由于以后我们写OJ题时会经常使用到vector,所以我们必不可缺的是熟悉它的各个接口。来为我们未来作铺垫。
首先,我们了解一下:
https://cplusplus.com/reference/vector/
vector的概念:
1. vector是表示可变大小数组的序列容器。
2. 就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是 又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
3. 本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小,为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
4. vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
5. 因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。
6. 与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效(因为它在内存中是连续的),在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list统一的迭代器和引用更好
vector的使用:
包含头文件#include<vector>
构造函数声明
1.定义(构造函数声明)
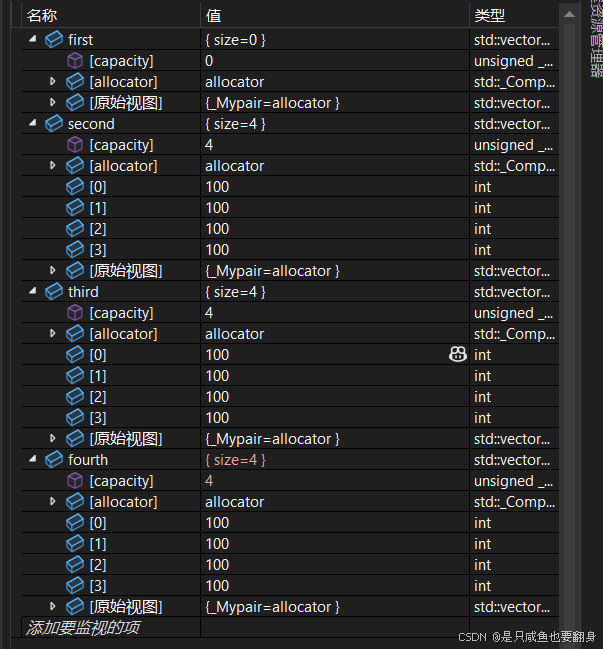
构造函数声明 接口 vector()(重点) 无参构造 vector(size_type n, const value_type& val = value_type()) 构造并初始化n个val vector (const vector& x); (重点) 拷贝构造 vector (InputIterator first, InputIterator last); 使用迭代器进行初始化构造

allocator简单理解
简单了解上面出现的allocator概念:
ps:allocator在C++ 中, alloc 通常和 内存分配有关。
std::allocator 是C++标准库中的一个 类模板,它用于将 内存分配和对象构造分离开来。例如,当你要创建一个包含自定义类型(如 class MyClass )的容器(像 std::vector )时, std::allocator 就会发挥作用。它可以 高效地获取内存块,并且能够在合适的时候释放这些内存。这有助于优化内存使用,特别是在频繁分配和释放内存的场景下。
此外,有些非标准的库或者自定义的代码中也可能会有名为 alloc 的函数或者类,用于实现自定义的内存分配策略,比如实现一个简单的 内存池 来避免频繁的系统内存分配调用所带来的开销。
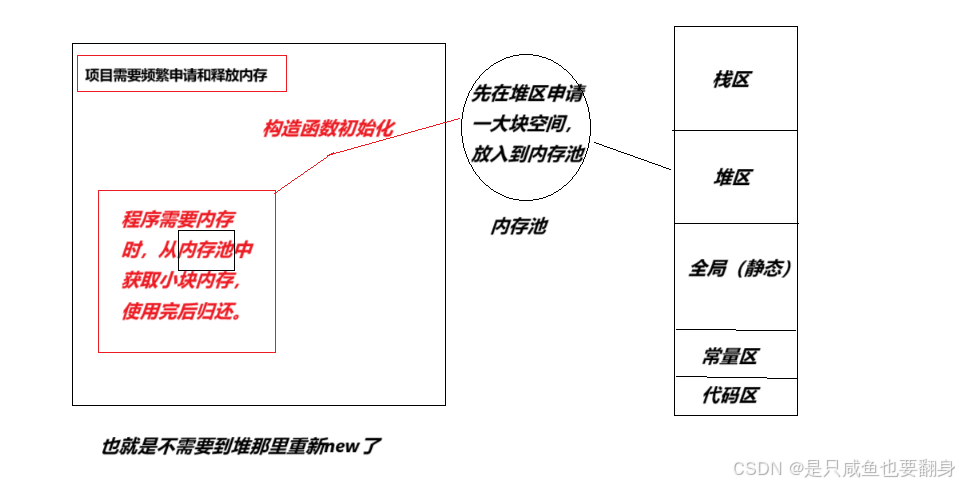
池化技术简单认识
什么是池化技术(包括:内存池,线程池,连接池)呢:这里简单了解了解
现在,以一个具体等等例子来讲解:
1.现有一座庙,庙的地点在山顶,住在庙里的和尚。由于山上没有水,只有山下有一湖水。每天起来刷牙,煮饭,和尚每天需要下山来一点一点的取水,这就显得非常麻烦的了而且耽误时间。而有一天,和尚在庙里弄了一个水池,来储存水。这时候,和尚就不需要每天上下山来用水了,减少了上下山所消耗的时间。
2.而C++中的池化技术也是类似的道理:
优势:减少内存碎片,提高内存分配效率,尤其是在频繁进行小内存分配的场景,如网络编程中服务器频繁创建和销毁小数据包。
构造函数初始化:
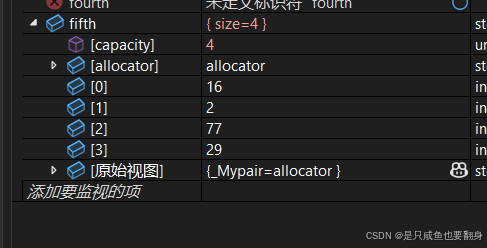
int TestVector1()
{// constructors used in the same order as described above:1.vector<int> first; // empty vector of ints2.vector<int> second(4, 100); // four ints with value 1003.vector<int> third(second.begin(), second.end()); // iterating through second4.vector<int> fourth(third); // a copy of third// 下面涉及迭代器初始化的部分,迭代器// the iterator constructor can also be used to construct from arrays:4.用数组的值进行初始化int myints[] = { 16,2,77,29 };vector<int> fifth(myints, myints + sizeof(myints) / sizeof(int));cout << "The contents of fifth are:";for (vector<int>::iterator it = fifth.begin(); it != fifth.end(); ++it)cout << ' ' << *it;cout << '\n';return 0;
}
vector迭代器的使用
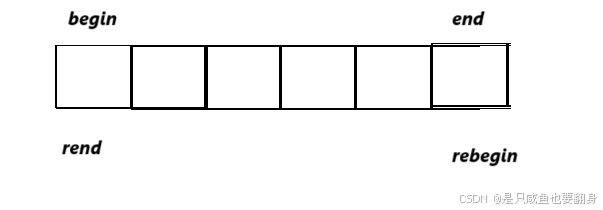
正向迭代器与反向迭代器:
| iterator的使用 | 接口说明 |
| begin + end(重点) | 获取第一个数据位置的iterator/const_iterator, 获取最后一个数据的下一个位置的iterator/const_iterator |
| rbegin + rend | 获取最后一个数据位置的reverse_iterator,获取第一个数据前一个位置的reverse_iterator (与上面的begin和end相反) |
void PrintVector(const vector<int>& v)
{// const对象使用const迭代器进行遍历打印vector<int>::const_iterator it = v.begin();while (it != v.end()){cout << *it << " ";++it;}cout << endl;
}ps:范围for同样适用:用法跟之前的string时也是一样的。
int main()
{vector<int> v={1,2,3,4,5,6};for(auto e:v){cout<<e<<" ";}return 0;
}vector的增删查改
| vector增删查改 | 接口说明 |
| push_back(重点) | 尾插 |
| pop_back (重点) | 尾删 |
| find | 查找。(注意这个是算法模块实现,不是vector的成员接口) |
| insert | 在position之前插入val |
| erase | 删除position位置的数据 |
| swap | 交换两个vector的数据空间 |
| operator[] (重点) | 像数组一样访问 |

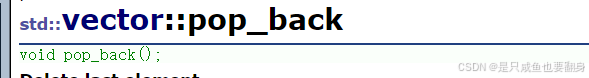





// 尾插和尾删:push_back/pop_back
void TestVector4()
{vector<int> v;v.push_back(1);v.push_back(2);v.push_back(3);v.push_back(4);auto it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;v.pop_back();v.pop_back();it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;
}// 任意位置插入:insert和erase,以及查找find
// 注意find不是vector自身提供的方法,是STL提供的算法
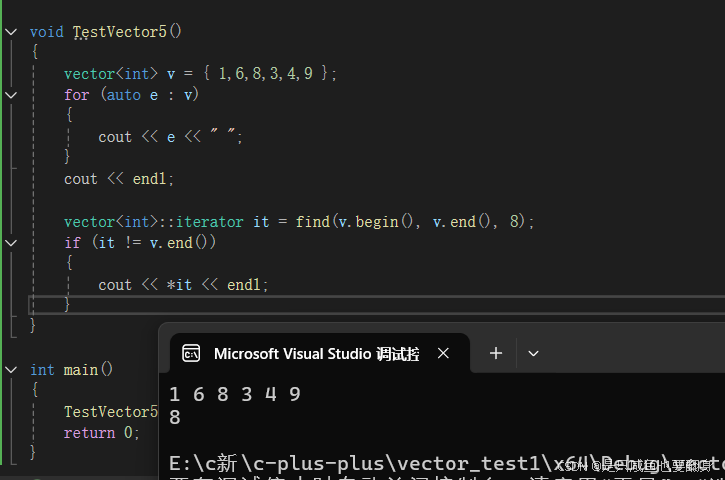
void TestVector5()
{// 使用列表方式初始化,C++11新语法vector<int> v{ 1, 2, 3, 4 };// 在指定位置前插入值为val的元素,比如:3之前插入30,如果没有则不插入// 1. 先使用find查找3所在位置// 注意:vector没有提供find方法,如果要查找只能使用STL提供的全局findauto pos = find(v.begin(), v.end(), 3);if (pos != v.end()){// 2. 在pos位置之前插入30v.insert(pos, 30);}vector<int>::iterator it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;pos = find(v.begin(), v.end(), 3);// 删除pos位置的数据v.erase(pos);it = v.begin();while (it != v.end()) {cout << *it << " ";++it;}cout << endl;
}区分:operator[]与at()
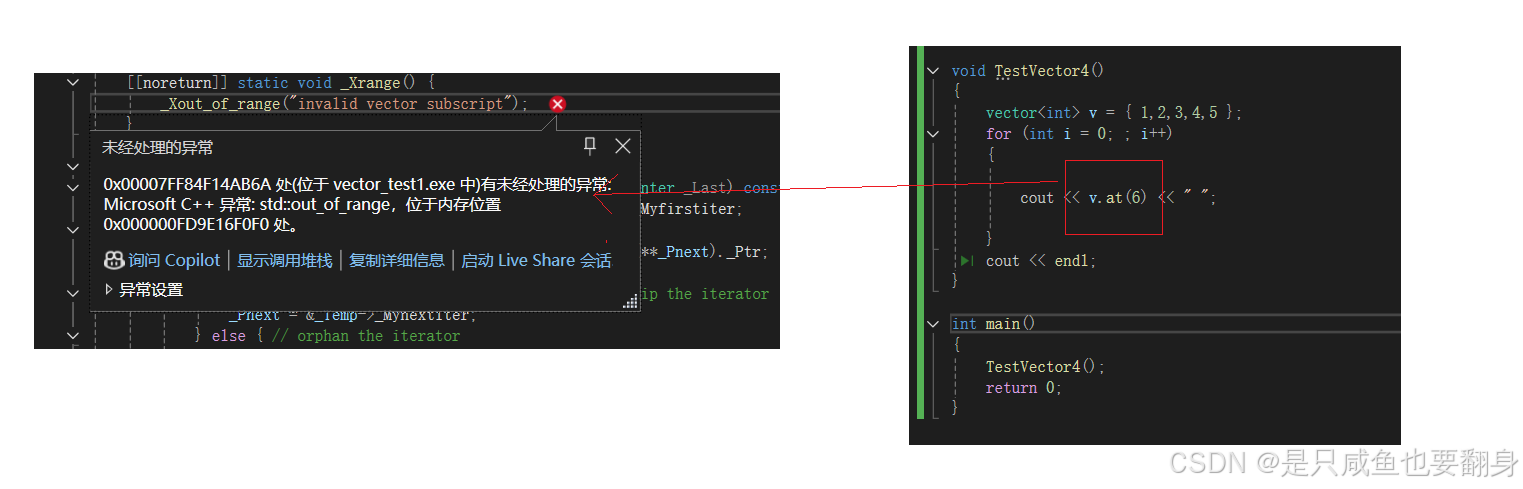
operator[]:返回对向量容器中位置n处的元素的引用。
但是,vector::at()是边界检查的,并在请求的位置超出范围后通过异常抛出(out_of_range)的信号。operator[]在vs2022中是通过断言的

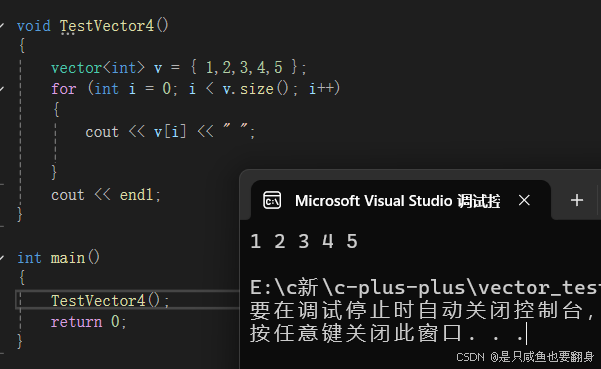
operator[]遍历vector对象:
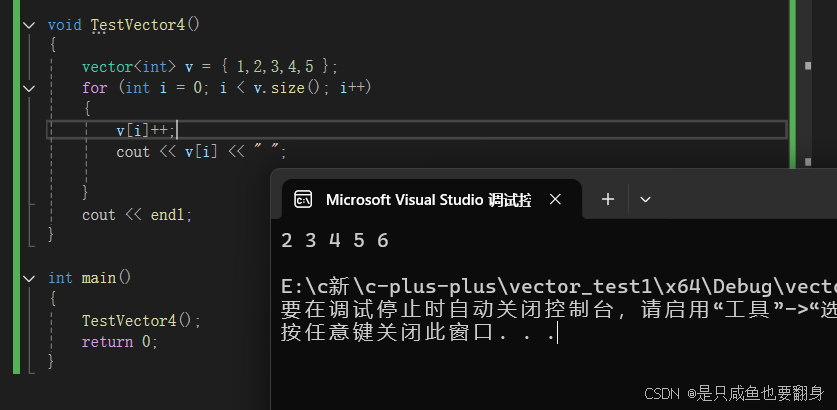
operator[]改变vector对象:
vector的容量空间:
| 容量空间 | 接口说明 |
| size | 获取数据个数 |
| capacity | 获取容量大小 |
| empty | 判断是否为空 |
| resize(重点) | 改变vector的size |
| reserve (重点) | 改变vector的capacity |
// reisze(size_t n, const T& data = T())
// 将有效元素个数设置为n个,如果时增多时,增多的元素使用data进行填充
// 注意:resize在增多元素个数时可能会扩容
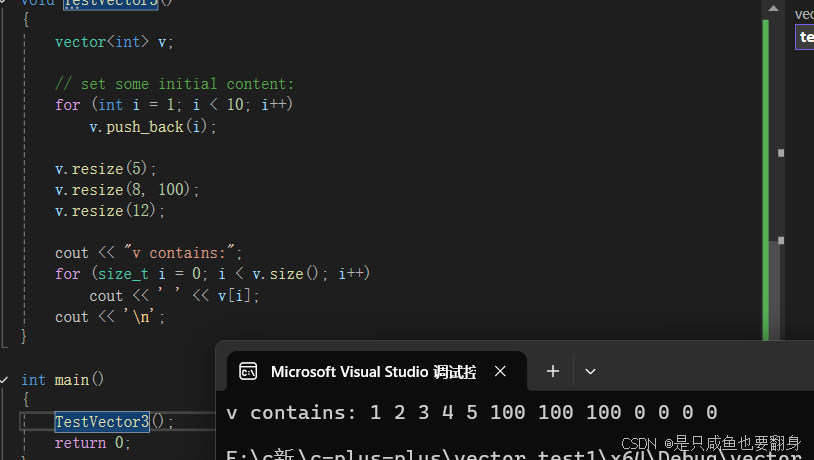
void TestVector3()
{vector<int> v;// set some initial content:for (int i = 1; i < 10; i++)v.push_back(i);v.resize(5);v.resize(8, 100);v.resize(12);cout << "v contains:";for (size_t i = 0; i < v.size(); i++)cout << ' ' << v[i];cout << '\n';
}
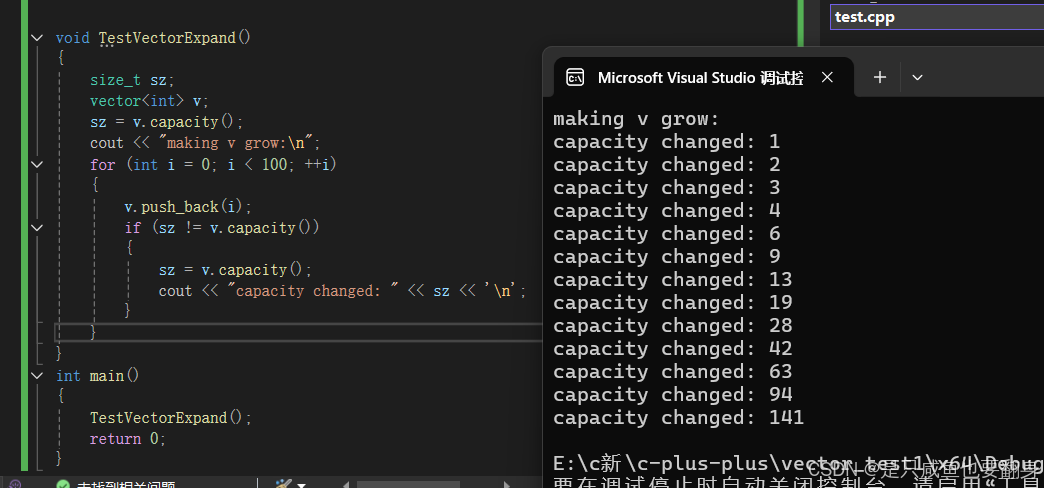
void TestVectorExpand()
{size_t sz;vector<int> v;sz = v.capacity();cout << "making v grow:\n";for (int i = 0; i < 100; ++i) {v.push_back(i);if (sz != v.capacity()) {sz = v.capacity();cout << "capacity changed: " << sz << '\n';}}
}不同平台下capacity的增长方式会不同
vs:
linux:
从上面我们可以得出:
vs下capacity是按1.5倍增长的,g++是按2倍增长的。因此,不要固化的认为,vector增容都是2倍,具体增长多少是根据具体的需求定义的。

// 往vecotr中插入元素时,如果大概已经知道要存放多少个元素
// 可以通过reserve方法提前将容量设置好,避免边插入边扩容效率低
void TestVectorExpandOP()
{vector<int> v;size_t sz = v.capacity();v.reserve(100); // 提前将容量设置好,可以避免一遍插入一遍扩容cout << "making bar grow:\n";for (int i = 0; i < 100; ++i) {v.push_back(i);if (sz != v.capacity()){sz = v.capacity();cout << "capacity changed: " << sz << '\n';}}
}易错:reserve误区:
使用reserve()开辟好看到的空间后直接使用operator[]来给vector赋值,这是错误的!!!
在 C++ 中, std::vector 的 reserve() 函数和 operator[] 的使用存在一些规则和限制,直接在 reserve() 开辟空间后就使用 operator[] 赋值是错误的,
主要原因如下:
reserve() 函数的作用是确保 vector 至少有足够的容量来容纳指定数量的元素,但它不会改变 vector 的 size (元素个数)。 size 表示 vector 中实际已有的元素数量,而 capacity 表示在不重新分配内存的情况下 vector 可以存储的最大元素数量。
operator[] 用于访问 vector 中已存在的元素,它不会自动添加新元素。当你在 reserve() 之后直接使用 operator[] 时,由于 size 没有改变, vector 中实际上还没有那么多元素,此时使用 operator[] 访问超出 size 的位置会导致未定义行为(因为该位置可能是无效的内存区域)。
#include <iostream> #include <vector> using namespace std;int main() {vector<int> v;v.reserve(5); // 预留 5 个元素的空间,但 size 还是 0v[0] = 10; // 错误,因为 v 的 size 是 0,不存在索引为 0 的元素,这是未定义行为return 0; }如果确实想通过来赋值,可以先使用 resize() 函数来调整 vector 的 size , resize() 函数不仅会改变 vector 的 size ,如果新的 size 大于原来的 size ,还会在末尾添加默认值初始化的元素,这样就可以安全地使用 operator[] 进行赋值了。
或者说使用push_back,每次插入一个
#include <iostream> #include <vector> using namespace std;int main() {vector<int> v;v.reserve(5); // 预留 5 个元素的空间v.resize(5); // 调整 size 为 5,元素初始化为 0v[0] = 10; // 现在可以安全地使用 operator[] 赋值for (int i : v) {cout << i << " ";}return 0; }综上:不能在 reserve() 开辟空间后直接使用 operator[] 赋值,因为 reserve() 没有改变 size , operator[] 访问超出 size 的位置会导致未定义行为。
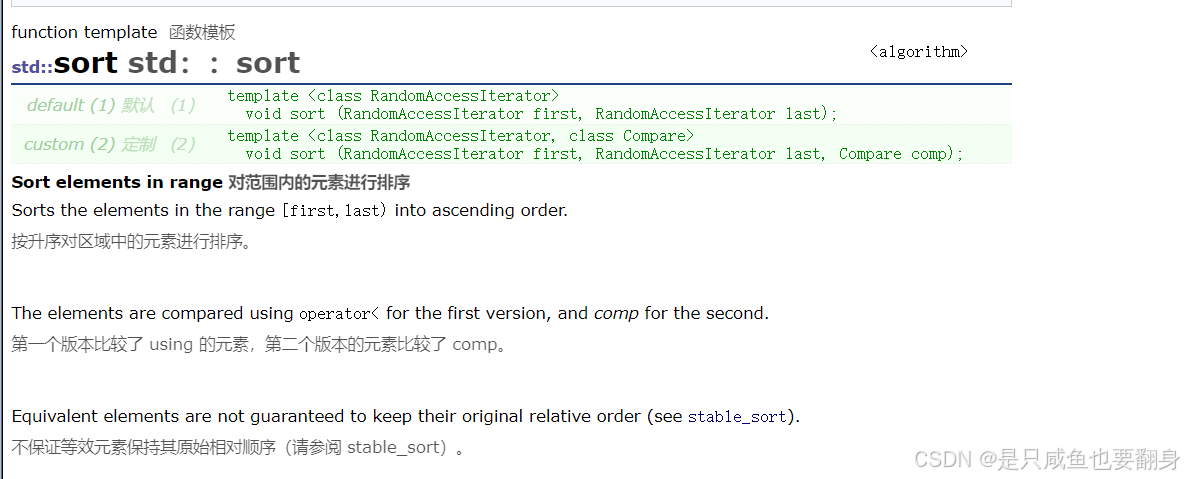
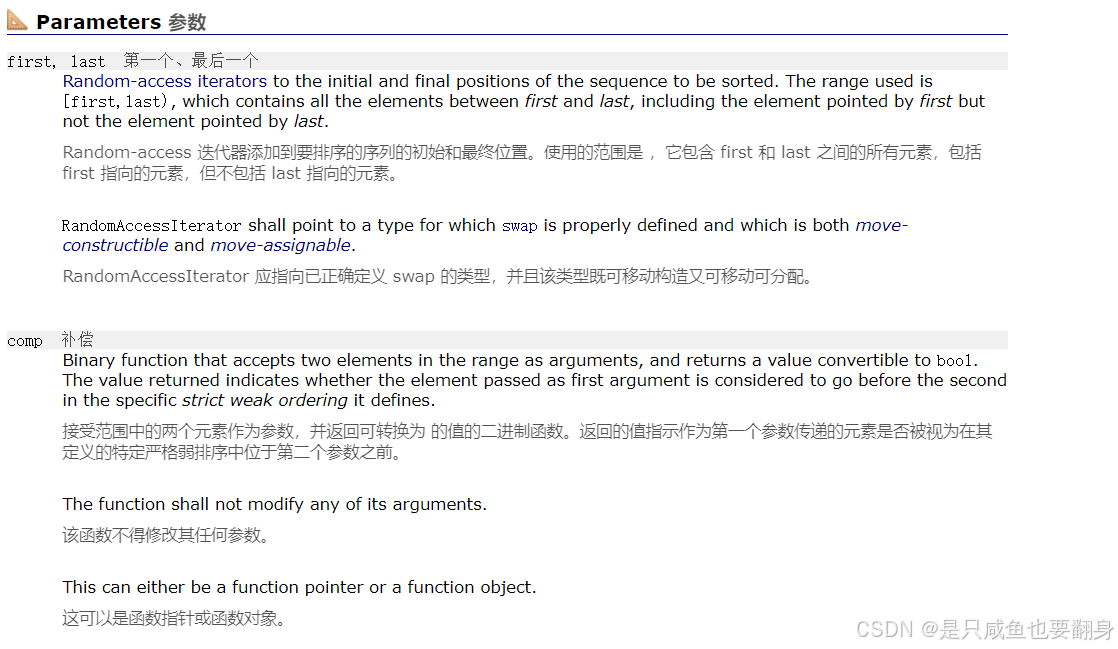
sort排序
1.sort()函数是STL中算法部分的一个接口。这个函数是在OJ题中是频繁使用到的。
2.调用sort时需要另外包含头文件#include<algorithm>
3.简单了解:
小于:
大于:
4.sort默认情况下是升序,若想要降序,则需要用greater辅助。
5.从上面我们可以看到,参数是一个类模板,所以sort可以是int,string,数组等等都可以排序的。


find()函数
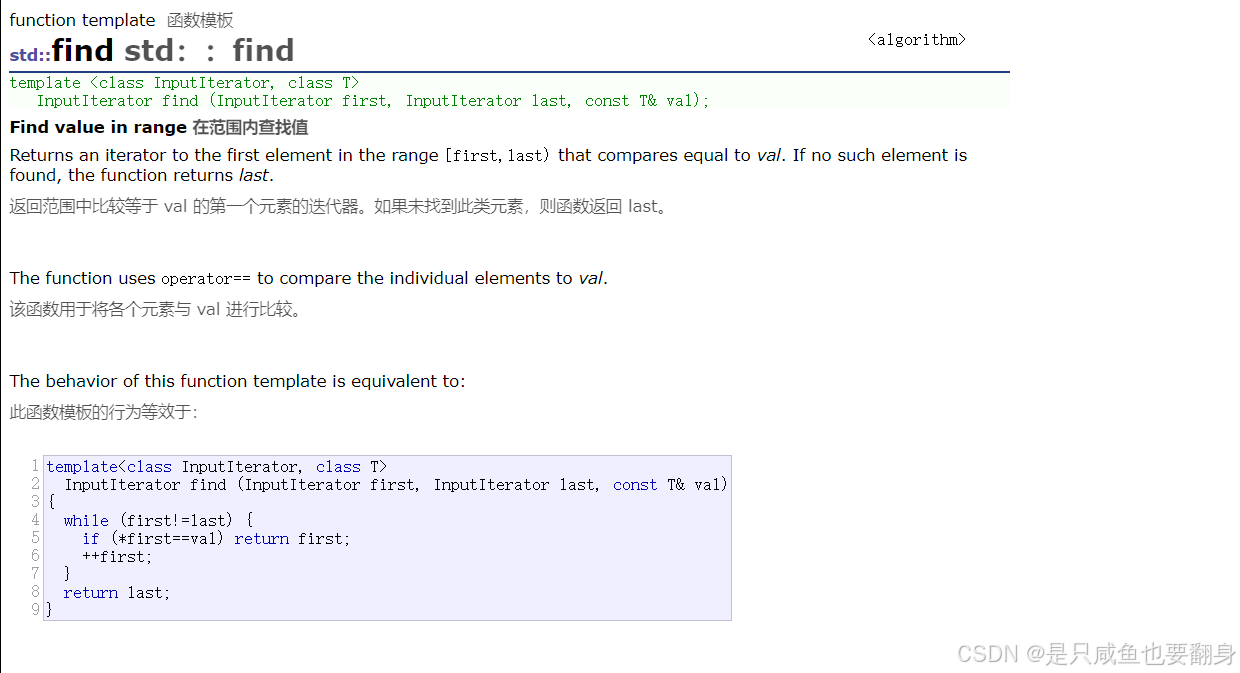
**重点**:
迭代器失效问题(分析)
概念:
迭代器失效是指在使用迭代器遍历容器(如 vector 、 list 等)的过程中,由于容器的结构发生改变,导致原来的迭代器不再有效。
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。
造成迭代器失效的原因:
引起其底层空间改变的操作
1.会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等。
我们知道预留空间时,一旦发生扩容,那么它实质上就是开一个新的空间,然后赋值过去,给原来的,这时候就会产生指向的空间被销毁的问题。
对应上面的函数,我们不妨去看看string的模拟实现那里看看它对应是如何实现函数的内容的,一旦有开一个新空间,如何在赋值拷贝给它,指向的空间发生变化,因此,就出现了迭代器失效的问题了。
string的模拟实现_string& s0 = strs[0];-CSDN博客

int main()
{
vector<int> v{1,2,3,4,5,6};
auto it = v.begin();
// 将有效元素个数增加到100个,多出的位置使用8填充,操作期间底层会扩容
// v.resize(100, 8);
// reserve的作用就是改变扩容大小但不改变有效元素个数,操作期间可能会引起底层容量改变
// v.reserve(100);
// 插入元素期间,可能会引起扩容,而导致原空间被释放
// v.insert(v.begin(), 0);
// v.push_back(8);
// 给vector重新赋值,可能会引起底层容量改变
v.assign(100, 8);从上面我们可以看到,一旦发生扩容,vector底层原理旧空间被释放掉,而在打印时,it还使用的是释放之间的旧空间,在对it迭代器操作时,实际操作的是一块已经被释放的空间,而引起代码运行时崩溃,这就是迭代器失效!!
指定位置元素的删除操作--erase
int main()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// 使用find查找3所在位置的iterator
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据,导致pos迭代器失效。
v.erase(pos);
cout << *pos << endl; // 此处会导致非法访问
return 0;
}erase删除pos位置元素后,pos位置之后的元素会往前搬移,没有导致底层空间的改变,理论上讲迭代器不应该会失效,
但是:如果pos刚好是最后一个元素,删完之后pos刚好是end的位置,而end位置是没有元素的,那么pos就失效了。因此删除vector中任意位置上元素时,vs就认为该位置迭代器失效了(这里挺好理解的,就不画图了)。
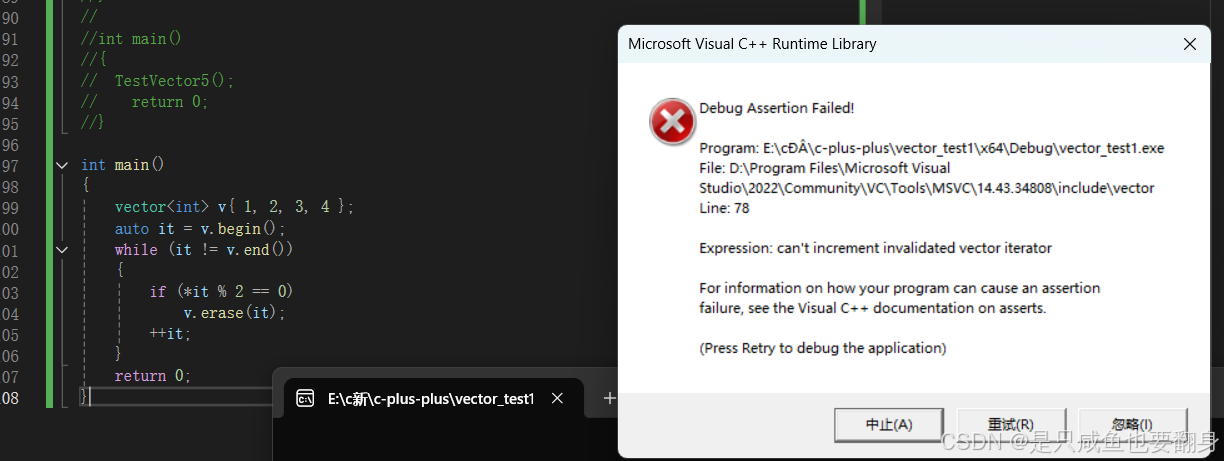
删除所有的偶数:
我们发现,它出现了迭代器失效的问题:其理由就是上面所说迭代情况。
那么我们该怎么改正它呢?
*******在使用前,对迭代器重新赋值即可******
区别差异:不同平台下,处理迭代器失效的问题的方式会不同:
vs平台下,它会出现直接强制检查,因此只要有迭代器失效,统统报错。
Linux的centos的g++编译器下:它有时尽管出现了迭代器失效的问题,但是仍然可以跑的。只是输出的结果不对而已!
删除所有的偶数:(Linux中)也是错误。


关于vector的基础知识分享就到处结束了。
最后,到了我们本次鸡汤环节:
下面文字与大家共勉!

![ZLMediaKit 源码分析——[5] ZLToolKit 中EventPoller之延时任务处理](http://pic.xiahunao.cn/ZLMediaKit 源码分析——[5] ZLToolKit 中EventPoller之延时任务处理)
组件)
)






)





![【GPT入门】第33 课 一文吃透 LangChain:chain 结合 with_fallbacks ([]) 的实战指南](http://pic.xiahunao.cn/【GPT入门】第33 课 一文吃透 LangChain:chain 结合 with_fallbacks ([]) 的实战指南)



