大家早好、午好、晚好吖 ❤ ~欢迎光临本文章

如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码
首先引入三件套和scipy
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
拿到实验数据,通过pandas读取为DataFrame
data = pd.read_csv("W-900K.csv")
data.head()
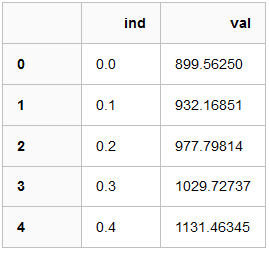
将数据绘制出来,以方便确认使用哪种方程进行拟合
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:702813599
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
plot1=plt.plot(data['ind'], data['val'], '*',label='original values')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc=4)
plt.title('ORIGIN VALUES')
plt.show()
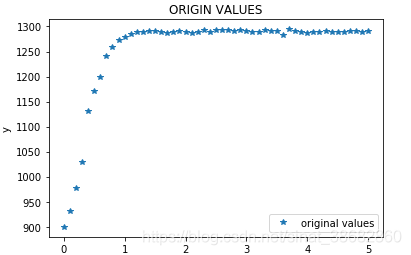
从上图曲线可以推断出,我们的数据应该符合指数分布,所以下面定义一个指数函数,将参数使用a,b,c预留出来.
def func(x,a,b,c):return a*np.exp(b*x) + c
1
2
进行拟合,得出上一步定义的参数, popt中得出的三个值分别代表上述函数中的三个参数 a,b,cpopt, pcov = curve_fit(func, data['ind'], data['val'])
print(popt)[-443.68006622 -2.49480416 1293.98737632]
至此我们的求解已经结束,下面用得到的结果绘制出函数曲线以验证结果的正确性
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:702813599
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 原始数据
plt.plot(data['ind'], data['val'], '*',label='original values')
# 拟合出的数据
plt.plot(data['ind'], func(data['ind'],popt[0],popt[1],popt[2]), 'r',label='curve fit values')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(loc=4)
plt.title('COMPARISON')
plt.show()
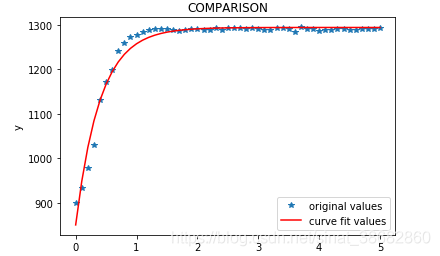
尾语
好了,今天的分享就差不多到这里了!
对下一篇大家想看什么,可在评论区留言哦!看到我会更新哒(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!



ClickHouse合并树MergeTree家族表引擎之GraphiteMergeTree详细解析)

)





)



 矩阵分析)




