中国科学院自动化研究所智能感知与计算研究中心携手华为等领军企业,共同推出面向产业应用的视觉目标检测全流程解决方案——GAIA智能检测平台。该研究成果已获CVPR 2021会议收录(论文链接:
论文地址:https://arxiv.org/pdf/2106.11346.pdf
开源框架:https://github.com/GAIA-vision
GAIA诞生的时代背景
在深度学习技术与海量数据双重驱动的浪潮下,虽然目标检测算法在COCO、OpenImages等基准测试集上屡创佳绩,但产业落地却面临"模型适配难"的显著痛点。现有的学术模型往往针对标准数据集优化,面对工业场景复杂多变的需求时显得水土不服。企业开发者常需投入大量资源进行数据清洗、模型调优和部署适配,这种重复造轮子的模式严重阻碍了AI技术的产业化进程。
针对产业应用中的四大核心挑战:
- 数据治理困境:从原始数据采集到可用数据集构建,需经历清洗、标注、对齐等多环节,流程冗长且成本高昂
- 模型优化壁垒:超参数调优依赖专家经验,算力资源不足导致训练周期漫长
- 资源复用难题:相似需求场景下,不同团队重复开发造成资源浪费
- 定制部署鸿沟:跨硬件平台的模型适配需人工干预,难以保证性能与效率的平衡
GAIA平台创新性地构建了"一站式"解决方案,用户只需在配置文件中定义检测类别,通过简单命令行交互,系统即可自动完成数据筛选、模型训练、参数优化到部署适配的全流程(如图1所示)。该平台支持从移动端到服务器端的无缝部署,真正实现了"开箱即用"的产业级检测能力。
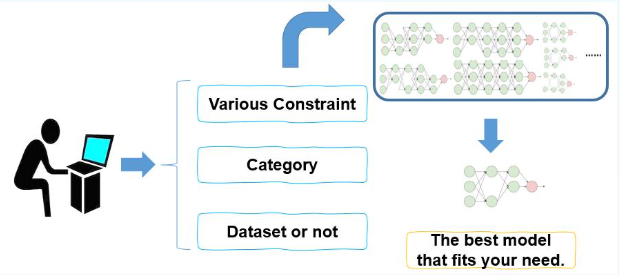
GAIA技术架构深度解析
作为新一代智能检测平台,GAIA由四大核心模块构成(如图2技术框架所示):
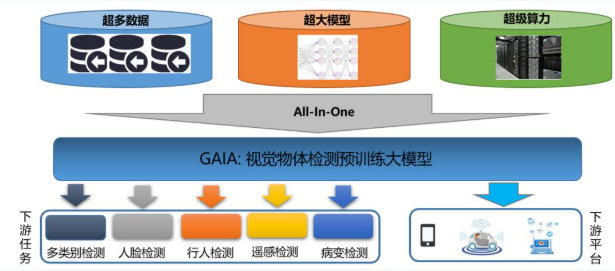
1. 多源数据集融合引擎
突破传统单数据集训练的局限,GAIA整合COCO、Object365、OpenImages等15+主流数据集,构建超大规模训练池。针对视觉数据中普遍存在的标签歧义问题(如"earth"与"ground"的语义重叠),创新性地引入语义相似度建模技术,通过阈值过滤实现跨数据集标签体系的统一,为模型泛化能力奠定坚实基础。
2. 神经架构搜索驱动的全模型训练
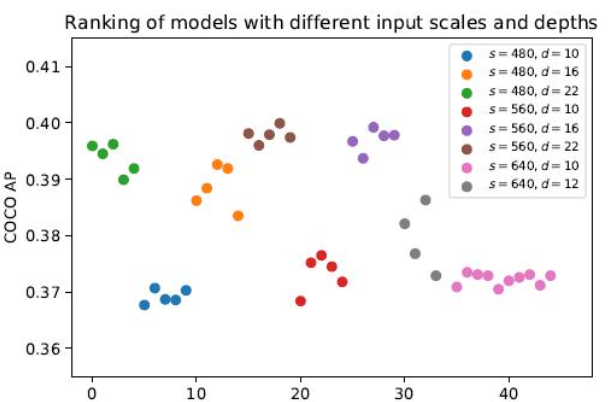
区别于BERT等通用预训练模型,GAIA将神经架构搜索(NAS)与大规模预训练有机结合。在采样空间设计上,系统分析了网络深度、输入分辨率、通道宽度三大维度对性能的影响(如图3性能分析所示),基于经典网络结构设置锚点,采用三维子网采样策略,在保持性能的前提下显著提升训练效率。生成的预训练模型库覆盖从16ms到53ms的多梯度时延需求,满足不同硬件平台的部署要求。
3. 小样本数据增强模块
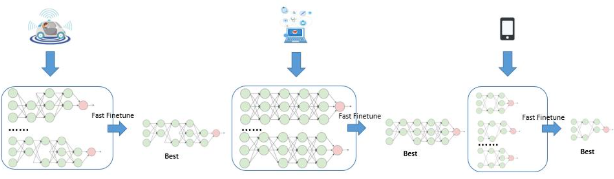
针对产业数据中常见的少样本问题,GAIA开发了智能数据选择策略。当本地标注数据不足时,系统自动在上游数据池中检索语义最近邻类别,通过特征向量相似度排序,筛选出与目标域差异最小的样本子集(如图5数据选择示意图)。实验表明,即使在仅提供10张标注样本的极端情况下,该策略仍能保证模型性能的显著提升。

4. 硬件感知模型适配层
平台预置了覆盖主流硬件的算力-精度对照表(如图6模型结构选择),用户只需输入目标设备的计算资源约束,系统即可从预训练模型库中匹配最优子网。对于高级用户,还支持自定义约束条件接口,实现更精细化的模型定制。在COCO数据集测试中,GAIA-det可输出时延16-53ms、AP指标38.2-46.2的系列模型,充分满足产业应用的多样化需求。
性能验证与产业价值
在VOC、Object365等15个公开数据集的对比实验中(如图7性能对比),GAIA模型展现出显著优势:
- 在保持学术基线性能的基础上,通过TSAS架构选择策略可获得额外2.5%的精度提升
- 在OpenImages等长尾数据集上,凭借多源数据融合技术实现8.8%的显著增益
- 在小样本场景下,智能数据选择策略带来0.8-2.3%的性能增益
未来发展方向
作为持续进化的智能检测生态,GAIA将不断拓展技术边界:
- 数据维度:定期吸收最新开源数据集,通过持续预训练保持模型先进性
- 模型库扩展:即将推出GAIA-seg(语义分割)和GAIA-ssl(自监督学习)模块
- 硬件适配:深化与芯片厂商合作,建立更细粒度的硬件特性画像
- 社区共建:诚邀学术界与产业界伙伴加入,共同构建检测模型预训练-微调的协作生态
GAIA的愿景是打造计算机视觉领域的"预训练模型集市",让开发者像选购商品一样便捷地获取定制检测方案。
以上如有理解错误,请指正。











)
)






)