数据定义语句执行
- 概述
- 数据定义语句执行流程
- 执行示例
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书
概述
数据定义语言(DDL,Data Definition Language) 是一类用于定义数据模式、函数等的功能性语句。不同于元组增删查改的操作,其处理方式是为每一种类型的描述语句调用相应的处理函数。
数据定义语句的处理过程比较简单,其执行流程最终会进入到ProcessUtility处理器,然后执行语句对应的不同处理过程。由于数据定义语句的种类很多,因此整个处理过程中的数据结构和方式种类繁冗、复杂,但流程相对简单、固定。
数据定义语句执行流程
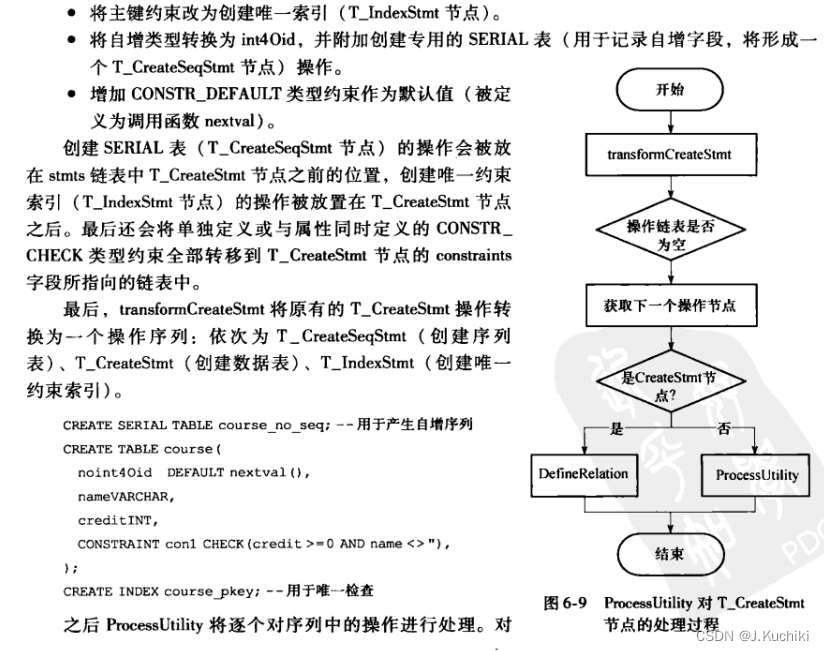
由于ProcessUtility需要处理所有类型的数据定义语句,因此其输人数据结构的类型也是各种各样,每种类型的数据结构表示不同的操作类型。ProcessUtility将通过判断数据结构中NodeTag字段的值来区分各种不同节点,并引导执行流程进人相应的处理函数。图6-7展示了ProcessUtility的总体流程。
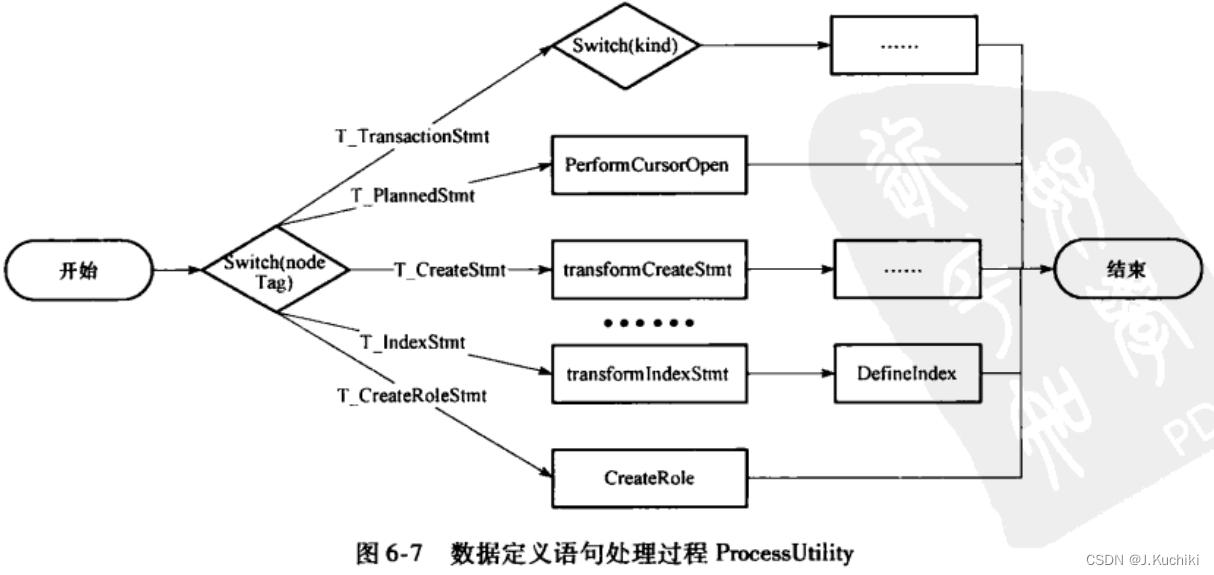
ProcessUtility函数源码如下:(路径:src/backend/tcop/utility.c)
/** ProcessUtility* general utility function invoker** pstmt: PlannedStmt wrapper for the utility statement* queryString: original source text of command* context: identifies source of statement (toplevel client command,* non-toplevel client command, subcommand of a larger utility command)* params: parameters to use during execution* queryEnv: environment for parse through execution (e.g., ephemeral named* tables like trigger transition tables). May be NULL.* dest: where to send results* completionTag: points to a buffer of size COMPLETION_TAG_BUFSIZE* in which to store a command completion status string.** Caller MUST supply a queryString; it is not allowed (anymore) to pass NULL.* If you really don't have source text, you can pass a constant string,* perhaps "(query not available)".** completionTag is only set nonempty if we want to return a nondefault status.** completionTag may be NULL if caller doesn't want a status string.** Note for users of ProcessUtility_hook: the same queryString may be passed* to multiple invocations of ProcessUtility when processing a query string* containing multiple semicolon-separated statements. One should use* pstmt->stmt_location and pstmt->stmt_len to identify the substring* containing the current statement. Keep in mind also that some utility* statements (e.g., CREATE SCHEMA) will recurse to ProcessUtility to process* sub-statements, often passing down the same queryString, stmt_location,* and stmt_len that were given for the whole statement.*/
void
ProcessUtility(PlannedStmt *pstmt,const char *queryString,ProcessUtilityContext context,ParamListInfo params,QueryEnvironment *queryEnv,DestReceiver *dest,char *completionTag)
{Assert(IsA(pstmt, PlannedStmt));Assert(pstmt->commandType == CMD_UTILITY);Assert(queryString != NULL); /* required as of 8.4 *//** We provide a function hook variable that lets loadable plugins get* control when ProcessUtility is called. Such a plugin would normally* call standard_ProcessUtility().*/if (ProcessUtility_hook)(*ProcessUtility_hook) (pstmt, queryString,context, params, queryEnv,dest, completionTag);elsestandard_ProcessUtility(pstmt, queryString,context, params, queryEnv,dest, completionTag);
}
函数参数解释:
- pstmt:是包装了 utility 语句的 PlannedStmt 结构体,其中存储了 utility 语句的执行计划信息。
- queryString:是原始的 SQL 查询文本,即用户输入的 utility 语句。
- context:标识 utility 语句的来源,可以是顶层客户端命令、非顶层客户端命令,或者是其他更大的 utility 命令的子命令。
- params:是在执行过程中可能需要用到的参数。
- queryEnv:是用于解析到执行期间的环境信息,比如在触发器中使用的过渡表等。可以为NULL。
- dest:指定了执行结果的输出位置。
- completionTag:是一个指向存储命令完成状态字符串的缓冲区,用于返回一些执行结果的状态信息,例如影响的行数等。可以为NULL,表示不需要这些状态信息。
函数执行流程解释:
- 首先,函数会进行一系列断言(Assert)的检查,确保传入的参数是符合要求的,例如 pstmt 必须是 PlannedStmt 类型,queryString 不为空,commandType 是 CMD_UTILITY 等。
- 接着,函数检查是否有外部插件定义了 ProcessUtility_hook 钩子函数。如果有插件定义了该钩子函数,那么数据库会调用这个插件的处理函数来处理 utility 语句,而不是继续执行下面的标准处理流程。
- 如果没有插件定义 ProcessUtility_hook 钩子函数,那么数据库会调用 standard_ProcessUtility 函数,来处理 utility 语句。standard_ProcessUtility 函数会根据不同的 utility 类型(比如创建表、创建索引等)调用相应的处理函数来执行 utility 语句,并且根据情况将执行结果返回给客户端。
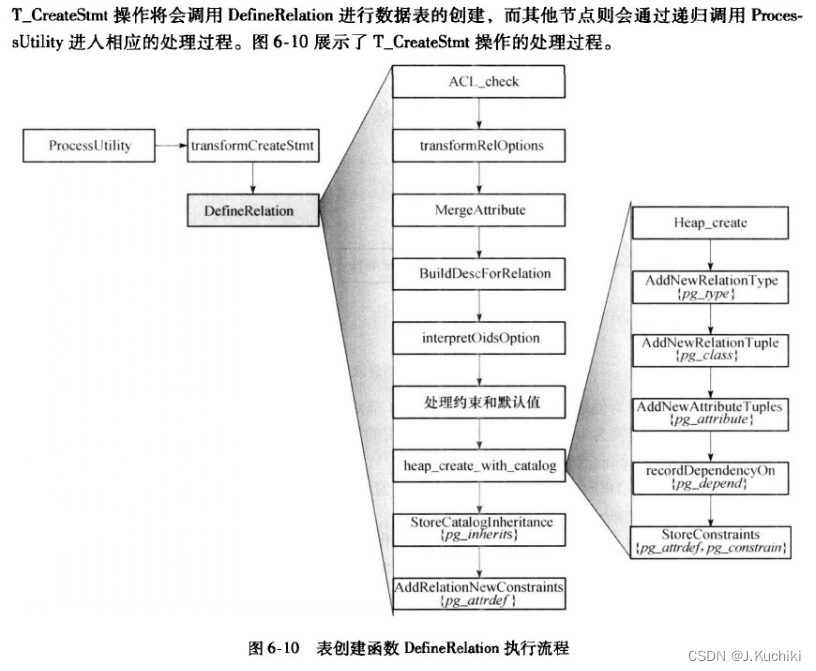
针对各种不同的查询树,查询编译器在执行处理前会做一些额外的处理对查询树进行分析、处理与转换。例如,创建表的语句会用函数transformCreateStmt进行查询树的处理。这些处理过程可能会在当前操作之前和之后增加一些新的操作(例如在创建表的操作之前增加创建serial序列表操作、之后增加创建触发器用于外键约束操作等),也可能会执行对数据结构的处理操作(例如将CreateStmt节点tableElts字段中CONST_CHECK类型的Constraint节点转存到CreateStmt的constraints链表中等)。由于这些处理过程会产生一些新的操作,因此最终会生成一个由多个操作构成的链表。因此,执行过程需要依次扫描该链表,为每一个原子操作调用相应的处理函数。
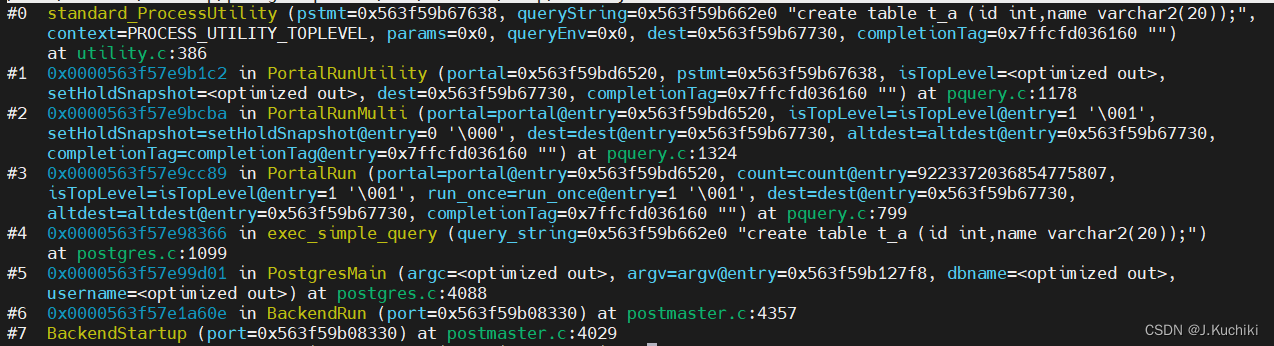
以创建表create table t_a (id int, name char(20));为例进行调试。
函数调用顺序:exec_simple_query —> PortalRun —> PortalRunMulti —> PortalRunUtility —>
ProcessUtility —> standard_ProcessUtility


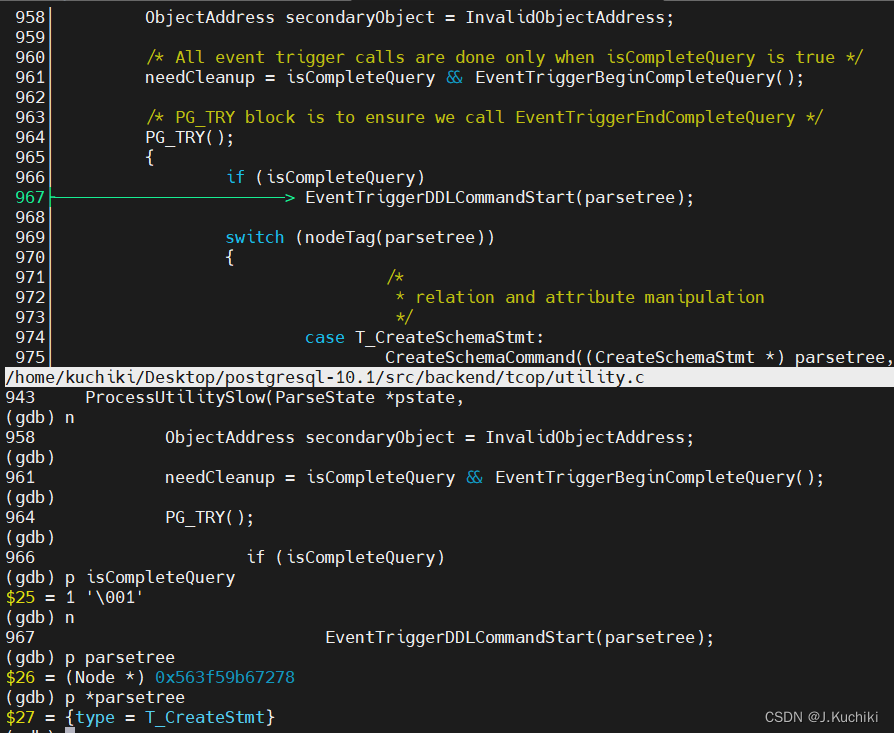
相同类别的语句处理过程涉及内容相近,实现思想和主要过程相似。例如,事务类处理主要是对于当前事务的状态的判断和转换;游标类处理的主要思想是首次将执行一个查询计划树(Plantree),将结果缓存在Portal指向的特殊结构中,然后按照要求获取元组数据;表、属性管理类主要涉及权限管理、修改相应系统表以及关系表的存储类别操作等。由于数据定义语句的种类多达上百种,我们下面将以一个创建表的例子来介绍数据定义语句的执行流程。
执行示例
来看一看书中给出的案例吧:




我们根据书中的描述来实际的调试一下代码吧:
由先前的查询树可视化工具可以打印出例6.1中经过查询重写的Query结构:
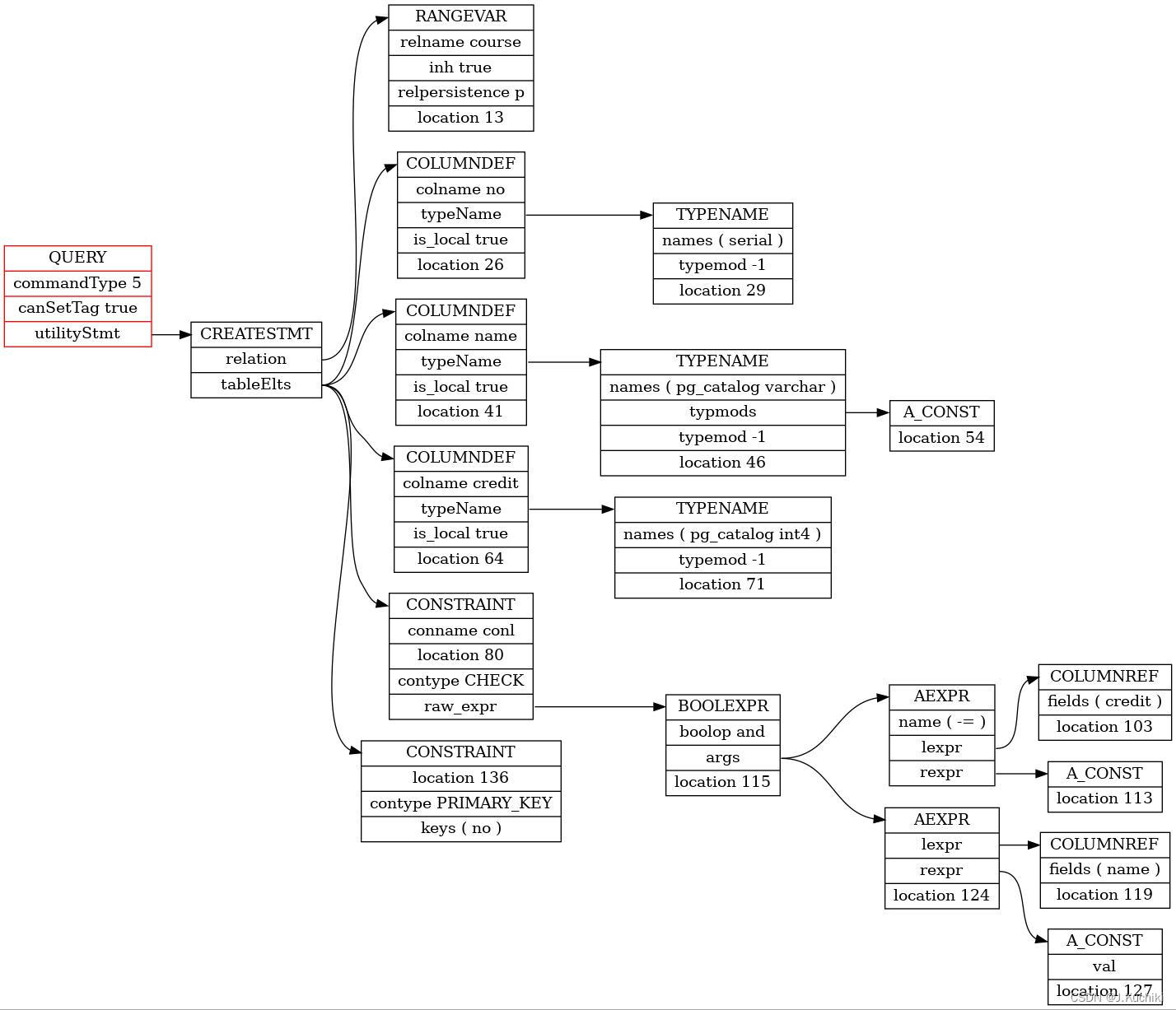
可以看到ChoosePortalStrategy函数的确选择了PORTAL_MULTI_QUERY字段。
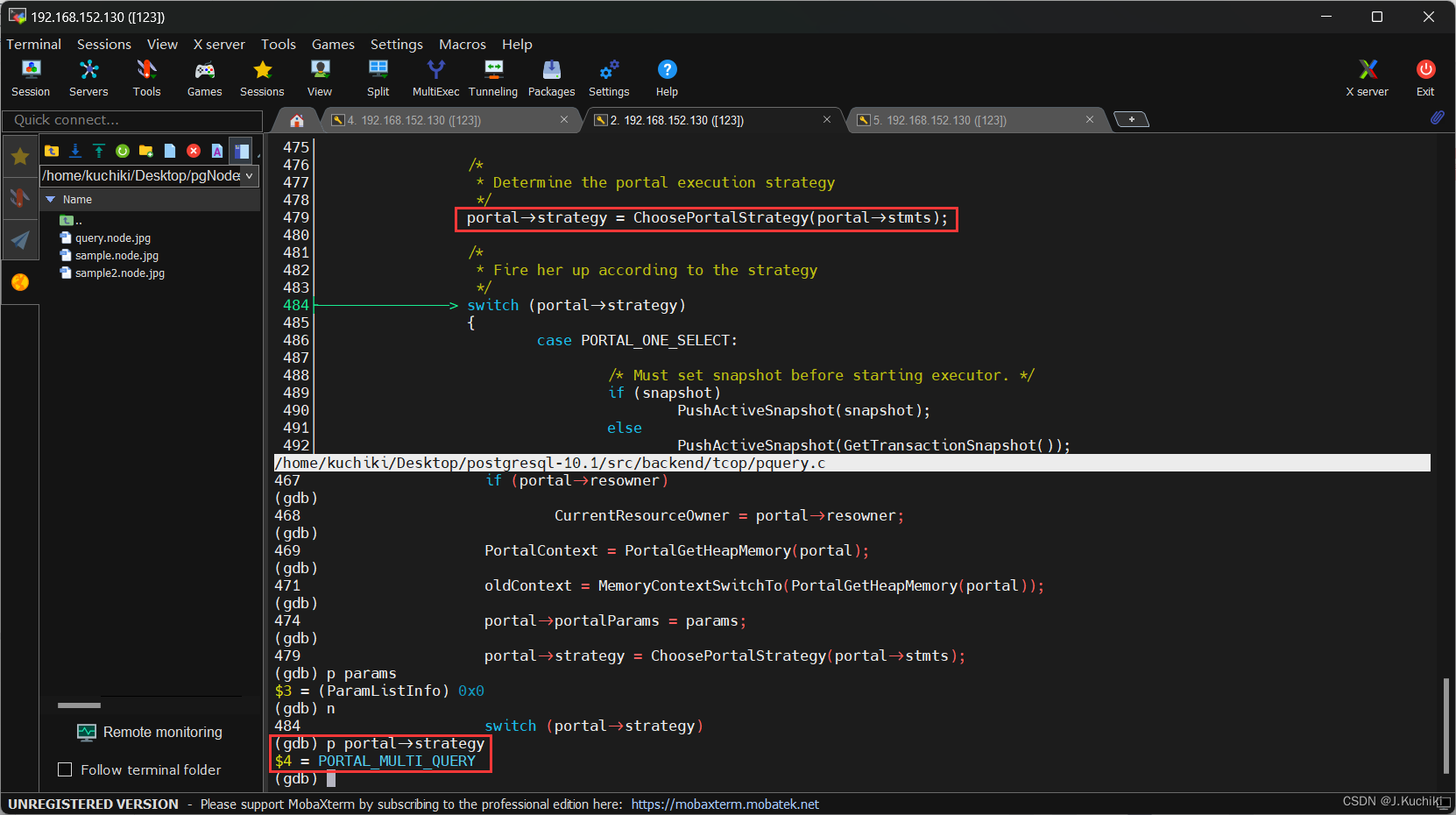
此外,PortalRun函数调用PortalRunMulti来执行PORTAL_MULTI_QUERY策略。

执行PortalDrop函数后Portal结构体如下所示: