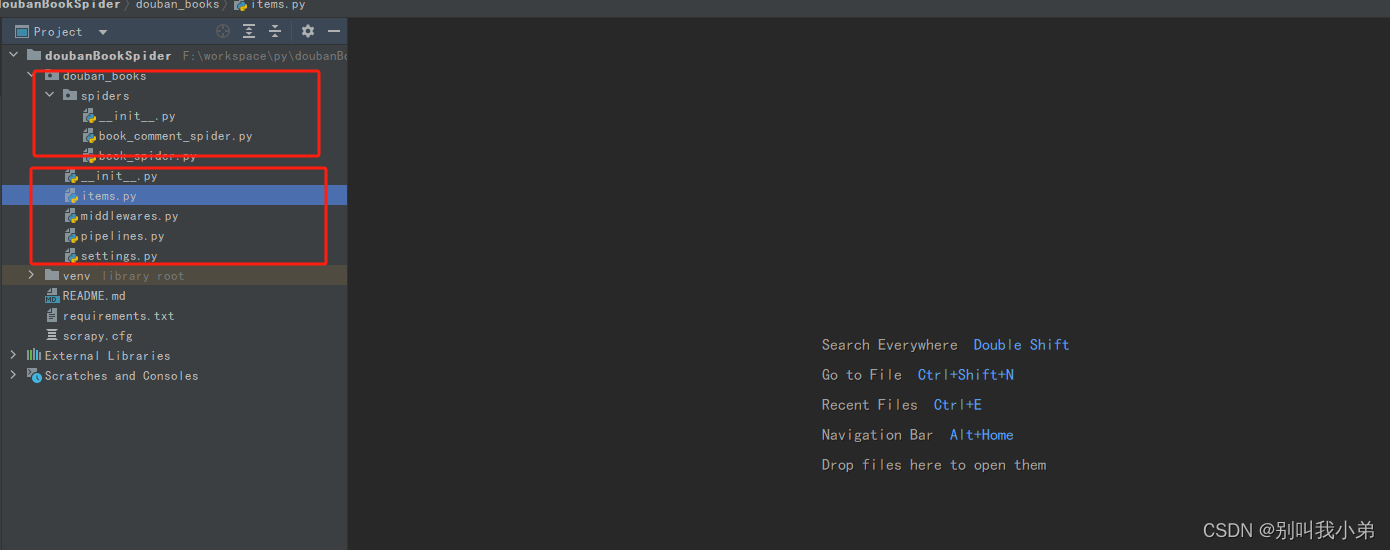
这个时候,整个项目框架如下图所示:
- 依赖管理
为了方便依赖的管理和项目的迁移,我定义了一份 requirements.txt 文件,内容如下:
scrapy
pymysql
- 安装依赖
pip install -r requirement.txt
scrapy 就是我们的爬虫框架,pymysql 是用来连接我们的 TDSQL 数据库的
这样就完成了最基础的框架搭建,然后我们主要对以下几个文件进行开发和修改:
- book_spider.py 图书的爬虫(需开发)
- book_comment_spider.py 图书评论的爬虫(需开发)
- items.py ORM文件(需开发)
- pipelines.py 管道文件,用来将数据存储到 TDSQL (需开发)
- settings.py 配置文件(需要修改)
我们首先将 TDSQL-C Serverless Mysql 集成到项目中
3.2 、根据数据表构建ORM
在 items.py 中增加两个模型映射,代码如下:
class DoubanBooksItem(scrapy.Item):book_id = scrapy.Field()title = scrapy.Field()cover_link = scrapy.Field()is_try_read = scrapy.Field()author = scrapy.Field()publisher = scrapy.Field()publish_date = scrapy.Field()price = scrapy.Field()rating = scrapy.Field()rating_count = scrapy.Field()class DoubanBookCommentItem(scrapy.Item):book_id = scrapy.Field()book_name = scrapy.Field()username = scrapy.Field()rating = scrapy.Field()comment_time = scrapy.Field()useful_count = scrapy.Field()content = scrapy.Field()3.3 、集成TDSQL-C ServerLess Mysql
- 增加数据库配置

在文件最尾部增加 DATABASE 配置:
DATABASE = {'host': 'gz-cynosdbmysql-grp-k2z7kdln.sql.tencentcdb.com','port': 21194,'user': 'root','passwd': 'Qwerabc.','db': 'douban','charset': 'utf8',
}
- 增加 pipelines 配置
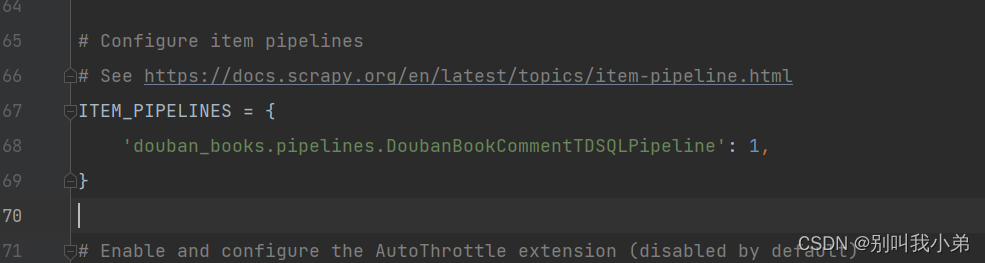
ITEM_PIPELINES = {'douban_books.pipelines.DoubanBookCommentTDSQLPipeline': 1,
}
这是我们下一步需要开发的 pipeline
3.4 、开发 DoubanBookCommentTDSQLPipeline
因为我们有两个不同的 item,所以我们会在 process_item 中进行判断
from twisted.enterprise import adbapifrom douban_books.items import DoubanBooksItem, DoubanBookCommentItem
from douban_books.settings import DATABASEclass DoubanBookCommentTDSQLPipeline:def __init__(self):self.conn = adbapi.ConnectionPool('pymysql', **DATABASE)def do_insert_book(self, tx, item):# 执行插入操作tx.execute("""insert into books (book_id, title, cover, is_try_read, author, publisher, publish_date, list_price, rating, ratings_count) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)""", (item['book_id'], item['title'], item['cover_link'], item['is_try_read'], item['author'], item['publisher'], item['publish_date'], item['price'], item['rating'], item['rating_count']))def do_insert_book_comment(self, tx, item):# 执行插入操作tx.execute("""insert into books (book_id, book_name, username, rating, comment_time, useful_count, content) values (%s,%s,%s,%s,%s,%s,%s)""", (item['book_id'], item['book_name'], item['username'], item['rating'], item['comment_time'], item['useful_count'], item['content']))def process_item(self, item, spider):if isinstance(item, DoubanBooksItem):print('开始写入 book')query = self.conn.runInteraction(self.do_insert_book, item)query.addErrback(self.handle_error)elif isinstance(item, DoubanBookCommentItem):print(item)print('开始写入 book item')query = self.conn.runInteraction(self.do_insert_book_comment, item)query.addErrback(self.handle_error)return itemdef handle_error(self, failure):# 处理异步插入的错误print(failure)
3.5 、开发豆瓣图书爬虫
这里我们主要爬取 top250 的图书,爬虫的数据会最后会通过 pipeline 转存到 TDSQL-C ServerLess
import scrapy
from douban_books.items import DoubanBooksItem
import reclass DoubanBookSpider(scrapy.Spider):name = 'douban_book_spider'start_urls = ['https://book.douban.com/top250']def parse(self, response):# 解析书籍信息for book_tr in response.css('tr.item'):item = DoubanBooksItem()# 提取书籍URLbook_url = book_tr.css('div.pl2 > a::attr(href)').get()# 提取书籍IDitem['book_id'] = book_url.split('/')[-2] if book_url else Noneitem['title'] = book_tr.css('div.pl2 a::text').get().strip()item['cover_link'] = book_tr.css('td a.nbg img::attr(src)').get()item['is_try_read'] = "是" if book_tr.css('div.pl2 img[title="可试读"]') else "否"# 提取作者、出版社、发行日期和价格的信息details = book_tr.css('p.pl::text').get().strip().split(' / ')item['author'] = details[0]item['publisher'] = details[-3]item['publish_date'] = details[-2]item['price'] = details[-1]item['rating'] = book_tr.css('span.rating_nums::text').get()rating_count_text = book_tr.css('span.pl::text').get()item['rating_count'] = re.search(r'(\d+)人评价', rating_count_text).group(1) if rating_count_text else Noneyield item# 翻页处理next_page = response.css('span.next a::attr(href)').get()if next_page:yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)现在我们可以对这个爬虫进行运行测试爬取
scrapy crawl douban_book_spider
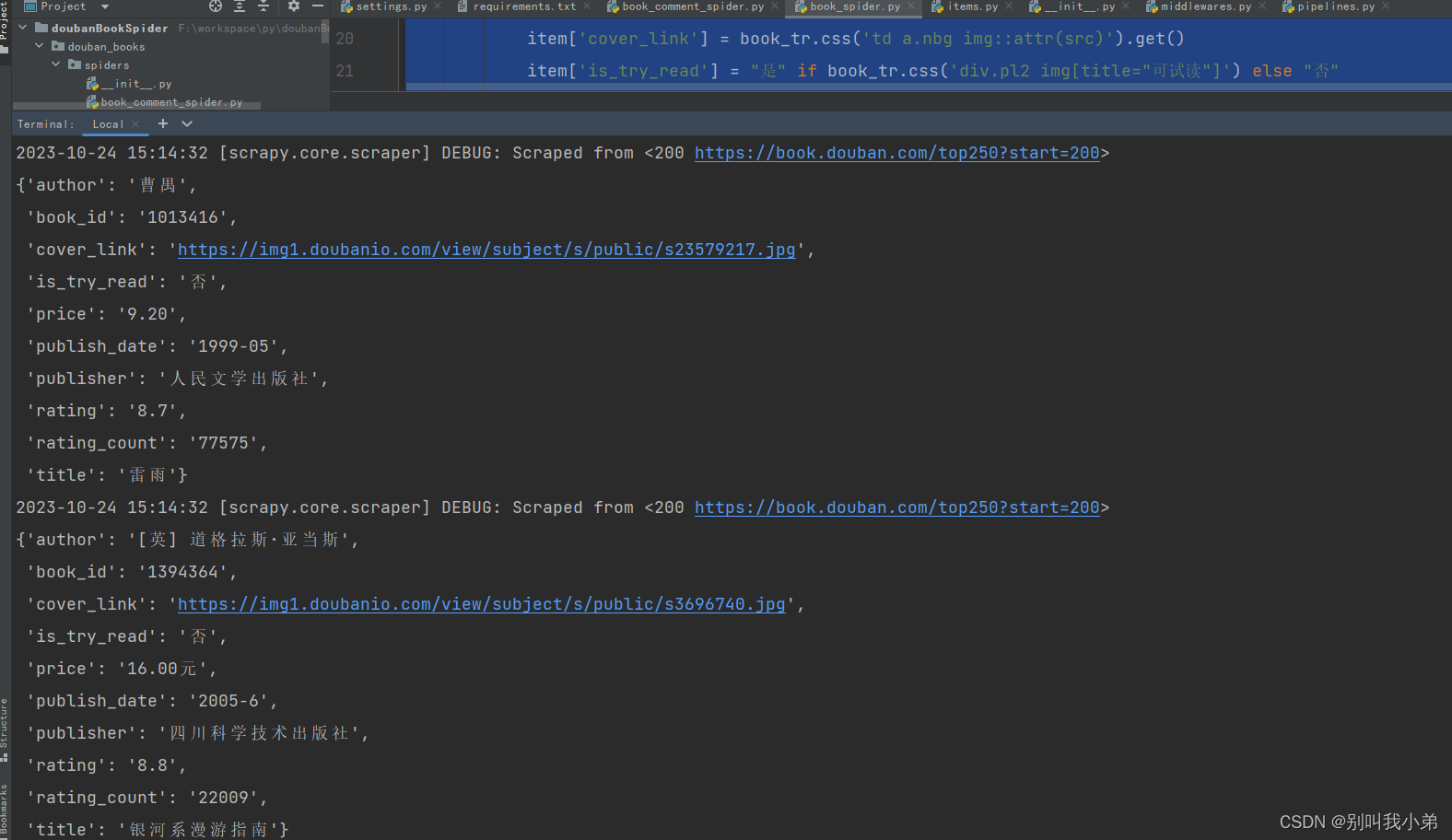
- 通过
DMC查看数据是否正常写入

3.6 、开发豆瓣图书评论爬虫
这里我们要通过 TDSQL-C 获取所有爬取的图书的 id,进行评论获取
import pymysql
import scrapy
import json
from douban_books.items import DoubanBookCommentItem
from douban_books.settings import DATABASEclass DoubanBookCommentSpider(scrapy.Spider):name = 'douban_book_comment_spider'db = pymysql.connect(**DATABASE)# 使用Cursor执行SQLcursor = db.cursor()sql = "SELECT book_id FROM books"cursor.execute(sql)# 获取结果results = cursor.fetchall()# 提取book_idbook_ids = [result[0] for result in results]# Step 2: Generate start_urls from book.csvstart_urls = [f'https://book.douban.com/subject/{book_id}/' for book_id in book_ids]def parse(self, response):self.logger.info(f"Parsing: {response.url}")# Extract music namebook_title = response.css('h1 span::text').get()print(book_title)# Construct the initial comments URLbook_id = response.url.split("/")[4]comments_url = f'https://book.douban.com/subject/{book_id}/comments/?start=0&limit=20&status=P&sort=new_score&comments_only=1'print(comments_url)yield scrapy.Request(url=comments_url, callback=self.parse_comments, meta={'book_title': book_title, 'book_id': book_id})def parse_comments(self, response):# Extract the HTML content from the JSON datahtml_content = response.json()['html']selector = scrapy.Selector(text=html_content)book_name = response.meta['book_title']book_id = response.meta['book_id']data = json.loads(response.text)print(selector.css('li.comment-item'))# 解析评论for comment in selector.css('li.comment-item'):item = DoubanBookCommentItem()item['book_id'] = book_iditem['book_name'] = book_nameitem['username'] = comment.css('a::attr(title)').get()item['rating'] = comment.css('.comment-info span.rating::attr(title)').get()# rating_class = comment.css('span.rating::attr(class)').get()# item['rating'] = self.parse_rating(rating_class) if rating_class else Noneitem['comment_time'] = comment.css('span.comment-info > a.comment-time::text').get()# item['comment_time'] = comment.css('span.comment-time::text').get()item['useful_count'] = comment.css('span.vote-count::text').get()item['content'] = comment.css('span.short::text').get()yield itembook_id = response.url.split("/")[4]base_url = f"https://book.douban.com/subject/{book_id}/comments/"next_page = selector.css('#paginator a[data-page="next"]::attr(href)').get()if next_page:next_page_url = base_url + next_page + '&comments_only=1'yield scrapy.Request(url=next_page_url, callback=self.parse_comments, meta={'book_title': book_name, 'book_id': book_id})
- 运行评论爬虫
scrapy crawl douban_book_comment_spider
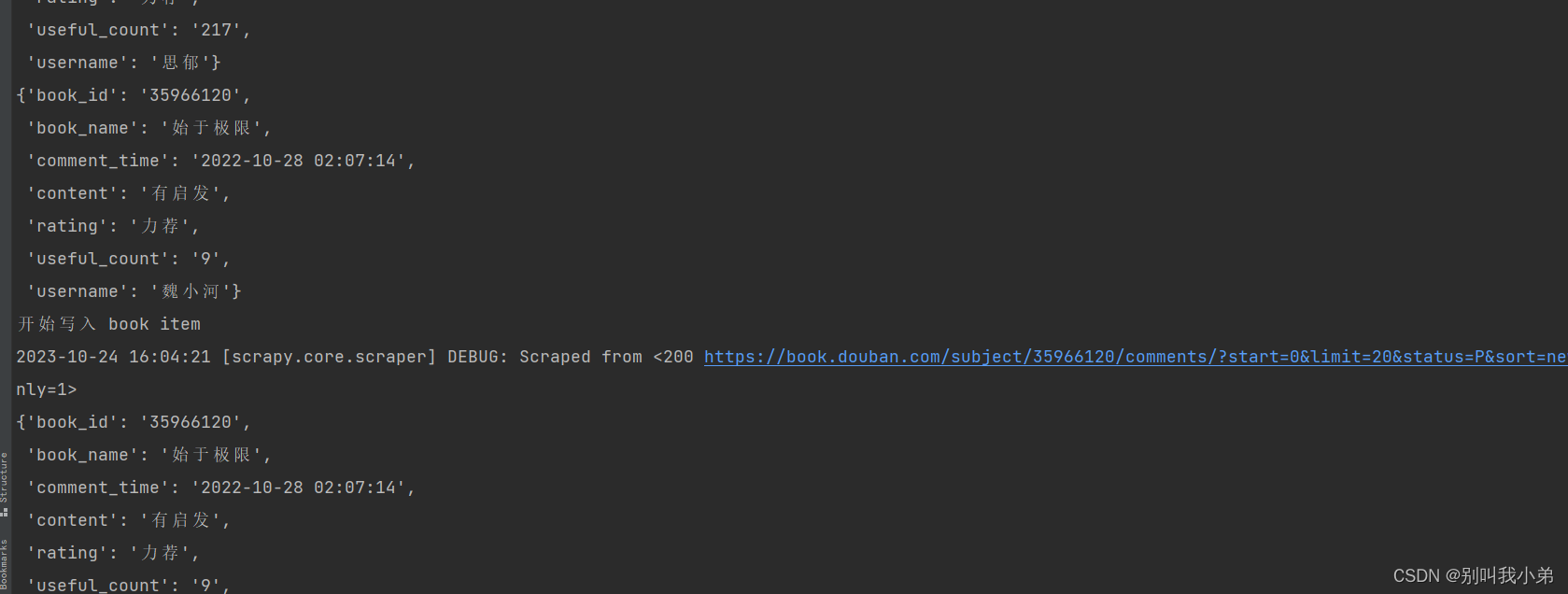
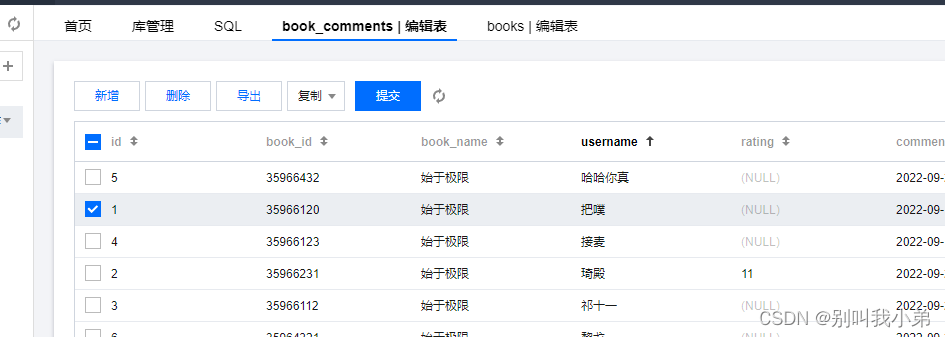
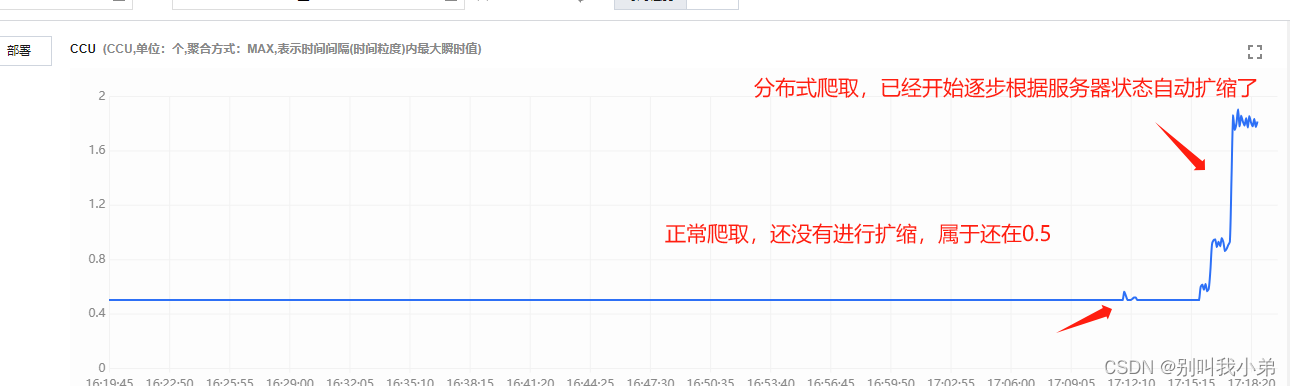
3.7 、CCU的扩缩
为什么购买 TDSQL-C ServerLess Mysql 的时候需要选择一个 min 和 max 的算力配置,那是因为 Serverless 的一大特点就是自动进行扩缩,TDSQL-C Serverless Mysql 是根据CCU 选择资源范围自动进行弹性扩缩容,一个 CCU 近似等于1个 CPU 和 2GB 内存的计算资源,每个计费周期的 CCU 使用数量为:数据库所使用的 CPU 核数 与 内存大小的1/2 二者中取最大值。
根据我们的算力上限 max 2,也就是当我们有大流量进来的时候最大会帮我们把数据库扩容成近似 2CPU+4GB的机器。
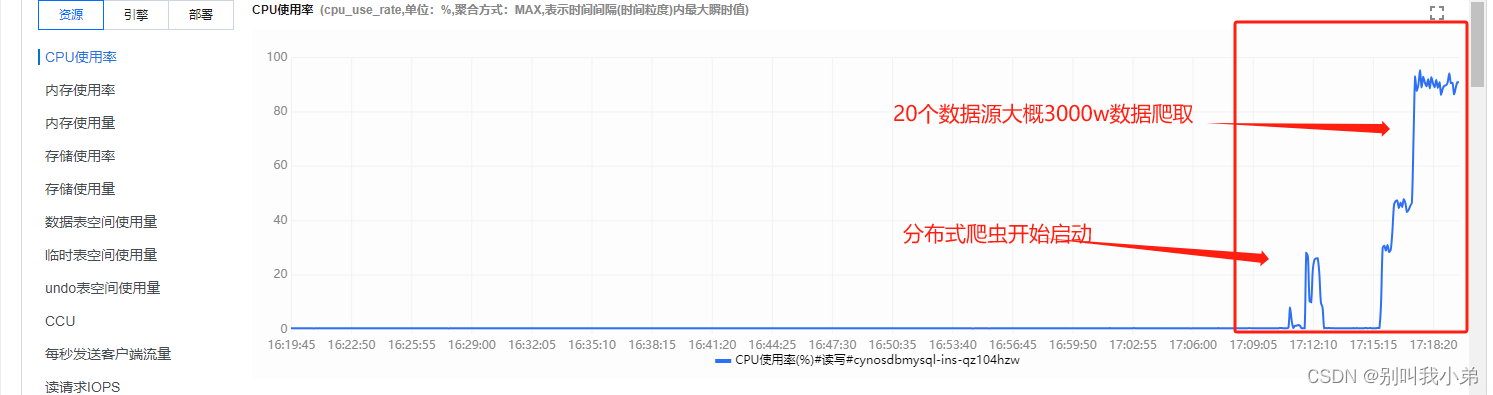
在我们进行爬虫的时候,经常会需要分布式爬虫,而多数据源的爬取对于数据库是一个不小的挑战,爬虫的性能也和数据库直接挂钩,我在进行多线程爬虫的时候就发现我们的 Serverless 数据库在自动扩缩:
这里我准备了 20 个数据据源,是以前积累的,同时进行分布式爬取,大约数据 3000w,让我们一起来观察一下 服务器的状态
- CPU
- CCU扩缩状态
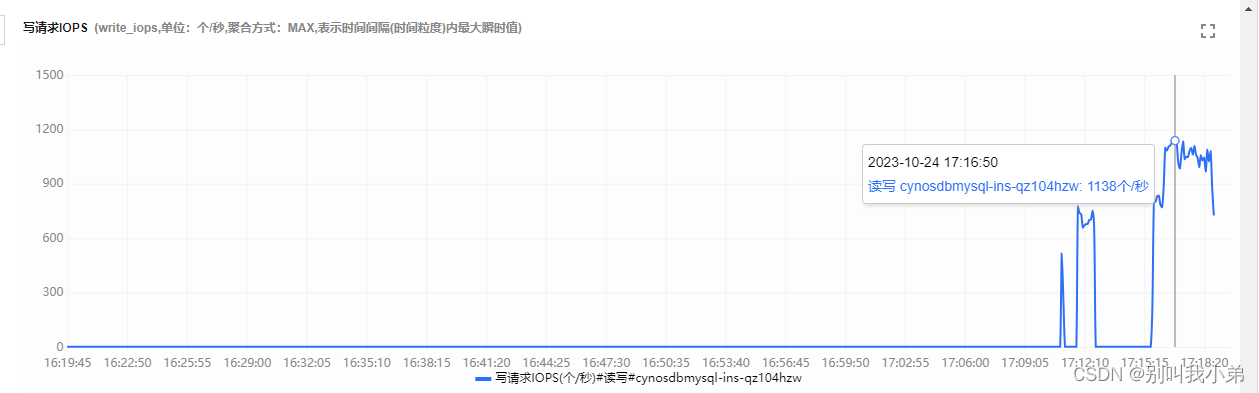
- 写请求IOPS
从这也可以看出写入是的性能也是逐步攀升的
体验总结
通过这次对TDSQL-C Serverless Mysql的体验,我对它也有了更深入的了解,后续会向公司推荐使用,确实很爽,我也总结一下本次的感受:
- 在应用方面
TDSQL-C Serverless Mysql适用于数据采集、分析和实时计算等动态负载场景。比如我们这个爬虫项目,随着数据量的增加,它可以自动进行扩容,满足性能需求。这对传统的数据库架构来说是难以实现的。
- 在使用体验方面
TDSQL-C Serverless Mysql最大的优势就是无需运维,我们只需关注业务开发本身。它采用了Serverless架构,我们无需购买和管理硬件,也无需监控调优数据库。这大大提升了开发效率。
- 在经济效益方面
TDSQL-C Serverless Mysql采用按用量付费的模式,成本更为精准合理。不需要为了闲置资源付费。且资源会根据负载自动弹性伸缩。这对节约IT成本简直不要太棒~
总体来说。TDSQL-C Mysql 作为Serverless 数据库,已经非常完备了,可用性也非常高。对于诸如数据采集这样无界资源需求的场景尤其适用。相信随着更多客户的验证和云技术的发展,它会发展的越来越好,今后我也会继续关注 TDSQL-C Serverless Mysql 的更新,并在合适的机会中将其应用到其他业务项目中,希望它能够带来更多的价值,



)




)


)
2024)






