目录
一,fack回顾
二,进程终止
1.进程终止,操作系统做了什么?
2.进程终止,常见的方式
1.main函数的,return + 返回码
2. exit()函数
三,进程等待
1. 回收进程方法
(1. wait方法
补充理解:僵尸进程与内存泄露区别
(2.waitpid函数
a,参数pid
b, 参数status
c, 参数options
四,进程替换
1,概念与原理
2,进程替换方法
3. 尝试fork + execl函数
其他函数补充:
4. 如何利用execl函数运行其他可执行程序
五,练习——制作一个简单的shell命令解释器
1. 制作框架方面:
2. 接收,并处理指令
3. 子进程替换,父进程等待
结语

一,fack回顾
#include <unistd.h>pid_t fork(void);返回值:自进程中返回0,父进程返回子进程id,出错返回-1
- 分配新的内存块和内核数据结构给子进程;
- 将父进程部分数据结构内容拷贝至子进程;
- 添加子进程到系统进程列表当中;
- fork返回,开始调度器调度。

由于前面已经出现了fork的理解,这里不做详解。
前面地址空间章节(【Linux】地址空间概念_花果山~~程序猿的博客-CSDN博客)我们已经初步了解了在创建子进程时,系统会采用写时拷贝这项决策,我们可以反向思考,如果系统直接拷贝一份给子进程呢?我们知道进程 = 内核数据结构 + 代码&数据,进程一旦被创建,代码是处于只读的状态,但数据可以转为可写,这样我们为啥不拷贝一份数据给子进程?因为系统是不知道那些数据是要被使用的,所以拷贝一份不怎么被使用的数据会导致内存利用率下降。
所以关于为何OS选择写时拷贝技术,对父子进程进行分离?
1.用的时候,给子进程分配,是一种高效的内存表现。
2.系统在执行代码时,无法的知道那些内存会被访问。
数据修改前后:

结论:在计算机系统中,当父进程创建子进程时,子进程会继承父进程的代码和数据。初始时,这些代码和数据的权限是只读的。当子进程需要修改这些代码和数据时,会进行写时拷贝操作,即将需要修改的部分数据的权限从只读变为可写。
二,进程终止
1.进程终止,操作系统做了什么?
进程终止,操作系统释放进程所申请的内核数据机构,代码和数据,其本质上就是内存释放。
2.进程终止,常见的方式
1.main函数的,return + 返回码
我们在编写一个C/C++程序时,运行起来,会有以下情况:
(a,代码跑完,结果正确;
(b,代码跑完,结果不正确;
我们在编写main函数时,往往都会返回一个0(不总是0),这是进程退出码,是提供给上一级父进程的,如果返回的不是0就代表结果不正确;反之,正常退出,则返回0;
补充: 获取上一次进程退出码指令 echo $?
那main()函数返回值有什么意义呢?
当我们在shell脚本中调用一个程序时,可以通过检查该程序的main函数返回码来确定程序是否成功执行。如果返回码为0,则表示程序执行成功;而如果返回码为其他非零值,则表示程序执行失败或出现错误。通过这种方式,我们可以根据main函数的返回码来进行后续的处理(意味着得程序跑完,才会有后续处理),例如输出相应的提示信息或进行错误处理(比如:strerror()函数的错误原因)。(来自chatgpt)
(c,代码未跑完,程序奔溃。(这里在信号部分讲解)
2. exit()函数
exit在代码任何地方调用,都会终止进程。这里补充一个系统层面的接口_exit()
接下来我们来实验一下两者的区别:
行缓冲区,如果我们不添加换行符,打印数据会先存放到缓存区,在进程结束后刷新到显示器。
int main()6 {7 cout << "lisan";8 sleep(3);9 exit(11); // _exit(11); 10 return 0; 11 } 12 尝试两个函数,_exit()函数在进程退出时不会打印lisan,下面是原因示意图。

由于_exit()直接终止程序,所以缓冲区的数据没有被刷新出。那这里我们会想缓冲区在那里呢?我们知道_exit()是操作系统的接口,exit()是库函数,因此我们可以大概猜到管理缓冲区的程序在操作系统之上。
三,进程等待
为什么需要进程等待?父进程需要拿到一个数据,创建子进程,等待子进程返回数据,父进程才能进入下一步操作。以及,子进程退出,如果父进程提前退出,子进程则变成僵尸进程,造成内存泄露。
总之;
- 之前讲过,子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。
- 另外,进程一旦变成僵尸状态,那就刀枪不入,“杀人不眨眼”的kill -9 也无能为力,因为谁也没有办法杀死一个已经死去的进程。
- 最后,父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对,或者是否正常退出。
- 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息。
执行下面程序:
int main()6 {12 pid_t pd = fork();14 if (pd < 0)15 {16 // 程序失败17 perror("fork ");18 }else if(pd == 0)19 {20 // 子进程21 int a = 5;22 while(a--) 23 {24 printf("是子进程:getpid:%d,getppid:%d\n",getpid(), getppid() );25 sleep(1);26 } 27 }else{28 // 父进程29 while(1)30 {31 printf("是父进程:getpid:%d,getppid:%d\n",getpid(), getppid() );32 sleep(1);33 } 34 }35 }

那我们如何接收进程呢?(虽然父进程提前结束,子进程会被操作系统领养,回收,这种思路:是一种编程思路,我们以后会学习到)
1. 回收进程方法
(1. wait方法

#include<sys/types.h>#include<sys/wait.h>pid_t wait(int* status);返回值: 成功返回被等待进程pid ,失败返回 -1 。参数: 输出型参数,获取子进程退出状态, 不关心则可以设置成为 NULL

补充理解:僵尸进程与内存泄露区别
我们知道子进程一旦进入僵尸状态,其代码和数据虽然可以被释放,但其PCB(task_struct)的内核数据结构会被保留,如果操作系统一直不回收那么也属于内存泄露;在我们编写的应用程序中,我们通过new,malloc向堆区申请的内存,需要我们在使用完后进行释放,否则会造成内存泄露。理解:
这两种泄露前者是操作系统级别的,后者是进程中,后者进程退出,系统回收内存,不存在内存泄露;前者操作系统不处理僵尸进程的PCB是永远回收不了这些内存的。
(2.waitpid函数
pid_ t waitpid(pid_t pid, int* status, int options);返回值:当正常返回的时候 waitpid 返回收集到的子进程的进程 ID ;如果设置了选项 WNOHANG, 而调用中 waitpid 发现没有已退出的子进程可收集,则返回0 ;如果调用中出错 , 则返回 -1, 这时 errno 会被设置成相应的值以指示错误所在;

a,参数pid
Pid=-1, 等待任一个子进程。与 wait 等效。Pid>0. 等待其进程 ID 与 pid 相等的子进程。
补充一点关于status的知识,我们知道其是用来记录子进程返回码的,同时我们也知道程序运行结束会有三种情况:
那怎么从status上表达这不同情况?
b, 参数status

所以我们怎么取得退出状态??
(status >> 8) & 0xff // 0xff -> 0000 0000....1111 1111保留最后8个比特位

这是进程正常结束,那进程异常结束呢?我们知道进程异常退出,其实是系统杀掉了进程,系统向进程发送杀掉信号。进程一但异常退出,那么其进程返回码就失去了意义。
所以如何获取这个信号呢?
(status >> 7) & 0x7F // 0000... 111 1111 保留最后7个比特位,(注意:如果status如果已经进行位向右移,这次的位运算是会在上次的基础上向右移)

进程异常结束,不都是进程内部代码问题,也有可能是外部原因,比如:kill -9 杀死进程,错误消息就是9
但是,这个还得知道status的组成,然后需要进行位运算,这个了解还行,但使用长期下来不方便,因此,为了使用方便提供了如下:
常用获取进程退出情况(推荐)
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程 是否是正常退出 )WEXITSTATUS(status): 若 WIFEXITED 非零,提取子进程退出码。(查看 进程的退出码 )
补充:

c, 参数options
option默认为0,表示子进程运行时,父进程为阻塞等待; WNOHANG 参数,是一个宏定义,表示父进程为非阻塞状态。(WNOHANG理解:HANG是一种专业的术语,如果一个进程卡死,这个进程要么在阻塞队列中,要么等地被调度,所以称作这个进程HANG住了。所以NOHANG就是非阻塞等待)
Linux由C语言编写,wait本质上是系统中的一个函数,我们通过一个伪代码来理解:
 那非阻塞等待,难道是不等待子进程?本质上,非阻塞等待是基于非阻塞调用的轮询方案,说人话是,我找张三帮忙,张三说在忙,我先做我的事,然后每过一分钟给他打个电话,查看他是事是否做完。
那非阻塞等待,难道是不等待子进程?本质上,非阻塞等待是基于非阻塞调用的轮询方案,说人话是,我找张三帮忙,张三说在忙,我先做我的事,然后每过一分钟给他打个电话,查看他是事是否做完。
四,进程替换
1,概念与原理
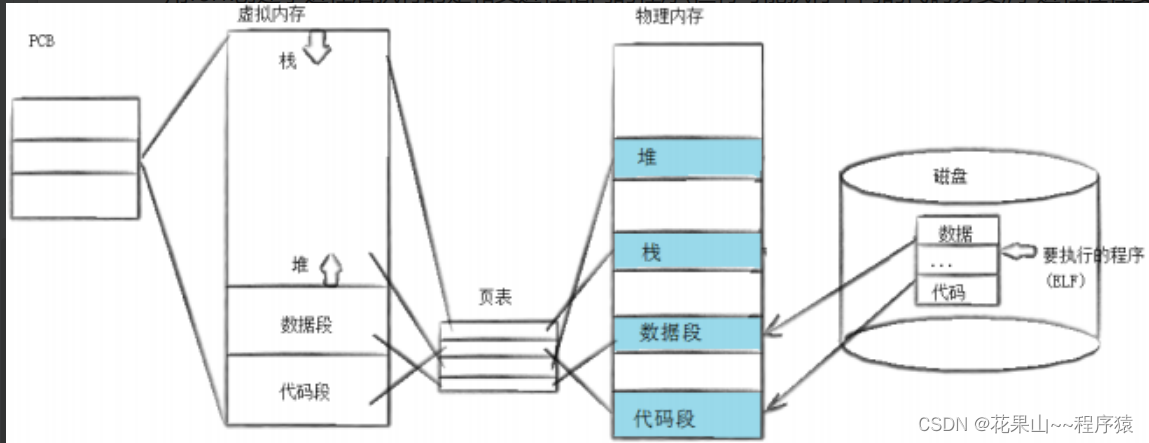
2,进程替换方法
方法:通过execl函数
我们问问man
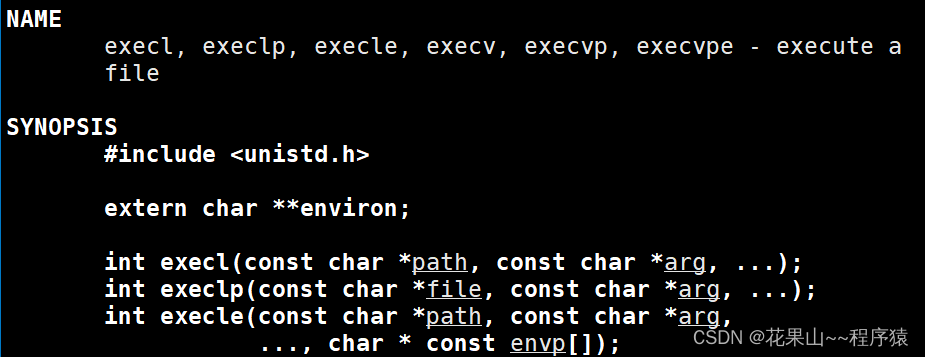
今天我们来学习最简单的execl。
int execl (const char* path, const char* arg, ...) // 路径 , 命令行上该怎么写就怎么写
path : 目标程序的地址+路径
arg: 函数参数
... : 的意思是可变参数列表,注意点:参数列表必须以NULL结尾,这表示参数提取结束。
下面是例子:

从上面的观察中发现:
1. 进程替换后,"进程结束"没有打印,这一点可以佐证,一旦execl函数调用成功,原来进程的代码和数据全部被替换为新进程。
2. 如果execl调用失败,继续原来进程,不过这时可以直接终止进程。
3. 尝试fork + execl函数
看下面代码:
1 #include <iostream>2 #include <unistd.h>3 #include <sys/types.h>4 #include <sys/wait.h>5 using namespace std;6 7 int main()8 {9 pid_t pd = fork();10 if (pd == 0)11 {12 // 子进程13 cout << "子进程开始, pid:" << getpid() << endl;14 execl("/usr/bin/ls", "ls","-l", "-a", "--color=auto", NULL);15 exit(-1);16 17 }else if (pd)18 {19 // 父进程20 int status = 100;21 cout << "父进程开始" << endl;22 pid_t ret = waitpid(-1, &status, 0); 23 if (ret)24 {25 cout << "子进程退出,打印子进程退出码:" << WEXITSTATUS(status) << endl;26 }else 27 {28 cout << "子进程未退出" << endl;29 }30 32 }33 else 34 {35 cout << "创建子进程失败" <<endl;36 }37 return 0;38 }结果:
问:为什么要创建子进程来替换呢?
答:为了实现父进程读取数据,分析数据,然后指派子进程去完成某项任务的思想。
问:父子进程代码共享,数据写时拷贝?那execl函数替换进程了呢?代码是否会进行写时拷贝?
答:会,因为如果父子进程共享,在调用execl函数时,会对代码进行写时拷贝,否则父进程会受到影响。
其他函数补充:
进程替换函数其实还是有挺多接口的,如下:

1. execv 函数,使用一图流如下:
2. execlp函数,
3. execvp函数,这个就挺容易用的,可以这么理解,指令方式以Vector存储,并且“P”省略文件路径,自动搜索环境变量。
4. execle函数,"e"表示的则是环境变量的意思,通过传递环境变量给新程序,可以在新程序中使用这些环境变量的值。例如,可以通过设置环境变量来影响新程序的行为,或者传递一些需要在新程序中使用的配置信息。
下面是一个示例,展示了如何使用execle函数传递环境变量:
#include <unistd.h>int main() {char *envp[] = {"MYVAR=Hello", "OTHERVAR=World", NULL};execle("/path/to/program", "/path/to/program", NULL, envp);return 0;
}
在上面的示例中,我们定义了两个环境变量MYVAR和OTHERVAR,并将它们传递给新程序。新程序可以使用getenv函数来获取这些环境变量的值。
需要注意的是,使用execle函数时,必须传递完整的环境变量数组,包括系统默认的环境变量。如果只想传递自定义的环境变量,可以使用execve函数(这是真正的系统调用,其他exec**函数都只是封装),并将environ变量作为参数传递给它。(来自chatgpt)
这里有个值得注意的点,即使是进程替换,环境变量是系统方面的数据,子进程会拷贝一份父进程的环境变量,且不会被替换。
命名总结:
l(list) : 表示参数采用列表v(vector) : 参数用数组p(path) : 有p自动搜索环境变量PATHe(env) : 表示自己维护环境变量
4. 如何利用execl函数运行其他可执行程序
诺,下面是我在Test程序上调用mypro程序。
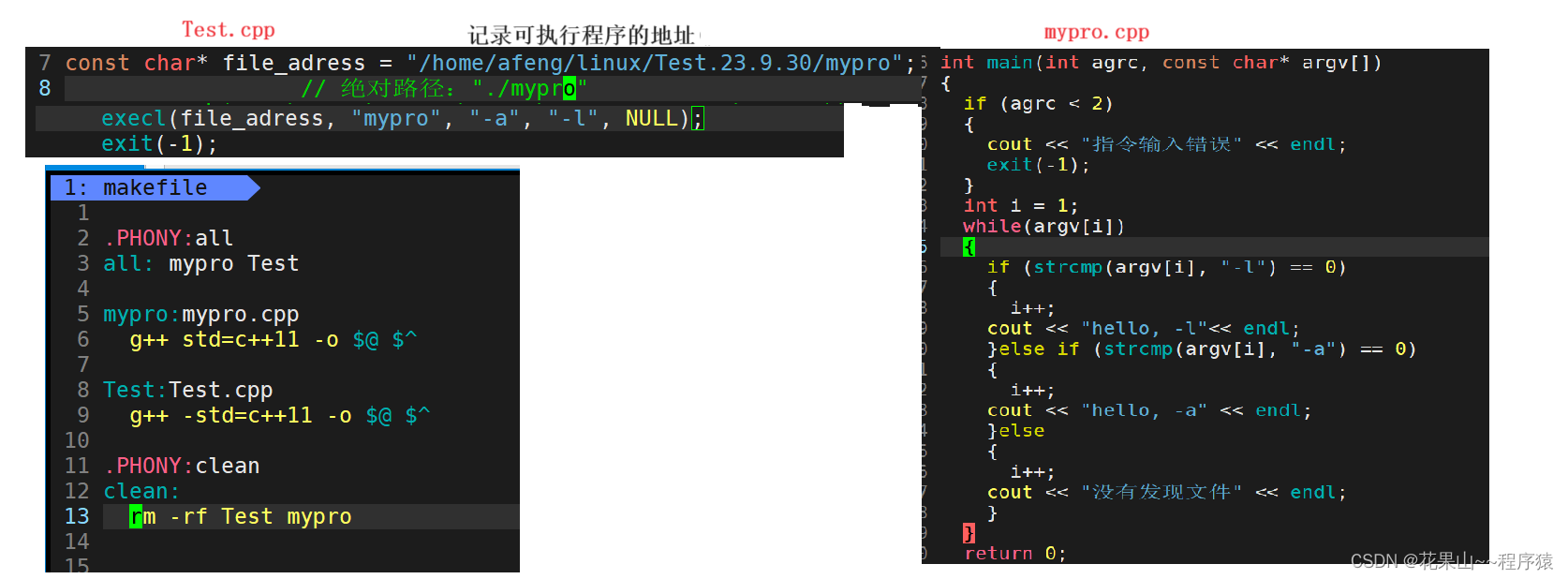
makefile: 可以做到一次编译多个文件。
最右侧的图,运用到了命令行参数,可参考本博客中命令行参数部分【Linux】进程基础概念【下篇】-CSDN博客
到这里我们,我们可以理解exec***函数的功能——底层加载器的接口
五,练习——制作一个简单的shell命令解释器
目标:
制作一个能读取,并执行指令的shell。
shell执行命令:

1. 制作框架方面:
我们需要制作一个死循环,不断的接收指令。
// 属于是死循环13 while (1)14 {15 // 首先是打印地址16 cout << "[afeng@_myshell]$ ";17 fflush(stdout); // 解决缓冲区的问题}我们可以简单打印一个shell名,但不能换行,但不能换行,就会有缓冲区的问题,通过fflush函数刷新即可。
2. 接收,并处理指令
不能使用cin, scanf 因为,指令伴随空格,cin,scanf遇到空格提前结束输入,这里我们采用可以接收空格字符的函数,比如:getline, 输入流函数fgets。我们首先将指令保存到指针数组中,由于我们只是简单制作一个shell,所以指令程序我们选择调用,而选择调用我们就要进行进程替换。(说到这里我们需要区分的是,我们利用子进程替换仅仅是为了启动其他程序,父进程的未层修改。)使用进程替换函数exec***,我们就得将指令分割下来。
// 然后开始接收指令20 char instruct[NUM];21 memset(instruct, '\0', sizeof instruct);22 if (fgets(instruct, sizeof instruct, stdin) == NULL)23 {24 continue;25 }26 instruct[strlen(instruct) - 1] = '\0';// 在输入指令后,我们会通过回车键确认,但回车键被当做'\n'记录,所以需要纠正。27 28 // 开始拆分出指令29 char* argv[100] = {0};30 argv[0] = strtok(instruct," ");31 int i = 1;
W> 32 while (argv[i++] = strtok(NULL, " "));
3. 子进程替换,父进程等待
接下来就是子进程与父进程的编写,子进程替换,我们知道我们在Linux中能不带路径的执行相应指令的基础是其路径已经存在环境变量中,所以系统会自动搜索。
36 // 内置命令 1.我们通过子进程替换打印我们需要的结果,父进程不受影响37 // 当需要更改路径时,目标是父进程38 if (strcmp(argv[0],"cd") == 0)39 {40 if (argv[1] != NULL)41 chdir(argv[1]);42 continue;43 }44 45 pid_t pd = fork();46 if (pd == 0) // child47 {48 execvp(argv[0], argv);49 exit(-1); 50 }51 else{52 // parent53 int status;54 pid_t ret = waitpid(pd, &status, 0);55 if (ret > 0 )56 {57 cout << "子进程运行成功,退出码:" << WEXITSTATUS(status)<< endl;58 }else{59 cout << "子进程运行失败,退出码:" << WEXITSTATUS(status)<< endl;}61 }62 }63 return 0;64 }
结语
本小节就到这里了,感谢小伙伴的浏览,如果有什么建议,欢迎在评论区评论,如果给小伙伴带来一些收获请留下你的小赞,你的点赞和关注将会成为博主创作的动力。



![[前端基础]typescript安装以及类型拓展](http://pic.xiahunao.cn/[前端基础]typescript安装以及类型拓展)








)


)

![【数据科学】Scikit-learn[Scikit-learn、加载数据、训练集与测试集数据、创建模型、模型拟合、拟合数据与模型、评估模型性能、模型调整]](http://pic.xiahunao.cn/【数据科学】Scikit-learn[Scikit-learn、加载数据、训练集与测试集数据、创建模型、模型拟合、拟合数据与模型、评估模型性能、模型调整])
——JSX、TSX语法详解)
