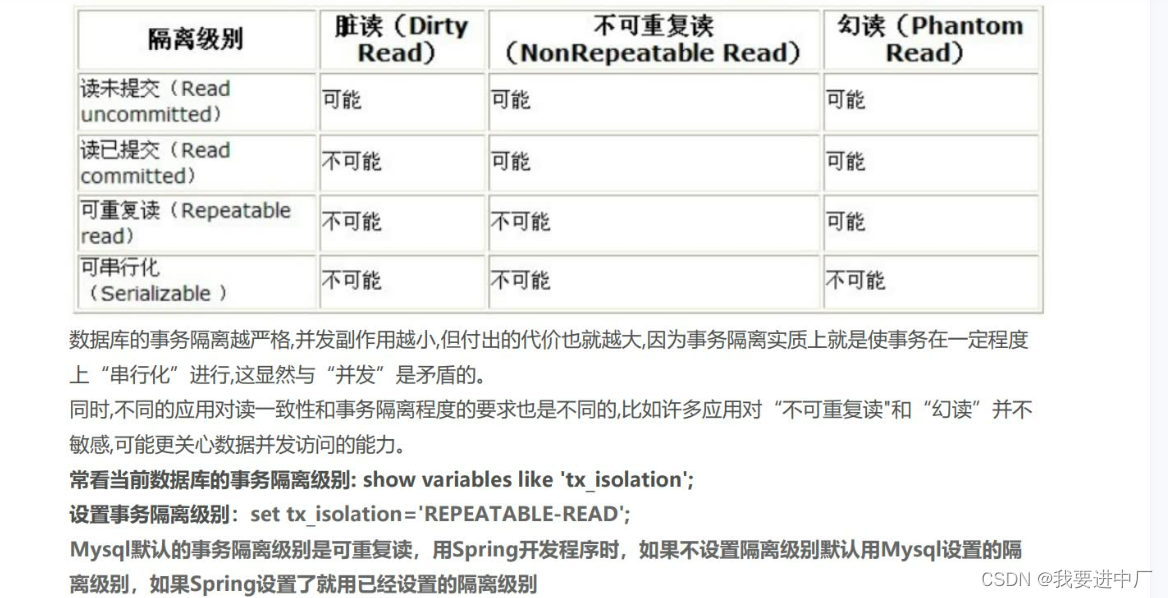
一)事务的特性:
一致性:主要是在数据层面来说,不能说执行扣减库存的操作的时候用户订单数据却没有生成
原子性:主要是在操作层面来说,要么操作完成,要么操作全部回滚;
隔离性:是自己的事务操作自己的数据,不会受到到其他事务的影响;
持久性:事务进行提交以后,数据要真实的修改在磁盘上面,不能说系统宕机数据就丢失了
二)脏写:
2.1)数据丢失或者是脏写:当有两个事务或者是多个事务选择同一行,然后基于最初的值选定该行的时候,由于每一个事务都不知道其他事务的存在,就会发生数据丢失更新问题,最后的更新覆盖了其他事务所做的更新;
乐观锁:就是假设两个事务并发执行,一个事务想要把库存扣减3,另一个事务想要把库存扣减2,那么两个事务并发执行的时候,此时就会发生脏写问题,如何解决呢,可以使用版本号机制,给库存字段再加上一个版本号,每进行一次数据的更新操作,版本号+1,此时就可以解决脏写问题,此时一定会出现一个事务版本号小于等于内存版本号,更新失败;
悲观锁:一个事务针对于要操作的数据加锁,其他事务想要操作数据,只能阻塞等待;
2.2)脏读:事务A读取到了事务B已经修改但是没有提交的数据,因为数据不稳定,发生脏读一定会发生不可能重复读和幻读;
2.3)不可重复读:事务A相同的查询语句在不同的时间查询到了不同的结果
可重复读就是不管其他变量对数据是否修改,第一查询只要查询的结果是true,后面只要当前事务不修改当前这个布尔值,那么读取到的始终是一条结果,侧重于已经存在但是修改过的数据
2.4)幻读:一个事务A会读取到事务B新增的数据
表锁:每次操作锁住整张表,开销小,加锁快,不会出现死锁,锁定粒度大,发生锁冲突的概率最高,并发度最低,一般用在整表数据迁移的场景,防止数据迁移数据发生变动;
手动增加表锁:lock table 表名称1 read(write),表名称2 read(write)
查看加上的表锁:show open tables
删除表锁:unlock tables;
加读锁:只能读取该表,不能写该表
加写锁:即可以读,又可以写,其他事务既不能读,也不可以写
行锁:每一次操作锁住一行记录,开销大,加锁慢,锁定粒度最小,发生所冲突的概率最低,并发程度最高,InnoDB和MYSIM存储引擎有两个区别:
1)InnoDB支持事务
2)InnoDB支持行级锁
行锁演示:一个Session开启事务以后不提交,另一个Session更新同一条记录的时候会发生阻塞,更新不同的记录的时候不会发生阻塞;
3)表锁开销小,加锁块,但是行锁开销大,加锁慢,这样子理解很简单,对于表来说只要找到这一张表,就可以直接给他加锁,速度很快,但是对于行锁来说,先要找到表,再来找行,效率很低,行锁的粒度肯定是比表锁小的,粒度越大,锁冲突的概率还是比较高的
4)MYSIM存储引擎在执行Select语句之前,会自动给设计所有的表加读锁,在执行update,insert,delete操作的时候会自动给涉及到的表加写锁,但是InnoDB存储引擎在执行查询语句Select操作的时候,因为有MVCC机制所以不加锁,但是update,insert和delete操作会加行锁,总而言之,就是读锁会阻塞写,但是不会阻塞读,但是写锁会把读和写都会阻塞
在数据库没有提交数据的时候,你更新的数据是在缓存进行更新的,事务与事务在并发进行的时候就叫作隔离级别,只有在提交之后,数据才从日志中把数据更新到数据库里面





三)MVCC:无论事务是否提交,undolog版本链的数据都是要记录下来的,因为事务要回滚,所以要记录,基于快照结果集+undolog版本链,undolog版本链只有一份;
1)begin和start transaction并不是一个事务的起点,在执行到第一个DML语句的时候,也就是执行到他们的第一个修改操作InnoDb的语句的时候,事务才算是真正的进行启动,才会向MYSQL中申请事务id,执行select操作是不会生成事务ID的
2)insert新插入的数据的版本连上面的记录的回滚指针的地址就是null,因为当前数据已经是最早的纪录了,不管事务是否提交,update更新的数据都会存放到undolog版本链中,一行数据由四个部分组成,当前事务操作操作完以后的数据完整记录+当前事务操作完成后的数据ID+聚簇索引ID+版本链(指针));
3)当一个事务id=60的事务新增了一条数据,那么这一行记录就变成
(userID=1,username="李四",60,聚簇索引ID,null(因为是事务新插入的第一条数据)
此时再来一个事务修改这条user数据username="王五",此时版本链的数据就变成了这样子:
0X666 (userID=1,username="王五",100,聚簇索引ID,0X777)| ---------------------------------------------------- | 0X777 (userID=1,username="李四",60,聚簇索引ID,null(因为是事务新插入的第一条数据)4)在可重复读级别,当事务开启以后,执行任何的查询SQL都会生成当前事务的一致性视图,也叫做readView,该视图只会生成一次且在事务提交前不会发生任何变化,但是是如果是读已提交隔离级别下每一次执行查询SQL都会生成读视图(必须是当前读),但是从版本连中取数据一定是从最新的undolog版本连中的数据查找的;
5)当前进行比对的过程中是从当前undolog版本链的最新的记录的事务ID开始和读视图readView进行比对,从而来确定最终MYSQL读取的是哪一条记录,如果这条记录不符合要求,那么按照undolog版本链单向链表查询下一条符合要求的记录;
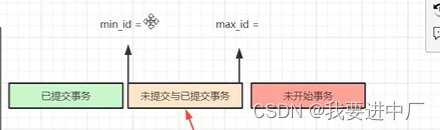
6)MYSQL会根据读视图中的最小事务ID和最大事务ID来划分区间
从而确定已提交事务和未提交事务
7)根据undolog版本链上的每一条记录的事务ID来判断当前这条记录是否已经在生成读视图之前提交了,小于min_id的一定是已提交事务,大于max_id一定是未提交事务,但是在min_id和max_id之间的记录有可能是已提交,也有可能是未提交;
8)事务操作中,update操作更新的是MYSQL中真实的数据;
比较规则:一个事务想要并可以读取到读视图生成之前事务提交的记录
1)trx_id=creator_trx_id,如果这条记录的事务ID等于创建读视图的事务ID,那么该数据记录的最后一次操作的事务就是当前事务,当前记录对当前事务可见;
2)trx_id<creator_trx_id,说明在生成读视图的时候这条记录的事务ID不在活跃列表里面,说明修改这条记录的事务已经在生成读视图之前提交了,所以当前记录可见;
3)trx_id>=max_trx_id,如果trx_id 值小于 Read View 中的 min_trx_id ,表示这个版本的记录是在创建 Read View后才启动的事务生成的,所以该版本的记录对当前事务不可见,否则会发生不可重复读的问题;
4)min_trx_id <= trx_id < max_trx_id:判断 trx_id 是不是在当前事务ID集合(m_ids)里面

四)一条SQL语句的执行流程:update user set name="张三" where userID=1;
1)执行器:调用执行引擎的接口把SQL语句丢给存储引擎层来进行执行
2)首先检查buffer pool缓冲池中有没有对应的数据,如果没有,就去加载缓存数据,把id=1的记录所在的16K页的数据加载到buffer pool中;
3)写入更新数据的旧值,用于回滚,将老的值写入到undolog回滚日志文件里面



















