在Wave Summit 2023深度学习开发者大会上,来自百度的资深研发工程师贺思俊和王冠中带来的分享主题是:飞桨大模型套件,一站式体验,性能极致,生态兼容。

大语言模型套件PaddleNLP
众所周知PaddleNLP并不是一个全新的模型库,自2021年以来PaddleNLP一直是国内头部的开源NLP库,在GitHub上拥有超过一万的Star。大模型时代,PaddleNLP升级成为飞桨大语言模型套件,同时秉承了一站式体验、性能极致、生态兼容的设计理念。
下面是飞桨大语言模型套件的全景图。中间是飞桨的核心深度学习框架,在其之上是飞桨针对大模型场景专门打造的全流程工具链。工具链里面主要分为五环,预训练、精调、压缩、推理、部署。从模型和工具链的角度,飞桨希望能够打造一个统一的全流程工具链,去覆盖尽可能多的模型。不管是百度自研的文心大模型,还是社区的第三方大语言模型,都尽可能去支持并沿用这套统一的方案。硬件方面,飞桨也希望能够发挥百度既有的硬件生态,让大模型在不同的平台上都跑起来。

一站式体验
不论工程优化或者前沿算法多么复杂,都可以在飞桨解决端到端的问题,不需要用户到处去找开源库,去攒自己的方案。百度飞桨在2021年就发布了业界首创的4D混合并行技术,并且依赖这套技术数次在国际权威的Benchmark MLPerf Training上做到了世界范围的性能第一。
因为大模型对于极致性能的要求,飞桨也将这套分布式的技术加入了PaddleNLP的全场景Trainer。让用户可以通过简单的参数化配置,控制复杂的并行策略。
如下图右边的代码片段。导入飞桨框架和PaddleNLP套件,简单定义一个4D混合并行配置,初始分布式环境,最后通过Auto API来加载这个模型。加载回来的模型会根据用户所提供的分布式配置调整结构,后续就可以直接开始训练或者推理。
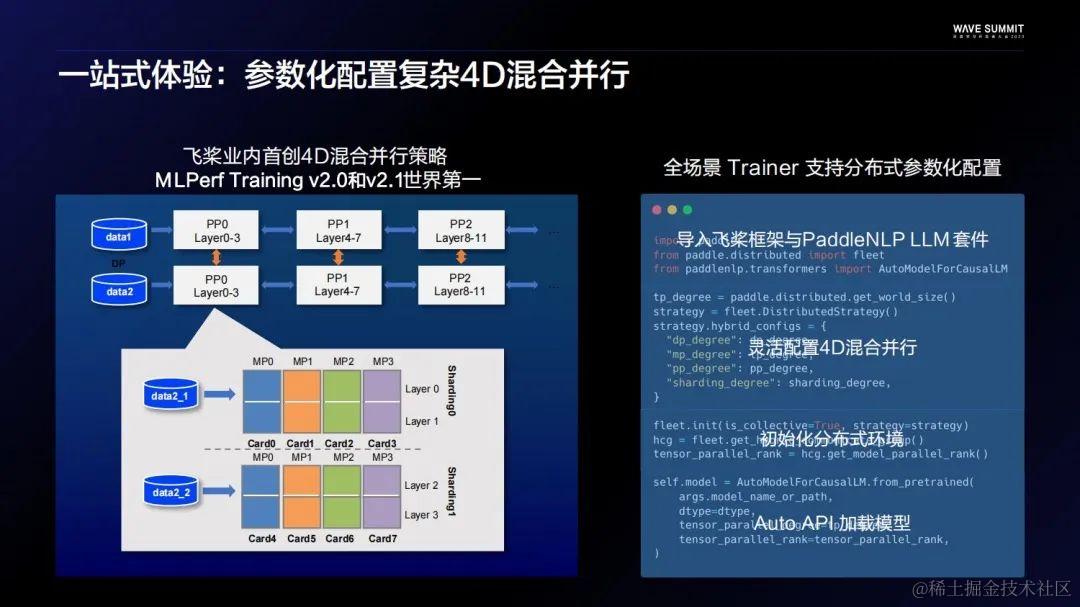
关于精调部分,飞桨大模型内置了业界主流的两种高效精调算法,LoRA和Prefix Tuning。再搭配上面说到的分布式策略,单机就可以做到微调千亿以上的模型。同样,飞桨也提供了一套统一的使用方法。虽然LoRA和Prefix各有优劣,但他们使用的方法是基本一致的。用户只用定义一个Config,就可以把Auto API加载回来的模型自动转为LoRA模型或者Prefix模型,然后便可直接开始训练。高效精调策略的核心优势之一是大大降低了大模型训练的门槛,一般情况下,它跟普通的精调SFT相比,硬件门槛只有之前的1/4左右。
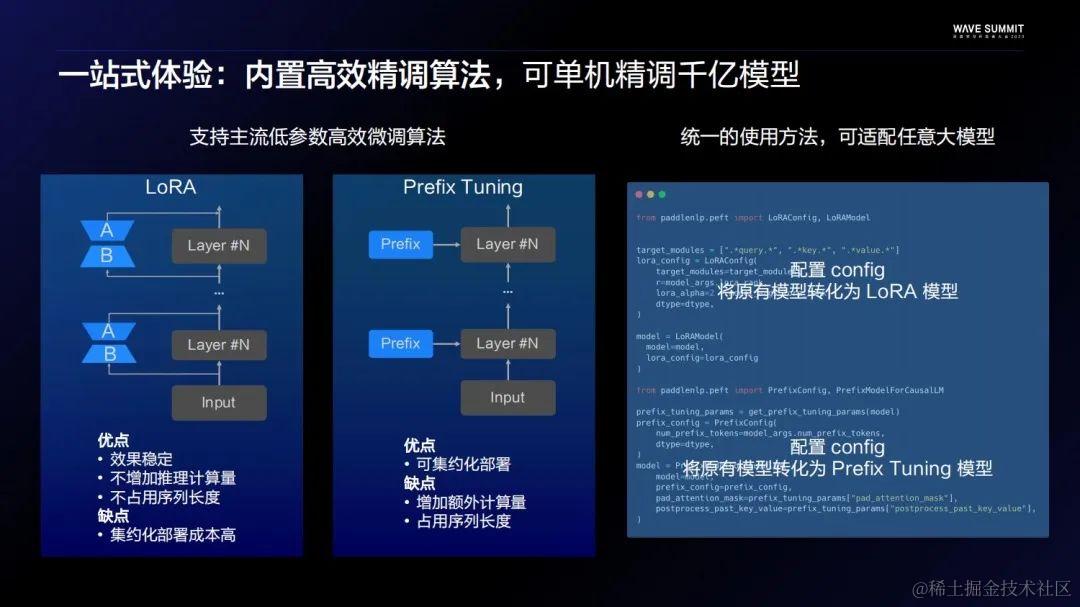
量化压缩方面,飞桨也内置了业界两种比较主流的量化算法,GPTQ和SmoothQuant。同时飞桨还开源了PaddleSlim团队自研的自适应Shift-SmoothQuant算法,这个算法能够解决一些SmoothQuant无法解决的量化Case。比如当一个模型的权重和激活的异常值发生在同一个通道的时候,一般SmoothQuant算法没有很好的方法去得到一个Scale,从而导致量化的损失。而PaddleSlim提出的分段搜索是一个很好的解决方案。
依托PaddleSlim全面实现了主流大模型的无损量化,从下图可以看到,不论是百度自研的ERNIE Bot Turbo,还是开源的ChatGLM、Bloomz、LLaMA等模型,不论是直接量化大模型或者先精调大模型再量化,都可以把量化的损失控制在一个点以内。

性能极致
预训练阶段,在飞桨框架以及大模型的Transformers结构上都做了全环节的算子融合。比如每个大模型都有一个不可或缺的Self-Attention层,将它的MultiHeadAttention层,还有FFN分层,甚至最后的Optimizer都做了算子融合,这让飞桨和业界主流的预训练库Megatron LM比起来有了一定的性能优势。
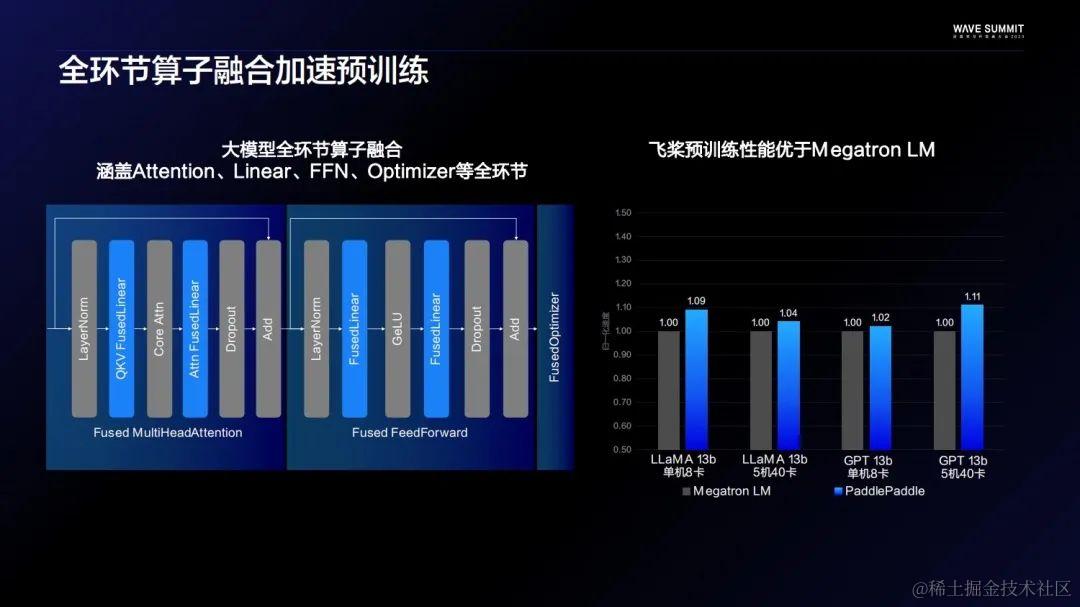
到了精调阶段,在算子融合的基础上,进一步对变长数据流做了比较极致的优化,大大提高了Token的有效率,其方法就是降低Pad Token的占比。通过上图可以看到飞桨和Hugging Face的Transformers比,在各个不同的模型结构上,都有一倍左右的性能优势。
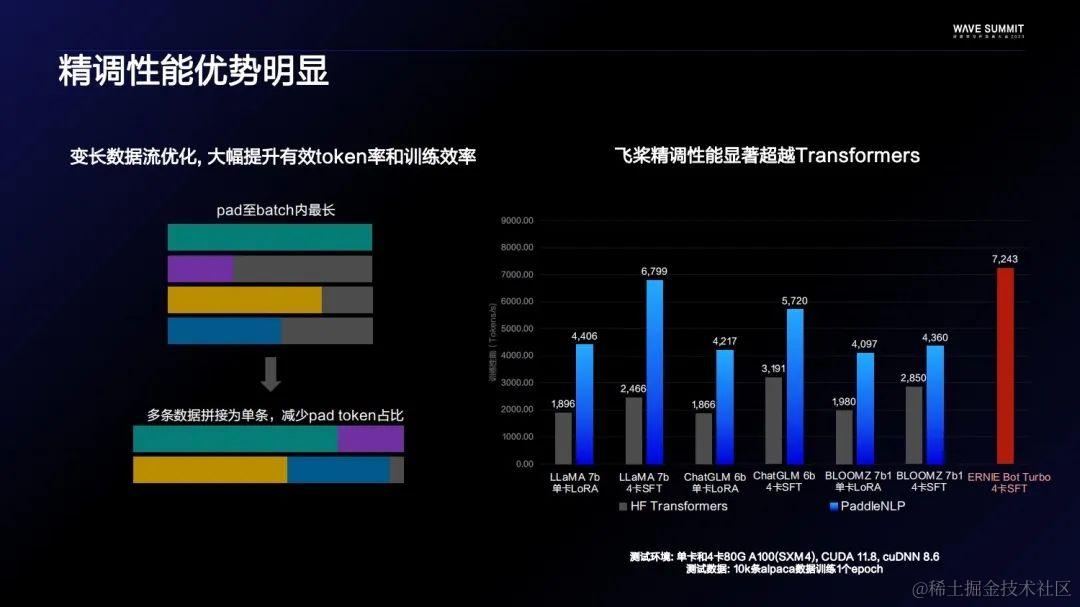
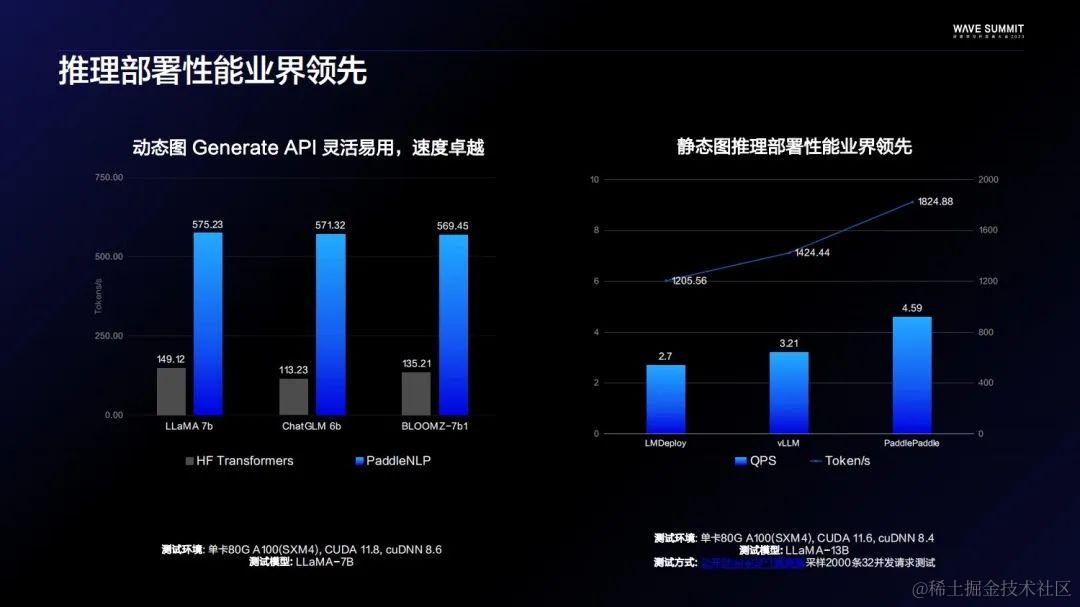
自文心一言上线以来,推理部署性能达原先30多倍,这也是负责飞桨推理的同学的功劳。飞桨大模型套件也整合了一部分在文心一言上使用过的优化点。比如推理算子融合,它让飞桨在对齐Transformers生成API和使用体验的情况下,提升三倍以上的性能优势。同时,得益于自研的动态插入技术,静态图推理部署也是业界领先。和几个主流的开源部署代码库比,不管吞吐还是实验都是业界最好的。
生态兼容
一直以来,不管是飞桨还是PaddleNLP,都有生态兼容的理念。现在也有非常多优秀的开源大模型,大家都能够在自己发布的大模型上顺畅的走通训压推流程。而目前,应该只有飞桨大模型套件可以做到使用同样一套工具去覆盖业界主流模型。此外,飞桨还基本对齐Hugging Face Transformers的API,也支持比较方便的去加载Hugging Face社区上的模型权重。

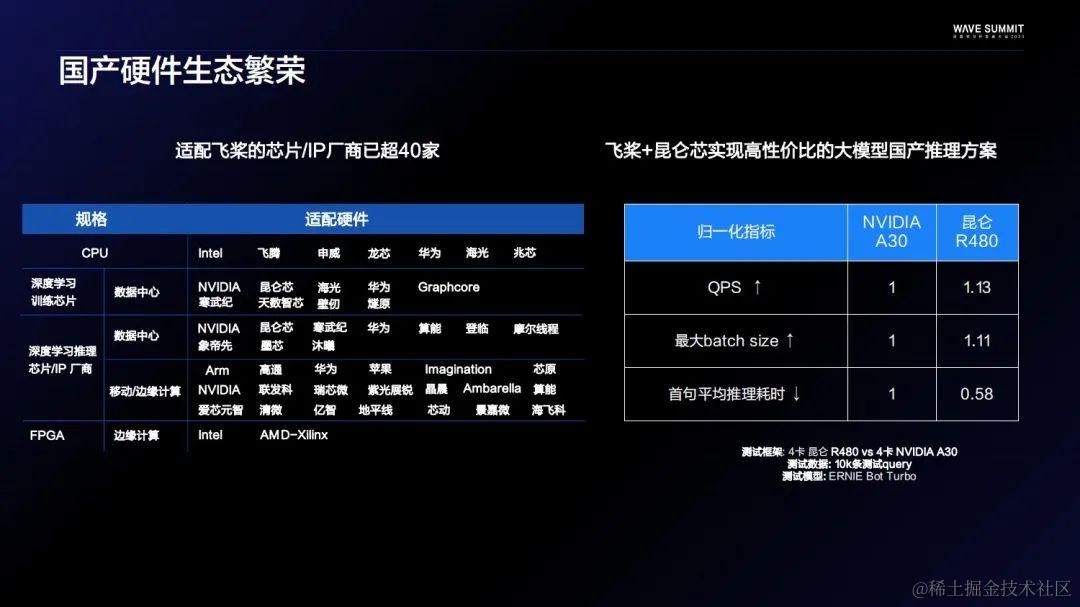
硬件生态是生态建设的重要一环。迄今为止,飞桨已经适配了超过40家的芯片/IP厂商,也成功发布了硬件共创计划。大模型时代的到来,给硬件带来新的挑战,飞桨大模型套件在国产硬件适配的道路上进行了很多优化,实现了芯片层、框架层和模型层的联动。比如基于飞桨和昆仑芯 ,实现了一套高性价比的国产大模型推理方案。能够在ERNIE Bot Turbo上使用更大的Batch Size,承载更高的QPS,以及产出更低的数据延迟。
跨模态大模型套件PaddleMIX
跨模态大模型技术发展趋势
跨模态的大模型被认为是从限定领域的弱人工智能,通向通用人工智能的一条探索路径,它更符合人类通过视觉、听觉等不同的感官去认知世界的过程。比如下图展现的这只狗,我们可以通过图片、文字、视频、音频的形式去描述它。目前跨模态大模型前沿的进展就包括了像以图生文为首的理解类任务,也包括以文生图为首的生成类任务。近期也出现了大量融合其他模态的跨模态大模型,这是必然的趋势之一。这些不同模态的增多也在促进创新应用的增多,另一个趋势是模型体量的增大。从下图右边部分可以看到,随着模型体量的增大,视觉问答的效果是不断提升的。
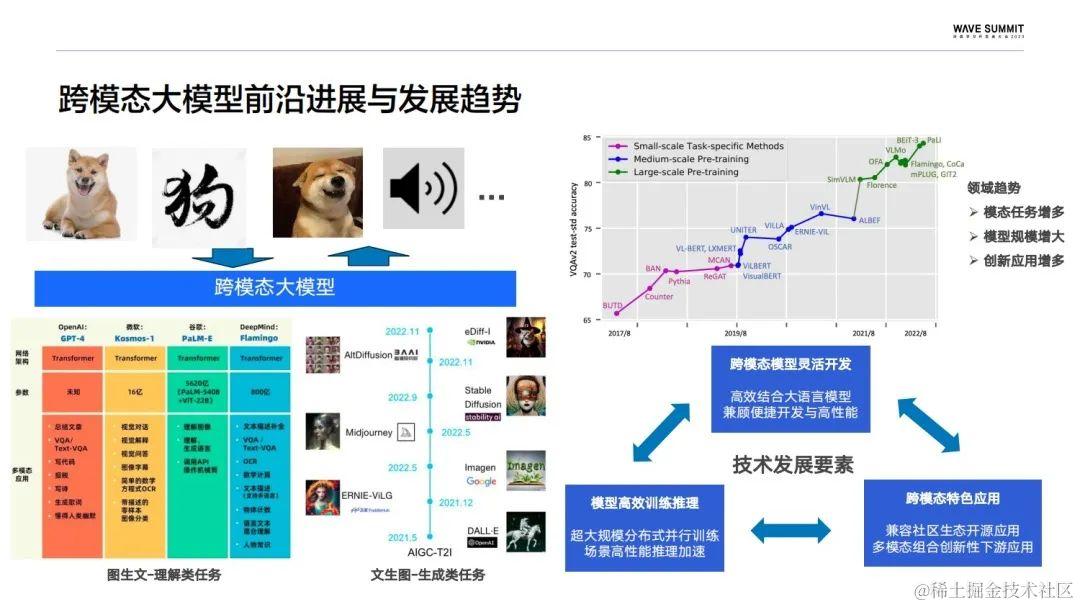
结合前沿的发展趋势可以总结出,核心的技术要素主要分为开发、性能以及应用。目前跨模态大模型的开发主要是以大语言模型为基础,开发的一个核心是高效地融合大语言模型。而极致的性能优化可以为大模型带来成本的大幅降低。社区当中已经涌现了大量的跨模态应用,不同模态的融合也为更多的创新应用提供了空间。
跨模态大模型套件PaddleMIX
下面是PaddleMIX的全景图。依托飞桨的核心框架,PaddleMIX推出了一套完整的大模型开发工具链。从开发,训练,精调到推理部署,上层的模型也覆盖了像图片、文本、音频、视频等不同的模态。模型库划分为多模态预训练和扩散模型两部分,其中包含了一些主流的的跨模态算法,结合这些不同的跨模态模型,PaddleMIX也推出了大模型的应用工具集,其中包括了文生图的应用pipeline,以及跨模态任务流水线AppFlow。
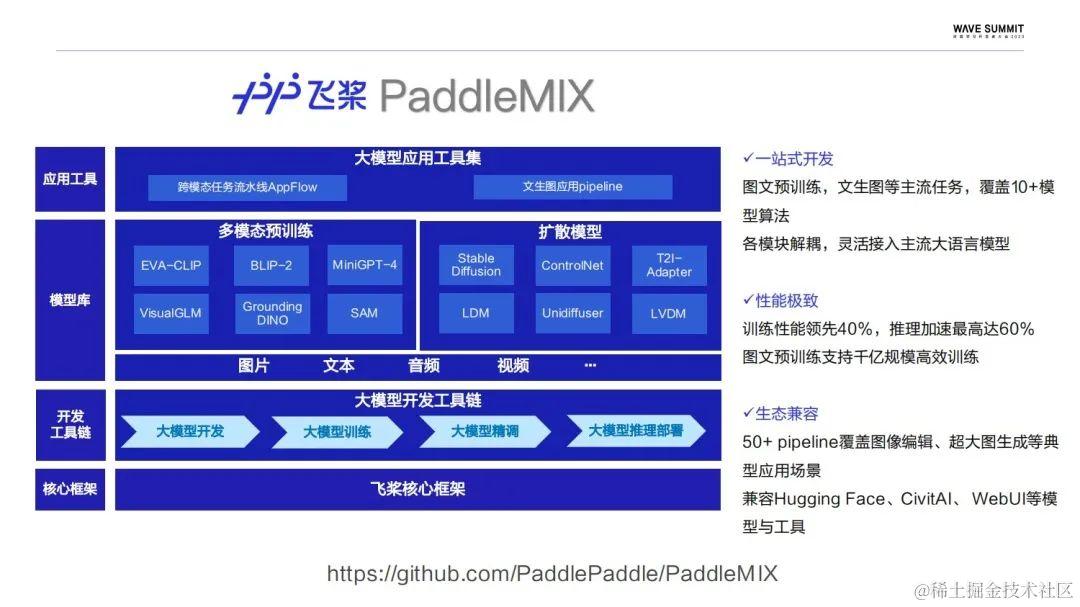
PaddleMIX的特点跟PaddleNLP大语言模型套件保持一致,它也具备一站式模型的开发体验,以及极致的训练、推理性能,同时保持生态的兼容。
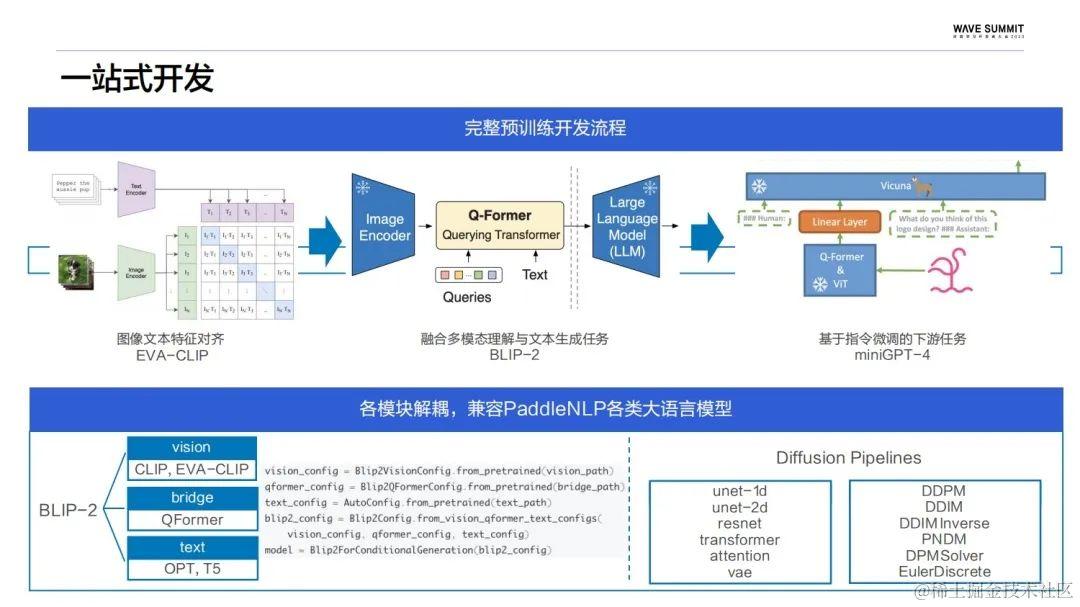
在一站式开发上,PaddleMIX针对图文预训练提供了一套完整的预训练开发流程,从CLIP系列的图文特征对齐,到以BLIP-2为代表的通过衔接模块连接大语言模型,同时冻结视觉语言模块来实现低成本、高效的跨模态预训练。最后是以MiniGPT4为代表的指令微调任务,去实现像VQA/Caption这种跨模态的下游任务。这里,不同阶段涉及的模型代码权重在PaddleMIX当中有做充分的打通,以提高跨模态预训练的开发效率。
对于模型解耦、兼容PaddleNLP的各类大语言模型,举了两个典型的结构,BLIP-2分为视觉、衔接以及语言模块,这些不同的模块都可以独立地进行配置,语言模型也可以灵活地进行替换。扩散模型更多的以pipeline的形式来实现不同的生图功能,这里会通过像unet,还有VAE这样独立的子模型,以及不同策略来实现循环采样。
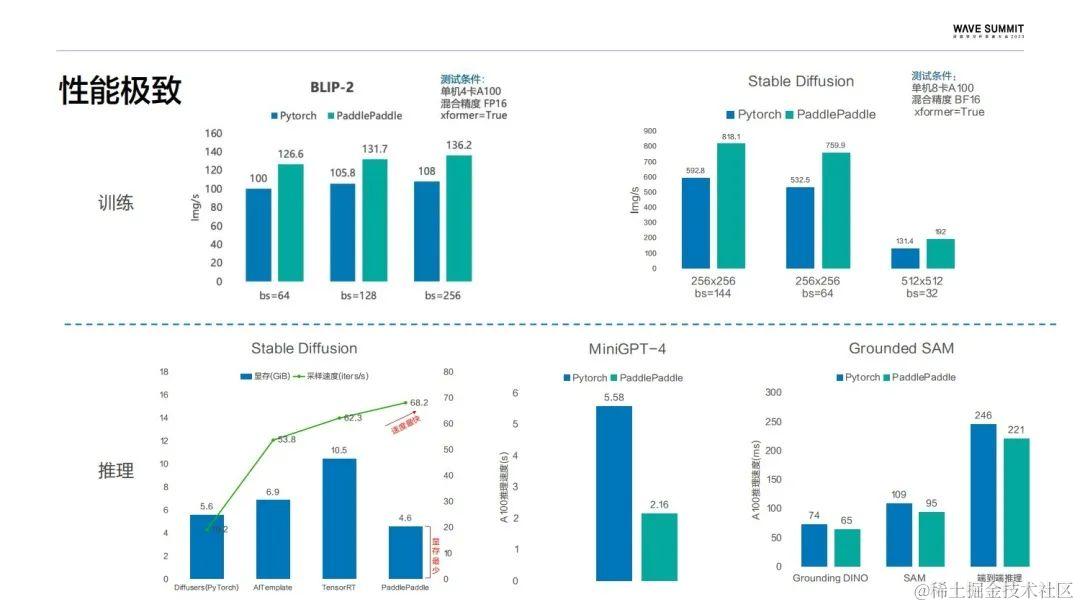
性能方面,结合飞桨核心框架做了一系列极致优化。训练侧,基于Flash Attention以及Fuse Linear的模块实现了BLIP-2在单机4卡的性能超越了Pytorch 25%。Stable Diffusion的训练性能超越了Pytorch 40%。推理侧,通过不同粒度的算子融合以及组网逻辑的一系列优化,在SD方面实现了出图速度达到Pytorch的四倍,它的显存占用也仅为TensorRT的43%。像MiniGPT-4的推力达到了加速1.6倍的效果,Grounded SAM较Pytorch的性能也提升了22%。
生态方面,PaddleMIX也提供了一套独立的PPDiffusers扩散模型工具箱,通过兼容Web UI和Civital以支撑这些复杂的Prompt,还能和万余种权重在众多场景中完成生成任务。权重生态方面,PPDiffusers也支持了Civital,提供超过3万余个LORA权重,来实现各类的个性化文生图模型。
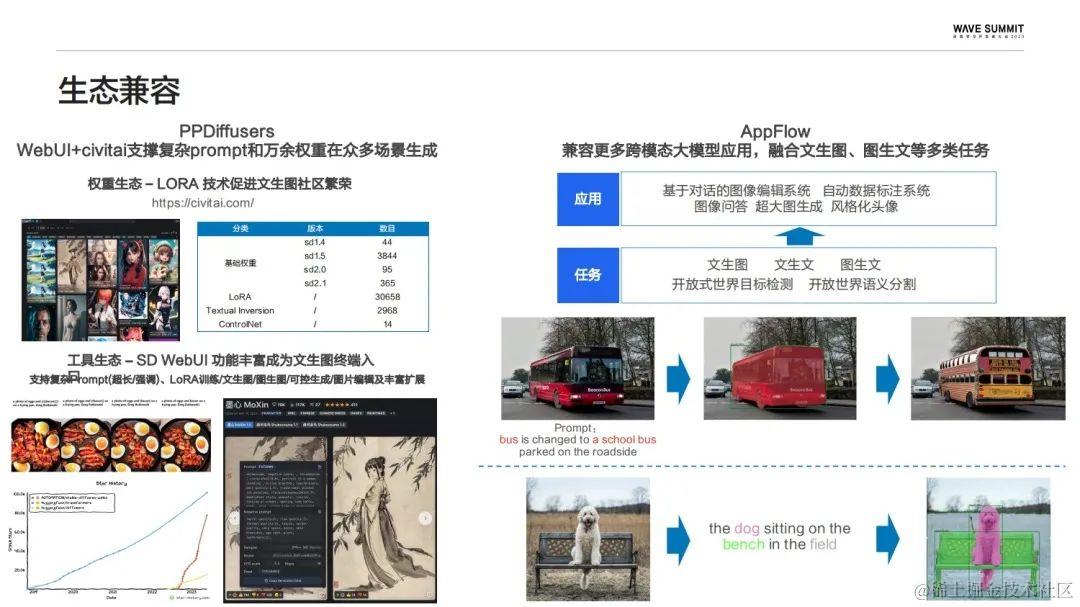
工具方面,兼容了WebUI来实现丰富的功能,比如可控生成、图像编辑。除此之外,PaddleMIX还提供了AppFlow跨模态任务流水线,它的目的是为了串联文生图、图生文这样的一些基础任务,来实现更加复杂的跨模态应用。比如基于对话的图像编辑系统,还有自动数据标注系统等等。同时,AppFlow也具备简单易用的特点,开发者们可以很方便的调用代码实现一键预测。
PaddleMIX应用体验
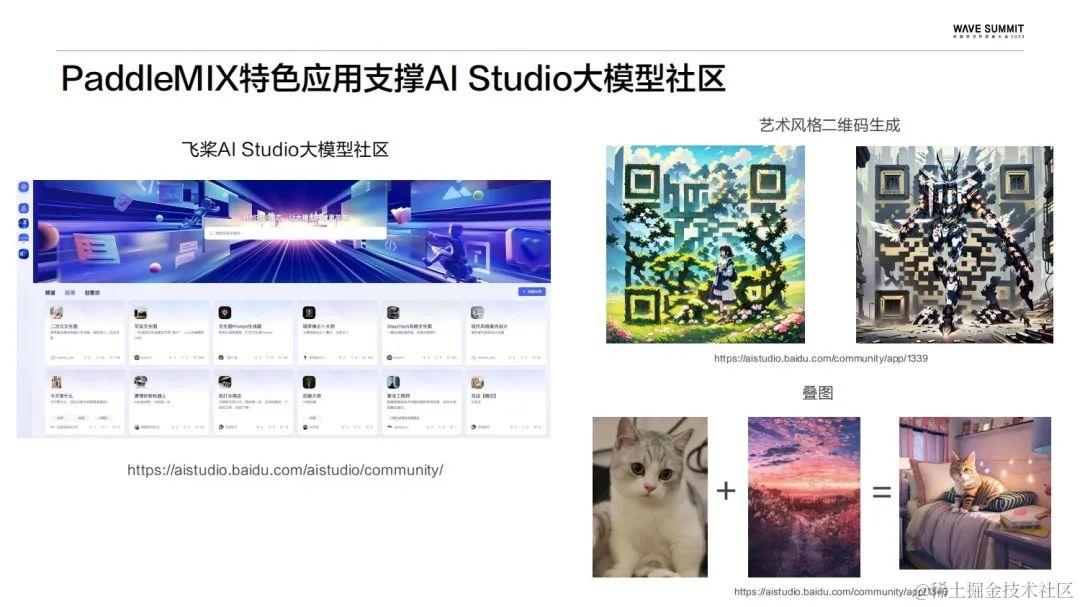
目前基于PaddleMIX所实现的这些特色应用已经上线到飞桨AI Studio星河社区,包括艺术风格二维码的生成,生成属于自己的特色二维码,这里推荐大家把链接复制到PC端,会有更好的使用体验。下图右下角是一个叠图应用,可以基于输入的两张图片和特定的提示词,自定义融合生成一张全新的图片。当然,后续PaddleMIX也会陆续上新更多的特色应用,也期待更多开发者们集思广益,来AI Studio上创建属于自己的大模型应用。
本篇文章根据WAVE SUMMIT 2023深度学习开发者大会讲稿整理而成



)
)


![[计算机提升] Windows文件系统类型介绍](http://pic.xiahunao.cn/[计算机提升] Windows文件系统类型介绍)

)


(Spring Cache,缓存配置)(注解方式))
真题解析)





