大家如果有兴趣做网站,在买了VPS,部署了wordpress,配置LNMP环境,折腾一番却发现内容提供是一个大问题,往往会在建站的大(da)道(keng)上泄气 ,别怕,本文解密如何使用爬虫来抓取网站内容发布在你的网站中,并提供源代码。
大概简要说下写爬虫的几个步骤,在学习的过程中,有成就感会给你前进莫大的动力,学习爬虫也是如此,那么就从最基础的开始:
Python有各种库提供网页爬取的功能,比如:
urllib urllib2 Beautiful Soup:Beautiful Soup: We called him Tortoise because he taught us. lxml:lxml - Processing XML and HTML with Python Scrapy:Scrapy | A Fast and Powerful Scraping and Web Crawling Framework Mechanize:mechanize PyQuery:pyquery: a jquery-like library for python requests:Requests: HTTP for Humans
下面我们只用python的urllib2和newspaper库来抓取文章:
首先用urllib2将页面抓取下来,打印查看一下,新手就是要多print print print 重要的事情说三遍!
import urllib2
import re #re是正则表达式,用于匹配文本,提取网页首页里文章的url地址
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’) #这里是设置默认的编码,一般为utf-8
url=‘www.example.com’
req=urllib2.Request(url)
html=urllib2.urlopen(req).read()
可以用print html 查看一下获取的网站首页内容,一般包含了许多杂七杂八的东东,比如广告、版权声明等等等,所以需要使用正则表达式从杂乱无章的内容中提取url
然后需要使用正则表达式提取你需要抓取的网页首页里所包含的文章网址
url_list = re.findall(‘<a target=“_blank” href="(.*) " title=’,html)#示例
获取的文章地址一般存在一个list列表中,你可以使用print type(url_list)来查看获取的url类型,如结果输出可能是这样子:
[‘http://www.example.com/article1’,
'‘http://www.example.com/article2’,
‘‘http://www.example.com/article3’’,
'‘http://www.exampele.com/article4’,]
那么我们就可以使用for循环来获取每一篇文章的url,有了文章的url就好办啦,因为往往我们用urllib2和正则表达式结合获取的是有很多噪声内容的,也就是杂质比较多。
提取网页正文内容的算法思路是这样,根据文本每一行和上下文的的长度来判断它是否是正文内容,这样来降噪,也就是去除杂质文本,我们可以使用Goose、newspaper、readbilitybundle等开源库来获取正文内容,
正文抽取的开源代码,基于文本密度的html2article: 我为开源做贡献,网页正文提取——Html2Article 基于标签比例的机器学习Dragnet: GitHub - seomoz/dragnet: Just the facts – web page content extraction 专注新闻类网页提取的Newspaper:GitHub - codelucas/newspaper: News, full-text, and article metadata extraction in Python 3 集成goose等三种算法的readbilitybundle GitHub - srijiths/readabilityBUNDLE: A bundle of html content extraction algorithms
这里我们使用newspaper,我在这里参考了网页正文提取工具这篇文章,感谢作者!
安装好newspaper后直接from newspaper import Article,然后按照以下步骤几步就可以搞掂啦!
for i in url_list:
a=Article(i,language=‘zh’)
a.download()
a.parse()
dst=a.text
title=a.title
print dst
print title
当然文章的url列表有可能也是这样:
[(‘http://www.example.com/article1’,’lhosdoacbw’)’
(‘http://www.example.com/article2’,’e83ry97yfr7fg9’)
(‘http://www.example.com/article3’,’jdoqf8yyrfrohr’)
(‘http://www.example.com/article4’,’djq0u9u0qfh8q’)]
要获取文章的url也很简单,使用range函数
for i in range(len(url_list)):
urls=url_list[i][0]
a=Article(urls,language=‘zh’)
a.download()
a.parse()
dst=a.text
title=a.title
print dst
print title
也有很多坑,主要是环境配置的安装的时候会有各种不成功,比如Scrapy安装的时候会要求预装很多其他的库,烦不胜烦,Windows系统那就更麻烦了,我用ubuntu配置环境没成功,怒而转向我在搬瓦工买的vps,装了centos系统后就方便多了,当然还有python版本的问题,centos6.5默认python版本是python2.6,所以需要升级并设置默认环境和版本。
这样再结合wordpress xmlrpc就可以把爬取的内容发送到你的网站了,再使用Linux系统里的定时执行任务的程序crond,设置每个小时执行一次任务,写多个爬虫分别爬取不同的站点在不同的时间段定时执行,简直不能再酸爽!!!
最后
分享一份Python的学习资料,但由于篇幅有限,完整文档可以扫码免费领取!!!

1)Python所有方向的学习路线(新版)
总结的Python爬虫和数据分析等各个方向应该学习的技术栈。

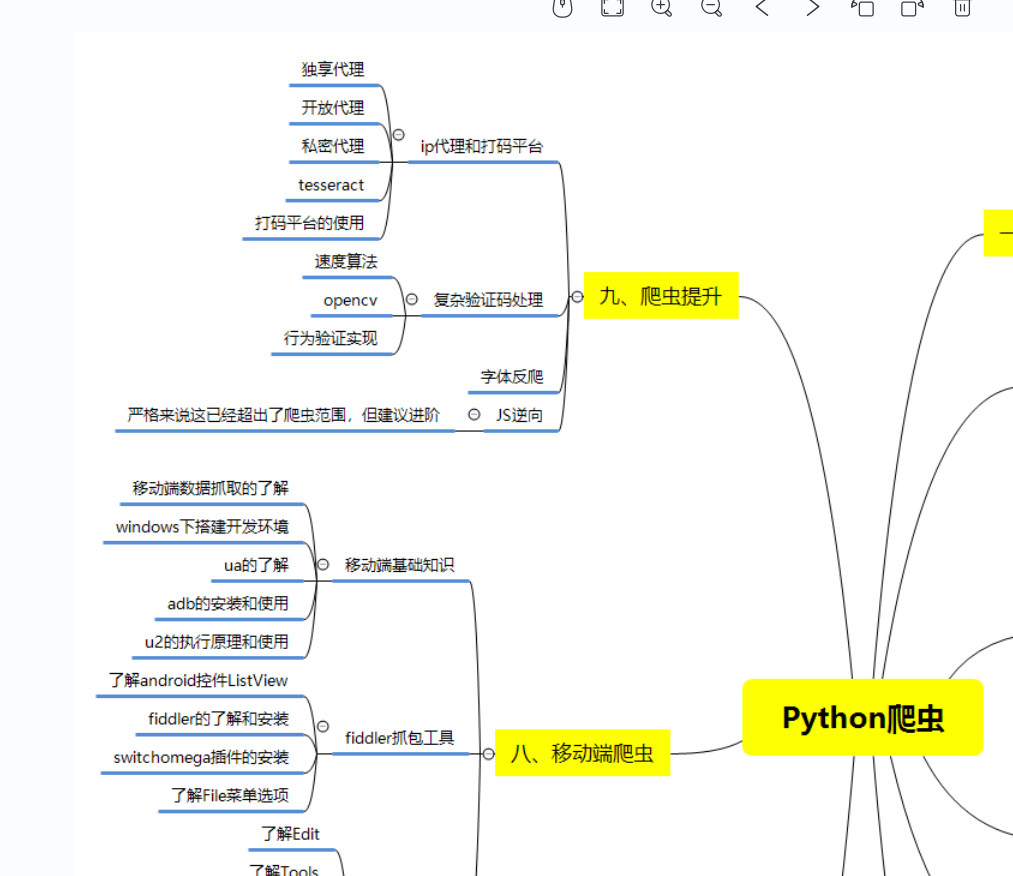
比如说爬虫这一块,很多人以为学了xpath和PyQuery等几个解析库之后就精通的python爬虫,其实路还有很长,比如说移动端爬虫和JS逆向等等。
(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然达不到大佬的程度,但是精通python是没有问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

。

)











)
)


![[计算机提升] Windows文件系统类型介绍](http://pic.xiahunao.cn/[计算机提升] Windows文件系统类型介绍)

)