Java基础教程之集合体系 · 上
- 🔹本章学习目标
- 1️⃣ 类集框架介绍
- 2️⃣ 单列集合顶层接口:Collection
- 3️⃣ List 子接口
- 3.1 ArrayList 类
- 🔍 数组(Array)与列表(ArrayList)有什么区别?
- 3.2 LinkedList 类
- 3.3 Vector 类
- 3.4 Stack 类
- 3.5 List 各子类间的区别及联系
- 4️⃣ Set 子接口
- 4.1 关于数据排序的说明
- 4.2 关于重复元素的说明
- 5️⃣ 取出集合元素
- 5.1 迭代输出:Iterator
- 5.2 双向迭代:Listlterator
- 5.3 foreach 输出
- 5.4 Enumeration 输出
- 🌾 总结
- 🍉🍉 送书活动

🔹本章学习目标
- 掌握 Java 设置类集的主要目的以及核心接口的使用;
- 掌握 Collection 接口的作用及主要操作方法;
- 掌握 Collection 子接口 List、Set 的区别及常用子类的使用;
- 掌握 Map 接口的定义及使用;
- 掌握集合的4种输出操作语法结构;
- 掌握 Properties类的使用;
- 了解类集工具类 Collections 的作用;
1️⃣ 类集框架介绍
在实际的开发中几乎所有项目都会使用到数据结构(核心意义在于解决数组的固定长度限制问题),所以为了开发者的使用方便, JDK1.0 提供了 Vector、Hashtable、Enumeration 等常见的数据结构实现类。而从 JDK1.2 开始, Java 又进一步完善了自己的可用数据结构操作,提出了完整的类集框架的概念。下面将为大家讲解在类集框架之中较为常见的接口与类的使用。
在实际的项目开发中, 一定会出现保存多个对象的操作,根据之前学习的知识来讲,此时会使用对象数组的概念。但是传统的对象数组有一个问题:长度是固定的。因为此缺陷,所以数组一般不会使用,而为了可以动态地实现多个对象的保存,可以利用链表来实现一个动态的对象数组,但是对于链表的数据结构编写会存在以下一些问题。
- 由于需要处理大量的引用关系,如果要开发链表工具类,对初学者而言难度较高;
- 为了保证链表在实际的开发中可用,在编写链表实现时必须更多地考虑到性能问题;
- 链表为了可以保存任意对象类型,统一使用了
Object类型进行保存。那么所有要保存的对象必会发生向上转型,而在进行对象信息取出时又必须强制性地向下转型操作。如果在一个链表中所保存的数据不是某种类型,这样的操作会带来安全隐患。
综上,可以得出一个结论:如果在开发项目里面由开发者自己去实现一个链表,那么不仅加大了项目的开发难度并且没必要。因为在所有的项目里面都会存在数据结构的应用,在 Java 设计之初就考虑到了此类问题,所以提供了一个与链表类似的工具类——Vector (向量类)。但是随着时间的推移,这个类并不能很好地描述出所需要的数据结构,所以 Java 2(JDK1.2 之后) 提供了一个专门实现数据结构的开发框架——类集框架 (所有的程序接口与类都保存在 java.util 包中)。在JDK 1.5之后,泛型技术的引入,又解决了类集框架中,所有的操作类型都使用 Object 所带来的安全隐患。而 JDK1.8又针对类集的大数据操作环境推出了数据流的分析操作功能 (MapReduce 操作)。
类集在整个Java 中最为核心的用处就在于其实现了动态对象数组的操作,并且定义了大量的操作标准。在整个类集框架中,其核心接口为: Collection、List、Set、Map、Iterator、Enumeration等。
2️⃣ 单列集合顶层接口:Collection
java.util.Collection 是进行单对象保存的最大父接口,即每次利用 Collection 接口都只能保存一个对象信息。单对象保存顶层接口定义如下。
public interface Collection<E> extends Iterable<E>
通过定义可以发现 Collection 接口中使用了泛型,这样可以保证集合中操作数据类型的统一,同时 Collection 接口属于 Iterable 的子接口。
随着Java 版本的不断提升,Collection接口经历从无到有的使用以及定义结构的不断加强,需要对 Collection 接口的发展进行以下几点说明。
Collection接口是从JDK 1.2开始定义的,最初所有的操作数据都会使用Object进行接收,这样就会存在向下转型的安全隐患;- JDK 1.5之后为了解决
Object所带来的安全隐患,使用泛型重新定义了Collection接口,同时为了进一步定义迭代操作的标准,增加了Iterable接口(JDK 1.5时增加),使得Collection接口又多了一个父接口; - JDK 1.8之后引入了
static与default定义接口方法的定义,所以在Collection接口中的方法又得到了进一步扩充(主要是为了进行数据流操作)。
在 Collection接口里面定义了9个常用操作方法,如下表所示。
| 方法名称 | 类型 | 描述 |
|---|---|---|
public boolean add(E e) | 普通 | 向集合里面保存数据 |
public boolean addAll(Collection<? extends E> c) | 普通 | 追加一个集合 |
public void clear() | 普通 | 清空集合,根元素为null |
public boolean contains(Object o) | 普通 | 判断是否包含指定的内容,需要 equals()支持 |
public boolean isEmpty() | 普通 | 判断是否是空集合(不是null) |
public boolean remove(Object o) | 普通 | 删除对象,需要equals()支持 |
public int size() | 普通 | 取得集合中保存的元素个数 |
public Object[] toArray() | 普通 | 将集合变为对象数组保存 |
public Iterator<E> iterator() | 普通 | 为Iterator接口实例化(Iterable接口定义) |
对于上表所列出的方法,大家应该要记住 add()与 iterator() 两个方法,因为这两个方法几乎所有的项目都会使用到,同时在进行 contains() 与 remove() 两个方法的操作时,必须保证类中已经成功地覆写了 Object 类中的equals() 方法,否则将无法正常完成操作。
虽然 Collection 是单对象集合操作的顶层父接口,但是 Collection 接口本身却存在一个问题:无法区分保存的数据是否重复。所以在实际的开发中,往往会使用 Collection 的两个子接口: List 子接口 (数据允许重复)、 Set 子接口(数据不允许重复),继承关系如下所示。
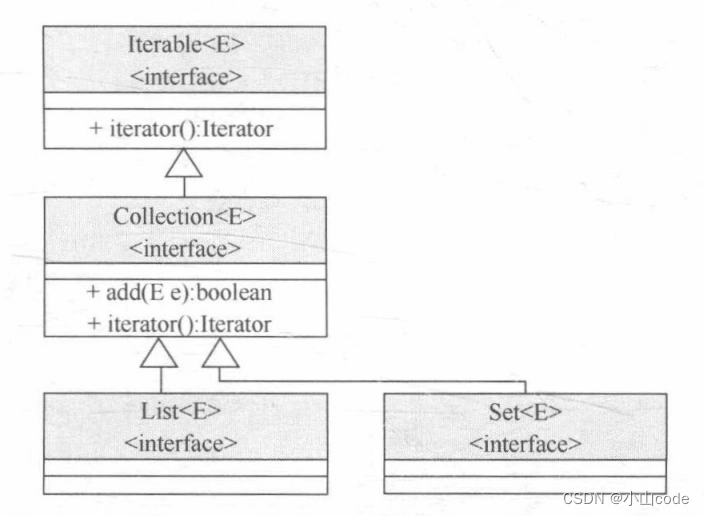
3️⃣ List 子接口
List 子接口最大的功能是里面所保存的数据可以存在重复内容,并且在 Collection 的子接口中,List 子接口是最为常用的一个子接口,在 List 接口中对 Collection 接口的功能进行了扩充。 List子接口扩充的方法如下所示。
| 方法名称 | 类型 | 描述 |
|---|---|---|
public E get(int index) | 普通 | 取得索引编号的内容 |
public E set(int index, E element) | 普通 | 修改指定索引编号的内容 |
public ListIterator<E> listIterator() | 普通 | 为ListIterator接口实例化 |
在使用 List 接口时主要使用 ArrayList 或 LinkedList 两个子类来进行接口对象的实例化操作。List 接口的继承体系如下所示,接下来我们会一一介绍ArrayList 类、 LinkedList 类、Vector类、Stack类。
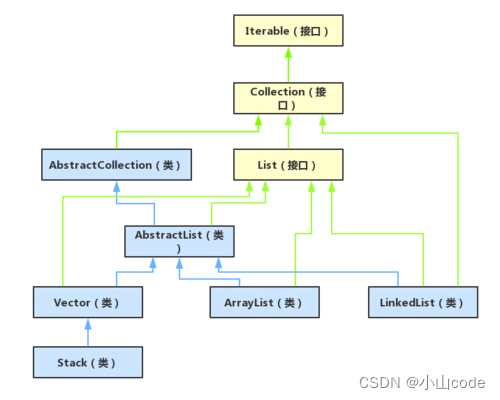
3.1 ArrayList 类
ArrayList 子类是 List子接口中最为常用的一个子类,下面通过 ArrayList 类来实现 List 接口的操作。
// 范例 1: List 基本操作
package com.xiaoshan.demo;
import java.util.ArrayList;
import java.util.List;public class TestDemo {public static void main(String[] args){//从JDK1.5 开始应用了泛型,从而保证集合中所有的数据类型都一致List<String> all = new ArrayList<String>(); // 实例化 List 集合System.out.println("长度:"+ all.size() +",是否为空:"+ all.isEmpty());all.add("Hello"); //保存数据all.add("Hello"); //保存重复元素all.add("World"); //保存数据System.out.println("长度:"+ alL.size() +",是否为空:"+ all.isEmpty());// Collection 接口定义size()方法取得了集合长度, List子接口扩充get()方法根据索引取得了数据 for (int x=0; x<all.size();x++){String str = all.get(x); //取得索引数据System.out.println(str); //直接输出内容}}
}
程序执行结果:
长度:0,是否为空:true
长度:3,是否为空:false
Hello
Hello
World
此程序通过 ArrayList 子类实例化了 List 接口对象,这样就可以使用 List 接口中定义的方法 (包括 Collection 接口定义的方法),由于List 接口相对于 Collection 接口中扩充了 get()方法,所以可以利用循环的方式依次取出集合中的每一个保存数据。
🔍 数组(Array)与列表(ArrayList)有什么区别?
数组(
Array)中保存的内容是固定的,而列表(ArrayList)中保存的内容是可变的。在很多时候,列表(ArrayList) 进行数据保存与取得时需要一系列的判断,而如果是数组(Array) 只需要操作索引即可。
如果在已经确定好长度的前提下,完全可以使用数组(Array)来替代数组列表 (ArrayList),但是如果集合保存数据的内容长度是不固定的,那么就使用ArrayList。
另外,在许多开发框架中会将数组与List集合作为同一种形式。例如,在Mybatis框架中的参数及结果映射中,如果是数组或者是List集合,其最终的结果是完全相同的。关于这一点大家可以随着技术的深入而有更深的体会。
ArrayList 是List接口的子类,所以也就是 Collection接口的子类,这样就可以利用 ArrayList 为 Collection 接口实例化(大部分情况下这样的操作不会出现),但是如果直接使用 Collection接口对象将不具备 get()方法,只能将全部集合转化为对象数组后才可以使用循环进行输出。
// 范例 2: Collection接口实例化操作
package com.xiaoshan.demo;
import java.util.ArrayList;
import java.util.Collection;public class TestDemo {public static void main(String[] args){Collection<String> all = new ArrayList<String>();all.add("Hello"); //保存数据all.add("Hello"); //重复元素all.add("World"); //保存数据//Collection不具备List接口的get()方法,所以必须将其转化为对象数组Object obj[] = all.toArray(): //变为对象数组for (int x=0; x<obj.length; x++){ //采用循环输出String str = (String) obj[x]; //强制向下转型System.out.println(str); //输出数据}}
}
程序执行结果:
Hello
Hello
World
可以发现,Collection与 List接口的最大区别在于,List 提供了get() 方 法,这样就可以根据索引取得内容,在实际的开发中,此方法使用较多。但是需要提醒大家的是,范例2的输出操作并不是集合的标准输出操作,具体的输出操作在下文讲解。
范例2的操作是在集合中保存了String 类的对象,然而对于集合的操作,也可以保存自定义对象。而如果要正确地操作集合中的 remove() 或 contains() 方法,则必须保证自定义类中明确地覆写了 equals() 方法。
// 范例 3: 在集合里面保存对象
package com.xiaoshan.demo;
import java util.ArrayList;
import java.util.List;class Book { //创建一个自定义类private String title;private double price;public Book(String title, double price){this.title = title;this.price = price;}@Overridepublic boolean equals(Object obj){ //必须覆写此方法,否则remove()、contains()无法使用if (this == obj){return true;}if (obj == null){return false;}if (!(obj instanceof Book)){return false;}Book book =(Book) obj;if (this.title.equals(book.title) && this.price == book.price){return true;}return false;}@Overridepublic String toString(){return "书名:"+this.title+",价格:"+this.price+"\n";}
}public class TestDemo {public static void main(String[] args){List<Book> all = new ArrayList<Book>();all.add(new Book("Java开发入门教程", 129.9)); //保存自定义类对象all.add(new Book("Java开发实战经典", 69.8)); all.add(new Book("Oracle开发实战经典", 89.8));all.remove(new Book("Oracle开发实战经典", 89.8)); //需要使用equals()方法System.out.println(all);}
}
程序执行结果:
[书名:Java开发入门教程,价格:129.9,
书名:Java开发实战经典,价格:69.8]
此程序实现了自定义类对象的保存,由于设置的泛型限制,所以在集合保存数据操作中只允许保存 Book 类对象,同时为了可以使用集合中的 remove() 方法 , 在 Book 类中必须明确覆写 equals() 方法。
3.2 LinkedList 类
在List子接口中还存在一个LinkedList子类,而使用时大部分情况下都是利用子类为父接口实例化。ArrayList和LinkedList的主要区别如下:
ArrayList中采用顺序式的结果进行数据的保存,并且可以自动生成相应的索引信息;LinkedList集合保存的是前后元素,也就是说,它每一个节点中保存的是两个元素对象, 一个它对应的下一个节点,以及另外一个它对应的上一个节点,所以LinkedList要占用比ArrayList更多的内存空间。同时LinkedList比ArrayList多实现 了一个Queue队列数据接口。
// 范例 4: 观察 LinkedList 的使用
public class TestDemo {public static void main(String[] args) {// 创建一个LinkedList对象LinkedList<Book> books = new LinkedList<>();// 添加元素到列表的末尾books.add(new Book("Java开发入门教程", 129.9)); //保存自定义类对象books.add(new Book("Java开发实战经典", 69.8));books.add(new Book("Oracle开发实战经典", 89.8));// 在列表指定位置插入元素books.add(1, new Book("Oracle从入门到放弃", 328.8));// 获取列表中的第一个元素Book firstBook = books.getFirst();// 移除列表中的最后一个元素Book lastBook = books.removeLast();// 遍历LinkedList并打印所有元素System.out.println("LinkedList元素:" + books);// 打印首个和最后一个元素System.out.println("首个元素: " + firstBook);System.out.println("最后一个元素: " + lastBook);}
}
程序执行结果:
LinkedList元素:[书名:Java开发入门教程,价格:129.9
, 书名:Oracle从入门到放弃,价格:328.8
, 书名:Java开发实战经典,价格:69.8
]
首个元素: 书名:Java开发入门教程,价格:129.9最后一个元素: 书名:Oracle开发实战经典,价格:89.8在上边代码中,我们首先创建了一个LinkedList<Book>类型的对象,然后使用add()方法向列表添加元素。还通过指定索引位置使用add()方法将元素插入列表中。接下来使用getFirst()方法获取列表中的第一个元素,使用removeLast()方法从列表中移除最后一个元素。
最后打印出每个元素,首个及最后一个元素。从输出结果中可以看出,我们成功地创建了一个含有几个元素的LinkedList,并且能够插入、移除和遍历它们。
3.3 Vector 类
在 JDK 1.0 时就已经提供了Vector 类(当时称为向量类),同时由于其提供的较早,这个类被大量使用。但是到了 JDK 1.2时由于类集框架的引入,对于整个集合的操作就有了新的标准,为了可以继续保留 Vector 类,就让这个类多实现了一 个List 接口 。
// 范例 5: 使用Vector
package com.xiaoshan.demo;
import java.util.List;
import java.util.Vector;public class TestDemo{public static void main(String[] args){//由于都是利用子类为父类实例化,所以不管使用哪个子类, List接口功能不变List<String> all = new Vector<String>(); //实例化 List集合System.out.println("长度:"+ all.size()+", 是否为空:"+ all.isEmpty());all.add("Hello"); //保存数据all.add("Hello"); //保存重复元素all.add("World");System.out.println("长度:"+ all.size()+", 是否为空:"+ all.isEmpty()); // Collection接口定义了size()方法取得集合长度, List子接口扩充了get()方法,根据索引取得数据for (int x=0; x<all.size(); x++){String str = all.get(x); //取得索引数据 System.out.println(str); //直接输出内容}}
}
程序执行结果:
长度:0,是否为空:true
长度:3,是否为空:false
Hello
Hello
World
此程序只是将 ArrayList 子类替换为 Vector 子类,由于最终都是利用子类实例化 List 接口对象, 所以最终的操作结果并没有区别,而两个操作子类最大的区别在于 Vector 类中的部分方法使用 synchronized 关键字声明,也就是说类中操作都是同步操作。
3.4 Stack 类
Stack 类表示栈,栈也是一种动态对象数组,采用的是一种先进后出的数据结构形式,即在栈中最早保存的数据最后才会取出,而最后保存的数据可以最先取出,如下所示。
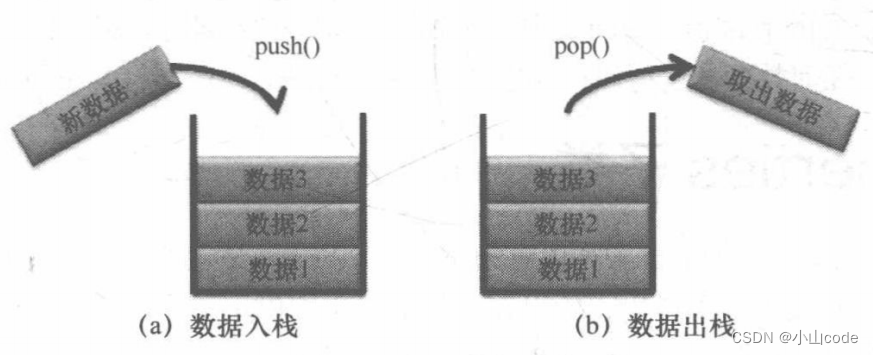
在 java.util 包中可以利用 Stack 类实现栈的功能,此类定义如下。
public class Stack<E> extends Vector<E>
通过定义可以发现, Stack 类属于 Vector 子类,但是需要注意的是,在进行 Stack 类操作时不会使用 Vector 类定义的方法,主要使用 Stack 自己定义的方法。 Stack 类的常用方法如下所示。
| 方法 | 类型 | 描述 |
|---|---|---|
public E push(E item) | 普通 | 数据入栈 |
public E pop() | 普通 | 数据出栈,如果栈中没有数据,则调用此方法会抛出空栈异常(EmptyStackException) |
// 范例 6: 观察栈的操作
package com.xiaoshan.demo;
import java.util.Stack;public class TestDemo {public static void main(String[] args){Stack<String> all = new Stack<String>();all.push("www.baidu.com");all.push("www.xiaoshan.com");all.push("www.ccc.cn");System.out.println(all.pop());System.out.println(all.pop());System.out.println(all.pop());System.out println(all.pop()); // EmptyStackException}
}
程序执行结果:
www.ccc.cn
www.xiaoshan.com
www.baidu.com
Exception in thread"main"java.util.EmptyStackExceptionat java.util.Stack.peek(Unknown Source)at java.util.Stack.pop(Unknown Source)at com.xiaoshan.demo.TestDemo.main(TestDemo.java:14)
程序利用 Stack 类的 push() 方法向栈中保存数据,而取得数据时只需要利用 pop()方法即可实现出栈操作,如果栈中没有任何数据,进行出栈操作时则将抛出 “EmptyStackException” 异常。
3.5 List 各子类间的区别及联系
- ArrayList:
ArrayList是基于数组实现的动态数组,它可以根据需要自动调整大小。它提供了快速的随机访问和高效的插入/删除操作。ArrayList允许存储重复元素,并且继承了AbstractList抽象类; - LinkedList:
LinkedList是基于双向链表实现的列表。它仅保留到前后节点的引用,在插入/删除操作时具有更好的性能。与ArrayList相比,LinkedList适用于频繁的插入/删除操作,但对于随机访问较慢,它也允许存储重复元素; - Vector:
Vector是一个线程安全的列表实现,与ArrayList类似,但它的所有方法都是同步的。它提供了与ArrayList相似的功能,不过由于同步的开销,通常比ArrayList的性能稍差。由于Java 2的引入,推荐使用ArrayList而不是Vector; - Stack:
Stack是一个基于后进先出(LIFO)原则的列表,它继承自Vector类。它提供了常规的栈操作,如push(将元素推入栈顶)、pop(将元素弹出栈顶)和peek(查看栈顶元素)。
这些类都位于Java集合框架(Java Collections Framework)中,通过它们可以方便地对列表进行操作。每个类都有其自己的特性和适用场景,根据实际需求选择适当的类是很重要的。
4️⃣ Set 子接口
在 Collection 接口下又有另外一个比较常用的子接口为 Set 子接口,但是 Set 子接口并不像 List 子接口那样对 Collection 接口进行了大量的扩充,而是简单地继承了接口。也就是说在Set 子接口里面无法使用 get()方法根据索引取得保存数据的操作。在Set 子接口下有两个常用的子类: HashSet、TreeSet。
HashSet是散列存放数据,而TreeSet是有序存放的子类。在实际的开发中,如果要使用TreeSet子类则必须同时使用比较器的概念,而 HashSet子类相对于TreeSet子类更加容易一些,所以如果没有排序要求应优先考虑 HashSet子类。
// 范例 7: 观察 HashSet 子类的特点
package com.xiaoshan.demo;
import java.util.HashSet;
import java.util.Set;public class TestDemo{public static void main(String[] args){Set<String> all = new HashSet<String>(); //实例化Set接口all.add("abcdefg"); //保存数据all.add("小山")all.add("HELLO")all.add("小山"); //重复数据System.out.println(all); //直接输出集合}
}
程序执行结果:
[abcdefg, 小山, HELLO]
此程序利用 HashSet 子类实例化了Set 接口对象,并且在Set 集合中不允许保存重复数据。
程序使用的是HashSet子类,并且根据名称可以发现,在这个子类上采用了 Hash算法(也称为散列、无序)。这种算法就是利用二进制的计算结果来设置保存的空间,根据数值的不同,最终保存空间的位置也不同,所以利用Hash算法保存的集合都是无序的,但是其查找速度较快。
而如果希望保存的数据有序,那么可以使用 Set 接口的另外一个子类: TreeSet 子类。
// 范例 8: 使用TreeSet 子类
package com.xiaoshan.demo;
import java.util.Set;
import java.util.TreeSet;public class TestDemo {public static void main(String[] args){Set<String> all = new TreeSet<String>(); // 实例化Set接口all.add("abcdefg"); //保存数据all.add("小山");all.add("HELLO");all.add("小山"); //重复数据System.out.println(all); //直接输出集合}
}
程序执行结果:
[HELLO, abcdefg, 小山]
TreeSet 子类属于排序的类集结构,所以当使用 TreeSet 子类实例化 Set 接口后,所保存的数据将会变为有序数据,默认情况下按照字母的升序排列。
4.1 关于数据排序的说明
TreeSet 子类保存的内容可以进行排序,但是其排序是依靠比较器接口(Comparable) 实现的,即如果要利用TreeSet 子类保存任意类的对象,并且按照自定义顺序对对象排序,那么该对象所在的类必须要实现 java.lang.Comparable接口。
在前面的讲解常用类库时的文章中,曾经讲解过比较器的使用,现在在TreeSet子类中,由于其不允许保存重复元素 (compareTo() 方法的比较结果返回0),如果说此时类中存在5个属性,但是只比较了3个属性,并且这3个属性的内容完全相同 (其余两个属性不同),那么TreeSet 也会认为是相同内容,从而不会保存该数据,因此会出现数据丢失的情况。
// 范例 9: 利用TreeSet 保存自定义类对象
package com.xiaoshan.demo;
import java.util.Set;
import java.util.TreeSet;class Book implements Comparable<Book>{ //需要实现Comparable 接口private String title;private double price;public Book(String title, double price){this.title = title;this.price = price;}@Overridepublic String toString(){return " 书名:"+this.title+",价格:"+this.price+"\n";}@Overridepublic int compareTo(Book o){ //排序方法,比较所有属性if (this.price > o.price){return 1;}else if(this.price < o.price){return -1;}else{return this.title.compareTo(o.title); //调用String类的比较大小}}
}public class TestDemo{public static void main(String[] args){Set<Book> all = new TreeSet<Book>(); // 实例化Set接口all.add(new Book("Java开发实战宝典",79.8)); //保存数据all.add(new Book("Java开发实战宝典",79.8)); //全部信息重复all.add(new Book("JSP开发实战宝典",79.8)); //价格信息重复all.add(new Book("Android开发实战宝典",89.8)); //都不重复System.out.println(all); }
}
程序执行结果:
[书名:JSP开发实战宝典,价格:79.8,
书名:Java开发实战宝典,价格:79.8,
书名:Android开发实战宝典,价格:89.8]
此程序首先利用 TreeSet 子类保存了几个 Book 类对象,由于 Book 类实现了 Comaprable 接口,所以会自动将所有保存的 Book 类对象强制转换为 Comparable 接口对象,然后调用 compareTo() 方法进行排序,如果发现比较结果为0则认为是重复元素,将不再进行保存。因此 TreeSet 数据的排序以及重复元素的消除依靠的都是 Comparable 接口。
4.2 关于重复元素的说明
TreeSet 利用 Comparable 接口实现重复元素的判断,但是这样的操作只适合支持排序类集操作环境下;而其他子类(例如: HashSet) 如果要消除重复元素,则必须依靠 Object 类中提供的两个方法。
- 取得哈希码:
public int hashCode(); - 对象比较:
public boolean equals(Object obj)。
依靠着两个方法,先通过第一个方法判断对象的哈希码是否相同,若不同则说明一定不是同一个对象,则相同则继续比较,通过第二个方法再将对象的属性进行依次的比较。
对于 hashCode()与 equals()两个方法的使用可以换个角度来看。例如:如果要核查一个人的信息,肯定先要通过身份证编号查找到这个编号的信息(hashCode()方法负责编号), 再利用此身份证信息与个人信息进行比较(equals()进行属性的比较) 后才可以确定结果。
// 范例 10: 利用HashSet子类保存自定义类对象
package com.xiaoshan.demo;
import java.util.Set;
import java.util.HashSet;class Book{private String title;private double price;public Book(String title, double price){this.title = title;this.price = price;}@Overridepublic int hashCode(){final int prime = 31;int result = 1;long temp;temp = Double.doubleToLongBits(price);result = prime* result +(int)(temp^(temp>>>32));result = prime* result +((title == null) ? 0 : title.hashCode());return result;}@Overridepublic boolean equals(Object obj){if (this == obj){return true;}if (obj == null){return false;}if (getClass() != obj.getClass()){return false;}Book other =(Book) obj;if (Double.doubleToLongBits(price) != Double.doubleToLongBits(other.price)){return false;}if (title == null){if (other.title != null){return false;}else if(!title.equals(other.title)){return false;}return true;}}@Overridepublic String toString(){return "书名:"+this.title+",价格:"+ this.price+"\n";}
}public class TestDemo{public static void main(String[] args){Set<Book> all = new HashSet<Book>(); //实例化Set接口all.add(new Book("Java开发实战经典",79.8)); //保存数据all.add(new Book("Java开发实战经典",79.8)); //全部信息重复all.add(new Book("JSP开发实战经典",79.8)); //价格信息重复all.add(new Book("Android开发实战经典",89.8)); //都不重复System.out.println(all);}
}
程序执行结果:
[书名:Android开发实战经典,价格:89.8,
书名:JSP开发实战经典,价格:79.8,
书名:Java开发实战经典,价格:79.8]
此程序实现了集合中重复元素的清除,利用的就是 hashCode() 与 equals() 两个方法,所以在进行非排序集合操作时,只要是判断重复元素依靠的永远都是 hashCode() 与 equals()。
5️⃣ 取出集合元素
由于集合中往往会保存多个对象数据,所以一般进行集合输出时都会采用循环的方式完成。而在 Java 中,集合的输出操作有4种形式: Iterator 输出、 ListIterator 输出、 foreach (加强for 循环 ) 输出、 Enumeration 输出。
5.1 迭代输出:Iterator
Iterator (迭代器)是集合输出操作中最为常用的接口,而在 Collection 接口中也提供了直接为 Iterator 接口实例化的方法 iterator(), 所以任何集合类型都可以转换为 Iterator接口输出。
在JDK1.5之前,Collection 接口会直接提供 iterator() 方法,但是到了JDK1.5之后,为了可以让更多的操作支持Iterator 迭代输出,单独建立了 Iterable 接口,同时在这个接口里只定义了一个 iterator() 的抽象方法。所谓迭代器就好比排队点名一样,从前向后开始,一边判断是否有人,一边进行操作。
在 Iterator 接口中一共定义了两个抽象方法,如下所示。
| 方法 | 类型 | 描述 |
|---|---|---|
public boolean hasNext() | 普通 | 判断是否还有内容 |
public E next() | 普通 | 取出当前内容 |
当使用 Iterator接口输出时,往往都先利用 hasNext() 改变指针位置,同时判断是否有数据,如果当前指针所在位置存在数据,则利用 next() 取出数据,这两个方法的作用如下所示。
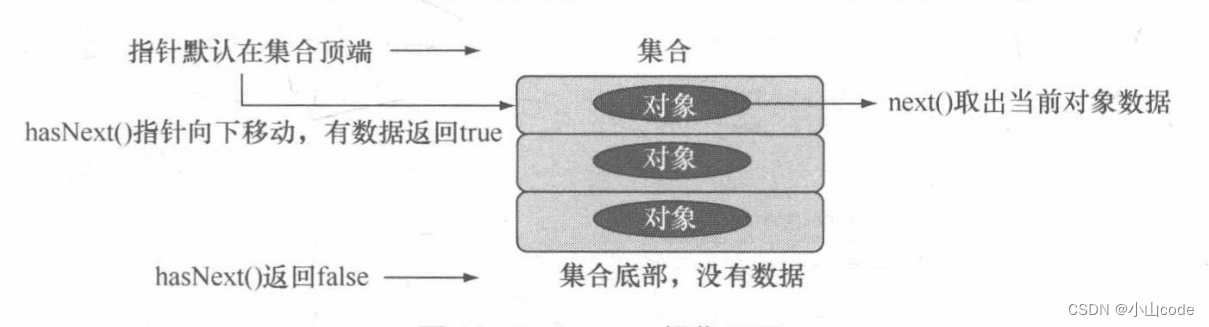
在前面讲解 IO操作的文章中,曾经讲解过一个 java.util.Scanner 的类,实际上 Scanner 就是 Iterator 接口的子类,所以在Scanner使用时才要求先利用 hasNextXxx() 判断是否有数据,再利用 nextXxx()取得数据。
// 范例 11: 使用 Iterator 输出集合
package com.xiaoshan.demo;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class TestDemo {public static void main(String[] args){List<String> all = new ArrayList<String>(); //实例化List集合all.add("Hello"); //保存数据all.add("Hello");all.add("World");Iterator<String> iterator= all.iterator(); //实例化Iterator接口while (iterator.hasNext()){ //判断是否有数据String str = iter.next(); //取出当前数据System.out.println(str); //输出数据}}
}
程序执行结果:
Hello
Hello
World
此程序利用 List 接口的 iterator()方法 (Collection 接口继承而来) 将全部集合转变为 Iterator 输出,由于不确定循环次数,所以使用 while循环进行迭代输出。
在Iterator接口定义了一个删除数据的操作方法,但是对不同的版本,此方法也存在以下两种定义。
- JDK 1.8以前:
public void remove(); - JDK 1.8之后:
default void remove()。
在JDK 1.8之前 remove()属于一个普通的删除方法,而JDK 1.8之后将其定义为一个接口的 default方法。而之所以提供这个方法,是因为在使用 Iterator输出数据时,如果利用集合类 (Collection、List、Set) 提供的 remove()方法会导致程序中断执行的问题,而如果非要进行集合元素的删除,只能利用 Iterator 接口提供的 remove()方法才可以正常完成。
// 范例 12: 观察删除问题
package com.xiaoshan.demo;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;public class TestDemo{public static void main(String[] args){List<String> all=new ArrayList<String>(); //实例化List集合all.add("Hello"); //保存数据all.add("java");all.add("World");all.add("xiaoshan");Iterator<String> iterator= all.iterator(); //实例化Iterator接口while (iterator.hasNext()){String str = iter.next(); //取出当前数据if ("java".equals(str)){all.remove(str); //此代码一执行,输出将中断}System.out.println(str);//输出数据}}
}
程序执行结果:
Hello
java
Exception in thread"main" java.util.ConcurrentModificationException
程序并没有完成正常输出,这是因为在迭代输出时进行了集合数据的错误删除操作,而要避免此类问题,只能利用Iterator接口提供的 remove() 方法。但是需要注意的是,从实际的开发来讲,集合输出中几乎不会出现删除数据的操作,所以对此概念了解即可。
同时也希望大家要记住,在集合的操作中,增加数据(add())以及迭代输出操作是较为核心的部分,对于此操作模式一定要熟练掌握。
5.2 双向迭代:Listlterator
虽然利用Iterator 接口可以实现集合的迭代输出操作,但是 Iterator 本身却存在一个问题:只能进行由前向后的输出。所以为了让输出变得更加灵活,在类集框架中就提供了一个 ListIterator 接口,利用此接口可以实现双向迭代。 Listlterator 属于Iterator 的子接口,此接口常用方法如下所示。
| 方法 | 类型 | 描述 |
|---|---|---|
public boolean hasPrevious() | 普通 | 判断是否有前一个元素 |
public E previous() | 普通 | 取出前一个元素 |
public void add(E e) | 普通 | 向集合追加数据 |
public void set(E e) | 普通 | 修改集合数据 |
在ListIterator 接口中除了可以继续使用 Iterator 接口的 hasNext()与 next()方法,也具备了向前迭代的操作(hasPrevious()、previous()), 同时还提供了向集合追加数据和修改数据的支持。
从实际的开发来讲,绝大多数情况如果要进行集合的输出都会使用Iterator接口,相较而言ListIterator接口在实际使用中并不常见。同时通过ListIterator接口的定义可以发现,该接口除了支持输出之外,还可以进行集合更新 (增加、修改、删除), 但是这些操作在实际开发中使用得非常有限。
Listlterator 是专门为 List 子接口定义的输出接口,所以 ListIterator 接口对象的实例化可以依靠 List 接口提供的方法:
public ListIterator<E> listIterator()
实际上迭代器本质上就是一个指针的移动操作,而 ListIterator与 Iterator的迭代处理原理类似。所以如果要进行由后向前迭代,必须先进行由前向后迭代。
// 范例 13: 完成双向迭代
package com.xiaoshan.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.Listlterator;public class TestDemo {public static void main(String[] args){List<String> all = new ArrayList<String>(); //实例化List接口对象 all.add("www.xiaoshan.com"); //向集合保存数据all.add("www.baidu.com");all.add("www.csdn.cn");System.out.print("由前向后输出:"); ListIterator<String> iterator = all.listIterator(); //实例化Listlterator接口while (iterator.hasNext()){ //由前向后迭代String str = iter.next(); //取出当前数据System.out.print(str + " 、");//输出数据}System.out.print("\n由后向前输出:");while(iter.hasPrevious()){ //由后向前迭代 String str = iter.previous(); //取出当前数据System.out.print(str+" 、"); //输出数据}}
}
程序执行结果:
由前向后输出:www.xiaoshan.com、www.baidu.com、www.csdn.cn、
由后向前输出:www.csdn.cn、www.baidu.com、www.xiaoshan.com、
程序利用 ListIterator 接口实现了List 集合的双向迭代输出,首先利用 hasNext()与 next()实现由前向后的数据迭代,然后使用 hasPrevious()与 previous()两个方法实现了数据的由后向前迭代。
5.3 foreach 输出
JDK 1.5之后为了简化数组以及集合的输出操作,专门提供了 foreach (增强型 for 循环)输出,所以也可以利用 foreach 语法实现所有集合数据的输出操作。
// 范例 14: 利用foreach 输出集合数据
package com.xiaoshan.demo;
import java.util.ArrayList;
import java.util.List;public class TestDemo{public static void main(String[] args){List<String> all =new ArrayList<String>();// 实例化List接口对象 all.add("www.baidu.com"); //向集合保存数据all.add("www.xiaoshan.com"); all.add("www.csdn.cn"); //集合中包含的数据都是String型,所以需要使用String接收集合中的每一个数据for (String str: all){ //for循环输出System.out.println(str);}}
}
程序执行结果:
www.baidu.com
www.xiaoshan.com
www.csdn.cn
此程序利用 foreach 循环实现了集合输出,由于集合中保存的都是 String 型数据,所以每次执行 foreach 循环时,都会将当前对象内容赋值给 str 对象,而后就可以在循环体中利用 str 对象进行操作。
5.4 Enumeration 输出
Enumeration (枚举输出) 是与 Vector 类一起在JDK 1.0 时推出的输出接口,即最早的 Vector 如果要输出数据,就需要使用 Enumeration 接口完成,此接口定义如下。
public interface Enumeration<E>{public boolean hasMoreElements(); // 判断是否有下一个元素,等同于hasNext()public E nextElement(); //取出当前元素,等同于next()
}
通过定义可以发现在 Enumeration 接口中一共定义了两个方法, hasMoreElements() 方法用于操作指针并且判断是否有数据,而 nextElement() 方法用于取得当前数据。
因为 Enuemration 出现较早,所以在 Collection 接口中并没有定义取得 Enumeration 接口对象的方法。 所以Enumeration 接口对象的取得只在 Vector 类中有所定义: public Enumeration<E> elements()。
// 范例 15: 利用 Enumeration 接口输出数据
package com.xiaoshan.demo;
import java.util.Enumeration;
import java.util.Vector;public class TestDemo{public static void main(String[] args){Vector<String> all= new Vector<String>(); //实例化Vector子类对象all.add("www.baidu.com"); //向集合保存数据all.add("www.xiaoshan.com");all.add("www.csdn.cn");Enumeration<String> enumeration = all.elements(); //取得Enumeration接口对象while(enumeration.hasMoreElements()){ //判断是否有数据String str = enumeration.nextElement(); //取出当前数据System.out.println(str); //输出数据}}
}
程序执行结果:
www.baidu.com
www.xiaoshan.com
www.csdn.cn
此程序与 Iterator 接口输出实现的最终效果是完全一致的,唯一的区别就是,如果要利用集合类为 Enuemration 接口实例化,就必须依靠 Vector 子类完成。
如果要进行类集的操作,大部分情况下都会使用 List或 Set子接口,很少会直接操作 Vector子类,所以对于Enumeration接口而言使用情况有限,大部分都以 Iterator输出为主。
🌾 总结
本文介绍了Java类集框架,重点关注了单列集合顶层接口Collection和其子接口List的特点和用法。我们比较了数组和列表(ArrayList)之间的区别,并深入探讨了List子类(ArrayList、LinkedList、Vector、Stack)之间的联系与区别。
在Set子接口部分,我们介绍了HashSet和TreeSet的区别,并解释了数据排序和处理重复元素的方法。
最后,我们讨论了取出集合元素的几种常见方式,包括迭代输出使用Iterator、双向迭代使用ListIterator、使用foreach循环以及使用Enumeration输出。
通过本文的学习,我们对类集框架有了全面的了解。了解不同的集合类型和它们的特点,可以根据实际需求选择最合适的集合。同时,熟练使用各种元素取出方法,可以方便地遍历和操作集合中的元素。
🍉🍉 送书活动
书籍介绍:
ISBN编号:9787302511052
书名:设计模式(第2版)(高等学校设计模式课程系列教材)
作者:刘伟、夏莉、于俊洋、黄辛迪
定价:79.80元
开本:16开
出版社名称:清华大学出版社
书籍图示:

书籍目录:
- 抽奖方式:满足条件的用户中随机抽取两名(程序抽取)~
- 参与方式:关注+点赞+收藏,评论区留言“打工真快乐,我爱上班,我学编程发自内心!” 每人最多评论三次!(截止到统计时,未关注、未收藏、未按格式正确评论的朋友将无法成功被程序统计到)
- 截止时间:2023/8/1 20:00:00
- 通知方式:私信 + 评论区@公布~
书籍目录:
第1章 统一建模语言基础知识
1.1 UML简介
1.1.1 UML的延生
1.1.2 UML的结构
1.1.3 UML的特点
1.2 类图
1.2.1 类与类图
1.2.2 类之间的关系
1.2.3 类图实例
1.3 顺序图
1.3.1 顺序图定义
1.3.2 顺序图组成元素与绘制
1.3.3 顺序图实例
1.4 状态图
1.4.1 状态图定义
1.4.2 状态图组成元素与绘制
1.4.3 状态图实例
1.5 本章小结
思考与练习
第2章 面向对象设计原则
2.1 面向对象设计原则概述
2.1.1 软件的可维护性和可复用性
2.1.2 面向对象设计原则简介
2.2 单一职责原则
2.2.1 单一职责原则定义
2.2.2 单一职责原则分析
2.2.3 单一职责原则实例
2.3 开闭原则
2.3.1 开闭原则定义
2.3.2 开闭原则分析
2.3.3 开闭原则实例
2.4 里氏代换原则
2.4.1 里氏代换原则定义
2.4.2 里氏代换原则分析
2.4.3 里氏代换原则实例
2.5 依赖倒转原则
2.5.1 依赖倒转原则定义
2.5.2 依赖倒转原则分析
2.5.3 依赖倒转原则实例
2.6 接口隔离原则
2.6.1 接口隔离原则定义
2.6.2 接口隔离原则分析
2.6.3 接口隔离原则实例
2.7 合成复用原则
2.7.1 合成复用原则定义
2.7.2 合成复用原则分析
2.7.3 合成复用原则实例
2.8 迪米特法则
2.8.1 迪米特法则定义
2.8.2 迪米特法则分析
2.8.3 迪米特法则实例
2.9 本章小结
思考与练习
第3章 设计模式概述
3.1 设计模式的诞生与发展
3.1.1 模式的诞生与定义
3.1.2 软件模式
3.1.3 设计模式的发展
3.2 设计模式的定义与分类
3.2.1 设计模式的定义
3.2.2 设计模式的基本要素
3.2.3 设计模式的分类
3.3 GoF设计模式简介
3.4 设计模式的优点
3.5 本章小结
思考与练习
第4章 简单工厂模式
4.1 创建型模式
4.1.1 创建型模式概述
4.1.2 创建型模式简介
4.2 简单工厂模式动机与定义
4.2.1 模式动机
4.2.2 模式定义
4.3 简单工厂模式结构与分析
4.3.1 模式结构
4.3.2 模式分析
4.4 简单工厂模式实例与解析
4.4.1 简单工厂模式实例之简单电视机工厂
4.4.2 简单工厂模式实例之权限管理
4.5 简单工厂模式效果与应用
4.5.1 模式优缺点
4.5.2 模式适用环境
4.5.3 模式应用
4.6 简单工厂模式扩展
4.7 本章小结
思考与练习
第5章 工厂方法模式
5.1 工厂方法模式动机与定义
5.1.1 简单工厂模式的不足
5.1.2 模式动机
5.1.3 模式定义
5.2 工厂方法模式结构与分析
5.2.1 模式结构
5.2.2 模式分析
5.3 工厂方法模式实例与解析
5.3.1 工厂方法模式实例之电视机工厂
5.3.2 工厂方法模式实例之日志记录器
5.4 工厂方法模式效果与应用
5.4.1 模式优缺点
5.4.2 模式适用环境
5.4.3 模式应用
5.5 工厂方法模式扩展
5.6 本章小结
思考与练习
第6章 抽象工厂模式
6.1 抽象工厂模式动机与定义
6.1.1 模式动机
6.1.2 模式定义
6.2 抽象工厂模式结构与分析
6.2.1 模式结构
6.2.2 模式分析
6.3 抽象工厂模式实例与解析
6.3.1 抽象工厂模式实例之电器工厂
6.3.2 抽象工厂模式实例之数据库操作工厂
6.4 抽象工厂模式效果与应用
6.4.1 模式优缺点
6.4.2 模式适用环境
6.4.3 模式应用
6.5 抽象工厂模式扩展
6.6 本章小结
思考与练习
第7章 建造者模式
7.1 建造者模式动机与定义
7.1.1 模式动机
7.1.2 模式定义
7.2 建造者模式结构与分析
7.2.1 模式结构
7.2.2 模式分析
7.3 建造者模式实例与解析
7.4 建造者模式效果与应用
7.4.1 模式优缺点
7.4.2 模式适用环境
7.4.3 模式应用
7.5 建造者模式扩展
7.6 本章小结
思考与练习
第8章 原型模式
8.1 原型模式动机与定义
8.1.1 模式动机
8.1.2 模式定义
8.2 原型模式结构与分析
8.2.1 模式结构
8.2.2 模式分析
8.3 原型模式实例与解析
8.3.1 原型模式实例之邮件复制(浅克隆)
8.3.2 原型模式实例之邮件复制(深克隆)
8.4 原型模式效果与应用
8.4.1 模式优缺点
8.4.2 模式适用环境
8.4.3 模式应用
8.5 原型模式扩展
8.6 本章小结
思考与练习
第9章 单例模式
…
第27章 访问者模式
27.1 访问者模式动机与定义
27.1.1 模式动机
27.1.2 模式定义
27.2 访问者模式结构与分析
27.2.1 模式结构
27.2.2 模式分析
27.3 访问者模式实例与解析
27.3.1 访问者模式实例之购物车
27.3.2 访问者模式实例之奖励审批系统
27.4 访问者模式效果与应用
27.4.1 模式优缺点
27.4.2 模式适用环境
27.4.3 模式应用
27.5 访问者模式扩展
27.6 本章小结
思考与练习
参考文献
文摘Abstract
《【Java基础教程】(四十七)网络编程篇:网络通讯概念,TCP、UDP协议,Socket与ServerSocket类使用实践与应用场景~》
《【Java基础教程】(四十九)集合体系篇 · 下》










)









