使用CNN实现简单的猫狗分类
完整代码见:基于Keras3.x使用CNN实现简单的猫狗分类,置信度约为:85%
文章目录
- 概述
- 项目整体目录
- 环境版本
- 注意
- 环境准备
- 下载miniconda
- 新建虚拟环境
- 基于conda虚拟环境新建Pycharm项目
- 下载分类需要用到的依赖
- 数据准备
- 数据目录结构
- 挪动图片可以采用下列代码
- config
- 准备训练、测试数据集
- 构建模型
- 训练模型
- 训练过程
- 损失和准确度曲线
- 测试模型
- 使用带标签的测试图片评估整体准确率
- 定义模型类
- 预测单张图片
- 将不带标签的测试图片分类并存到对应目录中
- 源码
- 错误记录
- 双重归一化问题
概述
项目整体目录
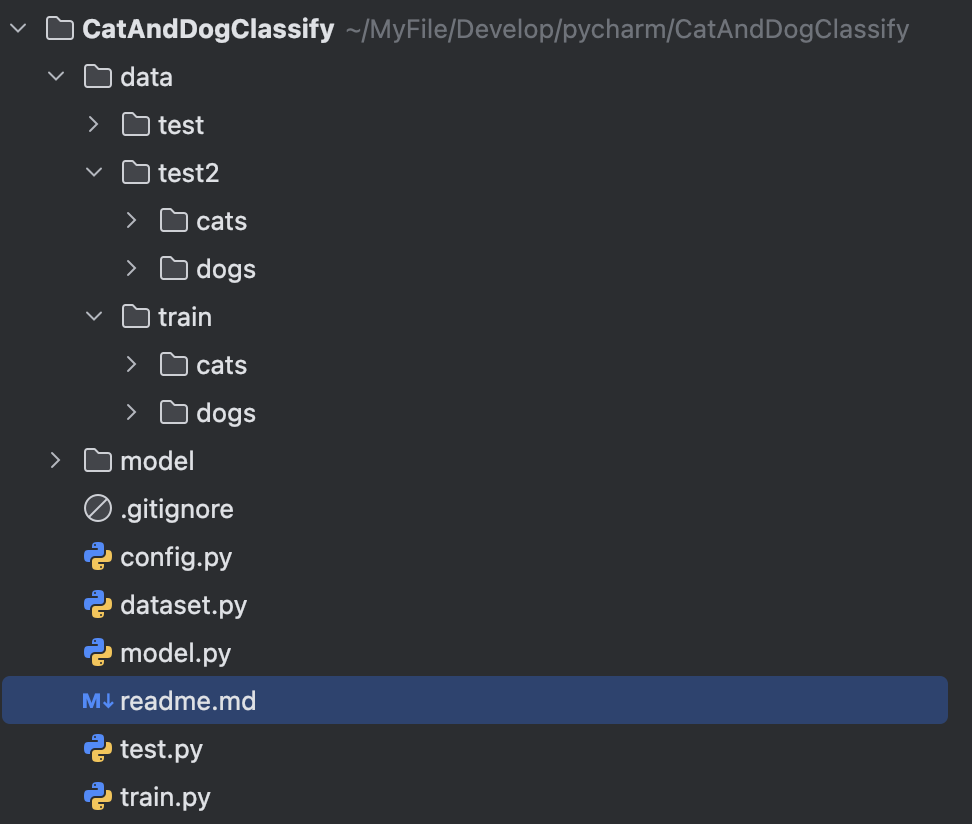
- /data 存放数据集
- /model 存放训练好的模型
- /config.py 存储一些关键模型参数和路径信息等
- /dataset.py 返回数据增强后的数据集,用于模型训练
- /model.py 定义模型
- /train.py 训练模型并绘制训练损失和准确度曲线
- /test.py 测试模型精准度
环境版本
- python 3.11
- keras 3.9.2
- tensorflow 2.19.0
注意
本项目使用Keras3.x实现,代码与keras 2.x有部分不同,请仔细甄别
环境准备
下载miniconda
如果没有下载conda,参照上一篇文章进行下载配置
新建虚拟环境
创建一个用于猫狗识别的虚拟环境,可以指定py版本
conda create --name catanddog python=3.11
基于conda虚拟环境新建Pycharm项目
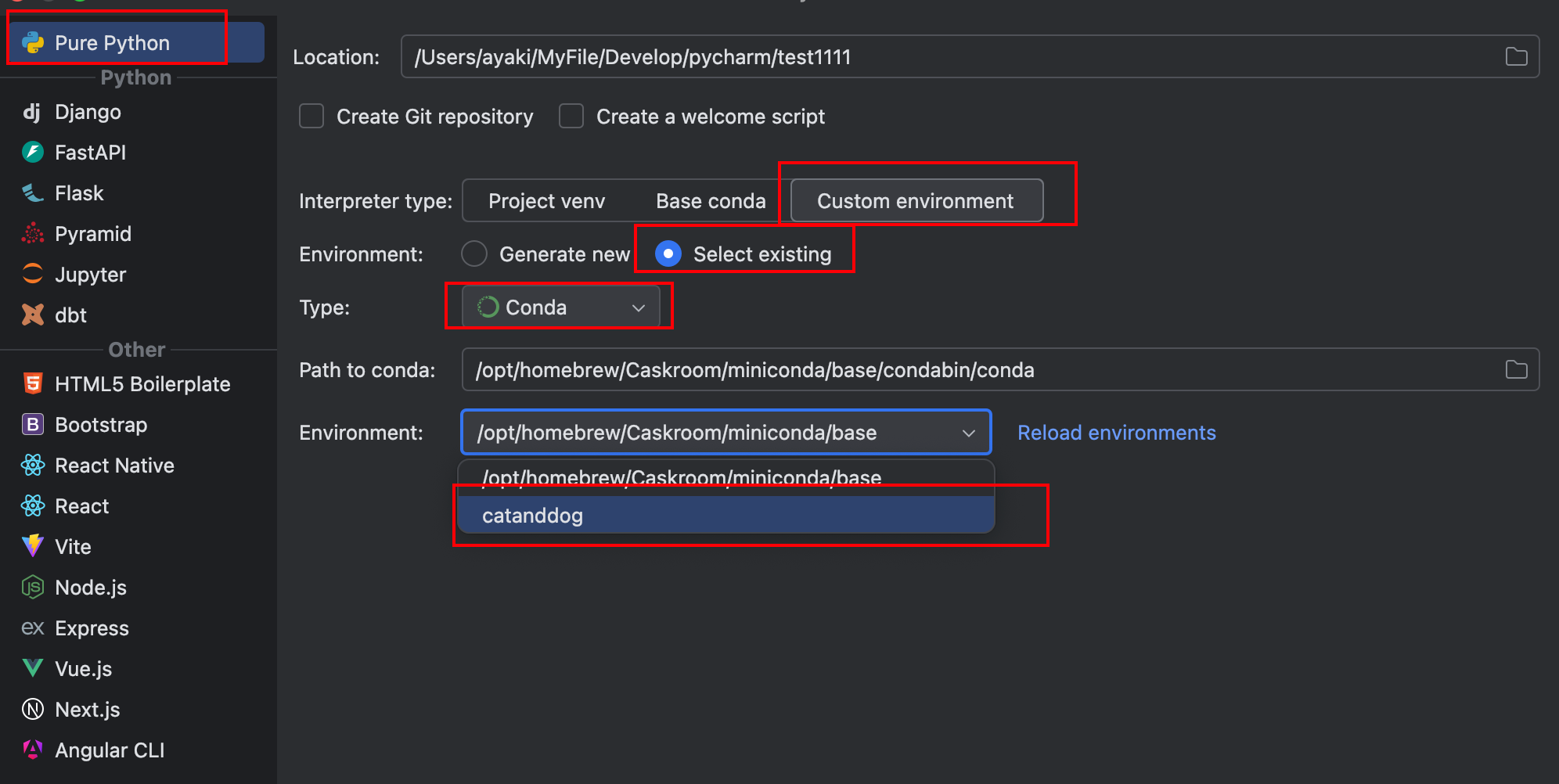
依次选择菜单路径:
File-NewProject-Pure Python
在弹出的窗口选择:
- custom environment
- Select existing
- Type:conda
- 选择刚刚新建的
catanddog虚拟环境
如图:
下载分类需要用到的依赖
主要用到:keras3.9.2和tensorflow2.19.0
pip install keras
数据准备
从Kaggle上下载常用的猫狗分类数据集,下载下来后,有训练数据(共25000张,猫狗各一半,带标签,命名示例:dog.0.jpg)和测试数据(共12500张,不带标签,命名示例:1.jgp)。
将训练数据分为两份,前20000张用于训练数据,后5000张带标签的数据用于预测模型整体准确度。12500张测试数据可以用于单张图片的模型预测,以及将猫狗分类后放入对应的目录中,方便查看。
如图组织数据:
- test为12500张不带标签的测试数据;
- test2为5000张带标签的测试数据;
- train为20000张训练数据
数据目录结构
注意:必须把训练数据、test2图片放在新建好的cats和dogs目录下,模型才能自动推断标签

挪动图片可以采用下列代码
import os, shutil
# 将train_dir_tag_cat后2500张猫图像移动到test2_dir_tag_cat
cats = ['cat.{}.jpg'.format(i) for i in range(1000)]
for cat in cats:src = os.path.join(train_dir_tag_cat, cat)dst = os.path.join(test2_dir_tag_cat, cat)shutil.move(src, dst)
config
config.py:用于存储一些关键参数和路径信息等。
训练的batch为:32
训练15个EPOCH
"""
@Author :Ayaki Shi
@Date :2025/4/18 11:03
@Description : 配置信息
"""
import os, shutildata_dir = './data'# 训练集、测试集所在路径
test_dir = os.path.join(data_dir, 'test')
test2_dir = os.path.join(data_dir, 'test2')
train_dir = os.path.join(data_dir, 'train')# 划分标签后的数据路径
train_dir_tag_cat = os.path.join(train_dir, 'cats')
test_dir_tag_cat = os.path.join(test_dir, 'cats')
test2_dir_tag_cat = os.path.join(test2_dir, 'cats')train_dir_tag_dog = os.path.join(train_dir, 'dogs')
test_dir_tag_dog = os.path.join(test_dir, 'dogs')
test2_dir_tag_dog = os.path.join(test2_dir, 'dogs')# 训练参数
IMG_SIZE = (256, 256)
BATCH_SIZE = 32
EPOCHS = 15# 模型路径
MODEL_PATH = './model/CatAndDogClassifier.keras'
准备训练、测试数据集
dataset.py
训练数据经过数据增强后返回,用于测试模型整体准确度的test2无需数据增强直接返回。
注意: 这个方法ImageDataGenerator已经不推荐使用了,因此使用image_dataset_from_directory这个方法,可以根据目录自动推断标签,只是数据增强稍微复杂了点
"""
@Author :Ayaki Shi
@Date :2025/4/18 11:02
@Description : 返回dataset
"""from keras.api.utils import image_dataset_from_directory
from config import train_dir,test2_dir, BATCH_SIZE,IMG_SIZE
from keras import layers, models
import tensorflow as tf# 数据增强
def create_augmentation_model():return models.Sequential([layers.RandomFlip("horizontal", seed=42),layers.RandomRotation(0.2, fill_mode='nearest', seed=42),layers.RandomZoom(0.2, fill_mode='nearest', seed=42),layers.RandomContrast(0.3, seed=42),layers.RandomTranslation(0.1, 0.1, fill_mode='nearest', seed=42),], name="data_augmentation")def create_train_dataset():train_dataset = image_dataset_from_directory(train_dir,label_mode = 'binary',batch_size = BATCH_SIZE,image_size = IMG_SIZE,shuffle=True, # 必须启用 shuffleseed=42)# 创建预处理模型augmentation_model = create_augmentation_model()# 定义预处理函数def preprocess_train(image, label):image = augmentation_model(image, training=True) # 训练模式激活增强return image, labeltrain_dataset = train_dataset.map(preprocess_train,num_parallel_calls= tf.data.AUTOTUNE)print('--------------返回增强后的训练数据集--------------')return train_dataset.prefetch(buffer_size=tf.data.AUTOTUNE)def create_test2_dataset():test2_dataset = image_dataset_from_directory(test2_dir,label_mode = 'binary',batch_size = BATCH_SIZE,image_size = IMG_SIZE,shuffle=False)print('--------------返回测试数据集[带标签]--------------')return test2_dataset构建模型
model.py 模型结构:
- 输入层:指定输入数据形状
- 数据归一化
- 四层卷积层和四层池化层交替
- 展平层:将输出的多维特征图展平为一维向量
- Dropout防止过拟合
- 两个全连接层,用于特征提取和最终分类
"""
@Author :Ayaki Shi
@Date :2025/4/18 11:02
@Description : 创建模型
"""
from keras import layers, models, optimizersfrom config import IMG_SIZEdef create_model():model = models.Sequential([# 输入层:指定输入数据形状layers.Input(shape=(*IMG_SIZE, 3)),layers.Rescaling(1./255), # 归一化到 [0,1]# 四层卷积层和四层池化层layers.Conv2D(32, (3, 3), activation='relu'),layers.MaxPooling2D(2, 2),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D(2, 2),layers.Conv2D(128, (3, 3), activation='relu'),layers.MaxPooling2D(2, 2),layers.Conv2D(128, (3, 3), activation='relu'),layers.MaxPooling2D(2, 2),# 展平层:将输出的多维特征图展平为一维向量layers.Flatten(),# 防止过拟合layers.Dropout(0.5),# 两个全连接层,用于特征提取和最终分类layers.Dense(512, activation='relu'),layers.Dense(1, activation='sigmoid')])# 编译模型model.compile(loss='binary_crossentropy', # 损失函数optimizer= optimizers.Adam(learning_rate=1e-4), # 优化器metrics=['accuracy']) # 评估标准:准确率print('--------------构建模型成功--------------')return model
训练模型
train.py
获取数据集-创建模型-训练模型-保存模型-绘制损失和准确度曲线
"""
@Author :Ayaki Shi
@Date :2025/4/18 16:08
@Description : 训练模型
"""from dataset import create_train_dataset
from model import create_model
from config import EPOCHS, BATCH_SIZE, MODEL_PATH
import matplotlib.pyplot as pltdef train_model():# 获取datasettrain_dataset = create_train_dataset()# 生成模型model = create_model()# 训练模型print('--------------开始训练模型--------------')history = model.fit(train_dataset,epochs = EPOCHS,batch_size = BATCH_SIZE)# 保存模型print('--------------开始保存模型--------------')model.save(MODEL_PATH)print('--------------开始绘制损失和准确性曲线--------------')# 绘制训练损失曲线plt.figure(figsize=(10, 4))plt.plot(history.history['loss'], label='Training Loss', color='blue', marker='o')plt.title('Training Loss Over Epochs')plt.xlabel('Epochs')plt.ylabel('Loss')plt.legend()plt.grid(True)plt.show()# 绘制训练准确率曲线plt.figure(figsize=(10, 4))plt.plot(history.history['accuracy'], label='Training Accuracy', color='green', marker='s')plt.title('Training Accuracy Over Epochs')plt.xlabel('Epochs')plt.ylabel('Accuracy')plt.legend()plt.grid(True)plt.show()if __name__ == '__main__':train_model()
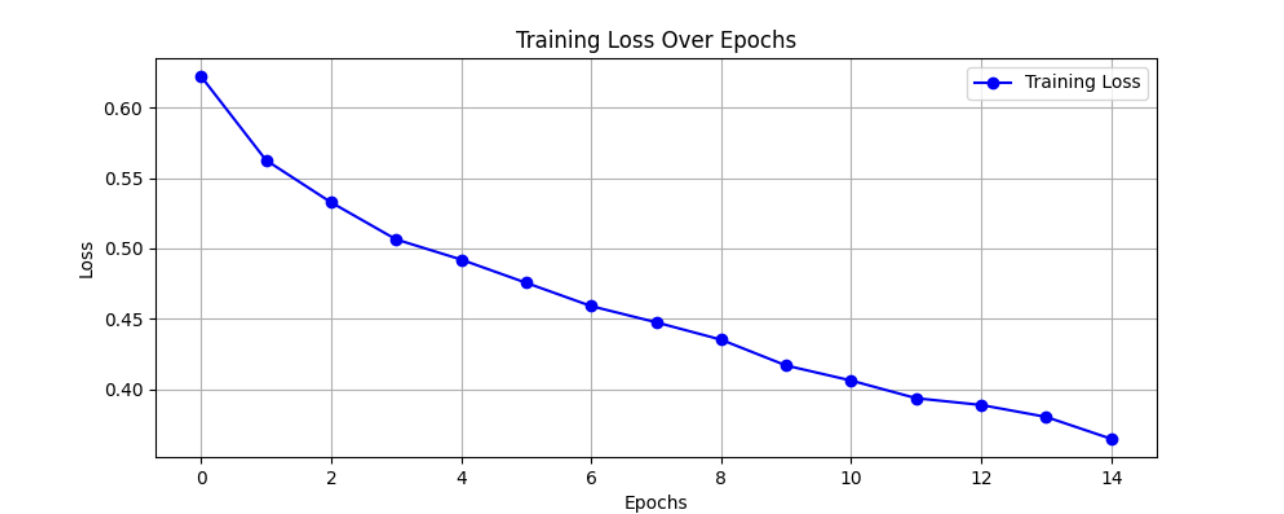
训练过程
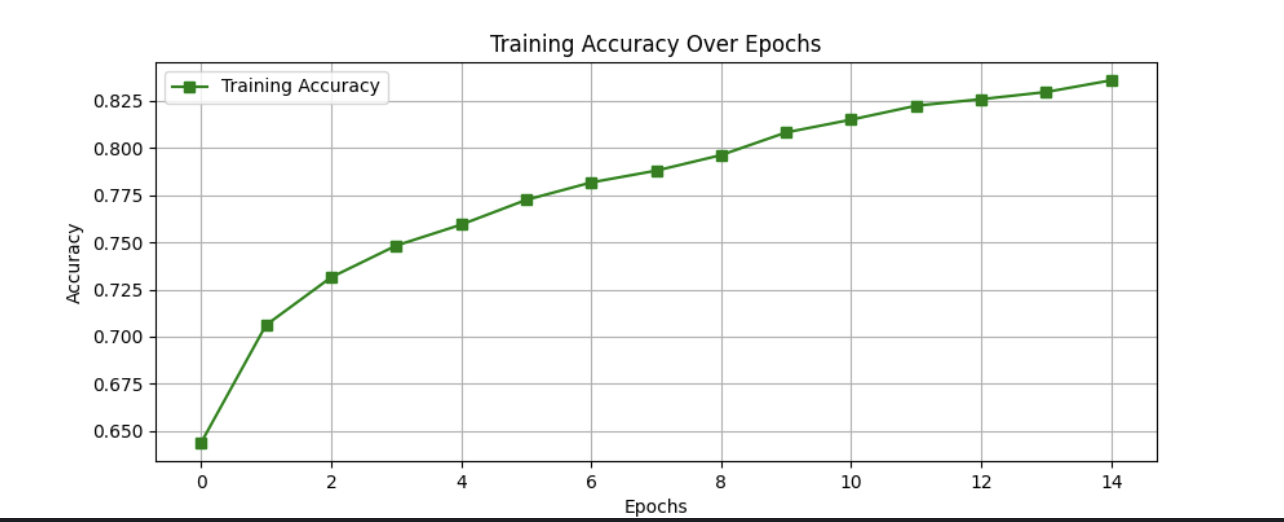
损失和准确度曲线
测试模型
test.py
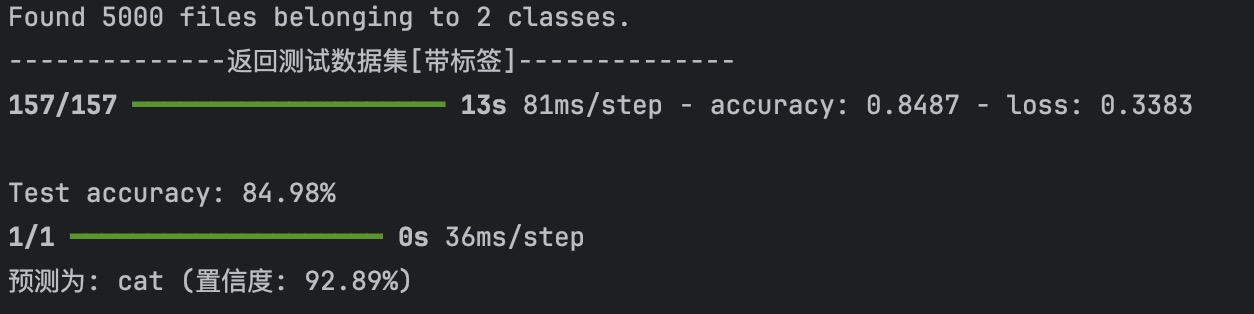
使用带标签的测试图片评估整体准确率
代码见后面,可以看到整体准确度为85%左右
定义模型类
代码见后面
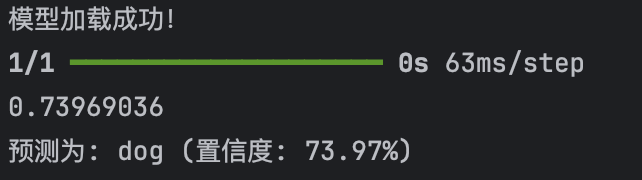
预测单张图片
代码见后面,预测为狗的概率是73%。
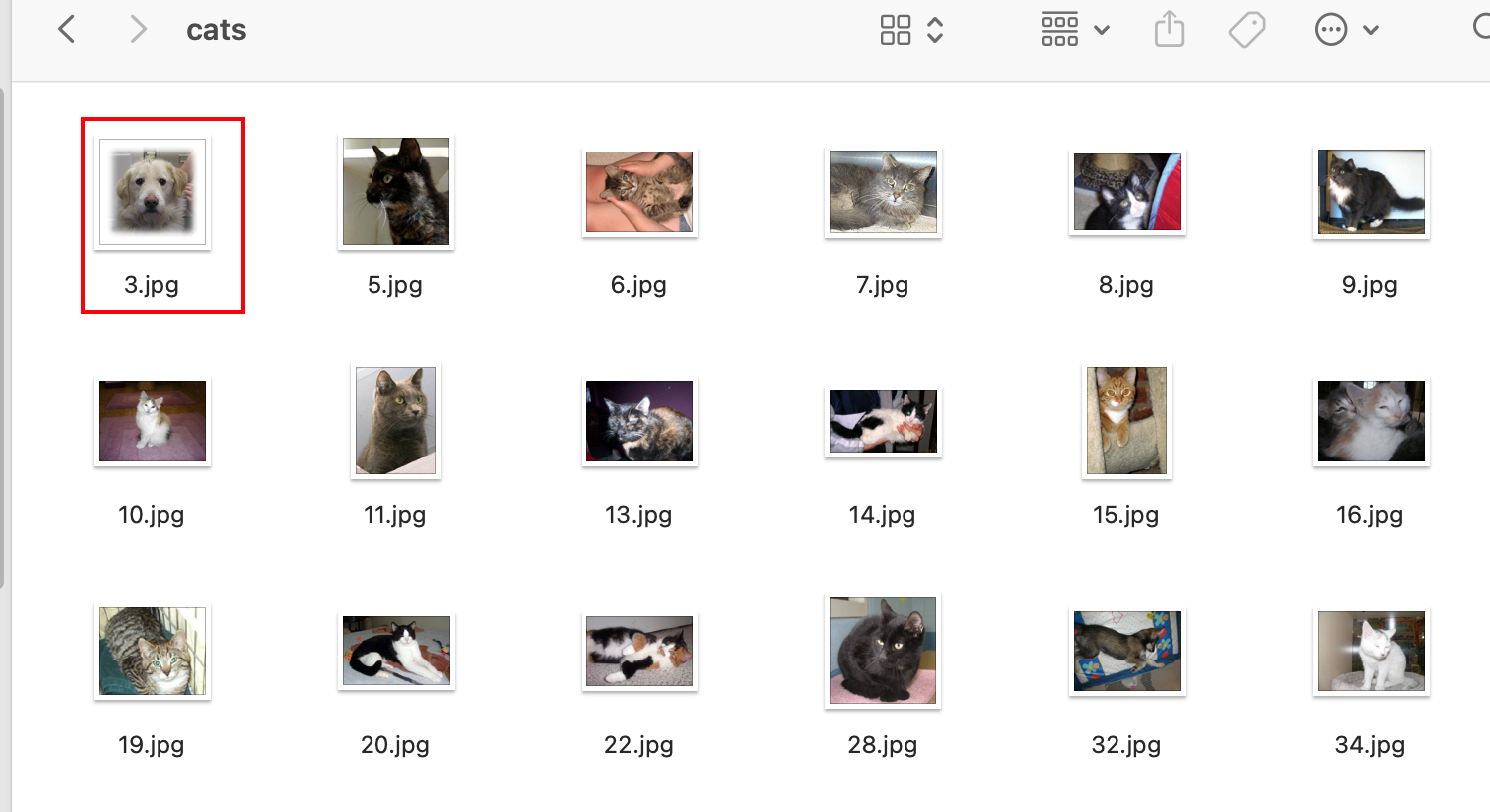
将不带标签的测试图片分类并存到对应目录中
代码见后面,可以看到大部分测试图片都被放到了正确的目录里,但是也有少数错的
源码
from keras import models
import numpy as np
import os, shutil
from keras_preprocessing import image
from config import MODEL_PATH,IMG_SIZE,test_dir,test_dir_tag_cat,test_dir_tag_dogDOG_TAG_STR = 'dog'
CAT_TAG_STR = 'cat'
NUM_IMAGES = 12500 # 测试图片数class CatAndDogClassifier:def __init__(self):self.model = models.load_model(MODEL_PATH)print("模型加载成功!")def predict_single_image(self, img_path):img = image.load_img(img_path, target_size=IMG_SIZE)img_array = image.img_to_array(img)# 错误代码:双重归一化# img_array = np.expand_dims(img_array, axis=0) / 255.0img_array = np.expand_dims(img_array, axis=0)prediction = self.model.predict(img_array)[0][0]print(prediction)return DOG_TAG_STR if prediction > 0.5 else CAT_TAG_STR, predictiondef classify_all_images(self):# 遍历所有图片# for i in range(1, NUM_IMAGES + 1):filename = ''for i in range(1, NUM_IMAGES + 1):try:#(文件名为1.jpg到12500.jpg)filename = f"{i}.jpg"src_path = os.path.join(test_dir, filename)# 跳过不存在的文件if not os.path.exists(src_path):print(f"Warning: {filename} 不存在,已跳过")continue# 进行预测label, confidence = self.predict_single_image(src_path)# 确定目标目录dest_dir = test_dir_tag_dog if label == DOG_TAG_STR else test_dir_tag_catdest_path = os.path.join(dest_dir, filename)# 移动文件shutil.move(src_path, dest_path)if i%500 == 0: # 打印12500行太多了,每500行打印一次print(f"[{i}/12500] {filename} -> {dest_dir} (置信度: {confidence:.2%})")except Exception as e:print(f"处理 {filename} 时发生错误: {str(e)}")continuedef evaluate_model():from dataset import create_test2_datasettest2_dataset = create_test2_dataset()model = models.load_model(MODEL_PATH)loss, acc = model.evaluate(test2_dataset)print(f'\nTest accuracy: {acc:.2%}')if __name__ == '__main__':# 初始化分类器classifier = CatAndDogClassifier()# # 评估整体准确率# evaluate_model()# # 单张图片预测# img_path = os.path.join('./data/train/dogs/dog.100.jpg')# label, prob = classifier.predict_single_image(img_path)# print(f'预测为: {label} (置信度: {prob if label == DOG_TAG_STR else 1 - prob:.2%})')# 将不带标签的测试图片分类放入不同的文件夹classifier.classify_all_images()
错误记录
双重归一化问题
在预测单张图片过程中,出现了不管什么图片,预测度总是特别低,只有7%左右

首先预测结果不对第一时间考虑到是不是模型欠拟合或者过拟合的问题。
但是基于以下两个原因:
- 首先训练过程中记录的准确度和测试整体准确率都是85%,说明模型大概率是没有问题的
- 其次这个置信度已经低的离谱了
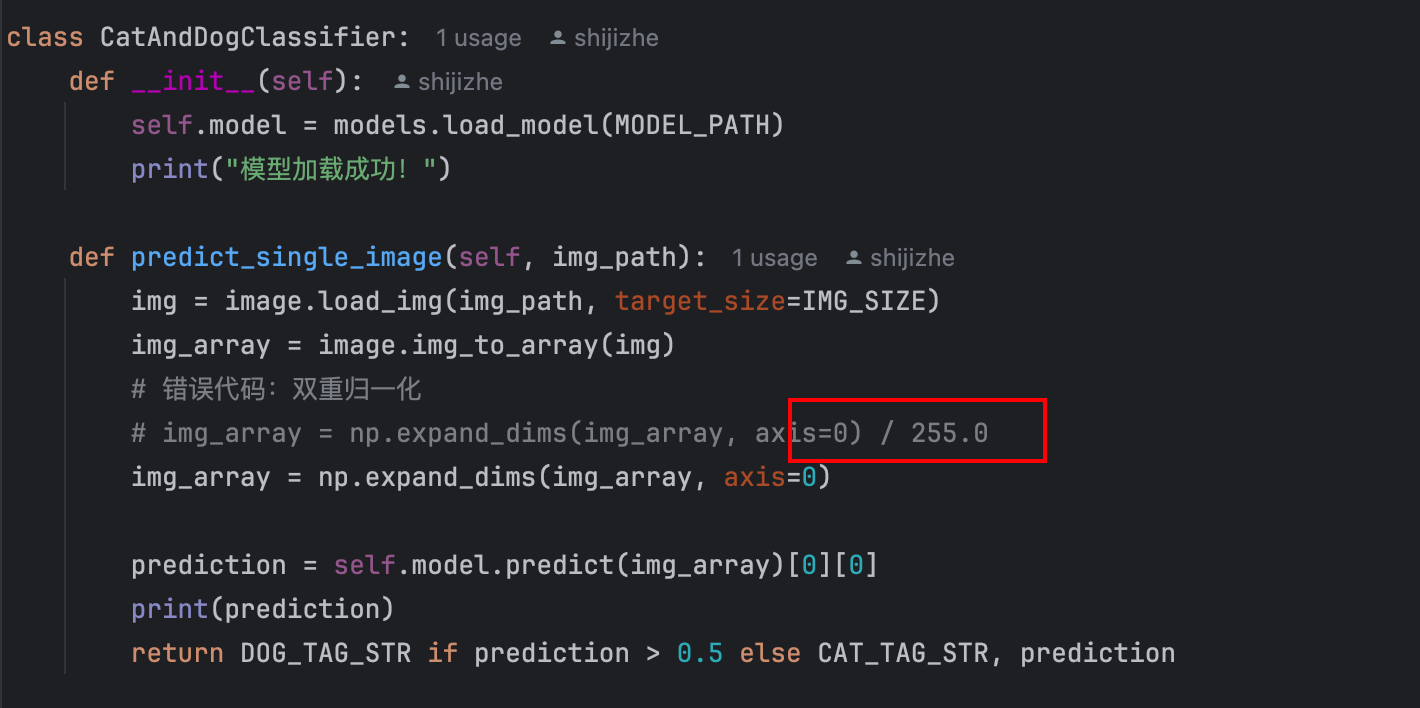
所以考虑是在测试单张图片对图片处理出现了问题,经过排查,发现问题出在了,我在对单张图片进行了归一化,然后模型中又进行了一次归一化,导致预测置信度极低。
test.py


框架深度解析)
——循环神经网络详解)
)


:摄入 MongoDB 数据)

等级考试试卷-理论综合)









