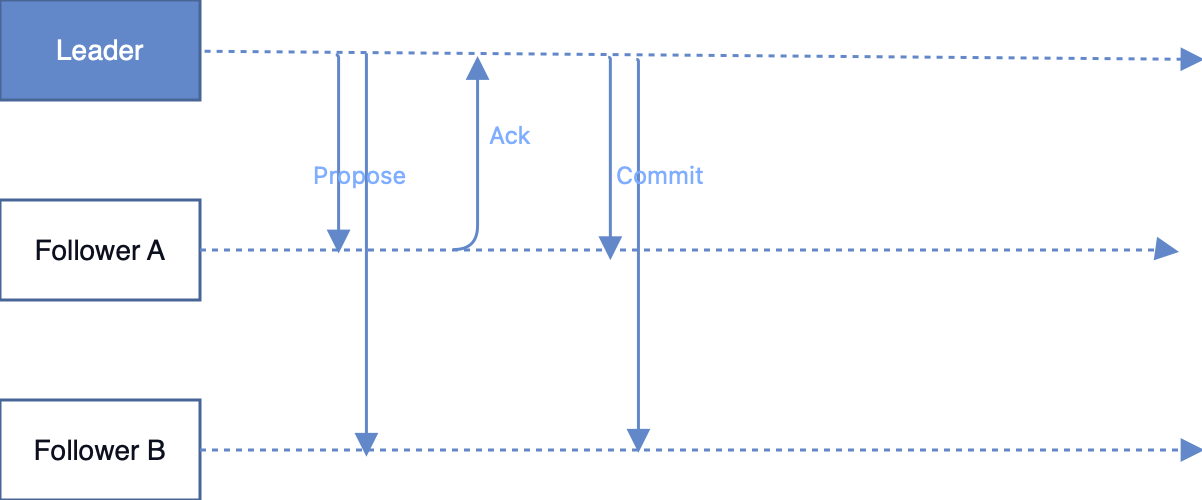
就在上个月,OpenAI 宣布对ChatGPT 进行重大更新,该模型不仅能够通过文字输入进行识别和分析,还能够通过语音、图像甚至视频等多种模态的输入来获取、识别、分析和输出信息。这一重要技术突破,将促进多模态自然语言处理的发展,为人工智能领域的发展带来广泛的影响。

OpenAI表示该功能可以应用于各种日常场景:从通过拍摄冰箱和食品储藏室的照片来让AI决定晚餐吃什么,到排除烧烤炉无法启动的原因。这意味着它可以更好地理解人类语言和图像信息,从而为各种应用提供更准确、更智能的解决方案。
GPT-4的多模态功能还可能对生成对抗网络(GAN)、强化学习、无监督和半监督学习、语义表示学习、机器翻译与多语言处理、情感计算与社交机器人等领域产生影响,推动人工智能技术的整体进步。
数据对多模态AI通用化的重要性不言而喻。对于多模态AI模型来说,不同模态之间的数据分布往往存在巨大差异,比如图像、语音、文本等。为了实现多模态AI的通用化,需要对这些数据进行标注,以便机器学习模型能够理解和处理这些数据。帮助模型更好地理解和处理这些数据,从而提高模型的准确度和性能。
景联文科技是人工智能基础行业的头部数据标注公司,可协助人工智能企业解决整个人工智能链条中数据标注环节的相对应问题。
提供多模态成品数据集,包含图像、视频、音频、文本等多种类型的数据,并提供丰富的场景和应用场景。对特定的视频内容切分和筛选,数据集包含平静、高兴、惊奇、悲伤、愤怒、恐惧等情感标签,包含对话文本内容、人物性别、人物ID信息、人物年龄段信息、对话场景(办公室、住宅、医院、餐厅、电话对话、户外、其他)等信息。
景联文科技拥有丰富的数据资源采集网络,支持人脸采集、手势采集、步态采集、掌纹采集、情绪表情采集、3D人脸采集、目标检测物品采集、手写体采集、语音识别ASR采集、语音合成TTS采集、唤醒词采集、多人对话采集、普通话采集、方言采集、英语采集、小语种采集、语音VAD采集、知识库、聊天对话采集等。先后建立杭州数据总部,武汉、金华、衡阳等不同省市数据处理分部。
自研数据标注平台和全品类标注工具,自建数据标注平台,支持计算机视觉(拉框标注、语义分割、3D点云标注、关键点标注、线标注、2D/3D融合标注、目标跟踪、图片分类等)、语音工程(语音切割、ASR语音转写、语音情绪判定、声纹识别标注等)、自然语言处理(OCR转写、文本信息抽取、NLU语句泛化)多类型数据标注。可全方位满足合作方各类数据标注需求,标注精细度达99%。支持AI算法预处理,支持本地化部署和SAAS服务,可为企业提供一体化数据采集标注方案,推动人工智能在更多地场景下实现落地应用,构建完整的AI数据生态。

景联文科技|数据采集|数据标注
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。