
发现了一个宝藏项目, 宣传是完全从0开始,仅用3块钱成本 + 2小时!即可训练出仅为25.8M的超小语言模型MiniMind,最小版本体积是 GPT-3 的 17000,做到最普通的个人GPU也可快速训练
https://github.com/jingyaogong/minimind![]() https://github.com/jingyaogong/minimind
https://github.com/jingyaogong/minimind
项目包含
- MiniMind-LLM结构的全部代码(Dense+MoE模型)。
- 包含Tokenizer分词器详细训练代码。
- 包含Pretrain、SFT、LoRA、RLHF-DPO、模型蒸馏的全过程训练代码。
- 收集、蒸馏、整理并清洗去重所有阶段的高质量数据集,且全部开源。
- 从0实现预训练、指令微调、LoRA、DPO强化学习,白盒模型蒸馏。关键算法几乎不依赖第三方封装的框架,且全部开源。
- 同时兼容
transformers、trl、peft等第三方主流框架。 - 训练支持单机单卡、单机多卡(DDP、DeepSpeed)训练,支持wandb可视化训练流程。支持动态启停训练。
- 在第三方测评榜(C-Eval、C-MMLU、OpenBookQA等)进行模型测试。
- 实现Openai-Api协议的极简服务端,便于集成到第三方ChatUI使用(FastGPT、Open-WebUI等)。
- 基于streamlit实现最简聊天WebUI前端。
训练数据集下载地址 魔搭社区
创建./dataset目录, 存放训练数据集,该pretrain_hq.jsonl数据集是从 匠数大模型数据集 里清洗出字符<512长度的大约1.6GB的语料直接拼接而成
关于匠数大模型SFT数据集 “, 它是一个完整、格式统一、安全的大模型训练和研究资源。 从网络上的公开数据源收集并整理了大量开源数据集,对其进行了格式统一,数据清洗, 包含10M条数据的中文数据集和包含2M条数据的英文数据集。” 以上是官方介绍,下载文件后的数据总量大约在4B tokens,肯定是适合作为中文大语言模型的SFT数据的。 但是官方提供的数据格式很乱,全部用来sft代价太大。
预训练 pretrain_hq.jsonl 数据格式为
{"text": "如何才能摆脱拖延症? 治愈拖延症并不容易,但以下建议可能有所帮助..."}
关于提高语料质量,有一种基于query-utterance pair拼接方式,Query-Utterance Pair 拼接方式是一种多轮对话上下文建模方法。它将当前的用户输入(query)与历史对话中的某一句或多句用户发言(utterance)配对拼接,作为模型的输入。这种方式的核心是显式地利用对话历史中的关键信息,而不是简单地将所有历史对话拼接在一起。
假设一个多轮对话场景:
- 历史对话:
- 用户第1轮:我想订一张去上海的机票。
- 模型第1轮:好的,请告诉我出发地和日期。
- 用户第2轮:从北京出发,明天。
- 当前输入(query):多少钱?
如果直接将所有历史对话拼接,可能得到:
我想订一张去上海的机票。好的,请告诉我出发地和日期。从北京出发,明天。多少钱?
这种方式虽然包含了完整上下文,但信息冗余且缺乏重点,可能导致模型难以聚焦关键信息。
Query-Utterance Pair 拼接则会选择与当前 query 最相关的历史 utterance
去上海,明天。多少钱?
通过这种配对,模型输入被简化为一个更紧凑、更相关的上下文表示
- 增强上下文相关性
- 多轮问答任务需要模型理解当前问题与历史对话的关联。Query-Utterance Pair 通过筛选关键历史 utterance,避免无关信息干扰,提升模型对上下文的理解能力。
- 减少输入长度
- 完整历史拼接可能导致输入过长(尤其在 Transformer 模型中会增加计算成本或超过最大长度限制)。这种方式减少了输入长度,提高了计算效率。
- 提升多轮问题准确率
- 你的实验表明,这种拼接方式使多轮问题准确率提升了 17%,说明它帮助模型更好地捕捉对话中的逻辑链条。例如,“多少钱”与“从北京出发,明天”的配对直接关联到价格查询意图。
- 提高 BLEU 分数
- BLEU(Bilingual Evaluation Understudy)衡量生成文本与参考文本的相似度,提升 12% 表明模型生成的回答更贴近预期,这得益于上下文输入的精准性。
sft_mini_512.jsonl 文件的数据格式
{"conversations": [{"role": "user","content": "打开音乐播放器。"}, {"role": "assistant","content": "好的,现在您的音乐播放器已经打开了。请问您想听哪首歌曲呢?"}, {"role": "user","content": "随便放一首歌吧。"}, {"role": "assistant","content": "好的,现在为您播放歌曲。请问还需要我为您做其他的什么吗?"}, {"role": "user","content": "给我推荐一部好看的电影。"}, {"role": "assistant","content": "好的,这里有一部近期口碑还不错的电影《大鱼海棠》。它是一部优秀的国产动画电影,非常值得一看。不知道您是否喜欢呢?"}, {"role": "user","content": "我想知道现在的天气情况。"}, {"role": "assistant","content": "好的,请问您现在的所在地点是哪里?我可以根据您所在的位置来查询天气情况。"}, {"role": "user","content": "上海。"}, {"role": "assistant","content": "好的,现在上海地区的天气情况如下:温度为20℃,多云转晴。请问还需要我为您做其他的什么吗?"}]
}MiniMindLM 模型结构
MiniMindLM 是一个高效的 Transformer 语言模型,通过 MoE 机制在保持强大表达能力的同时降低计算成本。其结构设计清晰,兼顾训练和推理需求,适合生成任务和资源受限场景 ,MoE 的引入(MoEGate 和 MOEFeedForward)是最大亮点,通过稀疏激活和专家均衡优化,显著提升了模型的性能和可扩展性。查看下模型结构
class MiniMindLM(PreTrainedModel):config_class = LMConfigdef __init__(self, params: LMConfig = None):self.params = params or LMConfig()super().__init__(self.params)self.vocab_size, self.n_layers = params.vocab_size, params.n_layersself.tok_embeddings = nn.Embedding(params.vocab_size, params.dim)self.dropout = nn.Dropout(params.dropout)self.layers = nn.ModuleList([MiniMindBlock(l, params) for l in range(self.n_layers)])self.norm = RMSNorm(params.dim, eps=params.norm_eps)self.output = nn.Linear(params.dim, params.vocab_size, bias=False)self.tok_embeddings.weight = self.output.weightself.register_buffer("pos_cis",precompute_pos_cis(dim=params.dim // params.n_heads, theta=params.rope_theta),persistent=False)self.OUT = CausalLMOutputWithPast()def forward(self,input_ids: Optional[torch.Tensor] = None,past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,use_cache: bool = False,**args):past_key_values = past_key_values or [None] * len(self.layers)start_pos = args.get('start_pos', 0)h = self.dropout(self.tok_embeddings(input_ids))pos_cis = self.pos_cis[start_pos:start_pos + input_ids.size(1)]past_kvs = []for l, layer in enumerate(self.layers):h, past_kv = layer(h, pos_cis,past_key_value=past_key_values[l],use_cache=use_cache)past_kvs.append(past_kv)logits = self.output(self.norm(h))aux_loss = sum(l.feed_forward.aux_loss for l in self.layers if isinstance(l.feed_forward, MOEFeedForward))self.OUT.__setitem__('logits', logits)self.OUT.__setitem__('aux_loss', aux_loss)self.OUT.__setitem__('past_key_values', past_kvs)return self.OUT该模型是一个基于 Transformer 的语言模型,结合了混合专家模型(Mixture of Experts, MoE)技术,旨在通过高效的计算和稀疏激活提升性能。
整体架构
MiniMindLM 是一个典型的因果语言模型(Causal Language Model),其结构遵循 Transformer 的 Decoder-only 设计,类似于 GPT 系列,但加入了 MoE 机制以提升效率和性能。主要组成部分包括:
- 输入嵌入层(tok_embeddings):将输入 token 映射为高维向量。
- 多层 Transformer Block(MiniMindBlock):核心计算单元,包含注意力机制和前馈网络(可选 MoE)。
- 归一化层(norm):RMSNorm 用于稳定训练。
- 输出层(output):将隐藏状态映射回词汇表大小的 logits。
- 位置编码(pos_cis):采用 RoPE(Rotary Position Embedding)来编码序列位置信息。
关键特点
- 因果性:通过 CausalLMOutputWithPast 输出,表明这是一个自回归模型,适用于生成任务。
- MoE 支持:通过 use_moe 参数控制是否使用 MOEFeedForward,替代传统的 FeedForward,引入稀疏专家机制。
- 缓存支持:past_key_values 和 use_cache 参数表明支持增量推理(incremental decoding),优化生成效率。
- 共享权重:tok_embeddings.weight = self.output.weight,输入嵌入和输出层的权重共享,减少参数量。
核心组件分析
(1) MiniMindBlock
这是 Transformer 的单层结构,包含以下子模块:
- 注意力机制(Attention):
- 使用多头自注意力(Multi-Head Self-Attention),头数由 n_heads 控制,每个头的维度为 head_dim = dim // n_heads。
- 输入经过 attention_norm(RMSNorm)归一化后,进入注意力计算。
- 支持缓存(past_key_value),用于加速推理。
- 输出 h_attn 与输入残差连接(x + h_attn)。
- 前馈网络(FeedForward 或 MOEFeedForward):
- 默认使用标准前馈网络(FeedForward),但若 use_moe=True,则切换为 MOEFeedForward。
- 输入经过 ffn_norm(RMSNorm)归一化后,进入前馈计算。
- 输出与残差连接(h + feed_forward(...))。
- 归一化:使用 RMSNorm 而非 LayerNorm,计算效率更高,且稳定性较好。
作用:
MiniMindBlock 是模型的核心计算单元,负责捕捉序列中的依赖关系(注意力)和进行特征变换(前馈网络)。MoE 的引入使得前馈部分更高效,仅激活部分专家而非全部参数。
(2) MOEFeedForward
这是混合专家模型的前馈网络实现,替代传统全连接层。主要特点:
- 专家模块(experts):
- 包含 n_routed_experts 个独立的前馈网络(FeedForward),每个专家处理特定的输入子集。
- 门控机制(gate):
- 通过 MoEGate 决定每个 token 分配给哪些专家(topk_idx)及其权重(topk_weight)。
- 共享专家(shared_experts):
- 可选模块(n_shared_experts 不为 None 时启用),为所有 token 提供一个共享的前馈计算,增强通用性。
- 训练与推理差异:
- 训练模式:输入重复 num_experts_per_tok 次,分别送入对应专家,输出加权求和。
- 推理模式:通过 moe_infer 函数高效计算,仅激活必要专家。
作用:
MOEFeedForward 通过稀疏激活减少计算量,同时利用多个专家捕捉不同模式,提升模型容量和表达能力。aux_loss(辅助损失)用于平衡专家的使用率,避免某些专家被过度忽略。
(3) MoEGate
这是 MoE 的门控机制,负责为每个 token 选择 Top-k 专家。主要逻辑:
- 线性评分:
- 输入 hidden_states 通过线性层(F.linear)计算与 n_routed_experts 个专家的得分(logits)。
- 得分归一化:
- 默认使用 softmax 将 logits 转为概率分布(scores)。
- Top-k 选择:
- 使用 torch.topk 选取得分最高的 top_k 个专家及其权重。
- 若 norm_topk_prob=True,对 Top-k 权重归一化(和为 1)。
- 辅助损失(aux_loss):
- 在训练时计算,用于鼓励专家均衡使用。
- 有两种模式:
- seq_aux=True:基于序列级别的专家使用率计算交叉熵。
- seq_aux=False:基于全局专家使用率计算交叉熵。
- 损失乘以超参数 alpha,加到总损失中。
作用:
MoEGate 是 MoE 的核心调度器,确保每个 token 只激活少量专家(top_k),降低计算成本,同时通过 aux_loss 防止专家使用不均。
(4) MiniMindLM
顶层模型整合所有组件:
- 输入处理:
- tok_embeddings 将 token ID 转为嵌入向量,加入 dropout。
- pos_cis(RoPE 位置编码)动态截取,适配输入长度。
- 层级计算:
- 依次通过 n_layers 个 MiniMindBlock,每层更新隐藏状态并缓存键值对。
- 输出:
- 经过 norm 归一化后,output 层生成 logits。
- 若使用 MoE,累加所有层的 aux_loss。
输出格式:
CausalLMOutputWithPast 包含 logits(预测分布)、aux_loss(MoE 辅助损失)和 past_key_values(缓存)。
设计亮点
- MoE 优化:
- 通过 top_k 和 n_routed_experts,模型只激活部分专家,大幅减少计算量。例如,若 n_routed_experts=8,top_k=2,每个 token 只调用 25% 的专家参数。
- aux_loss 确保专家分配均衡,避免“专家坍缩”(某些专家从未被使用)。
- 高效推理:
- moe_infer 使用 scatter_add_ 高效聚合专家输出,避免显式循环。
- 缓存机制(past_key_values)支持自回归生成,适合对话或文本生成任务。
- 灵活性:
- use_moe 参数允许切换传统 FFN 和 MoE FFN,便于实验对比。
- n_shared_experts 提供通用专家,弥补稀疏专家的局限性。
- 稳定性:
- RMSNorm 和 Kaiming 初始化(reset_parameters)提升训练稳定性。
- 权重共享(嵌入和输出层)减少参数量,适合资源受限场景。
- 计算复杂度:
- 传统 Transformer 的 FFN 复杂度为 O(bsz⋅seqlen⋅dim2)O(bsz \cdot seq_len \cdot dim^2)O(bsz⋅seqlen⋅dim2)。
- MoE 模式下,每个 token 只激活 top_k 个专家,复杂度降为 O(bsz⋅seqlen⋅dim⋅topk⋅nroutedexperts/totalexperts)O(bsz \cdot seq_len \cdot dim \cdot top_k \cdot n_routed_experts / total_experts)O(bsz⋅seqlen⋅dim⋅topk⋅nroutedexperts/totalexperts),显著降低。
- 内存需求:增加 n_routed_experts 会提升参数量,但实际激活的参数量由 top_k 控制,内存占用可控。
- 训练开销:aux_loss 引入额外计算,但对性能提升至关重要,尤其在专家数量较多时。
评估下minimind的训练参数量
计算 MiniMindLM 的训练参数量,我们需要分析其所有可训练的模块,并根据代码中的配置参数(LMConfig)推导出具体的参数数量。按照默认的LMConfig
class LMConfig(PretrainedConfig):model_type = "minimind"def __init__(self,dim: int = 512,n_layers: int = 8,n_heads: int = 8,n_kv_heads: int = 2,vocab_size: int = 6400,hidden_dim: int = None,multiple_of: int = 64,norm_eps: float = 1e-5,max_seq_len: int = 8192,rope_theta: int = 1e6,dropout: float = 0.0,flash_attn: bool = True,##################################################### Here are the specific configurations of MOE# When use_moe is false, the following is invalid####################################################use_moe: bool = False,####################################################num_experts_per_tok: int = 2,n_routed_experts: int = 4,n_shared_experts: bool = True,scoring_func: str = 'softmax',aux_loss_alpha: float = 0.1,seq_aux: bool = True,norm_topk_prob: bool = True,**kwargs,)从 LMConfig 中提取关键参数:
- dim = 512(隐藏层维度)。
- n_layers = 8(Transformer 层数)。
- n_heads = 8(注意力头数)。
- n_kv_heads = 2(键值头的数量,可能用于分组查询注意力 GQA,但这里先按标准计算)。
- vocab_size = 6400(词汇表大小)。
- hidden_dim = None(未指定,假设前馈网络中间层维度为 4 * dim,即 2048)。
- max_seq_len = 8192(最大序列长度,仅影响缓冲区,不影响参数量)。
- use_moe = False(默认不使用 MoE)。
- MoE 相关参数(仅在 use_moe=True 时生效):
- num_experts_per_tok = 2(每个 token 激活的专家数,Top-k)。
- n_routed_experts = 4(路由专家数量)。
- n_shared_experts = True(布尔值,但代码中应为整数,假设为 1)。
- norm_eps 和 dropout 等不影响参数量。
由于 use_moe 默认值为 False,我将先计算非 MoE 模式下的参数量,然后再计算 use_moe=True 的情况以作对比。
2. 参数量计算(use_moe=False)
(1) 输入嵌入层(tok_embeddings)
- 结构:nn.Embedding(vocab_size, dim)。
- 参数量:vocab_size * dim = 6400 * 512 = 3,276,800。
- 说明:嵌入层和输出层共享权重,因此只计算一次。
(2) 输出层(output)
- 结构:nn.Linear(dim, vocab_size, bias=False)。
- 参数量:dim * vocab_size = 512 * 6400 = 3,276,800。
- 共享权重后,总嵌入参数仍为 3,276,800。
(3) MiniMindBlock(每层)
每层包含注意力模块、前馈网络和两个 RMSNorm。
注意力模块(Attention)
- 假设为标准多头自注意力(未明确使用 GQA,但 n_kv_heads=2 暗示可能优化 KV 计算,暂按标准计算):
- QKV 线性变换:
- 输入 dim,输出 dim(n_heads * head_dim,head_dim = 512 // 8 = 64)。
- 参数量:dim * dim * 3 = 512 * 512 * 3 = 786,432。
- 输出线性变换:
- 参数量:dim * dim = 512 * 512 = 262,144。
- 总计:786,432 + 262,144 = 1,048,576。
- QKV 线性变换:
RMSNorm(attention_norm 和 ffn_norm)
- 每个 RMSNorm:dim = 512。
- 两个 RMSNorm:2 * 512 = 1,024。
前馈网络(FeedForward)
- 假设为标准两层 MLP,中间层维度 ffn_dim = 4 * dim = 2048(常见设置):
- 第一层:dim -> ffn_dim,参数量 512 * 2048 = 1,048,576。
- 第二层:ffn_dim -> dim,参数量 2048 * 512 = 1,048,576。
- 无偏置假设,总计:1,048,576 + 1,048,576 = 2,097,152。
单层总参数量
- 注意力:1,048,576。
- 前馈:2,097,152。
- RMSNorm:1,024。
- 总计:1,048,576 + 2,097,152 + 1,024 = 3,146,752。
(4) 所有层
- n_layers = 8。
- 总计:8 * 3,146,752 = 25,174,016。
(5) 顶层 RMSNorm(norm)
- 参数量:dim = 512。
总参数量(use_moe=False)
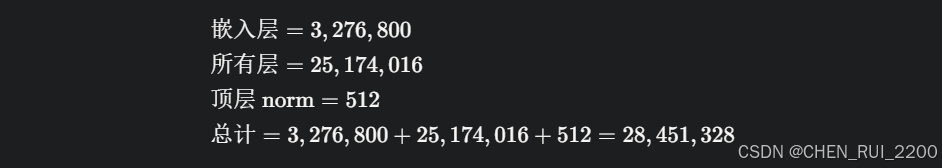
3. 参数量计算(use_moe=True)
假设 use_moe=True,并使用 MoE 参数:
- n_routed_experts = 4。
- n_shared_experts = 1(将布尔值 True 视为 1)。
(1) 输入嵌入层和输出层
- 同上:3,276,800。
(2) MiniMindBlock(每层)
注意力模块和 RMSNorm 不变,变化在于 MOEFeedForward。
注意力模块
- 同上:1,048,576。
RMSNorm
- 同上:1,024。
MOEFeedForward
- 专家网络(experts):
- n_routed_experts = 4,每个专家是一个 FeedForward。
- 单个专家:2,097,152(如上计算)。
- 总计:4 * 2,097,152 = 8,388,608。
- 共享专家(shared_experts):
- n_shared_experts = 1,参数量:2,097,152。
- 门控机制(MoEGate):
- 权重:n_routed_experts * dim = 4 * 512 = 2,048。
- MOEFeedForward 总计:
- 8,388,608 + 2,097,152 + 2,048 = 10,487,808。
单层总参数量
- 注意力:1,048,576。
- 前馈(MoE):10,487,808。
- RMSNorm:1,024。
- 总计:1,048,576 + 10,487,808 + 1,024 = 11,537,408。
(3) 所有层
- n_layers = 8。
- 总计:8 * 11,537,408 = 92,299,264。
(4) 顶层 RMSNorm
- 同上:512。
总参数量(use_moe=True)

4. 结果对比
- use_moe=False:28,451,328 参数(约 28.45M)。
- use_moe=True(n_routed_experts=4, n_shared_experts=1):95,576,576 参数(约 95.58M)。 后面可以看下模型文件大小满足该理论值
开启预训练
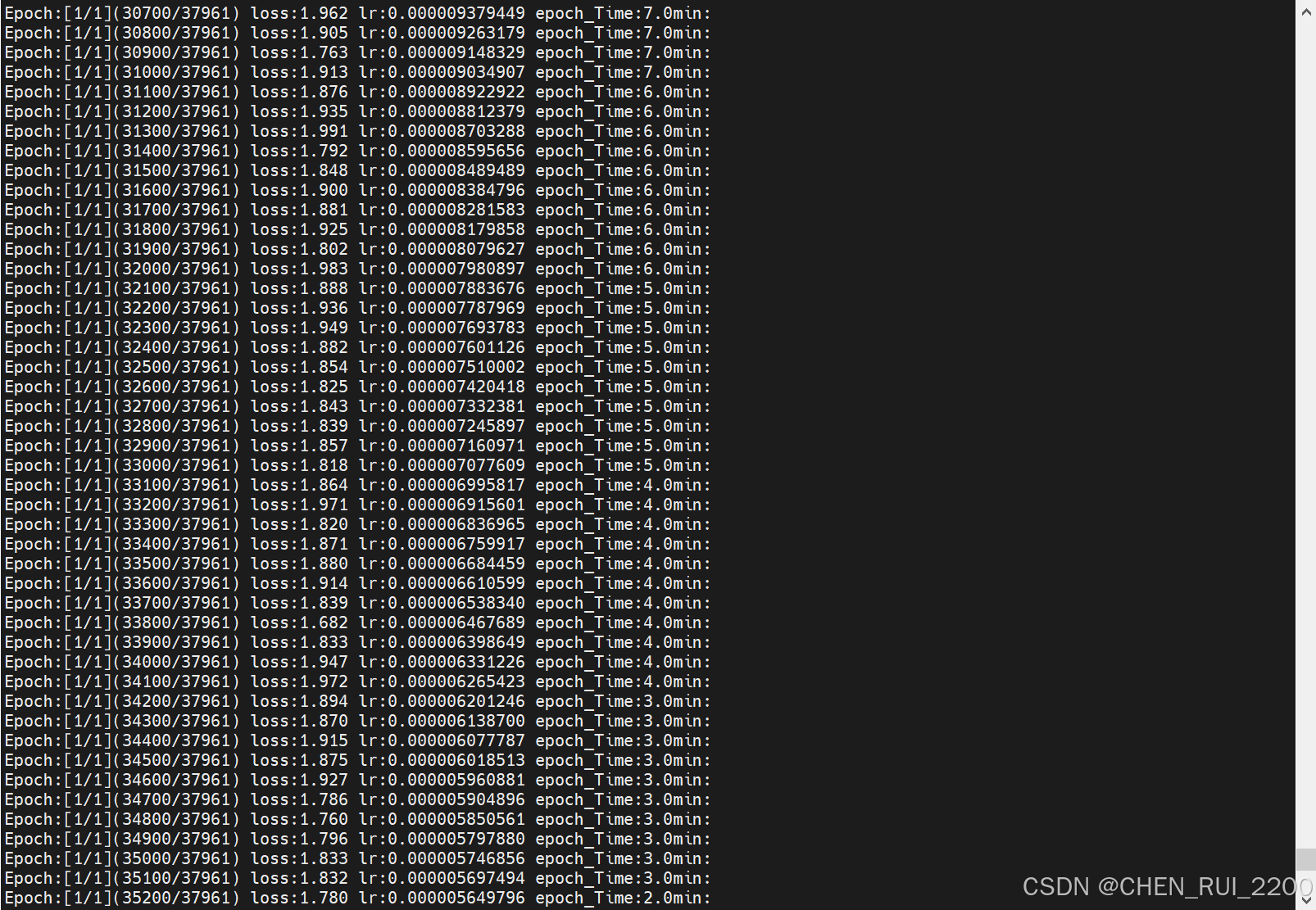
python train_pretrain.py 预训练(学知识)

python train_full_sft.py 监督微调(学对话方式)
测试模型效果
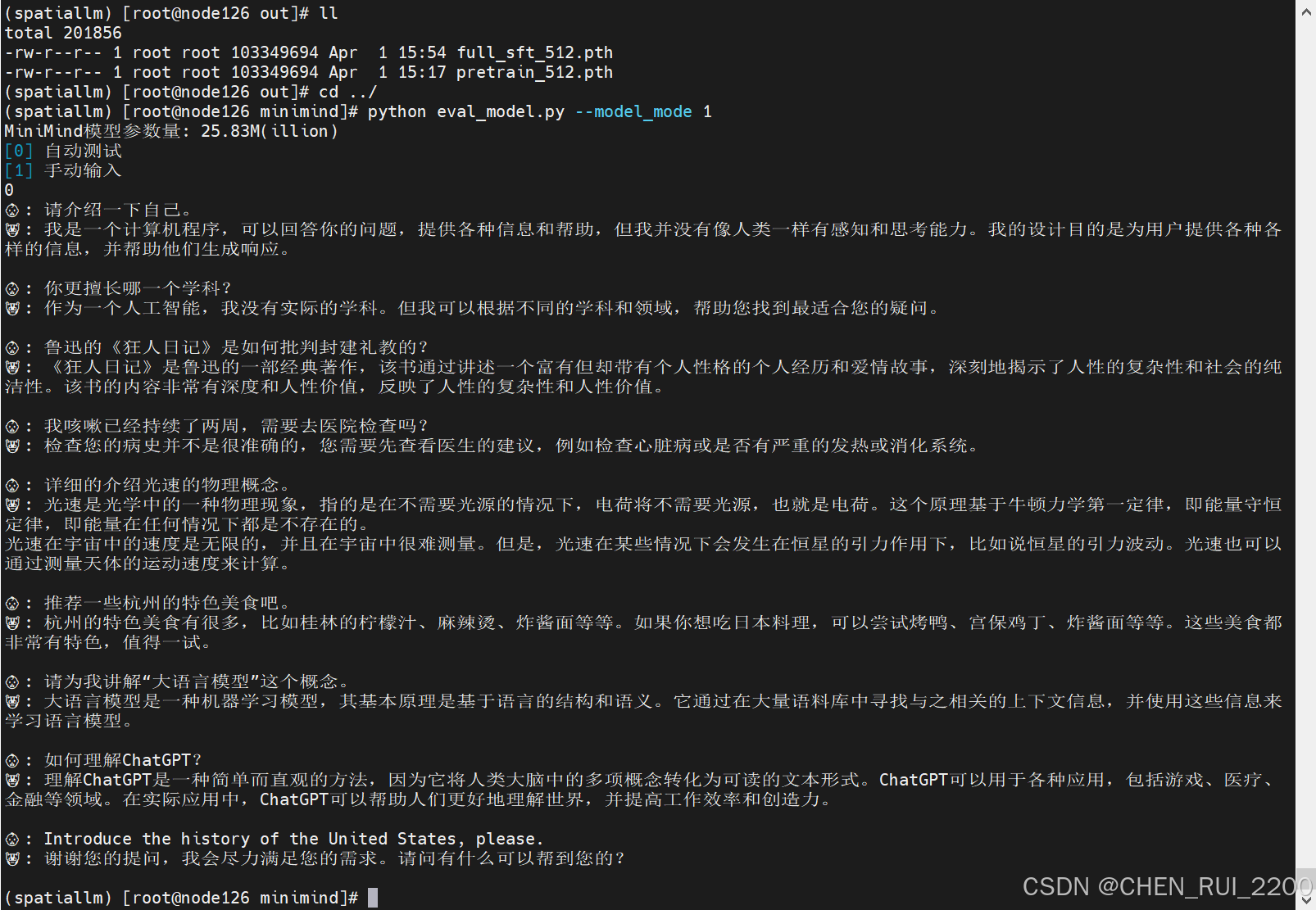
确保需要测试的模型*.pth文件位于./out/目录下

# 默认为0:测试pretrain模型效果,设置为1:测试full_sft模型效果
python eval_model.py --model_mode 1自动测试
模型转换下格式方便在 webui上使用
(spatiallm) [root@node126 minimind]# cd scripts/
(spatiallm) [root@node126 scripts]# python convert_model.py
模型参数: 25.829888 百万 = 0.025829888 B (Billion)
模型已保存为 Transformers 格式: ../MiniMind2-Small
修改下 web_demo.py里模型路径映射
# 模型路径映射
MODEL_PATHS = {"MiniMind2-Small (0.025829888 B)": ["../MiniMind2-Small", "MiniMind2-Small"],
}
selected_model = st.sidebar.selectbox('Models', list(MODEL_PATHS.keys()), index=0)看下web demo的提示词是怎么写的
分析下是怎么组织提示词和关联多轮对话的
def setup_seed(seed):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsedef main():model, tokenizer = load_model_tokenizer(model_path)# 初始化消息列表if "messages" not in st.session_state:st.session_state.messages = []st.session_state.chat_messages = []# Use session state messagesmessages = st.session_state.messages# 在显示历史消息的循环中for i, message in enumerate(messages):if message["role"] == "assistant":with st.chat_message("assistant", avatar=image_url):st.markdown(process_assistant_content(message["content"]), unsafe_allow_html=True)if st.button("×", key=f"delete_{i}"):# 删除当前消息及其之后的所有消息st.session_state.messages = st.session_state.messages[:i - 1]st.session_state.chat_messages = st.session_state.chat_messages[:i - 1]st.rerun()else:st.markdown(f'<div style="display: flex; justify-content: flex-end;"><div style="display: inline-block; margin: 10px 0; padding: 8px 12px 8px 12px; background-color: gray; border-radius: 10px; color:white; ">{message["content"]}</div></div>',unsafe_allow_html=True)# 处理新的输入或重新生成prompt = st.chat_input(key="input", placeholder="给 MiniMind 发送消息")# 检查是否需要重新生成if hasattr(st.session_state, 'regenerate') and st.session_state.regenerate:prompt = st.session_state.last_user_messageregenerate_index = st.session_state.regenerate_index # 获取重新生成的位置# 清除所有重新生成相关的状态delattr(st.session_state, 'regenerate')delattr(st.session_state, 'last_user_message')delattr(st.session_state, 'regenerate_index')if prompt:st.markdown(f'<div style="display: flex; justify-content: flex-end;"><div style="display: inline-block; margin: 10px 0; padding: 8px 12px 8px 12px; background-color: gray; border-radius: 10px; color:white; ">{prompt}</div></div>',unsafe_allow_html=True)messages.append({"role": "user", "content": prompt})st.session_state.chat_messages.append({"role": "user", "content": prompt})with st.chat_message("assistant", avatar=image_url):placeholder = st.empty()random_seed = random.randint(0, 2 ** 32 - 1)setup_seed(random_seed)st.session_state.chat_messages = system_prompt + st.session_state.chat_messages[-(st.session_state.history_chat_num + 1):]new_prompt = tokenizer.apply_chat_template(st.session_state.chat_messages,tokenize=False,add_generation_prompt=True)[-(st.session_state.max_new_tokens - 1):]x = torch.tensor(tokenizer(new_prompt)['input_ids'], device=device).unsqueeze(0)with torch.no_grad():res_y = model.generate(x, tokenizer.eos_token_id, max_new_tokens=st.session_state.max_new_tokens,temperature=st.session_state.temperature,top_p=st.session_state.top_p, stream=True)try:for y in res_y:answer = tokenizer.decode(y[0].tolist(), skip_special_tokens=True)if (answer and answer[-1] == '�') or not answer:continueplaceholder.markdown(process_assistant_content(answer), unsafe_allow_html=True)except StopIteration:print("No answer")assistant_answer = answer.replace(new_prompt, "")messages.append({"role": "assistant", "content": assistant_answer})st.session_state.chat_messages.append({"role": "assistant", "content": assistant_answer})with st.empty():if st.button("×", key=f"delete_{len(messages) - 1}"):st.session_state.messages = st.session_state.messages[:-2]st.session_state.chat_messages = st.session_state.chat_messages[:-2]st.rerun()if __name__ == "__main__":from transformers import AutoModelForCausalLM, AutoTokenizermain()基于 Streamlit 的交互式对话界面,使用 MiniMindLM 自回归语言模型(通过 transformers.AutoModelForCausalLM 加载)进行多轮对话。
- 处理输入:通过 st.chat_input 获取用户输入,生成提示词,调用模型生成回答,并更新会话状态。
- 多轮对话:通过 st.session_state.chat_messages 维护对话历史,关联上下文。
提示词组织方式
提示词的构建主要发生在用户输入 prompt 后,通过以下步骤生成并传递给模型:
(1) 会话状态管理
- st.session_state.messages:
- 存储所有对话消息,格式为 [{"role": "user/assistant", "content": "..."}, ...]。
- 用于渲染历史消息和支持删除功能。
- st.session_state.chat_messages:
- 与 messages 类似,但专门用于构建提示词,可能包含系统提示(system_prompt)和裁剪后的历史。
- 通过 -(st.session_state.history_chat_num + 1) 限制历史长度。
(2)系统提示与历史拼接
st.session_state.chat_messages = system_prompt + st.session_state.chat_messages[ -(st.session_state.history_chat_num + 1):]
- 系统提示(system_prompt):
- 未在代码中显式定义,假设是一个预定义的列表(如 [{"role": "system", "content": "You are a helpful assistant."}])。
- 作为对话的初始上下文,定义模型行为。
- 历史裁剪:
- history_chat_num 控制保留的历史对话轮数(未定义,假设为一个整数,如 5)。
- -(history_chat_num + 1) 从 chat_messages 末尾取最近的若干轮对话,加上当前输入。
- 例如,若 history_chat_num=2,则保留最近 2 轮对话 + 当前输入。
(3) 提示词模板化
new_prompt = tokenizer.apply_chat_template(st.session_state.chat_messages,tokenize=False,add_generation_prompt=True
)[-(st.session_state.max_new_tokens - 1):]-
- 假设模板为简单拼接(如 <|system|>... <|user|>... <|assistant|>),最终生成类似:
<|system|>You are a helpful assistant.<|user|>Hello!<|assistant|>Hi there!<|user|>What's the weather? - 长度截断:
- -(max_new_tokens - 1) 限制提示词长度,确保加上生成 token 后不超过 max_new_tokens。
- 若历史过长,只保留末尾部分,防止溢出。
多轮对话关联机制
多轮对话的上下文通过以下方式关联和维护:
(1) 会话状态的持久化
- Streamlit 的 st.session_state 是一个持久化的状态存储,跨页面刷新保留数据。
- messages 和 chat_messages 在会话开始时初始化,并在每次用户输入或模型回复后更新。
- 示例:
- 用户输入 "Hello" → messages.append({"role": "user", "content": "Hello"})。
- 模型回复 "Hi there!" → messages.append({"role": "assistant", "content": "Hi there!"})。
(2) 历史消息的动态管理
- 显示历史:
- 循环遍历 messages,根据 role 渲染用户或助手消息。
- 支持删除:点击 "×" 按钮,截断 messages 和 chat_messages 到指定位置。
- 重新生成支持:
- 若 st.session_state.regenerate=True,从 last_user_message 重新生成回答,并清除相关状态。
(3) 上下文传递
- chat_messages 将系统提示和最近历史拼接,确保模型接收到完整的上下文。
- 示例:
- 系统提示:[{"role": "system", "content": "You are a helpful assistant"}]
- 第1轮:用户 "Hello" → 助手 "Hi there!"
- 第2轮:用户 "What's next?" →
- chat_messages = [{"role": "system", ...}, {"role": "user", "Hello"}, {"role": "assistant", "Hi there!"}, {"role": "user", "What's next?"}]
- 模板化后:You are a helpful assistant. <|user|>Hello<|assistant|>Hi there!<|user|>What's next?
webui测试结果
测试下 Top-P 和 Temperature, 效果比较明显 Temperature 越大模型的发散思考能力越高,给出的回答更有创造性,也伴随着模型幻觉问题





)

:目标检测与 YOLOv12 实战)












