1. Agent (智能体)
智能体是进行决策和学习的实体,它能感知环境的状态,并基于策略采取动作以影响环境。智能体的目标是通过与环境的交互获得最大化的累积奖励。
2. Environment (环境)
环境是智能体所处的外部系统,它与智能体交互。环境的状态可能对智能体可见(如游戏中的棋盘状态),也可能对智能体不可见(如对手的策略)。
例如:在无人驾驶中智能体是无人驾驶系统,环境则是汽车本身、其他的汽车及建筑等。

他们之间关系如下:

3. Action (动作)
动作是智能体基于观察到的状态所做出的决策或行为,影响环境的转移。动作可以是离散的(如移动棋子)或连续的(如调整机器人的速度)。
4. Reward (奖励)
奖励是环境提供的数值反馈,用于评估智能体的动作质量。智能体的目标是通过选择动作最大化长期累积的奖励。
5. History (历史)
历史是指在交互过程中智能体观察到的状态、执行的动作和获得的奖励的序列。它是智能体进行决策的依据。

6. State (状态)
状态是描述环境的特定情况或配置的信息。智能体状态(Agent State)指其内部的信息,而环境状态(Environment State)指外部的环境信息。
有时候智能体状态可能会等同于环境状态,相当于开了上帝视角(没有战争迷雾),这时候两个state等同。
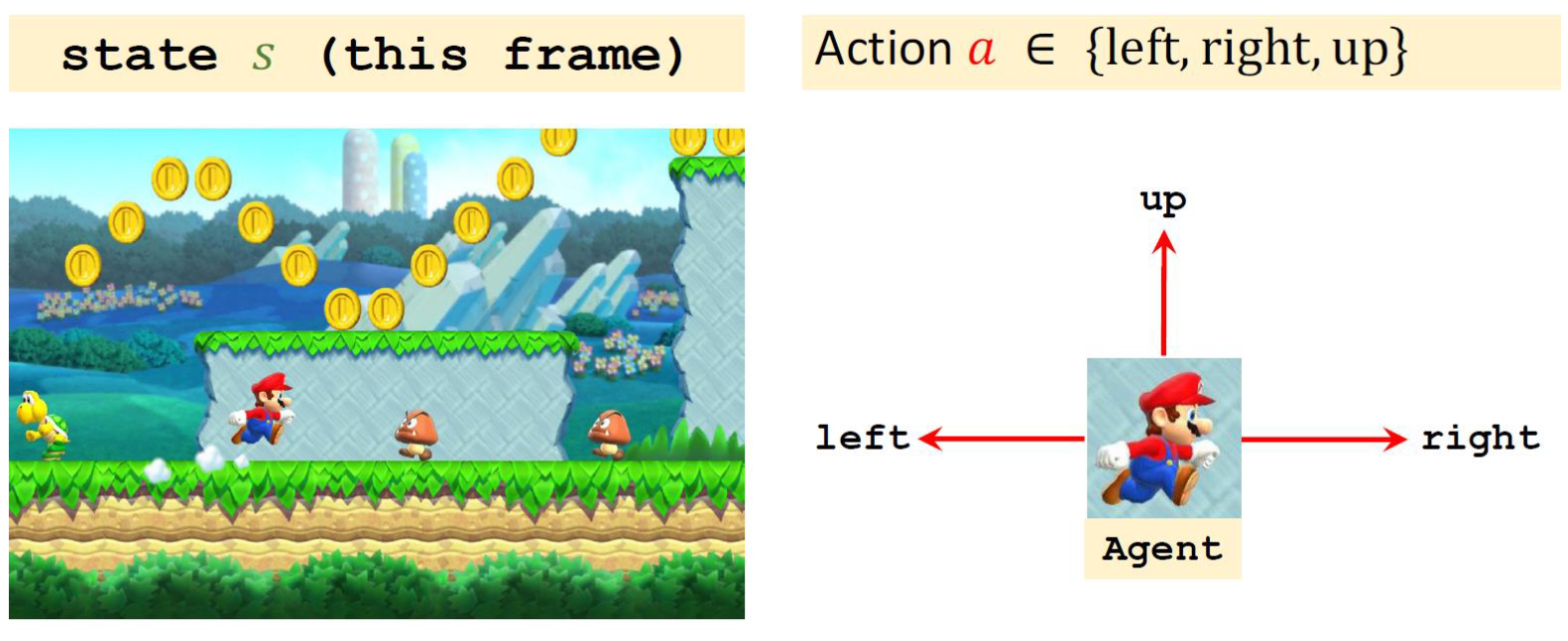
7. Policy (策略)
策略是智能体在特定状态下选择动作的规则或概率分布。良好的策略能使智能体获得更高的奖励。
我们一般用 来表示,表示在state下采取什么action(从 state 到 action的函数)。


8. Return (回报)
回报是指智能体在一个决策序列中获得的奖励的总和,可以用来评估策略的好坏以及选择最优策略。回报可以选择计算总奖励、折扣奖励以及平均奖励。

当游戏没有具体的轮次时,不确定时间,通常采用折扣奖励:

9. Model and State Transition (模型与状态转移)
模型是对环境的内部表示,用于预测状态转移和奖励。状态转移指从一个状态到另一个状态的转变过程。
10. Exploration and Exploitation (探索与利用)
在强化学习中,智能体需要在已知最佳动作的基础上进行利用以获得奖励,同时也需要探索未知动作以发现更优的策略。
Exploration 可以发现更多关于环境的信息
Exploitation 利用已知信息实现回报最大化
(我们需要定义一个概率使得模型进行随机探索,初期时占比应该更大一点。)
11. Model Free and Model Based (无模型学习与基于模型学习)
强化学习可以分为无模型学习,即不依赖模型直接学习策略,和基于模型学习,即利用环境模型进行规划和学习。
12. On-policy and off-policy (在策略和离策略)
在线策略方法(On-policy)是指智能体在学习过程中采用与它当前策略相符的样本进行学习。
(每一轮迭代的样本都直接拿来训练。)
离线策略方法(Off-policy)允许智能体从与其当前策略不符的样本中学习。
(具有经验缓冲区,可以随机抽样来训练。)
13. Classification of RL (强化学习分类)
-
13-1. Value based (基于值的方法)
- 这类方法主要关注值函数的学习,如Q-Learning、DQN等。
-
13-2. Policy based (基于策略的方法)
- 这类方法直接学习最优策略,如策略梯度算法等。
-
13-3. Actor-Critic (演员-评论家方法)
- 这类方法结合了值函数和策略的学习,同时使用演员(Actor)学习策略,评论家(Critic)学习值函数。








)


操作)
机制)

)
)



