在移动游戏对高品质画面的要求不断增加的背景下,我们一直专注于移动设备GPU性能的优化,以确保您的游戏体验得以最佳展现。然而,不同GPU芯片之间的性能差异以及由此可能引发的GPU瓶颈问题使得优化工作更加具有挑战性。
因此,在不久前,基于UWA最新发布的GOT Online GPU模式,我们为开发者提供了GPU性能优化免费试用测评和技术问诊服务。在总结经验时,我们发现了许多在开发、制作或优化性能过程中场景的问题,现在与大家分享,希望能够为大家提供一些有益的启示。
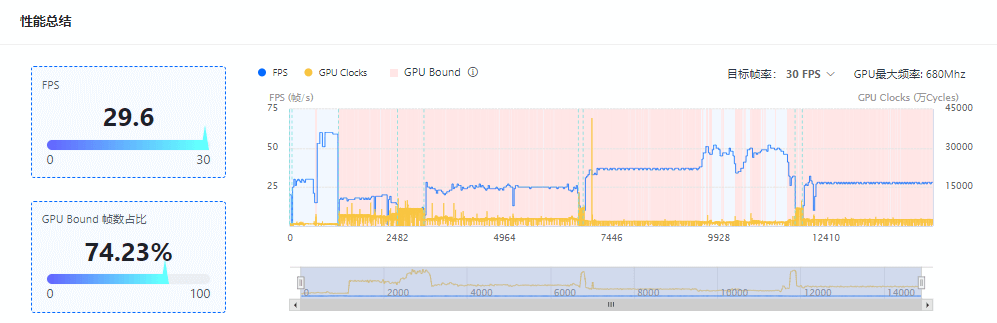
在GOT Online GPU模式报告中,UWA将GPU Clocks作为衡量GPU性能的主要指标,当GPU Clocks*目标帧率>=GPU最大频率*80%时,这一帧会被判定为GPU Bound并标记为粉色背景。GPU Bound反映了GPU在当前帧中计算所耗费的时钟周期数过高,使得单位时间内GPU的额定时钟周期数无法支持游戏满帧运行,即GPU压力。
当GPU出现Bound时,我们就需要通过一些更为细化的参数来分析,结合UWA报告的参数,例如GPU Shaded、GPU Primitive,Overdraw等走势,自行排查哪些参数造成的GPU渲染计算压力,并采取相应的优化方案。
1. 渲染密度顶点较多的网格 中招率:93%
网格最大屏占比和最小渲染密度则可以用于排查网格资源的精度是否合理,同时可以帮助降低网格渲染面片数。
网格的最大屏占比小于0.02%,说明该网格在手机屏幕中只占很小的一部分,可见性较低。如果报告中最大屏占比小于0.02%的网格较多,说明网格的精度过高,开发者可以考虑使用更低精度的模型进行替换。

渲染密度则表示在平均每一万像素(100*100,仅指甲盖大小的像素区)中网格的顶点数,如果该值大于1000,则说明我们在很小的画面中绘制了过于复杂的网格。

因此,当此网格的渲染密度最小时,如果该数值仍然高于1000,那么此网格的顶点数大概率是过高的,开发者可以考虑对这些网格资源进行减面操作,或使用LOD分级处理。
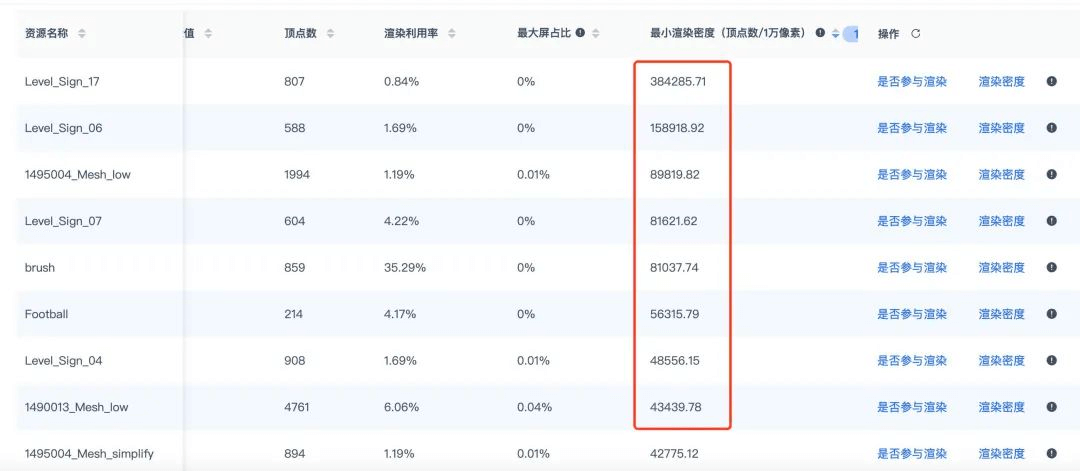
建议项目团队结合资源的渲染走势、生命周期和使用情况,进而更好地判断该资源是需要减模还是做Culling直接裁剪掉。
2. GPU不可见图元过多 中招率:92%
渲染面是产生GPU压力的重要因素之一。渲染面过多,一方面可能是模型过于复杂,一般可以通过 LOD、HLOD 等常用技术来简化远距离的模型,在不影响画质的情况下显著降低渲染面;另一方面,可能是地形、大建筑物等大面积模型没有进行适当的拆分,导致进入视域体的面片可能不多,但提交到GPU的渲染面依然很多。
在UWA的Primitive曲线中,我们可以看到:
总图元数:提交到GPU端的图元总数,该数值基本等同于引擎端统计的渲染面片总数。
可见图元数:在GPU端通过各种裁剪之后,留下的参与渲染的三角面。

在3D场景中,比较理想的情况下,可见图元的数量应该接近或高于 50%(对于大部分模型,有一半三角面会因为朝向被裁剪)。如果某些角度下,可见图元的比例非常低,则很可能存在上文提到的第二种情况,从而可以针对性地检查和优化场景中,这个角度下,被提交到GPU的大面积模型。
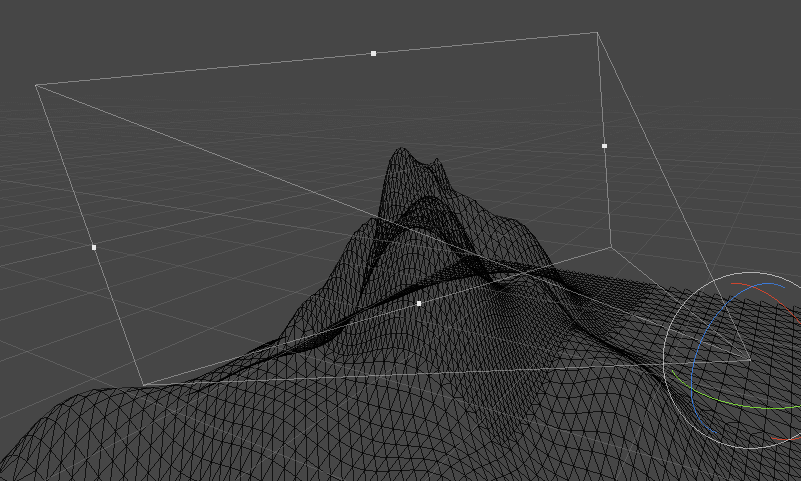
在如上项目中,我们看到大家这个裁剪的占比非常高,大部分场景下会有70%的比例。

我们建议应尽量在CPU端完成剔除,并减小送往GPU的图元数。
3. Overdraw较高 中招率:91%
Overdraw即多次绘制同一像素造成的GPU开销。在场景中渲染顺序控制合理的理想状况下,不透明物体的Overdraw应该尽量接近1。所以,造成Overdraw的主要元凶就是半透明物体,即粒子系统和UI。
在GPU模式中,我们定义了两种Overdraw,一种是“硬件”Overdraw,是由Fragment Shaded除以硬件分辨率得出,这种Overdraw是统计了后处理在内的渲染,也包括一些BlitCopy,如Copy Depth、Copy Color等;

另外一种是传统意义上的Overdraw,通过替换Shader渲染来计算叠加颜色的亮度从而计算得到的数值,这种Overdraw通常只统计场景或者UI,不会统计后处理以及BlitCopy,对于这种Overdraw,GPU模式提供了Overdraw视图。
这两种数值会存在一定的偏差,当偏差较大时,我们需要考虑是否是后处理造成的,如后处理中有较多的全屏BlitCopy。

结合热力图,也可以帮助排查导致Overdraw较高的来源。

如上图,从获得的Overdraw热力图中可以看到,爆炸特效对应的区域亮度较高,结合该场景截图判断该帧Overdraw较高应为爆炸特效所致。可以考虑以下方法进行:
(1)对粒子系统的最大粒子数量进行限制;
(2)在中低端机型上只保留“重要的”的粒子系统,对于该爆炸特效,可以只保留火焰本身,而关闭掉周边的烟尘效果;
(3)尽可能降低粒子特效在屏幕中的覆盖面积,覆盖面积越大,越容易产生重叠遮盖,从而造成更高的Overdraw。
4. 带宽过高 中招率:88%
由于GPU读、写带宽较高时都会造成大量的发热和耗电,需要开发者重点关注。
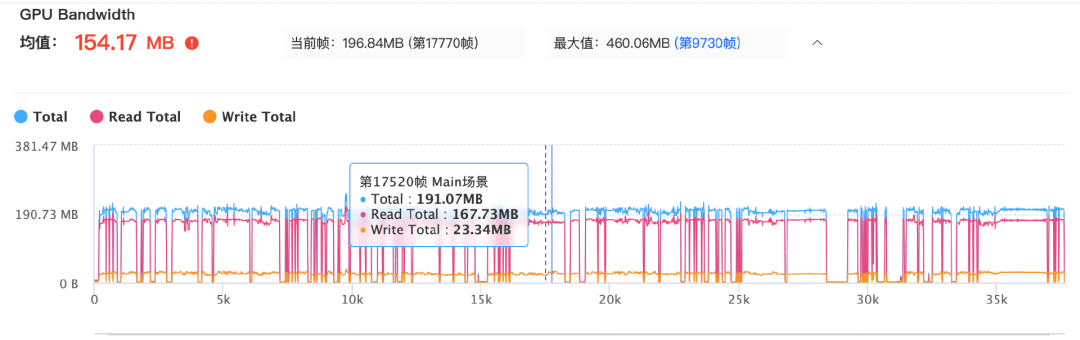
带宽分为 “读带宽”和“写带宽”,一般来说“读带宽”是个较高的占比,其中又分为读纹理和读顶点,我们需要关注以下这些方向:
>> 压缩格式
使用合理的压缩格式,能够有效降低纹理带宽。
>> 是否开启Mipmap
对于3D场景而言,对其中的物体材质的纹理开启Mipmap设置,能够用一小部分内存上升作为代价有效降低带宽。
>> 纹理的采样格式
纹理的各向异性采样和三线性插值采样,对于手游来说的性能开销都是较大的,应当尽量避免。概括来说,纹理采样时会去读OnChip缓存里面的内容,如果没命中就产生了Cache Miss,就会往离GPU更远的内存去读System Memory,因此会产生更大的Read带宽。当使用三线性插值采样或者各项异性采样时,纹理采样点会增多,在OnChip上的Cache Miss的概率就会变大,因此会造成带宽上升。
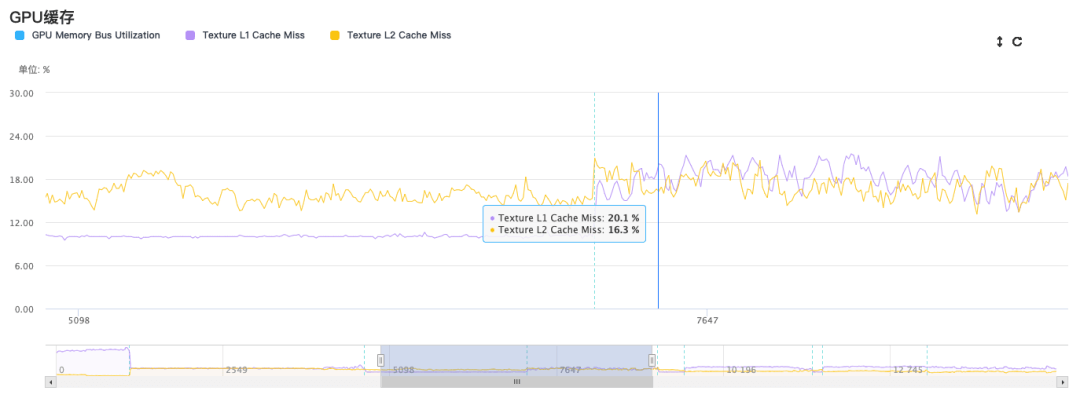
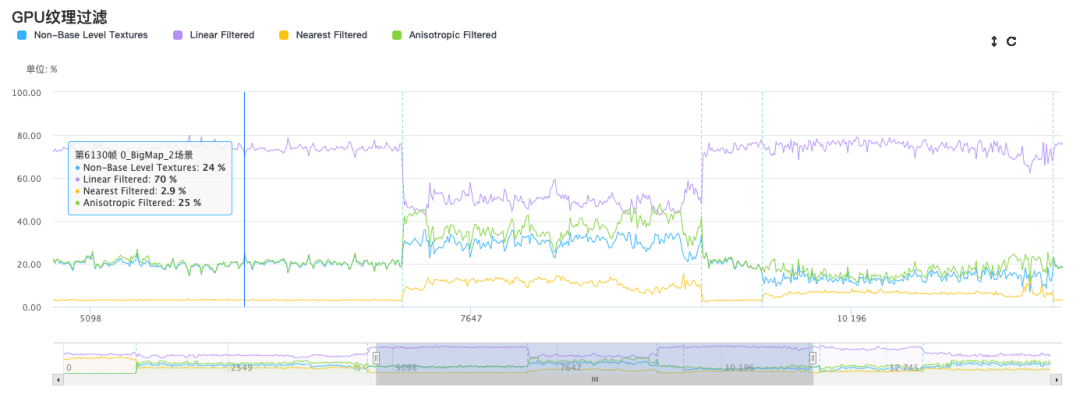
>> RT 相关采样的设置
比如Bloom的上下采样次数和采样的分辨率Blur、DOF、CopyColor CopyDepth,以及一些AA等操作,也是对带宽有较大的影响。
>> 分辨率
修改渲染分辨率为0.9倍乃至更低,会减少参与纹理采样的像素,也会降低渲染的RT的Load/Store的开销,最终降低带宽。
同时,功率和带宽是一个互相影响的逻辑,一般1G/S的带宽,会造成差不多 80 ~ 100 mw的功率开销。因此,也可以结合报告中的功率走势查看是否导致掉电过快的问题。
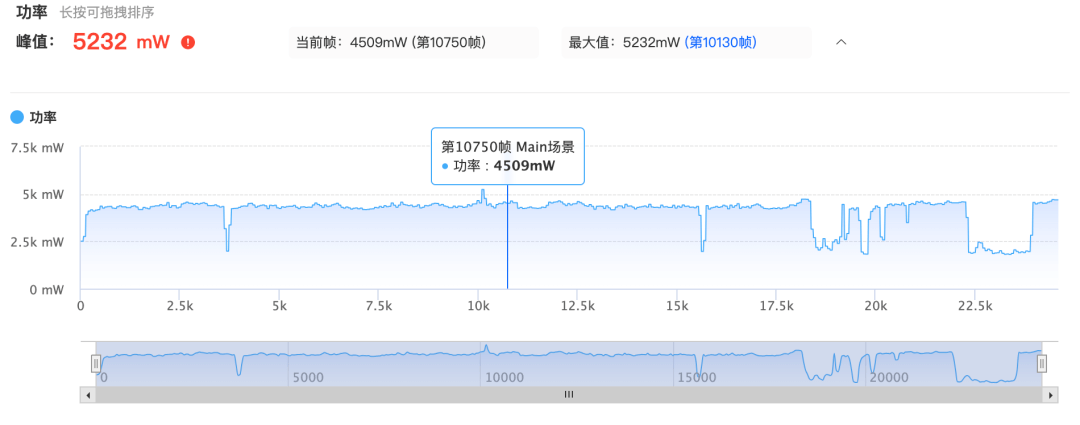
5. Shader复杂度过高 中招率:87%
片元阶段还有一个较为重要的影响因素,就是Shader Cycles,代表GPU花在Shader上的计算周期数。报告还列出了Shader Arithmetic Cycles、Shader Interpolator Cycles、Shader LoadStore Cycles、Shader Texture Cycles四项数据。用户可以快速定位到高Shader复杂度场景下,数学计算、顶点到像素插值、寄存器读取、纹理处理相关Cycles数中,哪一个单元是Shader复杂度过高的瓶颈,以便针对性地对项目的Shader复杂度情况进行排查和优化。

研发团队要避免在项目中存在大面积的Shader,比如建筑物地表的计算过于复杂,因为它的面积较大导致它的整体开销会比较大;另外一种就是半透明物体Shader,由于它更容易产生Overdraw,因此画的像素也会比较多,所以也要特别关注。
除此之外,也可以参考Mali Offline Compiler工具获取Shader的指令数和时钟周期数,对项目的Shader情况进行监控分析。
6. 渲染利用率为0的纹理/网格 中招率:83%

渲染利用率为0%,表示在整个游戏测试过程中,这些资源被加载到内存中,却没有提交给GPU,所以它的渲染利用率很低,甚至为0%。出现这种情况的原因主要有以下几点:
(1)过量加载导致资源被加载到内存中,但可能很少被用到或者压根用不到,建议研发团队结合具体资源名称查看资源的使用情况;
(2)测试过程中并没有测到这些资源,比如场景很大、特殊剧情需要触发或者特效预加载等等,建议制作更加全面的测试流程,尽可能把测试内容都跑全,最好做成自动化的遍历方式,进行长时间测试。
7. Mipmap层级使用不合理的纹理 中招率:82%
这里我们首先关注Mipmap第0层采样率低于20%的资源,这些资源大概率是尺寸过大,即没有物尽其用的,开发者可通过降低这些纹理资源分辨率缓解内存和GPU压力,同时也不会影响画面效果。

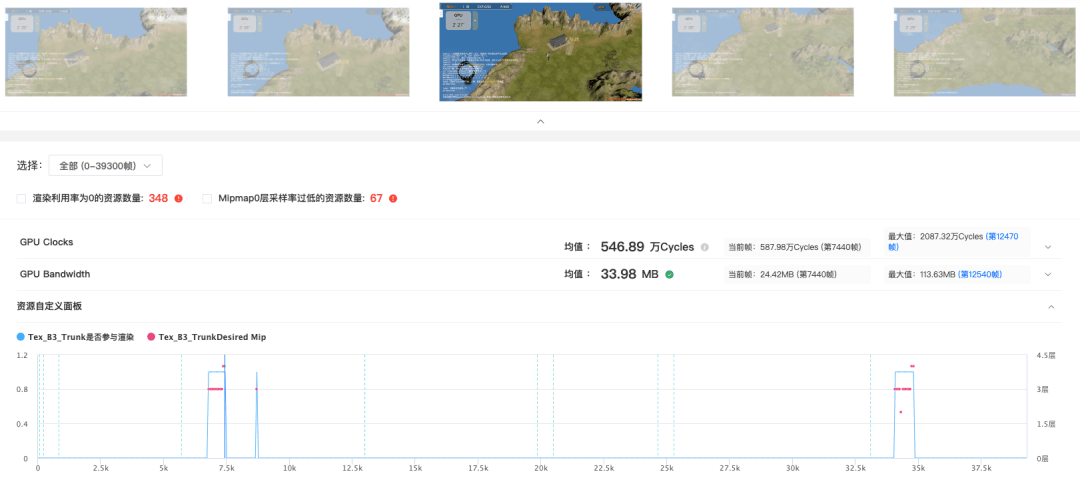
比如下图红框中的纹理,虽然是1024*1024,但是Mipmap第0层纹理在整个过程中完全没有使用过,96.15%的像素都是用128*128的层级进行采样的。
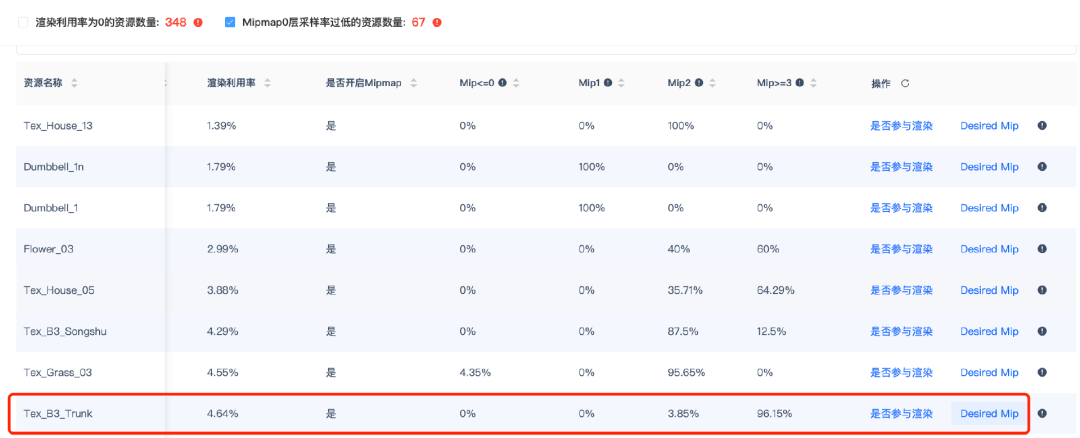
从它的使用生命周期中我们可以查到,该纹理在哪里参与渲染,以及使用的Mipmap层级具体情况:由于96.15%的像素用的都是Mipmap3+,所以该纹理可以直接从1024x1024的分辨率降为128x128,进而降低内存,提升加载效率。
虽然解决GPU的压力要注意方方面面,且随着玩家对于品质要求的提升优化的难度也越来越大,但好在通过科学的解题思路,再加上一些趁手的工具,我们也能一步步庖丁解牛,一些团队主动发来的优化前后对比效果,也是我们喜闻乐见的。

欢迎大家来使用UWA GOT Online GPU模式,帮助项目在渲染表现上达到更好的效果。



单元测试(Unit Testing, UT))



】)











