1.计算机视觉的概念与原理
1.1概念
计算机视觉(CV)是人工智能的一个重要发展领域,属于计算机科学的一个分支,它企图让计算机能像人类一样通过视觉来获取和理解信息。计算机视觉的应用非常广泛,包括但不限于图像识别、物体检测、人脸识别、光学字符识别、机器人导航、虚拟现实、智能监控等。


1.2原理
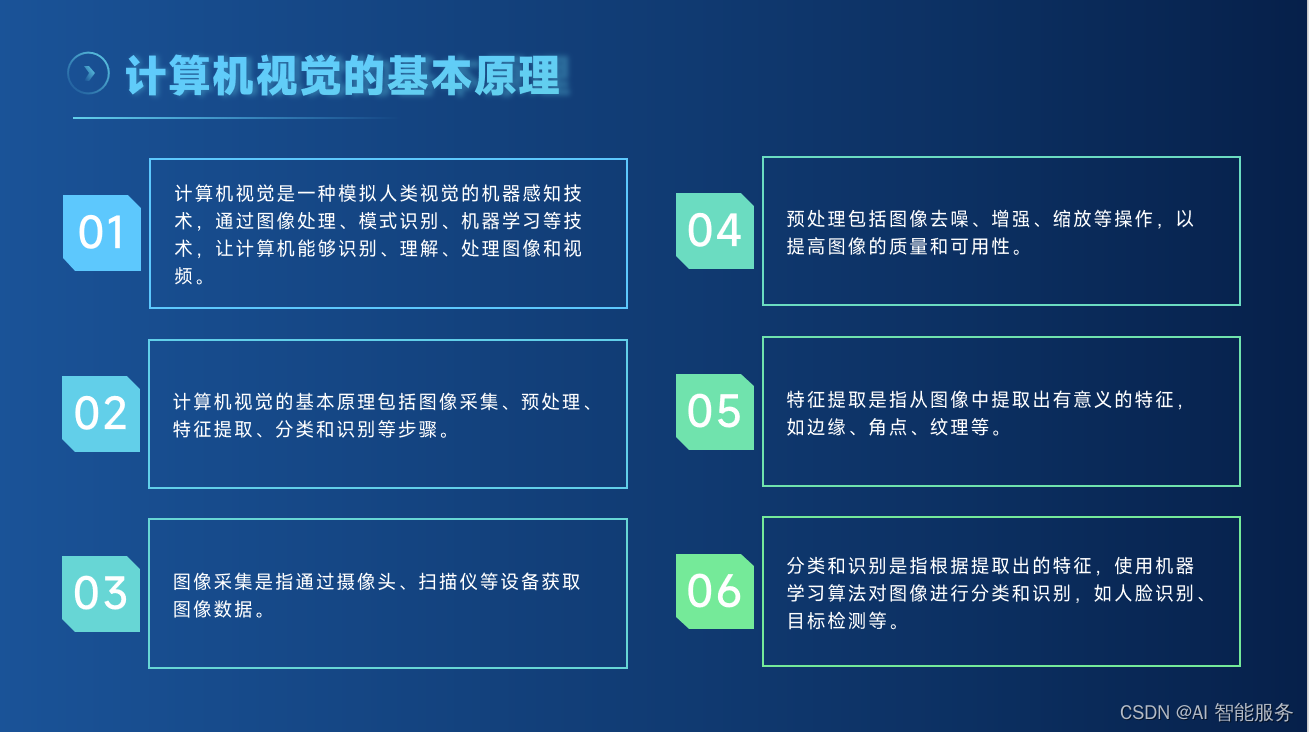
计算机视觉的基本原理是让计算机通过处理视觉输入(如图像和视频)来感知和理解这个世界。它利用各种成像系统(例如摄像头、显微镜等)来获取原始信号,并将这些信号转化为数字化形式,然后由计算机进行处理和解释。
在计算机视觉中,一种常见的方法是使用深度学习算法来训练计算机识别和分析图像中的各种特征和模式。这些算法可以通过多层神经网络来提取和分析图像中的各种特征,例如边缘、纹理、形状等,然后将这些特征组合起来形成更高层次的理解,例如识别出图像中的物体、人脸、文字等。
2.发展历程



3.关键技术
计算机视觉的关键技术有:
- 图像处理:这是计算机视觉的基础,包括图像增强、滤波、降噪、图像分割、形态学处理等。
- 特征提取:从图像中提取出有用的特征,常用的方法有边缘检测、角点检测、尺度不变特征变换(SIFT)等。
- 目标检测:在图像或视频中自动检测特定对象的位置和数量,常用的方法有Haar特征分类器、HOG+SVM、卷积神经网络(CNN)等。
- 目标跟踪:跟踪图像或视频中的目标,实现目标的持续识别和跟踪,常用的方法有卡尔曼滤波、粒子滤波、Mean-Shift算法、深度学习等。
- 图像识别:将图像中的内容自动分类或识别,常用的方法有支持向量机(SVM)、k最近邻(k-NN)、深度神经网络等。
- 深度学习:基于神经网络的图像识别、目标检测等任务的方法,常用的模型有卷积神经网络(CNN)、循环神经网络(RNN)、自编码器(Autoencoder)、生成对抗网络(GAN)等。
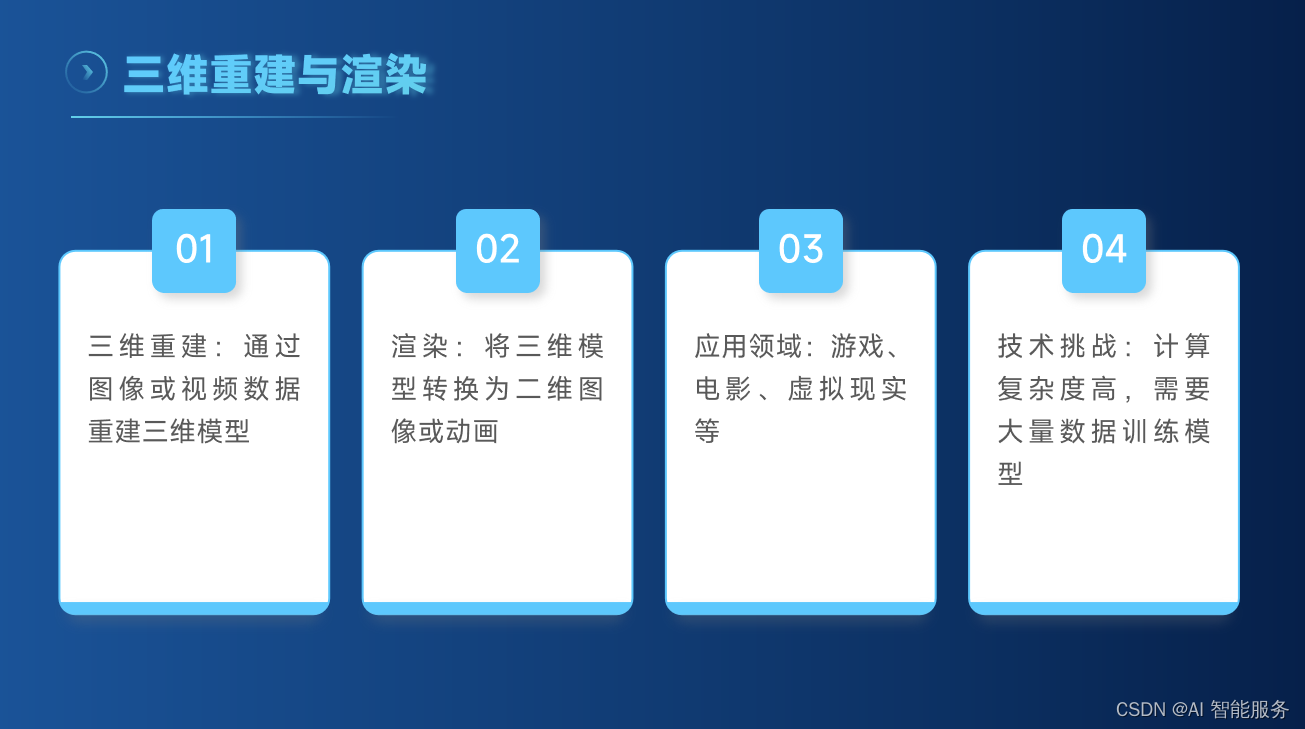
- 三维重建:包括立体匹配、结构从运动、激光扫描等方法,用于从多个图像或传感器数据中重建三维场景。
- 图像分割:包括基于边缘、区域和深度信息的方法,用于将图像分割成不同的区域或对象。
- 光流分析:包括基于像素级和区域级的方法,用于分析图像序列中的运动和变化。
下面做具体说明:


4.计算机视觉的未来展望



如下图:汽车能像人类一样通过视觉来获取和理解信息
特斯拉自动驾驶可以分为三个主要步骤:环境感知、路径规划和控制执行。
- 环境感知:特斯拉自动驾驶车辆通过自主驾驶计算机和各种传感器设备,对车辆周围的环境进行感知。其中,视觉摄像头用于识别车辆周围的车道线、交通标志和其他车辆、行人等;雷达和超声波用于检测车辆周围的障碍物和距离;激光雷达则可以提供更为精确的三维环境数据。
- 路径规划:特斯拉自动驾驶车辆通过自主驾驶计算机,基于环境感知数据和导航系统数据,进行路径规划。计算机算法根据当前道路情况和交通标志,为车辆规划最佳行驶路径和车速,同时避免碰撞和违规行驶等情况。
- 控制执行:特斯拉自动驾驶车辆通过自主驾驶计算机,控制车辆的加速、刹车、转向等行驶操作,以实现路径规划的结果。此外,特斯拉自动驾驶车辆还可以自动完成变道、超车、泊车等操作,提高了驾驶的便利性和安全性。



)







)




)



