声明:哔哩哔哩视频笔记
源地址
第一大题题目
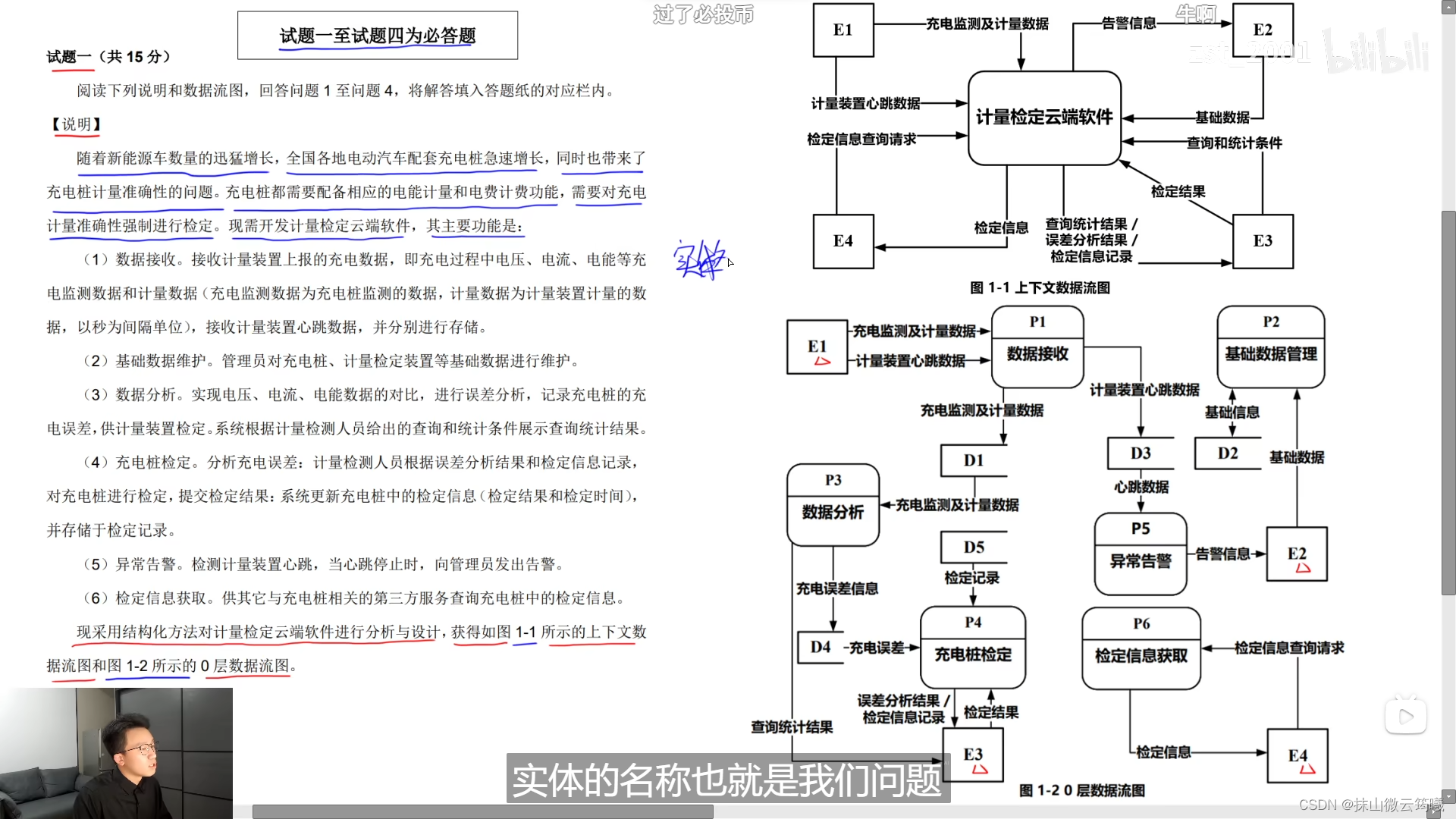
第一大题解答
第一小问

根据0层数据流图来找,看数据流向和相应的处理模块匹配。并且这个第一问,肯定是能在说明中找到对应短语作为答案的。
第二小问
搞清楚具体存储数据的信息名字,可以在后面加上 一个 表 字, 就可以作为答案了。

第三小问
数据流知识:

- 数据流的起点和终点必须有一个是加工,至少有一个是加工。
- 上下两个图要平衡,上下文数据流图系统交互具有的数据流,0层数据流图也要有对应的数据流。
- 每一个加工至少有一个输出数据流和输入数据流
- 数据守恒,说明和数据流图的描述一致,不会凭空出现和消失。
- 这一步需要细细的分析才行

第四小问
这个题目跟着自己的感觉走

第二大题题目

第二大题解答
第一小问
像这个样子的实体是一个子实体,就是某个一般实体的特殊实体。
先在试卷上画一下结果,确认好再画到答题卡上。
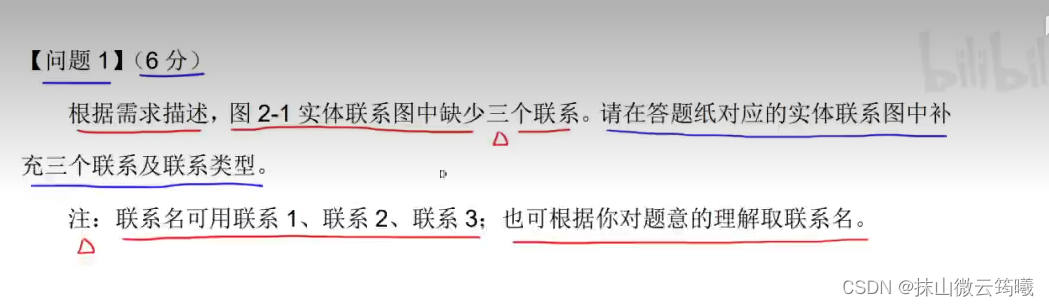
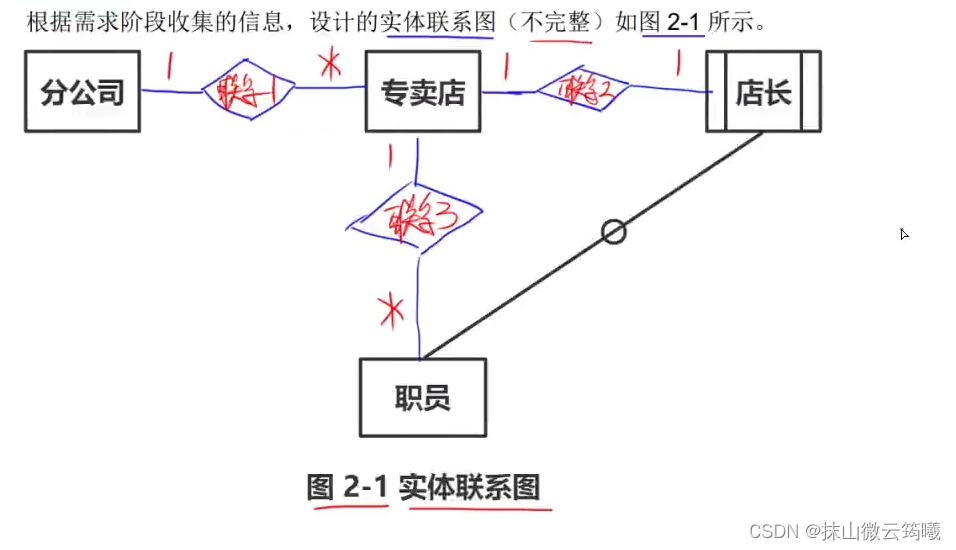
第二小问

第三小问
这一问不要想太多,切合题目结合实际,按着感觉走。

第三大题,分值分别是4,8,3,题目
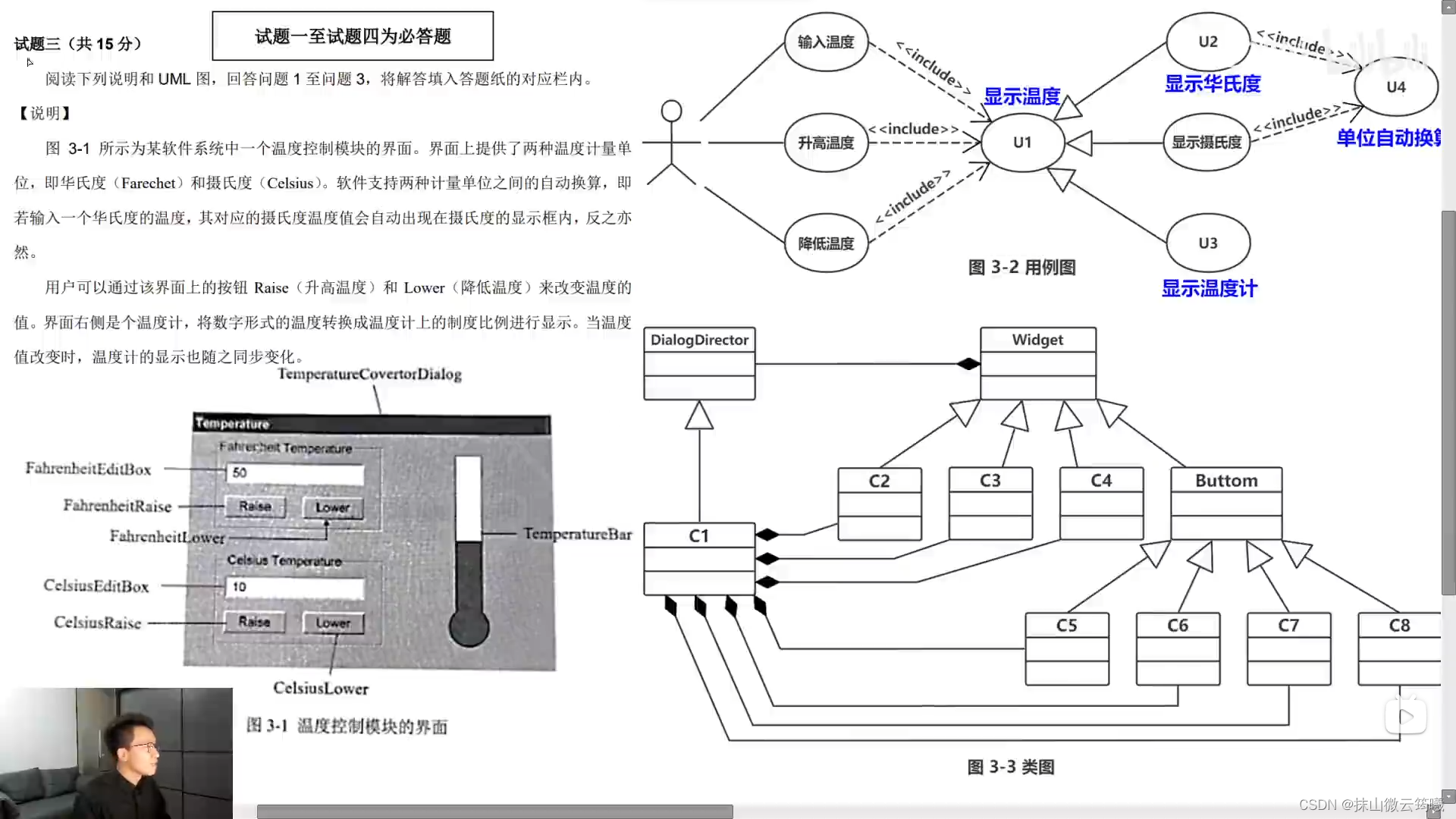
第一小问
用例一般是动词加上名词

第二小问,一分一个类名

第三小问
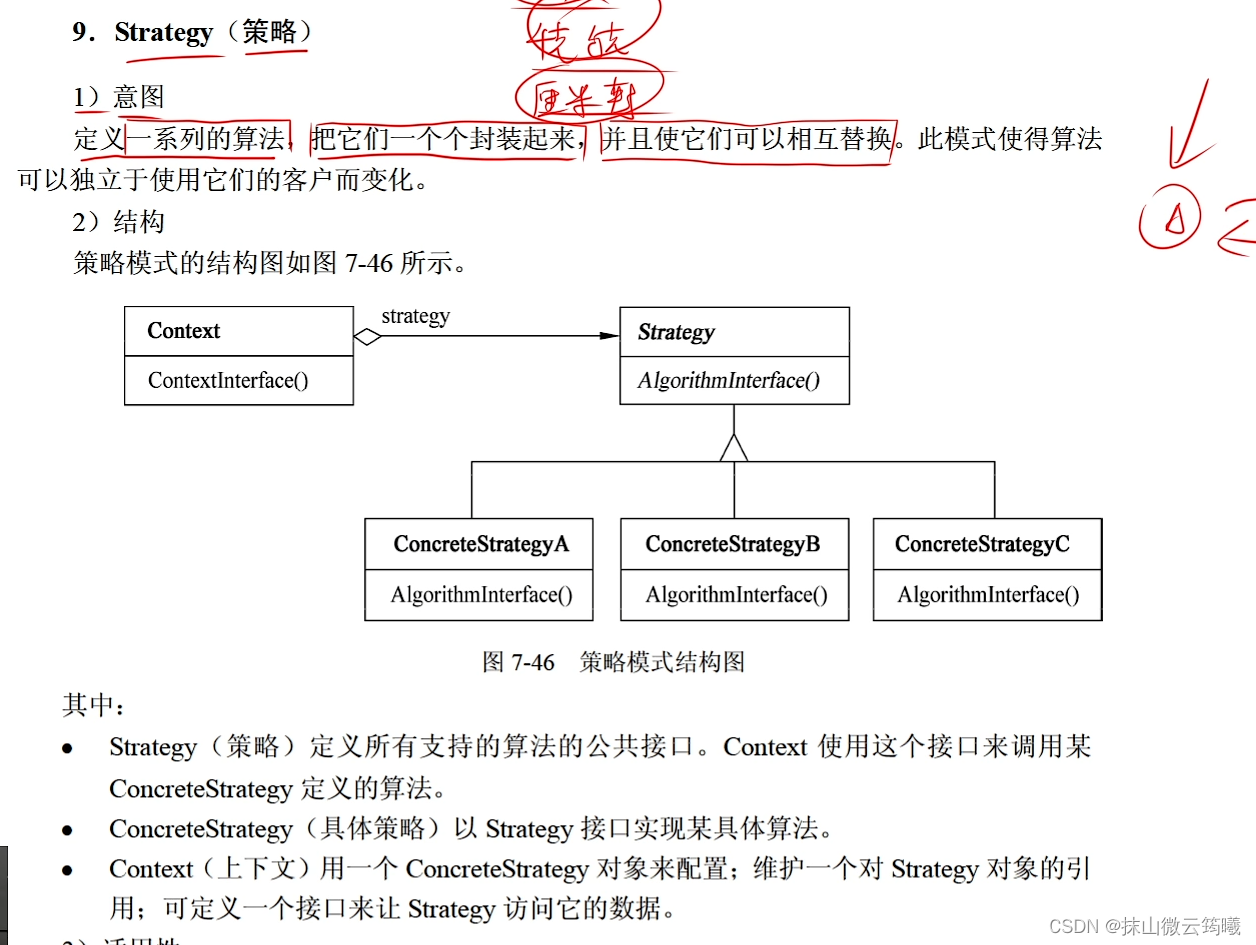
设计模式选对1.5分,解释原因1.5分
策略设计模式


第四大题题目


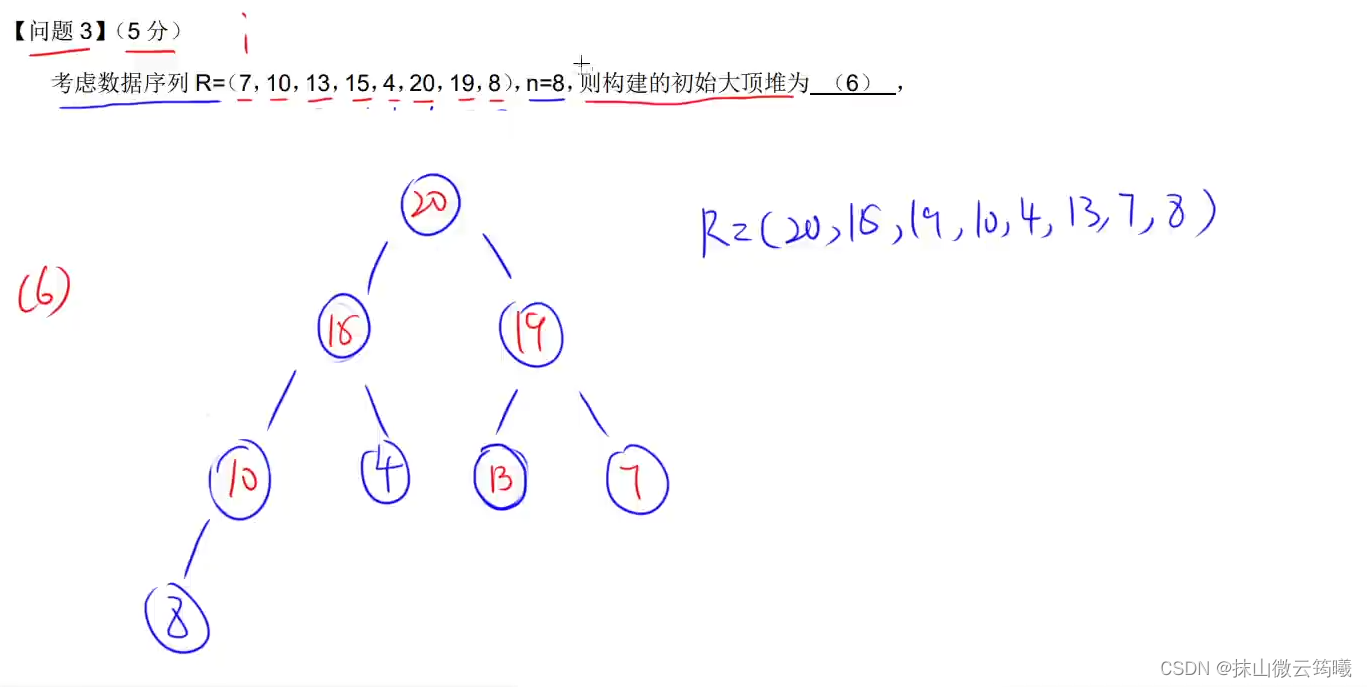
大顶堆
大顶堆(Max Heap)是一种特殊的二叉堆(Binary Heap),它是一种用于实现优先队列的数据结构。大顶堆具有以下特性:
-
堆属性:在一个大顶堆中,对于每个父节点P,P的值大于或等于其子节点的值。这意味着堆的根节点始终包含最大的元素。
-
结构属性:大顶堆通常是一棵完全二叉树,这意味着除了最底层,其他层的节点都是满的,而在最底层,节点从左到右填充,不留空。
大顶堆通常用于实现一些算法和数据结构,如堆排序、Dijkstra算法、Prim算法等,这些算法需要在运行时高效地找到最大值或进行优先级处理。在大顶堆中,最大的元素总是位于根节点,因此可以快速找到并移除最大元素。
大顶堆可以通过插入和删除操作来维护其属性,确保堆的结构属性和堆属性一直得到满足。在插入元素时,通常会将新元素添加到堆的底部,然后逐级向上调整,以确保堆属性保持不变。在删除元素时,通常会删除根节点,并将堆的底部元素移到根的位置,然后逐级向下调整以保持堆属性。
小顶堆(Min Heap)与大顶堆相反,其中每个父节点的值都小于或等于其子节点的值。它们在解决不同类型的问题时都有广泛的应用。
第一小问,堆排序给我整懵逼了,算法有点难搞

第二小问
堆排序的时间复杂度




第三小问
两种作答形式皆可,但是推荐第一种画图。
将第一个元素脱离,再调整成大顶堆后的数组为:
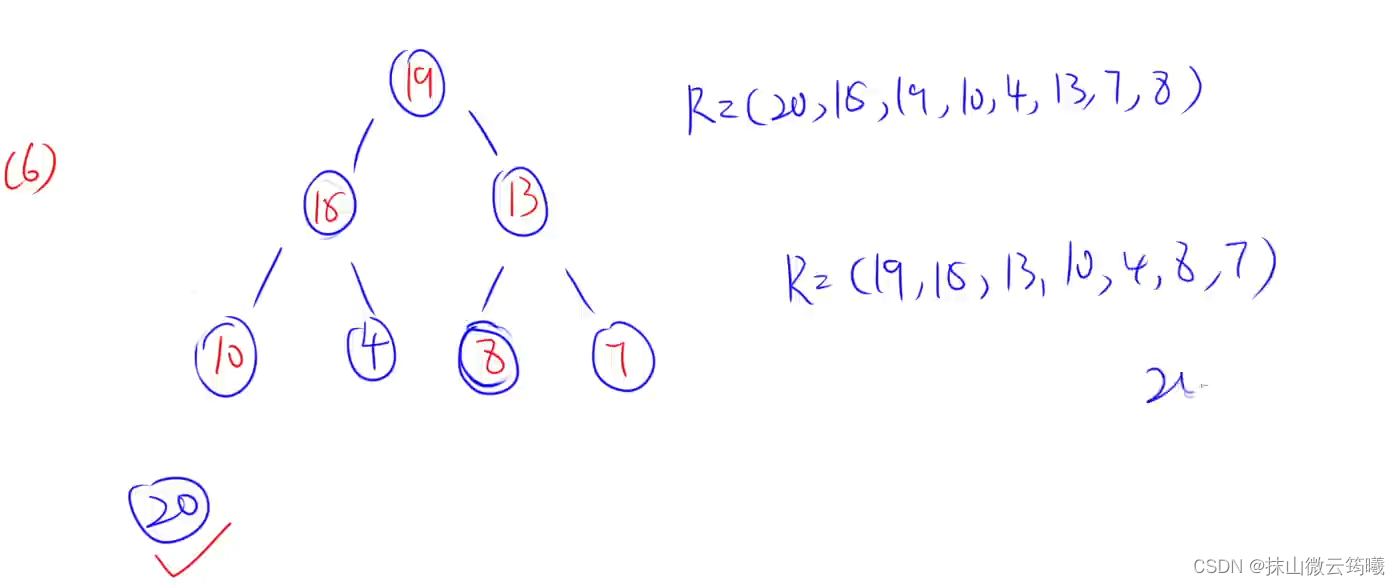
但是这里,第一个元素只是逻辑上脱离,但是物理上仍然存储在数组之中,这里还是要将第一个元素写上。
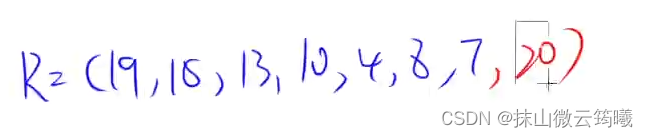
这一题可以在编译器运行代码测试一下。
第五大题题目,选做,需要填涂,默认小题号
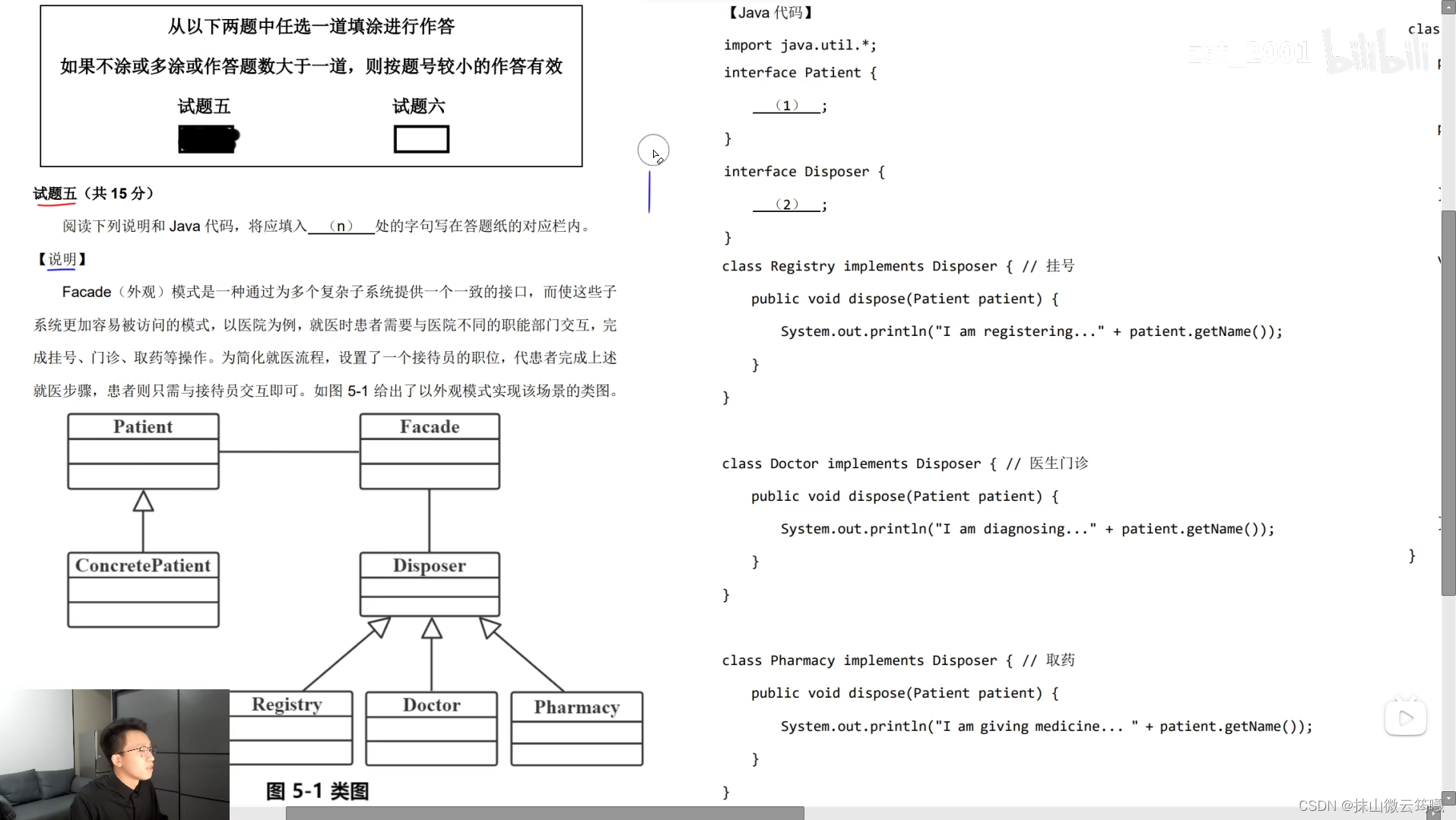

第一小问
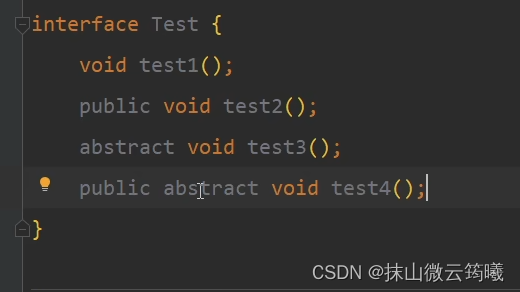
- 接口中的空找实现这个接口的类,寻找具体的方法。
- 相应的修饰符和参数写清楚写对,一般 修饰符最好不要省略。
- 构造方法按照方法的参数来传参。

对于冗余的修饰符,只要不会使程序报错,一般会给分,但是既然是冗余的,不写当然也可以。
第六大题
因为我主要学习的是Java,这里就是题目和答案

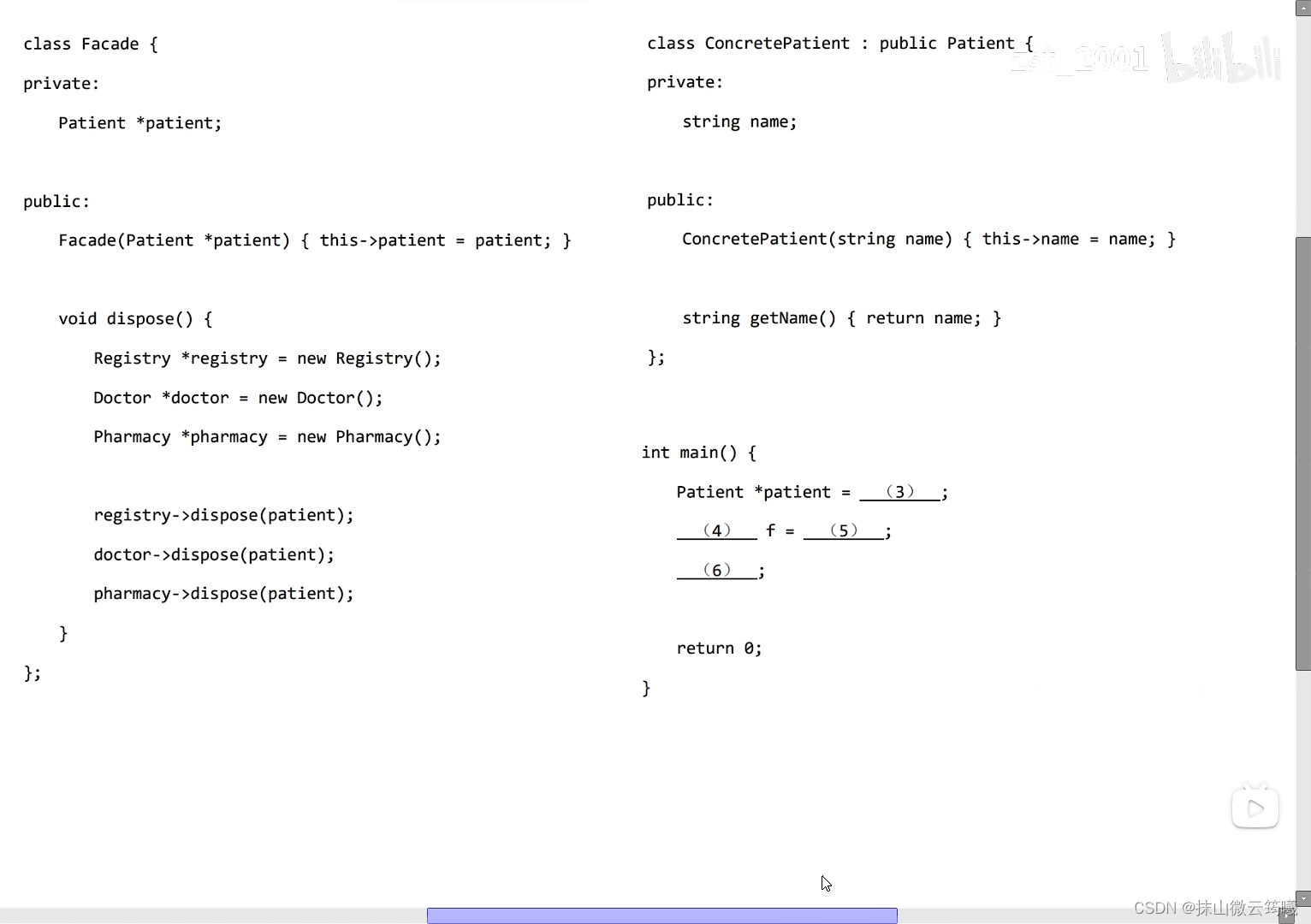
解答










采集日志到logstash,由logstash发送的es)

![分发糖果[困难]](http://pic.xiahunao.cn/分发糖果[困难])







