lambda表达式是什么?包装器又是什么?有什么作用?莫急,此篇文章将详细带你探讨它们的作用。很多同学在学习时害怕这些东西,其实都是方便使用的工具,很多情况下我们学这些新的东西觉得麻烦,累赘,其实是实践太少了。初学编程时,C语言基础不扎实,代码没敲过多少,项目没做过。听着别人说C++/Java/Python比C语言功能强大多了,赶紧去学,然而除了多记一堆的语法规则,也没有感觉到好用在哪里
归根到底,实践太少,你没有感受过一个工具带给你的不便,怎会感受到另一个更好工具带给你的舒适呢,刚学的东西还没有实践消化,立马就去学下一个,最后所获寥寥,消耗不多的热情,所以请实践起来
函数指针的不便
现在有这样一个场景,有进行加法和减法运算的函数add(), sub(),但是我们不能直接调用这两个函数,而是用统一接口fun_call来调用这两个函数,你只需要给出要运算的数字和要进行哪种操作(函数名),有fun_call在内部调用并把结果返回给你
int add(int a, int b){return a + b;}int sub(int a, int b){return a - b;}int fun_call(int tmp1, int tmp2, int(*op)(int, int)){return op(tmp1, tmp2);}
要实现这种统一调用接口,那我们就得有三个参数,两个是待操作的数字,另一个是进行某种操作的函数的指针,代码实现如上,op就是这个函数指针
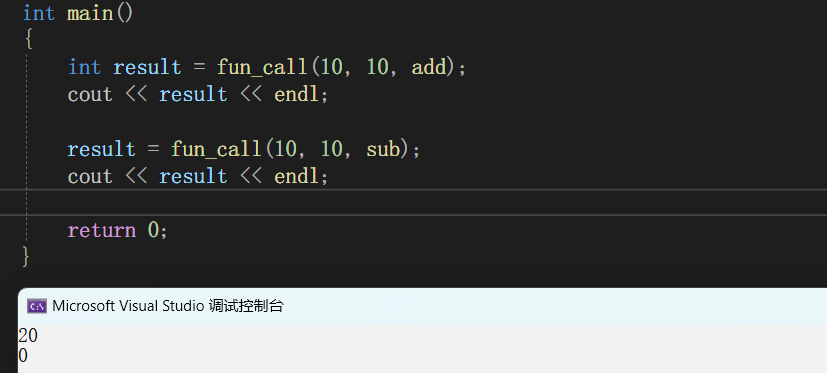
程序确实可以运行,但函数指针的写法实在不好用,看到函数指针这个参数你可能都要分析半天,如果你觉得还好,那么请看下面这个例子(出自C陷阱与缺陷)
(*(void(*)())0)()
你能分析出这是个什么类型的函数指针吗?
我们根据()的优先级,可将这个表达式分离成两部分
第一部分:(* tmp )() 里面的内容用tmp代替
第二部分:tmp == (void(*)())0
先看第二部分,void(*)()是一个返回值为void,无参的函数指针类型, 那(void(*)())0的意思就是将0强制转换成返回值为void,无参的函数指针
为什么要这么做呢?我们把强制类型转换给去掉,再看一下完整的表达式如下
(*0)(),该语句意思是用0这个地址作为函数指针来调用函数,但是0不能被直接作为函数指针来使用
所以我们要把0强制转换成一个函数指针,这样0就能被作为一个函数指针来使用了
如此以来就出现(* (void(*)())0 )()这个看起来非常复杂的式子
事实上在操作系统以及C/C++标准库中会出现大量的这种函数指针调用,如果基础不扎实的话,很容易就会被绕的晕头转向
仿函数的出现
鉴于函数指针这种写者难受,读者也难受的境况,C++推出一个名为仿函数的工具,仿函数笔者有在C++专栏中专门提到过,这里就简单的提一提,不再赘述
仿函数的解决方法就是把函数封装在类里面,并在类中重载(),这样示例化出一个对象,就可以直接当成函数来使用了,在把函数作为参数传递时,也不需传函数指针了,而是把这个类的对象传过去就可以了,如此以来就摆脱了分析函数指针的痛苦
class ADD {public:int operator()(int a, int b){return a + b;}};class SUB {public:int operator()(int a, int b){return a - b;}};template<class T> int fun_call(int tmp1, int tmp2, T op){return op(tmp1, tmp2);}
如上述代码,把add函数和sub函数分别封装在两个类中,形成两个仿函数,接下来就可以通过实例化出对象来调用这两个函数,传参的时候呢,也是直接传对象过去

lambda的出现
仿函数的出现一定程度上减轻了传函数指针的痛苦,但是这种痛苦是由分析C语言复杂的函数指针转换成对函数进行类封装的繁琐,每写一个简单功能的函数就得封装成一个类,用着用着大家就觉得仿函数还是不够方便
于是C++11就推出了lambda表达式,lambda表达式并不是C++独创的,而是其它语言先提出来的,C++委员会的人觉得lambda表达式用起来很方便,就借鉴到C++中了,所以lambda表达式看起来并不像C++的语法风格,但习惯后用起来还是很方便的
lambda书写格式:[capture-list] (parameters) mutable -> return-type { statement}
[capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推
{statement}:函数体,在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量
是不是看起来挺复杂的,其实这么多东西只有捕捉列表和函数体是必须的,其他则可以根据自己的需求选择性增添,所以最简单的lambda表达式就是 []{} ,表示什么都不做
接下来笔者逐步演示lambda表达式该如何使用,还拿我们前面的add和sub函数来举例
int main(){int val_1 = 20;int val_2 = 30;auto fun = [](int v1, int v2) {return v1 + v2;}int result = fun(val_1, val_2);cout << result << endl;return 0;}先来分析[ ](int v1, int v2) {return v1 + v2;}
[ ]用来告诉编译器这是一个lambda表达式,当然也有别的作用,我们后面再提
(int v1, int v2)就是参数列表,这个和普通函数的参数列表是一样的,接收传过来的参数
{return v1+v2;} 这个就是函数体,也就是函数具体要干什么事,我们这里要干的事就是将参数列表中的v1和v2相加然后返回
其实把[ ]去掉可以看出,lambda表达式就是一个函数定义嘛,只不过这个函数没有函数名和返回值的类型,但实际上lambda表达式的底层实现和仿函数一样,也是一个类,这也是为什么我们用auto fun来接收lambda表达式
但是请注意,lambda表达式虽然是一个类,但是没有具体的类名,这一点和仿函数很不一样,因为仿函数的类是我们自己封装的,所以我们知道具体的类名
但是lambda表达式是由编译器负责将其封装成一个类,编译器为了保证其唯一性,用随机哈希码来代表其类名,所以我们是不知道其具体的类名的,必须用auto来推导
这样看其实也能够很好理解lambda表达式,我们不是嫌弃仿函数自己手动封装类太麻烦了嘛,lambda表达式就是让编译器自动帮我们封装,我们只要把函数的具体实现传过去就可以了,不过lambda表达式的功能比仿函数还是要强大很多的,我们后面慢慢说
先看看上面程序的运行结果
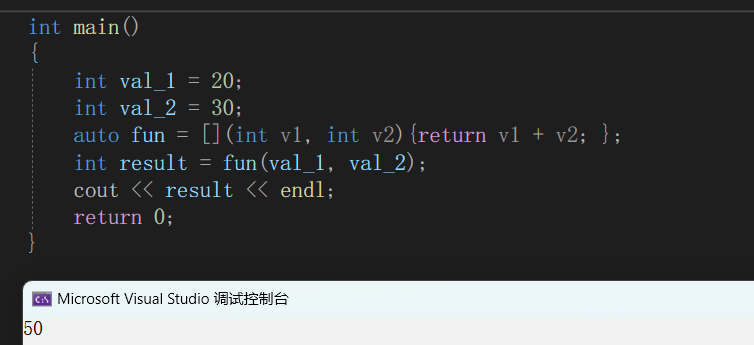
lambda表达式会自动帮我们推导返回值的类型,所以我们没有在lambda表达式中加上返回值的类型,如果你非想要指定具体的返回值类型,使用表达式中 ->returntype参数
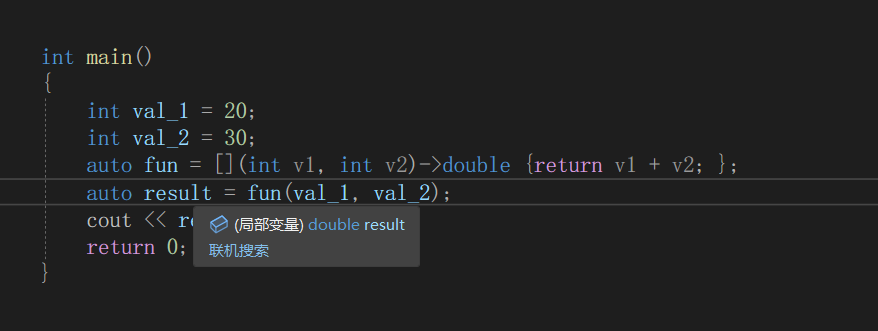
上述代码在lambda表达式中加上了->double,表明指定返回值类型为double类型,从result变量auto的结果可以看出,确实为double类型
接下来看看lambda表达式强于仿函数的功能,看下列代码及运行结果
int main(){int val_1 = 20;int val_2 = 30;auto fun = [val_1, val_2]{return val_1 + val_2; };int result = fun();cout << result << endl;return 0;}
什么情况?这个lambda表达式竟然可以直接使用main函数内的变量val_1, val_2
别慌,这就是捕捉列表的作用,仔细看可以发现笔者在[ ]里加上了变量名 val_1, val_2,这表示捕捉父作用域的变量 val_1, val_2(父作用域指包含lambda函数的语句块),也就是说一些情况下lambda表达式可以不用传参,而直接使用捕捉,如下是关于捕捉列表的相关写法

捕捉列表描述了上下文中哪些数据可以被lambda使用,以及使用的方式传值还是传引用
咱们看看以引用的形式捕捉
int main(){int val_1 = 20;int val_2 = 30;cout << "交换前:val_1 = " << val_1 << " val_2 = " << val_2 << endl;auto fun = [&val_1, &val_2] {std::swap(val_1, val_2); };fun();cout << "交换后:val_1 = " << val_1 << " val_2 = "<< val_2 << endl;return 0;}
使用捕捉列表需要注意的相关事项
1.捕捉列表不允许变量重复传递,否则就会导致编译错误
如代码[=, val_1]{},已经使用 '=' 全部传值捕捉,后面又传值捕捉val_1,此时会编译报错2.传值捕捉可以和传引用捕捉配合使用
如代码[=, &val_1] {},表示除val_1传引用捕捉外,其余都传值捕捉
3.在块作用域以外的lambda函数捕捉列表必须为空
4.在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都会导致编译报错
5.lambda表达式之间不能相互赋值,即使看起来类型相同,因为是两个不同的类嘛,肯定不能直接进行赋值转换
到目前为止,我们基本把lambda表达式语法格式用了一遍,但是好像mutable还没有提过,接下来我们看看mutable的用法,看下列代码

可以发现,传值捕捉val后,我们没有办法去修改val,这是因为lambda默认是一个const函数,也就是传值捕捉后的变量具有常性,无法修改,加上关键字mutable可取消常性

加上mutable后,确实可以修改val的值了,但程序打印val的值仍为20,这是因为lambda是传值捕捉,在lambda内部修改不会影响外部的val
所以mutable适合那种想捕捉借用父作用域的某个局部变量,并对其进行修改满足自己的要求,但是不希望修改后影响原父作域的这么一个场景
lambda表达式底层实现
前面提到过,lambda表达式的底层实现就是类,和仿函数一样,用类封装函数来直接调用,接下来我们用汇编源码来看看究竟是不是这么一回事
class ADD {public:int operator()(int x, int y){return x + y;}};int main(){int tmp1 = 10;int tmp2 = 20;ADD fun_1;auto fun_2 = [](int x, int y) {return x + y; };//仿函数调用int fun_1_ret = fun_1(tmp1, tmp2);//lambda调用int fun_2_ret = fun_2(tmp1, tmp2);return 0;}调试后查看这段代码的汇编代码

通过汇编代码可以看出,lambda表达式的底层确实和仿函数一样,都是将函数封装成一个类,然后重载(),只是lambda的类名对我们不可见,编译器才能够识别
可变参数模板
日常使用模板都是几个模板类型,C++11之后推出了可变模板参数,也就是模板类型的个数不需要再固定个数,而是想传几个就传几个
// Args是一个模板参数包,args是一个函数形参参数包// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。template <class ...Args>void ShowList(Args... args){}怎么知道是不是想传几个就传几个呢?可以使用如下语句计算参数包里的参数个数
template <class ...Args>void ShowList(Args... args){cout << sizeof...(args) <<endl;}//计算args参数包中参数的个数参数个数确定正确,不见得参数内容就是我们传过去的,所以接下来我们把参数包展开,看看是不是我们传过去的参数(可变参数模板参数包展开的语法比较晦涩,难以理解,并不需要掌握,大家了解一下即可)
//不可省略该函数,不然无法展开void ShowList(){cout << endl;}template <class T, class ...Args>void ShowList(T val, Args... args){cout << val << " ";ShowList(args...);}int main(){ShowList(10, 7.5, 'Y', string("hello"));return 0;}
这个语法很晦涩难懂,简单理解成递归式的调用,val每次接受参数包的一个参数,将其打印出来,然后参数包个数减1继续向下调用,直到参数包的个数为0,展开结束
可变参数模板的参数包展开还有一种方法,不过那个语法更加晦涩难懂,笔者就不展示了
如果从事库函数的开发的话,可变参数模板是个非常有用的工具,举个参数模板在容器中应用的例子,就以list为例,去官网可以查到list在C++11中多了一些成员函数

以emplace_ back()为例,这个成员函数是干嘛的呢?其实干得事情和push_back()是一样的,就是尾插元素,那有了push_back为何还要再多一个emplace_back()呢?
看笔者慢慢分析
list<string> test;test.push_back(string("hello workd");上述代码就是我们把一个匿名string给push到list中,整个过程就是用"hello workd"去构造这个匿名类,然后这个匿名类会被识别为右值,调用移动构造,转移资源给list中的string,这个过程主要有两部分的资源消耗,一是构造匿名类,二是调用移动构造
list<string> test;test.emplace_back("hello workd");
//emplace支持这种写法使用emplace_back后,就不需要去创建一个匿名类了,而是可以直接把参数给传过去,怎么做到的呢?可以发现emplace_back的实现用到了可变参数模板, 也就是说,"hello world"会作为一个参数存放在可变参数模板包中,然后编译器会用参数包中的参数去直接构造list中存放的string类,不需要我们先创建一个匿名类作为载体了
相比于push_back(),使用emplace_back()可以减少一次移动构造操作,所以说在传右值的时候 emplace_back()会比push_back()高效那么一些。真说高效多少也不见得,毕竟深拷贝下移动构造消耗资源可忽略,但若不涉及深拷贝,那还是不错的,能省一次浅拷贝呢
包装器
有了函数指针,仿函数,lambda三个传递函数的法宝,大家各取所需,有些情况下仿函数好用些,有些情况下lambda好用些,但是用多了就容易乱。于是C++委员会就考虑设计一种统一的接口,这个接口既可以接收函数指针,仿函数,也可以接收lambda,我们可以用这种统一的接口来调用函数指针,仿函数,及lambda,这个接口就是包装器
看一下包装器的定义
std::function在头文件<functional>// 类模板原型如下
template <class Ret, class... Args>
class function<Ret(Args...)>;模板参数说明:
Ret: 被调用函数的返回类型
Args…:被调用函数的形参包装器的本质是一个模板类,把函数指针,仿函数,lambda等类型再进行一次包装从而达到统一调用的目的,使用包装器要包含头文件<functional>,使用时和使用模板类一样
function< 返回值类型 (参数1类型,参数2类型...)> 类名 = (函数指针/仿函数/lambda/类成员函数); 下面提供了包装器的使用示例
void fun_ptr(int x, int y){cout << "函数指针: " << x+y << endl;}class FUN {public:void operator()(double x, double y){cout << "仿函数: " << x + y << endl;}};int main(){//把函数指针传给包装器,该函数无返回值,两个int参数function<void(int, int)> fun_1 = fun_ptr;//通过包装器使用函数指针指向的函数fun_1(10, 10);//把仿函数传给包装器,该函数无返回值,两个double参数function<void(double, double)> fun_2 = FUN();//通过包装器使用仿函数封装的函数fun_2(20.5, 20.5);//把lambda表达式传给包装器,该函数无返回值,两个longlong参数function<void(longlong, longlong)> fun_3 = [](longlong x, longlong y) { cout << "lambda表达式: " << x + y << endl; };//通过包装器使用lambda表达式fun_3(30, 30);return 0;}包装器看着定义比较复杂,实际用起来还是挺简单的,建议大家在实际开发过程中多使用包装器,因为包装器能够有效的减少代码膨胀,具体示例如下
void fun_ptr(int x, int y){cout << "函数指针: " << x+y << endl;}class FUN {public:void operator()(int x, int y){cout << "仿函数: " << x + y << endl;}};template<class fun>void call_fun(fun f, int tmp1, int tmp2){f(tmp1, tmp2);}int main(){call_fun(fun_ptr, 10, 10);call_fun(FUN(), 10, 10);call_fun([](int x, int y){ cout << "lambda表达式: " << x + y << endl; }, 10, 10); return 0;}学过模板我们,仔细分析都能够明白,call_fun函数会被实例化出三份,因为函数指针,仿函数,lambda是三种不同的类型,模板要为每一种类型都实例化出一份call_fun(),三个函数都是一样的功能,就因类型不同而被实例化出三份,导致代码膨胀
使用包装器就可以解决这个问题,因为函数指针,仿函数,lambda传给包装器后,类型就变为了包装器类,此时传给模板函数,会识别出三个都是包装器类型,只实例化一份
包装器可不仅能包装函数指针,仿函数,lambda表达式,还能包装类内成员函数
class TEST {public:static void test_fun_static(int x, int y){cout << "类内静态成员函数: " << x + y << endl;}void test_fun(int x, int y){cout << "类内成员函数: " << x + y << endl;}};int main(){function<void(int, int)> fun_1 = &TEST::test_fun_static;fun_1(10,20);function<void(int, int)> fun_2 = &TEST::test_fun;fun_2(10,20);return 0;}但是在编译器上,你会发现,无法直接用包装器封装test_fun函数,而可以封装test_fun_static函数,这是因为类内成员函数隐藏了一个this指针参数,而类内静态成员则不含this指针
缺this指针得补上呀,故而在封装类内非静态成员时还要加一个类名模板参数,然后在调用时传递一个匿名类,修改如下
function<void(TEST,int, int)> fun_2 = &TEST::test_fun;fun_2(TEST(), 10, 20);可能有些同学会觉得不对劲,仿函数和lambda不也是类嘛,为什么可以直接将仿函数和lambda传给包装器而没有this指针的问题呢?这是因为你传仿函数和lambda传的是一个对象呀,调用函数是通过对象中重载的()来完成,传对象要什么this指针,但你传类内成员函数就不一样了,传的是一个函数,需要考虑隐含的this指针参数
bind
接下来时此篇文章最后一部分内容,bind是一个函数模板,起到了适配器的作用,接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表
什么意思呢?咱们简单理解,前面不是使用包装器去封装类内成员函数嘛,但是类内成员有个隐藏的this指针,所以不得不在包装器模板参数列表中又加了一个类名,如代码
function<void(TEST,int, int)> fun_2 = &TEST::test_fun;
但是TEST这么一加,就会把包装器的书写格式又给破坏了,调用的时候还要给一个匿名类,看着就很突兀,这个时候我们可以使用bind,充当适配器的功能,将其从新适配回funcion<void(int, int)>这种统一的格式
调用bind的一般形式:auto newCallable = bind(callable, arg_list);
其中,newCallable本身是一个可调用对象,callable是要被bind的对象,arg_list是一个逗号分隔的参数列表,对应给定的callable的参数。当我们调用newCallable时,newCallable会调用callable,并传给它arg_list中的参数注意arg_list不是给定具体的参数类型,而是用占位符placeholders::_n表示,其中n是一个整数,这些参数是“占位符”,表示newCallable的参数,它们占据了传递给newCallable的参数的“位置”
先看一个简单的绑定函数指针的例子,了解绑定的用法后再解决上面问题
void fun_ptr(int x, int y){cout << "函数指针: " << x + y << endl;}int main(){ //绑定fun_ptr函数auto fun_1 = std::bind(fun_ptr, placeholders::_1, placeholders::_2);fun_1(10, 20);//将fun_1再赋给包装器function<void(int, int)> fun = fun_1;return 0;}在上面的代码中,因为fun_ptr有两个参数,因此我们使用placeholders::_1, placeholders::_2给适配后的对象fun_1占两个参数位,在调用fun_1时,fun_1会调用fun_ptr,并将占位符中的参数传给fun_ptr
来看看bind如何使调用类内成员函数时的格式统一,示例如下
class TEST {public:static void test_fun_static(int x, int y){cout << "类内静态成员函数: " << x + y << endl;}void test_fun(int x, int y){cout << "类内成员函数: " << x + y << endl;}};int main(){ auto fun_1 = std::bind(&TEST::test_fun, TEST(), placeholders::_1, placeholders::_2);//如此便可以直接赋给包装器function<void(int, int)> fun_2 = fun_1;return 0;}使用bind绑定类内成员时,除了要给定具体的类内成员,还要明确绑定的对象(可以给匿名对象),绑定完成后,就会将其适配成统一格式,可以直接赋给包装器
除此之外,bind还有其他的作用,以函数指针为例
void fun_ptr(int x, int y){cout << "我是参数x: " << x << endl;cout << "我是参数y: " << y << endl;}int main(){ //绑定fun_ptr函数auto fun_1 = std::bind(fun_ptr, placeholders::_1, placeholders::_2);fun_1(10, 20);//如果把placeholders::_1, placeholders::_2位置对换则传过去的参数位置也会换auto fun_2 = std::bind(fun_ptr, placeholders::_2, placeholders::_1);fun_2(10, 20);return 0;}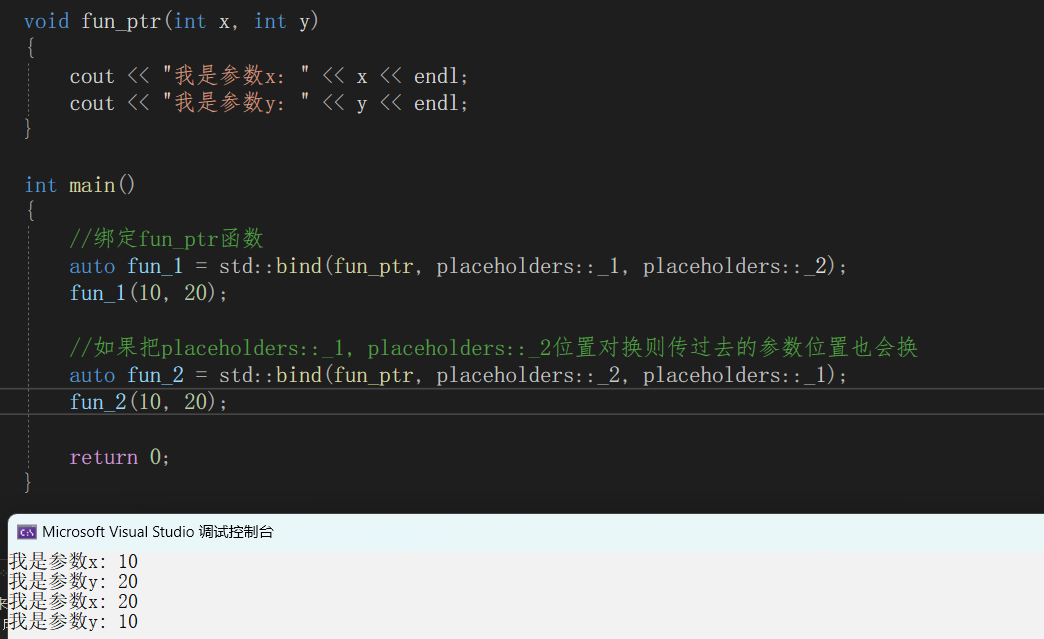
这是因为placeholders::_1就绑定到第一个参数了,placeholders::_2就绑定到第二个参数上了,即使你给其交换位置,placeholders::_1接收到20后,还是会把它传给x,因为x是第一个参数,还有一个玩法如下
void fun_ptr(int x, int y){cout << "我是参数x: " << x << endl;cout << "我是参数y: " << y << endl;}int main(){ //绑定fun_ptr函数且将fun_1的参数绑定具体的值auto fun_1 = std::bind(fun_ptr, 100, 200);fun_1(10, 20);//绑定fun_ptr函数且将fun_2的参数绑定具体的值auto fun_2 = std::bind(fun_ptr, 300, 400);fun_2(10, 20);return 0;} 
至此,此篇文章结束,希望大家多敲一敲,把这些工具都用起来
![uni-app开发微信小程序的报错[渲染层错误]排查及解决](http://pic.xiahunao.cn/uni-app开发微信小程序的报错[渲染层错误]排查及解决)









)
)

)



)

