引言
记录一次线上redis占用过大的排查过程,供后续参考
问题背景
测试同事突然反馈测试环境的web系统无法登陆,同时发现其他子系统也存在各类使用问题
排查过程
1、因为首先反馈的是测试环境系统无法登陆,于是首先去查看了登陆功能的报错信息,一查看服务器日志首先发现了redis集群宕机的问题
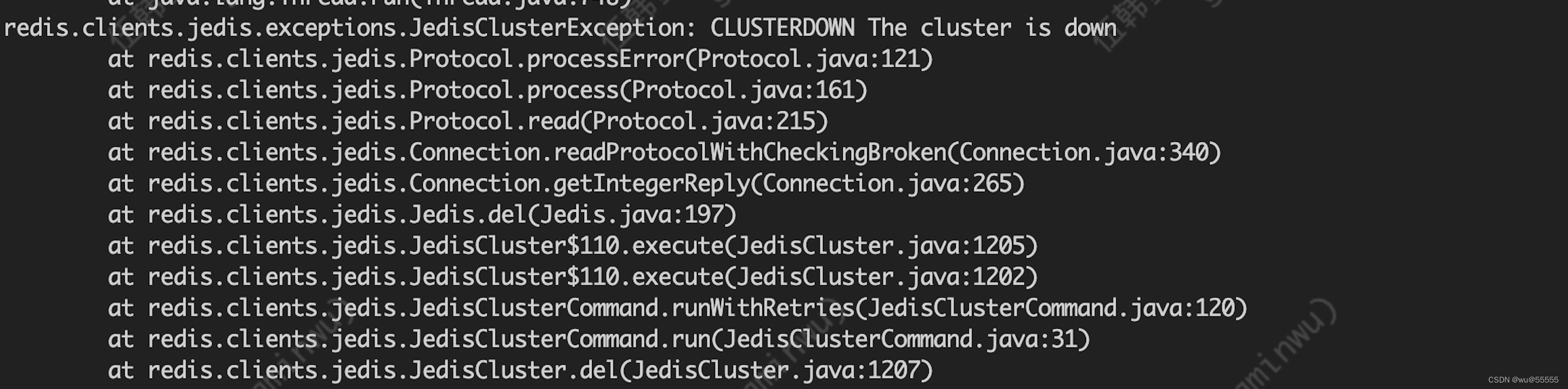
同时也有其他的一些redis相关报错
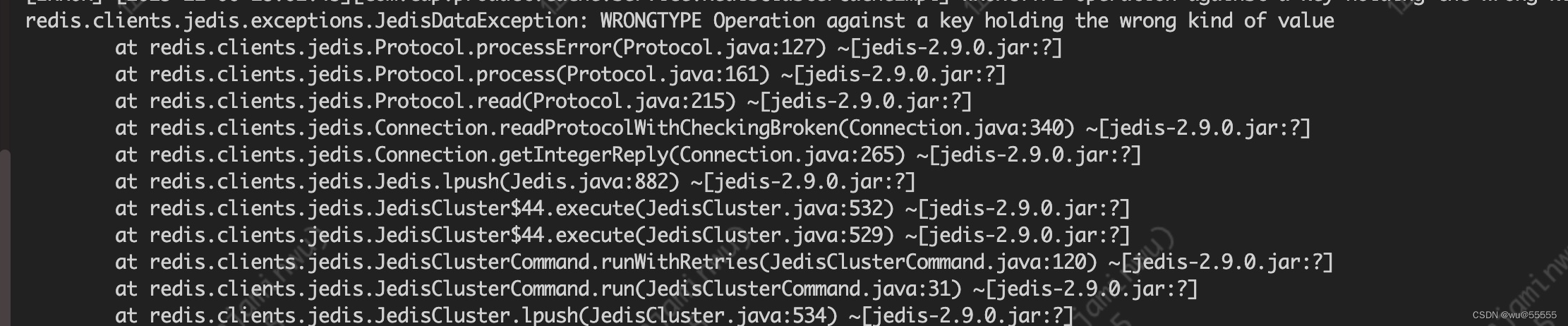
2、由此可知,肯定是redis出现了问题,那么进一步排查redis节点情况
3、因为redis部署的是集群,首先到服务器上通过top指令查看了各个节点的内存、cpu占用情况
4、结果发现有两个节点的内存占用高达15G
5、单独登陆这两个节点,通过INFO指令查询节点详细状态
redis-cli -p <端口>
INFO
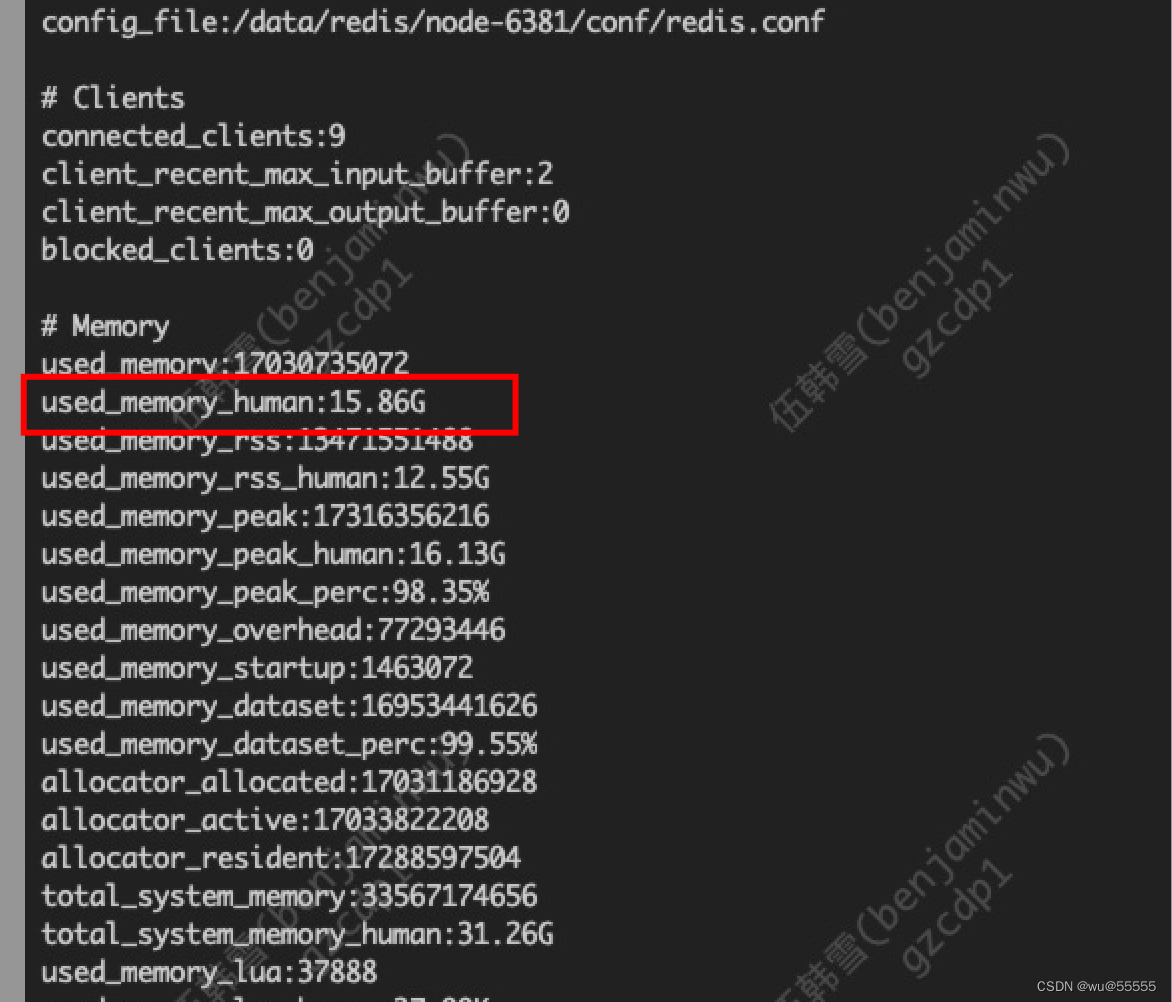
6、结果发现这两个节点的内存占用确实异常,而且这两个节点是主从节点。那么问题到这里有基本清晰了,以下基本就是两个方向:
-
- 产生了大量的key,没有及时清理导致内存占用过多
-
- 某几个key其值异常大,没有及时清理导致内存占用过多
但这里其实偏向于第2点,因为是集群模式下某一主从节点都出现该问题,说明是某一个hash段的key分配到这个节点上的很大。
通过通过INFO指令查询到redis中占用的key数量只有1百多万,不算很多,所以基本也定位到是第2点的可能性了。
7、要查询是否有占用内存较大的key, 可以通过bigkeys指令。如下图所示,可以看到其中jms_log_list的key占用内存高达50%
redis-cli -p <服务端口> -a <认证密码> --bigkeys
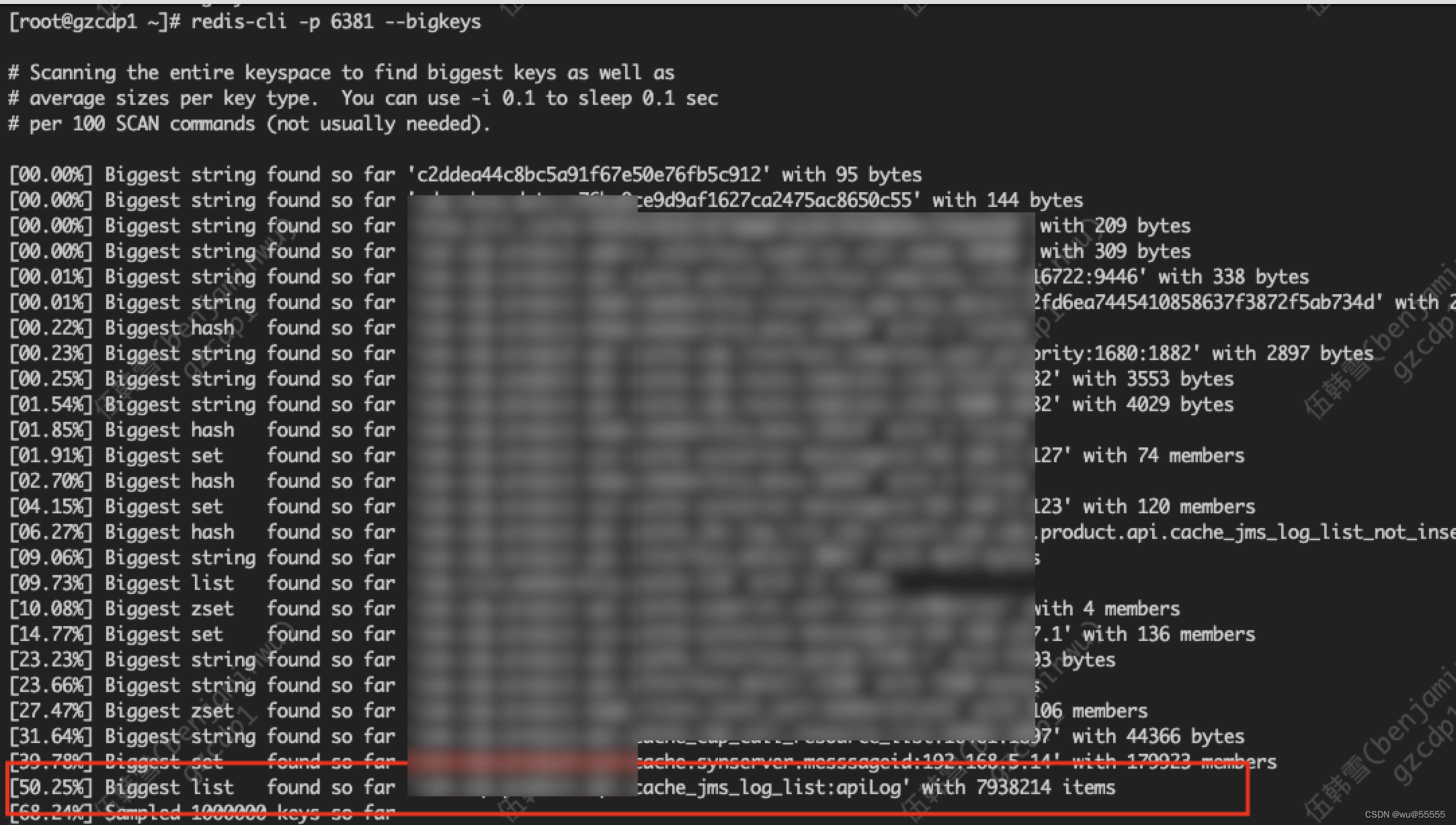
再详细查询这个key的占用空间,单位bytes,换算下来将近10G
memory usage <key>

8、到这里问题就基本明朗了,通过key值去查询代码,发现这个数据是list类型的,其作用就是作为一个临时队列。再去查看这个队列的消费者,发现这个服务没有正常消费
9、到服务器上查看消费者服务的状态,发现服务并没有运行。经调查为上周末测试服务器机房断电后,启动服务时把这个消费者服务漏了,经过几天的运行,数据累计到一定地步导致内存占用过大了。从而影响了整个redis集群的运行。
10、后续关掉了一个从节点,让主节点有足够的内存空间可以运行,同时把消费者服务启动起来了,为了加快消费,还临时增加了消费者的节点数,主节点消费完成后再将从节点启动起来,让从节点逐步同步主节点的数据
11、最终解决问题,由此引申出一个redis内存占用过大的问题排查思路,也提醒我们,完善测试环境的开机自启脚本,同时遇到此类问题,要结合服务器情况,耐心思考、解决问题。



)


)

)
)
)

)






