一、AutoGPT介绍
想象一下,生活在这样一个世界里,你有一个人工智能助手,它不仅能够理解你的需求,而且还能够与你一起学习与成长。人工智能已无缝融入我们工作、生活,并帮助我们有效完成各种目标。大模型技术的发展与应用,使以上想法成为现实。特别是ChatGPT等生成式对话模型的出现,极大改变了人们的生活与工作方式。
用户可利用ChatGPT通过对话交互的方式得到所需答案,即我们通过ChatGPT给出的答案以及我们的提问来评估是否满足要求。如果不满足要求,我们会继续向ChatGPT提问,并引导其给出满足目标的答案。这个过程是循环反复进行的,直到给出满意答案为止。用户在这个过程中起到作用的是评估与反馈。
那么,以上过程能不能通过ChatGPT来自动实现?
AutoGPT:自主运行的GPT,其运行过程无需或少需人工干预,能够根据GPT自主决策结果并结合外部资源执行相应操作,通过循环评估策略实时评估目标达成程度,来决定任务是否完成。
二、AutoGPT原理
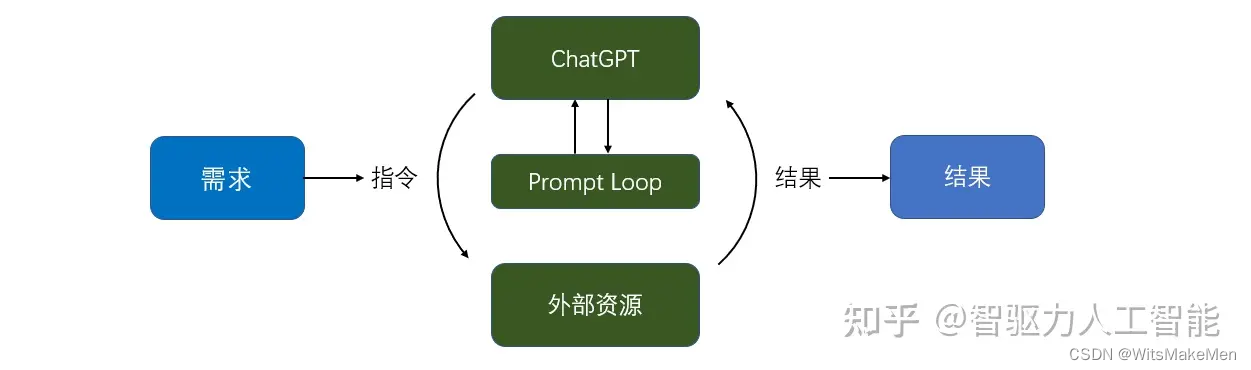
AutoGPT主要由三部分构成:需求下发、自主运行、结果输出。其中,自主运行是AutoGPT的核心模块。其流程如下:
1、任务定义:通过Prompt向ChatGPT下发任务,初次下发任务需包含以下内容:用户名(Name)、角色(Role)、目标(Goals)。后续的Prompt是根据执行结果由ChatGPT自动生成。
2、理解任务:对下发的Prompt,ChatGPT通过大模型对语义内容理解。这部分对应AutoGPT中的Thinking,模仿人类,接收到任务,正在思考。
3、生成方案:对思考的结果,ChatGPT会输出详细的Step-by-Step的解决方案,这部分对应AutoGPT中的PLAN。即ChatGPT根据思考结果,逐条列出了需要执行的步骤。
4、生成指令:对于需要执行的步骤,ChatGPT会通过逻辑判断,从中选择出优先执行的步骤,并生成可执行的操作或指令。这部分对应AutoGPT中的CRITICISM。为通过ChatGPT决策后返回的指令。包含command与arguements。例如,浏览百度网站指令。command=browse_website,arguments={‘url’:“http://www.baidu.com”}
5、执行指令:通过访问外部资源或调用ChatGPT完成任务。这些外部资源可包括:访问网站、解析网站、爬取数据、执行电脑指令等。使用ChatGPT资源可包括:编写代码等。
6、输出结果:指令操作完成后,系统返回执行结果,这些执行结果可以是:网站页面解析的结果、数据分析的结果等。
7、评估结果:执行任务后,AI 会评估结果以确定是否达到预期目标或是否需要进一步完善。这种评估有助于 AI 了解其行动的有效性并做出必要的调整。
循环执行以上过程,直至用户定义的所有目标均完成。以上为AutoGPT的整个运行流程。那么,它是如何实现以上各流程?
第一个问题:AutoGPT如何理解任务?
理解能力建立:AutoGPT理解任务通过调用ChatGPT实现。ChatGPT是大规模语言模型。它的理解能力是通过建立在训练过程中接触到的人类生成的文本例子获得的。在训练ChatGPT时,模型会暴露于各种各样的文本中,包括对话、故事、问题回答等。而这些文本中会包含不同角色、目标信息。在训练过程中,模型学会了角色和目标是如何关联的,角色和目标的上下文信息。比如,当角色设定为科学家,模型会根据学习到的科学家的性格、行为、目标等信息,生成符合角色信息的文本。
**新任务理解:**那如果定义的角色或目标,其从未见过,如何生成回答?在GPT-4中采用了zero-shot learning,即零样本学习。简单的说,模型在训练过程中没有接触到特定样本,但在推理过程中依然能够处理这些特定样本。为什么可以?零样本学习模型的设计,允许其学习到不同角色或目标类型之间的相似性。例如,我们在学习中,只采用了“研究人员”角色的数据进行训练,当我们定义“科学家”的角色时,模型会捕捉研究人员与科学家之间的语义相似性,从而生成符合角色的回答。
【总结】:当输入prompt时,其会被编码器映射至潜在空间特定维度的高语义表征向量。这些向量通过解码器解码生成我们所需要的回答。
第二个问题:AutoGPT如何分解任务?
**多任务学习:**AutoGPT的方案的生成旨在将单一任务拆解为多个子任务。通过多任务学习Multi-Task Learning,可以将单个任务分解为多个子任务。在训练过程中,任务作为输入,多个子任务作为输出。MTL 的基本思想是在一个共享的特征表示层和多个任务特定的输出层之间建立模型。共享的特征表示层负责学习通用的特征表示,可以从不同的任务中共享和提取共同的信息。而每个任务特定的输出层则负责学习任务特定的知识和模式。
例如:任务为“在某网站爬取最新新闻数据,并将标题数据以result.txt文件存储。”MTL会将任务拆解为:
浏览某网站并获取html数据;
编写并执行解析html数据脚本,将标题数据存储至result.txt。
【总结】:AutoGPT根据Prompt生成回答,并通过多任务学习,对任务进行拆解。
第三个问题:AutoGPT如何生成方案?
AutoGPT会根据目标数据、任务执行返回的结果等数据,生成新的方案。生成新方案的输入分为两种:
**第一种:**长期记忆Memory
用于存储用户角色、用户目标、关键段落等历史信息,并以向量的形式进行存储至本地或Pinecone向量数据库。因为存储的是向量,可以通过点乘的方式判断数据之间的相似性。因此,在GPT生成新Prompt时,通过最近N条Message与Memory的相似性,选择相似性最高的Memory作为GPT输入。
**第二种:**短期记忆History
短期记忆是历史的Chat信息。在GPT输入时,因为存在Token限制(GPT-3.5为4096),选择最近特定条数的对话作为GPT输入。
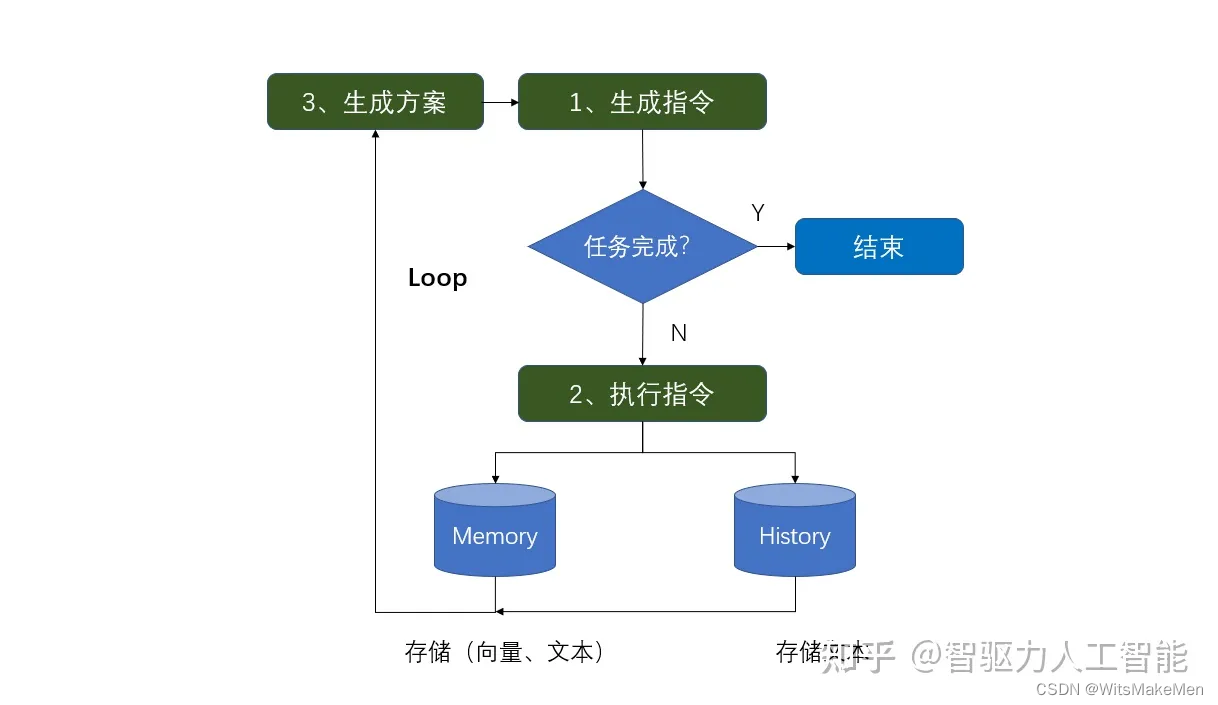
**【总结】:**为了能够最大程度利用过往数据,AutoGPT采用了Memory与History组合的方式来记忆数据。即采用距离最近的特定数量History数据与相关度最高特定数量的Memory数据作为输入。
三、AutoGPT应用
下面以“指定网站落马官员结构化数据爬取”任务为例,分析AutoGPT在内容抓取中的应用。引擎:GPT-3.5。
第一步:启动autogpt

第二步:定义任务

【定义任务】: “browse the website 精准查办案件 - 长春市纪律检查委员会 to obtain the news title and saved as result.txt”(浏览网站获取新闻标题数据,并将结果存储至result.txt)
第三步:创建名字、角色、目标
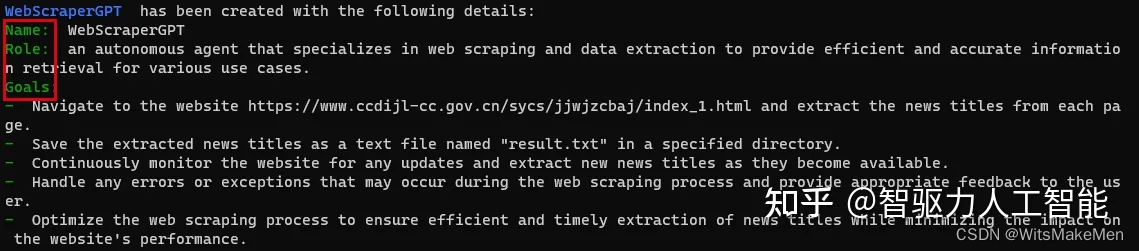
**Name:**WebScraperGPT(网页爬虫GPT)
**Role:**an autonomous agent that specializes in web scraping and data extraction to provide efficient and accurate information retrieval for various use cases.(一种自主代理,专门从事网页抓取和数据提取,为各种用例提供高效准确的信息检索。)
**Goals:**AutoGPT通过对任务的理解,拆分为了四个目标:
**目标1:**导航到网站,并从每个页面中提取新闻标题;
**目标2:**将提取的新闻标题保存为指定目录中名为“result.txt”的文本文件;
**目标3:**持续监控网站的任何更新,并提取可用的新新闻标题;
**目标4:**优化网页抓取过程,确保高效及时地提取新闻标题,同时最大限度地减少对网站性能的影响。
第四步:生成方案
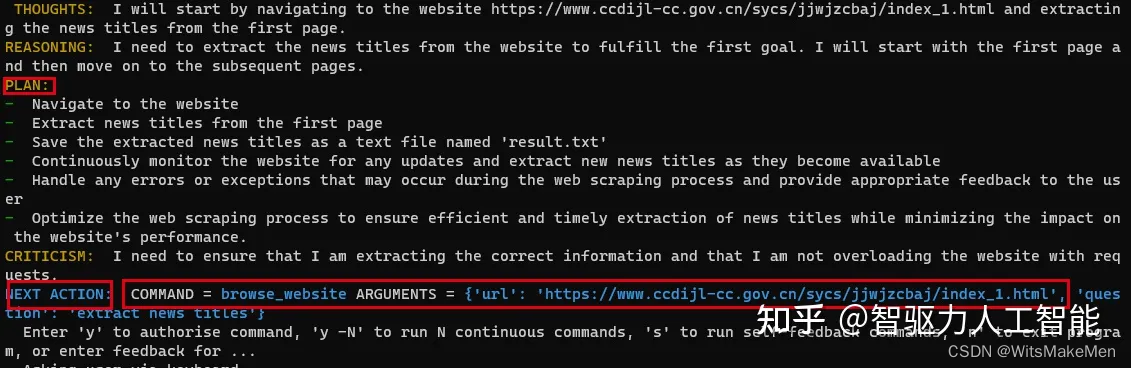
AutoGPT通过思考,给出了四条PLAN,并在这四条PLAN中选择了优先执行的一条:提取第一页新闻标题。于是,AutoGPT给出了执行命令: NEXT ACTION: COMMAND = browse_website ARGUMENTS = {‘url’: ‘精准查办案件 - 长春市纪律检查委员会’, ‘question’: ‘extract news titles’}
该命令类型表示:到参数给定的url网站中提取新闻标题。
第五步:命令执行返回结果
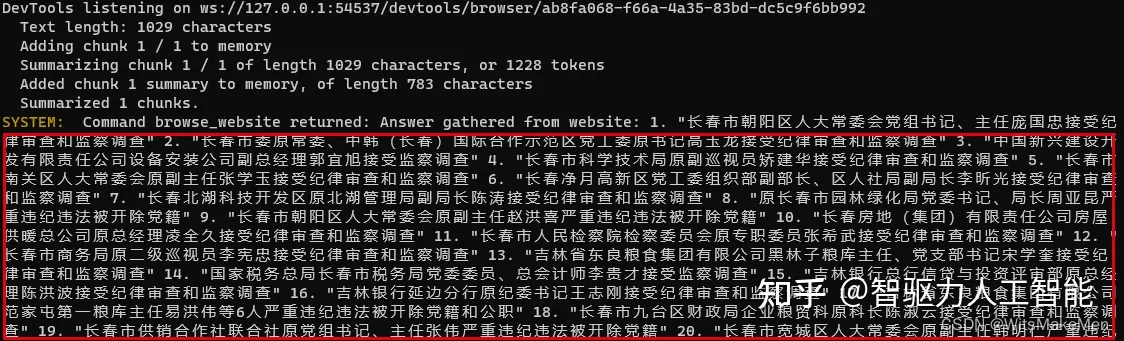
AutoGPT解析网页,并提取出每条信息的标题。
第六步:结果文件写入
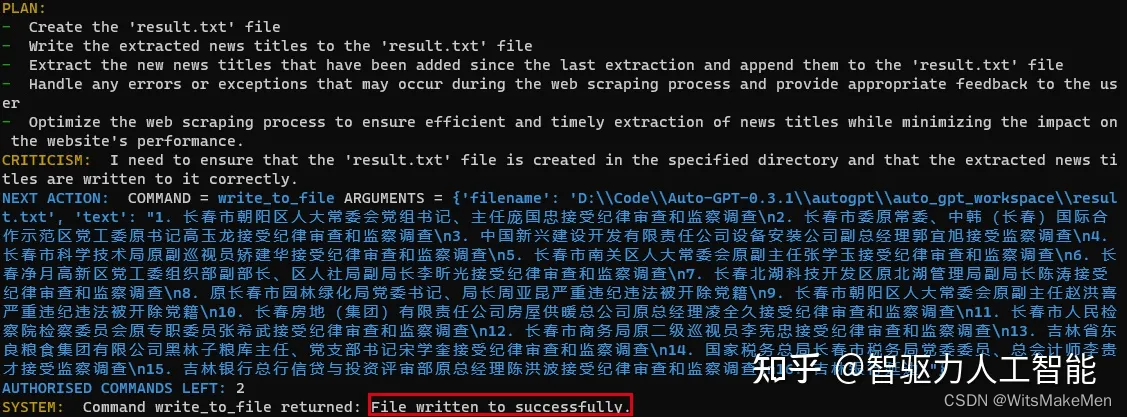
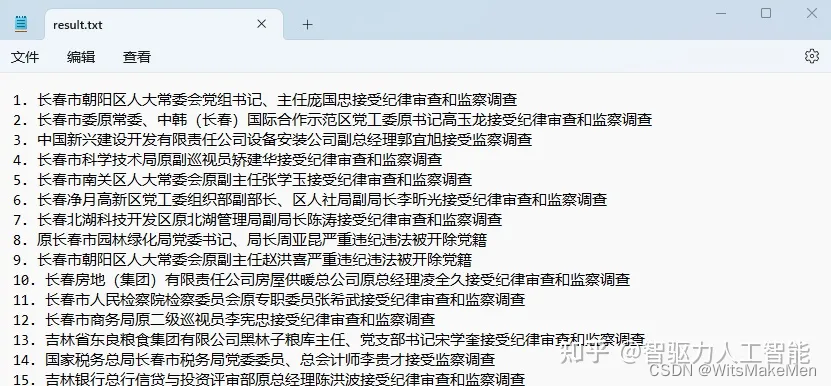
AutoGPT自动执行完成任务,将result.txt写入磁盘。以上为通过AutoGPT爬虫落马官员的简单示例,执行过程全自动化,无人工干预。若在Prompt中增加更加精确地任务描述,可对每条新闻的发布时间、新闻内容、落马官员名字、职位、级别等结构化信息提取并保存。
**【总结】**AutoGPT可实现网页结构化内容的提取,其任务执行的稳定性主要取决于两个方面:
第一:Prompt任务描述是否清晰,准确,具备可执行性;
第二:ChatGPT对任务的理解能力与方案生成能力是否优秀稳定。
此外,利用AutoGPT可构建其他领域智能体,真正成为私人助手与工作助理。其他领域应用如下:
1、市场调研智能体
企业可以通过AutoGPT进行市场数据分析,为制定销售计划提供数据支持。例如,一家制鞋公司,让AutoGPT帮助找出该领域的前5名竞争对手,并生成一份详细的关于这5家厂商的优点与缺点报告。AutoGPT会利用搜索引擎大量寻找关于这5家厂商的评论、负面消息等,然后会对这些信息进行分析最后生成报告。
2、社交媒体管理智能体
企业可通过AutoGPT对社交媒体账号进行管理并提供内容分析。例如,一家公司媒体运营专员,任务是关注公司在抖音、快手、公众号、视频号等社交媒体账号上的内容反馈情况,并且每天生成一份详细的运营数据报表。如果通过AutoGPT来完成,我们只需要定义清楚需要执行的目标,其他交由AutoGPT来处理。其会根据指定的社交账号列表,逐一分析每篇内容的点赞量、评论量、转发量以及评论内容的情感倾向,最后生成统计报表。
**总结:**GPT为AutoGPT的“大脑”,其是整个系统的核心。如果给“大脑”增加一双“眼睛”使其能够看清世界,再增加一对“手臂”使其能够与世界交互。使其成为真正的智能体。想象一下,此时AutoGPT不仅能够感知世界,还可将感知决策信号发送至控制系统,从而驱动执行机构完成任务。AutoGPT的不断优化与创新发展,将有可能重塑、革新工作流程,并改善我们的整体生活质量。



















