-
引言
-
简介
-
模型解读
-
模型架构
-
训练
-
-
实战
-
环境准备
-
本地实测
-
服务部署
-
-
总结
引言
谁念西风独自凉,萧萧黄叶闭疏窗,沉思往事立残阳。

Created by DALL·E 3
小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。今天这篇小作文主要介绍由上海人工智能实验室推出的多模态模型:浦语·灵笔。本文先介绍浦语·灵笔的模型细节,再以实战方式结束本地部署浦语·灵笔模型并实测各种任务上的效果。如果有疑问或者想要和小编进一步交流,欢迎通过《小窗幽记机器学习》找到小编。
简介
浦语·灵笔模型是基于书生·浦语大语言模型研发的视觉-语言大模型,提供图文理解和创作能力:
-
图文交错创作: 浦语·灵笔可以为用户打造图文并貌的文章,具体是提供文章生成和配图选择的功能。这一能力由以下步骤实现:
-
理解用户指令,创作符合要求的文章。
-
智能分析文章,自动规划插图的理想位置,确定图像内容需求。
-
基于以文搜图服务,从图库中检索出对应图片。
-
-
图文理解: 浦语·灵笔设计了高效的训练策略,为模型注入海量的多模态概念和知识数据,赋予其强大的图文理解和对话能力。
从公布的技术报告可以获悉InternLM-XComposer在公开评测数据集上的战绩:在多项视觉语言大模型的主流评测上均取得了最佳性能,包括MME Benchmark (英文评测)、 MMBench (英文评测)、Seed-Bench (英文评测)、 CCBench(中文评测)、MMBench-CN (中文评测)。
截至目前(2023年10月14日)官方开源2个版本的浦语·灵笔模型:
-
InternLM-XComposer-VL-7B :该模型是基于书生·浦语大语言模型的多模态预训练和多任务训练模型,在多种评测上表现出杰出性能, 例如:MME Benchmark, MMBench Seed-Bench, CCBench, MMBench-CN。该模型是base模型,即常说的基座模型。
-
InternLM-XComposer-7B:进一步对InternLM-XComposer-VL进行指令微调得到nternLM-XComposer。该微调模型可以用于创作图文并茂的文章,也支持多模态对话(目前支持图文对话,更具体是围绕给定图片的讨论,暂不支持指令编辑给定的图片)。
以下为小编体验演示:
AI科技爱科学
GitHub:
https://github.com/InternLM/InternLM-XComposer
技术报告:
https://arxiv.org/abs/2309.15112
模型解读
模型架构
InternLM-XComposer整体架构由3部分组成,包括视觉编码器、LLM-model (本文即InternLM) 和对齐模块(报告中称为Perceive Sampler,感知采样器)。

1. 视觉编码器:InternLMXComposer 中的视觉编码器采用 EVA-CLIP,这是标准 CLIP的改进版本,用mask图像的方式增强了模型的建模能力,能够更有效地捕捉输入图像的视觉细节。在该模块中,图像被调整为统一的 224×224 尺寸,然后以步长为14的方式切割成图块。这些图块作为输入token,再利用transformer中的自注意力机制,从而提取图像embeddings。
2. Perceive 采样器:InternLM-XComposer中的感知采样器其实是一种池化机制,旨在将图像embeddings从初始的257维度压缩为64。这些压缩优化后的embeddings随后与大型语言模型理解的知识进行对齐。仿照BLIP2的做法,InternLM-XComposer利用BERT-base中cross-attention层作为感知采样器。
3. 大型语言模型:InternLM-XComposer用InternLM 作为其基础大型语言模型。值得注意的是,InternLM 是一种功能强大的多语言模型,擅长英语和中文。具体是使用已经公开的 InternLM-Chat-7B 作为大型语言模型。
训练
InternLM-XComposer的训练过程分为 A 阶段和 B 阶段。A 阶段作为预训练阶段,利用大量数据训练基座模型。B阶段是监督微调,先做多任务训练,再做指令微调。在多任务训练后得到InternLM-XComposer-VL模型,在指令微调得到InternLM-XComposer模型。
1. Pre-training阶段:预训练基座视觉语言模型阶段利用了大量的图像-文本对(网络爬取)和交错的图像-文本数据。这些数据包括中英文两种语言的多模态数据。为了保持大型语言模型的语言能力,在 InternLM 预训练阶段使用的部分文本数据也在 InternLM-XComposer 的预训练阶段中使用。如Table 1 所示:
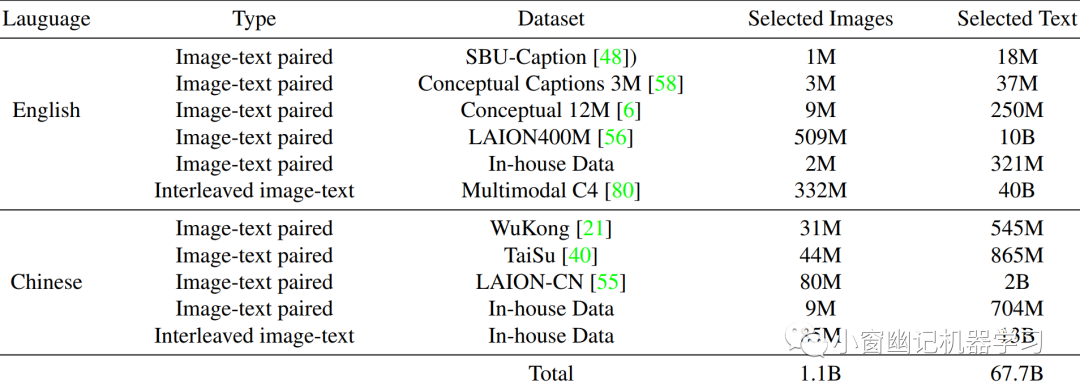
图像-文本对方面,使用了 11 亿张图像和 677 亿个文本token(其中506亿个英文文本token和171亿个中文文本token),包括公开数据集和从内部数据(从网站爬取收集),总共超过 1100 万个语义概念。内部数据集In-house Data有一个开放的子集:书生·万卷文本数据集。这个开源数据集,包含三个部分:纯文本格式数据集、文本-图像对数据集和视频数据集,可以从官网下载到,相关的数据说明也可以在对应论文上查阅。此外,还加入了约100亿个从InternLM 预训练数据集中抽样的文本token,以维持模型的语言能力。在训练过程中,所有预训练数据都经过了严格的清洗流程,以确保其质量和可靠性。
在预训练阶段,视觉编码器参数固定,主要对感知采样器和大型语言模型进行优化。感知采样器和大型语言模型的初始权重分别来自BLIP2和InternLM。由于大型语言模型天然缺乏对图像embeddings的理解,因此在多模态预训练框架内做优化有助于提高理解这些embeddings的能力。模型的训练目标集中在下一个token预测上,使用交叉熵损失作为损失函数。采用的优化算法是 AdamW,超参数设置如下:β1=0.9,β2=0.95,eps=1e-8。感知采样器和大型语言模型的最大学习速率分别设置为 2e-4 和 4e-5,采用余弦学习率衰减策略,最小学习率设置为1e-5。此外,在最初的 200 步中使用线性预热。训练过程一个batch size中约 1570 万个token,并进行 8000 次迭代。使用如此大的batch size有助于稳定训练,同时也有助于维持InternLM的固有能力。
2. 监督微调阶段:在预训练阶段,图像embeddings与文本表征对齐,使大型语言模型具有初步具备理解图像内容的能力。为进一步指导模型在恰当时机使用图像信息的能力,引入了各种视觉-语言任务。所以,整个监督微调阶段,其实由多任务训练和指令微调组成。
多任务训练。多任务训练数据集如Table 2 所示,这些任务包括场景理解(例如 COCO Caption,SUB)、位置理解(例如 Visual Spatial Reasoning 数据集)、光学字符识别OCR(例如 OCR-VQA)以及开放式回答(例如 VQAv2 ,GQA)等。
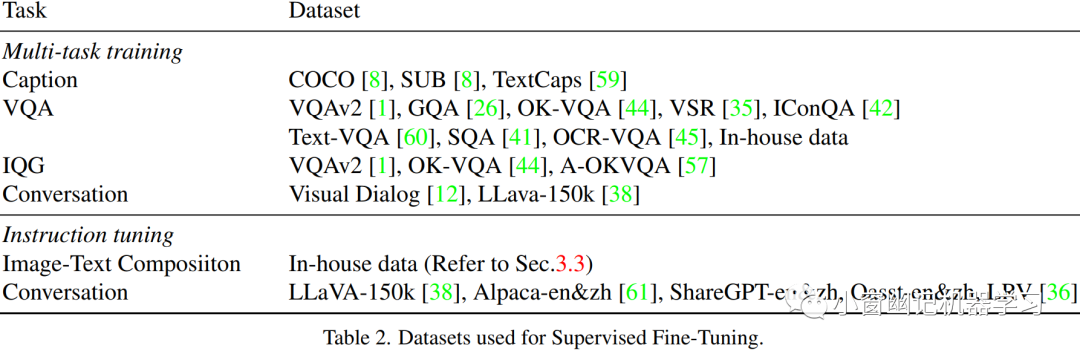
每个任务都被设计成会话交互形式,具体格式如下:

其中和 分别表示用户和机器人结束token。对于每张图像具有多个问题的QVA数据集,将其构造成多轮对话,问题随机排序,从而大大提高了 SFT 过程的效率。在这个阶段,所有问题都通过人工编写的提示引入,以增加任务的多样性。为了实现稳定且高效的微调,将大型语言模型的权重冻结,然后使用 Low-Rank Adaption(LoRA)架构进行模型微调。当然,在这个过程中,感知采样器也同时进行训练,只是学习率不同。LoRA 应用于注意力层的 query、value 和 key 以及前馈网络。实验发现较高的LoRA rank有助于赋予模型新能力;因此,将 LoRA rank和 alpha 参数都设置为 256。模型在10,000次迭代训练中使用全局batch size,值为256。LoRA 层和感知采样器的学习速率分别设置为 5e-5和 2e-5。
指令微调。为了进一步提升上述模型的指令跟随和交错的图像-文本组合能力,使用来自纯文本对话语料库和LLava-150k 的数据进行指令微调。此外,使用 LRV 数据集减轻幻觉。交错的图像-文本组合数据集的构建方法,可以查阅原始技术报告,这里略过。Batch size=256,并在1000 次迭代中使用较小的学习速率=1e-5。
实战
环境准备
安装 flash-attention:参考官方项目安装flash-attention:
pip3 install flash-attn --no-cache-dir --no-build-isolation -i https://mirrors.cloud.tencent.com/pypi/simple
安装 rotaty
pip3 install "git+https://github.com/Dao-AILab/flash-attention.git#subdirectory=csrc/rotary" -i https://mirrors.cloud.tencent.com/pypi/simple
如果不安装,可能报错:
File "/root/.cache/huggingface/modules/transformers_modules/internlm-xcomposer-7b/modeling_InternLM.py", line 5, in <module>import rotary_emb
ModuleNotFoundError: No module named 'rotary_emb'
注意,如果需要设置代理,请提前设置:
export HTTPS_PROXY=XXX
export HTTP_PROXY=XXXX
本地实测
取如下图片进行测试:

测试代码:
"""
CUDA_VISIBLE_DEVICES=7 python3 examples/example_chat.py
"""
import torch
from transformers import AutoModel, AutoTokenizertorch.set_grad_enabled(False)# init model and tokenizer
model_id = "/home/model_zoo/LLM/internlm/internlm-xcomposer-7b/"
model = AutoModel.from_pretrained(model_id, trust_remote_code=True).cuda().eval()
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model.tokenizer = tokenizer# example image
image = 'examples/images/baoguoma.jpeg'# Single-Turn Pure-Text Dialogue
text = '请介绍下马保国'
response = model.generate(text)
print(f'User: {text}')
print(f'Bot: {response}')# Single-Turn Text-Image Dialogue
text = '请问这张图片里面的人是谁?并介绍下他。'
image = 'examples/images/baoguoma.jpeg'
response = model.generate(text, image)
print(f'User: {text}')
print(f'Bot: {response}')# Multi-Turn Text-Image Dialogue
# 1st turn
text = '图片里面的是谁?'
response, history = model.chat(text=text, image=image, history=None)
print(f'User: {text}')
print(f'Bot: {response}')# 2nd turn
text = '他有哪些成就?'
response, history = model.chat(text=text, image=None, history=history)
print(f'User: {text}')
print(f'Bot: {response}')# 3rd turn
text = '他是最伟大的物理学家吗?'
response, history = model.chat(text=text, image=None, history=history)
print(f'User: {text}')
print(f'Bot: {response}')输出结果:
User: 请介绍下马保国
Bot: 马保国,男,汉族,1952年出生于河北省邯郸市大名县,中国武术家。2015年11月30日,马保国在一场业余搏击比赛中,被业余选手王庆民连续三拳打倒在地,随后倒地不起,被送往医院后抢救无效去世。User: 请问这张图片里面的人是谁?并介绍下他。
Bot: 这张图片里面的人是一位男子,他戴着墨镜,面带微笑,看起来心情不错。男子名叫郭德纲,是中国著名的相声演员和主持人。User: 图片里面的是谁?
Bot: 图片里面的是郭德纲。User: 他有哪些成就?
Bot: 郭德纲是中国相声演员、主持人、影视演员。User: 他是最伟大的物理学家吗?
Bot: 对不起,郭德纲并不是物理学家。
换成蔡某某的照片:

重新测试,输出结果如下:
User: 请介绍下蔡徐坤
Bot: 蔡徐坤(Cai Xukun),1998年8月2日出生于浙江省温州市,中国内地流行乐男歌手、影视演员。2012年,参加选秀节目《向上吧!少年》进入全国300强
。2013年,参加浙江卫视歌唱选秀节目《中国好声音第二季》,最终获得周杰伦组亚军、全国总决赛季军
。2018年4月6日,发行个人首支原创单曲《I Wanna Get Love》
;5月2日,发行原创单曲《Wait Wait Wait》
;8月2日,发行原创单曲《Hard To Get》
;12月21日,发行原创单曲《Pull Up》
。2019年1月1日,发行原创单曲《YOUNG》
;2月14日,发行原创单曲《情人》
;4月6日,发行原创单曲《重生》
;7月6日,发行原创
User: 请问这张图片里面的人是谁?并介绍下他。
Bot: 这张图片里的人是蔡徐坤。蔡徐坤是一位中国男歌手和演员,他在2018年通过选秀节目《偶像练习生》出道,成为NINE PERCENT成员之一。User: 图片里面的是谁?
Bot: 蔡徐坤User: 他有哪些成就?
Bot: 蔡徐坤是中国内地流行乐男歌手、音乐制作人、影视演员。User: 他是最伟大的篮球运动员吗?
Bot: 对不起,我无法回答这个问题。User: 描述下这张图片?
Bot: 这是一张蔡徐坤的照片,他正在打篮球。
服务部署
如果服务器因为网络原因只能使用本地模型,或者个人已经其他下载好模型,想要直接指定模型路径,那么需要进行几处修改。
-
modeling_vit.py将原来的:
url = "https://storage.googleapis.com/sfr-vision-language-research/LAVIS/models/BLIP2/eva_vit_g.pth"cached_file = download_cached_file(url, check_hash=False, progress=True)
改为:
# 预先下载好 "https://storage.googleapis.com/sfr-vision-language-research/LAVIS/models/BLIP2/eva_vit_g.pth" 文件,然后存在机器上。cached_file = "/home/model_zoo/LLM/internlm/internlm-xcomposer-7b/eva_vit_g.pth"
-
modeling_InternLM_XComposer.py:将原来的
encoder_config = BertConfig.from_pretrained("bert-base-uncased")
改为:
# 预先下载https://huggingface.co/bert-base-uncased/tree/main的模型存于 /home/model_zoo/LLM/bert-base-uncased
local_model_path = "/home/model_zoo/LLM/bert-base-uncased" # "bert-base-uncased"
encoder_config = BertConfig.from_pretrained(local_model_path)
将原来的:
Qformer = BertLMHeadModel.from_pretrained("bert-base-uncased", config=encoder_config)
改为:
local_model_path = "/home/model_zoo/LLM/bert-base-uncased"
Qformer = BertLMHeadModel.from_pretrained(local_model_path, config=encoder_config)
启动服务:
CUDA_VISIBLE_DEVICES=7 python3 examples/web_demo.py
图文交错创作功能测试:
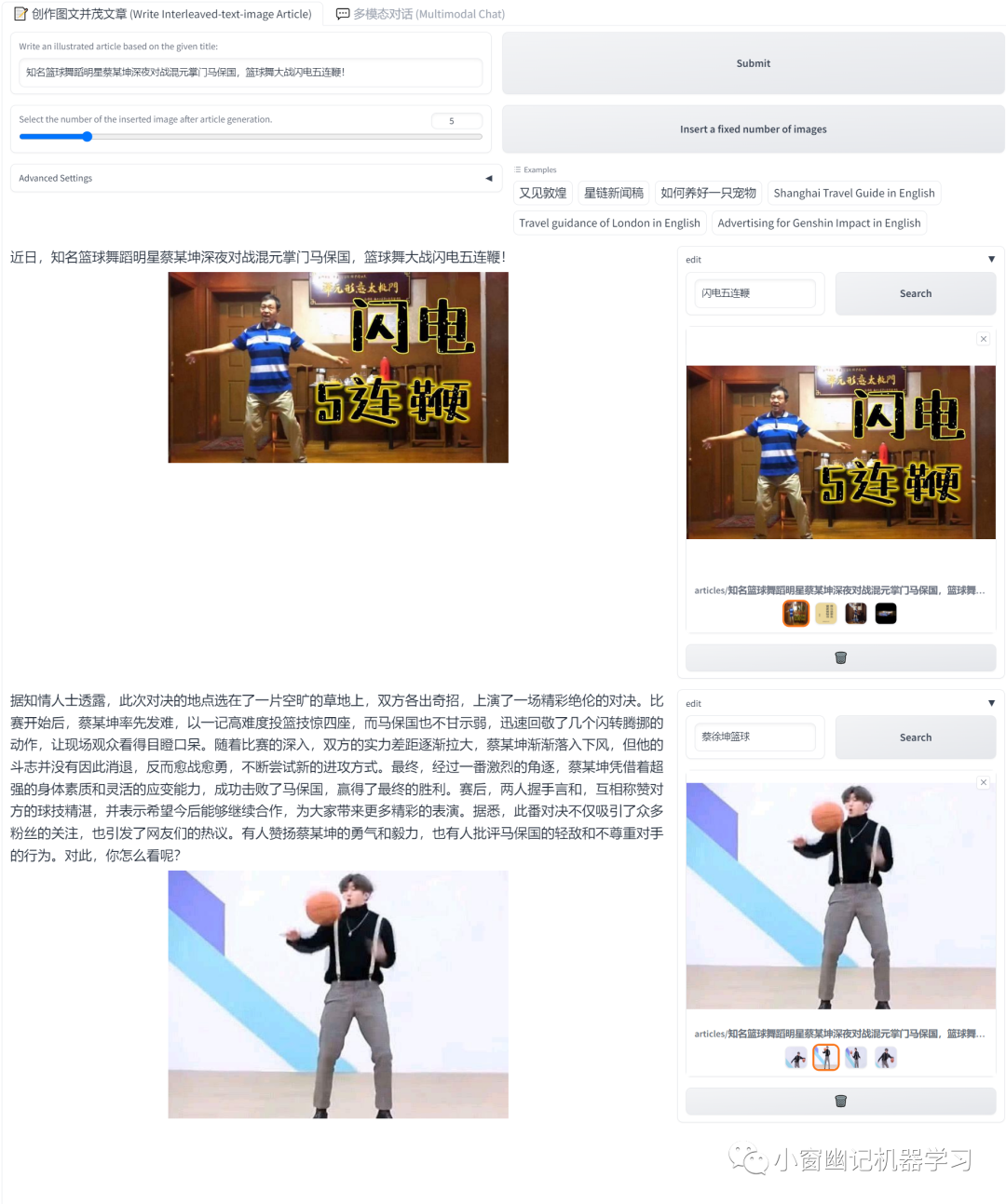
其中文章生成的配图来自调用内部以文搜图模块,并非通过图片生成的方式。但是,以文搜图的图库和背后的逻辑并没有说明,目前只给出一个调用接口https://lingbi.openxlab.org.cn/image/similar,且caption字符串最多54个字符。
图文理解测试:

总结
虽然技术层面没有太多创新,但是图文交叉的产品应用形态,还是值得肯定和借鉴的。如果可以进一步支持文章配图生成,直接解决配图版权问题,在体验层面会有更多惊喜。其实,小编在每篇小作文开头的配图都是生成的,比如今天小作文开头诗句配图就是通过DALL·E 3直接生成的。至于图文理解方面效果还行,但是对于近期知识和图中图标等一些局部元素的理解不足。后续需要考虑如何增量的方式融入新知识或者使用类似LORA的方式挂载外部知识。
此外,在使用过程中发现,ORC效果很差,但是技术报告里面声称,在微调阶段使用了OCR数据:OCR-VQA,但是在实际使用的时候,为啥OCR能力如此差?同样有待后续提高。


)



)






)

 数学建模挑战赛 解题思路)

集实战及其原理分析)

