MySQL 学习
文章目录
- MySQL 学习
- 1. 数据库三层结构
- 2. 数据在数据库中的存储方式
- 3. SQL 语句分类
- 3.1 备份恢复数据库的表
- 4. Mysql 常用数据类型(列类型)
- 4.1 数值型(整数)的基本使用
- 4.2 数值型(bit)的使用
- 4.3 数值型(小数)的基本使用
- 4.4 字符串的基本使用(面试题)
- 4.5 字符串使用细节
- 4.6 日期类型的基本使用
- 5 增删改查语句(CRUD)
- 5.1 insert 语句
- 5.2update 语句
- 5.3 delete 语句
- 5.4 select 语句
- 5.5 Order By 子句排序查询结果
- 6. 合计/统计函数
- 6.1 count
- 6.2 sum
- 6.3 avg
- 6.4 max/min
- 6.5 group by 分组
- 7. 字符串相关函数
- 8. 数学相关函数
- 9. 时间日期相关函数 date.sql
- 10. 加密和系统函数 pwd.sql
- 11. 流程控制函数
- 12. mysql 表查询-加强
- 12.1 介绍
- 12.2 分页查询
- 12.3 使用分组函数和分组子句 group by
- 12.4 数据分组的总结
- 13. mysql 多表查询
- 14. 自连接
- 15. mysql 子表查询
- 15.1 什么是子查询 subquery.sql
- 15.2 单行子查询
- 15.3 请思考:如何显示与 SMITH 同一部门的所有员工?
- 15.4 多行子查询
- 15.5 子查询当做临时表使用 ★
- 15.6 在多行子查询中使用 all 操作符
- 15.7 在多行子查询中使用 any 操作符
- 15.8 多列子查询 manycolumn.sql
- 15.9 在 from 子句中使用子查询 subquery03.sql
- 16. 表复制
- 16.1 自我赋值数据(蠕虫复制)
- 17. 合并查询
- 18. mysql 表外连接
- 19. mysql 约束
- 19.1 primary key(主键)-基本使用
- 19.2 not null(非空)
- 19.3 unique(唯一)
- 19.4. foreign key(外键)
- 19.5. check
- 19.6 商店售货系统表设计案例
- 20. 自增长
- 21. mysql 索引
- 21.1 索引快速入门
- 21.2 索引的原理 ★
- 21.3 索引的类型
- 21.4 索引使用
- 21.5 索引课堂练习
- 21.6 小结:哪些列上适合使用索引
- 22. mysql 事务
- 22.1 什么是事务
- 22.2 事务和锁
- 22.3 回退事务
- 22.4 提交事务
- 22.5 事务细节讨论
- 23. mysql 事务隔离级别
- 23.1 事务隔离级别介绍
- 23.2 查看事务隔离级别
- 23.3 事务隔离级别
- 23.4 mysql 的事务隔离级别--案例
- 23.5 设置事务隔离级别
- 24. mysql 事务 ACID
- 25. mysql 表类型和存储引擎
- 25.1 基本介绍
- 25.2 主要的存储引擎/表类型特点
- 25.3 细节说明
- 25.4 三种存储引擎表使用案例
- 25.5 如何选择表的存储引擎
- 25.6 修改存储引擎
- 26. 视图(view)
- 26.1 基本概念
- 26.2 视图的基本使用
- 26.3 完成提出的需求 view.sql
- 26.4 视图细节讨论
- 26.5 视图最佳实践
- 26.6 视图课堂练习
- 27. MySQL 管理
- 27.1 MySQL用户
- 27.2 创建用户
- 27.3 删除用户
- 27.4 用户修改密码
- 27.5 mysql 中的权限
- 27.6 给用户授权
- 27.7 回收用户授权
- 27.8 权限生效指令
- 27.9 课堂练习题 grant.sql
- 27.10 细节说明
- 28. 本章作业
- 使用命令行窗口连接 MYSQL 数据库

- 操作示意图

1. 数据库三层结构

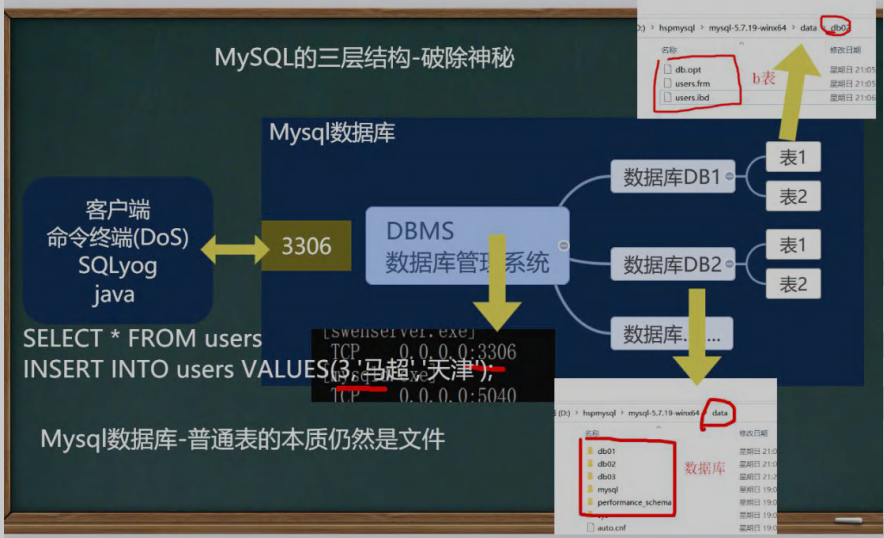
2. 数据在数据库中的存储方式

3. SQL 语句分类

3.1 备份恢复数据库的表
- 备份库的表

4. Mysql 常用数据类型(列类型)

4.1 数值型(整数)的基本使用

#演示整型的是一个
#使用 tinyint 来演示范围 有符号 -128 ~ 127 如果没有符号 0 ~ 255
#说明:表的字符集,校验规则,存储引擎,使用默认
#1. 如果没有指定 unsigned, 则 TINYINT 就是有符号
#2. 如果指定 UNSIGNED, TINYINT 就是无符号 0 ~ 255CREATE TABLE t3(id TINYINT);CREATE TABLE t4 (id TINYINT UNSIGNED);INSERT INTO t3 VALUES(-127); #有符号-128 ~ 127
SELECT * FROM t3INSERT INTO t4 VALUES(255); #无符号0 ~ 255
SELECT * FROM t4
4.2 数值型(bit)的使用

#演示 bit 类型使用
#说明
#1. bit(m) m 在 1-64
#2. 添加数据 范围 按照你给的位数来确定,比如 m = 8 表示一个字节 0~255
#3. 显示按照 bit
#4. 查询时,仍然可以按照数来查询
CREATE TABLE t05 (num BIT(8));
INSERT INTO t05 VALUES(255);
SELECT * FROM t05;
SELECT * FROM t05 WHERE num = 1;
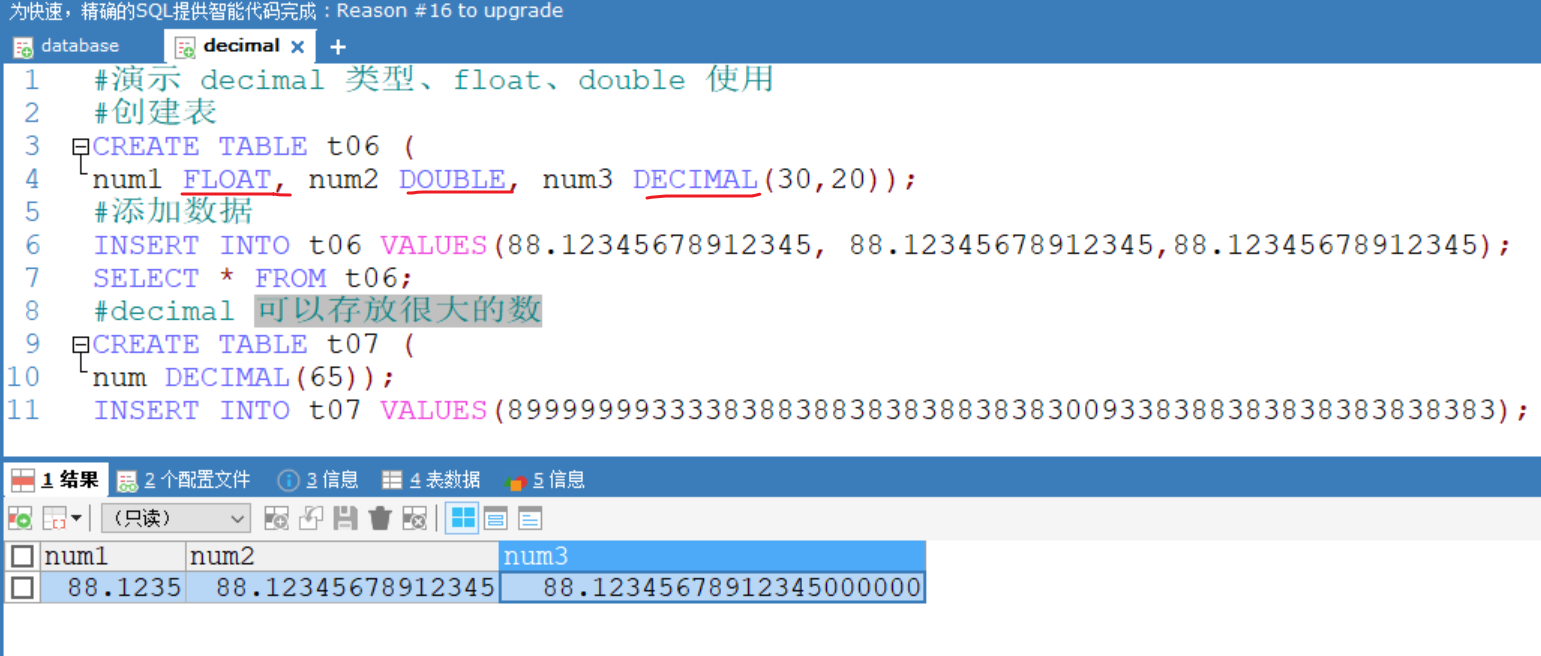
4.3 数值型(小数)的基本使用

#演示 decimal 类型、float、double 使用
#创建表
CREATE TABLE t06 (
num1 FLOAT, num2 DOUBLE, num3 DECIMAL(30,20));#添加数据
INSERT INTO t06 VALUES(88.12345678912345, 88.12345678912345,88.12345678912345);
SELECT * FROM t06;#decimal 可以存放很大的数
CREATE TABLE t07 (
num DECIMAL(65));
INSERT INTO t07 VALUES(8999999933338388388383838838383009338388383838383838383);
SELECT * FROM t07;
CREATE TABLE t08(
num BIGINT UNSIGNED)
INSERT INTO t08 VALUES(8999999933338388388383838838383009338388383838383838383);
SELECT * FROM t08;
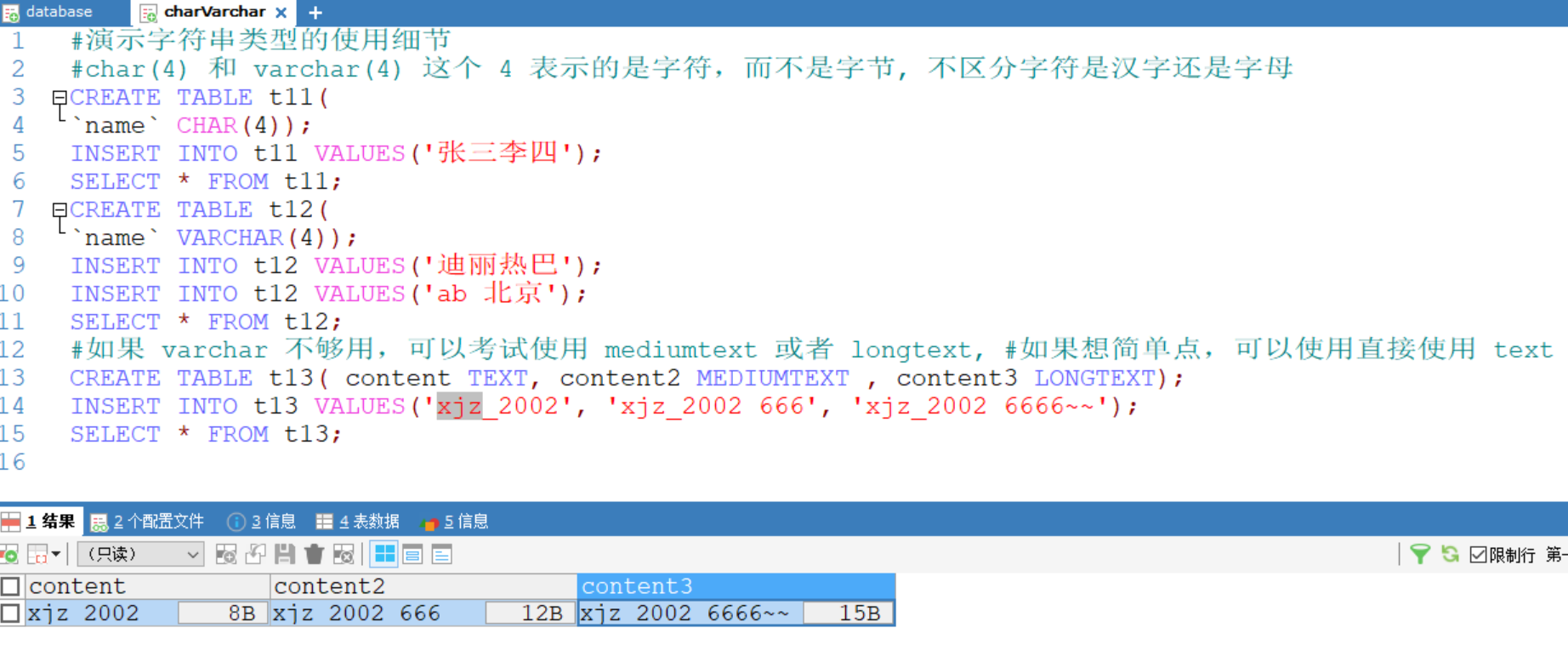
4.4 字符串的基本使用(面试题)

#演示字符串类型使用 char字符 varchar字节
#注释的快捷键 shift + ctrl + c,注销注释 shift + ctrl + r
-- CHAR(size)
-- 固定长度字符串 最大 255 字符
-- VARCHAR(size) 0 ~ 65535 字节
-- 可变长度字符串 最大 65532 字节 【utf8 编码最大 21844 字符 1-3 个字节用于记录大小】
-- 如果表的编码是 utf8 varchar(size) size = (65535-3) / 3 = 21844
-- 如果表的编码是 gbk varchar(size) size = (65535-3) / 2 = 32766
CREATE TABLE t09 (`name` CHAR(255));CREATE TABLE t10 (`name` VARCHAR(32766)) CHARSET gbk;DROP TABLE t10;4.5 字符串使用细节




#演示字符串类型的使用细节
#char(4) 和 varchar(4) 这个 4 表示的是字符,而不是字节, 不区分字符是汉字还是字母
CREATE TABLE t11(
`name` CHAR(4));
INSERT INTO t11 VALUES('张三李四');
SELECT * FROM t11;
CREATE TABLE t12(
`name` VARCHAR(4));
INSERT INTO t12 VALUES('迪丽热巴');
INSERT INTO t12 VALUES('ab 北京');
SELECT * FROM t12;
#如果 varchar 不够用,可以考试使用 mediumtext 或者 longtext, #如果想简单点,可以使用直接使用 text
CREATE TABLE t13( content TEXT, content2 MEDIUMTEXT , content3 LONGTEXT);
INSERT INTO t13 VALUES('xjz_2002', 'xjz_2002 666', 'xjz_2002 6666~~');
SELECT * FROM t13;
utf8编码(默认):一个汉字占三个字节,一个英文占一个字节
gbk编码中:一个汉字或英文都是占两个字节
4.6 日期类型的基本使用

#演示时间相关的类型
#创建一张表, date , datetime , timestamp
CREATE TABLE t14 (
birthday DATE , -- 生日
job_time DATETIME, -- 记录年月日 时分秒
login_time TIMESTAMP
NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP); -- 登录时间, 如果希望 login_time 列自动更新, 需要配置
SELECT * FROM t14;
INSERT INTO t14(birthday, job_time)
VALUES('2022-11-11','2022-11-11 10:10:10'); -- 如果我们更新 t14 表的某条记录,login_time 列会自动的以当前时间进行更新
5 增删改查语句(CRUD)
5.1 insert 语句

5.2update 语句

5.3 delete 语句

5.4 select 语句


- 使用表达式对查询的列进行计算

- 在 select 语句中使用 as 语句

- 在 where 子句中经常使用的运算符

5.5 Order By 子句排序查询结果


6. 合计/统计函数
6.1 count
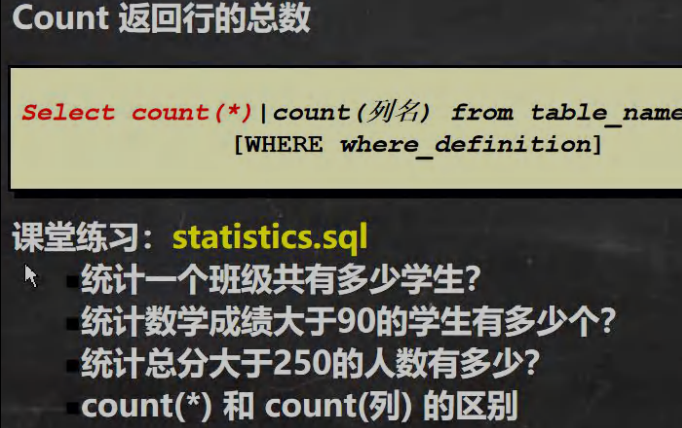
-- 演示 mysql 的统计函数的使用
-- 统计一个班级共有多少学生?
SELECT COUNT(*) FROM student;
-- 统计数学成绩大于 90 的学生有多少个?
SELECT COUNT(*) FROM student
WHERE math > 90
-- 统计总分大于 250 的人数有多少?
SELECT COUNT(*) FROM student
WHERE (math + english + chinese) > 250
-- count(*) 和 count(列) 的区别
-- 解释 :count(*) 返回满足条件的记录的行数
-- count(列): 统计满足条件的某列有多少个,但是会排除 为 null 的情况
CREATE TABLE t15 (
`name` VARCHAR(20));
INSERT INTO t15 VALUES('tom');
INSERT INTO t15 VALUES('jack');
INSERT INTO t15 VALUES('mary');
INSERT INTO t15 VALUES(NULL);
SELECT * FROM t15;SELECT COUNT(*) FROM t15; -- 4
SELECT COUNT(`name`) FROM t15;-- 3
6.2 sum

-- 演示 sum 函数的使用
-- 统计一个班级数学总成绩?
SELECT SUM(math) FROM student; -- 统计一个班级语文、英语、数学各科的总成绩
SELECT SUM(math) AS math_total_score,SUM(english),SUM(chinese) FROM student; -- 统计一个班级语文、英语、数学的成绩总和
SELECT SUM(math + english + chinese) FROM student; -- 统计一个班级语文成绩平均分
SELECT SUM(chinese)/ COUNT(*) FROM student;
SELECT SUM(`name`) FROM student;
6.3 avg

-- 演示 avg 的使用
-- 练习:
-- 求一个班级数学平均分?
SELECT AVG(math) FROM student; -- 求一个班级总分平均分
SELECT AVG(math + english + chinese) FROM student;
6.4 max/min

-- 演示 max 和 min 的使用
-- 求班级最高分和最低分(数值范围在统计中特别有用)
SELECT MAX(math + english + chinese), MIN(math + english + chinese)FROM student; -- 求出班级数学最高分和最低分
SELECT MAX(math) AS math_high_socre, MIN(math) AS math_low_socreFROM student;
6.5 group by 分组

- having 子句 对分组后的结果进行过滤


7. 字符串相关函数
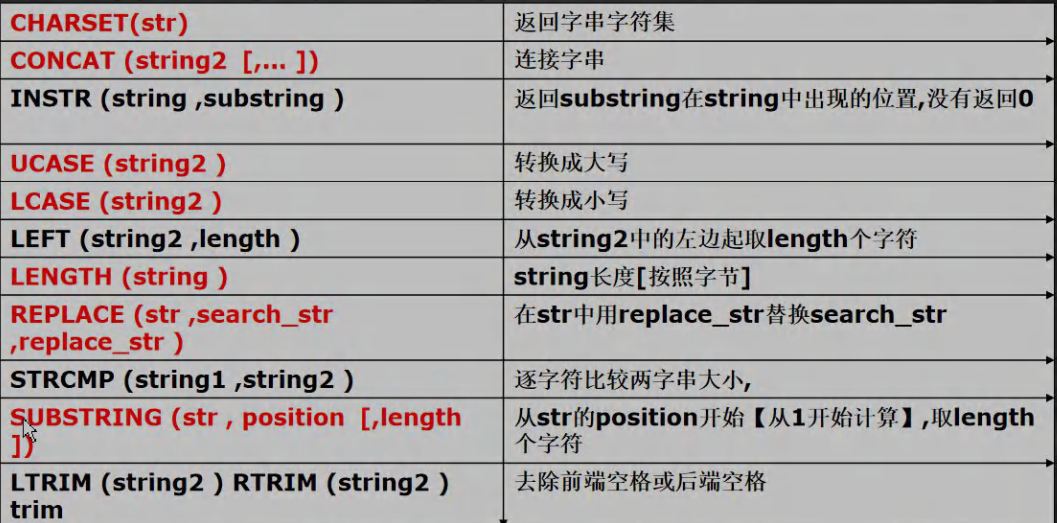
-- 练习: 以首字母小写的方式显示所有员工 emp 表的姓名
-- 方法 1
-- 思路先取出 ename 的第一个字符,转成小写的
-- 把他和后面的字符串进行拼接输出即可
SELECT CONCAT(LCASE(SUBSTRING(ename,1,1)), SUBSTRING(ename,2)) AS new_name
FROM emp;
SELECT CONCAT(LCASE(LEFT(ename,1)), SUBSTRING(ename,2)) AS new_name
FROM emp;
8. 数学相关函数

-- 演示数学相关函数-- ABS(num) 绝对值
SELECT ABS(-10) FROM DUAL;
-- BIN(decimal_number)十进制转二进制
SELECT BIN(10) FROM DUAL; -- 1010
-- CEILING (number2 ) 向上取整, 得到比 num2 大的最小整数
SELECT CEILING(-1.1) FROM DUAL; -- -1-- CONV(number2,from_base,to_base) 进制转换
-- 下面的含义是 8 是十进制的 8, 转成 2 进制输出
SELECT CONV(8,10,2) FROM DUAL; -- 1000-- 下面的含义是 16 是 16 进制的 16, 转成 10 进制输出
SELECT CONV(16, 16, 10) FROM DUAL; -- 6 + 1 x 16 = 22-- FLOOR(number2) 向下取整,得到比 num2 小的最大整数
SELECT FLOOR(-1.1) FROM DUAL;-- -2-- FORMAT (number,decimal_places ) 保留小数位数(四舍五入)
SELECT FORMAT(78.12548,2) FROM DUAL;-- HEX (DecimalNumber ) 转十六进制-- LEAST (number , number2 [,..]) 求最小值
SELECT LEAST(0.1,-10.4) FROM DUAL;
-- MOD (numerator ,denominator ) 求余
SELECT MOD(10,3) FROM DUAL;-- RAND([seed]) RAND([seed]) 返回随机数 其范围为 0 ≤ v ≤ 1.0
-- 函数说明
-- 1. 如果使用 rand() 每次返回不同的随机数,在 0 ≤ v ≤ 1.0
-- 2. 如果使用 rand(seed) 返回随机数, 范围 0 ≤ v ≤ 1.0, 如果 seed 不变,
-- 该随机数也不变了
SELECT RAND() FROM DUAL;SELECT CURRENT_TIMESTAMP() FROM DUAL;9. 时间日期相关函数 date.sql


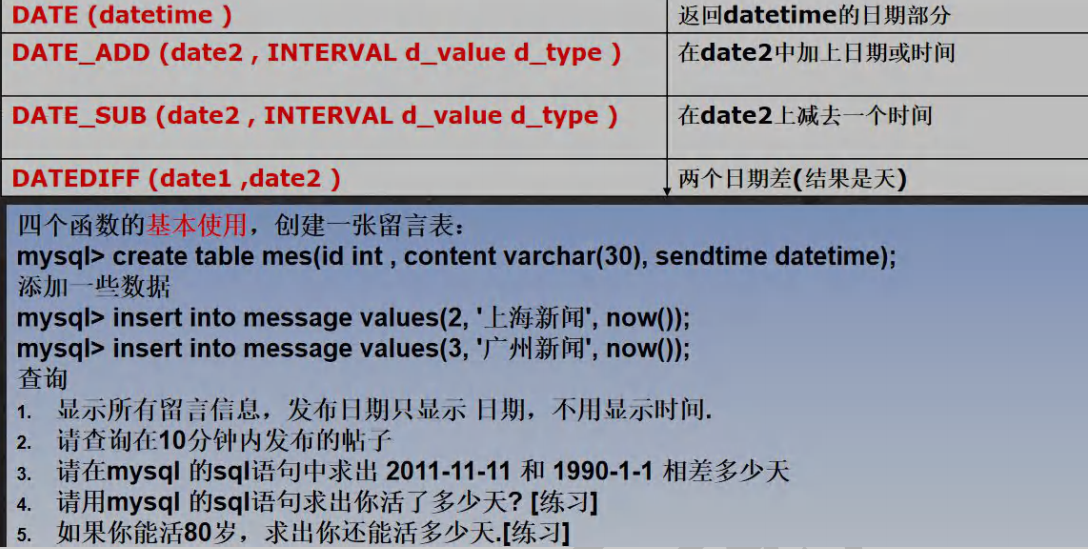


-- 日期时间相关函数-- CURRENT_DATE ( ) 当前日期
SELECT CURRENT_DATE() FROM DUAL;
-- CURRENT_TIME ( )当前时间
SELECT CURRENT_TIME() FROM DUAL;
-- CURRENT_TIMESTAMP ( ) 当前时间戳
SELECT CURRENT_TIMESTAMP() FROM DUAL;-- 创建测试表 信息表
CREATE TABLE mes(id INT,content VARCHAR(30),send_time DATETIME);-- 添加一条几率
INSERT INTO mes VALUES(1,'北京新闻',CURRENT_TIMESTAMP());SELECT * FROM mes;
SELECT NOW() FROM DUAL;-- 上应用实例
-- 显示所有新闻信息,发布日期只显示 日期,不用显示时间
SELECT id,content,DATE(send_time) FROM mes;-- 请查询在 10 分钟内发布的新闻, 思路一定要梳理一下.
SELECT * FROM mesWHERE DATE_ADD(send_time,INTERVAL 10 MINUTE) >= NOW()SELECT *FROM mesWHERE send_time >= DATE_SUB(NOW(),INTERVAL 10 MINUTE);-- 请在 mysql 的 sql 语句中求出 2011-11-11 和 1990-1-1 相差多少天
SELECT DATEDIFF('2011-11-11','1990-1-1') FROM DUAL;-- 请用 mysql 的 sql 语句求出你活了多少天? [练习]
SELECT DATEDIFF(NOW(),'2002-12-02') FROM DUAL;
-- 如果你能活 80 岁,求出你还能活多少天.[练习] 1986-11-11 出生
-- 先求出活 80 岁 时, 是什么日期 X
-- 然后在使用 datediff(x, now()); 1986-11-11->datetime
-- INTERVAL 80 YEAR : YEAR 可以是 年月日,时分秒
-- '1986-11-11' 可以 date,datetime timestamp
SELECT DATEDIFF(DATE_ADD('2002-12-02',INTERVAL 80 YEAR),NOW())FROM DUAL;SELECT TIMEDIFF('10:11:11','06:11:10') FROM DUAL; -- YEAR|Month|DAY| DATE (datetime )
SELECT YEAR(NOW()) FROM DUAL;
SELECT MONTH(NOW()) FROM DUAL;
SELECT DAY(NOW()) FROM DUAL;
SELECT MONTH('2013-10-3') FROM DUAL;
-- unix_timestamp() : 返回的是 1970-1-1 到现在的秒数
SELECT UNIX_TIMESTAMP() FROM DUAL;
-- FROM_UNIXTIME() : 可以把一个 unix_timestamp 秒数[时间戳],转成指定格式的日期
-- %Y-%m-%d 格式是规定好的,表示年月日
-- 意义:在开发中,可以存放一个整数,然后表示时间,通过 FROM_UNIXTIME 转换
--
SELECT FROM_UNIXTIME(1618483484, '%Y-%m-%d') FROM DUAL;
SELECT FROM_UNIXTIME(1618483484, '%Y-%m-%d %H:%i:%s') FROM DUAL;
10. 加密和系统函数 pwd.sql
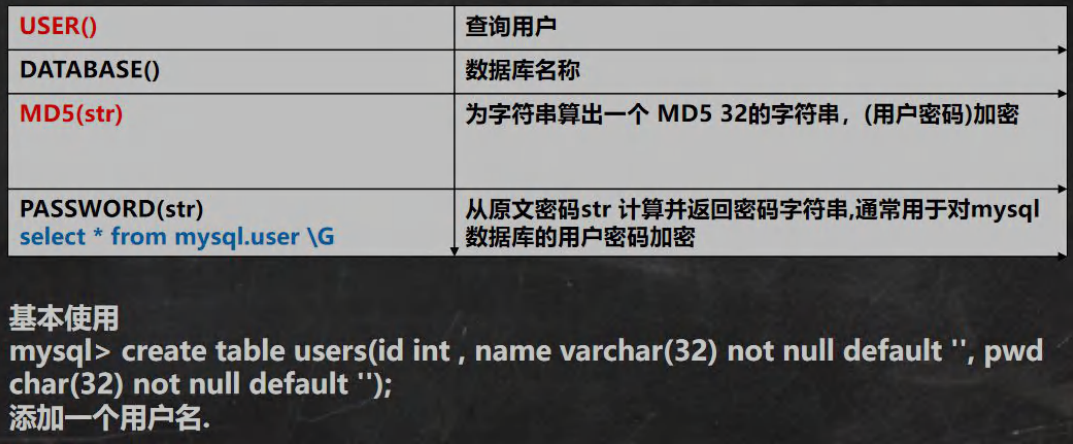
-- 演示加密函数和系统函数-- USER() 查询用户
-- 可以查看登录到 mysql 的有哪些用户,以及登录的 IP
SELECT USER() FROM DUAL;
-- DATABASE() 查询当前使用数据库名称
SELECT DATABASE();-- MD5(str) 为字符串算出一个 MD5 32 的字符串,常用(用户密码)加密
-- root 密码是 hsp -> 加密 md5 -> 在数据库中存放的是加密后的密码
SELECT MD5('xjz') FROM DUAL;
SELECT LENGTH(MD5('xjz')) FROM DUAL;-- 演示用户表,存放密码时,是 md5
CREATE TABLE xjz_user(id INT,`name` VARCHAR(32) NOT NULL DEFAULT '',pwd CHAR(32) NOT NULL DEFAULT '');INSERT INTO xjz_userVALUES(100,'徐金卓',MD5('xjz'));
SELECT * FROM xjz_user;SELECT * FROM xjz_user -- SQL注入问题WHERE `name`='徐金卓' AND pwd='xjz';-- PASSWORD(str) -- 加密函数, MySQL 数据库的用户密码就是 PASSWORD 函数加密
SELECT PASSWORD('xjz') FROM DUAL; -- 数据库的 *ED67761388EF40FBD9C6650F6FE1B248BCEC454A-- select * from mysql.user \G 从原文密码 str 计算并返回密码字符串
-- 通常用于对 mysql 数据库的用户密码加密
-- mysql.user 表示 数据库.表
SELECT * FROM mysql.user
11. 流程控制函数


-- 演示流程控制语句# IF(expr1,expr2,expr3) 如果 expr1 为 True ,则返回 expr2 否则返回 expr3
SELECT IF(TRUE,'北京','上海') FROM DUAL;
# IFNULL(expr1,expr2) 如果 expr1 不为空 NULL,则返回 expr1,否则返回 expr2
SELECT IFNULL(NULL,'xjz') FROM DUAL;
# SELECT CASE WHEN expr1 THEN expr2 WHEN expr3 THEN expr4 ELSE expr5 END; [类似多重分支.]
# 如果 expr1 为 TRUE,则返回 expr2,如果 expr2 为 t, 返回 expr4, 否则返回 expr5SELECT CASEWHEN TRUE THEN 'jack' -- jackWHEN FALSE THEN 'tom'ELSE 'mary' END;-- 1. 查询 emp 表, 如果 comm 是 null , 则显示 0.0
-- 说明,判断是否为 null 要使用 is null, 判断不为空 使用 is not
SELECT ename,IF(comm IS NULL,0.0,comm)FROM emp;
SELECT ename,IFNULL(comm,0.0)FROM emp;-- 2. 如果 emp 表的 job 是 CLERK 则显示 职员, 如果是 MANAGER 则显示经理
-- 如果是 SALESMAN 则显示 销售人员,其它正常显示
SELECT ename,(SELECT CASEWHEN job='CLERK' THEN '职员'WHEN job='MANAGER' THEN '经理'WHEN job='SALESMAN' THEN '销售人员'ELSE job END) AS jobFROM emp;SELECT * FROM emp;
12. mysql 表查询-加强
12.1 介绍



-- 查询加强
-- ■ 使用 where 子句
-- ?如何查找 1992.1.1 后入职的员工
-- 老师说明: 在 mysql 中,日期类型可以直接比较, 需要注意格式
SELECT * FROM empWHERE hiredate > '1992-1-1';-- ■ 如何使用 like 操作符(模糊)
-- %: 表示 0 到多个任意字符 _: 表示单个任意字符
-- ?如何显示首字符为 S 的员工姓名和工资
SELECT ename,sal FROM empWHERE ename LIKE 'S%';
-- ?如何显示第三个字符为大写 O 的所有员工的姓名和工资
SELECT ename,sal FROM empWHERE ename LIKE '__O%';-- ■ 如何显示没有上级的雇员的情况
SELECT * FROM empWHERE mgr IS NULL;
-- ■ 查询表结构
DESC emp;-- 使用 order by 子句
-- ?如何按照工资的从低到高的顺序[升序],显示雇员的信息
SELECT * FROM empORDER BY sal
-- ?按照部门号升序而雇员的工资降序排列 , 显示雇员信息
SELECT * FROM empORDER BY deptno ASC , sal DESC;
12.2 分页查询
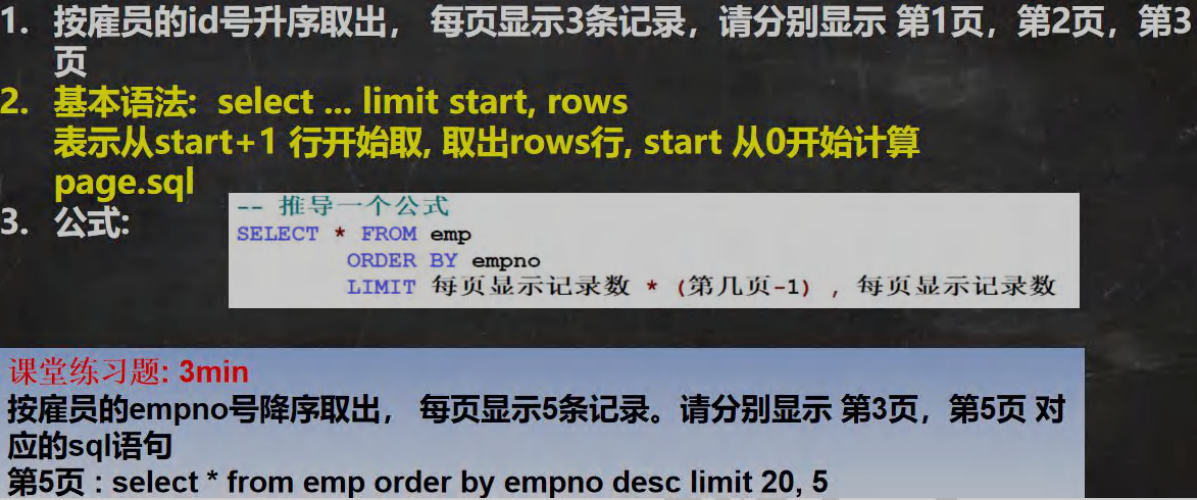
-- 分页查询
-- 按雇员的 id 号升序取出, 每页显示 3 条记录,请分别显示 第 1 页,第 2 页,第 3 页-- 第 1 页
SELECT * FROM empORDER BY empnoLIMIT 0,3;
-- 第 2 页
SELECT * FROM empORDER BY empnoLIMIT 3,3;
-- 第 3 页
SELECT * FROM empORDER BY empnoLIMIT 6,3;-- 推导一个公式
SELECT * FROM empORDER BY empnoLIMIT 每页显示记录数 * (第几页-1) , 每页显示记录数
12.3 使用分组函数和分组子句 group by

-- 增强 group by 的使用-- (1) 显示每种岗位的雇员总数、平均工资。
SELECT COUNT(*),AVG(sal),jobFROM emp GROUP BY job;
-- (2) 显示雇员总数,以及获得补助的雇员数
-- 思路: 获得补助的雇员数 就是 comm 列为非 null, 就是 count(列),如果该列的值为 null, 是
-- 不会统计 , SQL 非常灵活,需要我们动脑筋
SELECT COUNT(*),COUNT(comm)FROM emp;-- 扩展要求:统计没有获得补助的雇员数
SELECT COUNT(*),COUNT(IF(comm IS NULL,1,NULL))FROM emp;
SELECT COUNT(*),COUNT(*)-COUNT(comm)FROM emp;-- (3) 显示管理者的总人数。小技巧:尝试写->修改->尝试[正确的]
SELECT COUNT(DISTINCT mgr)FROM emp;-- (4) 显示雇员工资的最大差额。
-- 思路: max(sal) - min(sal)
SELECT MAX(sal) - MIN(sal) FROM emp;-- 应用案例:请统计各个部门 group by 的平均工资 avg,
-- 并且是大于 1000 的 having,并且按照平均工资从高到低排序, order by
-- 取出前两行记录 limit 0, 2SELECT deptno,AVG(sal) AS avg_salFROM empGROUP BY deptnoHAVING avg_salORDER BY avg_sal DESCLIMIT 0,2
12.4 数据分组的总结

13. mysql 多表查询
多表查询时指基于两个和两个以上的表查询,在实际应用中,查询单个表可能不能满足你的需求,(如下面的课堂练习),需要使用到(dept表和emp表)

-- 多表查询
-- ?显示雇员名,雇员工资及所在部门的名字 【笛卡尔集】
/*代码分析1. 雇员名,雇员工资 来自 emp 表2. 部门的名字 来自 dept 表3. 需求对 emp 和 dept 查询 ename,sal,dname,deptno4. 当我们需要指定显示某个表的列是,需要 表.列表
*/
SELECT emp.deptno,ename,sal,dnameFROM emp,deptWHERE emp.deptno = dept.deptno;SELECT * FROM emp;
SELECT * FROM dept;
SELECT * FROM salgrade;
-- 小技巧:多表查询的条件不能少于 表的个数-1, 否则会出现笛卡尔集
-- ?如何显示部门号为 10 的部门名、员工名和工资
SELECT emp.deptno,ename,sal,dnameFROM emp,deptWHERE emp.deptno = dept.deptno AND emp.deptno=10;-- ?显示各个员工的姓名,工资,及其工资的级别-- 思路 姓名,工资 来自 emp 13
-- 工资级别 salgrade 5
-- 写 sql , 先写一个简单,然后加入过滤条件...
SELECT ename,sal,gradeFROM emp,salgradeWHERE sal BETWEEN losal AND hisal;
14. 自连接
自连接是指在同一张表的连接查询 [将同一张表看做两张表]。
-- 多表查询的 自连接-- 思考题: 显示公司员工名字和他的上级的名字
-- 代码分析: 员工名字 在 emp, 上级的名字的名字 emp
-- 员工和上级是通过 emp 表的 mgr 列关联
-- 这里老师小结:
-- 自连接的特点
-- 1. 把同一张表当做两张表使用
-- 2. 需要给表取别名 表名 表别名
-- 3. 列名不明确,可以指定列的别名 列名 as 列的别名
SELECT worker.ename AS '职员号' , boss.ename AS '上级名'FROM emp worker,emp bossWHERE worker.mgr = boss.empno;
SELECT * FROM emp;
15. mysql 子表查询
15.1 什么是子查询 subquery.sql
子查询是指嵌入在其它 sql 语句中的 select 语句,也叫嵌套查询
15.2 单行子查询
单行子查询是指只返回一行数据的子查询语句
15.3 请思考:如何显示与 SMITH 同一部门的所有员工?
15.4 多行子查询
多行子查询指返回多行数据的子查询使用关键字 in

-- 子查询的演示
-- 请思考:如何显示与 SMITH 同一部门的所有员工?
/*
1. 先查询到 SMITH 的部门号得到
2. 把上面的 select 语句当做一个子查询来使用
*/
SELECT deptnoFROM empWHERE ename = 'SMITH'; -- 下面的是答案
SELECT *FROM empWHERE deptno = (SELECT deptnoFROM empWHERE ename = 'SMITH');-- 课堂练习:如何查询和部门 10 的工作相同的雇员的
-- 名字、岗位、工资、部门号, 但是不含 10 号部门自己的雇员.
/*
1. 查询到 10 号部门有哪些工作
2. 把上面查询的结果当做子查询使用
*/
SELECT DISTINCT jobFROM empWHERE deptno = 10;-- 下面语句完整
SELECT ename,job,sal,deptnoFROM empWHERE job IN (SELECT DISTINCT jobFROM empWHERE deptno = 10)AND deptno != 10;
15.5 子查询当做临时表使用 ★
练习题 subquery.sql

-- 查询ecshop中各个类别中,价格最高的商品-- 查询 商品表
-- 先得到 各个类别中,价格最高的商品 max + group by cat_id,当做临时表
-- 把子查询当做一张临时表可以解决很多很多复杂问题SELECT cat_id,MAX(shop_price) FROM ecs_goodsGROUP BY cat_id;SELECT goods_id, ecs_goods.cat_id, goods_name, shop_priceFROM (SELECT cat_id, MAX(shop_price) AS max_priceFROM ecs_goodsGROUP BY cat_id) temp, ecs_goodsWHERE temp.cat_id = ecs_goods.cat_idAND temp.max_price = ecs_goods.shop_price;SELECT goods_id, cat_id, goods_name, shop_priceFROM ecs_goods;
15.6 在多行子查询中使用 all 操作符

-- all 和 any 的使用-- 请思考:显示工资比部门 30 的所有员工的工资高的员工的姓名、工资和部门号SELECT ename,sal,deptnoFROM empWHERE sal > ALL(SELECT salFROM empWHERE deptno = 30)
-- 可以这样写
SELECT ename,sal,deptnoFROM empWHERE sal > (SELECT MAX(sal)FROM empWHERE deptno = 30)15.7 在多行子查询中使用 any 操作符

-- 请思考:如何显示工资比部门 30 的其中一个员工的工资高的员工的姓名、工资和部门号SELECT ename,sal,deptnoFROM empWHERE sal > ANY(SELECT salFROM empWHERE deptno = 30)
-- 可以这样写
SELECT ename,sal,deptnoFROM empWHERE sal > (SELECT MIN(sal)FROM empWHERE deptno = 30)
15.8 多列子查询 manycolumn.sql
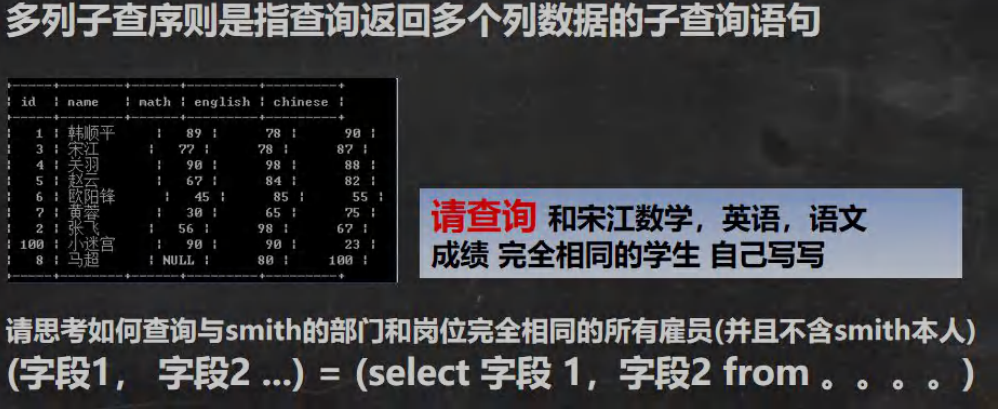
-- 多列子查询-- 请思考如何查询与 allen 的部门和岗位完全相同的所有雇员(并且不含 allen 本人)
-- (字段 1, 字段 2 ...) = (select 字段 1,字段 2 from 。。。。)-- 分析: 1. 得到 allen 的部门和岗位
SELECT deptno, jobFROM empWHERE ename = 'ALLEN';-- 分析: 2 把上面的查询当做子查询来使用,并且使用多列子查询的语法进行匹配
SELECT *FROM empWHERE (deptno,job) = (SELECT deptno, jobFROM empWHERE ename = 'ALLEN') AND ename != 'ALLEN';-- 请查询 和宋江语文,数学,英语
-- 成绩 完全相同的学生
SELECT * FROM studentWHERE (chinese,english,math) = (SELECT chinese,english,mathFROM studentWHERE `name` = '宋江');
15.9 在 from 子句中使用子查询 subquery03.sql


-- 子查询练习-- 请思考:查找每个部门工资高于本部门平均工资的人的资料
-- 这里要用到数据查询的小技巧,把一个子查询当作一个临时表使用-- 1. 先得到每个部门的 部门号和 对应的平均工资SELECT deptno, AVG(sal) FROM empGROUP BY deptno;-- 2. 把上面的结果当做子查询, 和 emp 进行多表查询SELECT ename,sal,temp.avg_sal,emp.deptno FROM emp,(SELECT deptno, AVG(sal) AS avg_salFROM empGROUP BY deptno) tempWHERE emp.deptno = temp.deptnoAND emp.sal > temp.avg_sal-- 查找每个部门工资最高的人的详细资料
SELECT ename, sal, max_sal, emp.deptnoFROM emp, (SELECT deptno, MAX(sal) AS max_salFROM empGROUP BY deptno) tempWHERE emp.deptno = temp.deptnoAND emp.sal = temp.max_sal;-- 查询每个部门的信息(包括:部门名,编号,地址)和人员数量,我们一起完成。-- 1. 部门名,编号,地址 来自 dept 表
-- 2. 各个部门的人员数量 -》 构建一个临时表SELECT * FROM dept
SELECT deptno,COUNT(*) AS '人数'FROM empGROUP BY deptnoSELECT dname, dept.deptno, loc, tmp.per_num AS '人数'FROM dept, (SELECT deptno,COUNT(*) AS per_numFROM empGROUP BY deptno) tmpWHERE dept.deptno = tmp.deptno-- 还有一种写法 表.* 表示将该表所有列都显示出来, 可以简化 sql 语句
-- 在多表查询中,当多个表的列不重复时,才可以直接写列名
SELECT tmp.*, dname,locFROM dept, (SELECT deptno,COUNT(*) AS per_numFROM empGROUP BY deptno) tmpWHERE dept.deptno = tmp.deptno
16. 表复制
16.1 自我赋值数据(蠕虫复制)
有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据。
思考题:如何删除一张表重复记录
copytab.sql
-- 表的复制
-- 为了对某个 sql 语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据CREATE TABLE my_tab01(id INT,`name` VARCHAR(32),sal DOUBLE,job VARCHAR(32),deptno INT);
DESC my_tab01
SELECT * FROM my_tab01-- 演示如何自我赋值
-- 1. 先把 emp 表的记录复制到 my_tab01
INSERT INTO my_tab01(id,`name`,sal,job,deptno)SELECT empno,ename,sal,job,deptno FROM emp;
-- 2. 自我复制
INSERT INTO my_tab01SELECT * FROM my_tab01;
SELECT COUNT(*) FROM my_tab01;-- 如何删除掉一张表重复记录
-- 1. 先创建一张表 my_tab02,
-- 2. 让 my_tab02 有重复的记录CREATE TABLE my_tab02 LIKE emp;-- 这个语句 把 emp表的结构(列),赋值到 my_tab02
DESC my_tab02INSERT INTO my_tab02SELECT * FROM emp;
SELECT * FROM my_tab02;
-- 3. 考虑去重 my_tab02 的记录
/*
思路
(1) 先创建一张临时表 my_tmp , 该表的结构和 my_tab02 一样
(2) 把 my_tmp 的记录 通过 distinct 关键字 处理后 把记录复制到 my_tmp
(3) 清除掉 my_tab02 记录
(4) 把 my_tmp 表的记录复制到 my_tab02
(5) drop 掉 临时表 my_tmp
*/
-- (1) 先创建一张临时表 my_tmp , 该表的结构和 my_tab02 一样
CREATE TABLE my_tmp LIKE my_tab02;-- (2) 把 my_tab02 的记录 通过 distinct(去重) 关键字 处理后 把记录复制到 my_tmp
INSERT INTO my_tmpSELECT DISTINCT * FROM my_tab02;-- (3) 清除掉 my_tab02 记录
DELETE FROM my_tab02;-- (4) 把 my_tmp 表的记录复制到 my_tab02
INSERT INTO my_tab02SELECT * FROM my_tmp;-- (5) drop 掉 临时表 my_tmp
DROP TABLE my_tmp;
select * from my_tab02;
17. 合并查询


-- 合并查询SELECT ename,sal,job FROM emp WHERE sal > 2500 -- 5
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3-- union all 就是将两个查询结果合并,不会去重
SELECT ename,sal,job FROM emp WHERE sal > 2500
UNION ALL
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- union 就是将两个查询结果合并,会去重
SELECT ename,sal,job FROM emp WHERE sal > 2500
UNION
SELECT ename,sal,job FROM emp WHERE job='MANAGER'
18. mysql 表外连接



-- 外连接-- 比如:列出部门名称和这些部门的员工名称和工作,
-- 同时要求 显示出那些没有员工的部门。-- 使用我们学习过的多表查询的 SQL, 看看效果如何?SELECT dname,ename,jobFROM emp, deptWHERE emp.deptno = dept.deptnoORDER BY dname;
SELECT * FROM dept;SELECT * FROM emp;-- 创建 stu
/*
id name
1 Jack
2 Tom
3 Kity
4 nono
*/
CREATE TABLE stu (id INT,`name` VARCHAR(32));
INSERT INTO stuVALUES(1,'Jack'),(2,'Tom'),(3,'Kity'),(4,'nono');
SELECT * FROM stu;-- 创建 exam
/*
id grade
1 56
2 76
11 8
*/
CREATE TABLE exam (id INT,grade INT);
INSERT INTO examVALUES(1,56),(2,76),(11,8);
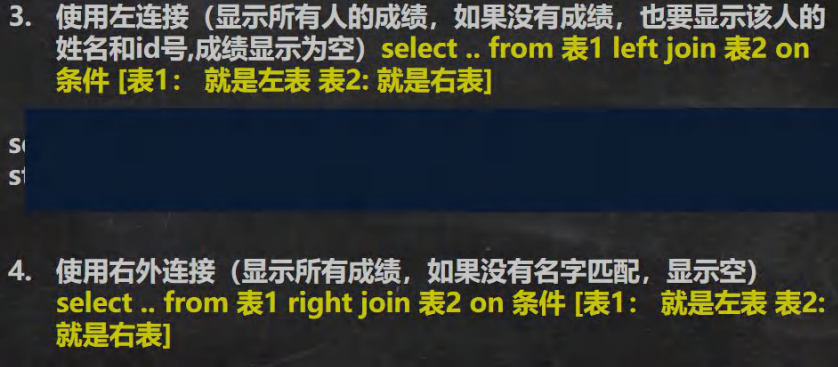
SELECT * FROM exam;-- 使用左连接
-- (显示所有人的成绩,如果没有成绩,也要显示该人的姓名和 id 号,成绩显示为空)-- 先看一下传统方法,如果不匹配,则不会显示多余的记录
SELECT `name`,stu.id,gradeFROM stu, examWHERE stu.id = exam.id;-- 改成左外连接
SELECT `name`,stu.id,gradeFROM stu LEFT JOIN examON stu.id = exam.id;-- 使用右外连接(显示所有成绩,如果没有名字匹配,显示空)
-- 即:右边的表(exam) 和左表没有匹配的记录,也会把右表的记录显示出来
SELECT `name`, stu.id, gradeFROM stu RIGHT JOIN examON stu.id = exam.id;-- 列出部门名称和这些部门的员工信息(名字和工作),
-- 同时列出那些没有员工的部门名。5min
-- 使用左外连接实现SELECT * FROM emp;
SELECT * FROM dept;SELECT dname,ename,jobFROM dept LEFT JOIN empON emp.deptno = dept.deptno-- 使用右外连接实现
SELECT dname,ename,jobFROM dept RIGHT JOIN empON emp.deptno = dept.deptno
19. mysql 约束

19.1 primary key(主键)-基本使用


-- 主键使用-- id name email
CREATE TABLE t17(id INT PRIMARY KEY,-- 表示 id 列是主键`name` VARCHAR(32),email VARCHAR(32));-- 主键列的值是不可以重复的
INSERT INTO t17VALUES(1,'jack','jack@sohu.com');
INSERT INTO t17VALUES(2,'xjz','xjz@sohu.com');INSERT INTO t17VALUES(1,'tom','jack@sohu.com');-- id重复 插入记录失败SELECT * FROM t17;-- 主键使用的细节讨论
-- primary key 不能重复而且不能为 null。
INSERT INTO t17VALUES(NULL,'xjz','xjz@sohu.com');-- 一张表最多只能有一个主键, 但可以是复合主键(比如 id+name)
CREATE TABLE t18(id INT PRIMARY KEY, -- 表示 id列是主键`name` VARCHAR(32) PRIMARY KEY -- 错误,email VARCHAR(32));-- 演示复合主键 (id 和 name 做成复合主键)
CREATE TABLE t18(id INT,`name` VARCHAR(32),email VARCHAR(32),PRIMARY KEY(id,`name`) -- 这里就是复合主键);
INSERT INTO t18VALUES(1,'tom','tom@sohu.com');
INSERT INTO t18VALUES(1,'xjz','xjz@sohu.com');
INSERT INTO t18VALUES(1,'tom','xx@sohu.com'); -- 这里就违反了复合主键
SELECT * FROM t18;-- 主键的指定方式 有两种
-- 1. 直接在字段名后指定:字段名 primakry key
-- 2. 在表定义最后写 primary key(列名);
CREATE TABLE t19(id INT,`name` VARCHAR(32) PRIMARY KEY,email VARCHAR(32));
DESC t19;CREATE TABLE t20(id INT,`name` VARCHAR(32),email VARCHAR(32),PRIMARY KEY(`name`) -- 在表定义最后写 primary key(列名));-- 使用 desc 表名,可以看到 primary key 的情况DESC t20; -- 查看 t20表的结果,显示约束的情况
DESC t18;
19.2 not null(非空)

19.3 unique(唯一)


-- unique 的使用CREATE TABLE t21(id INT UNIQUE, -- 表示 id列是不可以重复的`name` VARCHAR(32),email VARCHAR(32));
INSERT INTO t21VALUES(1, 'jack', 'jack@sohu.com');
INSERT INTO t21VALUES(1, 'tom', 'jack@sohu.com');-- unqiue 使用细节
-- 1. 如果没有指定 not null , 则 unique 字段可以有多个 null
-- 如果一个列(字段), 是 unique not null 使用效果类似 primary key
INSERT INTO t21VALUES(NULL,'tom','tom@sohu.com');
SELECT * FROM t21;
-- 2. 一张表可以有多个 unique 字段CREATE TABLE t22(id INT UNIQUE, -- 表示 id 列是不可以重复的`name` VARCHAR(32) UNIQUE,-- 表示 name不可以重复email VARCHAR(32));
DESC t22;
19.4. foreign key(外键)



-- 外键演示-- 创建 主表 my_class
CREATE TABLE my_class(id INT PRIMARY KEY,-- 班级编号`name` VARCHAR(32) NOT NULL DEFAULT '');-- 创建 从表 my_stu
CREATE TABLE my_stu(id INT PRIMARY KEY, -- 学生编号`name` VARCHAR(32) NOT NULL DEFAULT '',class_id INT, -- 学生所在班级的编号-- 下面指定外键关系FOREIGN KEY(class_id) REFERENCES my_class(id));-- 测试数据
INSERT INTO my_classVALUES(100,'java'),(200,'web');SELECT * FROM my_class;
INSERT INTO my_stuVALUES(1,'tom',100),(2,'jack',200);INSERT INTO my_stuVALUES(3,'xjz',300); -- 这里会失败..因为 300 班级不存在
SELECT * FROM my_stu;INSERT INTO my_stuVALUES(4,'king',NULL);-- 可以,外键 没有写 NOT NULL
SELECT * FROM my_class;-- 一旦建立主外键的关系,数据不能随意删除了
DELETE FROM my_classWHERE id = 100;
19.5. check

-- 演示 check 的使用
-- mysql 5.7 目前还不支持 check ,只做语法校验,但不会生效-- mysql 8.0 已经开始生效~-- 了解
-- 学习 oracle, sql server, 这两个数据库是真的生效-- 测试
CREATE TABLE t23(id INT PRIMARY KEY,`name` VARCHAR(32),sex VARCHAR(6) CHECK ( sex IN('man','woman')),sal DOUBLE CHECK ( sal>1000 AND sal < 2000));-- 添加数据
INSERT INTO t23VALUES(1,'xjz','mid',1.0);
SELECT * FROM t23
19.6 商店售货系统表设计案例

-- 使用约束的课堂练习CREATE DATABASE shop_db-- 现有一个商店的数据库 shop_db,记录客户及其购物情况,由下面三个表组成:
-- 商品 goods(商品号 goods_id,商品名 goods_name,单价 unitprice,商品类别 category,
-- 供应商 provider); -- 客户 customer(客户号 customer_id,姓名 name,住址 address,电邮 email 性别 sex,身份证 card_Id); -- 购买 purchase(购买订单号 order_id,客户号 customer_id,商品号 goods_id,购买数量 nums); -- 1 建表,在定义中要求声明 [进行合理设计]:
-- (1)每个表的主外键;
-- (2)客户的姓名不能为空值;
-- (3)电邮不能够重复; -- (4)客户的性别[男|女] check 枚举.. -- (5)单价 unitprice 在 1.0 - 9999.99 之间 check-- 商品 goods
CREATE TABLE goods(goods_id INT PRIMARY KEY,goods_name VARCHAR(64) NOT NULL DEFAULT '',unitprice DECIMAL(10,2) NOT NULL DEFAULT 0CHECK( unitprice >= 1.0 AND unitprice <= 9999.99),category INT NOT NULL DEFAULT 0,provider VARCHAR(32) NOT NULL DEFAULT'');-- 客户 customer(客户号 customer_id,姓名 name,住址 address,电邮 email 性别 sex,
-- 身份证 card_Id);
CREATE TABLE customer(customer_id CHAR(8) PRIMARY KEY, -- 程序员自己决定`name` VARCHAR(64) NOT NULL DEFAULT '',address VARCHAR(64) NOT NULL DEFAULT '',email VARCHAR(64) UNIQUE NOT NULL,sex ENUM('男','女') NOT NULL, -- 这里我们使用的是枚举类型,可生效card_id CHAR(18)); -- 购买 purchase(购买订单号 order_id,客户号 customer_id,商品号 goods_id,
-- 购买数量 nums);
CREATE TABLE purchase(order_id INT PRIMARY KEY,customer_id CHAR(8) NOT NULL DEFAULT '',-- 外键约束在后goods_id INT NOT NULL DEFAULT 0,-- 外键约束在后nums INT NOT NULL DEFAULT 0,FOREIGN KEY(customer_id) REFERENCES customer(customer_id),FOREIGN KEY(goods_id) REFERENCES goods(goods_id));
DESC goods;
DESC customer;
DESC purchase;
20. 自增长
- 基本介绍

- 使用细节

-- 演示自增长的使用
-- 创建表
CREATE TABLE t24(id INT PRIMARY KEY AUTO_INCREMENT,email VARCHAR(32) NOT NULL DEFAULT '',`name` VARCHAR(32) NOT NULL DEFAULT '');
DESC t24;-- 测试自增长的使用
INSERT INTO t24VALUES(NULL,'tom@qq.com','tom');INSERT INTO t24(email, `name`) VALUES('xjz@sohu.com', 'xjz');SELECT * FROM t24;-- 修改默认的自增长开始值
ALTER TABLE t25 AUTO_INCREMENT = 100;
CREATE TABLE t25(id INT PRIMARY KEY AUTO_INCREMENT,email VARCHAR(32) NOT NULL DEFAULT '',`name` VARCHAR(32) NOT NULL DEFAULT '');
INSERT INTO t25VALUES(NULL, 'mary@qq.com', 'mary');
INSERT INTO t25VALUES(666, 'xjz@qq.com', 'xjz')SELECT * FROM t25;

21. mysql 索引
21.1 索引快速入门

-- 创建测试数据库 tmp
CREATE DATABASE tmp;CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
) ;#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);DELIMITER $$#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'DECLARE chars_str VARCHAR(100) DEFAULT'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT '';DECLARE i INT DEFAULT 0; WHILE i < n DO# concat 函数 : 连接函数mysql函数SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i = i + 1;END WHILE;RETURN return_str;END $$#这里我们又自定了一个函数,返回一个随机的部门号
CREATE FUNCTION rand_num( )
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(10+RAND()*500);
RETURN i;
END $$#创建一个存储过程, 可以添加雇员
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 把autocommit设置成0#autocommit = 0 含义: 不要自动提交SET autocommit = 0; #默认不提交sql语句REPEATSET i = i + 1;#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表INSERT INTO emp VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num());UNTIL i = max_numEND REPEAT;#commit整体提交所有sql语句,提高效率COMMIT;END $$#添加8000000数据
CALL insert_emp(100001,8000000)$$#命令结束符,再重新设置为;
DELIMITER ;SELECT * FROM emp;-- 在没有创建索引时,我们的查询一条记录
SELECT * FROM empWHERE empno = 1234567;
-- 使用索引来优化一下,体验索引的 牛-- 在没有创建索引前,emp.ibd 文件大小是 524m
-- 创建索引后 emp.ibd 文件大小 是 655m[索引本身也会占用空间]
-- 创建 ename 列索引,emp.ibd 文件大小 是 827m-- empno_index 索引名称
-- ON emp (empno) : 表示在 emp 表的 empno 列创建索引
CREATE INDEX empno_index ON emp (empno)-- 创建索引后, 查询的速度如何SELECT *FROM empWHERE empno = 1234578 -- 0.001s 原来是 7.1s-- 创建索引后,只对创建了索引的列有效
SELECT *FROM empWHERE ename = 'PjDlwy' -- 没有在 ename 创建索引时,时间 6.4sCREATE INDEX ename_index ON emp (ename) -- 在 ename 上创建索引
21.2 索引的原理 ★

21.3 索引的类型

21.4 索引使用


-- 演示 mysql 的索引和使用
-- 创建索引
CREATE TABLE t26(id INT,`name` VARCHAR(32));-- 查询表是否有索引
SHOW INDEXES FROM t26;
-- 添加索引
-- 添加唯一索引
CREATE UNIQUE INDEX id_index ON t26(id);
-- 添加普通索引方式 1
CREATE INDEX id_index ON t26(id);-- 如何选择
-- 1. 如果某列的值,是不会重复的。则优先考虑使用 unique索引,否则使用普通索引
-- 添加普通索引方式 2
ALTER TABLE t26 ADD INDEX id_index(id);-- 添加主键索引
CREATE TABLE t27(id INT,`name` VARCHAR(32));
ALTER TABLE t27 ADD PRIMARY KEY (id);SHOW INDEXES FROM t26;
SHOW INDEXES FROM t27;-- 删除索引
DROP INDEX id_index ON t26;
-- 删除主键索引
ALTER TABLE t27 DROP PRIMARY KEY;-- 修改索引, 先删除,再添加新的索引-- 查询索引
-- 1. 方式
SHOW INDEX FROM t26
-- 2. 方式
SHOW INDEXES FROM t26
-- 3. 方式
SHOW KEYS FROM t26;
-- 4. 方式
DESC t26
21.5 索引课堂练习


-- 创建课后练习 tmp1 数据库
CREATE DATABASE tmp2;
-- 1. 建立索引(主键)课后练习
CREATE TABLE `order`(id INT, -- id 号`name` VARCHAR(32), -- 商品名buy_per VARCHAR(32), -- 订购人num INT);
-- id号为主键 方式 1
ALTER TABLE `order` ADD PRIMARY KEY (id);
-- id号为主键 方式 2
CREATE TABLE `order2`(id INT PRIMARY KEY, -- id 号`name` VARCHAR(32), -- 商品名buy_per VARCHAR(32), -- 订购人num INT);-- 建立索引(唯一)课后练习
CREATE TABLE menu(id INT,`name` VARCHAR(32),price DECIMAL(10,2));
-- 方式 1
CREATE UNIQUE INDEX id_index ON menu(`name`);
ALTER TABLE menu ADD PRIMARY KEY (id);
SHOW INDEX FROM menu;-- 方式 2
CREATE TABLE menu2(id INT PRIMARY KEY,`name` VARCHAR(32),price DECIMAL(10,2));
ALTER TABLE menu2 ADD UNIQUE (`name`); -- 创建唯一索引
SHOW INDEXES FROM menu2;-- 建立索引(普通)课堂练习
CREATE TABLE sportman(id INT PRIMARY KEY,`name` VARCHAR(32),hobby VARCHAR(32));
-- 方式 1
CREATE INDEX name_index ON sportman(`name`);-- 创建普通索引
SHOW INDEX FROM sportman;-- 方式 2
CREATE TABLE sportman2 (id INT,`name` VARCHAR(32),hobby VARCHAR(32));
ALTER TABLE sportman2 ADD PRIMARY KEY (id); -- 建立主索引
CREATE INDEX name_index ON sportman2(`name`); -- 建立普通索引
SHOW INDEXES FROM sportman2;
21.6 小结:哪些列上适合使用索引

22. mysql 事务
22.1 什么是事务
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功,要么全部失败。如:转账就要用事务来处理,用以保证数据的一致性。

22.2 事务和锁
当执行事务操作时(dml语句),mysql会在表上加锁,防止其他用户改表的数据,这对用户来讲是非常重要的。

-- 事务的一个重要的概念和具体操作
-- 看一个图[看示意图]
-- 演示
-- 1. 创建一张测试表
CREATE TABLE t28(id INT,`name` VARCHAR(32));-- 2. 开始事务
START TRANSACTION;-- 3. 设置保存点
SAVEPOINT a-- 执行 dml 操作
INSERT INTO t28 VALUES(100,'tom');
SELECT * FROM t28SAVEPOINT b
-- 执行 dml 操作
INSERT INTO t28 VALUES(200,'jack');-- 回退 到 b
ROLLBACK TO b;
SELECT * FROM t28-- 继续回退 a
ROLLBACK TO a-- 如果这样,表示直接回退到事务开始的状态
ROLLBACK
COMMIT
22.3 回退事务

22.4 提交事务

22.5 事务细节讨论

transaction_detail.sql
-- 讨论 事务细节
-- 1. 如果不开始事务,默认情况下,dml 操作是自动提交的,不能回滚
INSERT INTO t28 VALUES(300,'malan'); -- 自动提交 commitSELECT * FROM t28-- 2. 如果开始一个事务,你没有创建保存点. 你可以执行 rollback,
-- 默认就是回退到你事务开始的状态
START TRANSACTION
INSERT INTO t28 VALUES(400,'king');
INSERT INTO t28 VALUES(500,'scott');
ROLLBACK -- 表示直接回退到事务开始的状态
COMMIT;-- 3. 你也可以在这个事务中(还没有提交时), 创建多个保存点.比如: savepoint aaa; ]
-- 执行 dml , savepoint bbb-- 4. 你可以在事务没有提交前,选择回退到哪个保存点
-- 5. InnoDB 存储引擎支持事务 , MyISAM 不支持
-- 6. 开始一个事务 start transaction, set autocommit=off;
23. mysql 事务隔离级别
23.1 事务隔离级别介绍

23.2 查看事务隔离级别

23.3 事务隔离级别
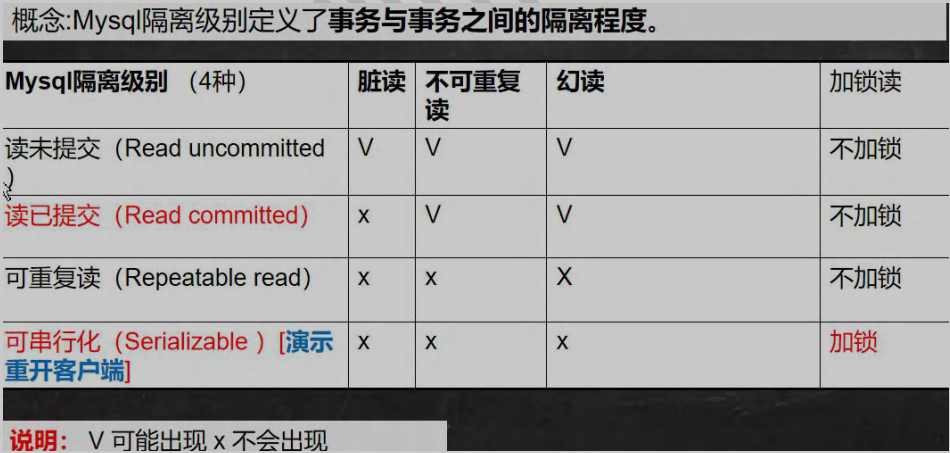
-
注意:
-
-
**可重复读:**当事务A提交后,则事务B不会产生(脏读、可重复读、幻读),如果想查看事务A 提交了哪些事务,则事务B 也要commit,提交事务才可看到事务A 进行了那些操作。
事务A:
事务B:

-
-
- **可串行化:**如果事务A 不commit,则事务B 查询时会停在查询窗口,超时自动返回查询失败。只有当事务A commit后,事务B 才可查询到事务A 提交的事务。


超时提示失败

提交事务A后,事务B才可查询
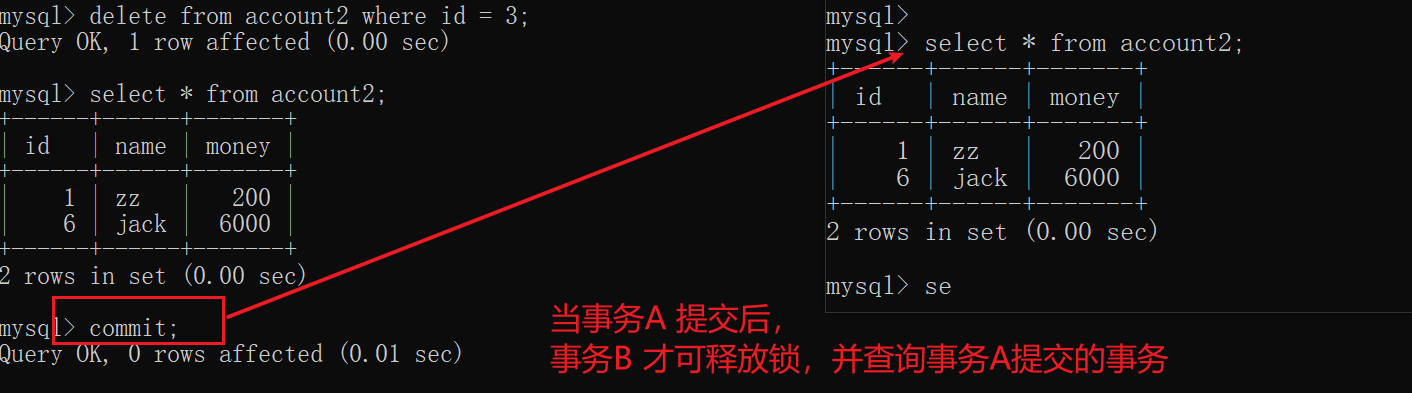
23.4 mysql 的事务隔离级别–案例

23.5 设置事务隔离级别


-- 演示 mysql 的事务隔离级别-- 1. 开了两个 mysql 的控制台
-- 2. 查看当前 mysql 的隔离级别
SELECT @@tx_isolation;-- mysql> SELECT @@tx_isolation;
-- +-----------------+
-- | @@tx_isolation |
-- +-----------------+
-- | REPEATABLE-READ |
-- +-----------------+-- 3.把其中一个控制台的隔离级别设置 Read uncommitted
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED-- 4. 创建表
CREATE TABLE `account`(id INT, `name` VARCHAR(32),money INT);-- 查看当前会话隔离级别
SELECT @@tx_isolation
-- 查看系统当前隔离级别
SELECT @@global tx_isolation
-- 设置当前会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- 设置系统当前隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL [你设置的级别]
24. mysql 事务 ACID

25. mysql 表类型和存储引擎
25.1 基本介绍

25.2 主要的存储引擎/表类型特点

25.3 细节说明
这里重点给大家介绍三种: MyISAM、InnoDB、MEMORY

25.4 三种存储引擎表使用案例
对前面我们提到的三种存储引擎,我们举例说明:
-- 表类型和存储引擎-- 查看所有的存储引擎
-- innodb 存储引擎,是前面使用过
-- 1. 支持事务 2. 支持外键 3. 支持行级锁-- myisam 存储引擎
CREATE TABLE t29(id INT,`name` VARCHAR(32)) ENGINE MYISAM;-- 1. 添加速度快 2. 不支持外键和事务 3. 支持表级锁START TRANSACTION;
SAVEPOINT t1;INSERT INTO t29 VALUES(1,'jack');
SELECT * FROM t29;
ROLLBACK TO t1; -- 回滚无效,插入的记录仍然显示,因为myisam不支持事务~-- memory 存储引擎
-- 1. 数据存储在内存中[关闭了 mysql 服务,数据丢失,但是表结构还在]
-- 2. 执行速度很快(没有IO读写) 3. 默认支持索引(hash 表)CREATE TABLE t30(id INT,`name` VARCHAR(32)) ENGINE MEMORY;
DESC t30;
INSERT INTO t30 VALUES(1,'tom'),(2,'jack'),(3,'xjz');
SELECT * FROM t30;-- 指令修改存储引擎
ALTER TABLE t30 ENGINE INNODB;
25.5 如何选择表的存储引擎

25.6 修改存储引擎

26. 视图(view)
26.1 基本概念


26.2 视图的基本使用

26.3 完成提出的需求 view.sql


-- 视图的使用
-- 创建一个视图 emp_view01,只能查询 emp表的(empno、ename、job 和 deptno)信息-- 创建视图
CREATE VIEW emp_view01ASSELECT empno, ename, job, deptno FROM emp;-- 查看视图
DESC emp_view01;SELECT * FROM emp_view01;
SELECT empno, job FROM emp_view01;-- 查看创建视图的指令
SHOW CREATE VIEW emp_view01;
-- 删除视图
DROP VIEW emp_view01;-- 视图的细节
-- 1. 创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式: 视图名.frm)
-- 2. 视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete ]-- 修改视图 会影响到基表UPDATE emp_view01SET job = 'MANAGER'WHERE empno = 7369;SELECT * FROM emp; -- 查询基表SELECT * FROM emp_view01;-- 修改基本表,也会影响到视图UPDATE empSET job = 'SALESMAN'WHERE empno = 7369;-- 3. 视图中可以再使用视图,比如从 emp_view01 视图中,选出 empno 和 ename 做出新视图
DESC emp_view01;CREATE VIEW emp_view02AS SELECT empno,ename FROM emp_view01;SELECT * FROM emp_view02;
26.4 视图细节讨论

26.5 视图最佳实践

26.6 视图课堂练习

-- 视图的课堂练习
-- 针对 emp ,dept , 和 salgrade 张三表.创建一个视图 emp_view03,
-- 可以显示雇员编号,雇员名,雇员部门名称和 薪水级别[即使用三张表,构建一个视图]
-- emp.empno emp.ename dept.dname salgrade.gradeCREATE VIEW emp_view03ASSELECT empno, ename, dname, gradeFROM emp,dept,salgradeWHERE emp.deptno = dept.deptnoAND (sal BETWEEN losal AND hisal);SELECT * FROM emp;
SELECT * FROM dept;
SELECT * FROM salgrade;SELECT * FROM emp_view03;
27. MySQL 管理
27.1 MySQL用户

27.2 创建用户

27.3 删除用户

27.4 用户修改密码

27.5 mysql 中的权限

27.6 给用户授权

27.7 回收用户授权

27.8 权限生效指令

27.9 课堂练习题 grant.sql

-- 演示 用户权限的管理-- 创建用户 jinzhuo 密码 123 , 从本地登录
CREATE USER 'jinzhuo'@'localhost' IDENTIFIED BY '123'-- 使用 root用户创建 testdb 数据库,表 news
CREATE DATABASE testdb;
CREATE TABLE news(id INT,content VARCHAR(32));
-- 添加一条测试数据
INSERT INTO news VALUES(100,'北京新闻');
SELECT * FROM news;-- 给 jinzhuo 分配查看 news 表 和 添加 news的权限
GRANT SELECT,INSERTON testdb.newsTO 'jinzhuo'@'localhost'-- 可以增加 update 权限
GRANT UPDATEON testdb.newsTO 'jinzhuo'@'localhost'-- 修改 jinzhuo 的密码为 abc
SET PASSWORD FOR 'jinzhuo'@'localhost' = PASSWORD('abc');-- 回收 jinzhuo 用户名在 testdb.news 表的所有权限
REVOKE SELECT, UPDATE, INSERT ON testdb.news FROM 'jinzhuo'@'localhost';
REVOKE ALL ON testdb.news FROM 'jinzhuo'@'localhost';-- 删除 jinzhuo 用户
DROP USER 'jinzhuo'@'localhost';
27.10 细节说明

-- 说明 用户管理的细节
-- 在创建用户的时候,如果不指定 Host,则为%,%表示表示所有 IP 都有连接权限
-- create user xxx;CREATE USER jack;SELECT `host`,`user` FROM mysql.user;-- 你也可以这样指定
-- create user 'xxx'@'192.168.1.%' 表示 xxx 用户在 192.168.1.*的 ip 可以登录 mysqlCREATE USER 'smith'@'192.168.1.%';-- 在删除用户的时候,如果 host 不是 %,需要明确指定 '用户'@'host 值'DROP USER jack; -- 默认就是 DROP USER 'jack'@'%'DROP USER 'smith'@'192.168.a1.%'

28. 本章作业
如果定义别名省略 AS的话,后面最多有一个单词,如果中间有空格需要用双引号包起来“”,否则报错 error


-- 3.使用简单查询语句完成
-- (1)显示所有部门名称
SELECT dname FROM dept;-- (2)显示所有雇员名及其全年收入 13月(工资+补助),并指定列别名'年收入'
SELECT ename,(sal+IFNULL(comm,0))*13 AS '年收入' FROM emp;-- 4.限制查询数据
-- (1) 显示工资超过2850的雇员姓名和工资
SELECT ename, sal FROM empWHERE sal > 2850;-- (2) 显示工资不在1500到2850之间的所有雇员名及工资
SELECT ename, sal FROM empWHERE sal<1500 OR sal >2850;-- 方法 2
SELECT ename, sal FROM empWHERE NOT (sal>=1500 OR sal <=2850);-- (3) 显示编号为7566的雇员姓名及所在部门编号
SELECT ename, deptno FROM empWHERE empno = 7566;-- (4) 显示部门 10 和 30中工资超过1500的雇员名及工资
SELECT ename, sal FROM empWHERE (deptno = 10 OR deptno = 30)AND sal > 1500-- (5) 显示无管理者的雇员名及岗位
SELECT ename, job FROM empWHERE mgr IS NULL;-- 5. 排序数据
-- (1) 显示在1991年2月1日到1991年5月1日之间雇佣的雇员名,岗位及雇用日期,并以雇佣日期进行排序
SELECT * FROM emp;
SELECT ename, job, hiredate FROM empWHERE hiredate BETWEEN '1991-2-1' AND '1991-5-1'ORDER BY hiredate;
-- (2)显示获得补助的所有雇员名,工资及补助,并以工资降序排序
SELECT ename,sal,comm FROM empWHERE comm IS NOT NULLORDER BY sal DESC;


-- 6. 根据 emp员工表 写出正确的SQL语句-- 1.选择部门30中的所有员工
SELECT * FROM empWHERE deptno = 30;-- 2.列出所有办事员(CLERK)的姓名,编号,部门编号
SELECT ename, empno, deptno, jobFROM empWHERE job = 'CLERK';-- 3.找出佣金高于薪金的员工
SELECT * FROM empWHERE IFNULL(comm,0) > sal;-- 4. 找出佣金高于薪金60%的员工
SELECT * FROM empWHERE IFNULL(comm,0) > sal*0.6;-- 5. 找出部门10中所有经理(MANAGER)和部门20中所有办事员(CLERK)的详细资料
SELECT * FROM empWHERE (deptno = 10 AND job = 'MANAGER')OR (deptno = 20 AND job = 'CLERK');-- 6. 找出部门10中所有经理(MANAGER),部门20中所有办事员(clerk),还有既不是经理又不是办事员
-- 但其工资大于或等于2000的所有员工的资料
SELECT *FROM empWHERE (deptno = 10 AND job = 'MANAGER')OR (deptno = 20 AND job = 'CLERK')OR (job != 'MANAGER' AND job <> 'CLERK' AND sal >= 2000);-- 7.找出收取佣金的员工的不同工作 -- (DISTINCT)
SELECT DISTINCT jobFROM empWHERE comm IS NOT NULL;-- 8.找出不收取佣金或收取的佣金低于100的员工
SELECT *FROM empWHERE comm IS NULL OR IFNULL(comm,0) < 100;-- 9. 找出各月倒数第 3 天受雇的所有员工
-- 代码提示:LAST_DAY(日期):可以返回该日期返回所在月份的最后一天SELECT *FROM empWHERE LAST_DAY(hiredate) - 2 = hiredate;-- 10.找出早于12年前受雇的员工。(即:入职时间超过12年)
SELECT * FROM empWHERE DATE_ADD(hiredate,INTERVAL 12 YEAR) < NOW();-- 11.以首字母小写的方式显示所有员工的姓名
SELECT CONCAT(LCASE(LEFT(ename,1)),SUBSTRING(ename,2)) AS new_nameFROM emp; -- 12.显示正好为5个字符的员工的姓名
SELECT * FROM empWHERE LENGTH(ename)=5;-- 13.显示不带有"R"的员工的姓名
SELECT *FROM empWHERE ename NOT LIKE '%R%';-- 14.显示所有员工姓名的前三个字符
SELECT LEFT(ename,3)FROM emp;-- 15. 显示所有员工的姓名,用a替换所有A
SELECT REPLACE(ename,'A','a')FROM emp;-- 16. 显示满10年服务年限的员工的姓名和受雇日期
SELECT ename, hiredateFROM empWHERE DATE_ADD(hiredate,INTERVAL 10 YEAR) <= NOW();-- 17. 显示员工的详细资料,按姓名排序
SELECT *FROM empORDER BY ename;-- 18. 显示员工的姓名和受雇日志,根据其服务年限,将最老的员工排在最前面
SELECT ename,hiredateFROM empORDER BY hiredate;-- 19. 显示所有员工的姓名、工作和工资,按工作降序排序,若工作相同则按工资排序
SELECT ename, job, sal FROM empORDER BY job DESC, sal;-- 20. 显示所有员工的姓名,加入公司的年份和月份,按受雇日期所在月排序,
-- 若月份相同则将最早月份的员工排在最前面
SELECT ename, CONCAT(YEAR(hiredate),'-',MONTH(hiredate))FROM empORDER BY MONTH(hiredate),YEAR(hiredate);-- 21. 显示在一个月为30天的情况所有员工的日薪金,忽略余数
SELECT FLOOR(sal / 30),sal / 30 -- FLOOR 向下取整,忽略余数FROM emp;-- 22.找出在(任何年份的)2月受聘的所有员工
SELECT *FROM empWHERE MONTH(hiredate) = 2;-- 23.对于每个员工,显示其加入公司的天数
SELECT DATEDIFF(NOW(),hiredate)FROM emp;-- 24.显示姓名字段的任何位置包含“A"的所有员工的姓名
SELECT *FROM empWHERE ename LIKE '%A%';-- 25. 以年月日的方式显示所有员工的服务年限(大概)
SELECT ename, FLOOR(DATEDIFF(NOW(), hiredate) / 365) AS '工作年',FLOOR(DATEDIFF(NOW(), hiredate) % 365 / 31) AS '工作月',DATEDIFF(NOW(),hiredate) % 31 AS '工作天'FROM emp;


-- 根据: emp员工表, dept部门表,工资 = 薪金sal + 佣金comm 写出正确SQLSELECT * FROM emp;
SELECT * FROM dept;-- (1)列出至少有一个员工的所有部门 --》 group by -> having/*先查出各个部门有多少人使用 having 子句过滤
*/
SELECT COUNT(*) AS c, deptnoFROM empGROUP BY deptnoHAVING c > 1;-- (2)列出薪金比 'SMITH' 多的所有员工 -- 子查询
/*先查出 smith 的 sal => 子查询然后其他员工 sal 大于 smith 即可
*/
SELECT * FROM empWHERE sal > (SELECT salFROM empWHERE ename = 'SMITH');-- (3)列出受雇日期晚于其直接上级的所有员工 -- 自连接
/*先把 emp 表 当做两张表 worker, leader条件 1. worker.mgr = leader.empno2. worker.hiredate > leader.hiredate;
*/SELECT worker.ename AS '员工名', worker.hiredate AS '员工入职时间',leader.ename AS '上级名', leader.hiredate AS '上机入职时间'FROM emp worker, emp leaderWHERE worker.mgr = leader.empnoAND worker.hiredate > leader.hiredate;-- (4)列出部门名称和这些部门的员工信息,同时列出哪些没有员工的部门 --> 外连接
/*因为这里需要显示所有部门,因此考虑使用外连接。(左外连接)
*/
SELECT dname, emp.*FROM dept LEFT JOIN empON emp.deptno = dept.deptno;-- (5)列出所有 'CLERK' (办事员)的姓名及其部门名称 -- 多表查询
SELECT ename, dname, jobFROM emp, deptWHERE job = 'CLERK'AND emp.deptno = dept.deptno;-- (6)列出最低薪金大于1500的各种工作
/*查询各个部门的最低工资使用 having 子句进行过滤
*/
SELECT job, MIN(sal) AS min_salFROM empGROUP BY jobHAVING min_sal > 1500;-- (7)列出在部门 'SALES' (销售部)工作的员工的姓名 -> 多表查询
SELECT ename,dnameFROM emp, deptWHERE dname = 'SALES'AND emp.deptno = dept.deptno;-- (8)列出薪金高于公司平均薪金的所有员工
/*先查出公司平均薪金 => 子查询然后其他员工 sal 高于 平均薪金 即可
*/
SELECT * FROM empWHERE sal > (SELECT AVG(sal)FROM emp);-- (9)列出与'SCOTT'从事相同工作的所有员工
SELECT *FROM empWHERE job = (SELECT jobFROM empWHERE ename = 'SCOTT') AND ename != 'SCOTT';-- (10)列出薪金高于部门30的工作的所有员工的薪金的员工姓名和薪金-- 先查询出30部门的最高工资
SELECT ename, salFROM empWHERE sal > (SELECT MAX(sal)FROM empWHERE deptno = 30);-- (11)列出在每个部门工作的员工数量,平均工资和平均服务期限
SELECT COUNT(*) AS '部门员工数量', deptno, AVG(sal) AS '平均工资',FORMAT(AVG(DATEDIFF(NOW(),hiredate) / 365), 2) AS '平均服务期限'FROM empGROUP BY deptno;-- (12)列出所有员工的姓名、部门名称和工资 多表查询
SELECT ename, dname, (sal + IFNULL(comm,0)) AS sal_countFROM emp, deptWHERE emp.deptno = dept.deptno;-- (13)列出所有部门的详细信息和部门人数-- 1. 先得到各个部门的人数,把下面的结果看成临时表 和 dept表联合查询
SELECT COUNT(*) AS c, deptnoFROM empGROUP BY deptno;
-- 2.
SELECT dept.*, tmp.cFROM dept, (SELECT COUNT(*) AS c, deptnoFROM empGROUP BY deptno) tmpWHERE dept.deptno = tmp.deptno;-- (14)列出各种工作的最低工资
SELECT job, MIN(sal)FROM empGROUP BY job-- (15)列出MANAGER(经理)的最低薪金
SELECT job, MIN(sal)FROM empWHERE job = 'MANAGER'-- (16)列出所有员工的年工资,按年薪从低到高排序
SELECT ename, (sal+IFNULL(comm,0))*12 AS year_salFROM empORDER BY year_sal


-- 班级表
CREATE TABLE class(classid INT PRIMARY KEY,`subject` VARCHAR(32) NOT NULL DEFAULT '',deptname VARCHAR(32), -- 外键字段,在表定义后指定enrolltime INT NOT NULL DEFAULT 2000,num INT NOT NULL DEFAULT 0,FOREIGN KEY(deptname) REFERENCES department(deptname));-- 学生表
CREATE TABLE student(studentid INT PRIMARY KEY,`name` VARCHAR(32) NOT NULL DEFAULT '',age INT NOT NULL DEFAULT 0,classid INT, -- 外键FOREIGN KEY(classid) REFERENCES class(classid));
-- 系表
CREATE TABLE department(departmentid CHAR(3) PRIMARY KEY,deptname VARCHAR(32) UNIQUE NOT NULL);-- 添加测试数据
INSERT INTO department VALUES('001', '数学');
INSERT INTO department VALUES('002', '计算机');
INSERT INTO department VALUES('003', '化学');
INSERT INTO department VALUES('004', '中文');
INSERT INTO department VALUES('005', '经济');INSERT INTO class VALUES(101,'软件','计算机',1995,20);
INSERT INTO class VALUES(102,'微电子','计算机',1996,30);
INSERT INTO class VALUES(111,'无机化学','化学',1995,29);
INSERT INTO class VALUES(112,'高分子化学','化学',1996,25);
INSERT INTO class VALUES(121,'统计数学','数学',1995,20);
INSERT INTO class VALUES(131,'现代语言','中文',1996,20);
INSERT INTO class VALUES(141,'国际贸易','经济',1997,30);
INSERT INTO class VALUES(142,'国际金融','经济',1996,14);INSERT INTO student VALUES(8101,'张三',18,101);
INSERT INTO student VALUES(8102,'钱四',16,121);
INSERT INTO student VALUES(8103,'王玲',17,131);
INSERT INTO student VALUES(8105,'李飞',19,102);
INSERT INTO student VALUES(8109,'赵四',18,141);
INSERT INTO student VALUES(8110,'李可',20,142);
INSERT INTO student VALUES(8201,'张飞',18,111);
INSERT INTO student VALUES(8302,'周瑜',16,112);
INSERT INTO student VALUES(8203,'王亮',17,111);
INSERT INTO student VALUES(8305,'董庆',19,102);
INSERT INTO student VALUES(8409,'赵龙',18,101);
INSERT INTO student VALUES(8510,'李丽',20,142);SELECT * FROM student;
SELECT * FROM class
SELECT * FROM department
-- (3)完成一下查询功能
-- 3.1 找出所有姓李的学生
SELECT *FROM studentWHERE `name` LIKE '李%';-- 3.2 找出所有开设超过1个专业的系的名字
-- 1. 先查出各个系有多少人SELECT COUNT(*) AS c, deptnameFROM classGROUP BY deptnameHAVING c > 1;-- 3.3 找出人数大于等于30的系的编号和名字
-- 1. 先查出各个系有多少人,并得到 >= 30 的系名SELECT SUM(num) AS nums, deptnameFROM classGROUP BY deptnameHAVING nums >= 30;-- 2. 将上面的结果看成一个临时表 和 department 联合查询即可SELECT tmp.*, departmentidFROM department, (SELECT SUM(num) AS nums, deptnameFROM classGROUP BY deptnameHAVING nums >= 30) tmpWHERE department.deptname = tmp.deptname;-- 3.4 学习又新增加了一个物理系,编号为006
INSERT INTO department VALUES('006','物理系');-- 3.5 学生张三退学,请更新相关的表-- 分析:1. 张三所在班级的人数-1
-- 2. 将张三从学生表删除
-- 3. 需要使用事务控制-- 开始事务
START TRANSACTION;
-- 张三所在班级的人数 -1
UPDATE class SET num = num - 1WHERE classid = (SELECT classidFROM studentWHERE `name` = '张三');
DELETE FROM studentWHERE `name` = '张三';-- 提交事务
COMMITSELECT * FROM student;
SELECT * FROM class;



之nl)

)



)









