
其实自动化测试很好理解,由两部分组成,“自动化”和“测试”,所以我们要理解自动化测试,就必须理解“自动化”和“测试”,只有理解了这些概念,才能更轻松的做好的自动化测试。其中“自动化”可以想象成通过各种编程技术实现程序对被测系统可操控的行为,重点在于对“测试”的理解。
1、关于测试的理解
所以首先作为一个测试人员,应该思考测试的本质是什么?
大多数从事自动化测试的人都是从手工测试转型过来的,所以对于测试都不会太陌生,那么对于测试工作我们可以简单的认为两种情况:
1,验证被测系统是正确的(即程序按照预期运行,认为做了正确的事情)
2,寻找错误(只要程序没有做错误的事情)

我们知道大概所有的测试用例都是按照情况1在编写测试用例,执行,而同样在做着情况2的事情,其中验证正确比较简单,只需要将实际结果和预期结果做比较,
一般只有一件正确的事会发生就只需要验证这件事发生了即可,而寻找错误就比较困难,因为太多不可预知或者偶然性的错误会发生。
所以测试最终的结果就是期望的结果,我们可以尝试回顾一下我们平时的日常工作流程
1.分到任务拿到需求,开始理解需求,那么分析需求的目的是什么?
2.学习并了解相关业务知识与工作流程,那么搞清业务流程的目的是什么?
3.当上面的工作完成后,开始设计并编写测试用例,那么设计测试用例的目的是什么?
4.开发完成后开始执行测试用例,那么判断测试用例fail/pass的标准是什么?
所以最后的我们测试目的就是:找出期望结果与实际结果不符的场景
如果理解了这个概念,那么单纯从技术角度上来说,我们的测试要做的最重要的工作就是搞清楚一个软件的功能块的期望结果是什么,
不管用什么方法(UI/API/UT自动化 等等),只要能把期望结果理解清楚,我们的测试便成功了一大半。
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036【csdn999】
2、关于自动化测试的理解
对于自动化测试理解简单来说就是由测试方法+测试目的(验证结果)组成,并不局限你使用了什么技术或者框架,但是自动化测试要做的事情与功能测试是一致。

先来看看功能测试是如何进行的:
编写测试用例,测试用例当中最主要的是测试步骤和预期结果;测试人员根据测试用例执行操作步骤,然后通过眼睛和思考判断实际结果与预期结果是否相等。如果相等,测试通过;如果不相等,测试失败。
自动化测试本质就是基于功能测试的实现,自动化测试常见主要包含三个层面的自动化,单元测试自动化,接口测试自动化和UI测试自动化。当然,不同层面的自动化关注点是不一样的。
1、单元测试自动化,调用被测试的类或方法,根据类或方法的参数,传入相应的数据。然后,得到一个返回的结果。最终断言返回的结果是否等于预期结果。如果相等,测试通过;如果不相等,测试失败。所以,这里单元测试关注的是代码的实现与逻辑。当然根据不同的测试系统或者软件架构单元测试方法以及技术都不一样,比如我曾经经历过前端js/后台springmvc/oracle数据库层不同层面的单元测试工作
2、接口测试自动化,根据接口文档,到底是否get请求呢?还是post呢?调用被测试的接口,构造相应的数据(id=1,name=zhangsan),得到返回值,200成功,并返回查询结果。还是500,用户名不能为空。不管输入的参数是怎样的,我们都将得到一个结果。最终断言返回的结果是否等于预期结果。如果相等,测试通过;如果不相等,测试失败。所以,接口测试关注的是数据。只要数据正确了,功能就做成大半,剩下的无非是如何把这些数据展示在页面上。
3、UI测试的自动化,这种测试更贴近用户的行为,模拟用户点击了某个按钮,向个输入框里输入了什么。但是用户可以看到登录成功了,但UI自动化并不知道它刚才的点击有没有生效。所以,要找“证据”,比如,登录成功后页面右上角会显示“欢迎,xxx”。这就是登录成功的有力“证据”。于是,当web自动化登录成功后,就去获取这个数据进行断言。断言如果相等,测试通过;如果不相等,测试失败。所以,web自动化地关注点用户操作行为,页面上真正的按钮和输入框是否可用。
3、如何实现自动化测试
刚才提到自动化测试本质就是基于功能测试的实现,都是看实际结果和预期结果是否相符。
其实大概可以分为三个部分:
1、实际结果:就是我们通过操作获取的实际执行结果,通常所讲的自动化测试的难度,大部分指就是指通过自动化获取实际结果的难度。因为UI层更贴近用户层,所以不管是视觉还是业务处理都相对于其他层更负责,所以往往实施起来难度验证结果很负责,成本更高
2、预期结果:是我们在需求上人为定义的,很多测试员在测试时遇到需求不明确,没有标准,其实就是不知道预期结果是什么。将预期结果转化为机器可识别的数据也是一个难点。
3、结果比较:验证测试结果是正确还是错误,良好的自动化测试除了需要自动化的执行,还需要包括自动化的验证,有时候自动化的验证比自动化操作更困难。
要实现自动化测试,就要将这三样东西通过程序来实现,并且高效地结合起来。何谓高效地结合起来?就是预期结果和实际结果可以大量快速获取进行比较,并且尽量少地出现人为干涉。
控制一个程序能够读取到全部预期结果,并且执行操作获取全部实际结果,然后可以自动比较两者生成报告,这样就比我们人手控制一个程序单个多次地读取预期结果,再人手控制另一个程序单个多次地获取实际结果,再人手控制第三个程序去单个多次地比较前两者的结果要高效。当然,如果这些程序是统一控制,相互自动触发的话,那效果也等同于一个程序,在实际中这种情况是很常见的。
实际过程中又可以分为UI界面交互和非UI界面交互的情况。
非UI界面交互,以接口测试为例:
1.批量的发送请求并获取返回值,
2.批量得到预期结果并转为机器可识别的数据,可以用xml或者excel一类的文档来准备数据,使用工具的话可以将多个case保存为一个集合。
3.批量比较返回值和预期结果数据,将前两步的数据都获取到之后再用字符或者正则表达式来比较两者,用工具的话需要选择那些可以断言返回值的。
4.将比较结果生成测试报告。
UI界面交互,以Web UI测试为例:
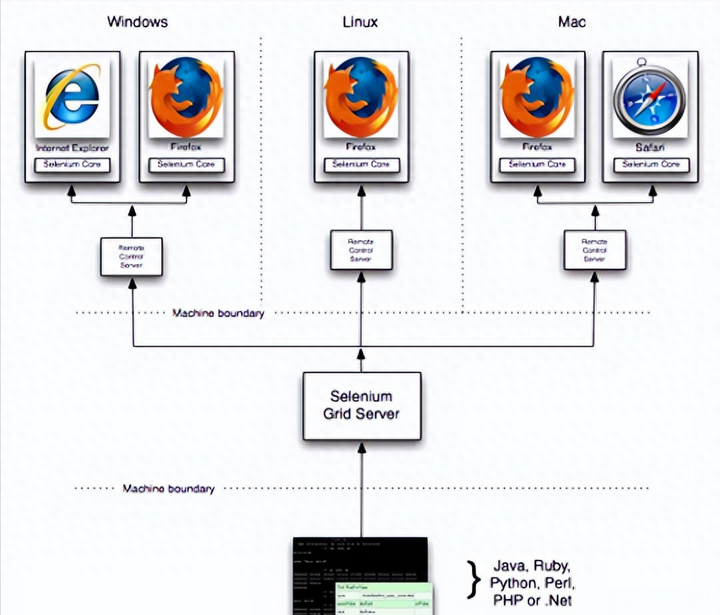
1.需要实现web操作,无论你是自己写程序实现,还是用现有的工具,都是将动作、对象、数值组织起来完成一个web操作。比如登录网站,分3个步骤:
(1)输入用户名
(2)输入密码
(3)点击登录按钮,
2. web操作之后,我们就可以获取到相关的实际结果,例如登入成功的提示,或者登入后的网页内容,我们就需要通过程序去获取回来,准备之后的比较。
3.通过实际结果与预期结果判断,使用断言来判别执行失败或者通过。
总结
如果想用自动化测试去发现错误,首先就必须有人去预想可能出现错误的各种情况,然后用自动化去检查。这样其实就不是用自动化去发现错误了,而是由人去寻找错误(或者错误的可能性),然后用自动化去验证。
偏偏试图通过自动化去发现错误是很多人开展自动化的最初目的,于是就导致了自动化的高代价,投入了人工(预测错误,设计用例,编写脚本),但自动化的成果只能局限在人工能够预测到的范围之内。
所以我们可以看到很多案例,在使用了自动化测试之后,用手工测试依然可以发现大量的bug。所以,能否发现bug,最核心的东西是用例,而不是工具或方法,只有用例能够发现bug,工具只是实现的手段而已。因此,想要测试得更好,应该加强的是设计用例的能力。
END今天的分享就到此结束了,点赞关注不迷路~
|LeetCode93. 复原 IP 地址、LeetCode78. 子集、LeetCode90. 子集 II)








(CNN-GRU-LSTM)通过堆叠CNN、GRU、LSTM实现多元预测和单元预测)


)






