第一章·前提须知
1.1 需要学什么
- Dbeaver 的基本使用
- SQL 语句:最重要的就是查询(在实战的时候,你会发现我们做的绝大部分工作就是 “查询”)
- MySQL 存储过程(利用数据库底层提供的语言,去进行业务逻辑的封装,其特点是
高性能高安全高便捷)银行、金融类用的是最多的!有些项目,后期想进行优化的话,优先考虑的就是把一些耗时的业务逻辑,转而写成 存储过程! - MySQL 优化:对于不同的业务来说,你写的 SQL 语句,最好是较优的。虽然说,前期的时候,我们是为了完成查询目的结果集为主,但后续有必要的话,还是会研究如何写才能更加优质,效率更高。
- 企业面试题:面试题肯定避免不了,现在大环境就是这样。。
1.2 为什么学
-
说句实在话~ 软件其实就是在处理数据,后端开发主要也是针对于这方面,或者就是 依托于数据库这个东西,去吃饭的,要不然都没活儿干。。
-
数据库对应的单词:DataBase 简称 => DB,数据库管理系统 DBMS。 数据库最终是存储在硬盘上的一个文件。而数据库管理系统是一款软件,专门用来管理存储在硬盘上的数据库文件!一般具有存储、截取、安全保障、备份等基础功能。我们学的 MySQL 就是一个DBMS。
-
当今世界是互联网时代,充斥着大量的数据。
发送的消息、图片、语音观看的视频听的音乐等等都是数据。 -
那么存储数据肯定是要存储到硬盘上或者临时存储到内存中,那么为什么非要用这个所谓的数据库去存储呢?答:因为数据库更加的专业,它们的增删改查更加的高效,如果是我们自己去研发这么一个东西,简直就是在开玩笑。。
1.3 数据库类型
- 关系型:是一个类似于 EXCEL 行列的二维表。我们把行称为
条,把列称为字段,它主张关系模型 如一对一、一对多、多对多缺点:耦合性强,可扩展性低、不灵活。 - 非关系型:干掉了关系型的缺点,数据之间并无关系!这样就很容易进行扩展,并且大多数都是存储于缓存的(内存),所以性能很高。
1.4 SQL 是何物
SQL 是结构化查询语言,是高级的非过程化编程语言。专门用来与数据库进行交流,打交道用的!
SQL 分类:
- DQL:数据库查询语言(SELECT、FROM、WHERE、ON、GROUP BY、HAVING、ORDER BY )
- DDL:数据定义语言(CREATE 创建、ALTER 修改、DROP 坠落) 专门弄表结构的
- DML:数据操纵语言(INSERT、UPDATE、DELETE)
- DCL:数据控制语言(GRANT 授权、REVOKE 撤权)专门用来给角色授权
- TPL:数据事务管理语言(BEGIN TRANSACTION、COMMIT、ROLLBACK)
- CCL:指针控制语言(DECLARE CURSOR、FETCH INTO、UPDATE WHERE CURRENT)我们查询拿到结果集后,可以用游标对结果集进行遍历。
DBMS 主要就是通过 SQL 来操控 DB 中的数据!
DML、DQL 是最常用的。
1.5 MySQL 登录
本地登录:
mysql -uroot -p[密码] -P[端口]
远程登录
mysql -uroot -h[目标IP] -P[端口] -p[密码]
1.6 一些常用的命令
show databases; # 展示所有数据库
create database 数据库名字; # 创建了个数据库
use 数据库名字; # 使用这个数据库
select database(); # 当前用的是哪个数据库
drop database 数据库名字; # 干掉一个数据库
source [sql脚本文件] # 自动去逐行执行 sql脚本文件的内容
----------------------------------------show tables; # 查看当前使用数据库中的表
desc [表名] #查看表的结构
exit # 退出 mysql 命令行
select version(); # 查询mysql版本号
# 在 windows 默认的 cmd 下直接输入 mysql --version 也可以查看 版本号
1.7 创建学习需要的数据库
DROP DATABASE IF EXISTS `sql_invoicing`;
CREATE DATABASE `sql_invoicing`;
USE `sql_invoicing`;SET NAMES utf8 ;
SET character_set_client = utf8mb4 ;CREATE TABLE `payment_methods` (`payment_method_id` tinyint(4) NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL,PRIMARY KEY (`payment_method_id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `payment_methods` VALUES (1,'Credit Card');
INSERT INTO `payment_methods` VALUES (2,'Cash');
INSERT INTO `payment_methods` VALUES (3,'PayPal');
INSERT INTO `payment_methods` VALUES (4,'Wire Transfer');CREATE TABLE `clients` (`client_id` int(11) NOT NULL,`name` varchar(50) NOT NULL,`address` varchar(50) NOT NULL,`city` varchar(50) NOT NULL,`state` char(2) NOT NULL,`phone` varchar(50) DEFAULT NULL,PRIMARY KEY (`client_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `clients` VALUES (1,'Vinte','3 Nevada Parkway','Syracuse','NY','315-252-7305');
INSERT INTO `clients` VALUES (2,'Myworks','34267 Glendale Parkway','Huntington','WV','304-659-1170');
INSERT INTO `clients` VALUES (3,'Yadel','096 Pawling Parkway','San Francisco','CA','415-144-6037');
INSERT INTO `clients` VALUES (4,'Kwideo','81674 Westerfield Circle','Waco','TX','254-750-0784');
INSERT INTO `clients` VALUES (5,'Topiclounge','0863 Farmco Road','Portland','OR','971-888-9129');CREATE TABLE `invoices` (`invoice_id` int(11) NOT NULL,`number` varchar(50) NOT NULL,`client_id` int(11) NOT NULL,`invoice_total` decimal(9,2) NOT NULL,`payment_total` decimal(9,2) NOT NULL DEFAULT '0.00',`invoice_date` date NOT NULL,`due_date` date NOT NULL,`payment_date` date DEFAULT NULL,PRIMARY KEY (`invoice_id`),KEY `FK_client_id` (`client_id`),CONSTRAINT `FK_client_id` FOREIGN KEY (`client_id`) REFERENCES `clients` (`client_id`) ON DELETE RESTRICT ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `invoices` VALUES (1,'91-953-3396',2,101.79,0.00,'2019-03-09','2019-03-29',NULL);
INSERT INTO `invoices` VALUES (2,'03-898-6735',5,175.32,8.18,'2019-06-11','2019-07-01','2019-02-12');
INSERT INTO `invoices` VALUES (3,'20-228-0335',5,147.99,0.00,'2019-07-31','2019-08-20',NULL);
INSERT INTO `invoices` VALUES (4,'56-934-0748',3,152.21,0.00,'2019-03-08','2019-03-28',NULL);
INSERT INTO `invoices` VALUES (5,'87-052-3121',5,169.36,0.00,'2019-07-18','2019-08-07',NULL);
INSERT INTO `invoices` VALUES (6,'75-587-6626',1,157.78,74.55,'2019-01-29','2019-02-18','2019-01-03');
INSERT INTO `invoices` VALUES (7,'68-093-9863',3,133.87,0.00,'2019-09-04','2019-09-24',NULL);
INSERT INTO `invoices` VALUES (8,'78-145-1093',1,189.12,0.00,'2019-05-20','2019-06-09',NULL);
INSERT INTO `invoices` VALUES (9,'77-593-0081',5,172.17,0.00,'2019-07-09','2019-07-29',NULL);
INSERT INTO `invoices` VALUES (10,'48-266-1517',1,159.50,0.00,'2019-06-30','2019-07-20',NULL);
INSERT INTO `invoices` VALUES (11,'20-848-0181',3,126.15,0.03,'2019-01-07','2019-01-27','2019-01-11');
INSERT INTO `invoices` VALUES (13,'41-666-1035',5,135.01,87.44,'2019-06-25','2019-07-15','2019-01-26');
INSERT INTO `invoices` VALUES (15,'55-105-9605',3,167.29,80.31,'2019-11-25','2019-12-15','2019-01-15');
INSERT INTO `invoices` VALUES (16,'10-451-8824',1,162.02,0.00,'2019-03-30','2019-04-19',NULL);
INSERT INTO `invoices` VALUES (17,'33-615-4694',3,126.38,68.10,'2019-07-30','2019-08-19','2019-01-15');
INSERT INTO `invoices` VALUES (18,'52-269-9803',5,180.17,42.77,'2019-05-23','2019-06-12','2019-01-08');
INSERT INTO `invoices` VALUES (19,'83-559-4105',1,134.47,0.00,'2019-11-23','2019-12-13',NULL);CREATE TABLE `payments` (`payment_id` int(11) NOT NULL AUTO_INCREMENT,`client_id` int(11) NOT NULL,`invoice_id` int(11) NOT NULL,`date` date NOT NULL,`amount` decimal(9,2) NOT NULL,`payment_method` tinyint(4) NOT NULL,PRIMARY KEY (`payment_id`),KEY `fk_client_id_idx` (`client_id`),KEY `fk_invoice_id_idx` (`invoice_id`),KEY `fk_payment_payment_method_idx` (`payment_method`),CONSTRAINT `fk_payment_client` FOREIGN KEY (`client_id`) REFERENCES `clients` (`client_id`) ON UPDATE CASCADE,CONSTRAINT `fk_payment_invoice` FOREIGN KEY (`invoice_id`) REFERENCES `invoices` (`invoice_id`) ON UPDATE CASCADE,CONSTRAINT `fk_payment_payment_method` FOREIGN KEY (`payment_method`) REFERENCES `payment_methods` (`payment_method_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `payments` VALUES (1,5,2,'2019-02-12',8.18,1);
INSERT INTO `payments` VALUES (2,1,6,'2019-01-03',74.55,1);
INSERT INTO `payments` VALUES (3,3,11,'2019-01-11',0.03,1);
INSERT INTO `payments` VALUES (4,5,13,'2019-01-26',87.44,1);
INSERT INTO `payments` VALUES (5,3,15,'2019-01-15',80.31,1);
INSERT INTO `payments` VALUES (6,3,17,'2019-01-15',68.10,1);
INSERT INTO `payments` VALUES (7,5,18,'2019-01-08',32.77,1);
INSERT INTO `payments` VALUES (8,5,18,'2019-01-08',10.00,2);DROP DATABASE IF EXISTS `sql_store`;
CREATE DATABASE `sql_store`;
USE `sql_store`;CREATE TABLE `products` (`product_id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL,`quantity_in_stock` int(11) NOT NULL,`unit_price` decimal(4,2) NOT NULL,PRIMARY KEY (`product_id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `products` VALUES (1,'Foam Dinner Plate',70,1.21);
INSERT INTO `products` VALUES (2,'Pork - Bacon,back Peameal',49,4.65);
INSERT INTO `products` VALUES (3,'Lettuce - Romaine, Heart',38,3.35);
INSERT INTO `products` VALUES (4,'Brocolinni - Gaylan, Chinese',90,4.53);
INSERT INTO `products` VALUES (5,'Sauce - Ranch Dressing',94,1.63);
INSERT INTO `products` VALUES (6,'Petit Baguette',14,2.39);
INSERT INTO `products` VALUES (7,'Sweet Pea Sprouts',98,3.29);
INSERT INTO `products` VALUES (8,'Island Oasis - Raspberry',26,0.74);
INSERT INTO `products` VALUES (9,'Longan',67,2.26);
INSERT INTO `products` VALUES (10,'Broom - Push',6,1.09);CREATE TABLE `shippers` (`shipper_id` smallint(6) NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL,PRIMARY KEY (`shipper_id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `shippers` VALUES (1,'Hettinger LLC');
INSERT INTO `shippers` VALUES (2,'Schinner-Predovic');
INSERT INTO `shippers` VALUES (3,'Satterfield LLC');
INSERT INTO `shippers` VALUES (4,'Mraz, Renner and Nolan');
INSERT INTO `shippers` VALUES (5,'Waters, Mayert and Prohaska');CREATE TABLE `customers` (`customer_id` int(11) NOT NULL AUTO_INCREMENT,`first_name` varchar(50) NOT NULL,`last_name` varchar(50) NOT NULL,`birth_date` date DEFAULT NULL,`phone` varchar(50) DEFAULT NULL,`address` varchar(50) NOT NULL,`city` varchar(50) NOT NULL,`state` char(2) NOT NULL,`points` int(11) NOT NULL DEFAULT '0',PRIMARY KEY (`customer_id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `customers` VALUES (1,'Babara','MacCaffrey','1986-03-28','781-932-9754','0 Sage Terrace','Waltham','MA',2273);
INSERT INTO `customers` VALUES (2,'Ines','Brushfield','1986-04-13','804-427-9456','14187 Commercial Trail','Hampton','VA',947);
INSERT INTO `customers` VALUES (3,'Freddi','Boagey','1985-02-07','719-724-7869','251 Springs Junction','Colorado Springs','CO',2967);
INSERT INTO `customers` VALUES (4,'Ambur','Roseburgh','1974-04-14','407-231-8017','30 Arapahoe Terrace','Orlando','FL',457);
INSERT INTO `customers` VALUES (5,'Clemmie','Betchley','1973-11-07',NULL,'5 Spohn Circle','Arlington','TX',3675);
INSERT INTO `customers` VALUES (6,'Elka','Twiddell','1991-09-04','312-480-8498','7 Manley Drive','Chicago','IL',3073);
INSERT INTO `customers` VALUES (7,'Ilene','Dowson','1964-08-30','615-641-4759','50 Lillian Crossing','Nashville','TN',1672);
INSERT INTO `customers` VALUES (8,'Thacher','Naseby','1993-07-17','941-527-3977','538 Mosinee Center','Sarasota','FL',205);
INSERT INTO `customers` VALUES (9,'Romola','Rumgay','1992-05-23','559-181-3744','3520 Ohio Trail','Visalia','CA',1486);
INSERT INTO `customers` VALUES (10,'Levy','Mynett','1969-10-13','404-246-3370','68 Lawn Avenue','Atlanta','GA',796);CREATE TABLE `order_statuses` (`order_status_id` tinyint(4) NOT NULL,`name` varchar(50) NOT NULL,PRIMARY KEY (`order_status_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `order_statuses` VALUES (1,'Processed');
INSERT INTO `order_statuses` VALUES (2,'Shipped');
INSERT INTO `order_statuses` VALUES (3,'Delivered');CREATE TABLE `orders` (`order_id` int(11) NOT NULL AUTO_INCREMENT,`customer_id` int(11) NOT NULL,`order_date` date NOT NULL,`status` tinyint(4) NOT NULL DEFAULT '1',`comments` varchar(2000) DEFAULT NULL,`shipped_date` date DEFAULT NULL,`shipper_id` smallint(6) DEFAULT NULL,PRIMARY KEY (`order_id`),KEY `fk_orders_customers_idx` (`customer_id`),KEY `fk_orders_shippers_idx` (`shipper_id`),KEY `fk_orders_order_statuses_idx` (`status`),CONSTRAINT `fk_orders_customers` FOREIGN KEY (`customer_id`) REFERENCES `customers` (`customer_id`) ON UPDATE CASCADE,CONSTRAINT `fk_orders_order_statuses` FOREIGN KEY (`status`) REFERENCES `order_statuses` (`order_status_id`) ON UPDATE CASCADE,CONSTRAINT `fk_orders_shippers` FOREIGN KEY (`shipper_id`) REFERENCES `shippers` (`shipper_id`) ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `orders` VALUES (1,6,'2019-01-30',1,NULL,NULL,NULL);
INSERT INTO `orders` VALUES (2,7,'2018-08-02',2,NULL,'2018-08-03',4);
INSERT INTO `orders` VALUES (3,8,'2017-12-01',1,NULL,NULL,NULL);
INSERT INTO `orders` VALUES (4,2,'2017-01-22',1,NULL,NULL,NULL);
INSERT INTO `orders` VALUES (5,5,'2017-08-25',2,'','2017-08-26',3);
INSERT INTO `orders` VALUES (6,10,'2018-11-18',1,'Aliquam erat volutpat. In congue.',NULL,NULL);
INSERT INTO `orders` VALUES (7,2,'2018-09-22',2,NULL,'2018-09-23',4);
INSERT INTO `orders` VALUES (8,5,'2018-06-08',1,'Mauris enim leo, rhoncus sed, vestibulum sit amet, cursus id, turpis.',NULL,NULL);
INSERT INTO `orders` VALUES (9,10,'2017-07-05',2,'Nulla mollis molestie lorem. Quisque ut erat.','2017-07-06',1);
INSERT INTO `orders` VALUES (10,6,'2018-04-22',2,NULL,'2018-04-23',2);CREATE TABLE `order_items` (`order_id` int(11) NOT NULL AUTO_INCREMENT,`product_id` int(11) NOT NULL,`quantity` int(11) NOT NULL,`unit_price` decimal(4,2) NOT NULL,PRIMARY KEY (`order_id`,`product_id`),KEY `fk_order_items_products_idx` (`product_id`),CONSTRAINT `fk_order_items_orders` FOREIGN KEY (`order_id`) REFERENCES `orders` (`order_id`) ON UPDATE CASCADE,CONSTRAINT `fk_order_items_products` FOREIGN KEY (`product_id`) REFERENCES `products` (`product_id`) ON UPDATE CASCADE
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `order_items` VALUES (1,4,4,3.74);
INSERT INTO `order_items` VALUES (2,1,2,9.10);
INSERT INTO `order_items` VALUES (2,4,4,1.66);
INSERT INTO `order_items` VALUES (2,6,2,2.94);
INSERT INTO `order_items` VALUES (3,3,10,9.12);
INSERT INTO `order_items` VALUES (4,3,7,6.99);
INSERT INTO `order_items` VALUES (4,10,7,6.40);
INSERT INTO `order_items` VALUES (5,2,3,9.89);
INSERT INTO `order_items` VALUES (6,1,4,8.65);
INSERT INTO `order_items` VALUES (6,2,4,3.28);
INSERT INTO `order_items` VALUES (6,3,4,7.46);
INSERT INTO `order_items` VALUES (6,5,1,3.45);
INSERT INTO `order_items` VALUES (7,3,7,9.17);
INSERT INTO `order_items` VALUES (8,5,2,6.94);
INSERT INTO `order_items` VALUES (8,8,2,8.59);
INSERT INTO `order_items` VALUES (9,6,5,7.28);
INSERT INTO `order_items` VALUES (10,1,10,6.01);
INSERT INTO `order_items` VALUES (10,9,9,4.28);CREATE TABLE `sql_store`.`order_item_notes` (`note_id` INT NOT NULL,`order_Id` INT NOT NULL,`product_id` INT NOT NULL,`note` VARCHAR(255) NOT NULL,PRIMARY KEY (`note_id`));INSERT INTO `order_item_notes` (`note_id`, `order_Id`, `product_id`, `note`) VALUES ('1', '1', '2', 'first note');
INSERT INTO `order_item_notes` (`note_id`, `order_Id`, `product_id`, `note`) VALUES ('2', '1', '2', 'second note');DROP DATABASE IF EXISTS `sql_hr`;
CREATE DATABASE `sql_hr`;
USE `sql_hr`;CREATE TABLE `offices` (`office_id` int(11) NOT NULL,`address` varchar(50) NOT NULL,`city` varchar(50) NOT NULL,`state` varchar(50) NOT NULL,PRIMARY KEY (`office_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `offices` VALUES (1,'03 Reinke Trail','Cincinnati','OH');
INSERT INTO `offices` VALUES (2,'5507 Becker Terrace','New York City','NY');
INSERT INTO `offices` VALUES (3,'54 Northland Court','Richmond','VA');
INSERT INTO `offices` VALUES (4,'08 South Crossing','Cincinnati','OH');
INSERT INTO `offices` VALUES (5,'553 Maple Drive','Minneapolis','MN');
INSERT INTO `offices` VALUES (6,'23 North Plaza','Aurora','CO');
INSERT INTO `offices` VALUES (7,'9658 Wayridge Court','Boise','ID');
INSERT INTO `offices` VALUES (8,'9 Grayhawk Trail','New York City','NY');
INSERT INTO `offices` VALUES (9,'16862 Westend Hill','Knoxville','TN');
INSERT INTO `offices` VALUES (10,'4 Bluestem Parkway','Savannah','GA');CREATE TABLE `employees` (`employee_id` int(11) NOT NULL,`first_name` varchar(50) NOT NULL,`last_name` varchar(50) NOT NULL,`job_title` varchar(50) NOT NULL,`salary` int(11) NOT NULL,`reports_to` int(11) DEFAULT NULL,`office_id` int(11) NOT NULL,PRIMARY KEY (`employee_id`),KEY `fk_employees_offices_idx` (`office_id`),KEY `fk_employees_employees_idx` (`reports_to`),CONSTRAINT `fk_employees_managers` FOREIGN KEY (`reports_to`) REFERENCES `employees` (`employee_id`),CONSTRAINT `fk_employees_offices` FOREIGN KEY (`office_id`) REFERENCES `offices` (`office_id`) ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `employees` VALUES (37270,'Yovonnda','Magrannell','Executive Secretary',63996,NULL,10);
INSERT INTO `employees` VALUES (33391,'D\'arcy','Nortunen','Account Executive',62871,37270,1);
INSERT INTO `employees` VALUES (37851,'Sayer','Matterson','Statistician III',98926,37270,1);
INSERT INTO `employees` VALUES (40448,'Mindy','Crissil','Staff Scientist',94860,37270,1);
INSERT INTO `employees` VALUES (56274,'Keriann','Alloisi','VP Marketing',110150,37270,1);
INSERT INTO `employees` VALUES (63196,'Alaster','Scutchin','Assistant Professor',32179,37270,2);
INSERT INTO `employees` VALUES (67009,'North','de Clerc','VP Product Management',114257,37270,2);
INSERT INTO `employees` VALUES (67370,'Elladine','Rising','Social Worker',96767,37270,2);
INSERT INTO `employees` VALUES (68249,'Nisse','Voysey','Financial Advisor',52832,37270,2);
INSERT INTO `employees` VALUES (72540,'Guthrey','Iacopetti','Office Assistant I',117690,37270,3);
INSERT INTO `employees` VALUES (72913,'Kass','Hefferan','Computer Systems Analyst IV',96401,37270,3);
INSERT INTO `employees` VALUES (75900,'Virge','Goodrum','Information Systems Manager',54578,37270,3);
INSERT INTO `employees` VALUES (76196,'Mirilla','Janowski','Cost Accountant',119241,37270,3);
INSERT INTO `employees` VALUES (80529,'Lynde','Aronson','Junior Executive',77182,37270,4);
INSERT INTO `employees` VALUES (80679,'Mildrid','Sokale','Geologist II',67987,37270,4);
INSERT INTO `employees` VALUES (84791,'Hazel','Tarbert','General Manager',93760,37270,4);
INSERT INTO `employees` VALUES (95213,'Cole','Kesterton','Pharmacist',86119,37270,4);
INSERT INTO `employees` VALUES (96513,'Theresa','Binney','Food Chemist',47354,37270,5);
INSERT INTO `employees` VALUES (98374,'Estrellita','Daleman','Staff Accountant IV',70187,37270,5);
INSERT INTO `employees` VALUES (115357,'Ivy','Fearey','Structural Engineer',92710,37270,5);DROP DATABASE IF EXISTS `sql_inventory`;
CREATE DATABASE `sql_inventory`;
USE `sql_inventory`;CREATE TABLE `products` (`product_id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL,`quantity_in_stock` int(11) NOT NULL,`unit_price` decimal(4,2) NOT NULL,PRIMARY KEY (`product_id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `products` VALUES (1,'Foam Dinner Plate',70,1.21);
INSERT INTO `products` VALUES (2,'Pork - Bacon,back Peameal',49,4.65);
INSERT INTO `products` VALUES (3,'Lettuce - Romaine, Heart',38,3.35);
INSERT INTO `products` VALUES (4,'Brocolinni - Gaylan, Chinese',90,4.53);
INSERT INTO `products` VALUES (5,'Sauce - Ranch Dressing',94,1.63);
INSERT INTO `products` VALUES (6,'Petit Baguette',14,2.39);
INSERT INTO `products` VALUES (7,'Sweet Pea Sprouts',98,3.29);
INSERT INTO `products` VALUES (8,'Island Oasis - Raspberry',26,0.74);
INSERT INTO `products` VALUES (9,'Longan',67,2.26);
INSERT INTO `products` VALUES (10,'Broom - Push',6,1.09);
第二章·单表查询
2.1 Select 基本查询
USE sql_store # 使用这个数据库
# 建议大写 SQL 关键字# from、where、order by 都是可选关键字
# * 代表所有字段
select * from customers; # 查哪个表的数据
select * from customers where customer_id = 1; # 条件查询
select * from customers order by first_name; # 按照某字段升序排序
select * from customers order by first_name desc; # 降序
select * from customers order by first_name asc, last_name desc; # 先 first_name 升序 然后再 last_name 降序
# look, you can write it and like this: 你可以这样写
select 1, 2
2.2 Select 字段值修饰与别名
select 查询出来的每行每列的字段值,是可以修饰的,修饰之后就会变成新的值展现给你。
- 对数值四则运算的修饰
use sql_store;select last_name,first_name,points,(points + 10) * 100 as discount_factor
from customers;select last_name,first_name,points,(points + 10) * 100 as 'discount factor' # 空格的话,就必须外套 ''
from customers;
- 去重修饰
select distinct state from customers; # distinct 会删除掉重复的项, 只保留第一项
返回所有产品,但要有一个新 price(unit price * 1.1)
select name, unit_price, unit_price * 1.1 as 'new price' from products;
- case when 条件 then 结果 end 修饰
select customer_id,first_name,points,case when points < 2000 then 'Bronze'when points between 2000 and 3000 then 'Silver'when points > 3000 then 'Gold'end as type
from customers;# sqlsugar 版本
var list = db.Queryable<Customer>().Select(c => new {c.customer_id,c.first_name,c.points,type = SqlFunc.IIF(c.points < 2000, "Bronze",SqlFunc.IIF(c.points >= 2000 && c.points <= 3000, "Silver", "Gold"))}).ToList();
CASE WHEN 语句是按顺序逐个判断的。一旦某个条件满足,CASE 语句会停止继续判断,并返回相应的结果。所以,一旦某个 WHEN 条件匹配了,接下来的条件就不会再被检查。
2.3 Where 子句
- 比较运算符
>
>=
<
<=
=
!= # <>
select * from Customers where birth_date > '1990-01-01' # 比较时间作为条件,可以直接写字符串,但与时间格式一致的常量作为时间数据
- 逻辑运算符
and # 与 and 优先级是要高一些
or # 或
not # 非
select * from Customers where birth_date > '1990-01-01' or points > 1000
select * from Customers where birth_date > '1990-01-01' or points > 1000 and state = "VA" # 由于 and 优先级要高一些,所以这条 SQL 等价于下面的
select * from Customers where birth_date > '1990-01-01' or (points > 1000 and state = "VA")
查询今年的订单
select * from orders where order_date >= '2019-01-01'
总价格大于30且订单编号为6
select * from order_itmes where orer_id = 6 and unit_price * quantity > 30
- between … and …
select * from customers where points >= 1000 and points <= 3000;select * from customers where points between 1000 and 3000select * from customers where birth_date between '1990-01-01' and '2001-01-02'
2.4 In 子句
In 是多条匹配的意思。
select * from Customers where state in('VA','FL','GA');select * from Customers where state not in('VA','FL','GA'); # 查询不是这仨的
查询质量49、38、72 的
select * from products where quantity_in_stok in (49, 38, 72);
2.5 Like 子句
like 是用于模糊匹配的。
select * from customers where last_name like 'b%' # % 是任意字符(0个字符、1个、多个都行)
select * from customers where last_name like '_b' # _ 是任意一个字符
获取顾客地址里面包含 trail 或者 avenue,然后电话号码最后一位是9
select * from customers where address like ('%trail%' or address like '%avenue%') and phone like '%9'
2.6 RegExp 子句
RegExp 是支持你写一个正则,然后进行匹配。
select * from customers where last_name regexp 'field';select * from customers where last_name regexp '^field'; # 以 field 开头的
select * from customers where last_name regexp 'field$'; # 以 field 结尾的
select * from customers where last_name regexp 'field|mac|rose'; # field 或 mac 或 rose
select * from customers where last_name regexp '^field|mac|rose'; # field 或 mac 或 rose
select * from customers where last_name regexp '[gim]e'; # 选择 gim 三个其中一个,然后 e 也就是 匹配 ge ie me
select * from customers where last_name regexp '[a-z]e'; # 选择 a到z 二十六个字母其中一个,然后 e
2.7 is null
当遇到数据为空的时候,其实用 is null 与 is not null 就基本够用了。
select * from customers where phone is not null;
查询还未发货的订单 ~
select * from sql_store.orders where shipped_date is null or shipped_id is null;
2.8 Order by 子句
Order by 就是根据字段排序的,所以挺简单的。
select birth_date, first_name from customers order by 1, 2; # 按照第一个字段和第二个字段排。
order_id = 2 并且总价格降序
select *, quantity * unit_price as total_price from order_items where order_id = 2 order by total_price desc;
2.9 limit 子句
limit 是用来分页的。
select * from customers limit 3 # 前三条数据select * from customers limit 6, 3 # 也就是 7 ~ 9
-- page 1 : 0 - 3
-- page 2 : 3 - 3
-- page 3 : 6 - 3
前三名最多积分的顾客
select * from customers order by points desc limit 3;
limit 使用格式:limit 索引,条数
第三章·联表查询
3.1 内连接
之所以叫内连接,是因为它只能够查询出真正连接上的。而不会查询出没连接上的!
select * from orders o inner join customers c on o.customer_id = c.customer_id # inner 可以省略
# on 的意思是我连接表的时候,我要确保一定的规则去连接
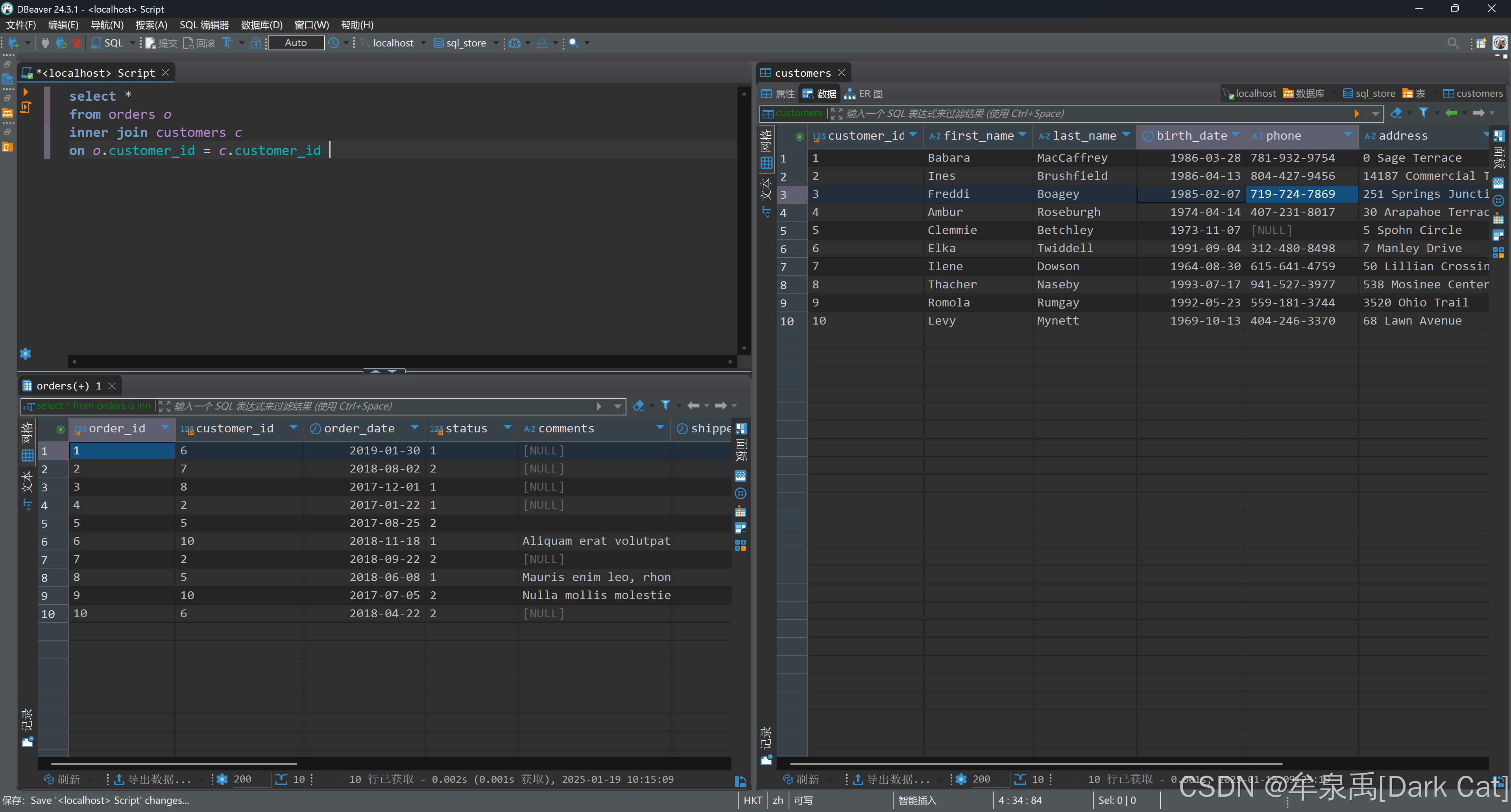
你会发现,我们这个连接,就是给特定条件匹配的行数据放到了一起。即拼接为了一行!
这样的话,我们就可以拿到两张表所有信息,去进行判断了。拼接之后,信息量更全!那么做特别的判断也就没啥好说的 ~
3.2 所谓跨库查询
实际上,就是 在表的前面加上数据库前缀。指定这个表是哪个库的,就跨库了。。。
use sql_inventory;select * from sql_store.order_items oi join products p on oi.product_id = p.product_id;
3.3 自连接
当一个表有类似于 parent_id 的时候,其实就属于自连接范畴了 ~
而自连接属于一种思想,即 我们自己连接自己这个思想。
use sql_hr;select e.employee_id, e.first_name, m.firsst_name as manager
from employees e join employees m on e.reports_to = m.employee_id;
3.4 多表连接与复合连接条件
多表连接也是一种思想,指的是联表查询超过两张表。
use sql_store;
select * from orders o join customers c on o.customer_id = c.customer_id
join order_statuses os on o.status = os.order_status_id;
连接条件其实并非只能如此单一,也可以复合。因为确实有的时候,我们需要复合才能够确定一条数据。
select * from order_items oi join order_item_notes oin On oi.order_id = oin.order_id and oi.product_id = oin.product_id
3.5 隐式连接等价于交叉连接
select * from orders o, customers c; # 交叉连接, 笛卡尔乘积select * from orders o, customers c where o.customer_id = c.customer_id;
# 隐式写法是交叉连接的隐式,而此时你只要用 where 来写条件,就还是等价于 内连接
3.6 外连接
外连接之所以存在,是因为我们会遇到这样的需求场景。
当我们想要知道顾客都有哪些订单的时候,你内连接去写。
select c.customer_id, c.first_name, o.order_id from customers c join orders o on c.customer_id = o.customer_id order by c.customer_id;
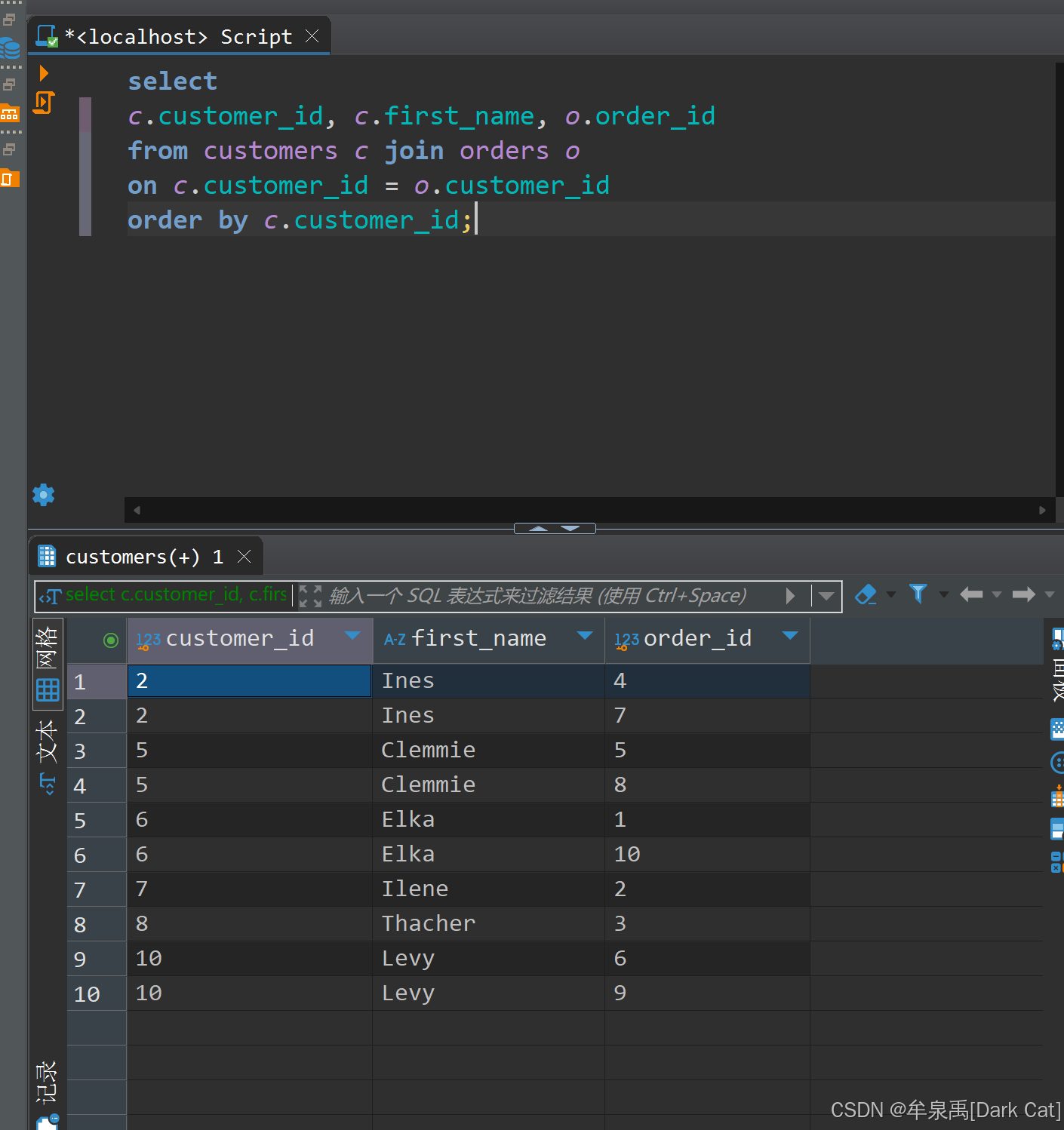
你会发现一个很重要的事情,那就是有些顾客它虽然没订单,但我得也把它放到这个结果集毕竟它没有。否则会造成我们二次处理数据或后续以此为基础查询时,较麻烦与困难的问题 ~
- 左连接:无论条件是否成立,我都以左表为基准全部返回左表的信息,而右表没匹配成功的,就返回 null
select c.customer_id, c.first_name, o.order_id from customers c left outer join orders o on c.customer_id = o.customer_id order by c.customer_id;
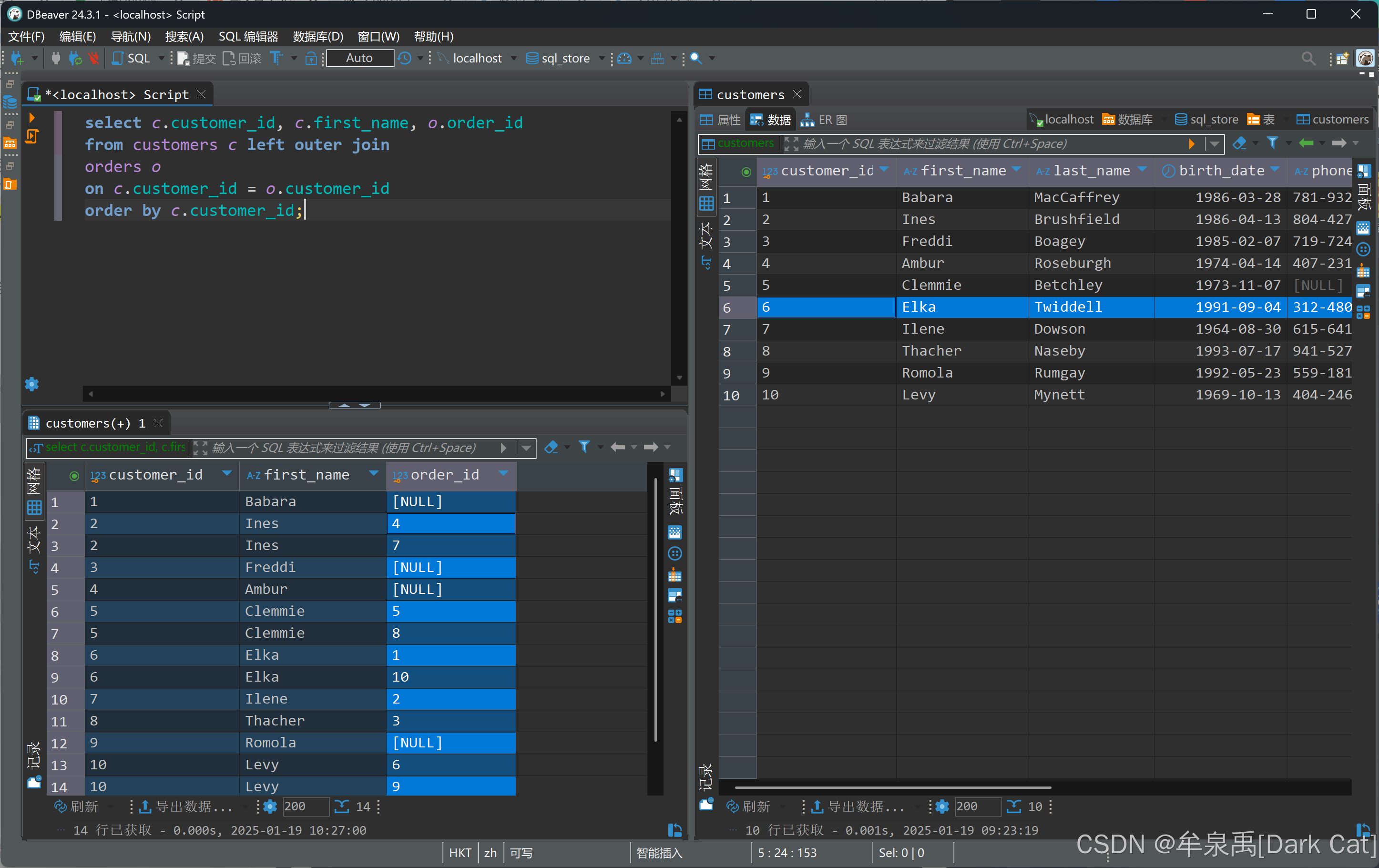
- 右连接:无论条件是否成立,我都以右表为基准全部返回右表的信息,而左表没匹配成功的,就返回 null
select c.customer_id, c.first_name, o.order_id from customers c right outer join orders o on c.customer_id = o.customer_id order by c.customer_id;select c.customer_id, c.first_name, o.order_id from customers c right join orders o on c.customer_id = o.customer_id order by c.customer_id;
其实这个 outer 可写可不写 ~
3.7 多表外连接与自外连接
select c.customer_id,c.first_name, o.order_id,sh.name as shipper
from customers c
left join orders o
on c.customer_id = o.customer_id
left join shippers sh on o.shipper_id = sh.shipper_id
order by c.customer_id;
多表里面,无论是 内连接还是外连接。一定要切记 “后一个联表,是在上一个联表结果集的基础上再去联的!”
自外连接就是 使用了 left join 与 right join 的自连接
use sql_hr;
select e.employee_id, e.first_name, m.first_name as manager
from employees e left join employees m on e.reports_to = m.employee_id;
3.8 Using 子句
using 是 简化on 语句的语法糖。它指的是如果你用的条件,仅仅只是同名字段相等,那么就可以用using。
select o.order_id, c.first_name from orders o join customers c using (customer_id) join shippers sh using (shipper_id)# 如果是复合条件,但是也是同名字段,那么也可以用 using
select * from order_items oi join order_item_notes oin using (order_id, product_id);
3.9 自然、交叉、联合(其它连接方式)
- 自然连接:数据库引擎会自己看着办,基于共同的列给你做连接。
selecto.order_id,c.first_name
from orders o natural join customers c
是很不推荐的一种连接方式。。
- 交叉连接:每条与每条都连接,笛卡尔乘积。
select c.first_name as customer,p.name as product
from customers c
cross join products p
order by c.first_name;select c.first_name as customer,p.name as product
from customers c, products p
order by c.first_name;
- 联合:指的是把两个结果集连接到一起!(并不是字段连接,就是单纯的两个结果集连接到一起)
select first_name from customers union select name from shippers
查询顾客的积分段位,如果是积分小于2000则是青铜,如果是 2000 ~ 3000 之间是白银,如果是 超过3000 则是黄金
select customer_id, first_name, points, 'Bronze' as type from customers
where points < 2000
union
select customer_id, first_name, points, 'Sliver' as type from customers
where points between 2000 and 3000
union
select customer_id, first_name, points, 'Glod' as type from customers
where points > 3000
第四章·聚合函数与子查询
4.1 聚合函数·简单使用
max() # 最大值
min() # 最小值
avg() # 平均值
sum() # 求和
count() # 数量select max(invoice_total) as highest,min(invoice_total) as lowest,avg(invoice_total) as average,sum(invoice_total) as total,sum(invoice_total * 1.1) as totalB,count(invoice_total) as number_of_invoices,
from invoices;
4.2 Group By 分组子句
分组:字面意思,按照哪些字段去分组。然后我们就在每一个组的基础上去 查数据了。
这里,其实可以自己想一下,所谓分组,你说是咋分呢?答:肯定是一样的分到一组啊 ~
select client_id, sum(invoice_total) as total_sales from invoices
where invoice_date > '2019-07-01' # 查询之前进行筛选
group by client_id # 按照 client_id 去进行分组
order by total_sales desc; # 查询之后的结果集再按照 total_sales 降序
Group By 误区:用了 Group By 就一定要知道,只能查询 可以代表每个组的字段。因为已经分组了,如果代表不了!那肯定就会报错。。
4.3 Having 筛选子句
Having 是在查询之后的结果集基础之上,再去进行筛选,然后返回一个新的结果集。所以通常来说,效率要比 where 低
select client_id,sum(invoice_total) as total_salescount(1) number_of_invoices
from invoices
where
group by client_id
having total_sales > 500 and number_of_invoices > 5;
但是 group by 总会搭配 having 去使用,毕竟 分完组之后,再去进行条件筛选,逻辑上才较为合理。
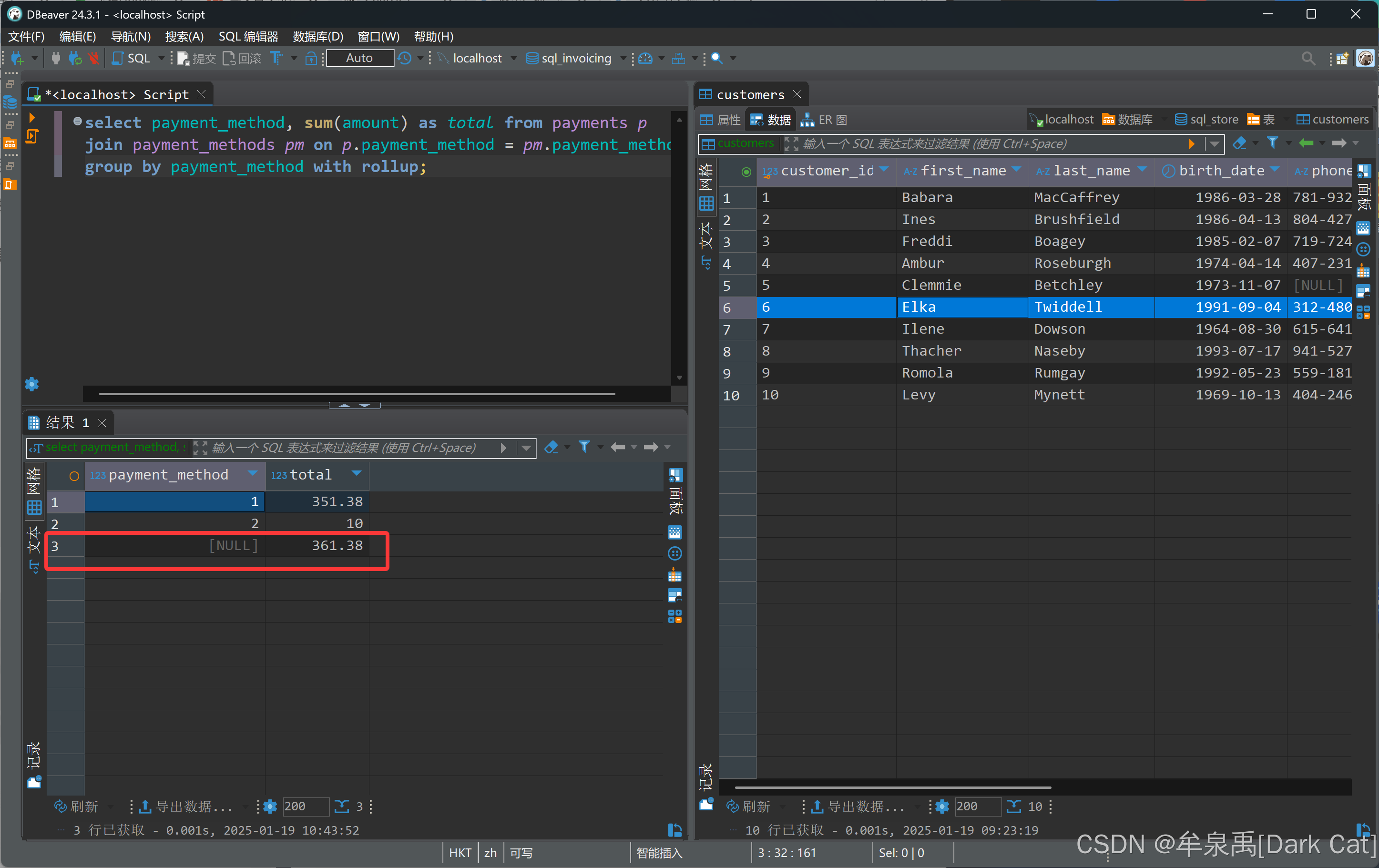
4.4 With RollUp 汇总子句(用来汇总较为方便)
with rollup:只能作用于 聚合函数的列,给你进行汇总。你查询之后就会发现多出来一行汇总数据。
select payment_method, sum(amount) as total from payments p
join payment_methods pm on p.payment_method = pm.payment_method_id
group by payment_method with rollup;
4.5 where 子查询
select * from products
where unit_price > ( # 该结果集正好是单行单列,所以可以这么写select unit_price from productswhere product_id = 3
)use sql_store;
select * from products where product_id
not in (select distinct product_id from order_items) # 正好是多行单列
如何选择使用 子查询还是联表查询,取决于三个:
- 是否更好的解决问题:而我们一般都把它放在首位!有些时候,我们可能用 联表查询解决问题会更好,而有些时候可能用子查询更好。极大可能是 个人习惯问题,就是写子查询比较多,可能就会选择先写子查询去解决问题。
- 可读性:如果两者解决问题都没啥差别,思路上都很好实现,那么此时就要考虑可读性。
- 执行速度:只有最后我们才会去考虑效率问题。而分析一条SQL 的效率,需要你去分析执行计划,慢慢地解读,才能知道它是否是高效的!
4.5 All、Any(Some) 关键字
如果你 where 子查询的时候,需要进行子查询所有结果的 一一比对,并且都符合。那么就得用 All 关键字。
select * from invoices
where invoice_total > all (select invoice_totalfrom invoiceswhere client_id = 3
)
# 这段 SQL 语句的作用是从 invoices 表中选择出那些 invoice_total 值大于特定条件下的所有其他 invoice_total 的记录。
如果你 where 子查询的时候,需要进行子查询所有结果的 一一比对,并且只要有一个复合。那么就得用 Any 或Some 关键字。
select * from invoices
where invoice_total > any (select invoice_totalfrom invoiceswhere client_id = 3
)select * from invoices
where invoice_total > some (select invoice_totalfrom invoiceswhere client_id = 3
)
4.6 关联子查询
即子查询里面,可以关联到 该 sql 语句中其它的表。
select * from
employees e
where salary > (select avg(salary)from employeeswhere office_id = e.office_id # 可以看到这里就用到了 上面的 e 表
)
4.7 Exists 运算符
exists 是用来检查是否存在某个表的。而 select 查询返回的结果集,其实就被视为一个表。
select * from clients c
where exists (select client_idfrom invoiceswhere client_id = c.client_id
)
# 这个子查询的结果集 是否存在,如果存在 则 满足条件,如果不存在则 不满足
4.8 Select 子查询
我们肯定会遇到这样的场景,那就是该字段是通过查询别的表查出来的。。
select invoice_id,invoice_total,(select avg(invoice_total) from invoices) as invoice_average,invoice_total - (select invoice_average) # 只有这样写我们才能直接使用子查询返回的字段
from invoices;
4.9 From 子查询
在 sql 中,select 查询返回的结果集其实也是一张表!所以可以把它当做表来使用!
select * from
(select client_id,name,(select sum(invoice_total)from invoiceswhere client_id = c.client_id) as total_sum,(select avg(invoice_total) from invoices) as total_avg,(select total_sales - average) as differencefrom clients c
) as sales_summary
第五章·增删改
5.1 关于字段
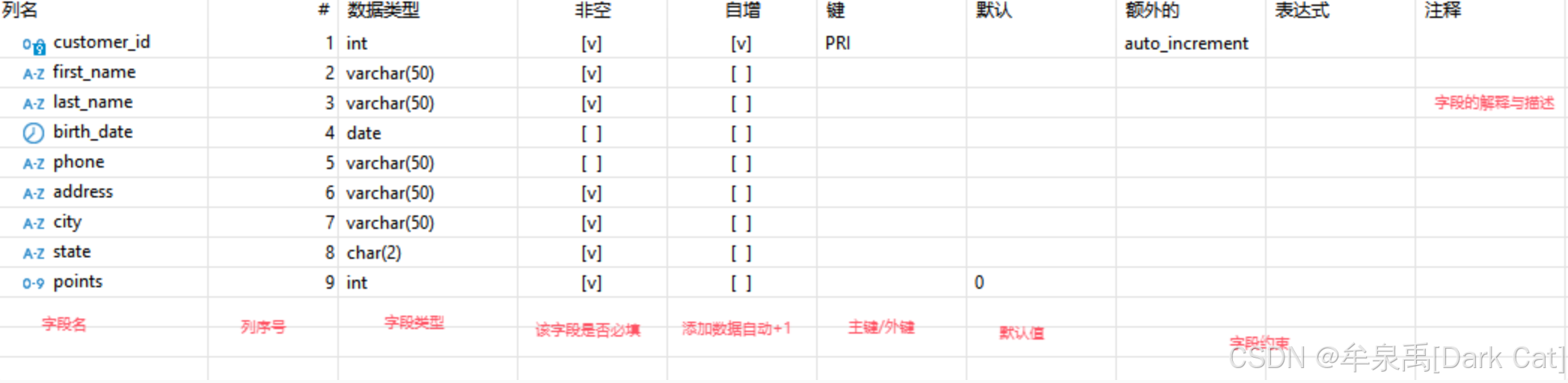
- 常用数据类型
数值类型
int:整数型
tinyint:常用于枚举值或布尔值
bigint unsigned:无符号大整数,常用于存储雪花ID,对应后端类型 long
decimal(10,2):长度10(包括小数点左边和右边),小数点右边最多2位。因此它是 从 -99999999.99 到 99999999.99。
float:单精度浮点数
double:双精度浮点数
字符串类型
varchar(50):可变字符串,最多50个字符,它会根据你存储的字符数,来决定数据大小。
char(2):固定存两个字符大小,你存储一个字符,它也是两个字符大小。(定长字符串,长度固定。)
text:存储大量文本,但查询和处理速度上可能不如char、varchar(常用于 文章、评论等需要存储大量文本的场景。)
日期时间类型
date:存储日期(年月日)YYYY-MM-DD
time:存储时间(小时分钟秒)HH:MM:SS
datetime:用于存储日期和时间的组合,通常表示某一特定的时刻。YYYY-MM-DD HH:MM:SS
范围: '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59'。
二进制类型
适用于存储二进制数据,如图像或文件。但查询和操作不如文本类型方便。所以现在几乎都是用url路径的方式存储文本,然后找到目标文件了。
BINARY(10):固定长度的二进制
VARBINARY(10):不固定长度的二进制
Blob:用来存储大量二进制数据的,最多 65,535 字节(约 64 KB)。
TINYBLOB: 最多 255 字节。
MEDIUMBLOB: 最多 16,777,215 字节(约 16 MB)。
LONGBLOB: 最多 4,294,967,295 字节(约 4 GB)。
特殊类型
JSON:JSON类型适用于存储结构化复杂的数据。比如存储用户的配置文件、产品的详细信息、订单详情等。但几乎不建议使用,或不见使用
ENUM:定义这个列只能存几个值。
CREATE TABLE clothing (size ENUM('small', 'medium', 'large', 'extra large')
);
# 此时排序是按照先后顺序
# 并且也可以根据 1 2 3 4 5 这样的序号 来进行增删改查,第一个位置的 枚举值就是 1
- 主键与外键
主键:一个表至少得有一个主键,来代表每一行数据!即,我只要知道了这个主键我就知道了这行数据。(每行数据的身份证)
主键是聚集索引,数据行存储在叶子节点中,这意味着数据行的物理顺序和主键值的顺序一致。所以这东西是可以提高效率的。
物理外键:在数据库层面上,表中与外界联系的字段,特别是 用其它表主键关联的时候,我们就应该赋予该字段外键。外键的目的是干扰你轻易的去增删改有关联的表数据。 也因为这个作用,加上它多了部分空间开销,现在都是不用物理外键,而是转而逻辑外键了。
逻辑外键:数据库层面上,不创建物理外键。但也创建了与外表关联的字段。而把控他们关系的外键,是在后端层面上,用代码逻辑去人为控制的。这大大提高了灵活性,并且减少了开销。
- 字段常见约束
# not null 不为空
CREATE TABLE Employees (EmployeeID INT NOT NULL,FirstName VARCHAR(50) NOT NULL,LastName VARCHAR(50) NOT NULL
);
ALTER TABLE Employees
MODIFY COLUMN FirstName VARCHAR(50) NOT NULL;# unique 不能存重复的值
CREATE TABLE Employees (EmployeeID INT NOT NULL UNIQUE,Email VARCHAR(100) UNIQUE
);
ALTER TABLE Employees
ADD CONSTRAINT unique_email UNIQUE (Email);# primary key 主键
CREATE TABLE Employees (EmployeeID INT NOT NULL PRIMARY KEY,FirstName VARCHAR(50),LastName VARCHAR(50)
);
ALTER TABLE Employees
ADD CONSTRAINT pk_employeeid PRIMARY KEY (EmployeeID);# auto_increment 自增
CREATE TABLE Employees (EmployeeID INT NOT NULL AUTO_INCREMENT PRIMARY KEY,FirstName VARCHAR(50),LastName VARCHAR(50)
);
ALTER TABLE Employees
MODIFY COLUMN EmployeeID INT NOT NULL AUTO_INCREMENT;# FOREIGN KEY 外键(不建议使用)
CREATE TABLE Departments (DepartmentID INT NOT NULL PRIMARY KEY,DepartmentName VARCHAR(100)
);CREATE TABLE Employees (EmployeeID INT NOT NULL PRIMARY KEY,DepartmentID INT,FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID)
);
ALTER TABLE Employees
ADD CONSTRAINT fk_department
FOREIGN KEY (DepartmentID) REFERENCES Departments(DepartmentID);# check 校验存值
CREATE TABLE Employees (EmployeeID INT NOT NULL PRIMARY KEY,Age INT CHECK (Age >= 18),Salary DECIMAL(10, 2) CHECK (Salary > 0)
);
ALTER TABLE Employees
ADD CONSTRAINT chk_age CHECK (Age >= 18);# check 可以使用 regexp 正则表达式
CREATE TABLE users (id INT PRIMARY KEY,email VARCHAR(255),CHECK (email REGEXP '[[:alnum:]]+@[[:alnum:]]+.[[:alnum:]]+')
);
ALTER TABLE users
ADD CONSTRAINT chk_email_format CHECK (email REGEXP '[[:alnum:]]+@[[:alnum:]]+\\.[[:alnum:]]+');# default 默认值
CREATE TABLE Employees (EmployeeID INT NOT NULL PRIMARY KEY,StartDate DATE DEFAULT CURRENT_DATE
);
ALTER TABLE Employees
MODIFY COLUMN StartDate DATE DEFAULT CURRENT_DATE;5.2 表复制
# 这种方式并不会标记主键和自增
create table orders_archived as select * from orders;
5.3 insert 插入(增)
- 插入单条
insert into customer values(default, 'John', 'Smith', '1990-01-01' ,null, 'address', 'city', 'CA', default); # 未指定是哪些字段,那么基本上就得全写
# default:在插入的时候 指的是 插入默认值
# null:插入 null# 指定了字段,特别是没有指定一些有默认值和可空的,还有自增的 字段,这些字段确实无需指定。
insert into customer(frist_name,last_name,birth_date,address,city,state
)
values ('John','Smith', '1990-01-01','address','city','CA'
)
- 插入多条(批量)
insert into shippers(name) values ('Shipper1'),
values ('Shipper2'),values ('Shipper3')
数据库引擎在处理批量操作时,可以对整个批次的数据进行优化。例如,在批量插入数据时,数据库可以更高效地分配资源,减少索引更新的频率,或者将多个插入操作合并为一个大的写操作。这样一来,数据库就能更高效地利用内存和CPU资源。
- 多层插入
借助 last_insert_id() 函数,就可以办到。只不过这种逻辑,我们都是放在后端去写!
insert into orders(customer_id, order_date, status) values (1, '2019-01-02', 1);select last_insert_id(); # 查询出最后一次插入的id是啥
insert into order_items values (last_insert_id(), 1,1,2.95),
(last_insert_id(), 1,1,2.95)
- 子查询方式插入(即 insert 可以接收一个结果集)
insert into orders_archived
select * from orders where order_date < '2019-01-01'
5.4 update 更新(改)
- 更新单行
update invoices set payment_total = 10, payment_date = '2019-003-01' where invoice_id = 1
# 我们可以更新为 default、null
update invoices set payment_total = default, payment_date = '2019-003-01' where invoice_id = 1
- 更新多行
update invoices
set payment_total = invoice_total * 0.5,payment_date = due_date
where client_id in (3, 4) # 主要其实就是条件上的筛选,可以筛选出多个!这里我就用 in 举例子了 ~
- 子查询更新
update invoices
setpayment_total = invoice_total * 0.5,payment_date = due_date
where client_id in
(select client_id from clients where name = 'MyWorks')update invoices
setpayment_total = invoice_total * 0.5,payment_date = due_date
where client_id in
(select client_id from clients where state in ('CA', 'NY'))
5.5 delete 删除
- 单行删除
delete from invoices where invoice_id = 1;
- 多行删除
delete from invoices where invoice_id in (1,2,3);
- 子查询删除(支持结果集)
DELETE FROM Employees
WHERE EmployeeID IN (SELECT EmployeeID FROM AnotherTable WHERE SomeCondition);DELETE Employees
FROM Employees
JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID
WHERE Departments.DepartmentName = 'Sales';
依照结果集删除的 秘诀:就是你先正常写查询,查询出来你要删除的 结果集,然后 把 select 直接改为 delete 就完事了~
第六章·内置函数
6.1 数值函数
select round(5.73) # 四舍五入
select round(5.73, 1) # 只保留一位小数的 四舍五入
select ceiling(5.7) # 返回大于等于这个数的最小整数
select floor(5.2) # 返回小于等于这个数的最大整数
select abs(-5.2) # 绝对值
select rand() # 查询会生成一个 0.0 到 1.0 之间的随机数
select rand() * 100 # 查询会生成一个 0.0 到 100.0 之间的随机数
select floor(rand() * 100); # 查询会生成一个 0 到 99 之间的随机整数
6.2 字符串函数
select upper("shy") # 转大写
select lower("Sky") # 转小写
select ltrim(" 2222") # 把左空全部删掉
select rtrim(" 2222") # 把右空全部删掉
select trim(" 111 ") # 把所有空格删掉
select left("123456", 2) # 前两个字符
select right("45466", 2) # 后两个字符
select substring("123456123456789", 3, 5) # 取位点3开始的五个字符
select locate('q', 'qqqqqq12313') # 会返回找到的第一个位置
select locate('fq', 'qqqfqqq12313') # 会返回找到的第一个位置
select replace("fqfqfqfq12", "fq", 'wc'); # 替换字符串
select concat("fist", "-" , "last");
select char_length("fist"); # 查询字符串长度
6.3 日期函数
select now(), curdate(), curtime(); # 查询当前的 datetime、date、time
select year(now()) # 获取年部分
# 同理 => month() day() 等等
select dayname(now()) # 返回英文的星期几
select monthname(now()) # 返回英文的月份
select extract(year from now()) # 根据你指定的 单位获取年
select extract(day from now()) # 根据你指定的 单位获取现在是本月几号select date_format(now(), '%M2%d2%Y') # 返回 月份2几号2年份
select date_format(now(), '%H:%i %p') # 返回类似于 12:58 PMselect date_add(now(), interval 1 day)
select date_add(now(), interval 1 year)
select date_add(now(), interval -1 month)
select date_sub(now(), interval 1 month)select datediff('2019-01-05', '2019-01-01') # 减法,但只返回天数间隔select time_to_sec('09:00'); # 返回从 0 点计算的秒数
select time_to_sec("09:00") - time_to_sec("09:02")
6.4 IfNull、Coalesce
ifnull,当为空的时候 用一个值替代。case...when 与 is null 搭配的简写方式
use sql_store;select order_id,ifnull(shipper_id, 'not assigned') as shipper
from orders;
coalesce,一堆匹配值,只要有 一个不为空,就匹配到。然后不再继续往下匹配。用的极少
use sql_store;select order_id,coalesce(shipper_id, comments ,'not assigned') as shipper
from orders;
6.5 case…when、if
case…when 在前面修饰字段那里讲到过,也用到过,不做重复讲解。
select order_id,order_date,if(year(order_date) = year(now()),'Active', # 条件成立返回的值'Archived'# 条件不成立返回的值) as category
from orders;
第七章·视图、存储过程、函数、触发器、事件
无论是视图、存储过程还是函数,这都是可以直接优化 系统性能的大杀器。因为主动的关注于 数据库层,而减少后端逻辑的过多使用,就肯定能在一定程度上,提高性能。
7.1 视图
视图:把查询的SQL保存起来,称之为视图。当你下次再想查的时候,就可以直接查视图了。
- 简化查询写法
- 可以轻松复用该查询结果集
use sql_invoicing;create view sales_by_client as
select c.client_id,c.name,sum(invoice_total) as total_sale
from clients c
join invoices i using (client_id)
group by client_id, nameselect * from sales_by_client order by total_sales desc;
# 上面这个 sql 就相当于下面这样
select * from (select c.client_id,c.name,sum(invoice_total) as total_salefrom clients cjoin invoices i using (client_id)group by client_id, name
) order by total_sales desc;
- 删除视图
drop view sales_by_client
- 更改视图
create or replace view sales_by_client as
select c.client_id,c.name,sum(invoice_total) as total_sale
from clients c
join invoices i using (client_id)
group by client_id, name
- update、delete 视图
由于 视图仅仅是 保存了 SQL 查询语句,所以 update、delete 视图的时候,改变的就都是 真实的表内容了。
# 有时候我们也希望 update 与 delete 别作用于 视图。。
# 此时你可以加一条 语句
create or replace view sales_by_client as
select c.client_id,c.name,sum(invoice_total) as total_sale
from clients c
join invoices i using (client_id)
group by client_id, name
with check option # 就是这条语句
7.2 存储过程
在系统的后期阶段,基本不会太大变动后。我们往往会考虑使用存储过程,视图,函数等来用所谓的专注于数据库层,来简单粗暴的对性能进行优化。
-
减少网络流量:存储过程在数据库端执行,可以减少服务器与数据库的数据传输,不必多次发送复杂的 SQL。从而降低网络开销。
-
预编译与缓存:存储过程是预编译的,并且数据库系统会将执行计划缓存起来,这意味着它甚至可能比动态SQL快,尤其是频繁调用的情况下。
-
集中数据操作,复杂业务逻辑集中到存储过程后,整体架构分层会更加清晰。更好维护。(前提是,不更换数据库的情况下。。)
-
存储过程可以增加安全性,敏感操作可以集中在数据库端,而不暴露在程序代码中。
-
存储过程也肯定是跨平台、跨语言的、、存储过程对统一事务管理这方面也嘎嘎滴好,没的说。
delimiter $$ # 存储过程分隔符是 $$
delimiter // # 存储过程分隔符是 //
create procedure get_clients()
begin # {select * from clients;
end$$ # }delimiter ; # 把默认的分隔符改回来call get_clients(); # 执行或调用 get_clients 存储过程drop procedure if exists get_clients # 删除 get_clients 这个存储过程
- 带有参数的 存储过程
delimiter $$
create procedure get_client_by_state (state char(2)
)
begin select * from clients cwhere c.state = state;
end $$
delimiter ;call get_client_by_state('CA');delimiter $$
create procedure `get_invoices_by_client`(client_id int
)
beginselect * from invoices i where client_id = i.client_id
end$$
delimiter ;
- 带有默认值的参数
delimiter $$
create procedure get_clients_by_state
(state char(2)
)
beginif state is null thenset state = 'CA';end if;select * from clients cwhere c.state = state;
end$$
delimiter ;call get_clients_by_state(null);create procedure get_clients_by_state
(state char(2)
)
begin if state is null thenselect * from clients;else select * from clients cwhere c.state =state;end if;
end $$create procedure get_clients_by_state
(state char(2)
)
begin select * from clients cwhere c.state = ifnull(state, c.state);
end $$
- 参数验证(也就是我们得用一些判断语句去拦截)
温馨提示:这种拦截,其实更加建议你写到 后端逻辑里,而不是写到这里。。
create procedure make_payment
(invoice_id int,payment_amount decimal(9, 2),payment_date date
)
beginif payment_amount <= 0 thensignal sqlstate '22003'set message_text = '错误信息';end if;update invoices iset i.payment_total = payment_amount,i.payment_date = payment_datewhere i.invoice_id = invoice_id;
end;
- 输出参数
create procedure get_unpaid_invoices_for_client
(client_id int,out invoices_count int,out invoices_total decimal(9, 2)
)
begin select count(1), sum(invoice_total)into invoices_count, invoices_total from invoices iwhere i.client_id = client_idand payment_total = 0;
end $$set @invoices_count = 0; # 定义变量,别忘了加前缀 @
set @invoices_total = 0;
call sql_invoicing.get_unpaid_invoices_for_client(3, @invoices_count, @invoices_total)
select @invoices_count, @invoices_total;
- 存储过程中定义变量
create procedure get_risk_factor ()
begin declare risk_factor decimal(9, 2) default 0;declare invoices_total decimal(9, 2);declare invoices_count int;select count(1), sum(invoice_total)into invoices_count, invoices_totalfrom invoices;set risk_fator = invoices_total / invoices_count * 5;select risk_fator;
end $$
set:给变量进行赋值
into:查询中给变量赋值
declare:定义一个变量
7.3 函数
函数是可以返回值的,存储过程只能通过 参数外传来拿到返回的值。
create function get_risk_factor_for_client
(client_id int
)
returns integer # 返回什么类型
deterministic # 缓存机制,意思是说 只要你提供我一样的参数我就给你返回上次一样的值,无论表的内容变不变。
reads sql data # 只读数据不写
modifies sql data # 改权限
beginreturn 1;
end;
create function get_risk_factor_for_client
(client_id int
)
returns integer # 返回什么类型
reads sql data # 只读数据不写
begindeclare risk_factor decimal(9, 2) default 0;declare invoices_total decimal(9, 2);declare invoices_count int;select count(1), sum(invoice_total)into invoices_count, invoices_totalfrom invoices;set risk_fator = invoices_total / invoices_count * 5;return risk_fator;
end;
7.4 触发器
触发器的加入,使得你的 数据库就可以编写业务。
- 新增触发器
delimiter $$
create trigger payments_after_insert
after insert on payments
for each row # 作用于每一个受影响的行,比如说我们噶一下子插入五行,每一行都会触发这个触发器
beginupdate invoicesset payment_total = payment_total + new.amountwhere invoice_id = new.invoice_id;
end $$delimiter ;
- 查看触发器
show triggers;
show triggers like 'payments%'
- 删除触发器
drop trigger if exists payments_after_insert;
- 触发器可以写审计记录
审计:是一种系统性和独立的检查和评估活动,其目标是提高组织的治理、风险管理和控制流程的有效性。 所以,对于审计来说,最重要的前提就是记录关键信息。
delimiter $$
create trigger payments_after_insert
after insert on payments
for each row # 作用于每一个受影响的行,比如说我们噶一下子插入五行,每一行都会触发这个触发器
beginupdate invoicesset payment_total = payment_total + new.amountwhere invoice_id = new.invoice_id;# 在数据库中做审计,那你就得有个审计表,然后往里插数据了insert into payments_auditvalues (new.client_id, new.date, new.amnount, 'insert', now());
end $$delimiter ;
7.5 事件
事件是根据计划执行一堆SQL代码。比如说每天早上十点,你给我去做什么什么事。
show variables; # 展示所有变量
show variables like 'events%'; # 确保 event_scheduler 是开启的
set global event_scheduler = ON; # 开启事件调度器
delimiter $$create event yearly_delete_stale_audit_rows
on schedule
-- at '2019-05-01' ## 某一天执行一次
every 1 year starts '2019-01-01' ends '2029-01-01' # 一年执行一次,且从 2019-01-01 开始这个事件,一直到 2029-01-01 结束这个事件
do begindelete from payments_auditwhere action_date < now() - interval 1 year # 对于时间上的 常量,前面必须有 interval 作为标识
end $$
delimiter ;show events; # 查看所有事件
show event if exists yearly_delete_stale_audit_rows # 删除事件※ 第八章·事务与权限管理
事务是代表单个工作单元的一组 SQL 语句,而这些语句都应该成功完成,如果有一点儿失败,那么事务的运行就会失败。事务就会采取回滚策略。把这些SQL语句的操作全部撤销~
工作单元例子:比如你生成订单了,然后就要去减少相关商品的库存数量。此时这俩操作其实就是属于一个工作单元的。
而事务则是希望我们这些操作作为一个 “单元” 一起的成功或失败,只能是这俩种情况!
- 原子性(单元):表示无论多少语句,它都是一个整体,即一个单元。具有所谓的原子性。然后 这个单元要么成功要么失败,也就是我们把它当做一个单元来看待。
- 一致性:它指的是,通过使用事务,我们可以保证事务失败、成功、之前、之后数据都是一致的状态。之前什么样就是什么样。失败后就应该是事务之前的摸样。而成功后也应该是该单元执行后的摸样。
- 隔离性:意味着事务之间是相互隔离的,它们互不干扰,各自执行自己的单元。而当多个事务对同样数据进行影响的时候,它会采取行锁措施,给这个行加锁,等我处理完了,其它事务再去处理。
- 持久性:事务的更改,一旦生效,就是相对永久的。只要你的硬盘不坏,它就一直保持这个更改结果到永远。
ACID(酸性,事务这东西是挺酸性的 ~):数据库事务四大特性
8.1 异常
在MySQL中,有几种常见的异常类型:
SQLEXCEPTION:表示任何SQL错误或异常。常见的SQL错误包括数据类型不匹配、违反唯一性约束、外键约束失败等。SQLWARNING:表示SQL警告。这通常是非致命性错误,比如一些非关键的警告信息。NOT FOUND:通常用于游标操作中,表示未找到符合条件的行。
MySQL提供了DECLARE ... HANDLER语句来声明异常处理程序。根据异常类型,可以分别定义不同的处理程序。语法如下:
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN-- 发生错误时,回滚事务ROLLBACK;
END;
- 记录日志
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN-- 发生错误时,回滚事务ROLLBACK;-- 下面就会抛出这个错误信息, 并且记录到日志里signal sqlstate '45000' set message_text = '错误的内容';
END;
- 捕获到异常但继续执行 SQL
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGINset @warning_caught = true;END;
8.2 事务的简单使用
use sql_store;# 一般你手动事务的话,就都是一个存储过程、函数之类的
delimiter //
create procedure InsertOrder()
begin declare exit handler for sqlexceptionbegin rollback;end;-- 开始事务start transaction;insert into orders(customer_id, order_date, status)
values (1, '2019-01-01', 1);insert into order_items values (last_insert_id(), 1, 1, 1);-- 提交事务commit;
end //
delimiter ;
只要使用 START TRANSACTION,MySQL就会在该事务的上下文中直接关闭自动提交,直到你执行 COMMIT 或 ROLLBACK。
也就是说,我们不需要写 SET autocommit = 0;
8.3 并发和锁
在现实世界中,会存在两个及更多的用户同时访问相同数据的情况。
我们称之为 并发
而并发问题:通常指的是,当一个用户修改其它用户正在检索或修改的数据时,可能会出现各种错误的问题。
脏读:读取一个尚未提交的更改数据,即你读取的并不是最终的正确版本。
不可重复读:在同一个事务当中,多次读取同一行数据,但读取的结果却不同。而我们可能只需要之前的那个数据去辅助我们完成当前单元的任务。
幻读:在同一个事务当中,多次查询结果集可能会多了几行或少了几行。
丢失更新:两个事务都基于读取出来的同一个数据,去进行相应的处理更新,这可能会导致另一个事务的更新被覆盖(丢失)。
写偏差:我在读取可靠信息,决定是否可以写新数据的时候,可能会有偏差。比如 第一个事务觉得可以写,而第二个事务也觉得可以写,一下子就添加两个新数据。。但实际上只能写一个。。
死锁:事务A占用着资源B的锁并等待着事务B释放掉资源A的锁。而此时事务B占用着资源A的锁,等待着事务A释放掉资源B的锁。互相等待 ~ 导致了死锁。。
资源饥饿:某些事务总是会被抢占锁的拥有权,自己一直在等待着别人释放锁给它用。。
ABA问题:是经典乐观锁机制会出现的问题,乐观锁只会比较一个变量的值是否符合预期值,如果符合,就会操作。但在并发的情况下,很有可能有一个线程将它的值进行了 ABA 的更改,即我改了这个值,但我又改回去了。欸~ 改到了你预期的值,也就乐观锁认为这次操作没有冲突,实际上是有冲突的。。而为了解决ABA问题,乐观锁会在这个基础上,给每个数据都加一个版本号,一旦有人介入尝试操作它,那么版本号就会更新值,而我们每次检验的时候,也都要携带这个版本号去进行校验。
# 如果下面的操作,你不开启事务去执行,那么就会触发 并发问题
# 而我们现在大多数情况下,使用数据库,都会开启自动提交的事务管理
use sql_store;
start transaction;
update customers
set points = points + 10
where customer_id = 1;
commit;
自动提交的事务管理,我们也称之为 数据库的并发兜底。
8.4 事务隔离级别
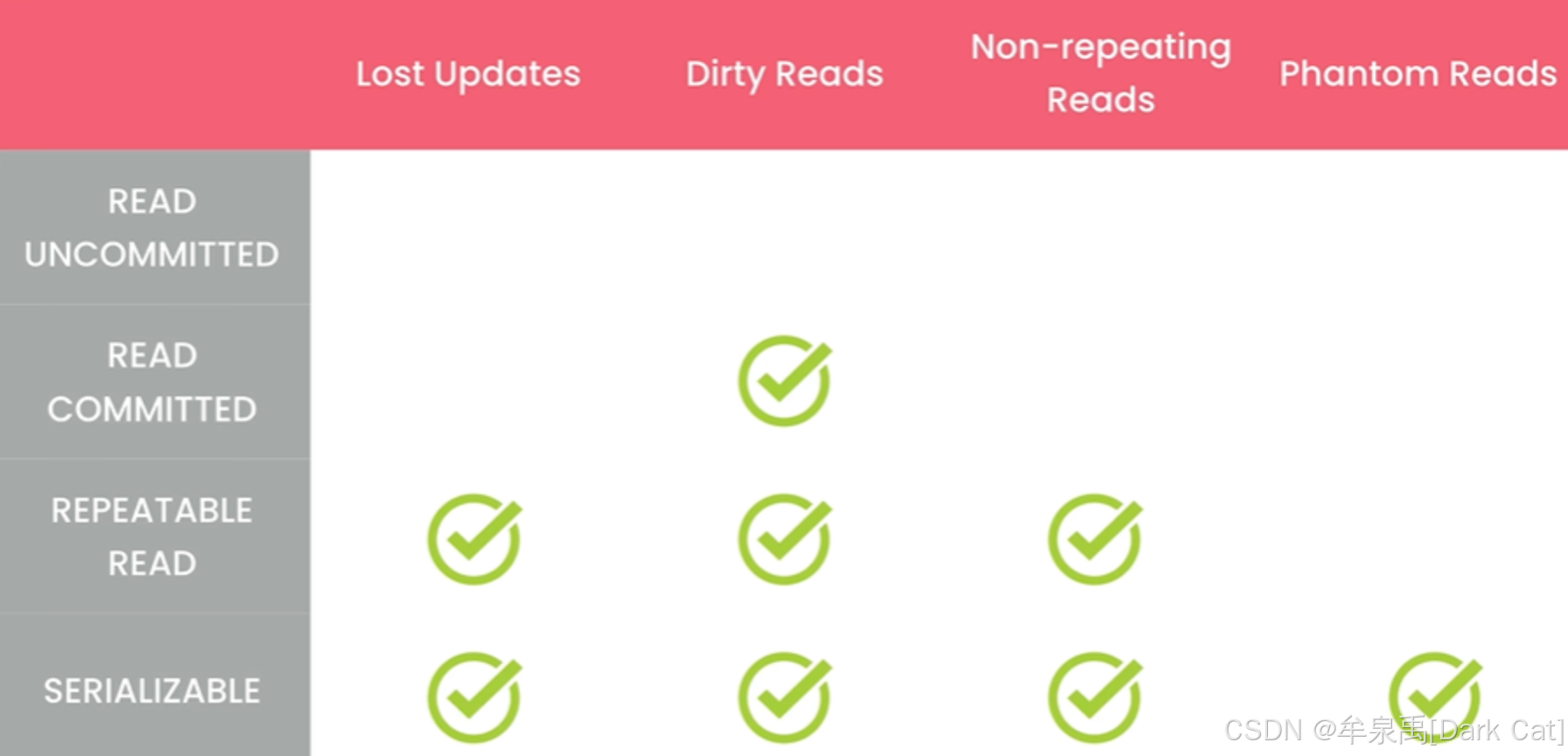
级别越高,肯定越安全。但是也需要更多的资源,而且也会限制我们高并发的性能。
在 MySQL 中,默认的事务隔离级别是可重复读取。它仅仅是没有防御幻读,所以我们只需要在后端写代码的时候,避免幻读即可。
show variables like 'transaction_isolation'; # 查看当前事务隔离级别set session transaction isolation level serializable; # 当前回话这个级别set global transaction isolation level serializable; # 所有回话,全局的
8.5 死锁简单展示
- A 用户
use sql_store;start transaction;
update customers set state = 'VA' where customer_id = 1;
update orders set status = 1 where order_id = 1;
commit;
- B 用户
use sql_store;start transaction;
update orders set status = 1 where order_id = 1;
update customers set state = 'VA' where customer_id = 1;
commit;
A 用户:当执行 customer_id = 1 那个 update 的时候,事务会使用行锁。锁住该行。
B 用户:当执行 order_id= 1 那个 update 的时候,事务会使用行锁。锁住该行。
A 用户:order_id = 1 被上锁了,所以我得 等待。
B 用户:customer_id = 1 被上锁额,所以我得 等待。
这是因为,只有事务结束了之后,锁才会被释放。。所以很轻松的就造成了 死锁。
- 解决方案:统一资源的访问顺序,无论是 A 用户,还是 B 用户 都是下面的顺序。
use sql_store;start transaction;
update customers set state = 'VA' where customer_id = 1;
update orders set status = 1 where order_id = 1;
commit;
- 更细粒度的锁
START TRANSACTION;
-- 显式地为需要更新的行加锁
SELECT * FROM customers WHERE customer_id = 1 FOR UPDATE;
SELECT * FROM orders WHERE order_id = 1 FOR UPDATE;
UPDATE customers SET state = 'VA' WHERE customer_id = 1;
UPDATE orders SET status = 1 WHERE order_id = 1;
COMMIT;
8.6 关于用户
正常来说,一个 后端 程序员的数据库账户,应该只有 读和写业务表的权限。而不能有其它权限。所以创建 一个合适的 用户,是至关重要的!
- 创建用户和连接权限
create user john@127.0.0.1 # 只能本机连接
create user john@locahost # 只能本机连接
create user john@'codewithmosh.com' # 只能是这个 codewithmosh.com 主域名可以连接
create user john@'%.codewithmosh.com' # 任何这个域的任何计算机或任何子网域都可以连接
create user john # 可以让任何计算机连接create user john identified by '123123' # 创建了一个可以让任何计算机连接的用户, 密码是 123123
- 删除、查询
select * from mysql.user; # 这样就可以很轻松的查到所有用户
drop user john@127.0.0.1; # 删除用户
- 修改密码
set password for john = '1234';
8.7 关于授权
- 授权
create user moon_app@127.0.0.1 identified by '1234';grant select, insert, update, delete, execute
on sql_store.*
to moon_app@127.0.0.1;
create user mqy@127.0.0.1 identified by '1234';
grant all on *.*
to mqy@127.0.0.1; # 这个一般都是管理员
- 查看权利
show grants for john; # 这一下子就可以 查看 john 的权限
show grants; # 查询当前用户的 权限
- 撤掉权限
remove create view
on sql_store.* from moon_app; # 撤销 create view
※第九章·索引
在大型数据库和高流量网站中,索引非常重要!因为它们可以显著的提高查询性能。
索引是数据库引擎用来快速查找数据的数据结构。
假设你想找到 加利福尼亚的顾客,如果没有索引,那么 MySQL 必须扫描顾客表中所有的记录,是否有 state = ‘CA’ ??对于几百、几千条的小型表肯定是没啥太大问题。但是呢,如果数据量一大,那可就不是那么快了 ~
此时我们可以在 state 这个列上,创建索引来加快查询。它会创建一个索引树。里面会存储一对多关系的结构作为元素。[数据:数据的相关引用]
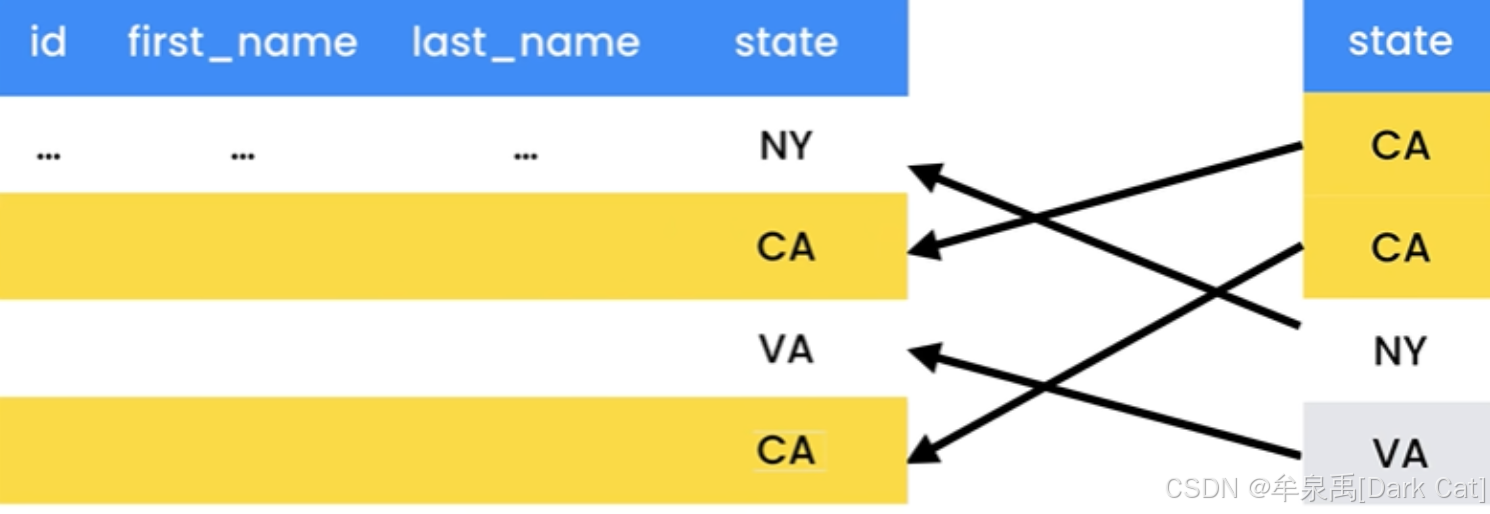
这样,我们就可以 O(1) 去查询数据了。
而在大多数情况下,索引相对数据库来说都是较小的,所以会被放到内存中。这也是间接性的又加强了查询 速度。
索引缺点:
- 增加数据库的大小,因为它们必须永久存储在表的附近。典型的空间换时间
- 每次增删改的时候,我们都需要额外的去更新一下索引。否则肯定会影响到 查询。
所以,我们一般都是把索引加在比较核心重要的查询表中,对应的条件列。
即 => 基于查询来创建索引
通常存储索引的数据结构,用的是二叉树。而抽象展示的时候,习惯展示为一个表。
9.1 创建索引
explain select customer_id from customers where state = 'UA'
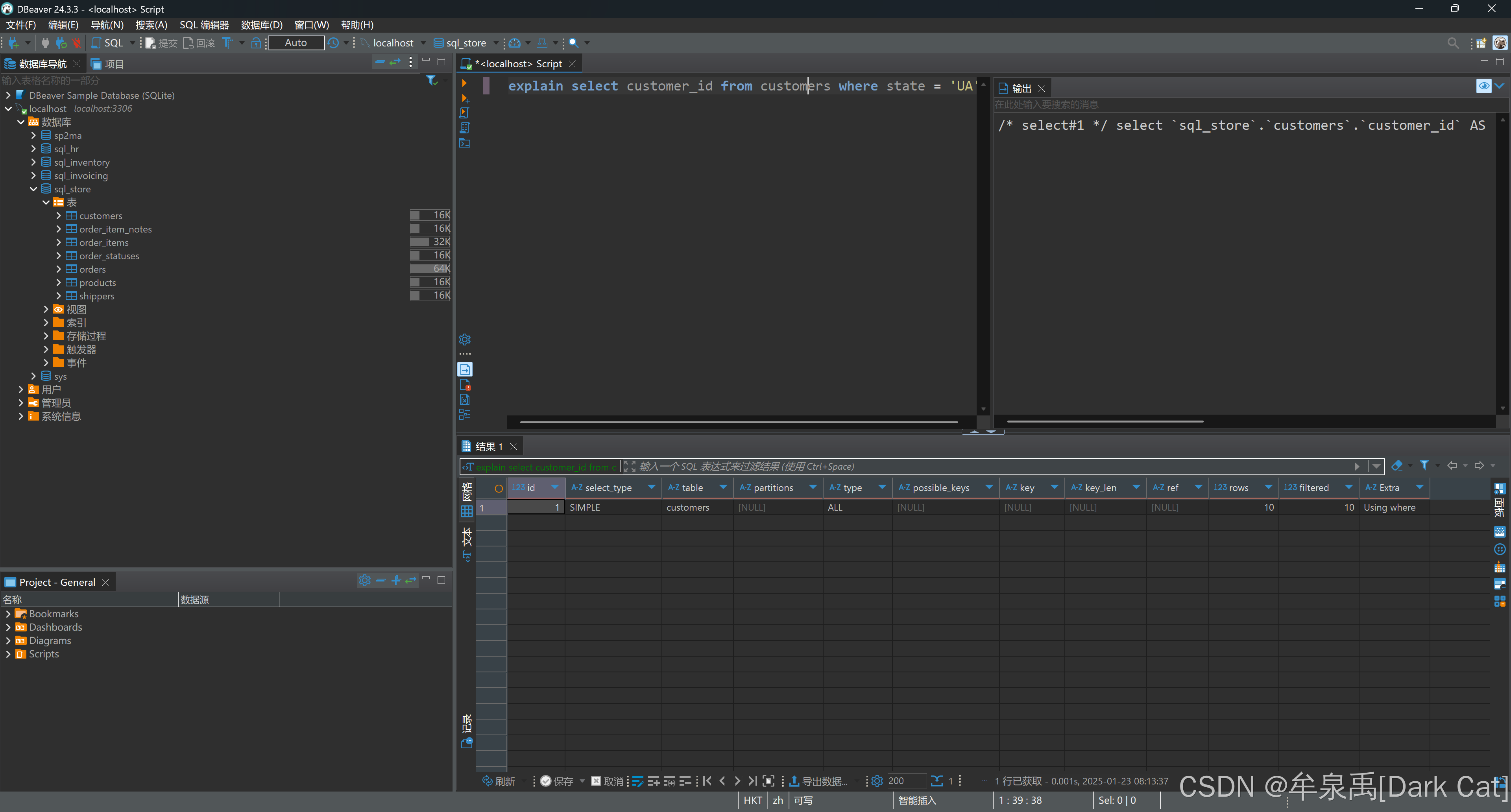
- type:类型(All 就是全表扫描了 ~)
- rows:去操作的行数
create index idx_state on customers (state);
explain select customer_id from customers where state = 'UA'

- ref:这个类型的意思是我们通过 引用的方式 扫描的
-- Write a query to find customers with more than 1000 points
create index idx_points on customers (points);explain select customer_id from customers where points > 1000;
9.2 查看索引
show indexes in customers;
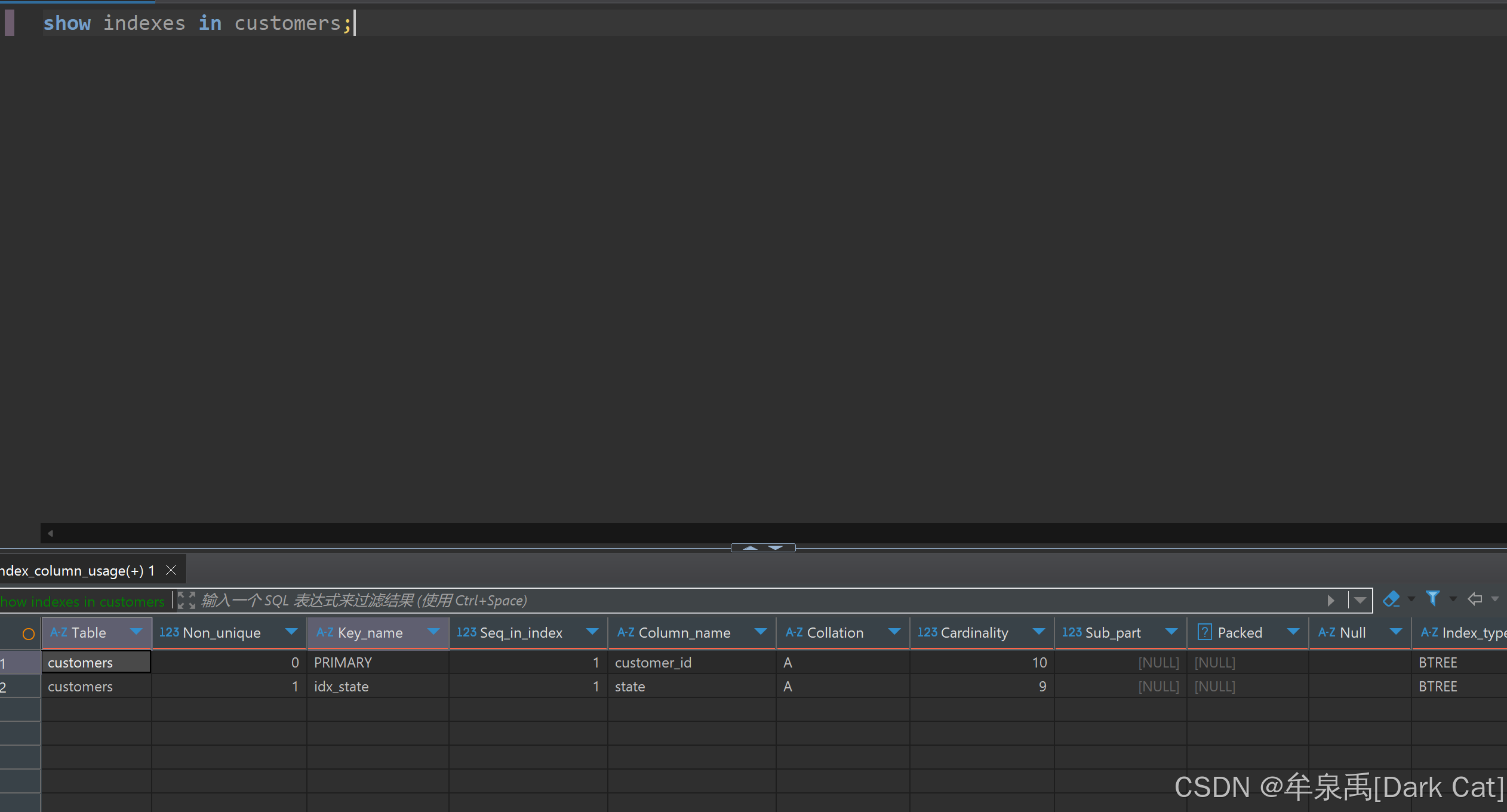
PRIMARY:聚合索引(每张表最多只能有一个)
Collation:A 代表升序
Cardinality:索引中唯一值的估计数量(在你没有执行 analyze table customers 之前就是估计量)
除了主键之外,其它的索引我们又称之为 二级索引
每当我们创建二级索引的时候,MySQL 都会自动的把主键的那个列纳入到二级索引中。
比如说 idx_state,它的那个 key 就是 id 与 state 一起的
9.3 前缀索引
当我们想要在字符串列上创建索引的时候。我们肯定要避免索引占用空间太大的问题 ,且也能达到很好的索引效果。此时其实你就可以考虑使用 前缀索引!
即,我们通过截取一部分字符串,来作为 key,相当于把表通过这种 key 引用的方式拆分为了多个小表,而这个表就是引用表。这样就可以提高 我们的速度。
# 一个比较好的技巧,来决定比较好的 前缀数目
selectcount(distinct left(last_name, 1)),count(distinct left(last_name, 5)),count(distinct left(last_name, 10))
from customers;

这就很明显了, 我们取 前缀 5,就可以保证不重复的唯一值可以高达 10个,这样的话,我们对应的 引用表就可以小一些,项可以少一些。也就是查询会更快。
create index idx_lastname on customers(last_name(5)) # 所以 5 个就行了
9.4 全文索引
全文索引,是专门用来制作快速灵活的搜索引擎的。
use sql_blog;
select *
from posts
where title like '%react redux%' or
body like '%react redux%';
# 这样的搜索,显然不是很好,因为太不灵活
全文索引会包括整个字符串列,而不只是存储前缀。它们会忽略任何停止词,对于每个单词,它们又存储了一列这些单词会出现的行或记录。
create fulltext index idx_title_body on posts(title, body);select *, match(title, body) against('react redux') as realationScore
from posts
where match(title, body) against('react redux');
- 布尔模式
match … against 的默认模式是 自然模式,就是自然匹配。而还有一个模式是布尔模式,它可以排除一些字符串和必须得有一些字符串然后进行搜索。
select *, match(title, body) against('react redux') as realationScore
from posts
where match(title, body) against('react -redux +from' in boolean mode);
# -字符串 意思是说必须没有这个字符串
# +字符串 意思是说必须得有这个字符串
9.5 复合索引
当我们查询是多条件的时候,其实最好 用 复合索引。
create index idx_state_points on customers(state, points);
drop index if exists idx_state on customers;
drop index if exists idx_points on customers;
复合索引在使用中,会探讨一个问题。那就是列的顺序。
-
第一准则:建议是 当大多数查询用到的列,排在前面 ,而用的少的列排在后面、这样也可以 加快我们整体 应用的查询效率。 -
第二准则:列的唯一值的数量如果比较大,那么就排在前面。因为这个列更好索引。
select count(distinct state),count(distinct last_name)
from customer;create index idx_lastname_state on customers (last_name, state);
create index idx_state_lastname on customers (state, last_name);explain select customer_id
from customers
use index (idx_lastname_state) # 该查询使用 idx_lastname_state 索引
where state = 'NY' and last_name like 'A%';explain select customer_id
from customers
use index (idx_state_lastname) # 该查询使用 idx_state_lastname 索引
where state = 'NY' and last_name like 'A%';
需要注意的是,复合索引只能作用在多条件上面。而 不能作用在单个条件上。所以此时你就得新建一个 普通索引。
create index idx_lastname customers(last_name)
explain select customer_id
from customers
use index (idx_lastname) # 该查询使用 idx_lastname 索引
where last_name like 'A%';
9.6 索引丢失问题
or 条件可能会导致索引无法有效的使用!下面我们来举几个场景:
- 单列索引 与 or 条件
SELECT * FROM my_table WHERE column1 = 'value1' OR column2 = 'value2';
如果column1和column2分别有单独的索引,MySQL可能无法同时利用这两个索引。MySQL可能会选择使用其中一个索引,或者在某些情况下可能直接进行全表扫描。
- 复合索引与 or 条件
SELECT * FROM my_table WHERE column1 = 'value1' OR column3 = 'value3';
假设你有一个复合索引 (column1, column2),但查询中用到的是column3,那么这个复合索引对OR条件下的查询帮助不大。
- 解决 or 导致的索引失效问题
使用 union代替 or,进行联合即可
SELECT * FROM my_table WHERE column1 = 'value1'
UNION
SELECT * FROM my_table WHERE column2 = 'value2';
优化索引设计:如果你经常在多个列上使用OR条件,可以考虑创建一个包含这些列的复合索引,但这种方法需要确保查询的实际使用模式能够充分利用复合索引。
9.7 索引可以改善排序
索引其实也可以改善排序查询的速度。让排序不再是 外部排序。
explain select customer_id from customers order by first_name;
show status like 'last_query_cost'; # 上次查询的用时
explain select customer_id from customers order by state;
9.8 覆盖索引的概念
覆盖索引:指的是 select 索引的列时,MySQL 是会直接利用索引去找的,然后返回给你。而不是普通的扫描。
explain select customer_id, state from customers order by state;show status like 'last_query_cost';
9.9 维护索引的建议
索引是典型的 空间换时间,所以一定要斟酌的去创建索引。
- 在经常用于查询条件的字段上创建索引
- 由于不推荐物理外键,所以应该手动在表与表的关联列上创建索引
- 在总是排序的字段上,创建索引
- 模糊查询字符串,需要创建前缀索引
- 重复索引和多余索引,自己要测一测和检查,然后删掉。
※ 第十章·数据库设计思想
10.1 三大模型
- 尽可能的了解客户需求、涉及到业务的领域内容和知识
- 根据获得到的 信息,去构建比较充实的概念模型
- 然后我们要把这些概念模型联系起来,构建逻辑模型
- 最后我们精确到属性的类型、是否可空、多大 等等等 构建 实体类型
这里比较推荐 DbFirst 方式 ,实体类型直接映射到数据库里面变成一张张的表。
- 概念模型:简单来说,就是这个程序,众多业务中,都有哪些角色?它们都是谁?它们主要是干嘛的?你得理清楚。它们之间都有什么关系。
展现形式:一个图表,里面写着角色的名字,还有基本的一些重要信息(属性)。然后与其它关联的角色画一根线进行连接,并且标注是因为什么事联系在一起的。
从图上看,概念模型只是让我知道了业务实体都有哪些,然后它们都有啥关系。
- 逻辑模型:每个模型的属性都要明确类型。并且把逻辑展现出来,这可能就会伴随中间表的出现了。
这里,我们会发现,登记这个东西,从逻辑上来说应该细化为一个表。也就是登记表。我得知道学生什么时候买的什么课程。也就是把概念模型中一些动作,化为了逻辑模型。
- 实体模型:它可以是数据库里面的每一张表,也可以是 后端代码中的每一个 实体类。是完全抽象化在代码层面的。
其最明显的特征就是各个模型之间属性描述、约束更加的细化,各个表之间会有关联列出现。中间表也是必须的。
10.2 公共列
- id:主键 id,代表行数据的唯一标识,是一个聚合主键。
- create_time:创建该条数据的日期时间
- update_time:更改该条数据的日期时间
- is_deleted:伪删除标识 [0 未删除 1 删除]
- operator:操作人的 id
`id` bigint primary key unsigned NOT NULL COMMENT '雪花 id',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP '创建时间',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更改时间',
`is_deleted` tinyint DEFAULT '0' COMMENT '0 未删除 1 删除',
`operator` bigint unsigned DEFAULT NULL COMMENT '操作人 id',
10.3 三大范式
数据库设计的三大范式(Normal Forms)是用来优化数据库结构,减少数据冗余、提高数据一致性的一些规则。它们依次为第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。让我用一个简单的例子来通俗易懂地解释这三大范式。
1. 第一范式(1NF):消除重复的列,确保每个字段的原子性
定义: 数据库表中的每一列都必须是不可分割的原子值,也就是说,每个字段只能存储一个值。
例子: 假设你有一个学生表,记录学生的名字、电话和选修的课程。
不符合1NF的表:
| 学生ID | 姓名 | 电话 | 选修课程 |
|---|---|---|---|
| 1 | 张三 | 123456, 789012 | 数学, 英语 |
| 2 | 李四 | 987654 | 物理, 化学, 生物 |
符合1NF的表:
| 学生ID | 姓名 | 电话 | 选修课程 |
|---|---|---|---|
| 1 | 张三 | 123456 | 数学 |
| 1 | 张三 | 789012 | 英语 |
| 2 | 李四 | 987654 | 物理 |
| 2 | 李四 | 987654 | 化学 |
| 2 | 李四 | 987654 | 生物 |
现在,每个字段中只有一个值,符合第一范式。
其实电话字段,如果是有多个电话,那就得弄个 电话表了。
2. 第二范式(2NF):消除部分依赖
定义: 在符合1NF的基础上,确保每个非主键字段都完全依赖于主键,消除部分依赖。简单来说,表中的每一列都必须依赖于整个主键,而不是主键的一部分。
例子: 假设你有一个课程表,记录了学生ID、课程名和老师姓名。
不符合2NF的表:
| 学生ID | 课程名 | 老师姓名 |
|---|---|---|
| 1 | 数学 | 王老师 |
| 1 | 英语 | 李老师 |
| 2 | 数学 | 王老师 |
| 2 | 化学 | 张老师 |
在这个表中,“老师姓名”字段只依赖于“课程名”而不是“学生ID”,这是部分依赖,不符合2NF。
符合2NF的表: 可以将表拆分为两个表:
学生-课程表:
| 学生ID | 课程名 |
|---|---|
| 1 | 数学 |
| 1 | 英语 |
| 2 | 数学 |
| 2 | 化学 |
课程-老师表:
| 课程名 | 老师姓名 |
|---|---|
| 数学 | 王老师 |
| 英语 | 李老师 |
| 化学 | 张老师 |
这样,每个非主键字段完全依赖于主键,符合第二范式。
3. 第三范式(3NF):消除传递依赖
定义: 在符合2NF的基础上,确保每个非主键字段都直接依赖于主键,而不是通过另一个非主键字段间接依赖于主键。
例子: 假设你有一个学生信息表,记录了学生ID、姓名、班级和班主任姓名。
不符合3NF的表:
| 学生ID | 姓名 | 班级 | 班主任姓名 |
|---|---|---|---|
| 1 | 张三 | 一班 | 李老师 |
| 2 | 李四 | 二班 | 王老师 |
在这个表中,“班主任姓名”依赖于“班级”,“班级”又依赖于“学生ID”,这是传递依赖,不符合3NF。
符合3NF的表: 可以将表拆分为两个表:
学生信息表:
| 学生ID | 姓名 | 班级 |
|---|---|---|
| 1 | 张三 | 一班 |
| 2 | 李四 | 二班 |
班级-班主任表:
| 班级 | 班主任姓名 |
|---|---|
| 一班 | 李老师 |
| 二班 | 王老师 |
这样,每个非主键字段直接依赖于主键,符合第三范式。
总结:
- 1NF:确保每列都是原子值,不可分割。
- 2NF:消除部分依赖,确保每个非主键字段完全依赖于整个主键。
- 3NF:消除传递依赖,确保每个非主键字段直接依赖于主键。
这三大范式的目标是减少冗余数据,提高数据一致性,同时保持良好的性能。在实际应用中,设计数据库时会综合考虑性能和规范化的平衡,不一定严格遵循所有范式。
10.4 中间表
在数据库设计中,中间表(也称为桥表或连接表)扮演着非常重要的角色,特别是在处理多对多(many-to-many)关系时。中间表通过将多对多的关系拆分成两个一对多的关系,从而有效地组织和管理数据。
中间表的作用
- 实现多对多关系:
- 关系数据库不直接支持多对多关系。因此,通过使用中间表,可以将多对多的关系拆分为两个一对多的关系。
- 中间表通常包含两个外键字段,分别指向两个相关表的主键。
- 维护数据完整性:
- 中间表可以帮助维持数据的一致性和完整性,确保多对多关系中的数据不会产生冗余或不一致的情况。
- 添加额外的关联信息:
- 中间表不仅可以存储两个表之间的关联,还可以存储与该关联相关的额外信息。例如,在一个订单和产品的多对多关系中,中间表可以存储每个产品在订单中的数量。
中间表的例子
- 多对多关系的例子:学生与课程
假设你有一个学生表 (students) 和一个课程表 (courses),一个学生可以选修多门课程,而一门课程也可以有多个学生选修。这就是一个典型的多对多关系。
students表:
| student_id | name |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
courses表:
| course_id | course_name |
|---|---|
| 101 | 数学 |
| 102 | 英语 |
为了表示学生和课程之间的多对多关系,我们引入一个中间表 student_courses:
student_courses表(中间表):
| student_id | course_id |
|---|---|
| 1 | 101 |
| 1 | 102 |
| 2 | 101 |
在这个中间表中,每一行表示一个学生和一门课程之间的关联。通过这种方式,我们有效地表示了多对多的关系。
- 中间表存储附加信息的例子:订单与产品
假设你有一个订单表 (orders) 和一个产品表 (products),一个订单可以包含多个产品,而一个产品也可以出现在多个订单中。这也是一个多对多关系。
orders表:
| order_id | order_date |
|---|---|
| 1 | 2024-08-01 |
| 2 | 2024-08-02 |
products表:
| product_id | product_name |
|---|---|
| 201 | 手机 |
| 202 | 笔记本 |
为了解决多对多关系并且记录每个产品在订单中的数量,我们使用一个中间表 order_products:
order_products表(中间表):
| order_id | product_id | quantity |
|---|---|---|
| 1 | 201 | 2 |
| 1 | 202 | 1 |
| 2 | 201 | 3 |
在这个中间表中,每一行不仅表示一个订单与一个产品的关联,还记录了该产品在订单中的数量。这使得我们能够非常灵活地处理订单和产品的关系。
总结
中间表在数据库设计中具有重要作用,特别是在表示和管理多对多关系时。通过使用中间表,不仅可以有效地组织数据,确保数据完整性,还可以在表之间的关系中存储额外的信息,使数据模型更加灵活和强大。
10.5 创建表
create database if not exists sql_store character set utf8mb4 collate utf8mb4_general_ci; # 创建数据create table customers (# 字段名 类型 主键 自增customer_id int primary key auto_increment, first_name varchar(50) not null, # 非空points int not null default 0, # 默认值email varchar(255) not null unique, # 唯一性order_id int,foreign key fk_customers_orders (order_id)references orders (order_id) # 外键# 级联关系如下 => on update cascade # 当该表更新的时候,orders 表对应的记录也会更新on delete no action # 当该表删除该行的时候,orders 表不会删除该行。如果是 on delete cascade 那么该表这行删掉了,那么对应order_id 一样的 orders 表里面,就全跟着删掉。
) engine=innodb default charset=utf8mb4;
# InnoDB 是支持事务的,并且是 MySQL 默认的存储引擎。# 更改主键和外键
alter table customers drop primary key, # 因为主键就一个add primary key (customer_id)drop foreign key fk_customers_ordersadd foreign key fk_customers_orders(customer_id) references customers(customer_id)on update cascadeon delete no action;
10.6 修改表和删除表
alter table customers
add last_name varchar(50) not null after first_name; # 在 first_nae 后面加上 字段 last_namealter table customers
modify column first_name varchar(55) default '', # 修改字段的一些属性alter table customers
change first_name new_first_name varchar(55) default ''; # 修改表的名字alter table customers
drop points; # 删除字段
一般情况下,我们都不会在项目的部署环境(生产环境)去改变表的结构。
10.7 字符集、排序规则和存储引擎
排序规则
utf8mb4_unicode_ci: 基于 Unicode 的通用排序规则,可以处理多种语言,包括中文。它会按照 Unicode 的标准顺序对汉字进行排序,这种排序规则是大小写不敏感的(ci 表示 case-insensitive)。
utf8mb4_general_ci: 一般排序规则,适用于大多数语言,但对于中文的排序可能不是完全准确。
utf8mb4_zh_cn_ci: 这是 MySQL 5.7 及更高版本中提供的中文排序规则。它按照汉语拼音排序,因此更适合用于处理中文数据。
utf8mb4_zh_0900_as_ci: MySQL 8.0 中引入的排序规则,基于最新的 Unicode 版本,更加准确地处理中文排序和比较,支持拼音排序。as 表示区分大小写(accent-sensitive),ci 表示不区分大小写。
show charset; # 查看所有字符集
charset database db_name character set utf8; # 这个是最常用的字符集
alter table customers engine = innodb; # 更换为 innodb
alter table customers engine = myisam; # 更换为 myisam
第十一章·窗口函数
首先,我们要熟悉 窗口函数的格式:
function(args) over([partition by expression] [order by expression [assc|desc] [frame]])
# partition by 是决定用哪个字段 来进行分组的,然后在每个分组里面去做事
11.1 排序函数
- row_number:序号不重复,序号连续 (1 2 3)
- rank:序号可以重复,序号不连续(1 2 2 4)
- dense_rank:序号可以重复,序号连续(1 2 2 3)
rank() over(order by xx desc) # 这样写就是没有分组而进行了排序- LeetCode - 178 题
select score,dense_rank() over(order by score desc) as rank from Scores;
- leetCode - 184 题
select tempTable.dName as Department, tempTable.eName as Employee , tempTable.salary as Salary from (select d.name as dName, e.name as eName, e.salary ,rank() over(partition by d.name order by e.salary desc) as `rank` from Employee e join Department d on e.departmentId = d.id) tempTable where `rank` = 1;
11.2 [frame] 滑动窗口—— 聚合范围
ROWS:指定物理行的范围。通常用来明确指定前后多少行。
rows between 2 preceding and current row; # 前两行到当前行,也就是三行
rows between unbounded preceding and current row; # 从开始到当前行
rows between current row and 2 following; # 从当前行到之后的 N 行
rows between unbounded preceding and unbounded following # 从头到尾
如果不写这个 [frame] 那就是开始行到当前行。
RANGE:指定逻辑范围,通常根据排序列的值来定义。
select product, year_month, gmv,
avg(gmv) over(partition by departent, product order by year_month rows 2 preceding) as avg_gmv from product;
11.3 lag、lead 函数
lead(字段,n):返回当前行的后n行里面的某个字段
lag(字段,n):返回当前行的前n行里面的某个字段
总是应用在当前行需要前几行和后几行数据的场景下。
比如说我们算 gmv 环比增长绿:
环比(Ring growth)即与上期的数量作比较。
select product, year_month, gmv, lag(gmv, 1) over(partition by department, product order by year_month) as lag_gmv, cast(gmv as double) / lag(gmv,1) over(partition by department, product order by year_month) -1 as growth_rate
from product;
11.4 分布函数
-
percent_rank():它是公式
(分组内当前行的 rank 值 - 1)/(分组内总行数 - 1) -
cume_dist():它是公式
(小于等于当前值的行数)/(分组内总行数)
所以这俩函数就是用来计算百分比的。
11.5 Ntile(n) 桶
ntile(n):是会将你排序的数据,进行分n个桶。谁是哪个桶的,会给你标记桶号。
如果你提供的桶数目过多,它没分完,也无所谓。
select product, ntile(10) over (order by sales desc) as ntile_rank from sku_sales;






:从 60Hz 到 120Hz,多刷新率进化简史)
)





)


)
在浏览器中解析视频)
|(链表篇)02.07. 链表相交(疑点))
