1、import所需要的torch库和包

2、加载mnist手写数字数据集,划分训练集和测试集,转化数据格式,batch_size设置为200
3、定义三层线性网络参数w,b,设置求导信息

4、初始化参数,这一步比较关键,是否初始化影响到数据质量以及后续网络学习效果

5、自定义三层线性网络

6、选定优化器激活函数和loss函数

7、训练及测试,并记录每轮训练的loss变化和在测试集上的效果。第一轮就达到了98的准确度,判断是初始化效果较好,在前几次测试中根据初始化的情况不同,初始准确率为50%-85%不等
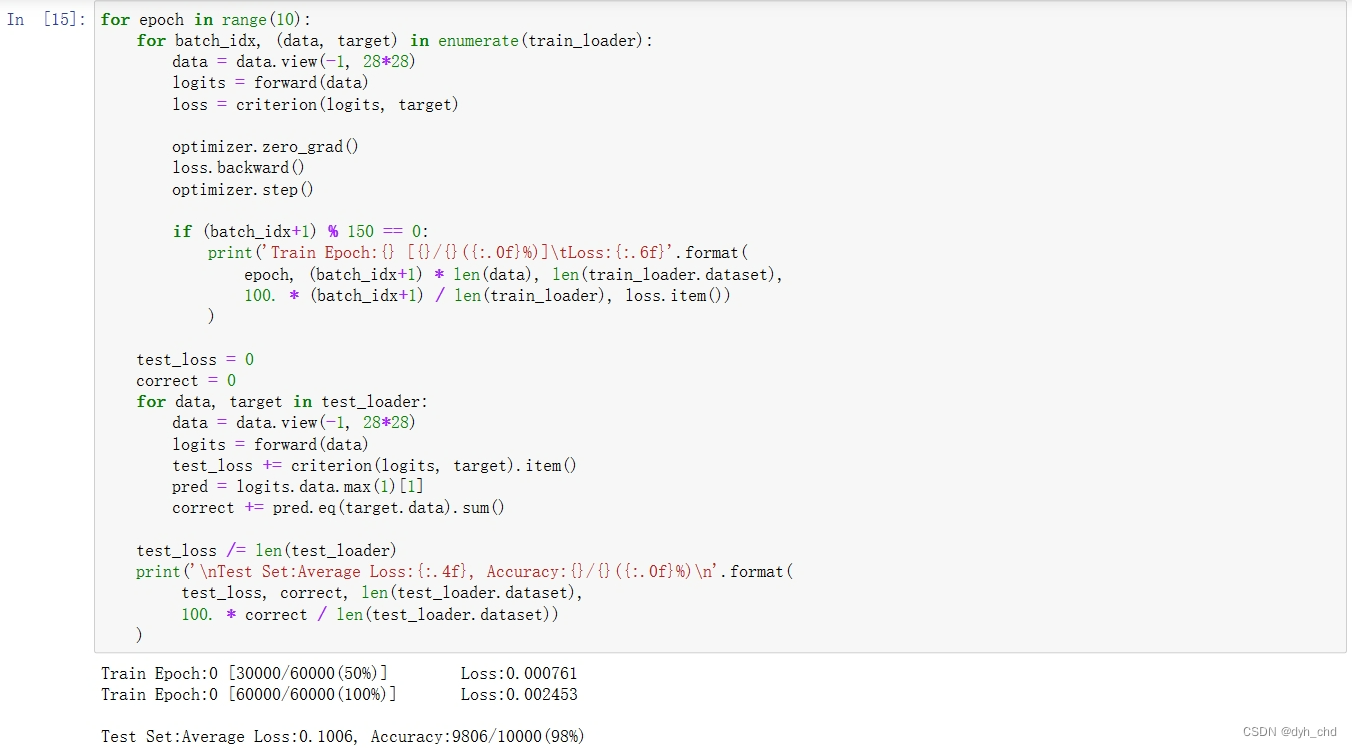
完整代码:
import torch
import torchvision
import torch.nn.functional as Ftrain_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307, ), (0.3081, ))])),batch_size=200, shuffle=True)test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307, ), (0.3081, ))])),batch_size=200, shuffle=True)w1 = torch.randn(200, 784, requires_grad=True)
b1 = torch.randn(200, requires_grad=True)
w2 = torch.randn(200, 200, requires_grad=True)
b2 = torch.randn(200, requires_grad=True)
w3 = torch.randn(10, 200, requires_grad=True)
b3 = torch.randn(10, requires_grad=True)torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)def forward(x):x = x@w1.t() +b1x = F.relu(x)x = x@w2.t() +b2x = F.relu(x)x = x@w3.t() +b3x = F.relu(x)return xoptimizer = torch.optim.Adam([w1, b1, w2, b2, w3, b3], lr=0.001)
criterion = torch.nn.CrossEntropyLoss()for epoch in range(10):for batch_idx, (data, target) in enumerate(train_loader):data = data.view(-1, 28*28)logits = forward(data)loss = criterion(logits, target)optimizer.zero_grad()loss.backward()optimizer.step()if (batch_idx+1) % 150 == 0:print('Train Epoch:{} [{}/{}({:.0f}%)]\tLoss:{:.6f}'.format(epoch, (batch_idx+1) * len(data), len(train_loader.dataset),100. * (batch_idx+1) / len(train_loader), loss.item()))test_loss = 0correct = 0for data, target in test_loader:data = data.view(-1, 28*28)logits = forward(data)test_loss += criterion(logits, target).item()pred = logits.data.max(1)[1]correct += pred.eq(target.data).sum()test_loss /= len(test_loader)print('\nTest Set:Average Loss:{:.4f}, Accuracy:{}/{}({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))




目录最新无死角讲解)




![[牛客习题]“幸运的袋子”](http://pic.xiahunao.cn/[牛客习题]“幸运的袋子”)









)