前言
(1)此系列文章是跟着汪辰老师的RISC-V课程所记录的学习笔记。
(2)该课程相关代码gitee链接;
(3)PLCT实验室实习生长期招聘:招聘信息链接
前置知识
RISC-V 汇编指令编码格式
(1)在学习RISC-V的反汇编之前,我们需要先知道RISC-V的编码格式,RISC-V的编码格式有如下图6种。
(2)现在我们以RV32I为例子说明。RV32I的指令长度为32位,因此我们每次读取指令的时候,都是4字节4字节的抽取出来。
(3)RISC-V将一条指令分为了多个域(field),例如下面的R-type格式中32bit,有funct7,rs2,rs1,funct3,rd,opcode6个域(field)。每个域(field)都有自己的含义。
<1>funct3/funct7和opcode一起决定最终的指令类型。
<2>rs1,rs2表示寄存器被操作的寄存器。rd表对操作结束后,存放值的寄存器。
<3>imm,表示立即数,即一个有效数据。

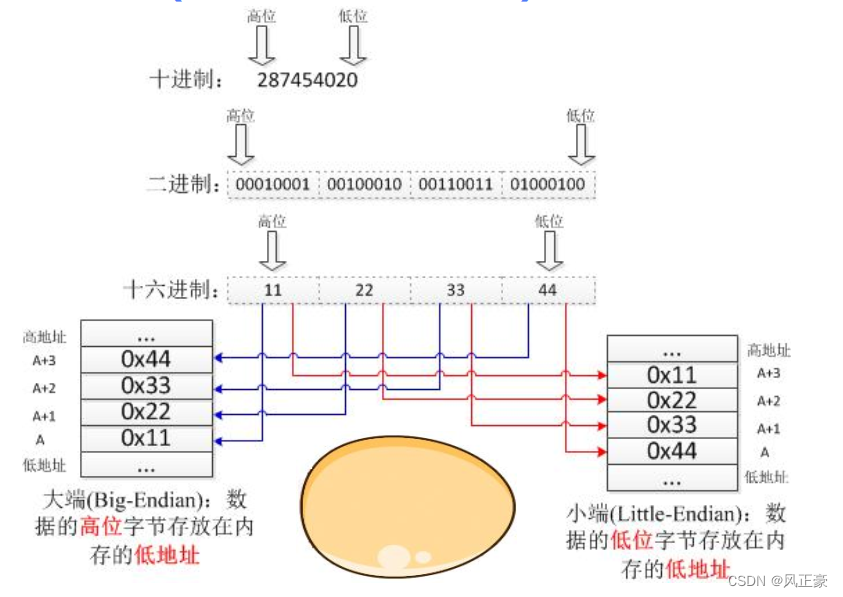
大端序和小端序
(1)现在知道了RISC-V的数据长度和存储格式之后,我们还需要知道数据如何摆放的。这个就和C语言的大小端意思类似。
(2)RISC-V的指令在内存中按照 小端序 排列。
(3)大小端序就是看高位还是低位数据谁存放在低地址。大端序,高位数据存放在低地址。小端序,低位数据存放在低地址。为了方便理解,我举个例子。假设我们有数据地址从低到高:0x00 0x11 0x22 0x33 0x44 0x55 0x66 0x77。
<1>首先抽4字节取出数据,0x00 0x11 0x22 0x33,0x44 0x55 0x66 0x77。
<2>小端序,低位数据放在低地址,所以实际上读取的数据是0x33221100和0x77665544。
<3>大端序,高位数据放在低地址,所以实际上读取的数据是0x00112233和0x44556677。
实操
(1)很好,有了上面的认知之后,我们就可以开始反汇编了。现在我们尝试反汇编下面这四条汇编代码。
<1>首先,依照惯例,四字节抽取数据。
<2>因为RISC-V的指令是小端序,所以需要修改一下顺序。
<3>上面说了,funct3/funct7和opcode一起决定最终的指令类型。也就是bit[0:6],bit[12:14],bit[25:31]。从RISC-V 汇编指令编码格式可以知道,RISC-V有6种编码格式,但是一定会有opcode,因此,我们优先查看bit[0:6]。
<4>根据bit[0:6]我们即可知道此条命令的格式,如果没有funct3/funct7,那么这条命令就找到了,否则就开始对比funct3,如果之后还有funct7继续对比,最后就可以找到指令了。
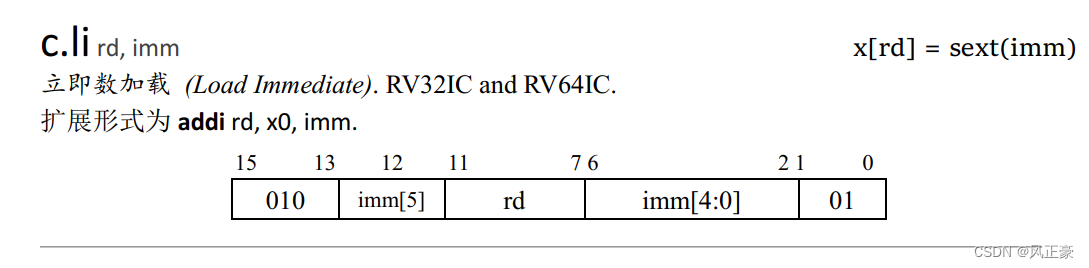
_start:li x6,1li x7,-2add x5,x6,x7
stopj stop
-----------------
//四字节抽取数据
1303 1000
9303 e0ff
b302 7300
6f00 0000
-----------------
//小端序存储,改变数据位置
0010 0313
ffe0 0393
0073 02b3
0000 006f

(2)按照上述步骤,想必大家一定找到的是如下三条指令。

(3)这个时候肯定就会有人要问了,我们的汇编代码里面明明是
j和li命令呀,怎么这里找到的是jal和addi呢?这个就又涉及到另外的一个知识点了 — 伪指令。为了简化编程难度,大佬们将一些特殊的指令用基础指令封装起来了。这个有点类似与C语言的宏定义,如下:
#define register_base 0x6666
#define register_a register_base
#define register_b register_base + 0x08

参考
(1)riscv-spec-20191213.pdf;
(2)汪辰老师公开课;
(3)汪辰老师公开课第五课课件;
(4)大端序(Big-endian)和小端序(Little-endian)网络字节序;
(5)RISC-V-Reader-Chinese-v2p1.pdf;






 - 附代码)












