Pocket2Mol: Efficient Molecular Sampling Based on 3D Protein Pockets
code: GitHub - pengxingang/Pocket2Mol: Pocket2Mol: Efficient Molecular Sampling Based on 3D Protein Pockets
所用数据集
与“A 3D Generative Model for Structure-Based Drug Design”文章所用的数据集一致:
Data We use the CrossDocked dataset [7] following [20]. The dataset originally contains 22.5 million docked protein-ligand pairs at different levels of quality. We filter out data points whose binding pose RMSD is greater than 1Å, leading to a refined subset consisting of 184,057 data points. We use mmseqs2 [31] to cluster data at 30% sequence identity, and randomly draw 100,000 protein-ligand pairs for training and 100 proteins from remaining clusters for testing.
RMSD是用来比较实验或计算得到的蛋白质-配体复合物的结构与某个参考结构之间的差异,这里过滤掉了相似度(RMSD)大于 1Å的复合物。
“crossdocked_pocket10/index.pkl”中包含3种信息,分别是: pocket_fn(口袋名称), ligand_fn(配体名称), _, rmsd_str(受配体RMSD(比较蛋白质结构或化合物结构之间的相似程度))
评价指标
这里主要介绍容易混淆的两个metrics:
Vina Score(kcal/mol, ↓):We use Vina [33, 1] to compute the binding affinity (Vina Score). Before feeding the molecules to Vina, we employ the universal force fields (UFF) [24] to refine the generated structures following [20].
High Affinity(%, ↑):有更高亲和力的百分比,测量结合位点生成的结合亲和力高于或等于参考ligand的分子的百分比。
作者提出了一种新的可以满足口袋施加的多个几何约束的采样方法:Pocket2Mol,这是一个由两个模块组成的 E(3)-等变生成网络,它不仅可以捕获结合口袋原子之间的空间和键合关系,还可以在不依赖 马尔科夫链蒙特卡洛方法(MCMC)的情况下从易于处理的分布中以口袋表示为条件对新候选药物进行采样。实验结果表明,从 Pocket2Mol 中取样的分子具有明显更好的结合亲和力和其他药物特性,例如药物相似性和合成可及性。
1.介绍
深度学习在药物设计方面取得了巨大成功。生成模型主要思想是在紧凑的低维空间中高效地表示所有收集的化学结构,并通过扰乱隐藏值来采样新的候选药物。这些模型的输出可以是一维化学描述符、二维图(graph)和3D结构。
然而,在分子水平上,小分子仅通过与特定的蛋白质口袋结合来抑制或激活特定的生物学功能。因此,基于口袋的药物设计受到越来越多的关注。更具体地说,给定目标蛋白的 3D 结合口袋,这些模型知道 3D 口袋的几何信息,并相应地生成与口袋结合的分子。早期的方法通过:
- 集成评估功能(例如采样分子和口袋之间的对接分数)来修改无口袋模型,以指导候选搜索。
- 另一种方法将 3D 口袋结构转换为分子 SMILES 字符串或 2D 分子图,但是没有明确建模小分子结构和 3D 口袋之间的相互作用。
条件生成模型可以模拟 3D 口袋结构内的 3D 原子密度分布。然后这个问题的挑战点从学习分布转移到结构采样算法的效率上。此外,以前的模型过分强调原子 3D 位置的重要性,而忽略了化学键的产生,这导致在实践中原子连接不切实际。作者从以下方向改进了基于口袋的药物设计:
- 第一,开发一种新的深度几何神经网络来准确地模拟口袋的 3D 结构;
- 第二, 设计一种新的采样策略,以实现更有效的条件 3D 坐标采样;
- 第三,将采样一对原子之间的化学键的能力分配给Pocket2Mol模型。
Pocket2Mol模型利用基于向量的神经元和几何向量感知器学习蛋白质口袋施加的化学和几何约束,通过共享原子级嵌入联合预测前沿原子、原子位置、原子类型和化学键,并以自回归方式对分子进行采样。由于基于向量的神经元,该模型可以直接生成相对于焦点原子的相对原子坐标的易处理分布,以避免使用传统的 MCMC 算法。实验结果表明,Pocket2Mol 采样的候选药物不仅表现出更高的结合亲和力和药物相似性,而且比最先进的模型包含更真实的子结构。此外,Pocket2Mol 比以前基于 MCMC 的自回归采样算法快得多。
3.方法
Pocket2Mol 的中心思想是根据已经存在的原子来学习口袋内每个位置的原子或键类型的概率分布。为了学习这种特定于上下文的分布,作者采用自回归策略从训练药物的其余部分预测随机被mask掉的部分。
3.1、生成步骤
形式上,蛋白质口袋表示为一组带有坐标的原子,
![]()
其中 和
分别是第 i 个重原子、及其坐标,N 是蛋白质口袋中的原子数。以连续方式对分子进行采样。将已经生成的具有n个原子的分子片段表示为带有坐标的图:
![]()
、
、
分别表示第i个重原子,它的坐标、它与其他原子的价键
生成模型记为φ,生成过程定义如下:
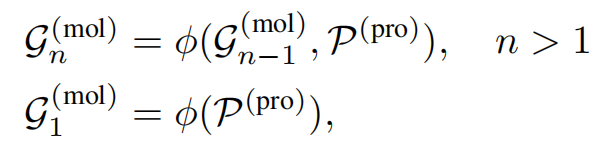
蛋白质口袋、
分子片段
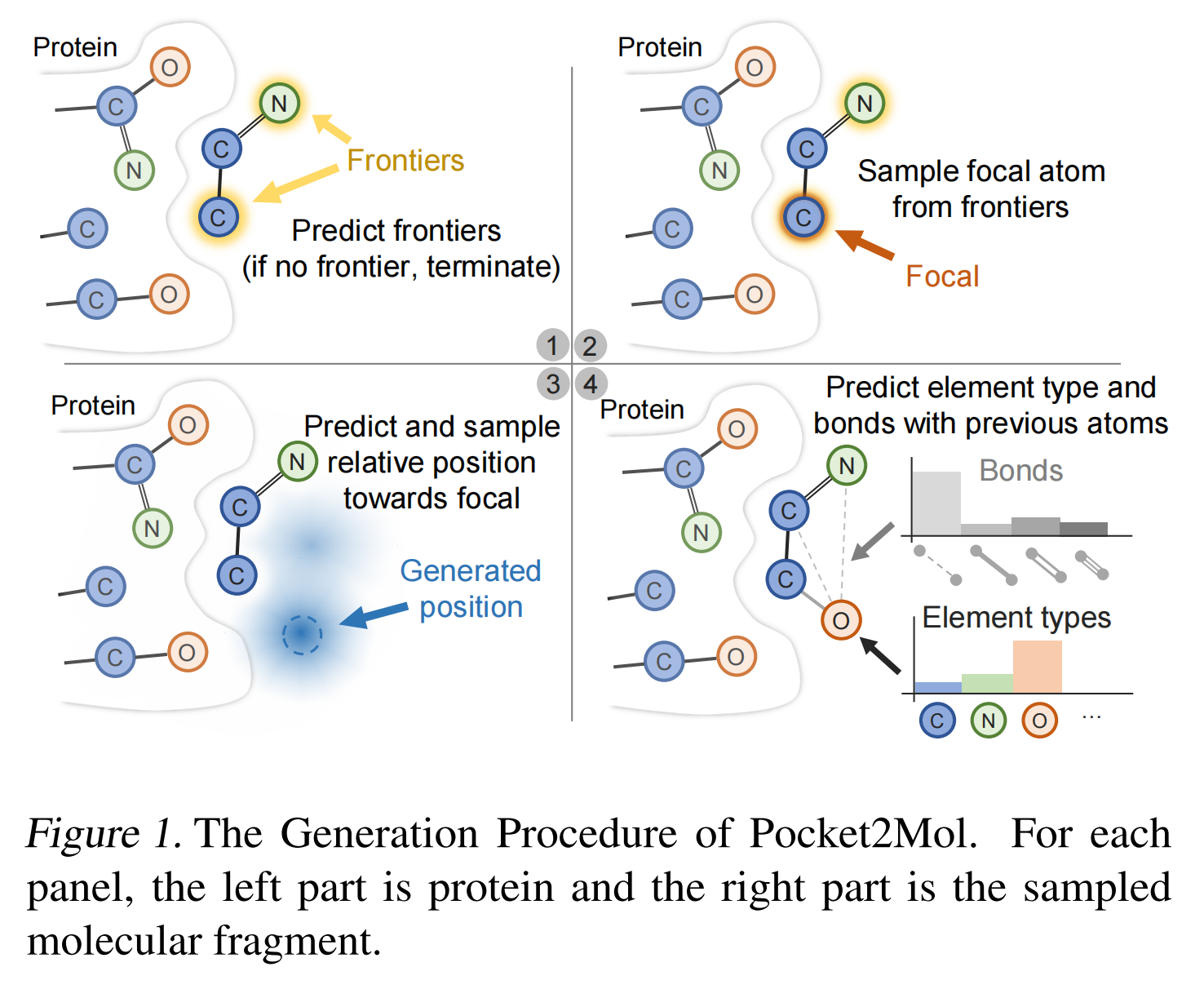
对于每个原子,生成过程由四个主要步骤组成,如图一所示:
- 首先,该模型的前沿预测器
将预测当前分子片段的前沿原子(Frontiers)。前沿被定义为可以共价连接到新原子的原子。如果所有的原子都不是前沿,则表明当前分子是完整的,生成过程终止。
- 第二步,该模型从前沿原子集中采样一个原子作为焦点(Focal)原子。
- 第三步,基于焦点(Focal)原子,模型的位置预测器
预测新原子的相对位置。
- 最后,模型的原子元素预测器
和键型预测器
将预测元素类型和与键类型的概率,然后采样新原子的元素类型和价键。
- 通过这种方式,新原子被成功地添加到当前的分子片段中,生成过程继续下去,直到找不到前沿原子(Frontiers)。
这个生成过程对于第一个前沿原子是不同的,对于第一个原子,蛋白质口袋中的所有原子都被用来预测前沿(Frontiers),这里的Frontiers被定义为新原子可以在4˚A内产生的原子。【可以从第一个Frontiers的生成和采样做文章】
3.2、模型架构
基于上述生成过程,模型需要由四个模块组成:编码器(encoder)、前沿原子预测器(frontier predictor)、原子位置预测器( position predictor )和元素和键预测器( element and-bond predictor)。
3.2.1、E(3)等变神经网络【主体架构,可以更好的捕获3D口袋和分子fragment的信息】
研究表明,用标量和向量特征表示三维图中的顶点和边(2021)可以帮助提高神经网络的表达能力。在我们的网络中,蛋白质口袋和分子片段的所有顶点和边都与标量和矢量特征相关联,以更好地捕获三维几何信息。
标量和向量分别用点和箭头表示![]()
我们采用几何矢量感知器(geometric vector perceptrons GVP)(Jing et al.,2021)和基于矢量的神经网络(vector-based neural network)(Deng et al.,2021)来实现E(3)-等变。
- 几何向量感知器(GVP)扩展了标准的密集层(standard dense layers),可以在标量特征和向量特征之间传播信息(Jing et al., 2021)。
- 向量神经元网络将一组普通的神经操作(例如线性层、激活函数)扩展到向量特征空间(Deng et al., 2021)。
我们对原GVP进行修改,在GVP的输出向量上加入一个向量非线性激活(vector nonlinear activation),记为Gper:

![]() 可以是任何一对标量向量特征
可以是任何一对标量向量特征
在我们的模型中,我们选择LeakyReLU非线性函数作为GVP的标量和矢量输出。此外,我们通过去掉GVL的标量和矢量输出的非线性激活,定义了一个几何向量线性( geometric vector linear GVL)块,记为Glin。改进的GVP块Gper和GVL块Glin是我们模型的主要构建块,这使得模型是E(3)-等变的。此外,包含矢量特征对于我们的模型直接准确地预测基于蛋白质口袋提供的几何环境的原子位置至关重要(细节将在第3.2.3节中描述)。
3.2.2 Encoder
我们将蛋白质口袋和分子片段表示为 k 近邻图(KNN),其中顶点为原子,每个原子与其 k 近邻相连。
蛋白质原子的输入标量特征包括元素类型、所属氨基酸以及是骨架原子还是侧链原子。
分子原子的输入标量特征包括元素类型、化合价和不同化学键的数量。
此外,所有原子还有一个标量特征,表明它们属于蛋白质还是分子片段。标量边缘特征包括用高斯 RBF 核(Sch¨utt et al. 输入矢量顶点特征包括原子坐标,而矢量边缘特征则是三维空间中边缘的单位方向矢量。
3.2.2 预测
前沿原子预测器(frontier predictor)
原子位置预测器( position predictor )
元素和键预测器( element and-bond predictor)。
4、训练
在训练阶段,作者随机mask分子的原子,并训练模型恢复被mask的原子。具体地说,对于每个口袋配体对,从均匀分布U[0,1]中抽样mask比率,并mask相应数量的分子原子。其余与被mask原子有价键的分子原子被定义为前沿(frontiers)。然后,位置预测器和元素键预测器试图通过预测掩蔽原子朝向相应前沿的位置、元素类型和与剩余分子原子的键,来恢复与前沿原子具有价键的mask原子。如果所有分子原子都被mask,则frontiers定义为在4˚A范围内具有mask原子的蛋白质原子,frontiers附近的被屏蔽原子将被恢复。对于元素类型预测,作者在查询位置增加了一个不表示任何内容的元素类型。
前沿预测的损失是预测前沿的二元交叉熵损失(binary cross entropy loss)。位置预测器的损失是掩蔽原子位置的负对数可能性(negative log likelihood)。对于元素类型和键型预测,作者使用交叉熵损失(cross entropy losses)进行分类。总损失函数为:
![]()
参考:
Pocket2Mol : 基于3D蛋白质口袋的高效分子采样 - 知乎
如何做机器视觉项目)
)







)






。Javaee项目。)


