🙌秋名山码民的主页
😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
获取源码,添加WX
目录
- 前言
- 1. 热榜前50爬虫
- 最后
前言
基于大数据技术的社交媒体文本情绪分析系统设计与实现,首先需要解决的就是数据的问题,我打算利用Python 语言的Scrapy、Beautiful Soup等工具抓取一段时间内新浪微博用户对于热点事件的博文之后,按照事件、时间等多种方式进行分类,接着利用正则表达式等工具过滤掉微博正文中的超链接、转发信息、表情符号、广告宣传和图片等无效信息之后,将处理完的文本进行手工标注,最终将标注的文本作为训练语料库。今天的主要工作量就是对数据的获取,进行简单的热榜爬虫、和热点爬虫,热榜爬虫代码进行公开,热点爬虫代码需要的欢迎私信有偿获取。
1. 热榜前50爬虫
所需库:
import requests
from bs4 import BeautifulSoup
import pandas as pd
新浪微博目标网站:
url = ‘https://s.weibo.com/top/summary/’
cookie的获取:
Cookie中包含以下字段:
- SUB:用户身份认证信息,通常由数字和字母组成。
- SUBP:用户身份认证信息,通常由数字和字母组成。
- SINAGLOBAL:用户身份认证信息,通常由数字和字母组成。
- _s_tentry:用户访问来源网站的信息。
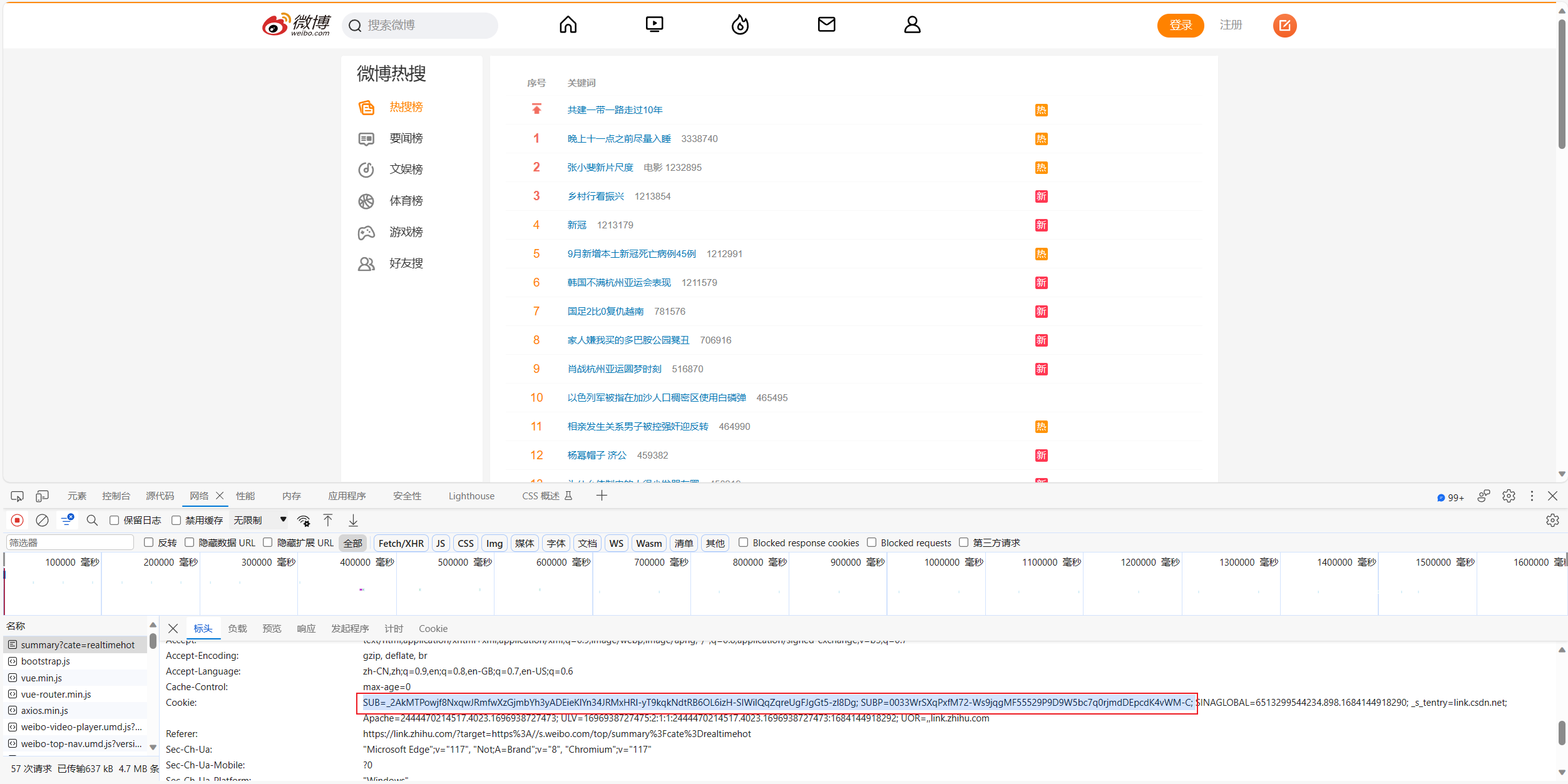
cookie = '你自己的cookie'
常规爬虫代码
# 获取网页响应,对网页响应进行编码
response = requests.get(url, headers=headers)
response.encoding = response.apparent_encoding
html = response.text# 将网页文本使用Beautifulsoup解析
soup = BeautifulSoup(html, 'html.parser')# allnews存放热搜前50的新闻和热度,形式为{'新闻':'热度'}字典
all_news = {}
微博热榜分析
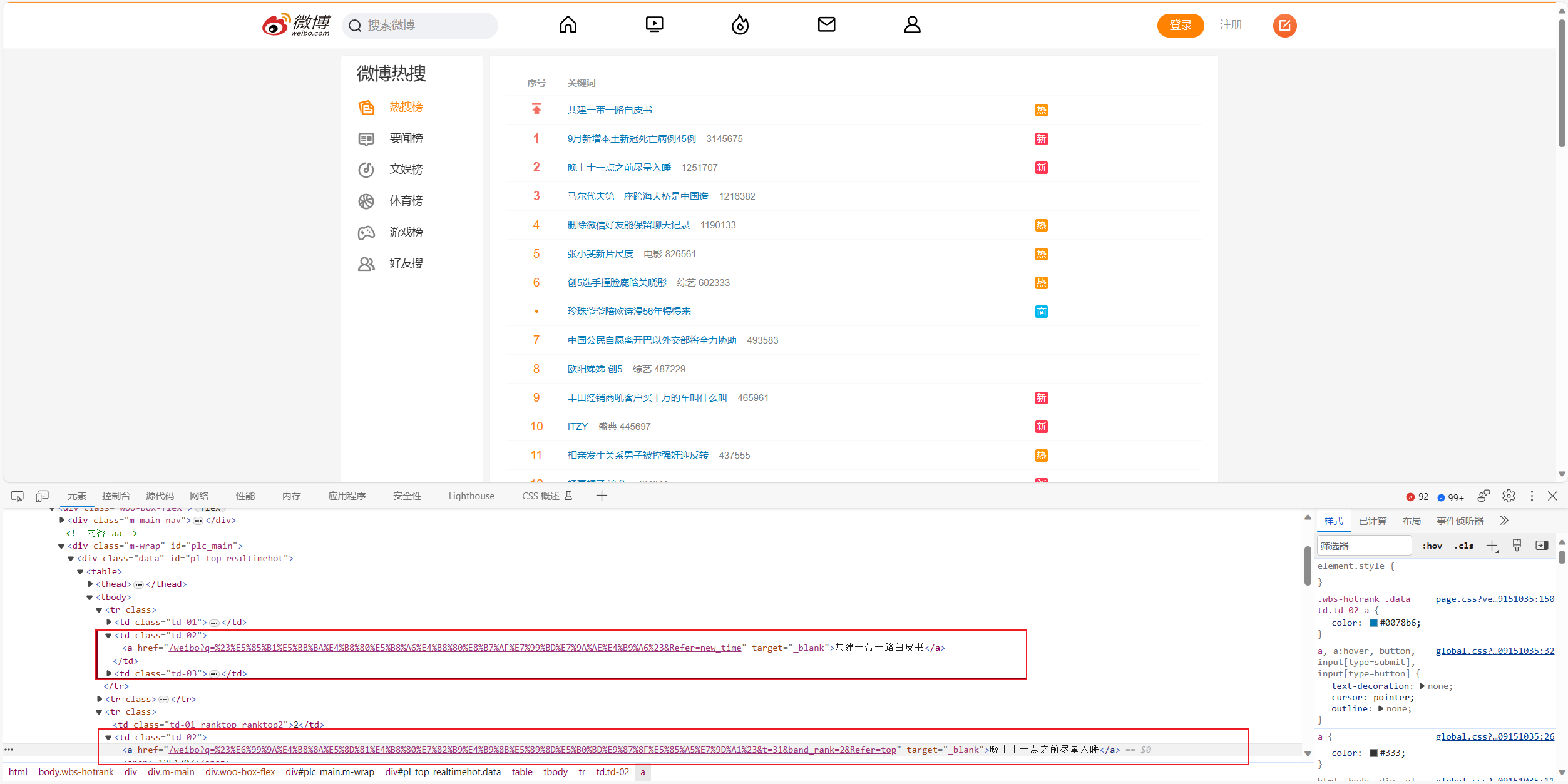
# 定位网页元素,观察到热搜新闻位于'td'元素下,class为'td-02'
for news in soup.find_all('td', class_='td-02')[1:]:text = news.text.split('\n')[1].strip()if news.text.split('\n')[2].strip() == '':continueelif news.text.split('\n')[2].strip()[0].isdigit():hot = news.text.split('\n')[2].strip()else:hot = news.text.split('\n')[2].strip()[2:]all_news[text] = hot存储为csv
# 将字典转为DataFrame,并将DataFrame保存为csv文件
df = pd.DataFrame.from_dict(all_news, orient='index', columns=['热度'])
df.index.name = '新闻'
df.to_csv('weibo_hot.csv', encoding='utf-8-sig')结果展示

最后
如果本文对你有所帮助,还请三连支持一下博主!



)










- CSS技巧与布局)
代码模块的导入、快捷使用、自定义 (IntelliJ IDEA 2022.1.3版本))




