
🚀write in front🚀
📜所属专栏: C++学习
🛰️博客主页:睿睿的博客主页
🛰️代码仓库:🎉VS2022_C语言仓库
🎡您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!
关注我,关注我,关注我,你们将会看到更多的优质内容!!

文章目录
- 1. 关联式容器
- 2. 键值对
- 3. 树形结构的关联式容器
- 3.1`set`:
- 3.1.1:set的介绍:
- 3.1.2set几个常用函数:
- a.count函数:
- b.find函数:
- c.边界处理的函数:
- lower_bound和upper_bound:
- equal_range:
- 3.1.3set的使用:
- 3.2`multiset`:
- 3.3`map`:
- 3.3.1map的介绍:
- 3.3.2map的常用函数:
- a.insert函数:
- b.map的遍历:
- c.[]访问:
- 3.3.3map的使用:
- 3.4multimap:
- 一道经典例题:
- 方法1:
- 方法2:
- 方法3(不推荐):
1. 关联式容器
在初阶阶段,我们已经接触过STL中的部分容器,比如:list,vector,deque,forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。
那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,并且在数据检索时比序列式容器效率更高(实现是AVL树,就是进阶版的二叉搜索树)。
2. 键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
};
3. 树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap,multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列(都是中序遍历)。下面一依次介绍每一个容器。
3.1set:
3.1.1:set的介绍:
-
set是按照一定次序存储元素的容器
-
set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。

-
set在底层是用二叉搜索树(红黑树)实现的。
-
与
map不同,map中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是<value, value>构成的键值对。 -
set中插入元素时,只需要插入value即可,不需要构造键值对。
-
set中的元素不可以重复(因此可以使用set进行去重)。
-
使用set的迭代器遍历set中的元素,可以得到有序序列
-
set中的元素默认按照小于来比较:
less<T>

-
set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2n
3.1.2set几个常用函数:
和其他容器一样,set的迭代器,构造函数,析构函数,容量,插入删除等函数可以自己去查看文档了,在这里我就讲几个常用和易错的几个函数:
a.count函数:

此函数就是返回val值在set里面有多少个。但是因为set里面的元素不重复,所以这个函数在set里面只可能返回0或1,所以我们查找元素在不在的时候可以使用这个函数。
b.find函数:
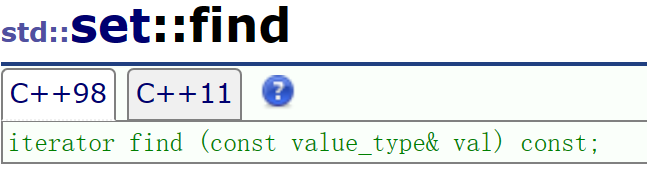
其实这个函数也很简单,我们只需要注意一下他的返回值:
- 找到了就返回那个地方的迭代器
- 没找到就返回末尾的迭代器
end()
c.边界处理的函数:
lower_bound和upper_bound:
说白了,这两个函数就是为了erase()服务的:他们可以给erase提供一个范围空间,供其删除中间的内容。
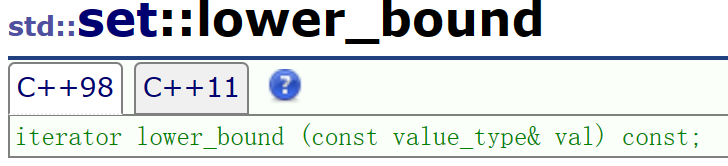
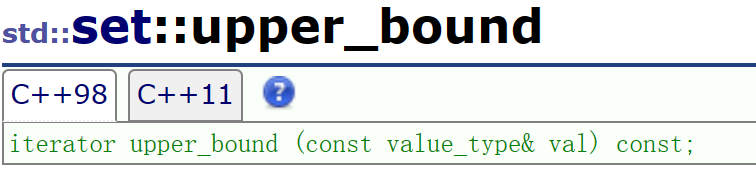
由于erase删除的时候是左闭右开的原则,这两个函数根据这个原则,lower_bound返回的值是>=val的,而upper_bound返回的值是>val的(都是为了左开右闭准备的)
举个🌰:
multiset<int> s;for (int i = 1; i < 10; i++){s.insert(i * 10);//10 20 30 40 50 60 70 80 90}auto itlow = s.lower_bound(30);//30auto itup = s.upper_bound(60);//70cout << *itlow << endl;cout << *itup << endl;s.erase(itlow,itup);//左闭右开,删除了30,40,50,60
equal_range:

说白了,这个函数也是应该使用在multiset里面更好,他是返回val值的一小段区间,其实也是为了erase这个val值。他返回的这个值是一个pair,第一个其实就相当于lower__bound,第二个就相当于upper__bound
auto ret = s.equal_range(30);//该函数返回的是一个pair,因为也要左闭右开,所以还是和什么一样,而pair的first是lower,second是upperauto itlow = ret.first;//>= 这里相当于lower_boundauto itup = ret.second;//> 这里相当于upper_boundcout << *itlow << endl;//cout << *itup << endl;s.erase(itlow,itup);//左闭右开
3.1.3set的使用:
set可以进行去重,或者检查有没有重复的元素,比如我们之前做的判断链表是否为环形链表的题,如果我们将链表的结点都存入set,如果发现一样的,那就一定是环形链表了。(判断记得用count()更简单)
3.2multiset:
其实有两个函数就是为multiset写的:

还要就是在删除erase(val)或通过equal_range()删除val的时候,会将val值全部删掉!!
3.3map:
3.3.1map的介绍:
- 在map中,键值key通常用于排序和唯一的标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型
value_type绑定在一起,为其取别名称为pair:typedef pair<const key, T> value_type; - 在内部,map中的元素总是按照键值key进行比较排序的。
- map支持下标访问符加粗样式,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树)
- key的值不能改,value的值可以改:
typedef pair<const key, T> value_type;
3.3.2map的常用函数:
a.insert函数:
对于pair类型,我们该怎么插入呢?有下面几种方法:
map<string, string> mp;//c++98!!//方法一:构造后插入pair<string, string> k1("insert", "插入");mp.insert(k1);//方法二:匿名对象插入mp.insert(pair<string, string> ("sort", "排序"));//方法三:调用make_pair函数mp.insert(make_pair("string", "字符串"));//c++11:支持了多参数的构造函数隐式类型转换!!mp.insert({ "map","映射" });
b.map的遍历:
那么,我们的map如何遍历呢?
其实还是和其他的容器一样,只是我们的map里面是pair类型,要多一次解引用:
auto it = mp.begin();while (it != mp.end()){(*it).second = "xxx";//(*it).first = "xxx";只能修改第二个值,不能修改第一个值cout << (*it).first << " :" << (*it).second << endl;it++;}cout << endl;while (it != mp.end()){cout << it->first << " :" << it->second << endl;//这里本来应该是it->->first原本是://pair<K,V> operator->()//{//return &it->val;//}it++;}for (const auto& kv : mp){//kv.second = "ccc";cout << kv.first << " :" << kv.second << endl;}
c.[]访问:
如果要通过map来统计次数该如何统计呢?
通常大家会这样统计:
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> mp;for (auto& ch : arr){auto it=mp.find(ch);if (it == mp.end()){mp.insert({ ch,1 });}else{it->second++;}}
但是还要更简便的方法,那就是使用[]。我们先来看看他的使用:
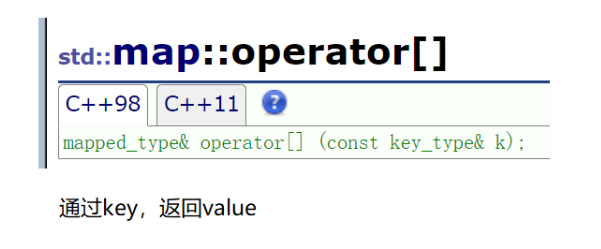
实际上这里的源码是这样的:

这里就不得不说insert的返回值了:

所以上面[]的实现简化下来是这样的:

所以上面的统计次数可以这样来写:
string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> mp;
for (auto& ch : arr){mp[ch]++;}
这样的话,我们就可以通过key来插入/修改value的值了,是不是很方便呢?
3.3.3map的使用:
map其实就是一种映射关系,以后只要见到有映射关系的题目都可以通过map来实现:
比如之前的括号的题目:
还有随机链表复制的题目。
3.4multimap:
multimap和multiset类似,就是可以存入相同的key的值。
一道经典例题:
前k个高频单词

在学习了map之后,我们就可以通过map进行计数,而且而且!map还顺便排了个序!!虽然不是最终结果,但是还是给我们省了很多步骤。下面有三种方法解决这个问题:
方法1:
先用map统计次数,而且此时也正好按字典序排序了,但是要按次序排序,而我们map不能通过算法里面的排序(快排是用数组的),所以我们用vector来保存pair。但是最后在快排的时候,快排没有稳定性(相对位置会改变),所以我们用另外一个排序,叫stable_sort来排序。
class Solution {
public:struct Greater{bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){return kv1.second > kv2.second;}};vector<string> topKFrequent(vector<string>& words, int k){map<string, int> countmap;for (const auto& ch : words){countmap[ch]++;}vector<string> v;vector<pair<string, int>>kv(countmap.begin(), countmap.end());stable_sort(kv.begin(), kv.end(), Greater());for (int i = 0; i < k; i++){v.push_back(kv[i].first);}return v;}
};方法2:
其实,我们还可以通过对仿函数进行限制,还是可以使用sort函数排序的。此时仿函数的限制就非常的巧妙!!在次数相等的时候让其通过字典序来比!!
class Solution {
public:struct Greater{bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){return kv1.second > kv2.second || kv1.second == kv2.second && kv1.first < kv2.first;}};vector<string> topKFrequent(vector<string>& words, int k){map<string, int> countmap;for (const auto& ch : words){countmap[ch]++;}vector<string> v;vector<pair<string, int>>kv(countmap.begin(), countmap.end());sort(kv.begin(), kv.end(), Greater());for (int i = 0; i < k; i++){v.push_back(kv[i].first);}return v;}
};
方法3(不推荐):
multimap在构建的时候,在排序有可能是稳定的(这个看编译器,其他编译器不一定对)。所以如果multimap稳定的情况下,我们就可以在创建一个multimap,来通过次数再来排一次序!
class Solution {
public:struct Greater{bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){return kv1.second > kv2.second || kv1.second == kv2.second && kv1.first < kv2.first;}};vector<string> topKFrequent(vector<string>& words, int k){map<string, int> countmap;for (const auto& ch : words){countmap[ch]++;}multimap<int, string, greater<int>> sortMap;for (const auto& e : countmap){sortMap.insert({ e.second,e.first });}vector<string> v;auto it = sortMap.begin();while (k--){v.push_back(it->second);++it;}return v;}
};
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
专栏订阅:
每日一题
C语言学习
算法
智力题
初阶数据结构
Linux学习
C++学习
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!

Chapter 10 Mining Social-Network Graphs)








)



)
和Mapper映射文件(XXXMapper.xml)模板)


)

