📚 博主的专栏
🐧 Linux | 🖥️ C++ | 📊 数据结构 | 💡C++ 算法 | 🌐 C 语言
上篇文章: 【Linux】线程:从原理到实战,全面掌握多线程编程!-CSDN博客
下篇文章: 线程同步、条件变量、生产者消费者模型
目录
线程ID
线程ID是是虚拟地址
库内部承担对线程的管理
库如何管理线程的:先描述再组织。
Linux线程 = pthread库中的线程的属性集 +内核LWP(比率1:1)
clone创建的执行流默认是和主进程共享地址空间。
__thread 让每个线程各自私一份的同一个名称的变量
简单封装线程
准备三个文件:
实现线程控制的几个方法
Start()
Stop()与Join()
简单的线程封装成品:
创建一批线程:对一批线程进行管理
线程互斥
抢票程序:
可重入VS线程安全
常见锁概念
死锁
死锁四个必要条件
1. 什么是互斥锁?
2. 互斥锁的核心接口(C语言,pthread库)
1. 初始化互斥锁
(1) 静态初始化
(2) 动态初始化
2. 加锁与解锁
(1) 阻塞加锁
(2) 非阻塞加锁
(3) 解锁
3. 销毁互斥锁
3.所谓的对临界资源进行保护,本质是对临界区代码进行保护
注意:
修改线程封装:
从原理角度理解这个锁:
从实现角度理解锁:
加锁(lock)逻辑
解锁(unlock)逻辑
线程ID
线程ID是是虚拟地址
示例代码:
#include <iostream> #include <string> #include <unistd.h> #include <pthread.h>void *threadrun(void *args) {std::string name = static_cast<const char *>(args); // 使用static_cast强转类型,得到线程的名字while (true){ // 任何一个线程可以通过pthread_self获取自己的线程idstd::cout << name << " " << "is running, tid: " << pthread_self() << std::endl;sleep(1);} }int main() {pthread_t tid;// 1.创建一个线程,1.取地址线程id 2.线程属性设为nullptr 3.线程要执行的函数 4.线程的名字(参数强转为void*)pthread_create(&tid, nullptr, threadrun, (void *)"thread-1");std::cout << "new thread tid: " << tid << std::endl;// 2.线程一旦创建就需要join它pthread_join(tid, nullptr);return 0; }给用户提供的线程的id,不是内核中的LWP(轻量级进程),而是自己(pthread库)维护的一个值。
库内部承担对线程的管理
将id值转成16进制打印出:
std::string ToHex(pthread_t tid) {char id[128];snprintf(id, sizeof(id), "0x%lx", tid);return id; }void *threadrun(void *args) {std::string name = static_cast<const char *>(args); // 使用static_cast强转类型,得到线程的名字while (true){ // 任何一个线程可以通过pthread_self获取自己的线程idstd::string id = ToHex(pthread_self());std::cout << name << " " << "is running, tid: " << id << std::endl;sleep(1);} }int main() {pthread_t tid;// 1.创建一个线程,1.取地址线程id 2.线程属性设为nullptr 3.线程要执行的函数 4.线程的名字(参数强转为void*)pthread_create(&tid, nullptr, threadrun, (void *)"thread-1");std::cout << "new thread tid: " << ToHex(tid) << std::endl;// 2.线程一旦创建就需要join它pthread_join(tid, nullptr);return 0; }
线程id实际上是一个地址。
动态库在没有被加载的时候在哪里?在磁盘中。库是什么?文件
pthread库本身是一个文件libpthread.so,而我写的文件mythread也是一个文件在磁盘当中
多线程在启动之前,也必须先是一个进程,再动态的创建线程。
而创建线程,前提是把库加载到内存,映射到我进程的地址空间。
当线程动态库已经加载到内存,库中有pthread_create()方法,线程还不能够执行这个方法。需要先将库映射到堆栈之间的共享区当中,在共享区中构建了对应的动态库的起始地址经过页表再映射到内存的整个库中,建立好了映射,未来想要访问任意函数地址就通过页表映射找到库中方法,比如创建线程,就通过页表的映射,找到了内存库中创建线程的函数地址,在库中将线程创建好。
库如何管理线程的:先描述再组织。
在虚拟地址空间中:在动态库里,创建一个线程的时候,库会创建一个对应的线程控制块tcb在内存当中,线程控制块当中有struct pthread用于描述该线程的相关结构体字段属性、以及线程栈(每一个新线程都有自己独立的栈空间)。pthread_t tid就是每个线程控制块的起始地址。因此只要有tid,就能访问到这个线程的所有属性。线程的所有属性在库里被维护(不代表在库里开空间,空间还可以在堆上开,管理字段放库里)
这里可以联想到之前讲到的知识点,在文件管理的时候,C语言的额FILE*(是C标准库申请的),打开一个文件(fopen函数)会返回FILE*,那么FILE在哪里,在C标准库里面。用地址访问文件对象。
创建一个线程过后,在没有pthread_join的时候,执行流已经关闭,线程已经退出return/pthread_exit(num),此时会将num放置struct pthread属性当中,线程底层的内核LWP直接释放,该线程的属性一直被维护在库里,直到join通过线程id也就是线程控制块的地址,拿到线程退出的信息num。这就是为什么,不join会导致类似于僵尸进程的问题,因为在库中还保留该线程的信息,没有被释放。
struct tcb内部包含数据块:struct pthread other、char stack[N]等。每一个新线程栈实际上也是和主线程的栈一样存在虚拟地址空间内部的,是用户级空间,因此可以随我们访问。
pthread_t 到底是什么类型呢?取决于实现。对于Linux目前实现的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。
Linux线程 = pthread库中的线程的属性集 +内核LWP(比率1:1)
如何保证一个新线程在执行程序时产生的临时变量存在自己的栈空间内
Linux有LWP的系统调用
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ... /* pid_t *parent_tid, void *tls, pid_t *child_tid */ );创建轻量级进程:clone(也是创建子进程fork()函数的底层实现)
让创建的lwp去执行我设置的回调函数,所形成的临时变量放置于我所指明的新线程栈空间内。
fn
子进程/线程启动函数(类似线程入口函数)
返回值为子进程的退出状态码
st ack
必须提供子进程独立的栈空间地址
示例:
char stack[STACK_SIZE] = {0};
flags(关键控制位)
标志位 作用 CLONE_VM共享虚拟内存空间(实现线程核心特性) CLONE_FS共享文件系统属性(根目录、umask等) CLONE_FILES共享文件描述符表 CLONE_SIGHAND共享信号处理函数表 CLONE_THREAD将新进程放入父进程的线程组 CLONE_SYSVSEM共享System V信号量
arg
传递给
fn函数的参数
clone创建的执行流默认是和主进程共享地址空间。
因为,主线程和新线程共享地址空间,全局变量(存在全局区)对于多线程来说是是被共享的,因此主线程和新线程都能访问到同一个全局变量。
示例:证明clone创建的默认执行流是和主进程共享地址空间的
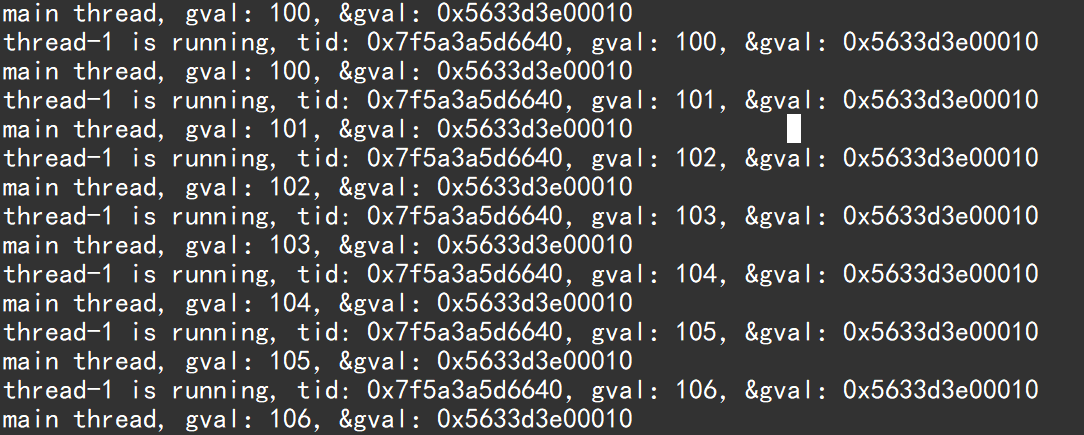
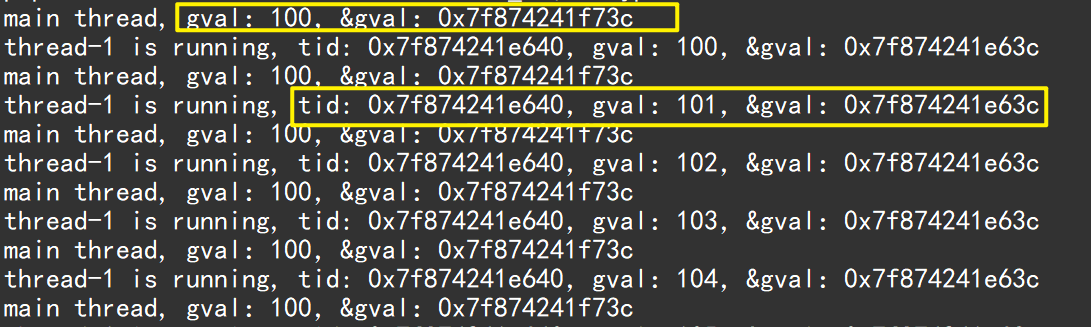
#include <iostream> #include <string> #include<stdio.h> #include <unistd.h> #include <pthread.h>int gval = 100;//全局变量 std::string ToHex(pthread_t tid) {char id[128];snprintf(id, sizeof(id), "0x%lx", tid);return id; }void *threadrun(void *args) {std::string name = static_cast<const char *>(args); // 使用static_cast强转类型,得到线程的名字while (true){ // 任何一个线程可以通过pthread_self获取自己的线程idstd::string id = ToHex(pthread_self());std::cout << name << " " << "is running, tid: " << id <<",gval:"<< gval << ",&gval:" << &gval << std::endl;sleep(1);gval++;} }int main() {pthread_t tid;// 1.创建一个线程,1.取地址线程id 2.线程属性设为nullptr 3.线程要执行的函数 4.线程的名字(参数强转为void*)pthread_create(&tid, nullptr, threadrun, (void *)"thread-1");while(true){ //主线程不对gval做修改std::cout << "main thread, gval:" << gval << ",&gval:" << &gval << std::endl;sleep(1);}std::cout << "new thread tid: " << ToHex(tid) << std::endl;// 2.线程一旦创建就需要join它pthread_join(tid, nullptr);return 0; }主线程,新线程访问到同一个全局变量
__thread 让每个线程各自私一份的同一个名称的变量
Linux适用,只支持内置类型
简单封装线程
准备三个文件:
Thread.hpp
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>namespace ThreadModle
{// 线程要执行的方法typedef void (*func_t)(const std::string &name); // 函数指针类型class Thread{public:Thread(){}~Thread(){}void Start(){}void Stop(){}void Join(){}private:std::string _name; // 线程名pthread_t _tid; // 线程所对应的idbool _isrunning; // 线程此时是否正在运行func_t _func; // 线程要执行的回调函数};
}
Main.cc
#include<iostream>
#include"Thread.hpp"int main()
{Thread<int> t;//类模版创建一个线程对象t.Start();//启动线程的方法t.Stop();//停止线程的方法t.join();//回收线程return 0;
}Makefile
testthread:Main.ccg++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:rm -f testthread实现线程控制的几个方法
Start()
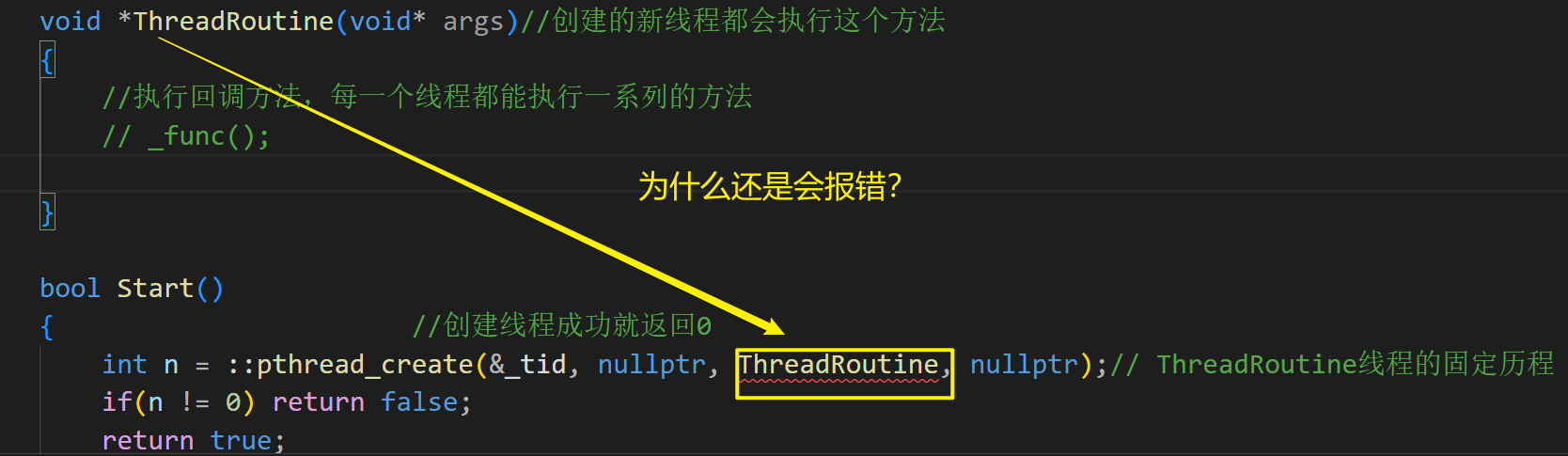
ThreadRoutine是类内的成员方法,这就意味着,这个方法默认带了当前对象的this指针(类型是Thread*),而创建线程的函数要求所传的该参数必须是一个返回值是void*,参数只有一个void*的函数指针。因此在类当中想要创建线程执行类的成员方法,是不可能的。
解决办法:加static,static定义的类成员函数是没有this指针的,这个成员函数就属于类,不属于对象了。
带来的问题:不能在ThreadRoutine再调用_func(),因为_func是私有的类内部成员属性
解决办法:在pthread_create函数传参数时,将当前对象传进ThreadRoutine,再强转args成对应的对象。再写一个成员函数Excute()用于调用回调函数,在ThreadRoutine直接用当前对象调用这个成员函数,就相当于调用回调函数,增加代码可读性,Excute()还能用来判断我的线程是否已经开始running:_isrunning = true
namespace ThreadModle
{// 线程要执行的方法typedef void (*func_t)(const std::string &name); // 函数指针类型class Thread{public:void Excute() //调用回调函数的成员方法{_isrunning = true;_func(_name);}public:Thread(){}~Thread(){}static void *ThreadRoutine(void* args)//创建的新线程都会执行这个方法{//执行回调方法,每一个线程都能执行一系列的方法Thread* self = static_cast<Thread*>(args);//获得了当前对象self->Excute();}bool Start(){ //创建线程成功就返回0int n = ::pthread_create(&_tid, nullptr, ThreadRoutine, this);// ThreadRoutine线程的固定历程if(n != 0) return false;return true;}void Stop(){}void Join(){}private:std::string _name; // 线程名pthread_t _tid; // 线程所对应的idbool _isrunning; // 线程此时是否正在运行func_t _func; // 线程要执行的回调函数};}
Stop()与Join()
首先,如果线程已经启动了才能stop,因此要先判断线程是否已经启动。如果线程已经结束了才join,因此要先判断线程是否已经结束。
void Stop(){if(_isrunning){pthread_cancel(_tid);//取消线程_isrunning = false; //设置状态为false线程停止}}void Join(){pthread_join(_tid, nullptr);}想要得到线程返回结果,可以修改回调函数的返回值为我想要的类型(返回结果),
typedef std::string (*func_t)(const std::string &name); // 函数指针类型
再在Thread类中封装一个成员属性result:
std::string result;
以及从Excute当中调用_func()的时候获取返回结果:
void Excute() //调用回调函数的成员方法{_isrunning = true;_result = _func(_name);}简单的线程封装成品:
#pragma once
#include <iostream>
#include <string>
#include <pthread.h>namespace ThreadModle
{// 线程要执行的方法typedef void (*func_t)(const std::string &name); // 函数指针类型class Thread{public:void Excute() // 调用回调函数的成员方法{std::cout << _name << ",is running" << std::endl;_isrunning = true;_func(_name);_isrunning = false;}public:Thread(const std::string &name, func_t func) : _name(name), _func(func){std::cout << "create " << name << " done" << std::endl;}~Thread(){// Stop();// Join();}static void *ThreadRoutine(void *args) // 创建的新线程都会执行这个方法{// 执行回调方法,每一个线程都能执行一系列的方法Thread *self = static_cast<Thread *>(args); // 获得了当前对象self->Excute();return nullptr;}bool Start(){ // 创建线程成功就返回0int n = ::pthread_create(&_tid, nullptr, ThreadRoutine, this); // ThreadRoutine线程的固定历程if (n != 0)return false;return true;}std::string Status(){if(_isrunning) return "running";else return "sleep";}void Stop(){if (_isrunning){pthread_cancel(_tid); // 取消线程_isrunning = false; // 设置状态为false线程停止std::cout << _name << " Stop" << std::endl;}}void Join(){pthread_join(_tid, nullptr);std::cout << _name << " Joined" << std::endl;}private:std::string _name; // 线程名pthread_t _tid; // 线程所对应的idbool _isrunning; // 线程此时是否正在运行func_t _func; // 线程要执行的回调函数// std::string _result;};}
Main.cc
void Print(const std::string &name){int cnt = 1;while (true){std::cout << name << "is running, cnt: " << cnt++ << std::endl;sleep(1);}}
运行结果:
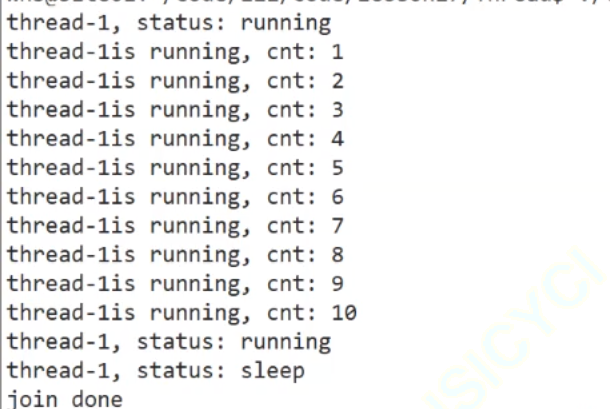
stop之后只剩一个线程:join后,都结束
通过以上代码,能够感受线程在C++11里,实际上就是对原生线程的一种封装
创建一批线程:对一批线程进行管理
管理原生线程,先描述,再组织(这里用数组下标就管理了线程)对vector的增删查改
#include<iostream> #include"Thread.hpp" #include<vector> #include<unistd.h> using namespace ThreadModle; const int gnum = 10;void Print(const std::string &name) {int cnt = 1;while (true){std::cout << name << ",is running, cnt: " << cnt++ << std::endl;sleep(1);} } int main(){// 我在管理原生线程, 先描述,在组织// 构建线程对象std::vector<Thread> threads;for (int i = 0; i < gnum; i++){std::string name = "thread-" + std::to_string(i + 1);threads.emplace_back(name, Print);sleep(1);}// 统一启动for (auto &thread : threads){thread.Start();}sleep(10);// 统一结束for (auto &thread : threads){thread.Stop();}// 等待线程等待for (auto &thread : threads){thread.Join();}return 0;}运行结果: 线程统一启动,10s后,线程集体结束,再集体被Joined
线程互斥
线程能够看到的资源--共享资源
往往我们需要对这个共享资源进行保护
进程线程间的互斥相关背景概念
临界资源:多线程执行流共享的资源就叫做临界资源
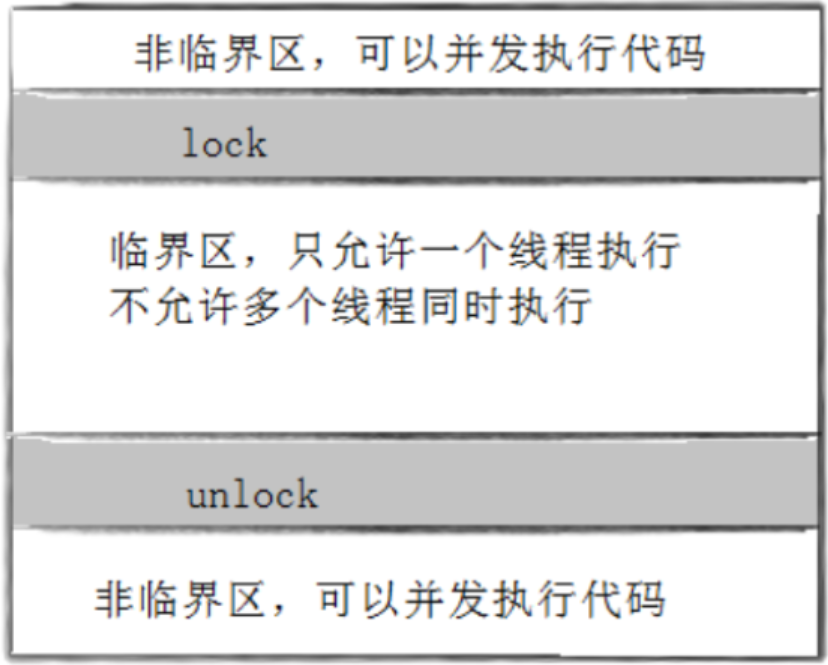
临界区:每个线程内部,访问临界资源的代码,就叫做临界区互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用
原子性:不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成
互斥量mutex
大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况,变量归属单个线程,其他线程无法获得这种变量。
但有时候,很多变量都需要在线程间共享,这样的变量称为共享变量,可以通过数据的共享,完成线程之间的交互。多个线程并发的操作共享变量,会带来一些问题。
抢票程序:
可重入VS线程安全
概念
线程安全:多个线程并发同一段代码时,不会出现不同的结果。常见对全局变量或者静态变量进行操作,并且没有锁保护的情况下,会出现该问题。
重入:同一个函数被不同的执行流调用,当前一个流程还没有执行完,就有其他的执行流再次进入,我们称之为重入。一个函数在重入的情况下,运行结果不会出现任何不同或者任何问题,则该函数被称为可重入函数,否则,是不可重入函数。
常见的线程不安全的情况
- 不保护共享变量的函数
- 函数状态随着被调用,状态发生变化的函数
- 返回指向静态变量指针的函数
- 调用线程不安全函数的函数
常见锁概念
死锁
死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
死锁四个必要条件
互斥条件:一个资源每次只能被一个执行流使用
请求与保持条件:一个执行流因请求资源而阻塞时,对已获得的资源保持不放不剥夺条件:一个执行流已获得的资源,在末使用完之前,不能强行剥夺循环等待条件:若干执行流之间形成一种头尾相接的循环等待资源的关系
避免死锁
- 破坏死锁的四个必要条件加锁顺序一致
- 避免锁未释放的场景资源一次性分配
避免死锁算法:死锁检测算法(了解)银行家算法(了解)
以下所写的抢票系统,哪个线程先抢,哪个线程后抢,是不确定的,整个线程的调度以及运行过程,完全是由调度器决定的。
#include<iostream>
#include"Thread.hpp"
#include<vector>
#include<unistd.h>
using namespace ThreadModle; int tickets = 10000;void route(const std::string &name)
{while(true){if(tickets > 0) //只有票数大于0的时候才需要抢票{// 抢票过程usleep(1000); // 1ms -> 抢票花费的时间printf("who: %s, get a ticket: %d\n", name.c_str(), tickets);tickets--;}else{break;}}
}int main()
{Thread t1("thread-1", route);Thread t2("thread-2", route);Thread t3("thread-3", route);Thread t4("thread-4", route);t1.Start();t2.Start();t3.Start();t4.Start();t1.Join();t2.Join();t3.Join();t4.Join();
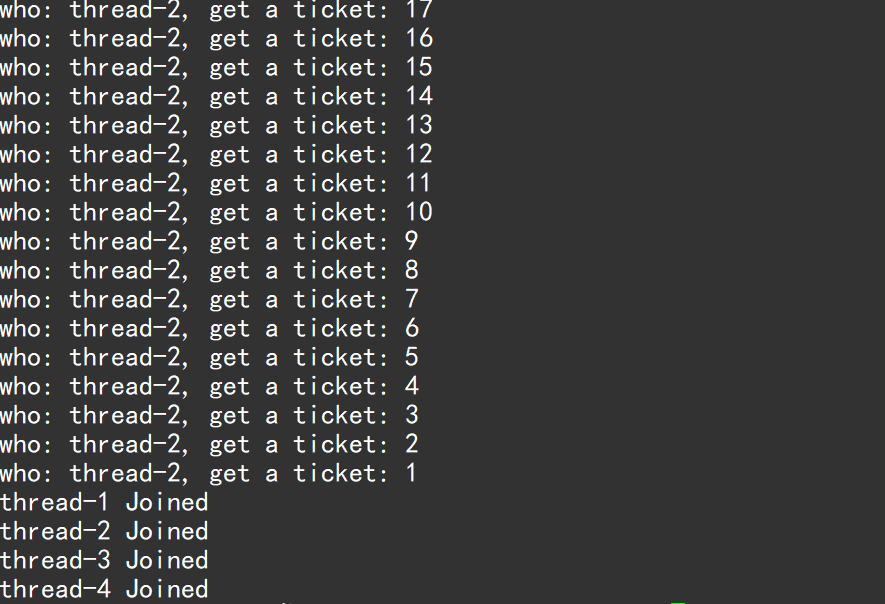
}票数是10000张,因此不能让票数减到负数,多线程在并发访问共享资源时,错误或异常的问题:不仅抢到的负票,还抢到了同一张负票。
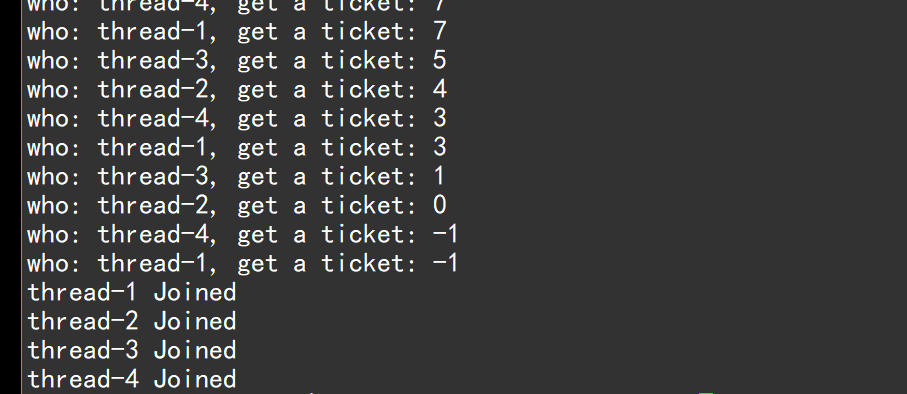
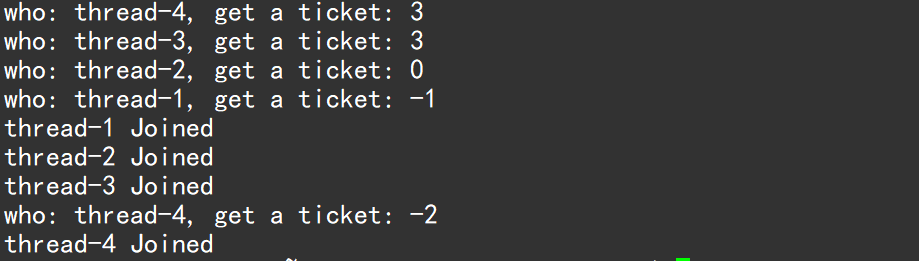
1.为什么会抢到负数
判断的过程是否是计算?是 ---> 计算的结果是真假,是一种逻辑运算(计算机的运算类型还有算数运算)计算由CPU(应用程序被CPU调度)来做,tickets有空间和内容,刚开始存放在内存当中的一个变量。当需要做这个逻辑运算的时候,第一步,把数据(tickets的)从内存移动到CPU中的寄存器(eax),还需要有一个寄存器将符号的另一端的值(0,立即数)放进另一个寄存器,CPU对两个寄存器中的值做逻辑判断,是真为1,是假为0。得到结果后,CPU再控制执行流是执行if还是else。
在执行判断的时候,会有我们设定的多个线程进入函数里进行抢票,每一个线程都要执行对应的判断逻辑。CPU一般一直在执行某个线程代码。CPU中的寄存器只有一套,而寄存器中的数据可有多套,每套数据属于线程私有,当线程备切换的时候,线程会带走自己的数据,线程回来的时候,会恢复寄存器中自己的一套数值。
假如现在是四个线程,并且只剩一张票了,线程a现在将tickets放进一个寄存器里,0也放进另一个寄存器,线程a正在被调度且已经判断tickets = 1 > 0得到值是1,正准备执行抢票(printf)的时候(还未对tickets进行 --),被切换了,此时线程a会保存自己的上下文数据,以及判断的结果res = 1,线程b被叫醒进来抢票,此时的tickets仍然是1,逻辑判断后,res = 1,此时(还未抢票和--tickets)有可能线程b也被切换。线程c、d来到,他们都执行如上操作,票数只有1张,但是却进来了四个线程,线程a此时被唤醒,抢票后票数--,b进来,再--,tickets早已被-为负数。
tickets:1.重读数据,2.--数据,3.写回数据
总结:
- if 语句判断条件为真以后,代码可以并发的切换到其他线程
- usleep 这个模拟漫长业务的过程,在这个漫长的业务过程中,可能有很多个线程会进入该代码段
- --ticket 操作本身就不是一个原子操作
要做到这三点,本质上就是需要一把锁。Linux上提供的这把锁叫互斥量。
1. 什么是互斥锁?
定义:互斥锁(Mutual Exclusion Lock)是一种同步机制,用于在多线程编程中保护共享资源,确保同一时间只有一个线程可以访问临界区(Critical Section)。
核心作用:防止多个线程同时修改共享数据,避免数据竞争(Race Condition)导致的不一致性。
2. 互斥锁的核心接口(C语言,pthread库)
在 Linux 中,互斥锁通过 pthread 库实现。以下是主要接口函数:
1. 初始化互斥锁
(1) 静态初始化
适用于全局或静态互斥锁。
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
特性:快速初始化,无需手动销毁
pthread_mutex_destroy。(2) 动态初始化
可自定义互斥锁属性(如设置递归锁)。
pthread_mutex_t mutex; pthread_mutex_init(&mutex, NULL); // 第二个参数为属性,NULL 表示默认
必须销毁:使用后需调用
pthread_mutex_destroy。操作成功都是返回1,操作失败,返回-1
2. 加锁与解锁
(1) 阻塞加锁
若锁已被占用,当前线程会阻塞,直到锁被释放。
int pthread_mutex_lock(pthread_mutex_t *mutex);
返回值:成功返回
0,失败返回错误码(如未初始化的锁返回EINVAL)。(2) 非阻塞加锁
尝试加锁,若锁被占用,立即返回错误码
EBUSY。int pthread_mutex_trylock(pthread_mutex_t *mutex);(3) 解锁
释放锁,允许其他线程获取。
int pthread_mutex_unlock(pthread_mutex_t *mutex);
3. 销毁互斥锁
释放动态初始化的锁资源。
int pthread_mutex_destroy(pthread_mutex_t *mutex);在最前面的抢票系统:
3.所谓的对临界资源进行保护,本质是对临界区代码进行保护
全局的 tickets叫做共享资源,多线程未来都会执行同route,在线程执行的代码之中,tickets临界资源会被我们加以保护,这种被保护的全局资源就叫做临界资源,在多线程所执行的代码中一定会存在访问临界资源的代码,访问临界资源的代码就叫做临界区,其他代码叫做非临界区。
我们对所有资源进行访问,本质都是通过代码进行访问,因此要保护资源本质就是想办法把访问资源的代码进行保护。
在临界区的代码只能串行执行
现在我们在刚才的抢票系统中添加锁(加锁和解锁):
注意:
1.加锁的范围和粒度(临界区包含的代码的长度)一定要尽量小。
串行周期如果长,会导致整个系统的效率降低。
因此不将锁加在循环外面(这会导致一个线程将所有的票都抢完,下一个线程才能进来,这是不合理的,不符合我们期待的多线程并发需求),解锁也不能只加在break之后,会导致其他线程不能进来。而一个线程抢完票之后应该立马让另外的线程进来抢票,因此tickets--之后也要解锁:
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;void route(const std::string &name) {while(true){pthread_mutex_lock(&gmutex);//加锁if(tickets > 0) //只有票数大于0的时候才需要抢票{// 抢票过程usleep(1000); // 1ms -> 抢票花费的时间printf("who: %s, get a ticket: %d\n", name.c_str(), tickets);tickets--;pthread_mutex_unlock(&gmutex);}else{pthread_mutex_unlock(&gmutex);break;}} }
2.任何线程,要进行抢票,都得先申请锁,原则上,不应该有例外
3.所有的线程申请锁,前提是所有的线程都能看到这把锁,所锁本身也是共享资源,因此加锁的过程,必须是原子的。
4.原子性,要么不做,要做就做完,没有中间状态
5.如果线程申请锁失败了,线程被阻塞
6.如果线程申请成功了,就会继续向后运行
7.如果线程申请锁成功了,就开始执行临界区代码了,在执行临界区代码的期间,可以被切换吗,是可以被切换的(对于CPU来说加锁解锁也不过就是像运算一样的代码),但是其他线程无法进入。假如我现在线程1正在执行,被切换走了,其他2,3,4线程能进来吗,不能进来,因为我虽然被切换了,但是我没有释放锁。一个线程在持有锁的状态下,可以放心的执行完临界区代码,几遍被切换,其他线程无法进来,在我回来时又继续执行代码。
结论:所以对于其他线程,要么我没有申请锁,要么我释放了锁,对其他线程才有意义!这就相当于,我访问临界区,对其他线程就是原子的(要么是我解锁了,要么就是我没解锁 ,我在中间发生任何事都对他们无关)。
修改线程封装:
封装一个线程数据(包括线程的名字以及线程的锁(锁传地址)),未来想要创建一个线程,一方面在创建线程的时候传递线程名,传递一个回调方法,再传递一个线程参数(线程数据也就是)。
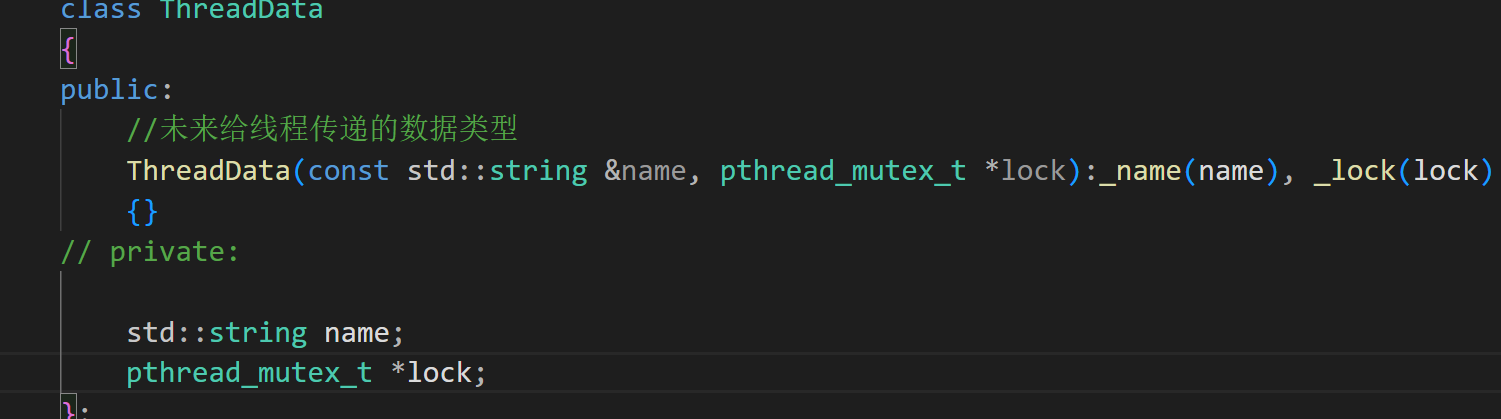
class ThreadData{public://未来给线程传递的数据类型ThreadData(const std::string &name, pthread_mutex_t *lock):_name(name), _lock(lock){}private:std::string name;pthread_mutex_t *lock; };// 线程要执行的方法typedef void (*func_t)(ThreadData *td); // 函数指针类型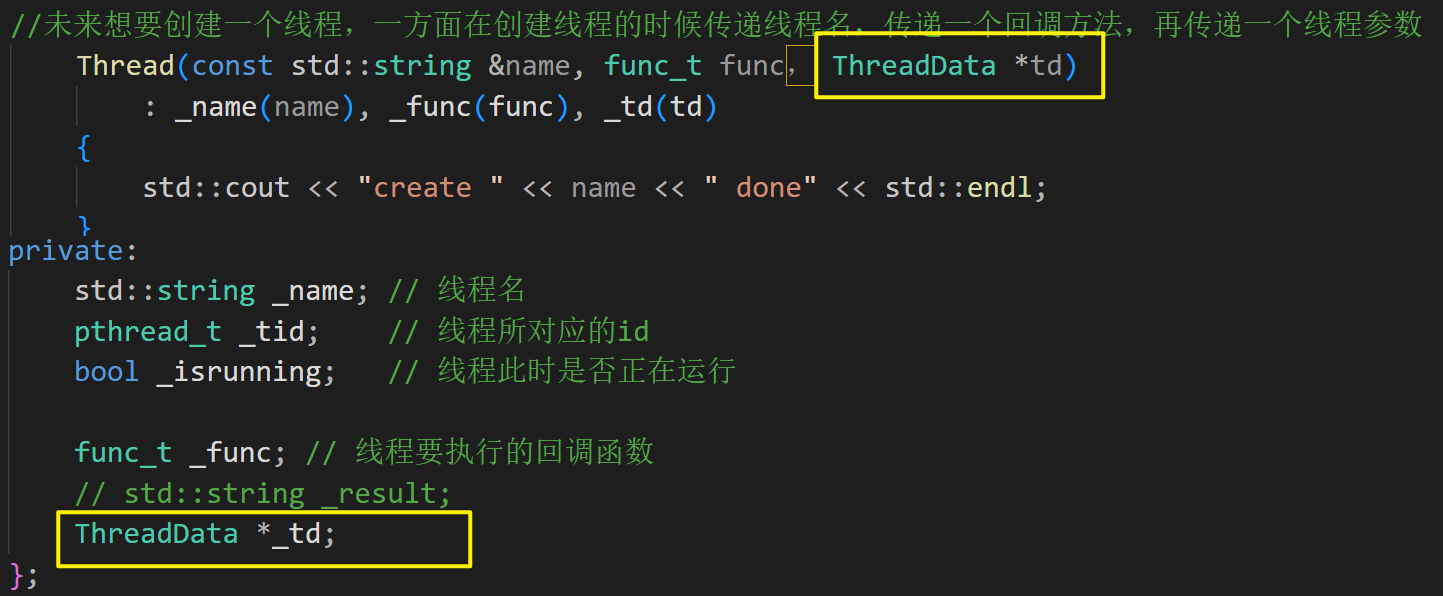
创建多线程:
// 创建threadnum个线程
static int threadnum = 4;
int main()
{//创建的是局部锁pthread_mutex_t mutex;pthread_mutex_init(&mutex, nullptr);// 创建多线程std::vector<Thread> threads;for (int i = 0; i < threadnum; i++){std::string name = "thread-" + std::to_string(i + 1);ThreadData *td = new ThreadData(name, &mutex); //将线程名字与锁地址传递给ThreadDatathreads.emplace_back(name, route, td);//创建线程,将线程名字要执行的回调函数,以及回调函数的参数(线程参数)}//统一启动for (auto &thread : threads){thread.Start();}// 等待线程等待for (auto &thread : threads){thread.Join();}pthread_mutex_destroy(&mutex);
}实际情况下最好写上private然后写Get函数:
route函数:
void route(ThreadData *td)
{//检验是否访问到的是同一把锁// std::cout << td->_name <<",mutex address: " << td->_lock << std::endl;// sleep(1);while (true){pthread_mutex_lock(td->_lock); // 加锁if (tickets > 0) // 只有票数大于0的时候才需要抢票{// 抢票过程usleep(1000); // 1ms -> 抢票花费的时间printf("who: %s, get a ticket: %d\n", td->_name.c_str(), tickets);tickets--;pthread_mutex_unlock(td->_lock);}else{pthread_mutex_unlock(td->_lock);break;}}
}对锁进行保护:
新建一个LockGuard.hpp文件:
#pragma once#include <pthread.h>class LockGuard
{
public:LockGuard(pthread_mutex_t *mutex):_mutex(mutex){pthread_mutex_lock(_mutex);}~LockGuard(){pthread_mutex_unlock(_mutex);}
private:pthread_mutex_t *_mutex;
};route代码:注意看其中的注释
void route(ThreadData *td)
{while (true)//是一个代码块{ //LockGuard是一个类型,定义出来的;临时对象,会调用他的构造函数,自动进行加锁,//while循环结束或者break结束,该对象临时变量被释放,析构函数被调用,解锁//RAII风格的锁LockGuard lockguard(td->_lock);//定义一个临时对象,对区域进行保护if (tickets > 0){// 抢票过程usleep(1000); // 1ms -> 抢票花费的时间printf("who: %s, get a ticket: %d\n", td->_name.c_str(), tickets);tickets--;}else{break;}}
}从原理角度理解这个锁:
pthread_mutex_lock(&mutex);
如何理解申请锁成功,允许你进入临界区
如何理解申请锁失败,不允许你进入临界区
允许我进入临界区的本质就是申请锁成功,pthread_mutex_lock()函数会返回
申请锁失败(锁没有就绪),pthread_mutex_lock()函数不返回,线程就是阻塞了。
pthread_mutex_lock()属于pthread库,线程也属于pthread库,所以在这个函数实现的时候,就是在做一个判断,申请锁是否成功,再设置线程的状态,然后把线程放在全局的队列当中。
一旦申请成功的线程把锁pthread_mutex_ulock(),对应的在队列当中的线程就会被唤醒,在重新pthread_mutex_lock()内部被重新唤醒,重新申请锁。
最典型的就是scanf(检测键盘是否输入数据,没输入数据就被阻塞)
从实现角度理解锁:
- 经过上面的例子,大家已经意识到单纯的 i++ 或者 ++i 都不是原子的,有可能会有数据一致性问题
- 为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用是把寄存器和内存单元的数据相交换,由于只有一条指令,保证了原子性,即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时另一个处理器的交换指令只能等待总线周期。 现在我们把lock和unlock的伪代码改一下
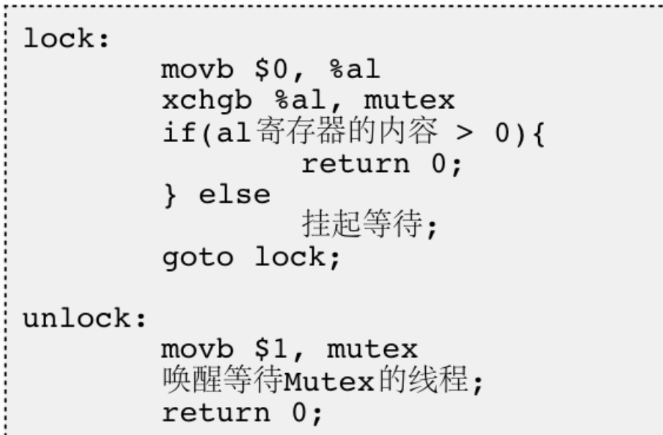
加锁(lock)逻辑
初始化:
movb $0, %al将al寄存器设为0,为后续操作做准备。原子交换:
xchgb %al, mutex通过原子操作交换al寄存器和内存中mutex的值。
若
mutex原值为1(未锁定),交换后mutex变为0(锁定),al变为1。若
mutex原值为0(已锁定),交换后mutex仍为0,al变为0。条件判断:
若
al > 0:表示成功获取锁(原mutex为1),返回0(成功)。否则:锁已被占用,线程挂起等待,之后通过
goto lock重新尝试获取锁。解锁(unlock)逻辑
释放锁:
movb $1, mutex将mutex设为1,表示释放锁。唤醒线程:
注释提示“唤醒等待Mutex的线程”,表明释放锁时会通知其他等待线程继续竞争锁。返回成功:
返回0(操作成功)
1.CPU的寄存器只有一套,被所有的线程共享,但是寄存器里面的数据,属于执行流的上下文,属于执行流私有的数据
2.CPU在执行代码的时候,一定要有对应的执行载体 线程&&进程
3.数据在内存中,被所有线程共享的。
结论:把数据从内存移动到寄存器,本质是把数据从共享,变成线程的私有
结语:
随着这篇关于题目解析的博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容,让我们在知识的道路上共同前行。
:移植SM2算法前,解决错误码的定义问题)


:Transformer 与 BERT从原理到实践)



)
)









)
