提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、继承的概念及定义
- 1、继承的概念
- 2、继承的定义
- 2.1 定义格式
- 2.2 继承关系和访问限定符
- 2.3 继承基类成员访问方式的变化
- 二、基类和派生类对象赋值转换
- 三、继承中的作用域
- 四、派生类的默认成员函数
- 五、继承与友元
- 六、继承与静态成员
- 七、复杂的菱形继承及菱形虚拟继承
- 八、继承的总结和反思
前言
一、继承的概念及定义
1、继承的概念
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计层次的复用。
2、继承的定义
2.1 定义格式
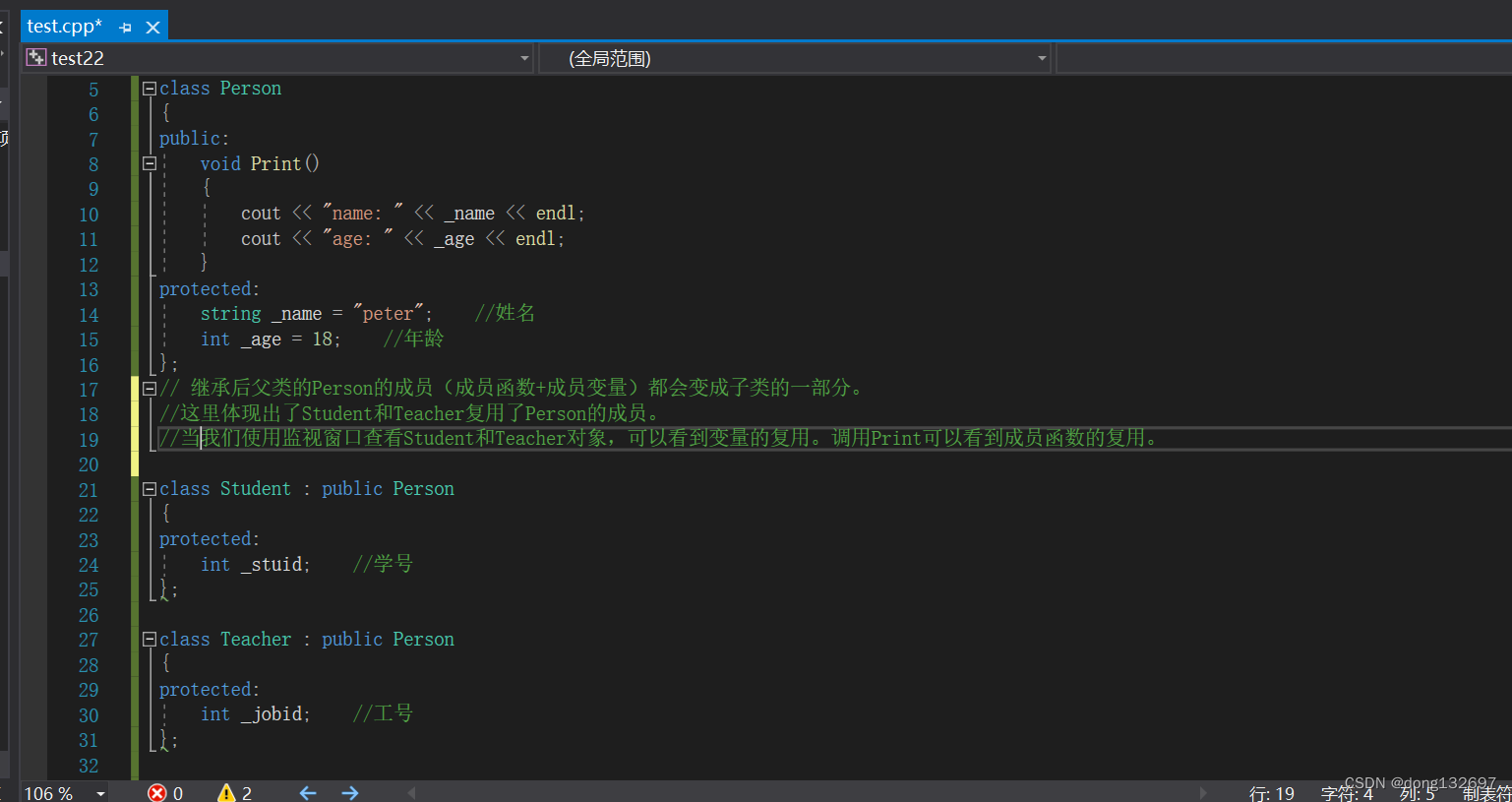
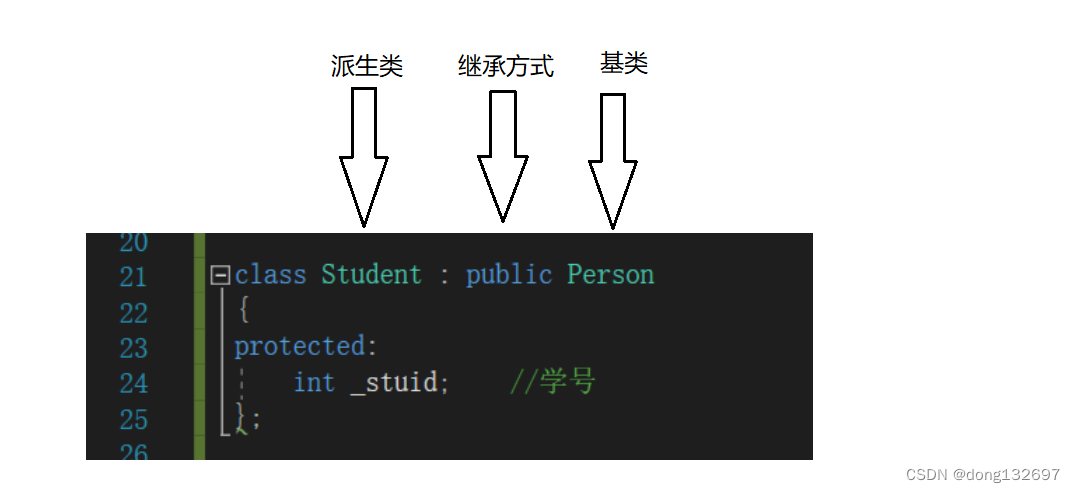
下面我们看到的Person是父类,也称作基类。Student是子类,也称作派生类。
2.2 继承关系和访问限定符

2.3 继承基类成员访问方式的变化
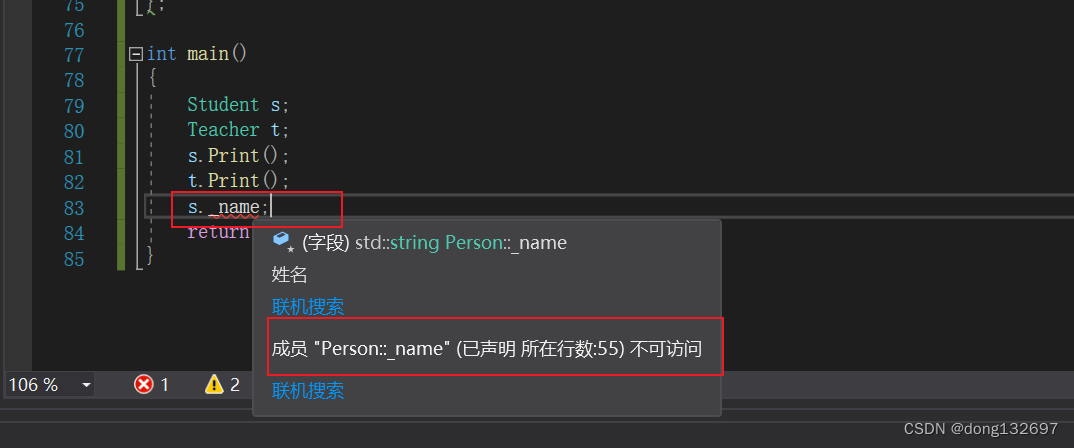
(1). 基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
我们看到基类Person中的private成员 _name 和 _age 不能在派生类Student和Teacher中直接访问,但是我们可以看到 _name 和 _age 还是继承到了Student和Teacher类中,并且Student和Teacher对象可以调用Person类中的Print方法打印这两个私有成员,这是因为Print方法为Person类的,虽然 _name 和 _age 为私有的,但是Person类中的方法还是可以访问的。当基类的一个成员不想继承给子类时,就可以设为private。
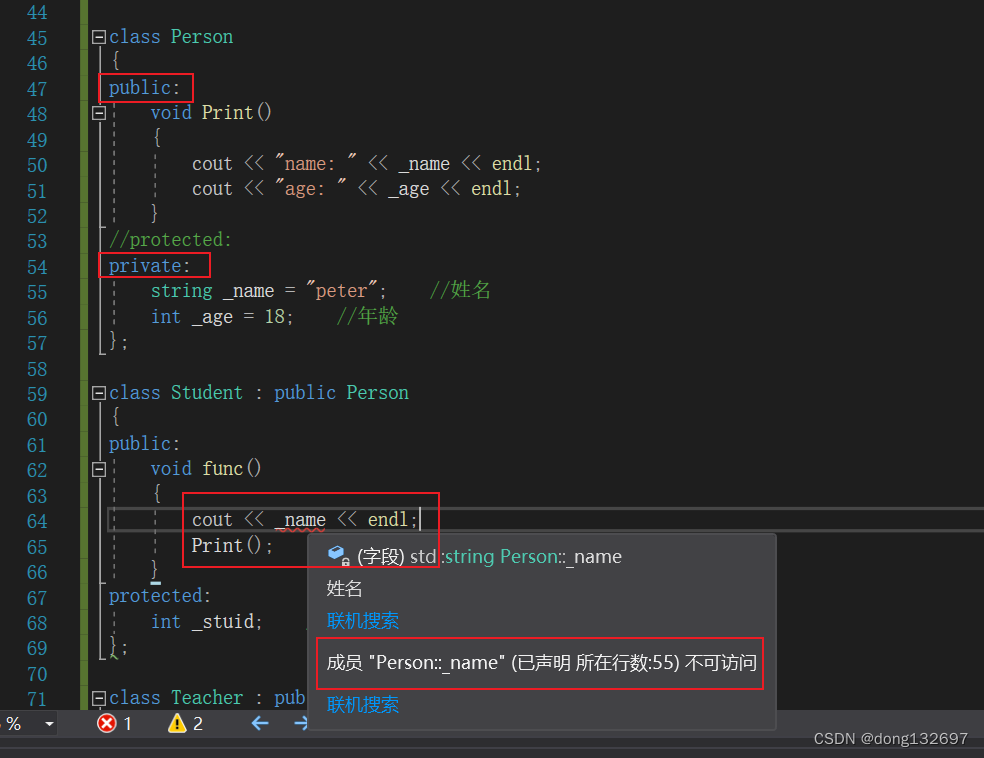

(2). 基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
我们看到在Student派生类中可以访问Person基类中的protected成员,但是在除了基类和派生类之外的地方就不可以访问基类中的protected成员了。所以可以体会到Person类中的private和protected成员在Person类中没有区别,在派生类Student中有区别。
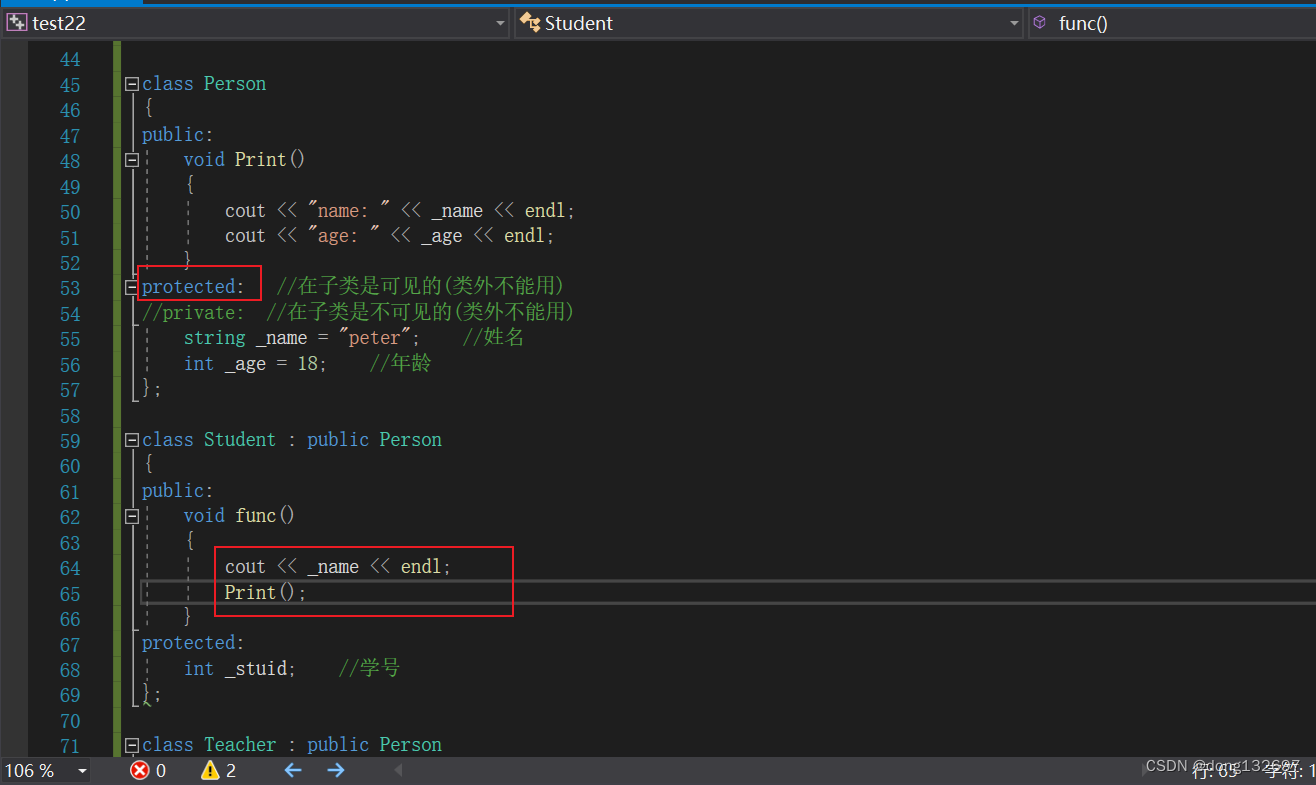
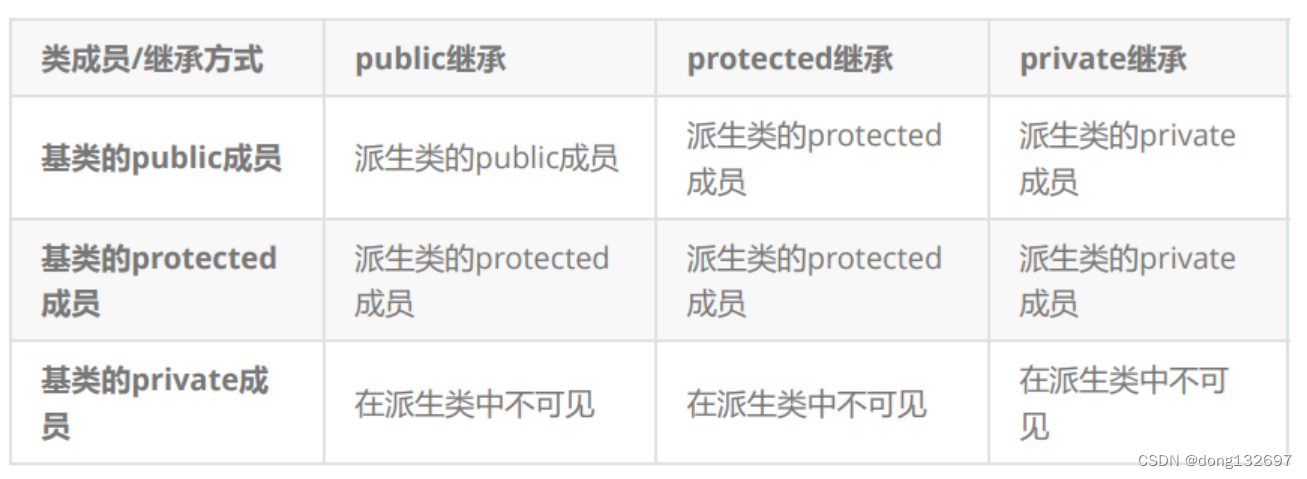
(3). 上面的表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected > private。
例如我们将Person类中的成员变量和成员函数都设为public,然后我们将Student类使用protected的方式继承Person类,然后我们就发现了Student类类型的对象不能访问Person类中的Print函数了,这是因为public > protected,所以在派生类Student中基类的Person类中的Print成员函数变为protected成员了。

再例如下面的Person类的成员函数和成员变量都为public,然后Student使用public方式继承Person类的成员变量和成员函数,所以在Student类中,Print和_name和_age的访问权限都是public,所以可以在类外面直接访问这些成员函数和成员变量。
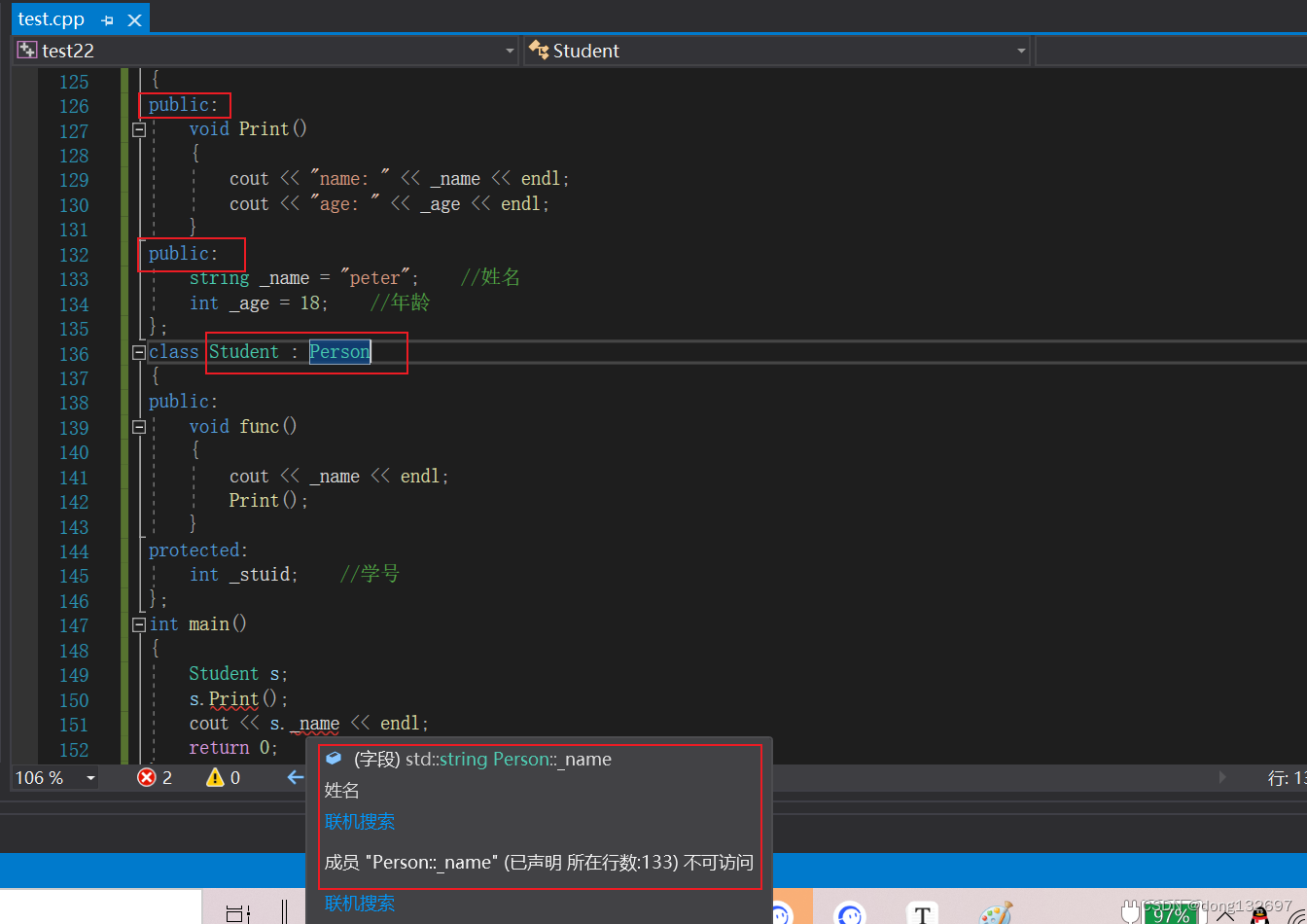
(4). 使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显示的写出继承方式。
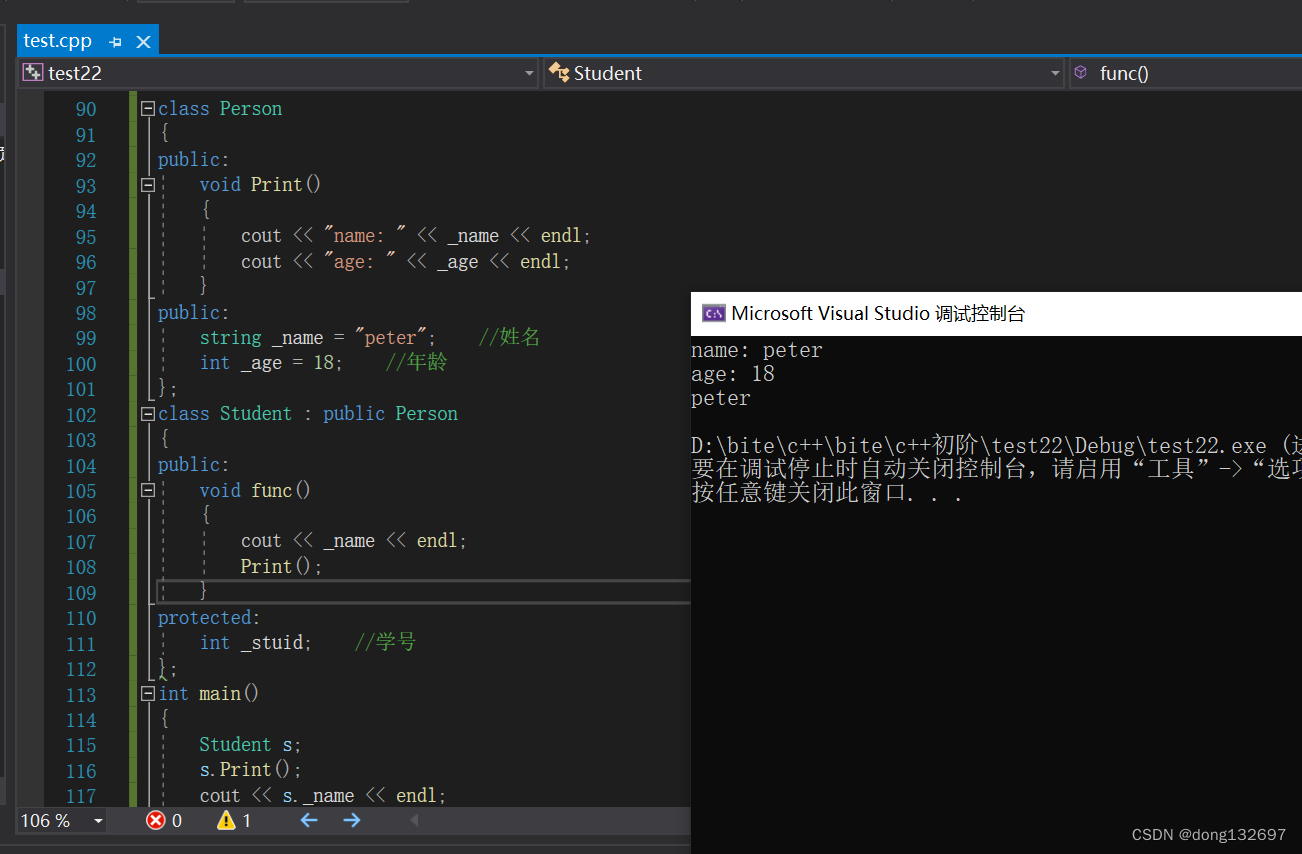
我们看到当Student类继承Person类时,如果不写继承方式,则默认的继承方式为private,所以Student类在使用private方式继承了Person类后,Person类中的成员函数和成员方法在Stuent类中都是被private访问限定符修饰的了,所以在类外面不能被访问的了,但是在Student类里面还是可以访问Print和_name和_age的。
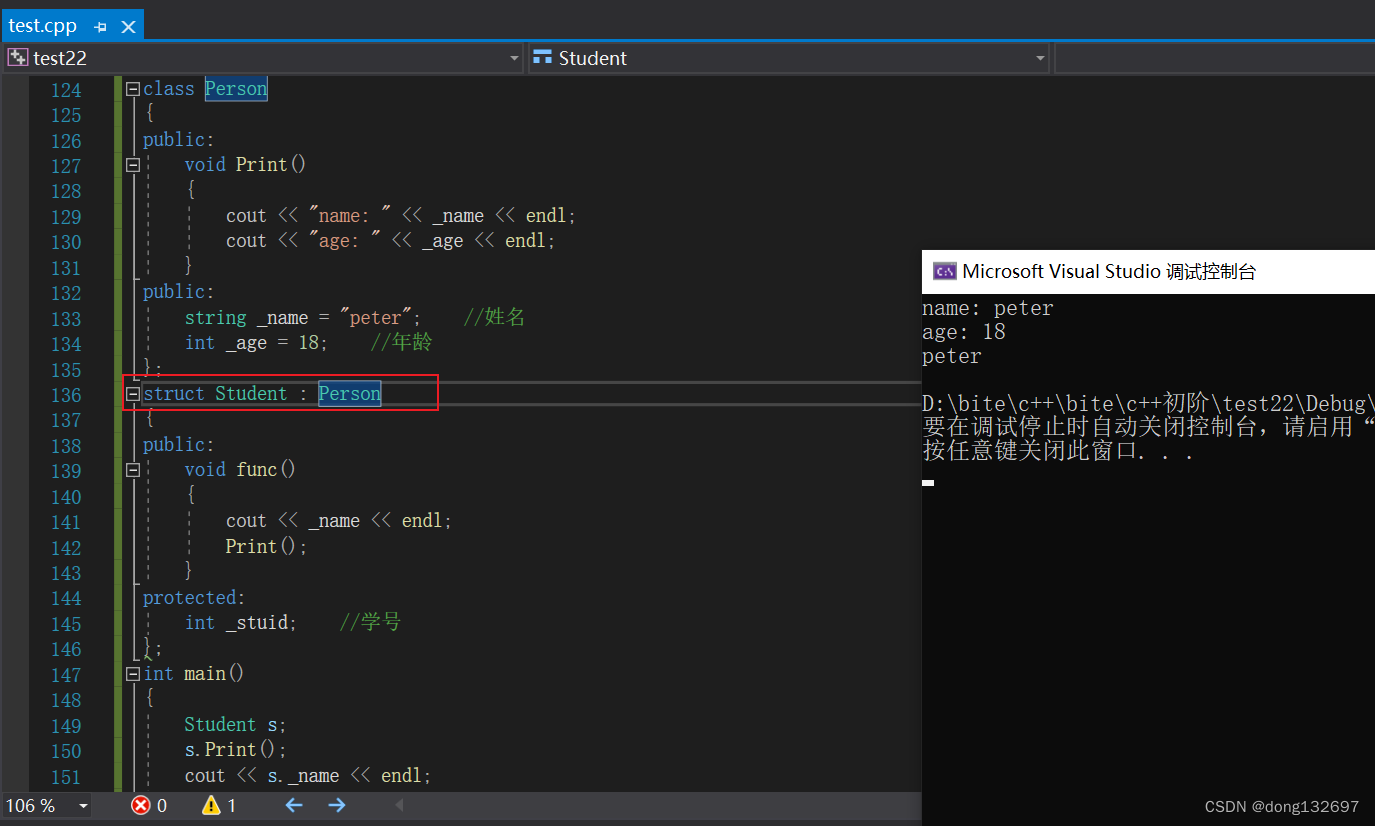
下面使用结构体Student继承Person类中的成员变量和成员方法,可以看到在类外面可以访问Person类的成员函数和成员方法,这是因为struct结构体默认使用public方式继承。
(5). 在实际运用中一般使用都是public继承,几乎很少使用protected/private继承,也不提倡使用protected/private继承,因为protected/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。

二、基类和派生类对象赋值转换
派生类对象 可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。
基类对象不能赋值给派生类对象。
基类的指针或者引用可以通过强制类型转换赋值给派生类的指针或者引用。但是必须是基类的指针是指向派生类对象时才是安全的。这里基类如果是多态类型,可以使用RTTI(RunTime Type Information)dynamic_cast 来进行识别后进行安全转换。(ps:这个我们后面再讲解,这里先了解一下)
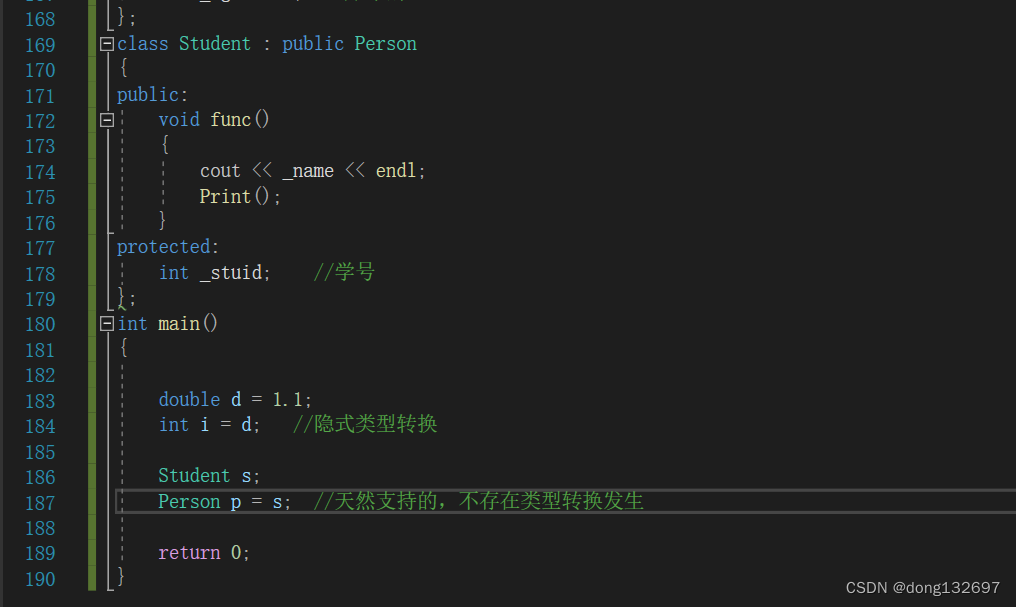
我们知道内置类型发生类型转换时,会在中间生成一个临时变量,但是将派生类对象赋值给基类对象时并不会发生类型转换,这个过程是天然支持的。
当想要创建一个类型转换后的引用变量需要加上const修饰,因为类型转换产生的临时变量具有常性。但是将派生类对象s赋值给基类对象p不会产生临时对象,所以不需要使用const修饰。并且我们可以看到引用变量rp的_name变量其实和对象s的_name是同一个。而p对象的_name和s对象的_name不是一个。这是因为引用变量rp指向了对象s中的Person类里面的变量,而p对象其实是调用了拷贝构造函数根据s对象里面的Person类的变量数据创建了一个新的Person类类型的对象。
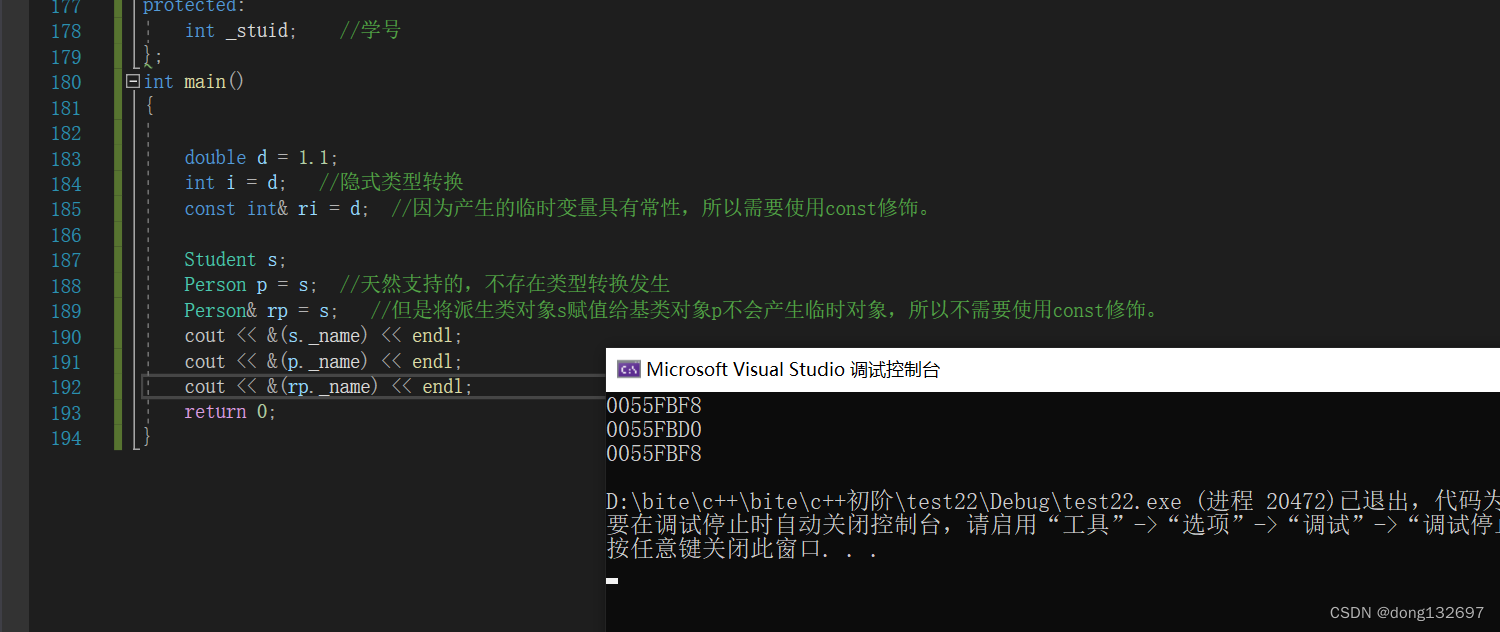
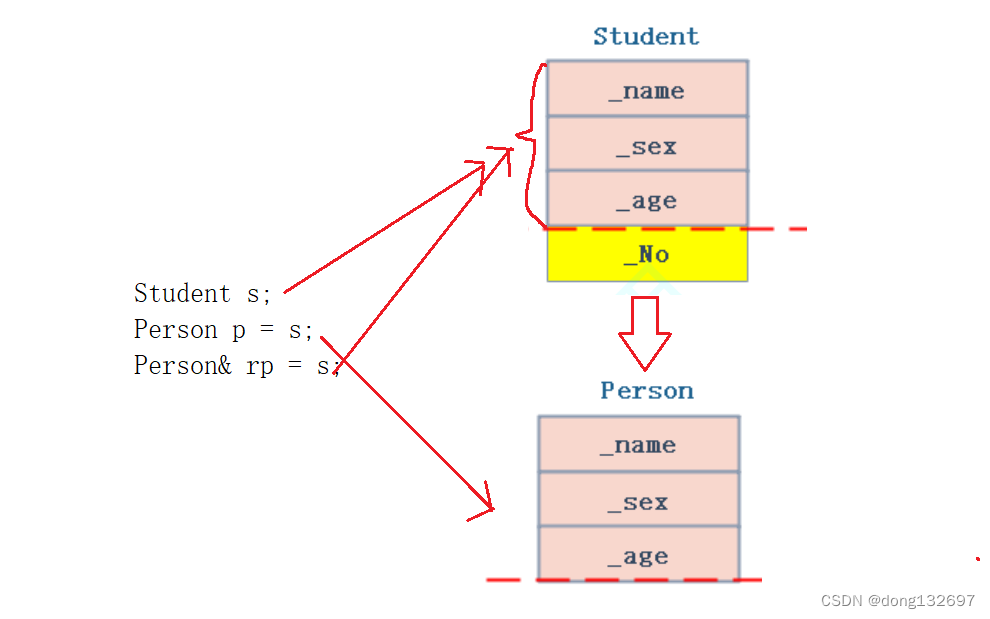
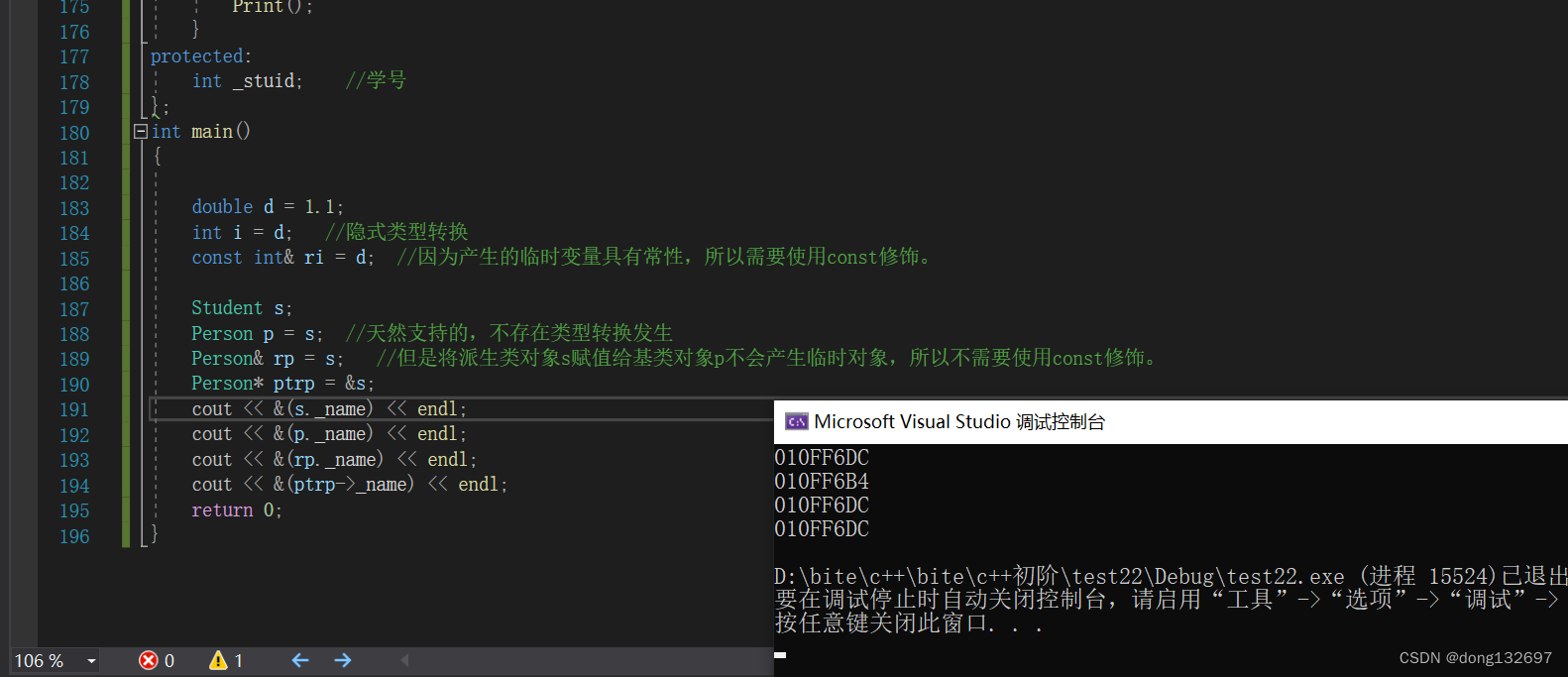
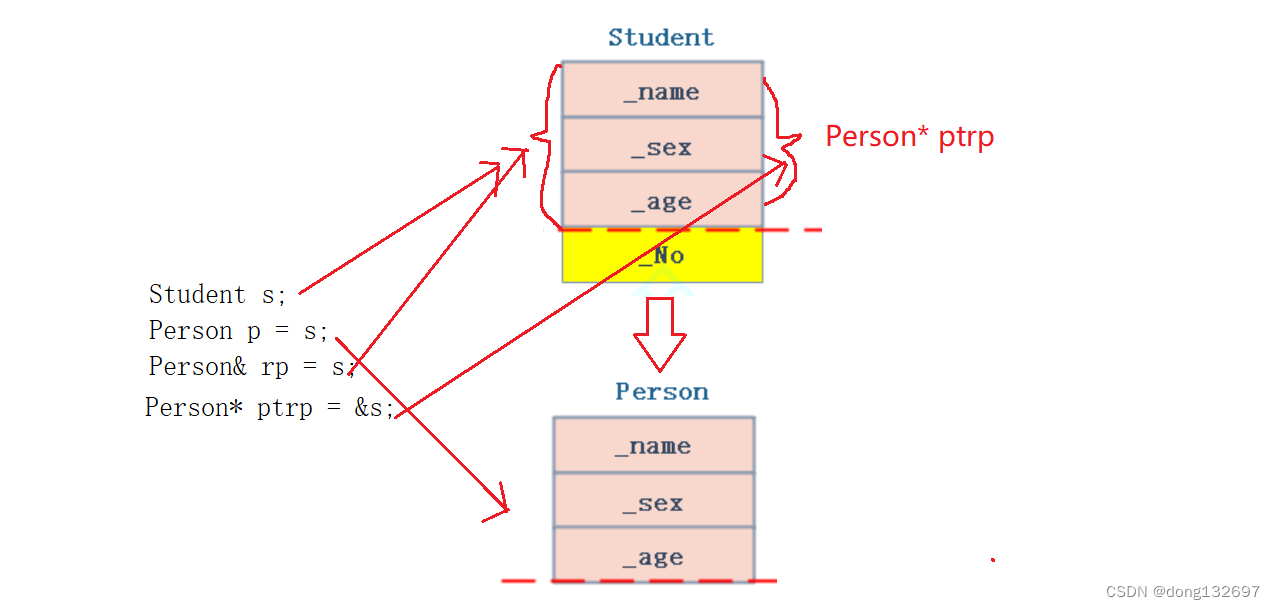
我们看到下面的Person类类型的指针ptrp指向了s对象,其实指针ptrp只是指向了s对象中Person类中的成员,所以当使用指针ptrp或引用rp修改_name时,对象s里面的_name内容也会改变。
三、继承中的作用域
1.在继承体系中基类和派生类都有独立的作用域。
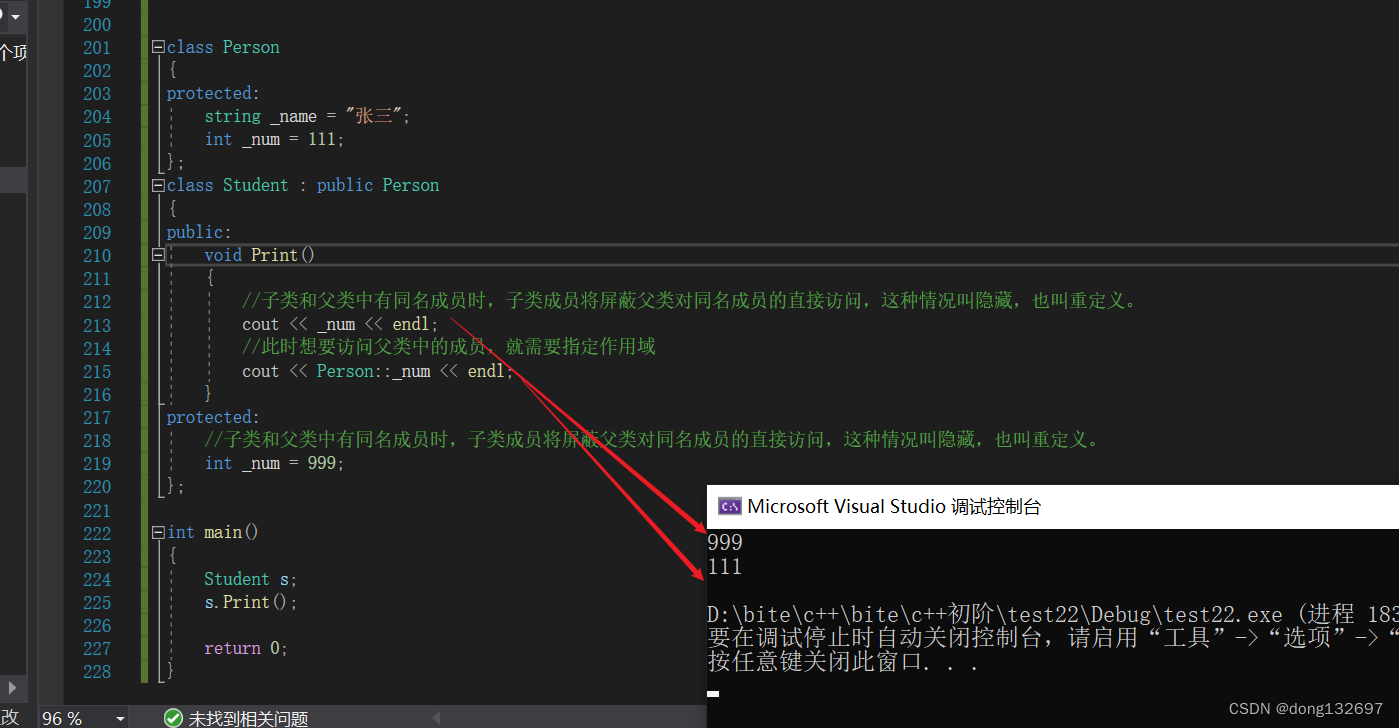
2.子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
3.需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
4.注意在实际中在继承体系里面最好不要定义同名的成员。
下面的代码中派生类Student和基类Person中可以定义名字相同的成员变量_num,当派生类中直接访问这个同名的成员变量时默认会访问派生类里面的,因为就近原则。如果想要访问基类中的,就需要指定作用域。
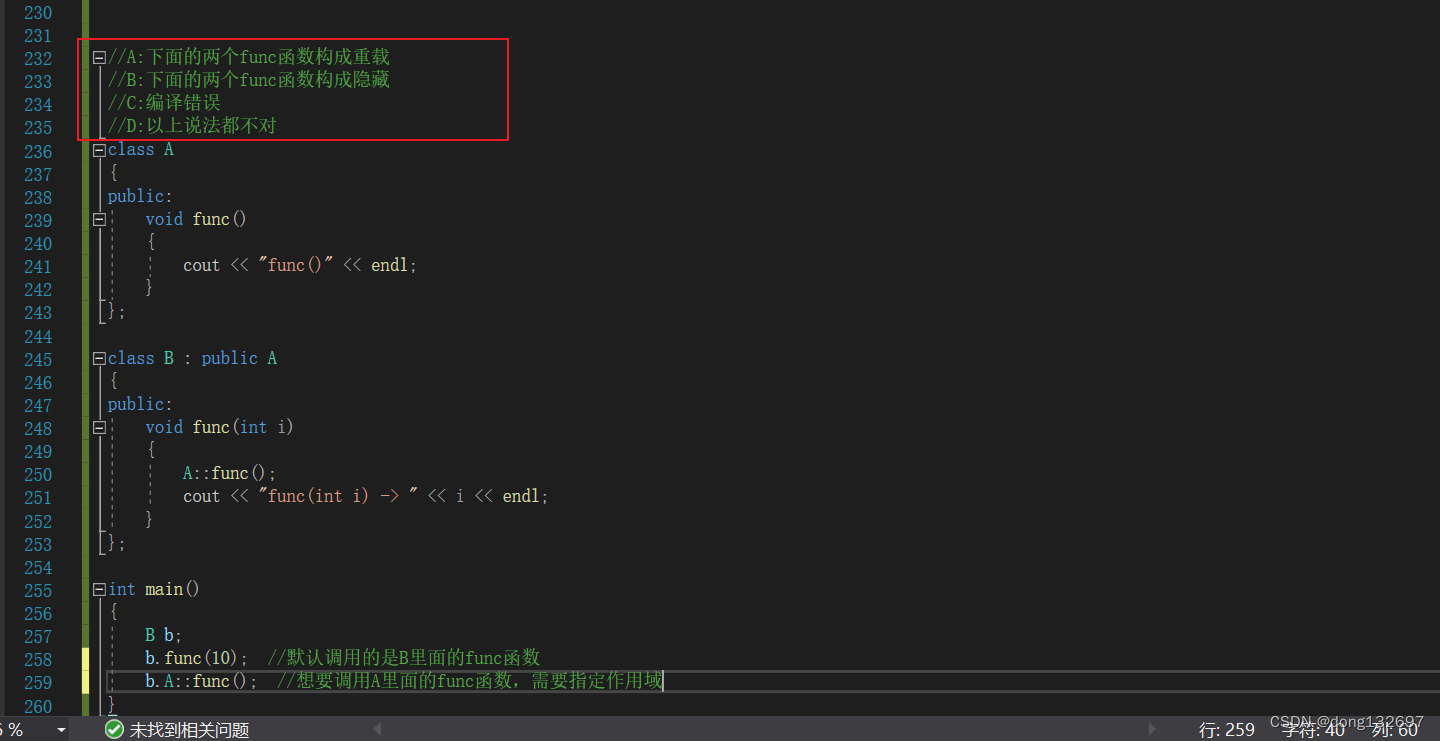
下面的选项中A是错的,因为函数重载必须是在同一个作用域里面,但是下面的两个func函数分别在A类和B类的作用域中,所以不构成重载。 B为对的,为隐藏关系,因为成员函数的隐藏只需要函数名相同就构成隐藏。
创建的b对象默认调用的是B类中的func函数,如果想要调用A类里面的,需要指定作用域。
四、派生类的默认成员函数
6个默认成员函数,“默认”的意思就是指我们不写,编译器会变我们自动生成一个,那么在派生类中,这几个成员函数是如何生成的呢?
1.派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
2.派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
3.派生类的operator=必须要调用基类的operator=完成基类的复制。
4.派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序。
5.派生类对象初始化先调用基类构造再调派生类构造。
6.派生类对象析构清理先调用派生类析构再调基类的析构。
7.因为后续一些场景析构函数需要构成重写,重写的条件之一是函数名相同(这个我们后面会讲解)。那么编译器会对析构函数名进行特殊处理,处理成destrutor(),所以父类析构函数不加virtual的情况下,子类析构函数和父类析构函数构成隐藏关系。
(1). 派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
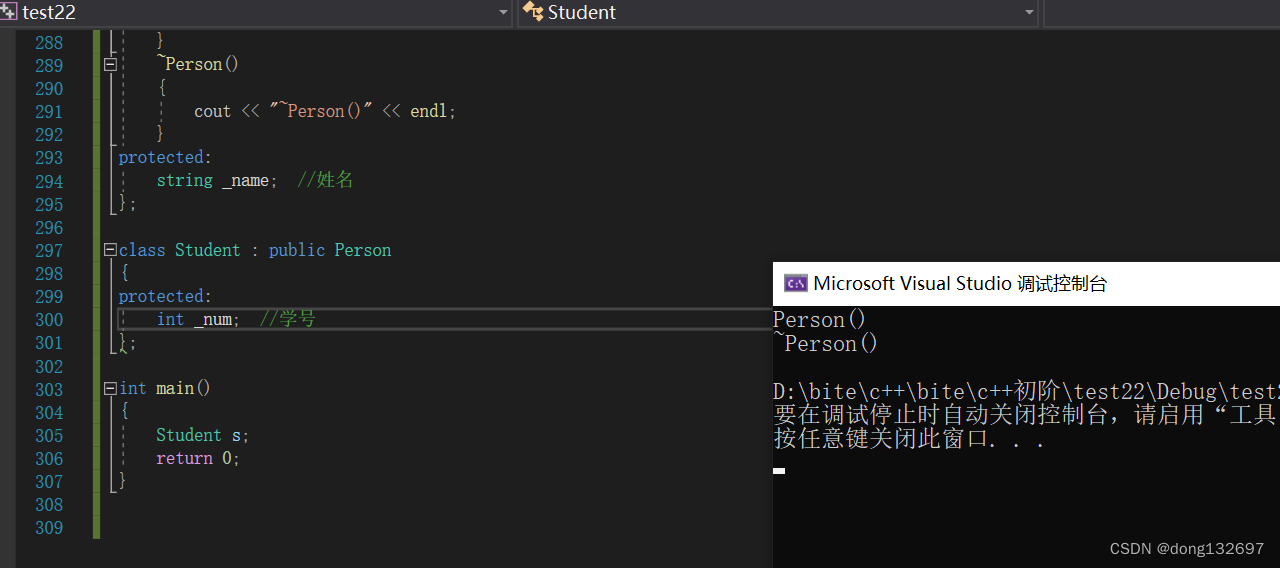
下面的代码中我们没有给派生类Student写构造函数,所以会默认生成一个构造函数,并且会调用Person基类的构造函数。
class Person
{
public:Person(const char* name = "peter"):_name(name){cout << "Person()" << endl;}Person(const Person& p):_name(p._name){cout << "Person(const Person& p)" << endl;}Person& operator=(const Person& p){cout << "Person operator=(const Person& p)" << endl;if (this != &p){_name = p._name;}return *this;}~Person(){cout << "~Person()" << endl;}
protected:string _name; //姓名
};class Student : public Person
{
protected:int _num; //学号
};int main()
{Student s;return 0;
}
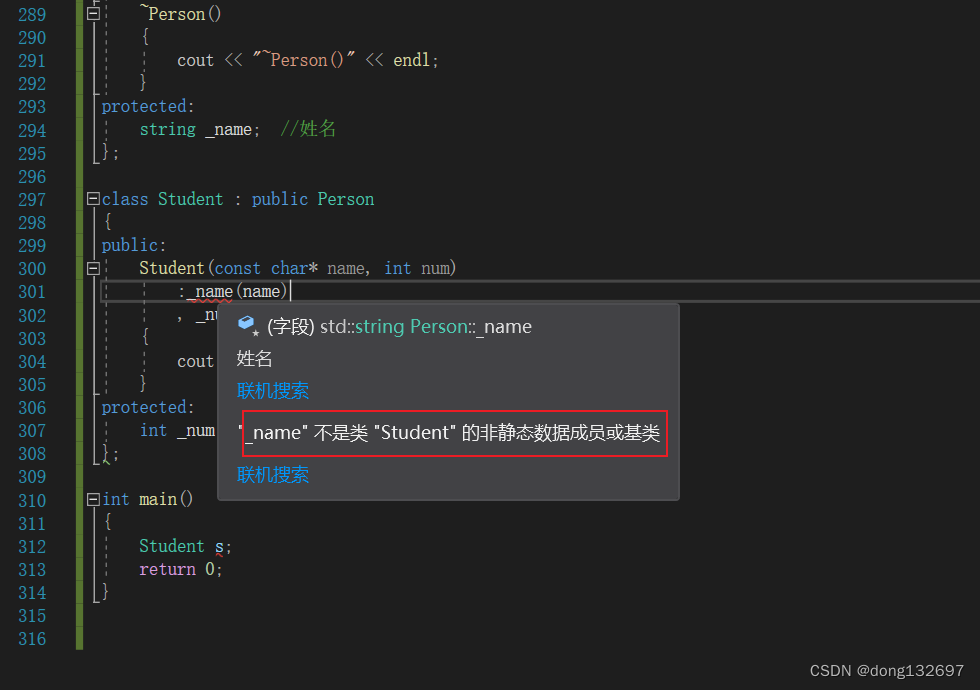
当我们在派生类Student中写了构造函数时,并且我们在Student的构造函数的初始化列表中初始化Person类中的_name,我们发现报出了错误,这是因为想要在派生类的初始化列表中初始化基类的成员变量时需要显示调用基类的构造函数。
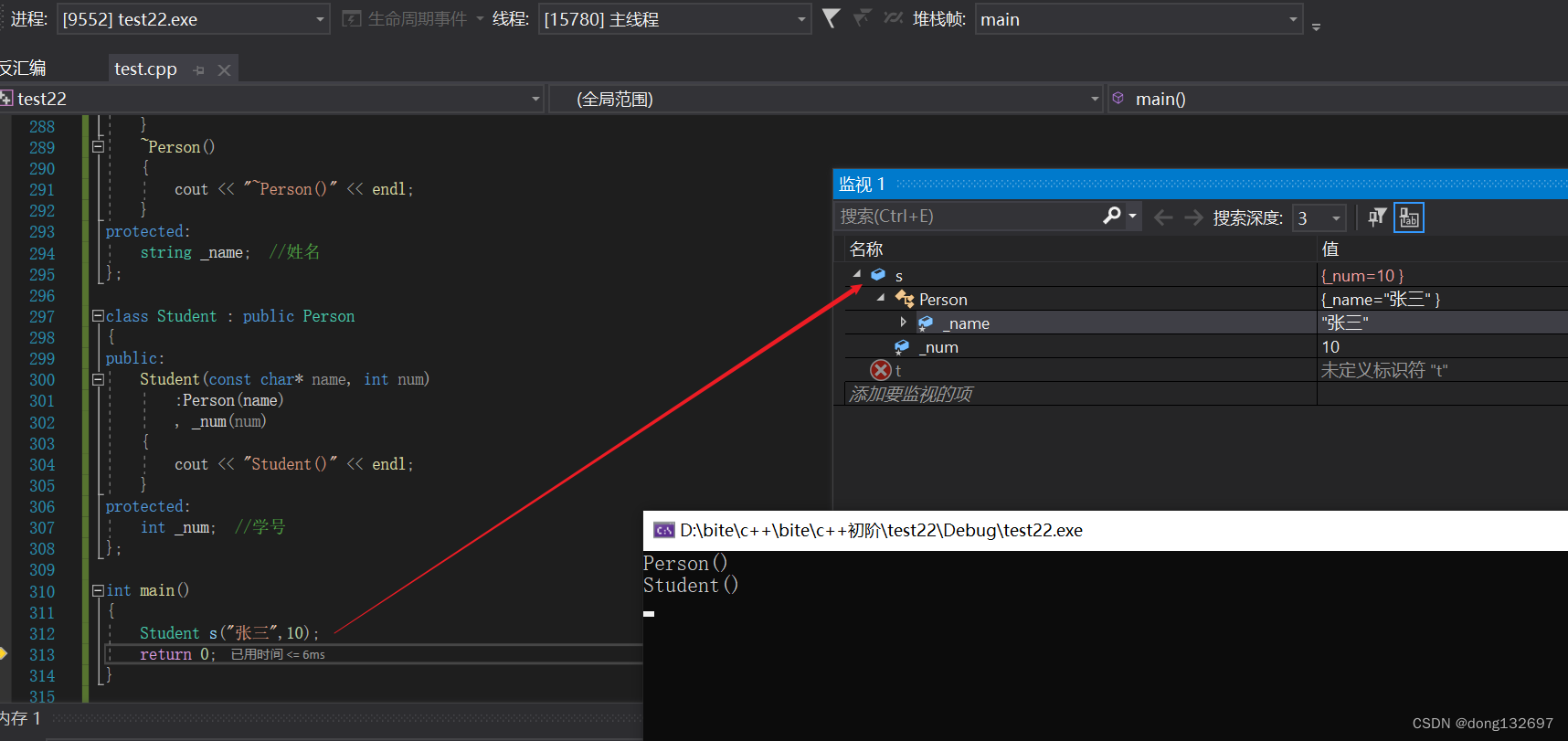
当基类中有默认构造函数时,我们在派生类的初始化列表中不显示调用基类的构造函数,初始化列表中也会自动调用基类的默认构造函数。但是我们看到因为没有显示调用基类的构造函数,所以调用的基类的默认构造函数,在基类默认构造函数中,_name的值为缺省值peter,而不是"张三"。
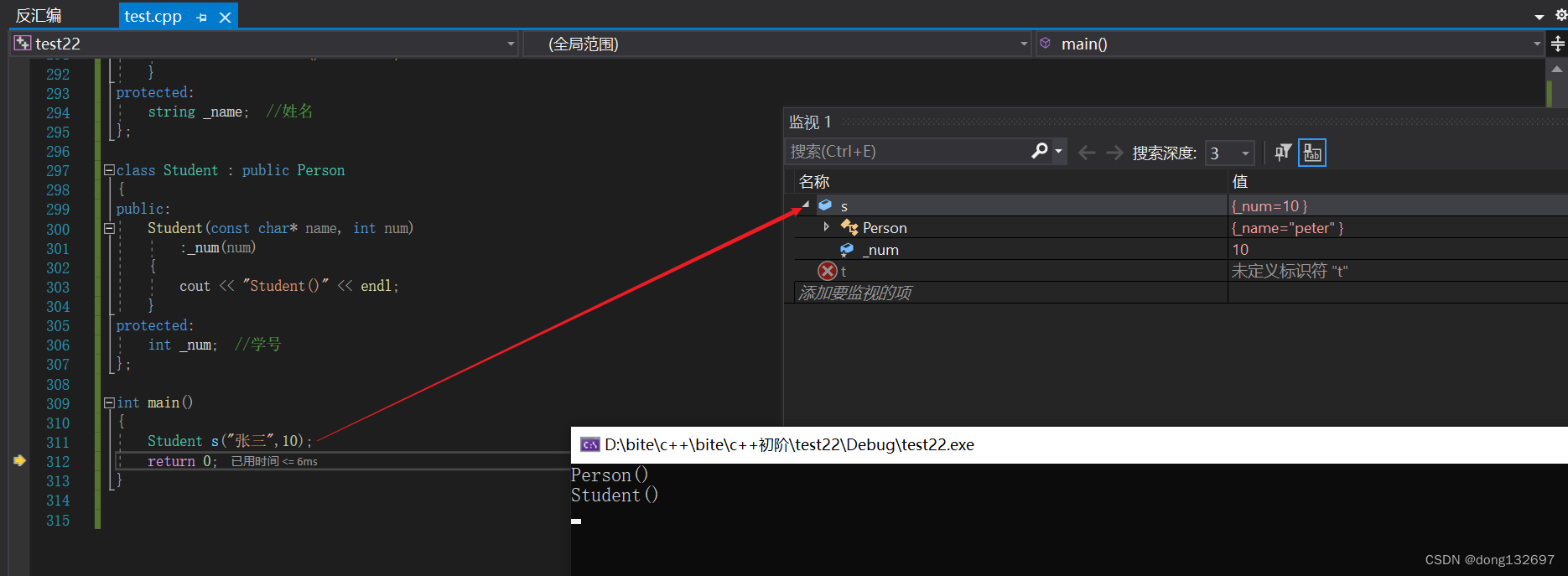
当基类中没有默认构造函数时,派生类的默认构造函数中必须显式调用基类的构造函数。
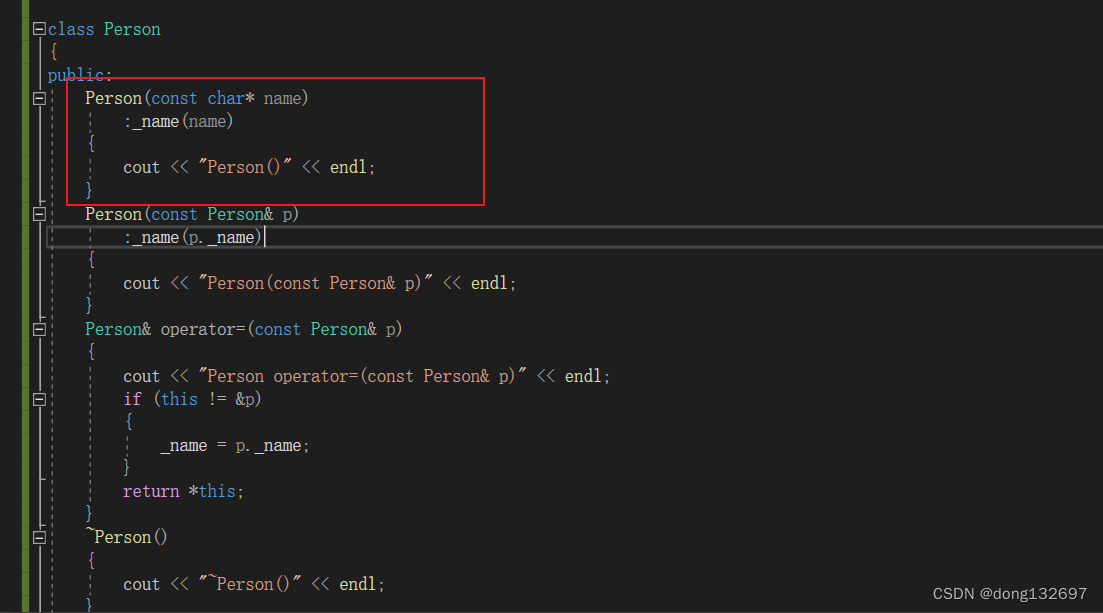
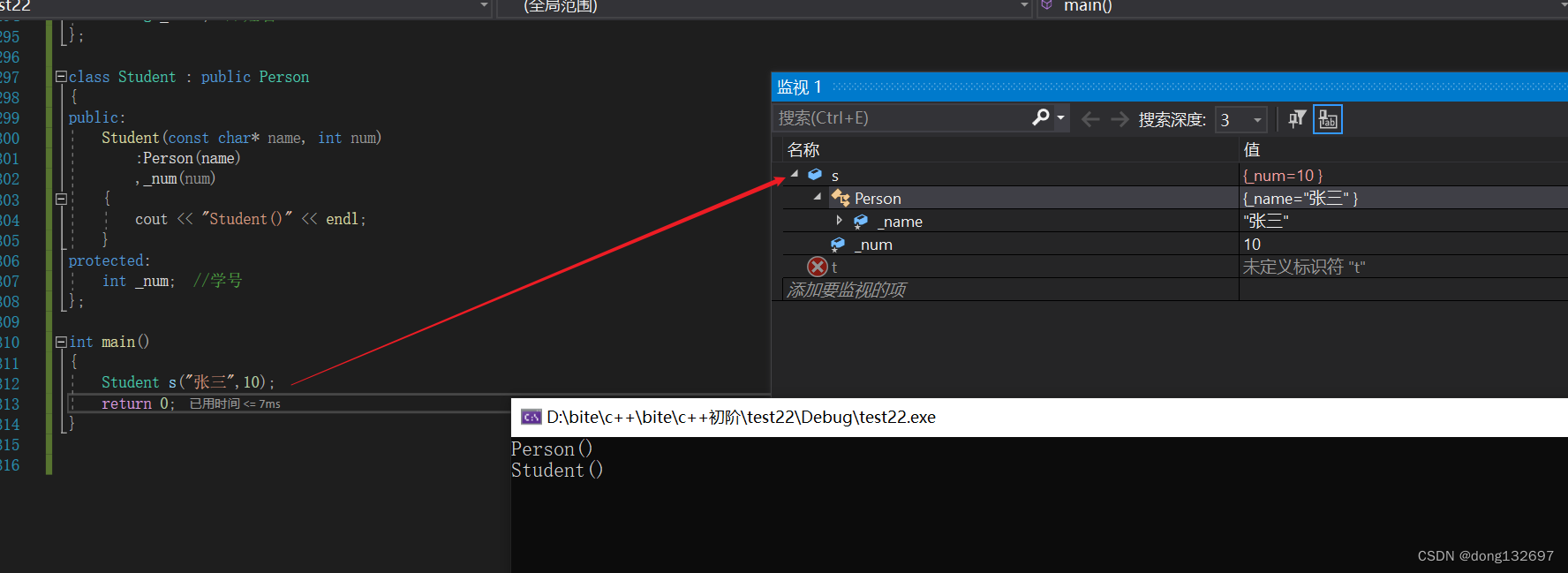
(2). 派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
可以看到派生类的拷贝构造函数中先调用了基类的拷贝构造函数完成了对基类的拷贝初始化。
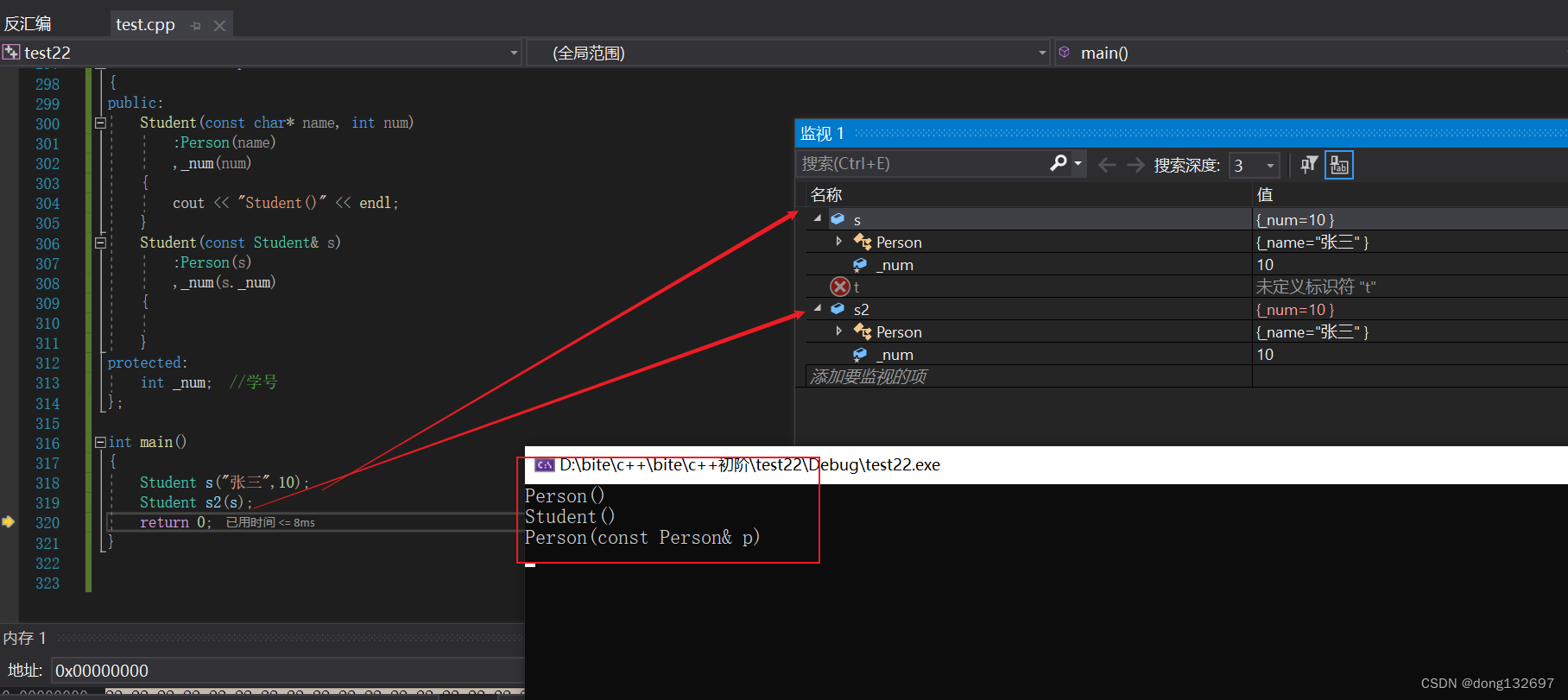
(3). 派生类的operator=必须要调用基类的operator=完成基类的复制。
如果我们这样写派生类的赋值重载函数的话,下面的代码会死循环,然后栈溢出。因为operator=其实是调用的Student类的operator=函数,会一直循环调用下去,然后就会栈溢出。所以我们需要指定调用的是Person类的赋值运算符重载函数。
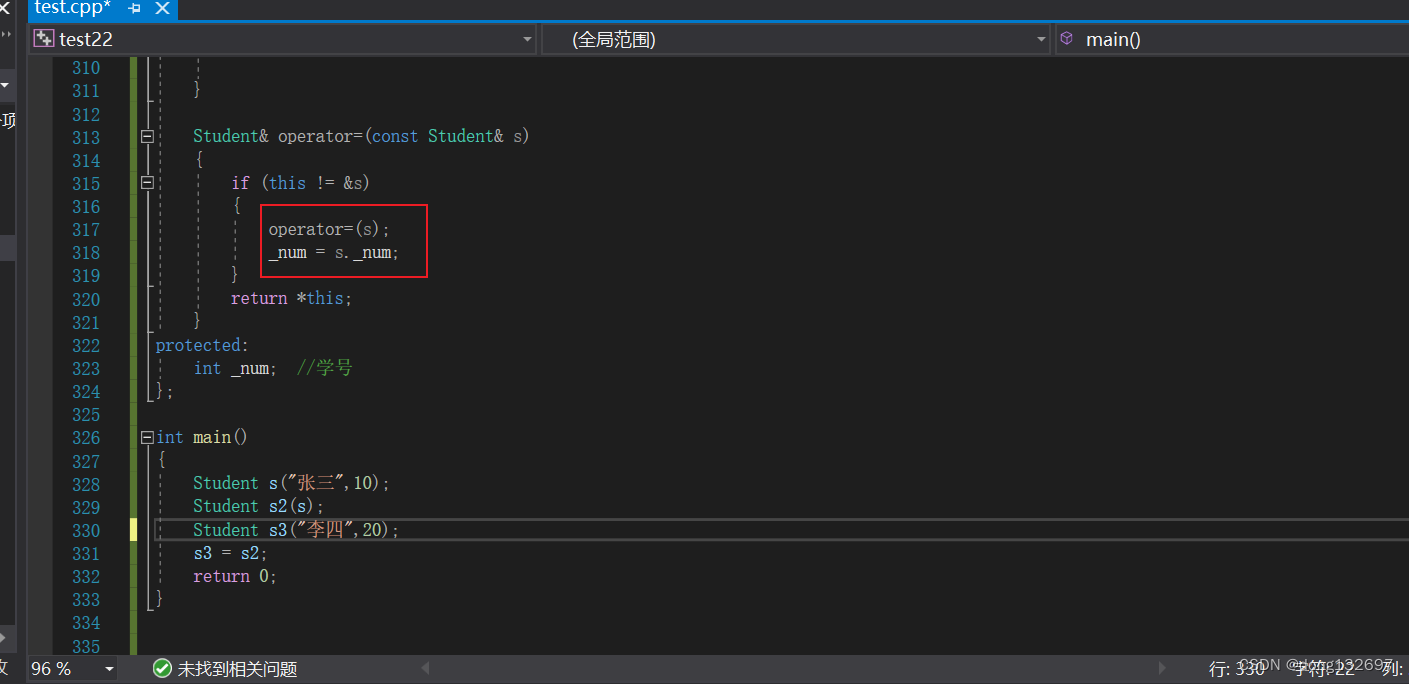
当我们指定好赋值运算符重载函数的作用域后,就会先调用基类的赋值运算符重载函数了。并且我们看到构造函数、拷贝构造函数、赋值重载函数都是先执行基类的函数,再执行派生类的函数。
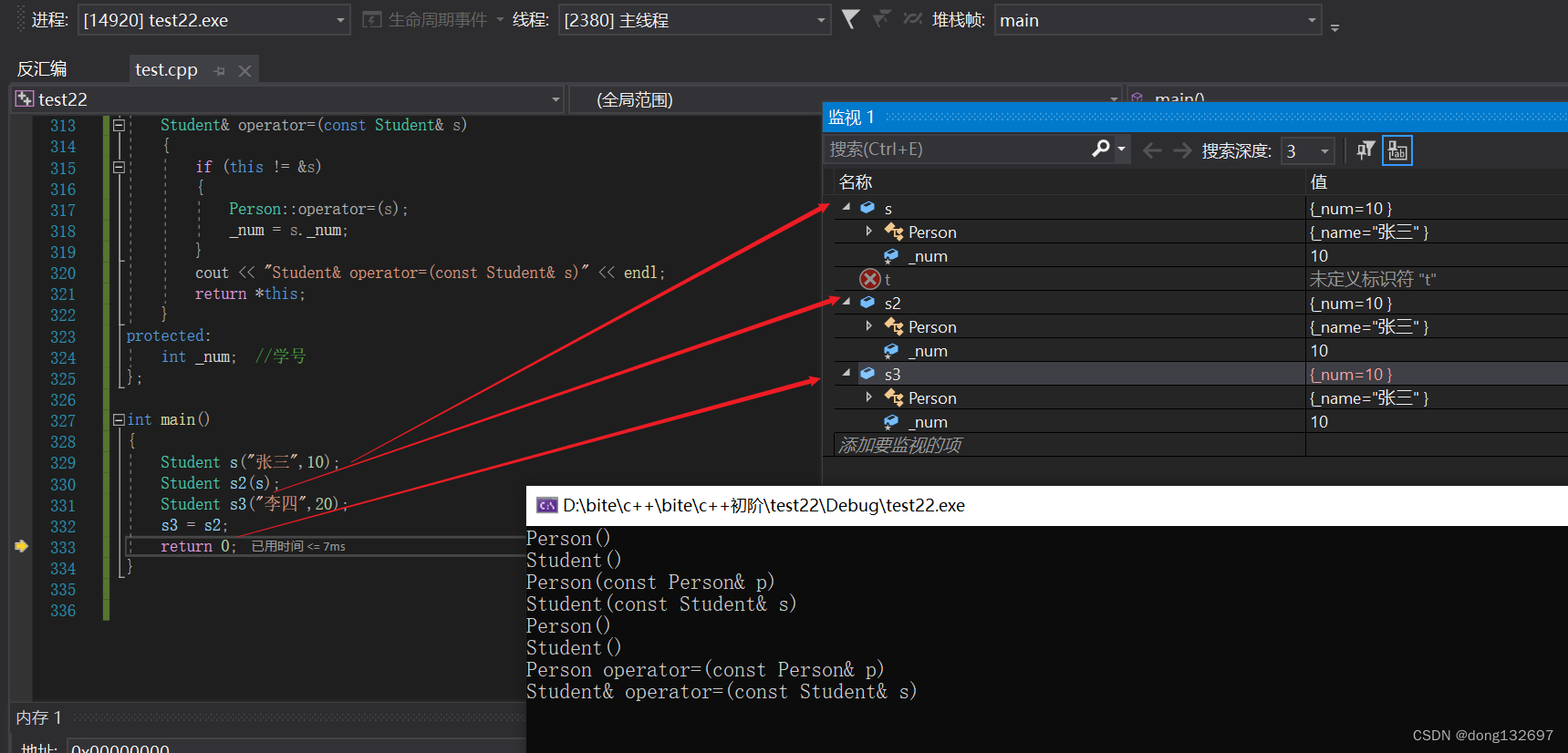
(4). 派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序。
我们在派生类的析构函数中先显示调用基类的析构函数,然后我们发现基类的析构函数被调用了两次。
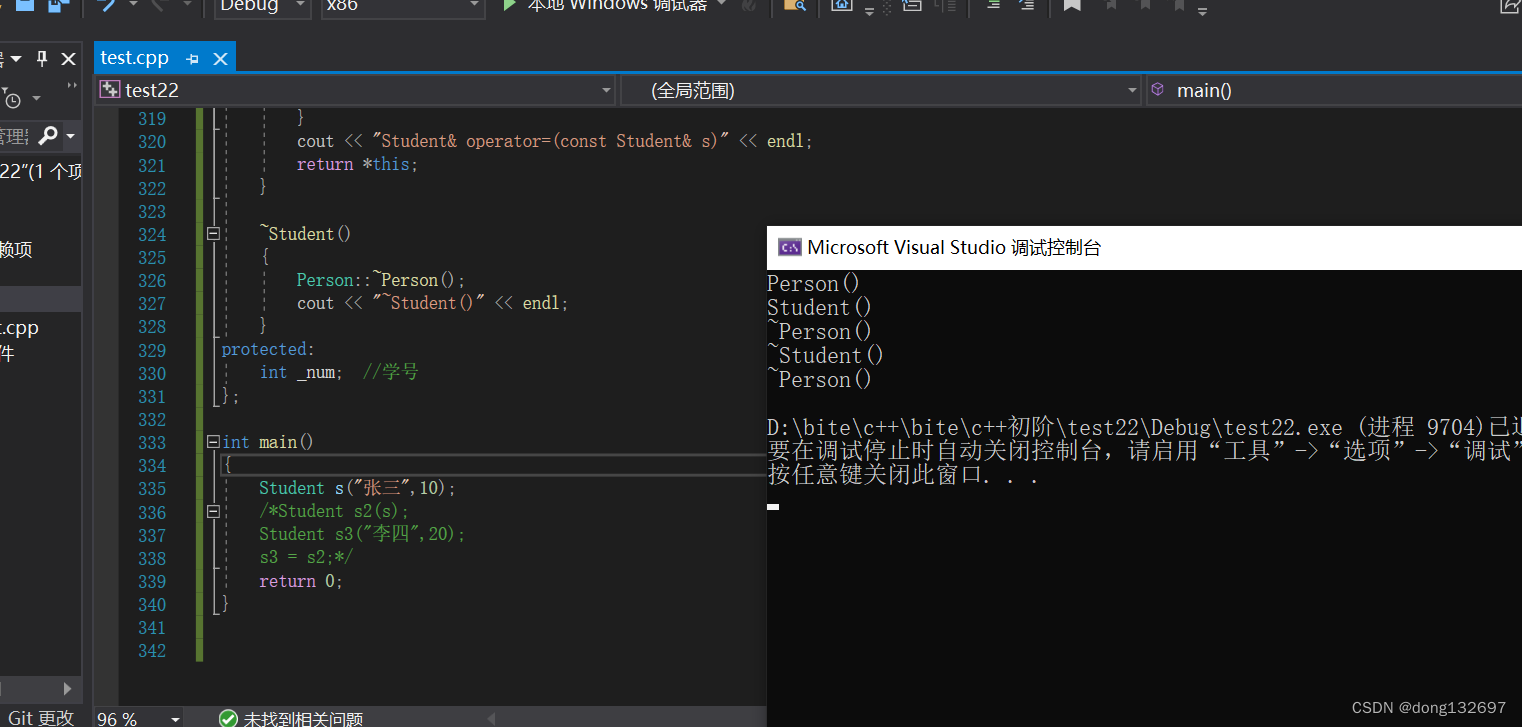
我们前面知道了构造函数调用顺序为先父后子,而析构函数调用为先子后父,即后生成的先析构,这是为了保证派生类对象先清理派生类成员再清理基类成员的顺序。因为栈帧规则为后进先出。如果显式调用父类的析构函数,不能保证析构函数的调用顺序为先子后父,所以子类析构函数完成时,会自动调用父类析构函数。析构函数为特殊处理。
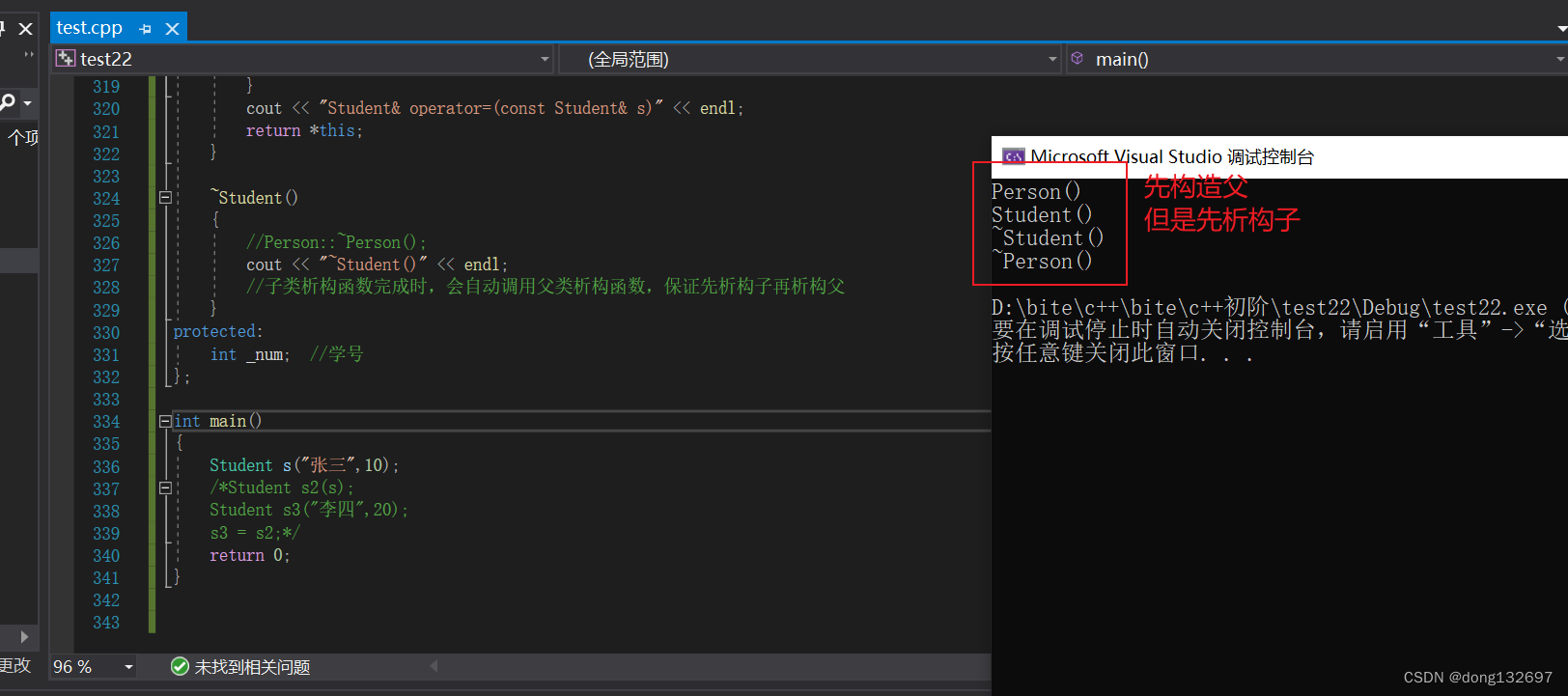
五、继承与友元
友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员。
可以看到虽然基类Person类将Display函数设置为友元函数,但是该函数不能访问派生类Student里面的private和protected成员变量。
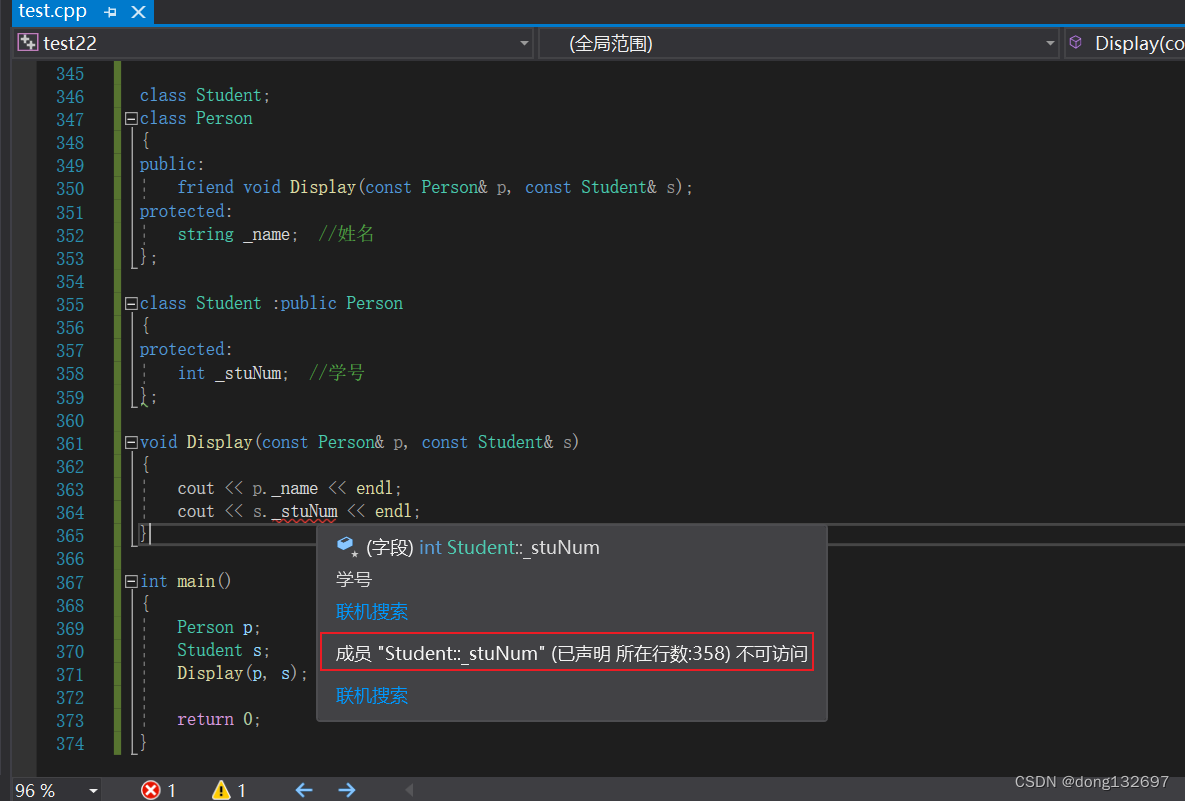
Display函数想要访问Student的private和protected成员变量的话,需要在派生类Student中也将Display函数设置为友元函数。

六、继承与静态成员
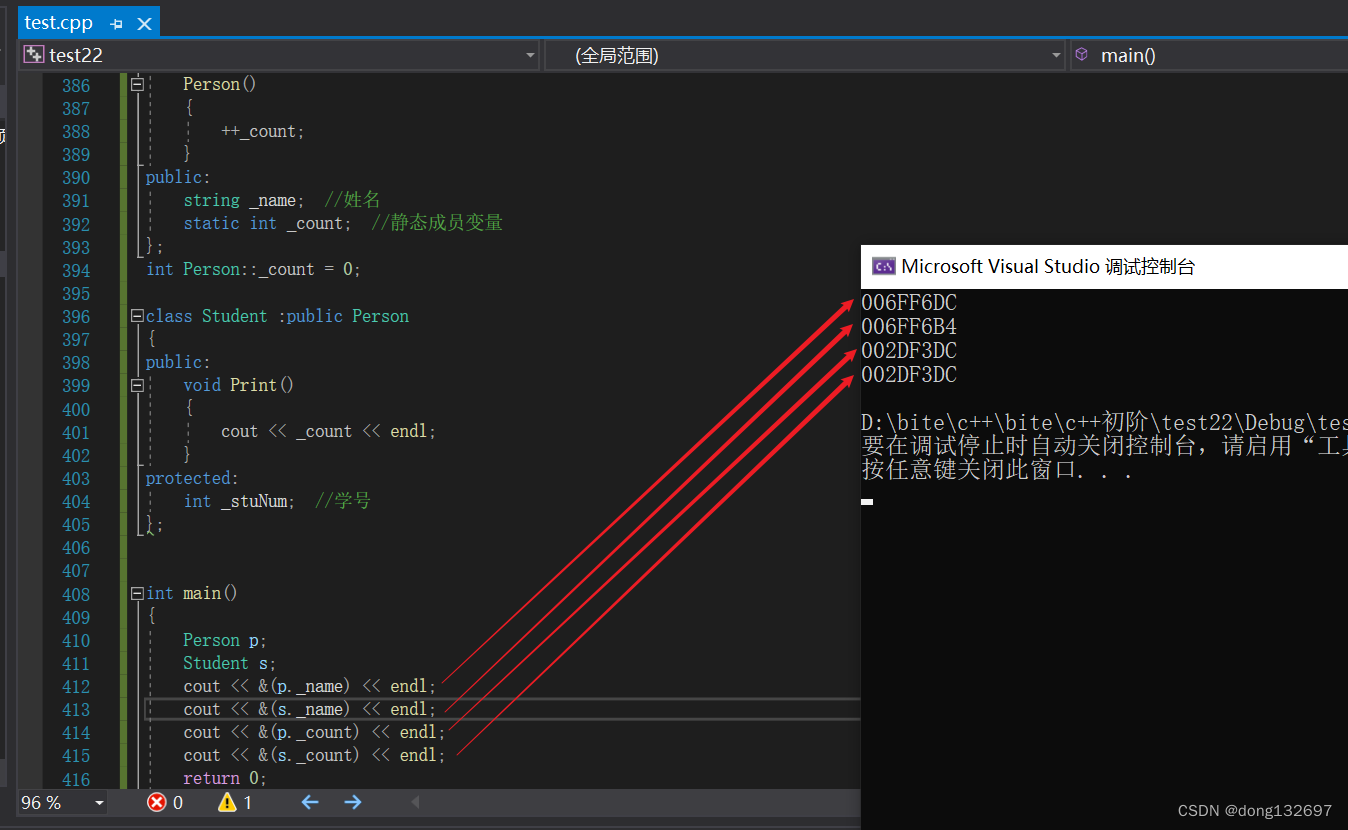
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例 。
父类的静态成员不会被继承,但是可以访问。即这个静态成员不只是属于父类,也属于它的子类,这些类共有这一个静态成员。
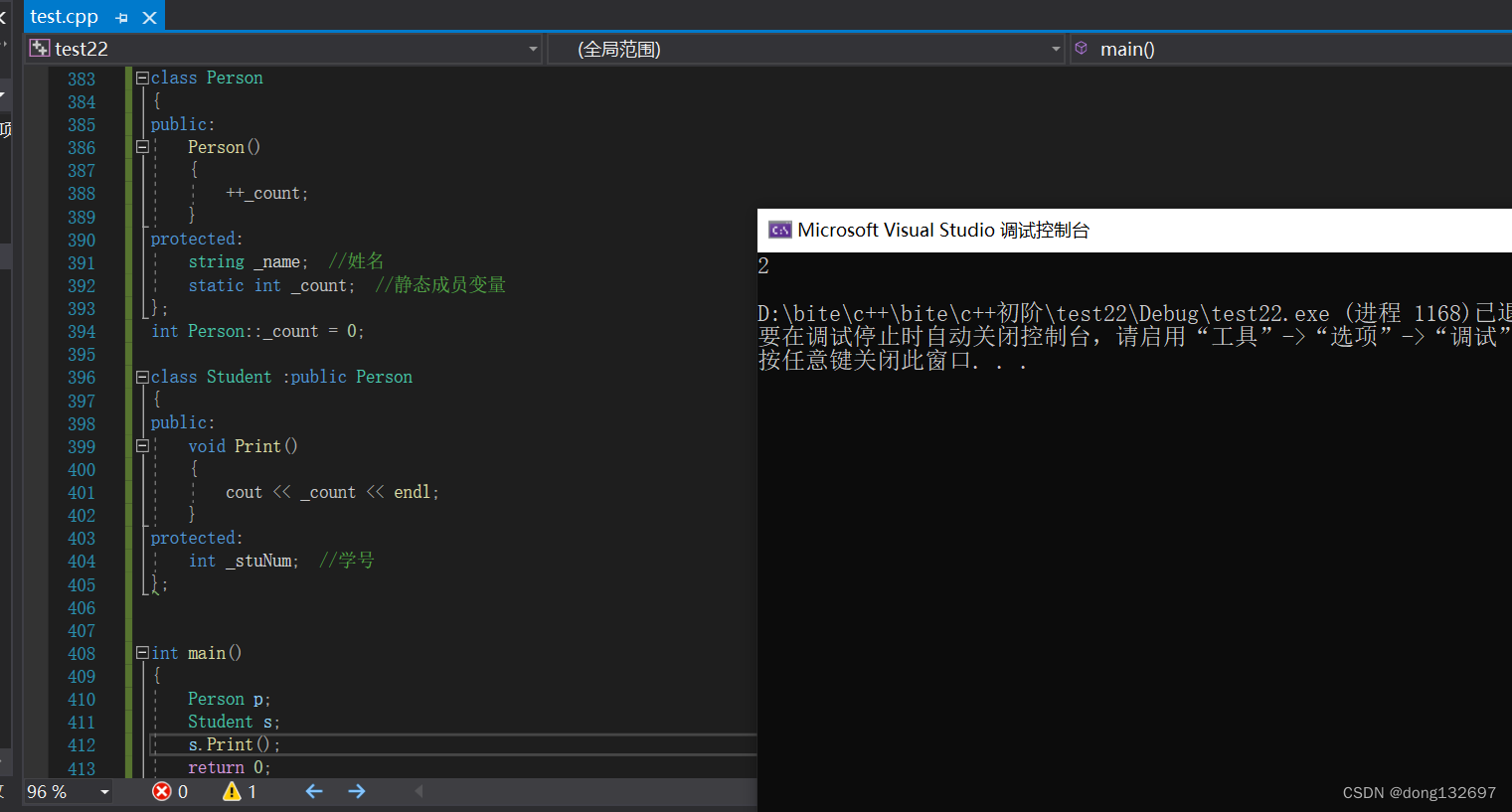
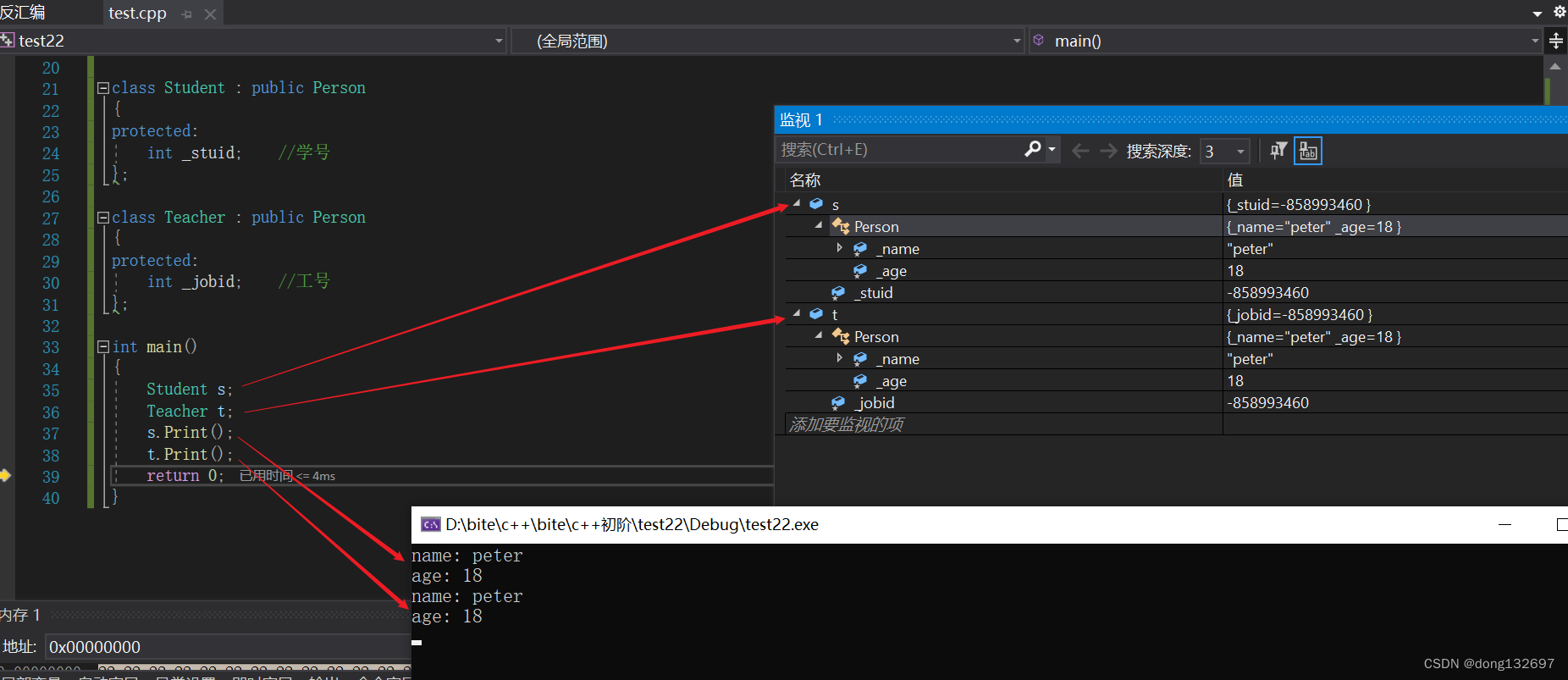
可以看到p对象和s对象的_name的地址不同,但是_count的地址相同,即基类的 _name和派生类的 _name不是一个,因为地址不同,但是基类的静态成员和派生类的静态成员为一个。并且当创建派生类对象时,都会先调用基类的构造函数,所以静态成员变量_count可以计算出创建的对象个数。
实现一个不能被继承的类
将构造函数或析构函数私有化。此时B创建对象时需要先调用A的构造函数,但是A的构造函数为私有,没有办法调用。析构函数也是一样的原理,所以A类就无法被继承了。
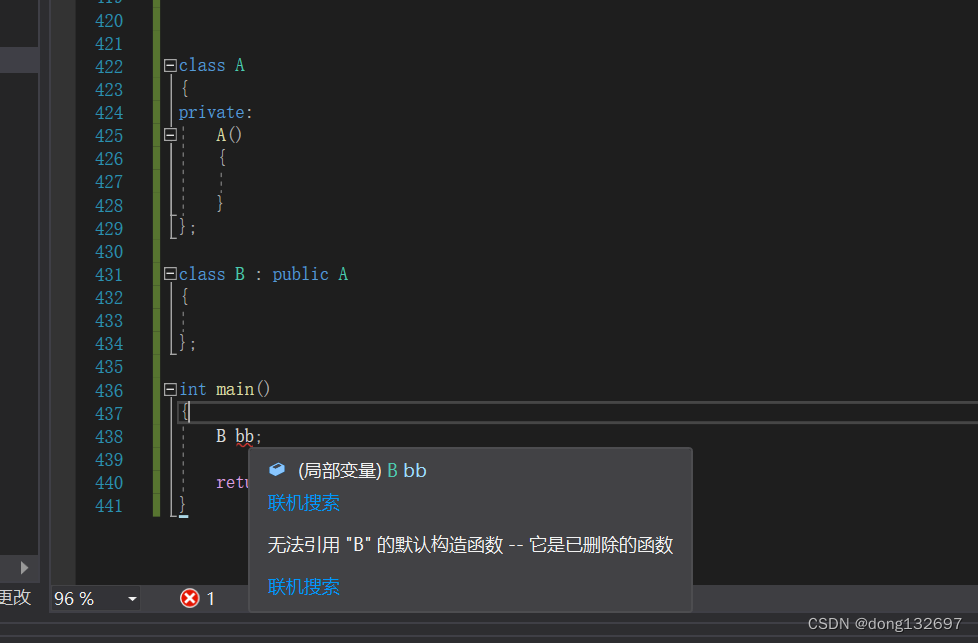
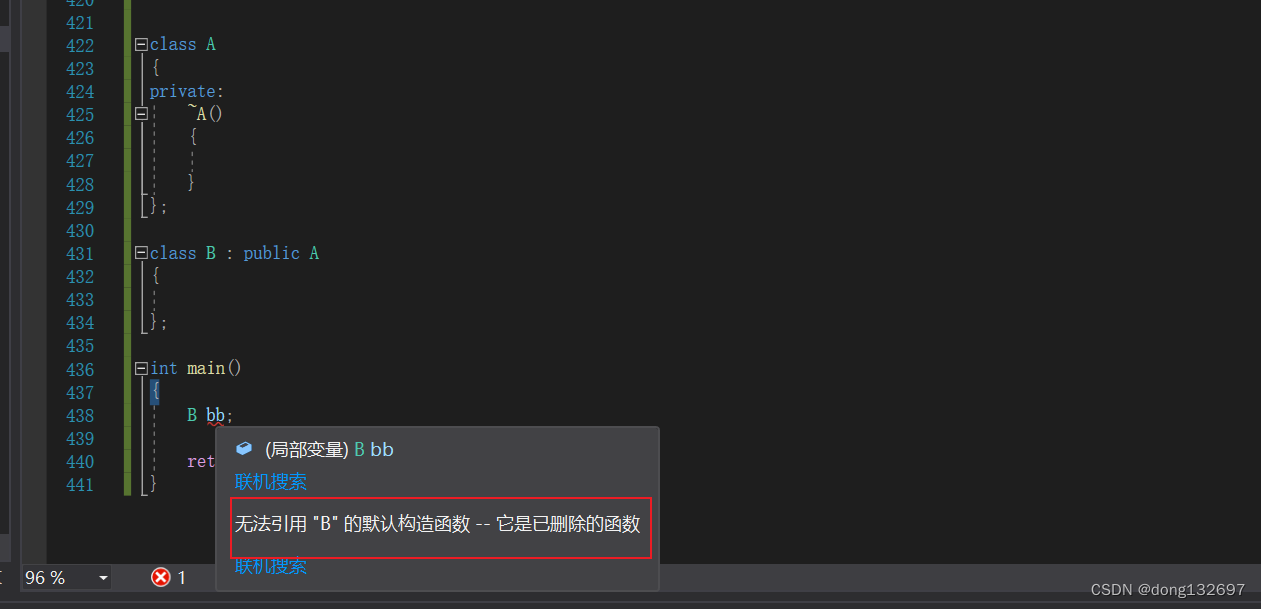
但是如果将A的构造函数或析构函数设为private,那么创建A类的对象时也调用不了构造函数或析构函数了,所以我们可以使用下面的方法,在A中定义一个public的函数,里面调用A的构造函数。但是像下面这样写是行不通的,因为调用CreateObj这个函数需要A对象,而创建对象又需要通过这个函数,这样就陷入了死循环中。
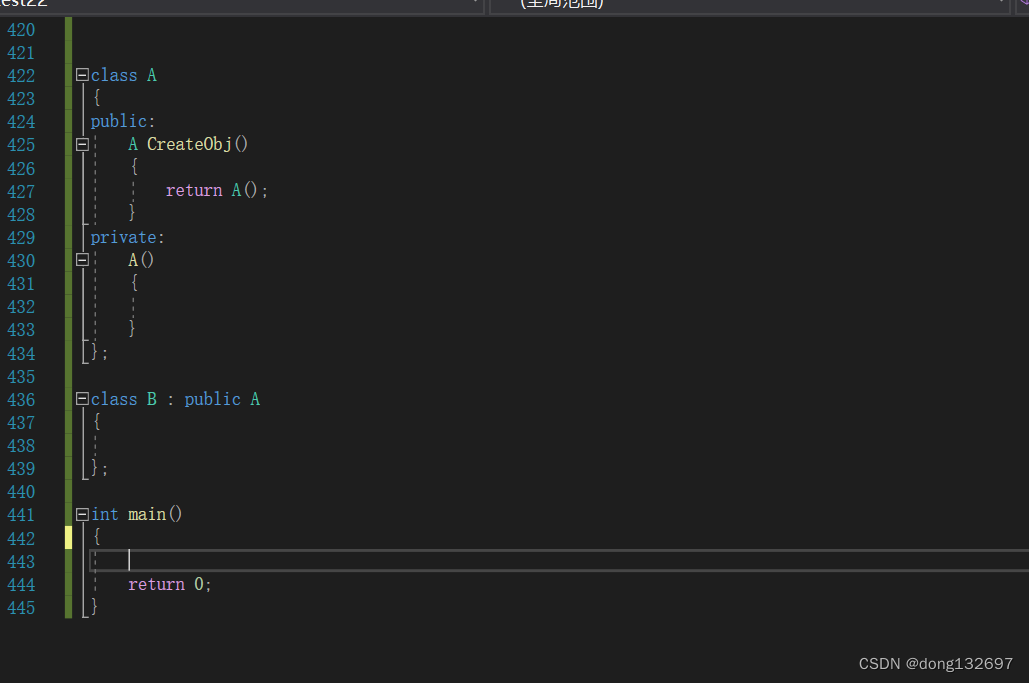
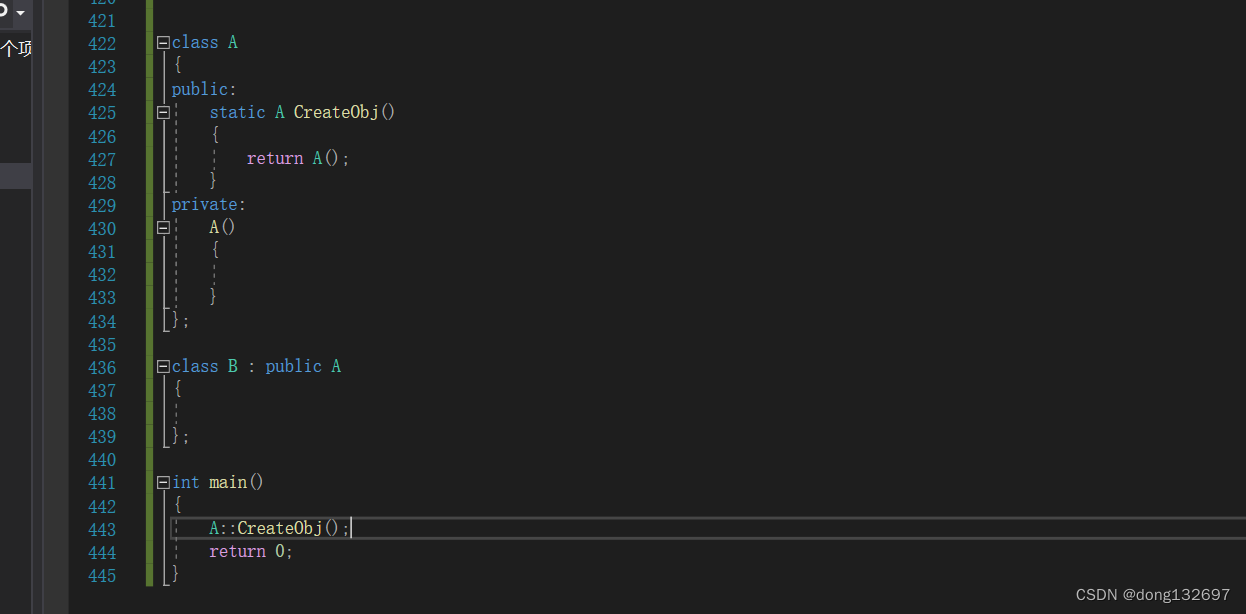
所以将这个函数设置为静态成员函数。
七、复杂的菱形继承及菱形虚拟继承
单继承:一个子类只有一个直接父类时称这个继承关系为单继承。
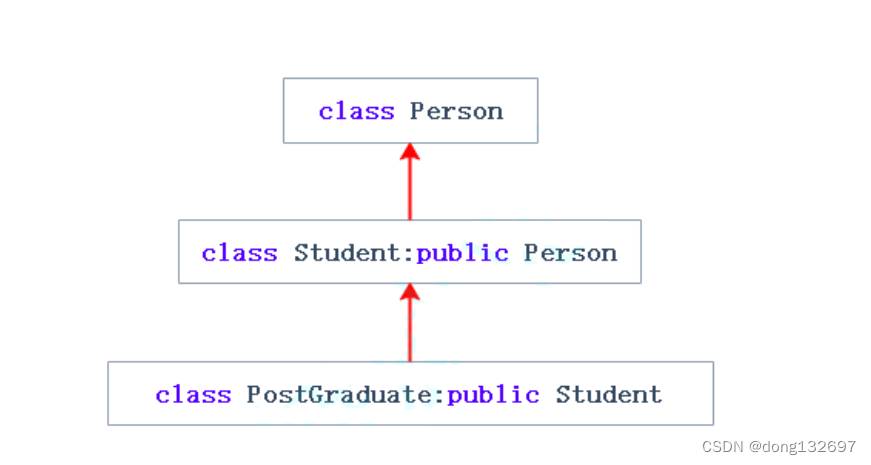
多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承。
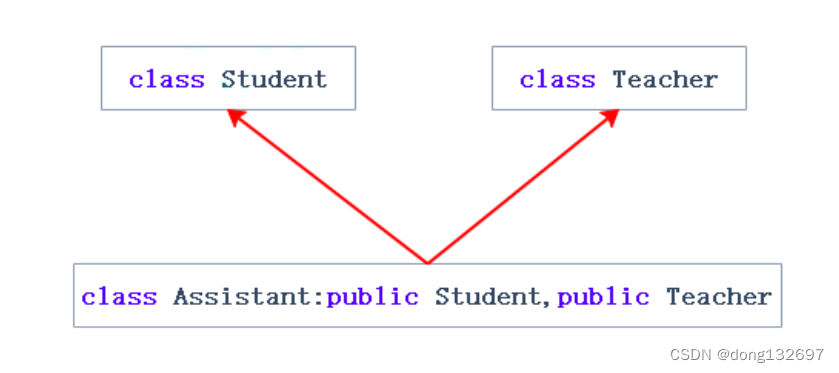
菱形继承:菱形继承是多继承的一种特殊情况。

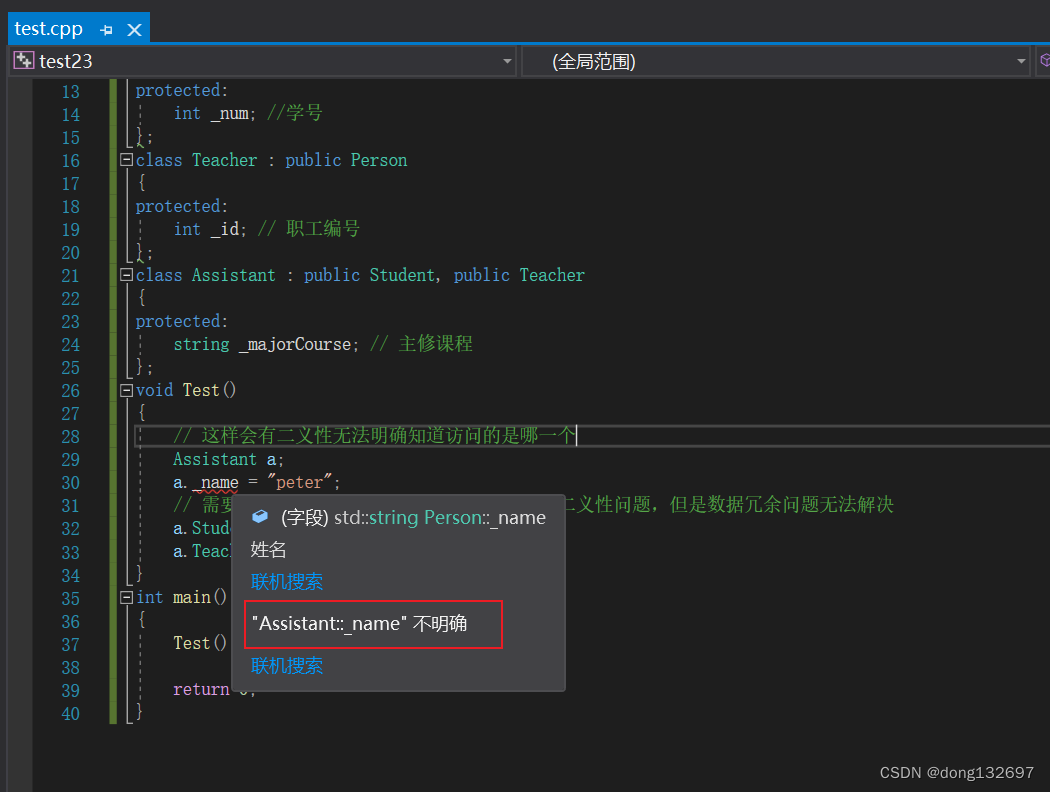
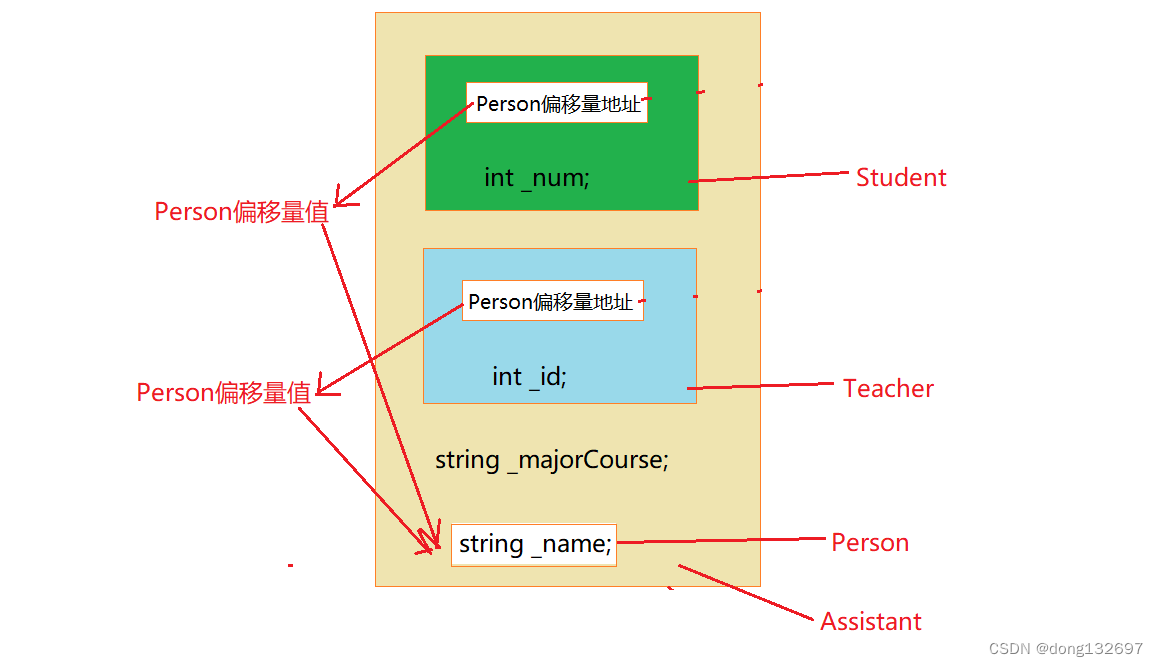
菱形继承的问题:从下面的对象成员模型构造,可以看出菱形继承有数据冗余和二义性的问题。在Assistant的对象中Person成员会有两份,所以就会有两个_name。
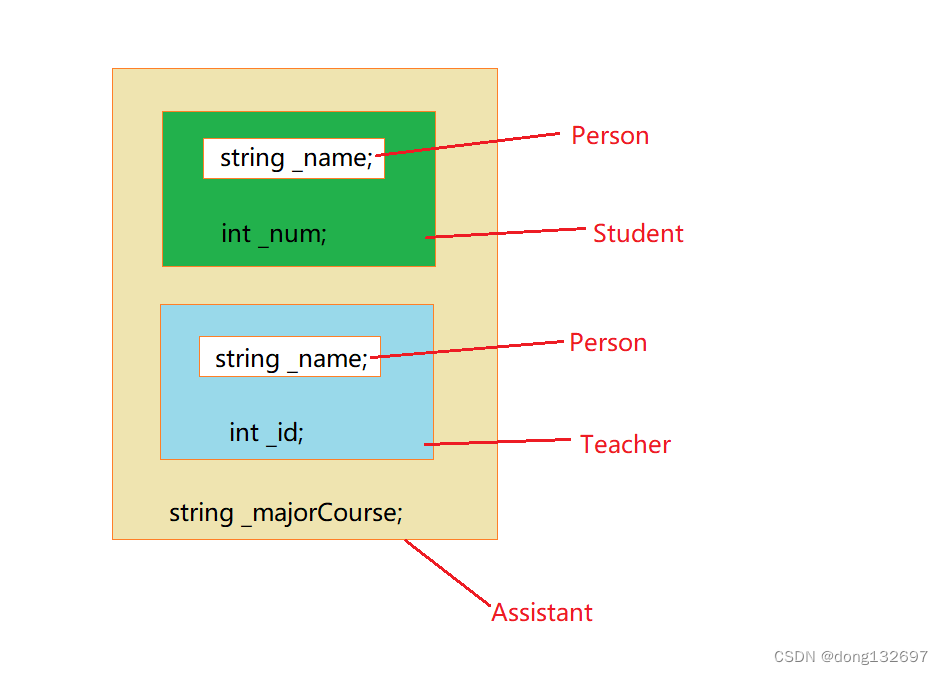
当我们创建一个Assistant 类类型的对象a,然后访问对象a的_name时,会出现_name不明确的错误,这就是因为在对象a中有两份_name,所以需要显式指定访问哪个父类的成员,这样做虽然解决了二义性的问题,但是数据冗余问题还是没有解决,即Student里面有一份Person数据,Teacher里面也有一份Person数据。
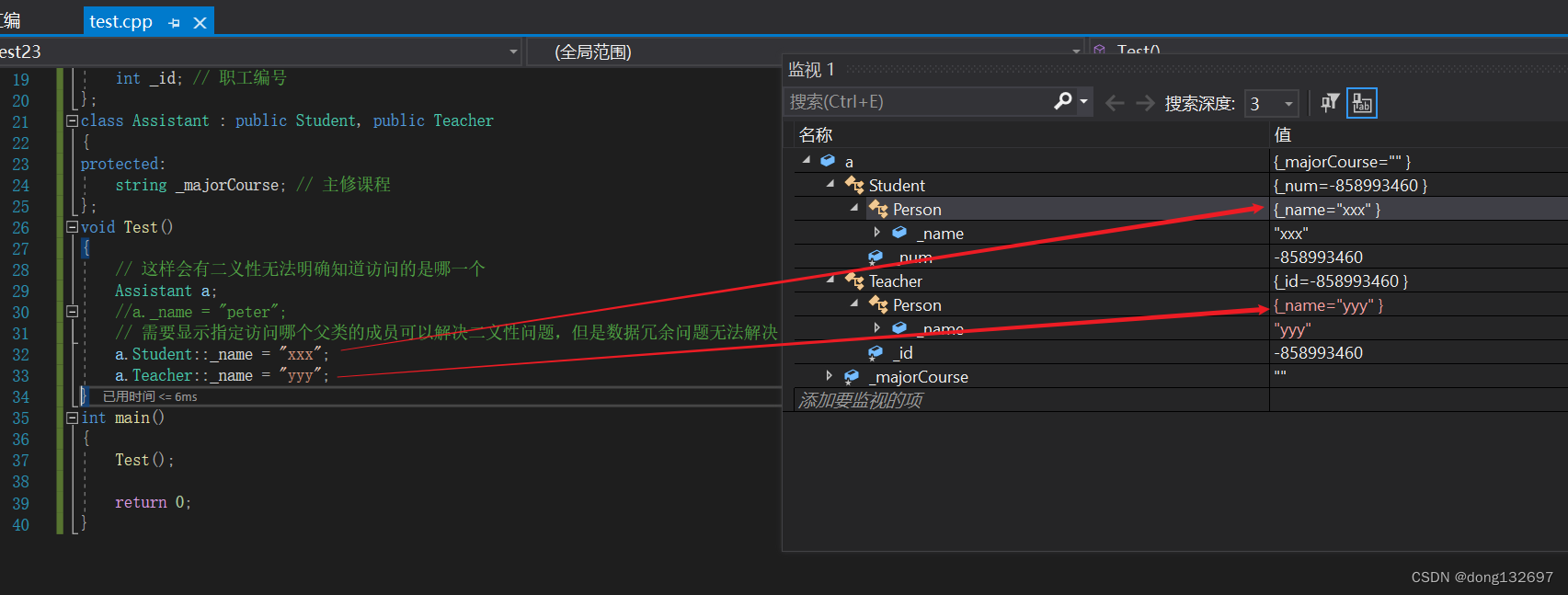
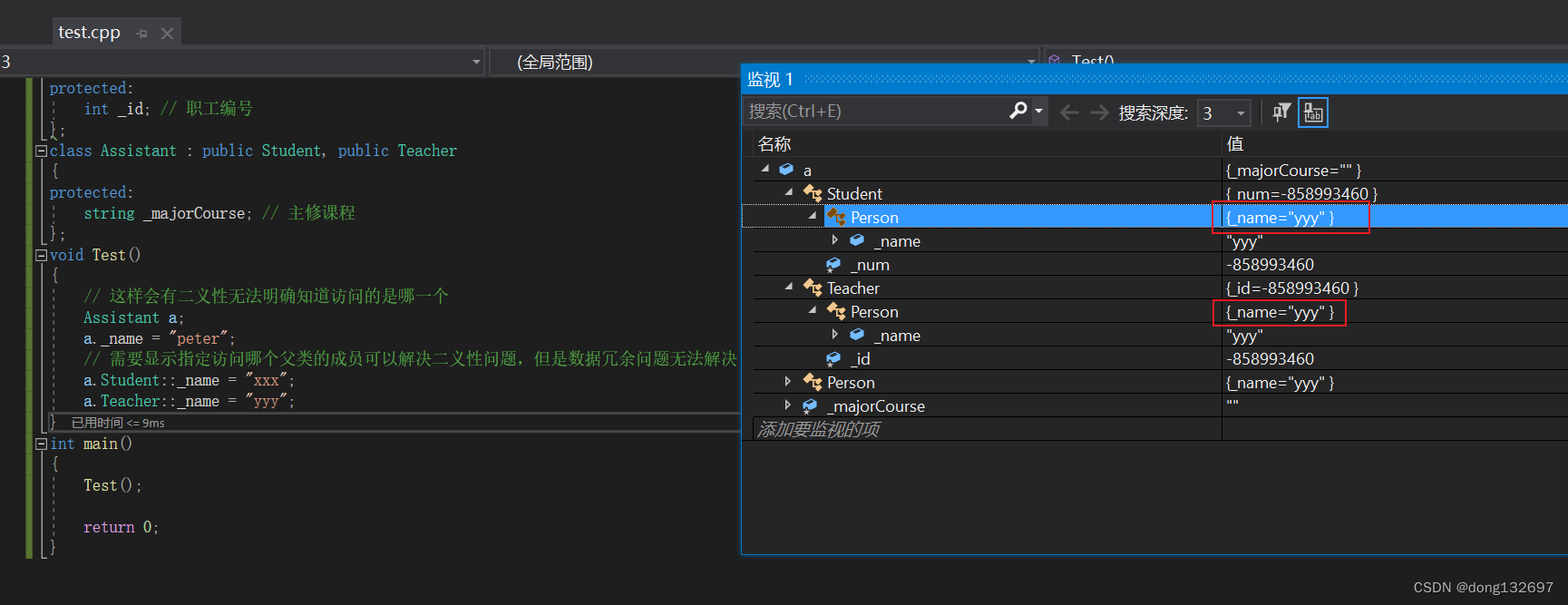
虚拟继承可以解决菱形继承的二义性和数据冗余的问题。如上面的继承关系,在Student和Teacher继承Person时使用虚拟继承,即可解决问题。需要注意的是,虚拟继承不要在其他地方去使用。
我们看到当使用了虚继承后,Assistant类类型对象a中的_name就都一样了。

虚拟继承解决数据冗余和二义性的原理:
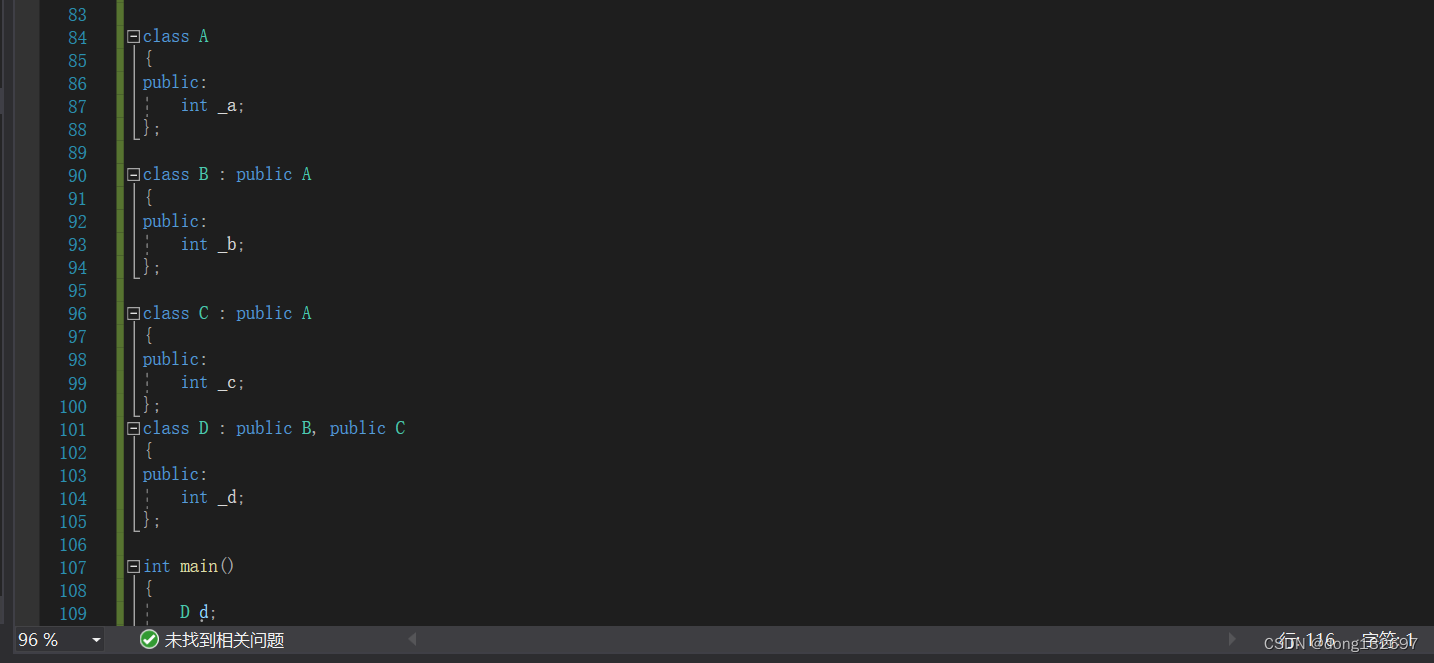
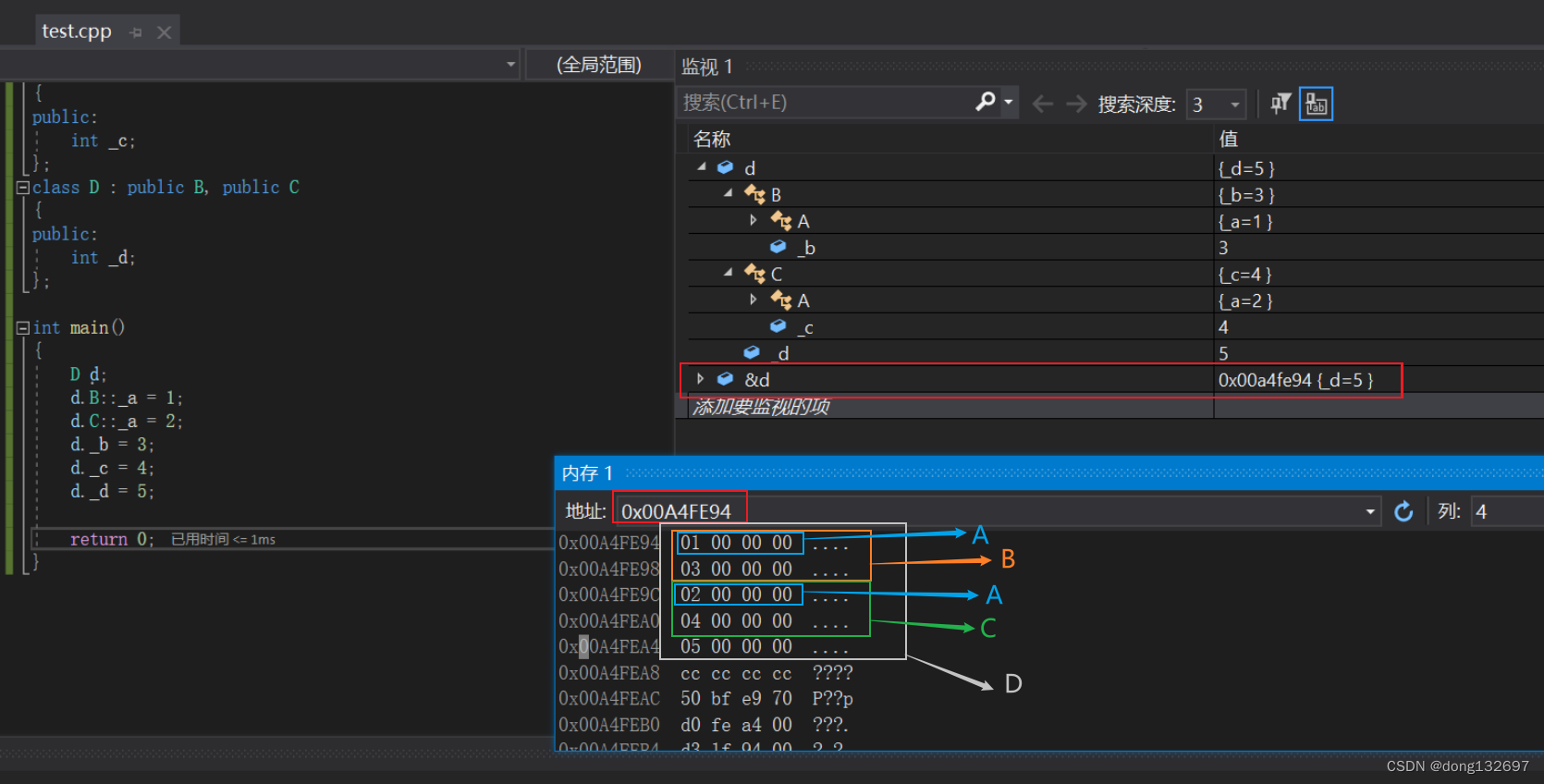
下面的代码中B类和C类都继承了A类的_a成员变量,然后D类继承了B类和C类,此时就构成了菱形继承,此时D类类型对象d的内部有两份A类的数据,即B类里面有一份A类的数据,C类里面有一份A类的数据。

下面为菱形继承下的内存分布模型。可以看到A类的_a数据在内存中有两份。
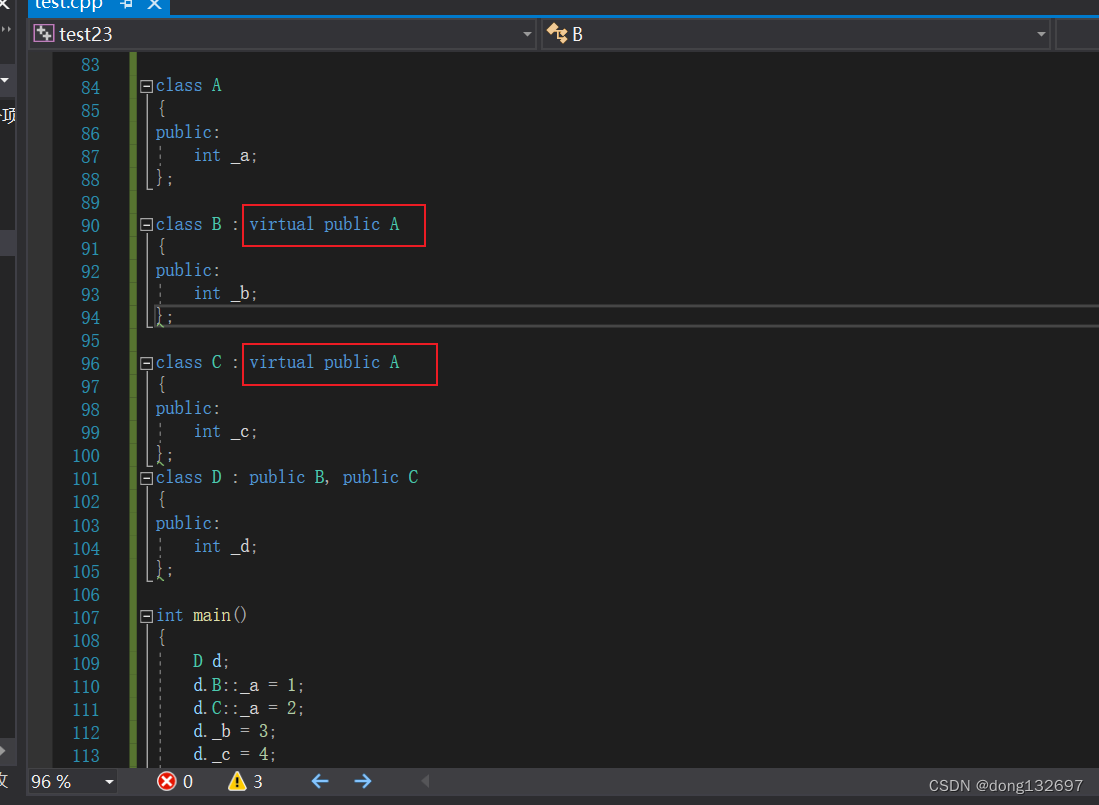
下面我们将类B和类C使用虚拟继承来继承类A,然后我们看到D类类型对象d中的B类里面的A类的数据和C类里面的A类的数据相同。
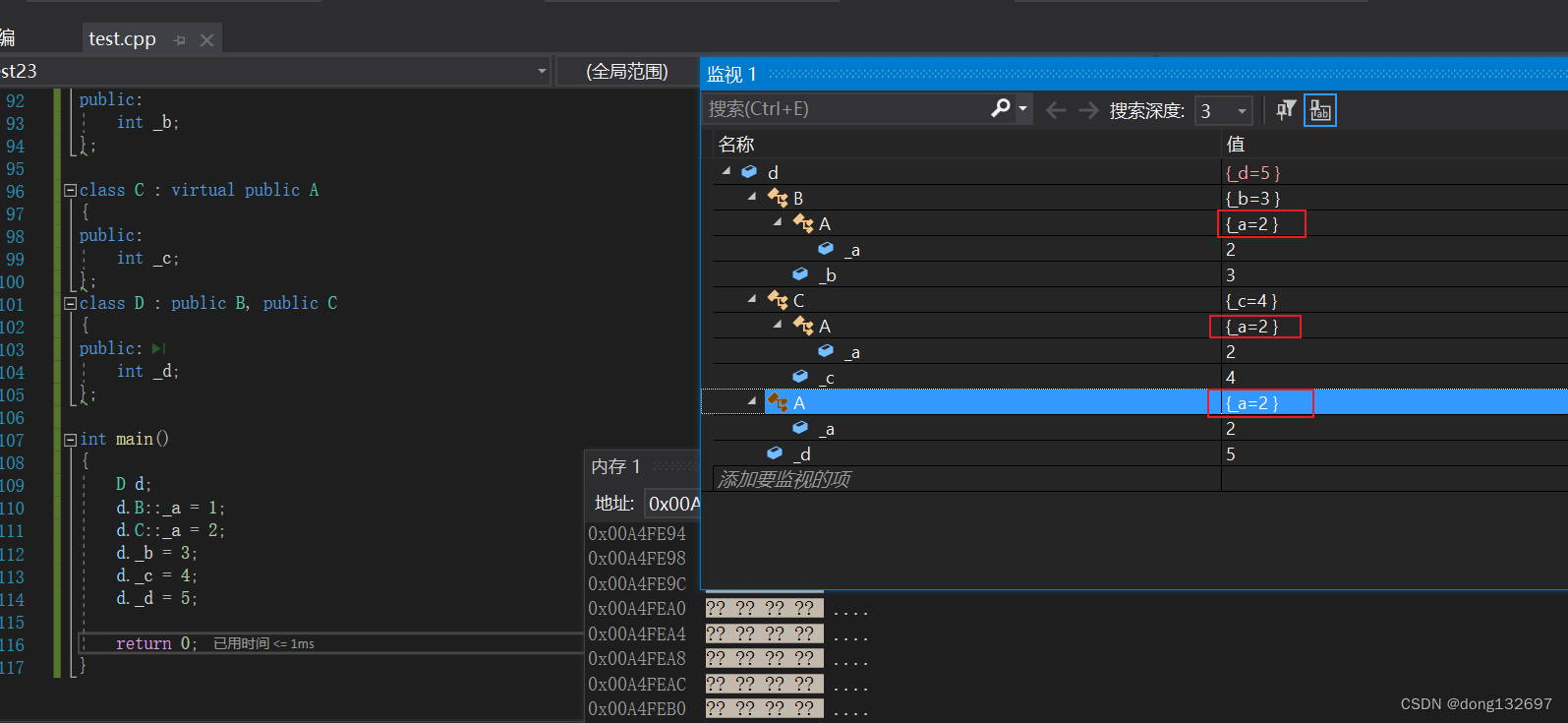
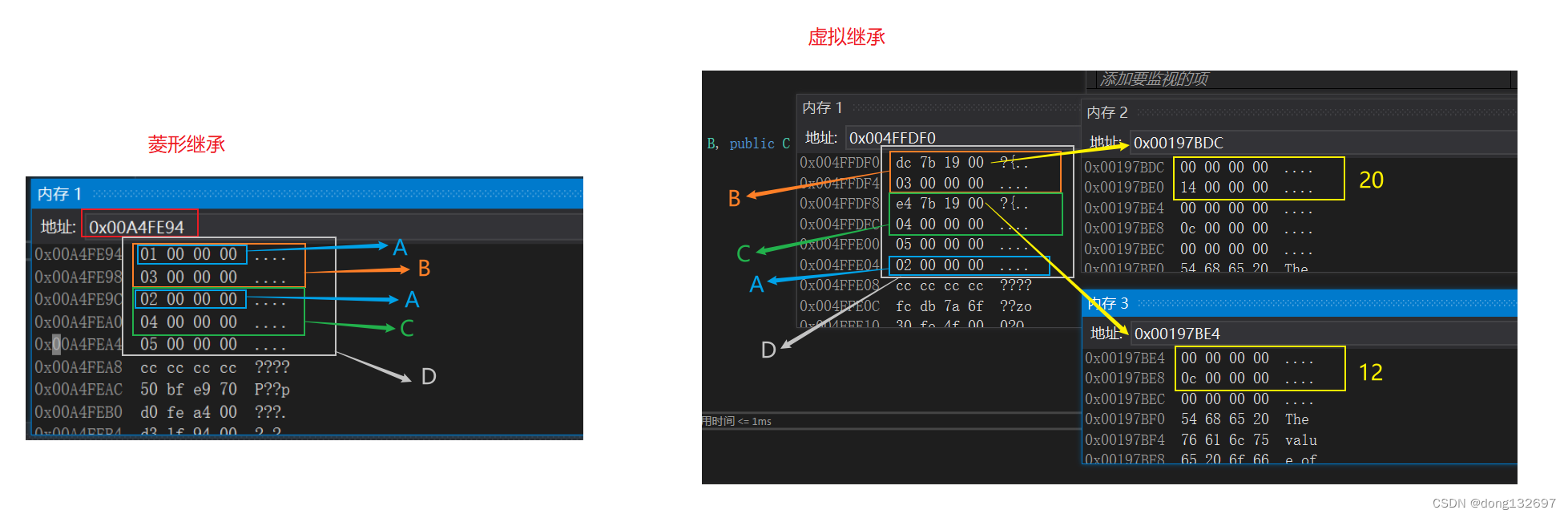
下面为虚拟继承下的内存分布模型。可以看到A类的_a数据在内存中只有一份。但是在B类中还使用4字节内存存了一个随机数据,在C类中也使用4字节内存存了一个随机数据,那么这两个4字节的空间中存的是什么呢?
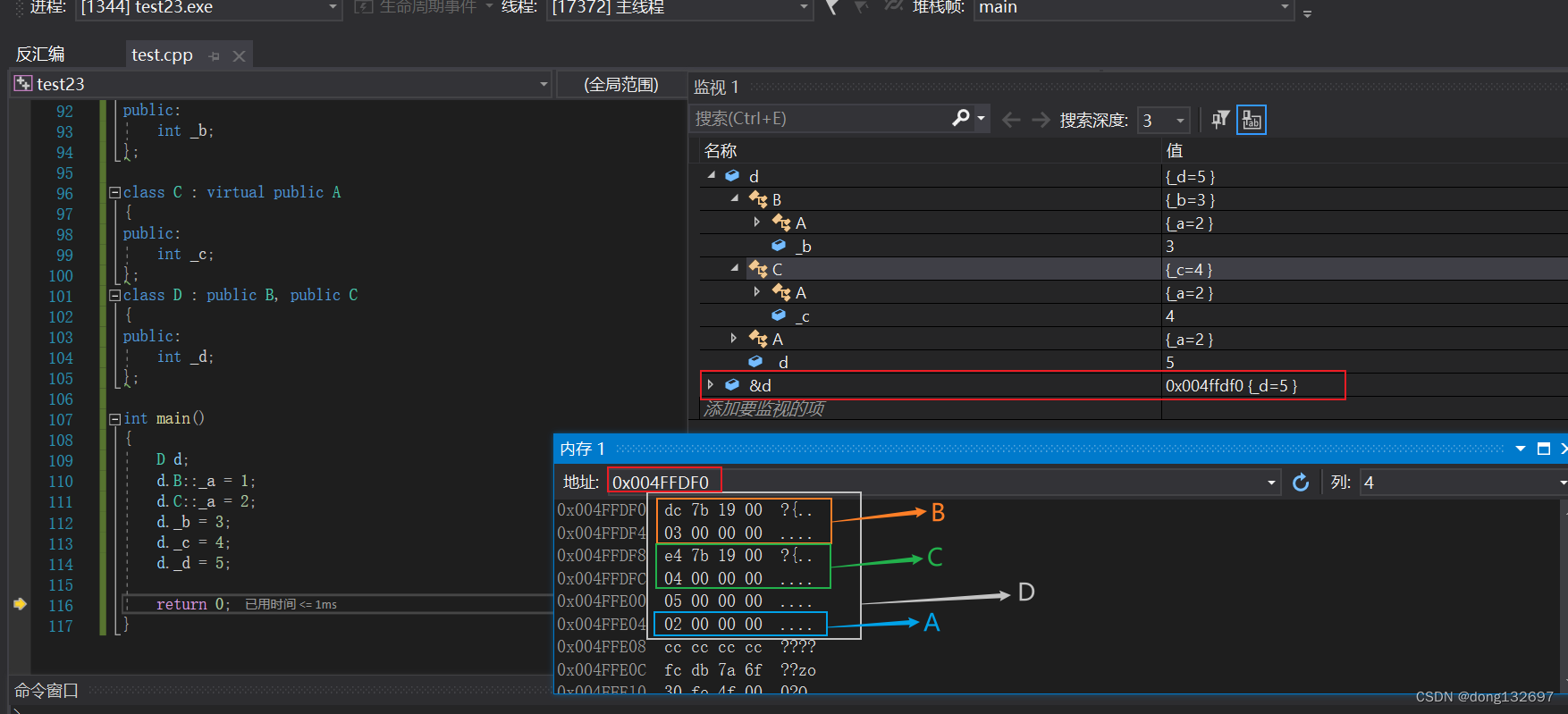
我们发现这两个随机数更像两个地址,因为这两个随机数的大小差不多。所以我们查看这两个地址里面存储的内容,可以看到B类的内存里面存的这个地址中的值为20,C类的内存里面存的这个地址中的值为12。我们可以发现B类中存地址的内存的地址0x004FFDF0 + 20 就是 A 类在内存中的地址,C类中存地址的内存的地址0x004FFDF8 + 12 就是A类在内存中的地址。所以我们知道了这两个地址中存的是A类在内存的地址相对于这个地址的偏移量/相对距离。这里是通过了B和C的两个指针,指向的一张表。这两个指针叫虚基表指针,这两个表叫虚基表。虚基表中存的偏移量。通过偏移量可以找到A类的地址。当需要访问B类中的A类的数据时,就先通过B类中存的地址得到偏移量,然后通过B类在内存中首地址加偏移量得到B类中的A类的地址,然后就可以拿到A类中的数据了。当需要访问C类中的A类的数据时,就先通过C类中存的地址得到偏移量,然后通过C类在内存中首地址加偏移量得到C类中的A类的地址,然后就可以拿到A类中的数据了。
我们可能有个疑问,为什么B类和C类的内存中没有直接存A类的地址呢?而是存了A类地址的相对偏移量的地址,并且这个A类地址的相对偏移量的地址中的首地址也没有存偏移量,而是后4个字节存的偏移量?这是因为A类地址的相对偏移量的地址中的空间还需要存其他的数据,不在该地址的前4个字节存偏移量也是因为前4个字节内存以后要存其它内容。
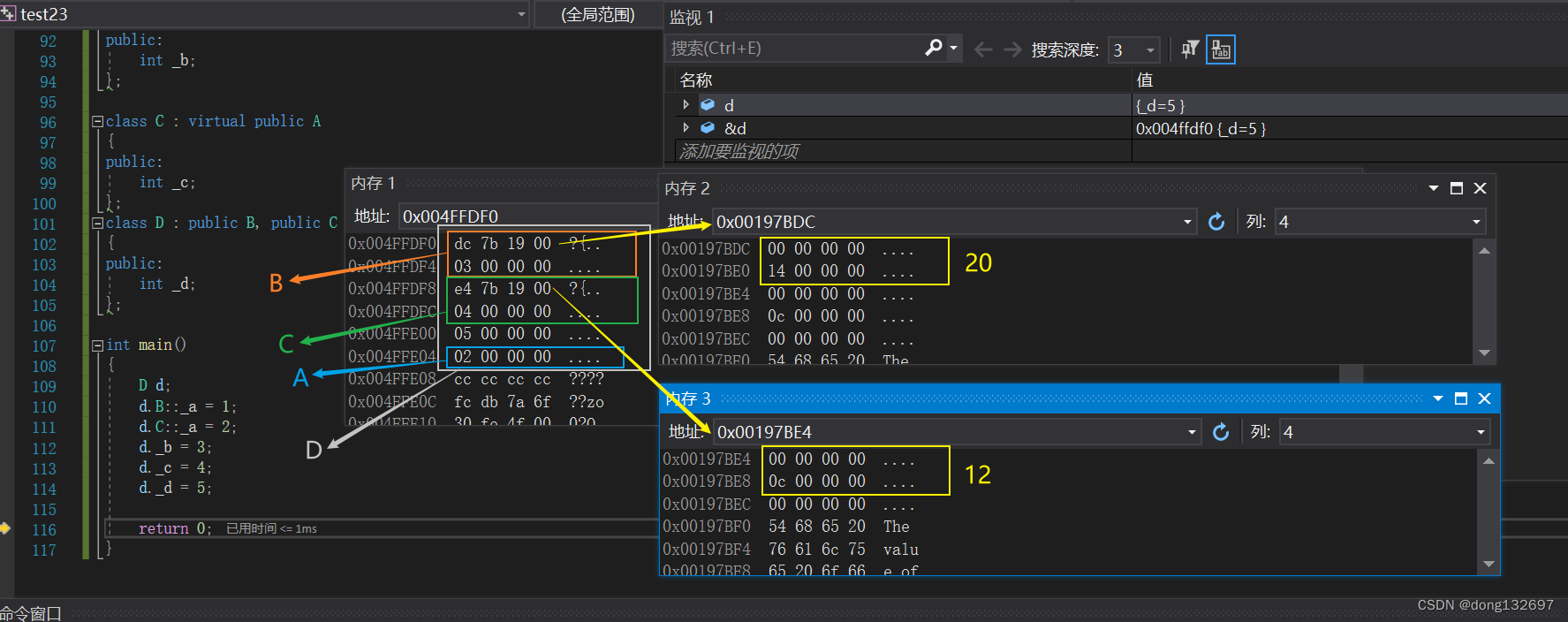
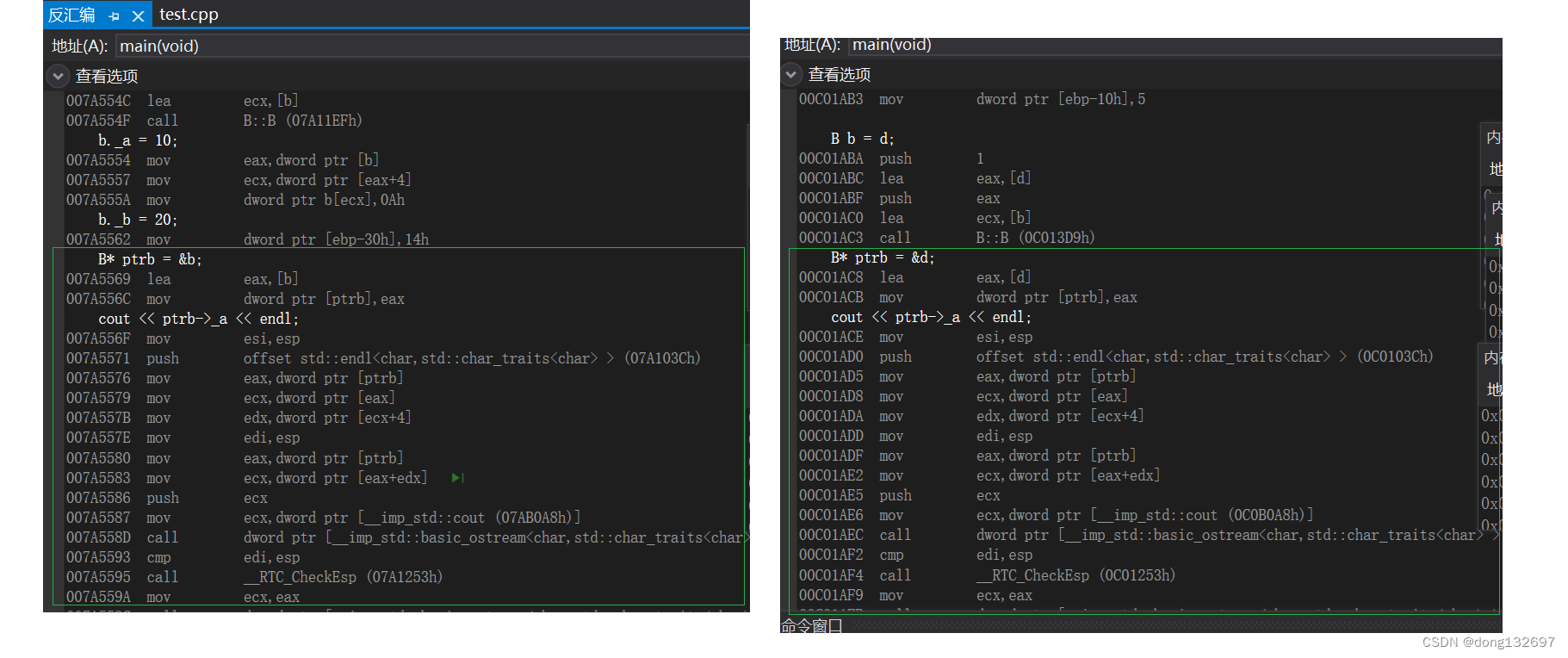
下面的两种情况中,都是访问ptrb->_a的值,但是这两种情况中ptrb指向的对象的内存模型都不一样。可以看到第一种情况中A类的_a数据的地址与ptrb指向的地址偏移量为20。第二种情况中A类的_a数据的地址与ptrb指向的地址偏移量为8。这样看来这两种情况执行ptrb->_a是完全不一样的,但是这两种情况在底层执行的指令其实都是一样的。即都是先去ptrb指向的地址中取地址,然后访问取出的地址得到偏移量,然后ptrb指向的地址加上偏移量得到A类的地址,这样就可以得到_a的数据了。我们可以看到这两种情况汇编的指令是一样的。
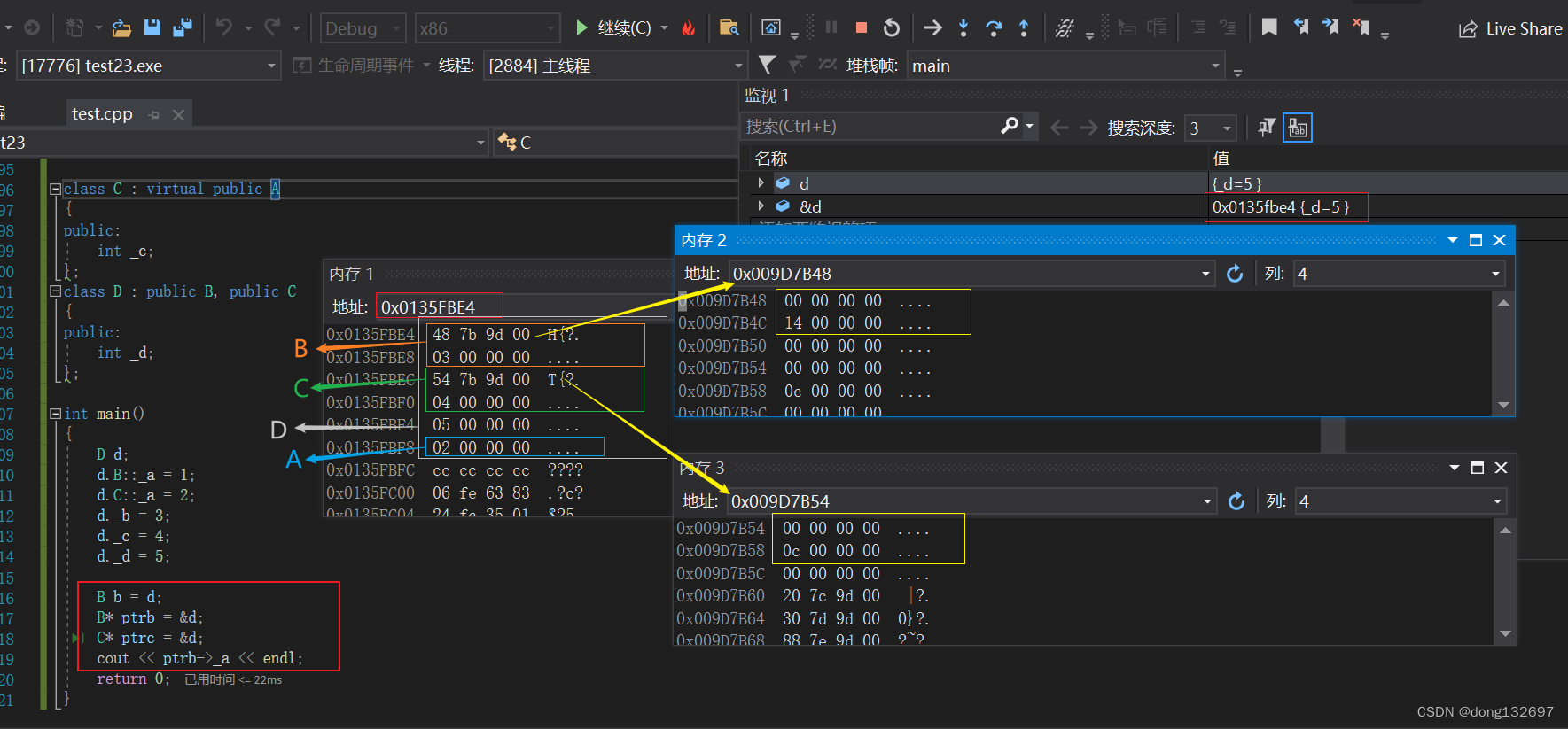
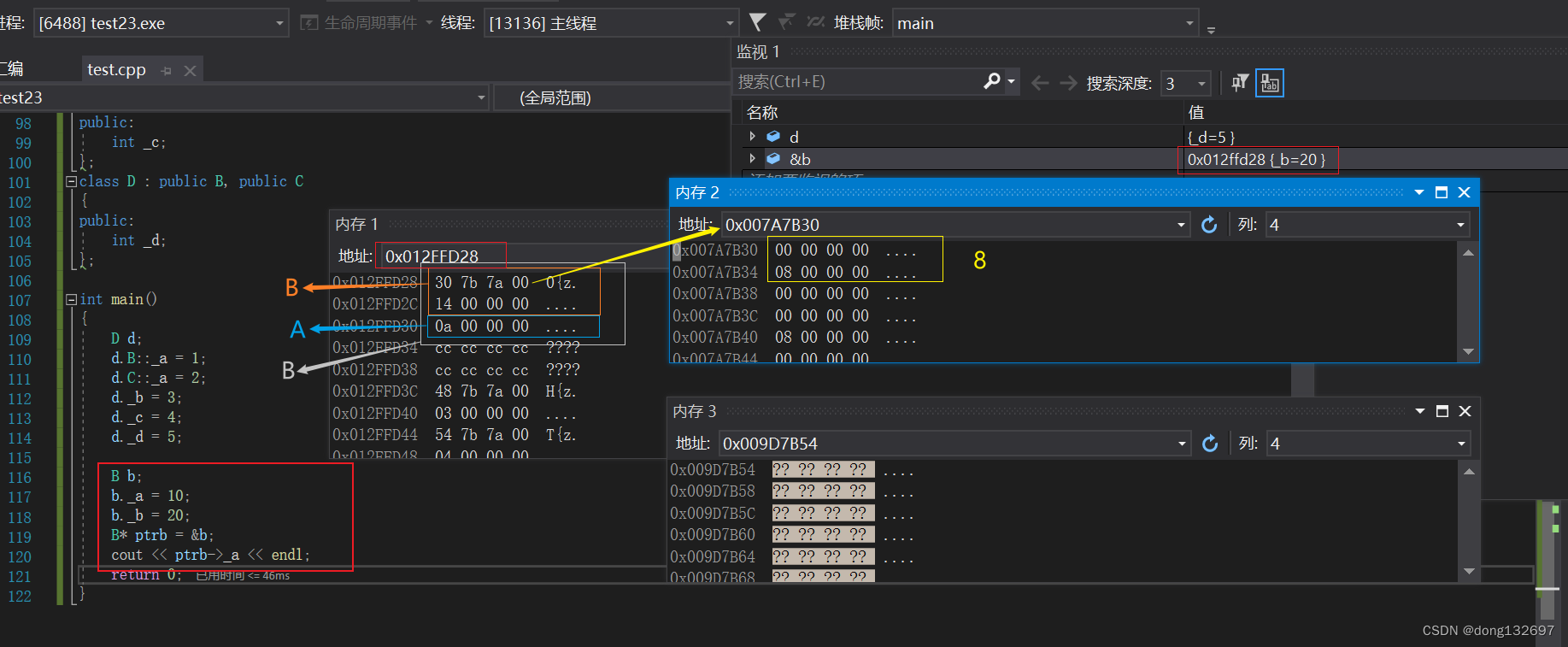
我们看下面的菱形继承和虚拟继承的内存模型,我们发现使用了虚拟继承后不但没有节省空间,还增加了4字节空间,这是因为A类中的成员变量所占的空间太小了,如果A类中的成员变量占的空间大的话,就可以看到节省空间了。而且记录A类的地址的偏移量的空间因为每个D类类型对象都是一样的,所以这些对象共用这一个空间的数据,故这片空间的开销不计算。
下面是上面的Person关系菱形虚拟继承的原理解释:
综上我们可以知道虚继承会增加消耗,因为取基类的成员变量时,需要先得到地址,然后访问地址得到偏移量,然后地址加偏移量才得到基类的地址。并且还会很复杂,遇到问题不好解决,所以能不使用菱形继承就不使用菱形继承。
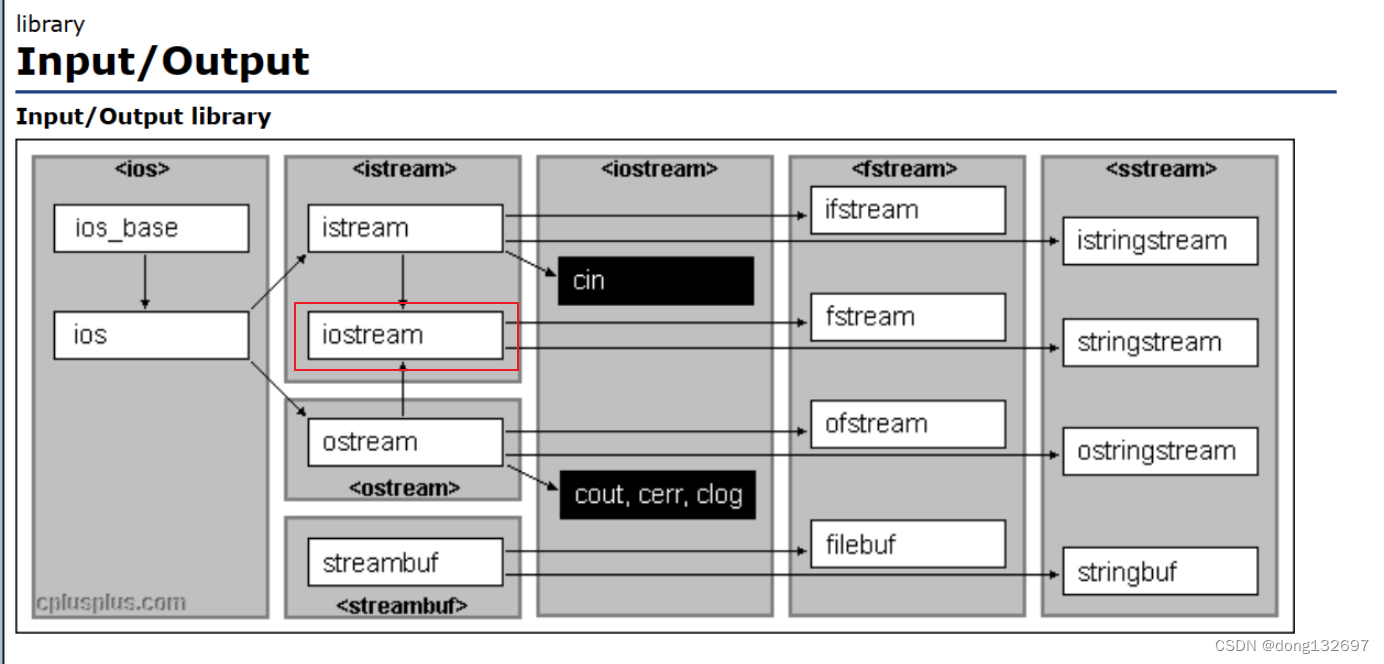
虽然菱形继承很麻烦,但是在c++库中,iostream类就用到了菱形继承,可以看到类iostream继承了istream类和ostream类,而istream类和ostream类都继承了ios类。
虚拟继承练习题:
class A
{
public:A(char* s){cout << s << endl;}~A(){}
};class B :virtual public A
{
public:B(char* s1, char* s2):A(s1){cout << s2 << endl;}
};class C :virtual public A
{
public:C(char* s1, char* s2):A(s1){cout << s2 << endl;}
};
class D :public B, public C
{
public:D(char* s1, char* s2, char* s3, char* s4):B(s1, s2), C(s1, s3), A(s1){cout << s4 << endl;}
};int main()
{char str1[] = "class A";char str2[] = "class B";char str3[] = "class C";char str4[] = "class D";D* p = new D(str1, str2, str3, str4);delete p;return 0;
}
上面的代码中会输出什么结果?
(A). class A class B class C class D
(B). class D class B class C class A
( C ). class D class C class B class A
(D). class A class C class B class D
答案为:A。按代码逻辑来说会调用3次A的构造函数,但是因为有虚继承,所以只调用了一次。初始化列表中的执行顺序和声明顺序有关,即谁先声明谁先执行。而声明顺序和继承顺序有关,谁先继承就是谁先声明。
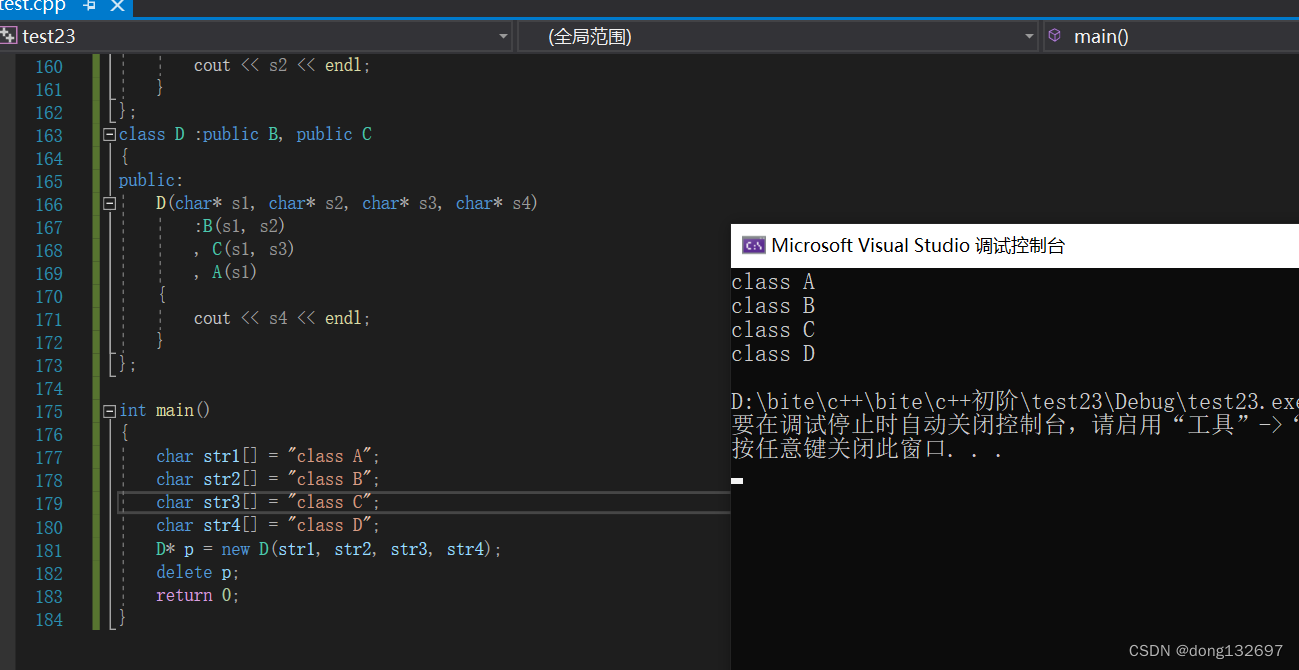
就算是下面的顺序也选A,因为继承的顺序没有变,所以初始化列表的执行顺序也不会变。因为初始化列表的执行顺序和继承顺序有关。
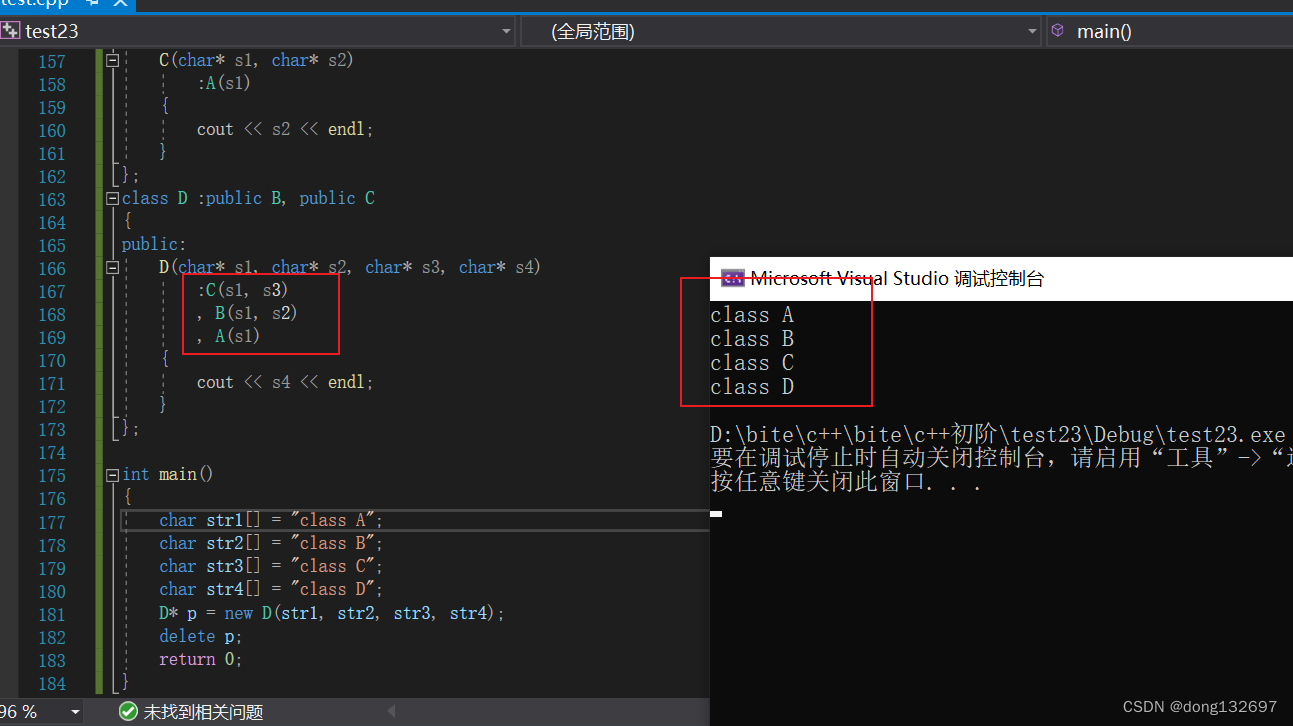
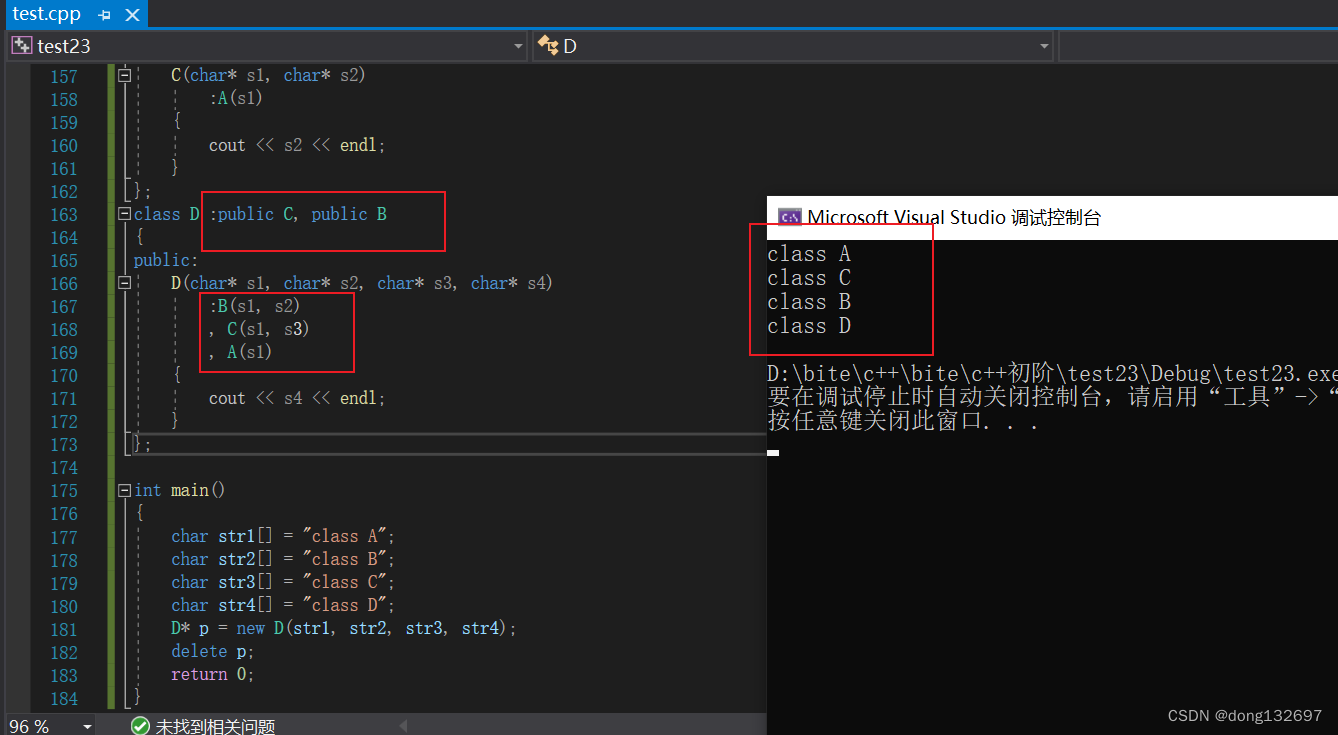
只有当继承顺序变了时,初始化列表的执行顺序才会变。下面改变了D类继承B类和继承C类的顺序,可以看到初始化列表中构造函数的执行顺序也变了。
八、继承的总结和反思
1.很多人说C++语法复杂,其实多继承就是一个体现。有了多继承,就存在菱形继承,有了菱形继承就有菱形虚拟继承,底层实现就很复杂。所以一般不建议设计出多继承,一定不要设计出菱形继承。否则在复杂度及性能上都有问题。
2.多继承可以认为是C++的缺陷之一,很多后来的OO语言都没有多继承,如Java。
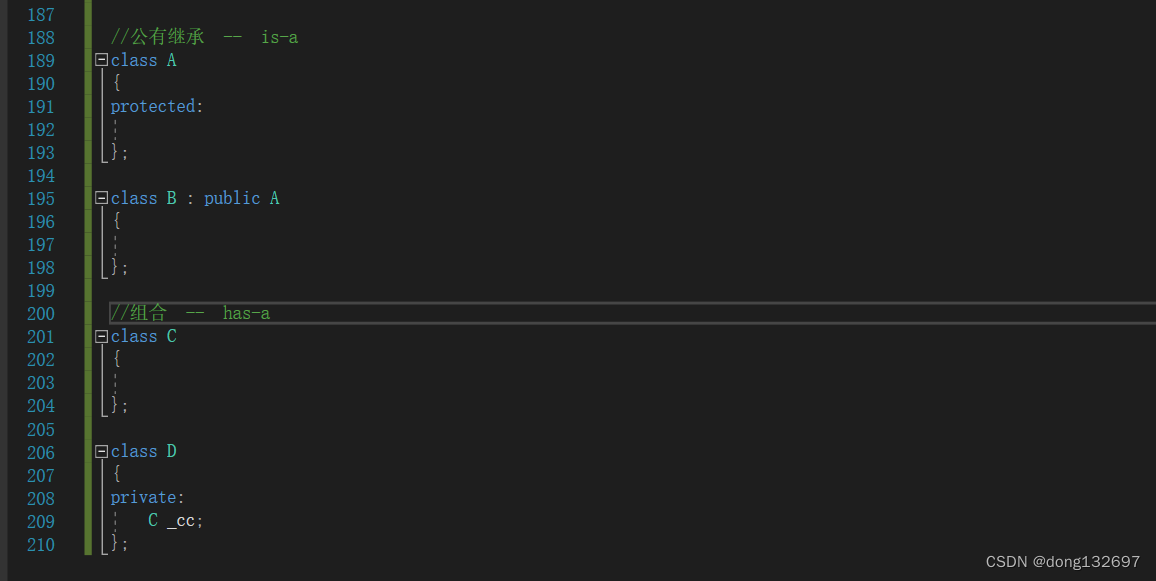
3.继承和组合。
public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。
组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象。
优先使用对象组合,而不是类继承 。
继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见 。继承一定程度破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。
对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助于你保持每个类被封装。
实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。类之间的关系可以用继承,可以用组合,就用组合。
例如:
车和轮胎就是组合的关系,即车中有轮胎。
人和眼睛也是组合的关系,即人有眼睛。
学生和人是继承关系,即学生是人。
】26 - QNX Ethernet MAC 驱动 之 emac_rx_thread_handler 数据接收线程 源码分析)
(2))




 消失的数字)







)

)
- ring allreduce)

