国产数据库-内核特性-gbase8a智能索引
南大通用gbase8a MPP Cluster是一款分析型MPP数据库,有个特性鲜明的功能就是智能索引。该索引建立膨胀率不超过百分之一,包含基于列的统计信息,可以有效过滤数据,大幅降低数据库磁盘IO,尤其是在聚合操作上也能达到很高的性能。
1、infobright
Infobright是一款开源列式存储数据库,采用知识网格查询优化方式,对即席查询有很大提升。可惜已经没人维护了。而Gbase8a的列存就是基于infobright。吸收了infobright列存带来的优势,我们看下infobright典型结构:

Infobright通过知识网格进行数据筛选,从而降低数据IO。知识网格由Knowlege Node、Data Pack Node和Data Pack组成。
1)Data Pack(DP):将数据按照64K行的大小切分成一个一个的Rough Rows,而Rough Rows根据列分为一个个Data Pack。他是底层的数据存储单元,也是基本的压缩/解压缩单元。每个列第i个DP包中行数是一样的。
2)Data Pack Node(DPN):一个DPN与一个DP对应,存储了:最大值、最小值、平均值和sum值,以及null值数量和记录总数量;压缩方式;占用的字节数等
3)Knowlege Node(KN):相比DPN由了更高层的一些智能化信息,包括直方图、字符位图和pack-to-pack。
4)直方图:包含数值类型的列细腻些。根据每个DP中实际数据分布,将数值范围分成1024段,若某段中有数据则标记1,否则标记0。查询时,可以快速判断该列数据是否满足条件。
5)字符位图:字符类型列的映射表。映射表中每个格子占用一位,表示字符在字符串的该位置是否存中,查询时可以快速判断列数据是否满足条件。
6)Pack-to-pack:是一个特殊的元数据,存储两个表在列上的join关系。也是一个二维矩阵,每个格子1位,表示表1某列的第i个DP与表2中某列的第j个DP至少有一个值相等满足等值join条件。
Infobright对数据进行进一步划分,根据查询条件,通过知识网格对DP进行分类:
1)无关DP:DP中没有符合查询条件的数据
2)强相关DP:DP中所有数据都符合查询条件
3)待定DP:可能部分数据符合条件。
针对普通查询,只有相关DP和待定DP才需要进行解压。
2、gbase8a技术白皮书讲解
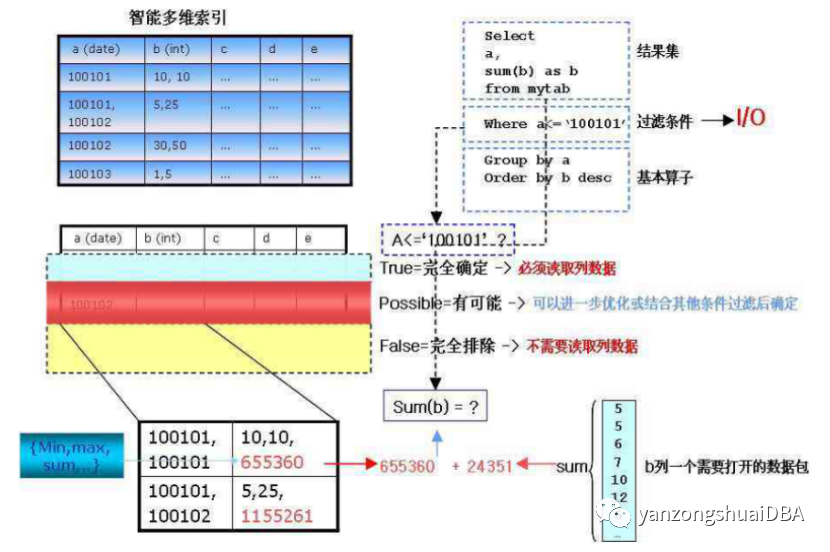
假设表mytab有A、B、C、D、E五列,每列都有几个数据包。
测试语句:select a,sum(b) as b from mytab where a<=’100101’ group by a order by b desc;
1)根据查询条件,智能索引先过滤A的数据包,即哪些数据包符合a<=’100101’这个条件。上图,淡蓝和红色表示强相关和待定。
2)对于淡蓝的数据,只需要访问B数据包的智能索引信息,就能得到sum信息,不需要对此数据包进行解压。这里的sum值是655360。(白皮书这样说不对吧,如果没有group by a倒是可以理解;加上group by a,怎么理解?强相关DP中,a列相同值不止一个吧,不能直接使用B数据包的索引信息,它的索引信息是没分组的。不了解gbase8a中对带group by的聚合到底是怎么实现的,有了解的可以一起讨论下)
3)对于红色的数据,将其对应的A、B包解压,进行查询聚合计算
4)将2)和3)的结果求和,返回。
不管怎么说,刨除带group by外,从上述原理上可以看出,过滤操作可以通过每个DP包的统计信息快速筛选出满足条件的DP包,强相关的DP包仅从它的统计信息中就可以得到聚合值,无需再解压DP包并进行扫描计算,无关DP包就可以直接跳过。大大降低了计算过程及IO。
3、参考
https://www.researchgate.net/publication/221213121_Data_warehouse_technology_by_infobright
https://www.researchgate.net/publication/252041317_Research_of_infobright_based_on_MySQL's_open_source_engine
https://www.docin.com/p-70898761.html



)
)
)





:图标库知识点)




)
(20230725))
9.2-信息发送的Filter机制)
