
本教程的知识点为:爬虫概要 爬虫基础 爬虫概述 知识点: 1. 爬虫的概念 requests模块 requests模块 知识点: 1. requests模块介绍 1.1 requests模块的作用: 数据提取概要 数据提取概述 知识点 1. 响应内容的分类 知识点:了解 响应内容的分类 Selenium概要 selenium的介绍 知识点: 1. selenium运行效果展示 1.1 chrome浏览器的运行效果 Selenium概要 selenium的其它使用方法 知识点: 1. selenium标签页的切换 知识点:掌握 selenium控制标签页的切换 反爬与反反爬 常见的反爬手段和解决思路 学习目标 1 服务器反爬的原因 2 服务器常反什么样的爬虫 反爬与反反爬 验证码处理 学习目标 1.图片验证码 2.图片识别引擎 反爬与反反爬 JS的解析 学习目标: 1 确定js的位置 1.1 观察按钮的绑定js事件 Mongodb数据库 介绍 内容 mongodb文档 mongodb的简单使用 Mongodb数据库 介绍 内容 mongodb文档 mongodb的聚合操作 Mongodb数据库 介绍 内容 mongodb文档 mongodb和python交互 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的入门使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy管道的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy中间件的使用 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy_redis原理分析并实现断点续爬以及分布式爬虫 scrapy爬虫框架 介绍 内容 scrapy官方文档 scrapy的日志信息与配置 利用appium抓取app中的信息 介绍 内容 appium环境安装 学习目标
完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/爬虫/爬虫开发从0到1全知识教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:
Mongodb数据库
介绍
在前面的中我们学习了mysql这种关系型数据库,那么接下来,我们会来学习一种非关系型数据库mongodb,mongodb数据库主要用于海量存储,常被用在数据采集项目中。
内容
- mongodb的介绍和安装
- mongodb的简单使用
- mongodb的增删改查
- mongodb的聚合操作
- mongodb的索引操作
- mongodb的权限管理
- mongodb和python交互(pymongo模块)
mongodb文档
[
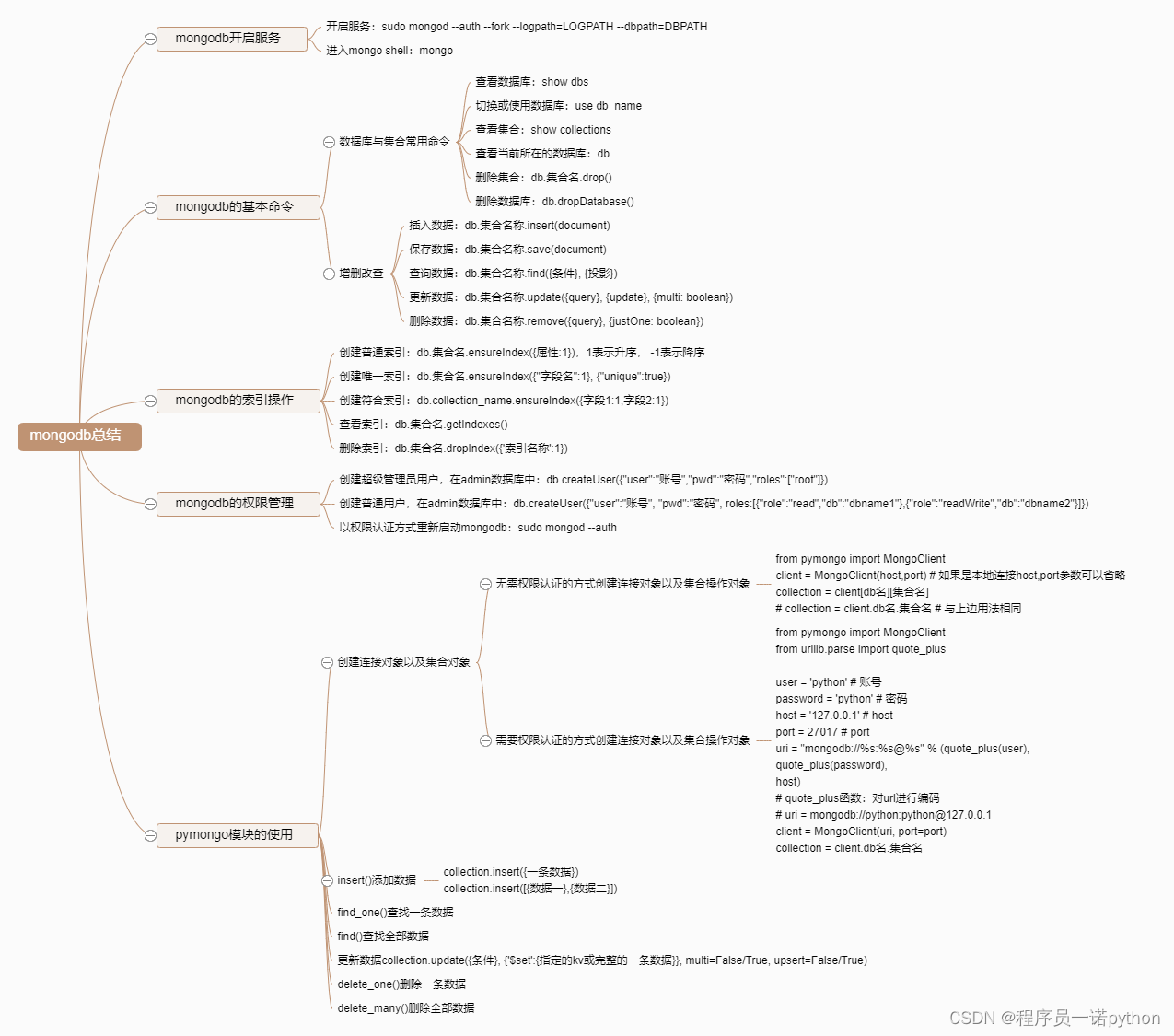
mongodb和python交互
学习目标
- 掌握 mongdb和python交互的增删改查的方法
- 掌握 权限认证的方式使用pymongo模块
1. mongdb和python交互的模块
pymongo 提供了mongdb和python交互的所有方法 安装方式: pip install pymongo
2. 使用pymongo
2.1 导入pymongo并选择要操作的集合
数据库和集合能够自动创建
2.1.1 无需权限认证的方式创建连接对象以及集合操作对象
from pymongo import MongoClientclient = MongoClient(host,port) # 如果是本地连接host,port参数可以省略collection = client[db名][集合名]# collection = client.db名.集合名 # 与上边用法相同
2.1.2 需要权限认证的方式创建连接对象以及集合操作对象
from pymongo import MongoClient
from urllib.parse import quote_plususer = 'python' # 账号
password = 'python' # 密码
host = '127.0.0.1' # host
port = 27017 # port
uri = "mongodb://%s:%s@%s" % (quote_plus(user),quote_plus(password),host)# quote_plus函数:对url进行编码# uri = mongodb://python:python@127.0.0.1client = MongoClient(uri, port=port)
collection = client.db名.集合名
2.2 insert()添加数据
insert可以批量的插入数据列表,也可以插入一条数据
collection.insert({一条数据})
collection.insert([{数据一},{数据二}])
2.2.1 添加一条数据
返回插入数据的_id
ret = collection.insert({"name":"test10010","age":33})
print(ret)
2.2.2 添加多条数据
返回ObjectId对象构成的列表
item_list = [{"name":"test1000{}".format(i)} for i in range(10)]
rets = collection.insert(item_list)
print(rets)
for ret in rets:print(ret)
2.3 find_one()查找一条数据
接收一个字典形式的条件,返回字典形式的整条数据 如果条件为空,则返回第一条
ret = client.test.test.find_one({'name': 'test10001'})
print(ret) # 包含mongodb的ObjectId对象的字典
_ = ret.pop('_id') # 清除mongodb的ObjectId对象的k,v
print(ret)
2.4 find()查找全部数据
返回所有满足条件的结果,如果条件为空,则返回全部 结果是一个Cursor游标对象,是一个可迭代对象,可以类似读文件的指针,但是只能够进行一次读取
rets = collection.find({"name":"test10005"}),
for ret in rets:print(ret)
for ret in rets: #此时rets中没有内容print(ret)
2.5 update()更新数据(全文档覆盖或指定键值,更新一条或多条)
- 语法:collection.update({条件}, {'$set':{指定的kv或完整的一条数据}}, multi=False/True, upsert=False/True)
- multi参数:默认为False,表示更新一条; multi=True则更新多条; multi参数必须和$set一起使用
- upsert参数:默认为False; upsert=True则先查询是否存在,存在则更新;不存在就插入
- $set表示指定字段进行更新
2.5.1 更新一条数据;全文档覆盖;存在就更新,不存在就插入
data = {'msg':'这是一条完整的数据1','name':'哈哈'}
client.test.test.update({'haha': 'heihei'}, {'$set':data}, upsert=True)
2.5.2 更新多条数据;全文档覆盖;存在就更新,不存在就插入
data = {'msg':'这是一条完整的数据2','name':'哈哈'} # 该完整数据是先查询后获取的
client.test.test.update({}, {'$set':data}, multi=True, upsert=True)
2.5.3 更新一条数据;指定键值;存在就更新,不存在就插入
data = {'msg':'指定只更新msg___1'}
client.test.test.update({}, {'$set':data}, upsert=True)
2.5.4 更新多条数据;指定键值;存在就更新,不存在就插入
data = {'msg':'指定只更新msg___2'}
client.test.test.update({}, {'$set':data}, multi=True, upsert=True)
2.6 delete_one()删除一条数据
collection.delete_one({"name":"test10010"})
2.7 delete_many()删除全部数据
collection.delete_many({"name":"test10010"})
3. pymongo模块其他api
查看pymongo官方文档或源代码 [
小结
- 掌握pymongo的增删改查的使用
- 掌握权限认证的方式使用pymongo模块
scrapy爬虫框架
介绍
我们知道常用的流程web框架有django、flask,那么接下来,我们会来学习一个全世界范围最流行的爬虫框架scrapy
内容
- scrapy的概念作用和工作流程
- scrapy的入门使用
- scrapy构造并发送请求
- scrapy模拟登陆
- scrapy管道的使用
- scrapy中间件的使用
- scrapy_redis概念作用和流程
- scrapy_redis原理分析并实现断点续爬以及分布式爬虫
- scrapy_splash组件的使用
- scrapy的日志信息与配置
- scrapyd部署scrapy项目
scrapy官方文档
[
scrapy的概念和流程
学习目标:
- 了解 scrapy的概念
- 了解 scrapy框架的作用
- 掌握 scrapy框架的运行流程
- 掌握 scrapy中每个模块的作用
1. scrapy的概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了Twisted['twɪstɪd]异步网络框架,可以加快我们的下载速度。
Scrapy文档地址:[
2. scrapy框架的作用
少量的代码,就能够快速的抓取
3. scrapy的工作流程
3.1 回顾之前的爬虫流程
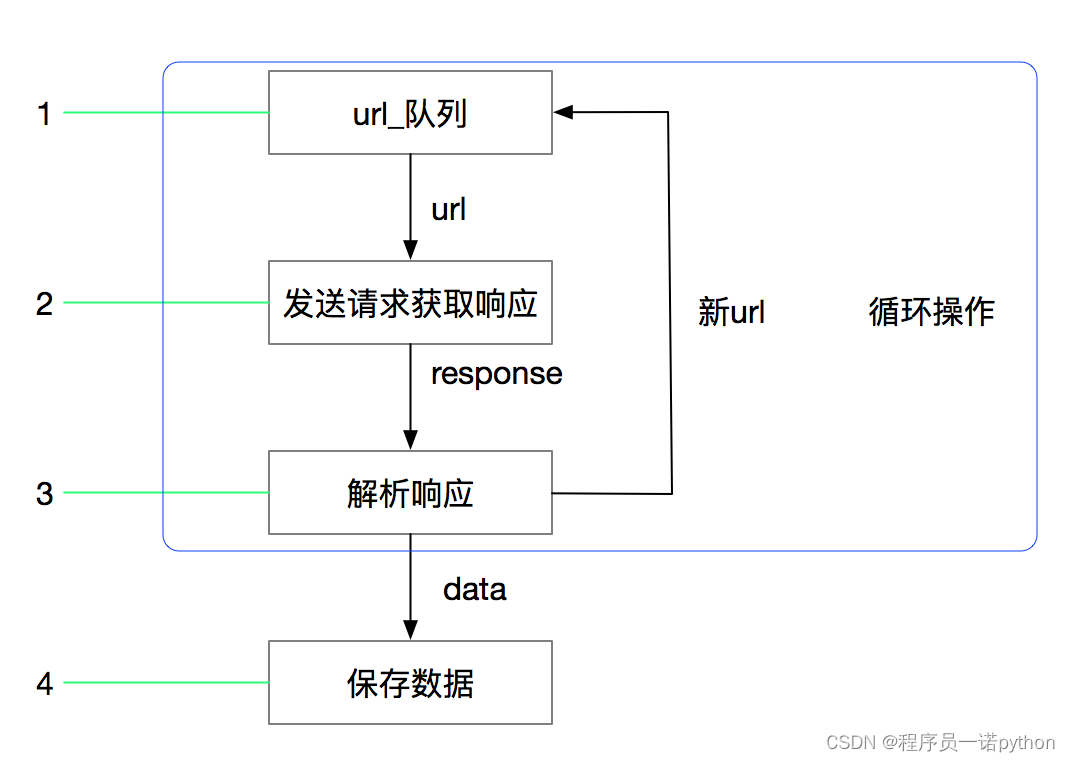
3.2 上面的流程可以改写为
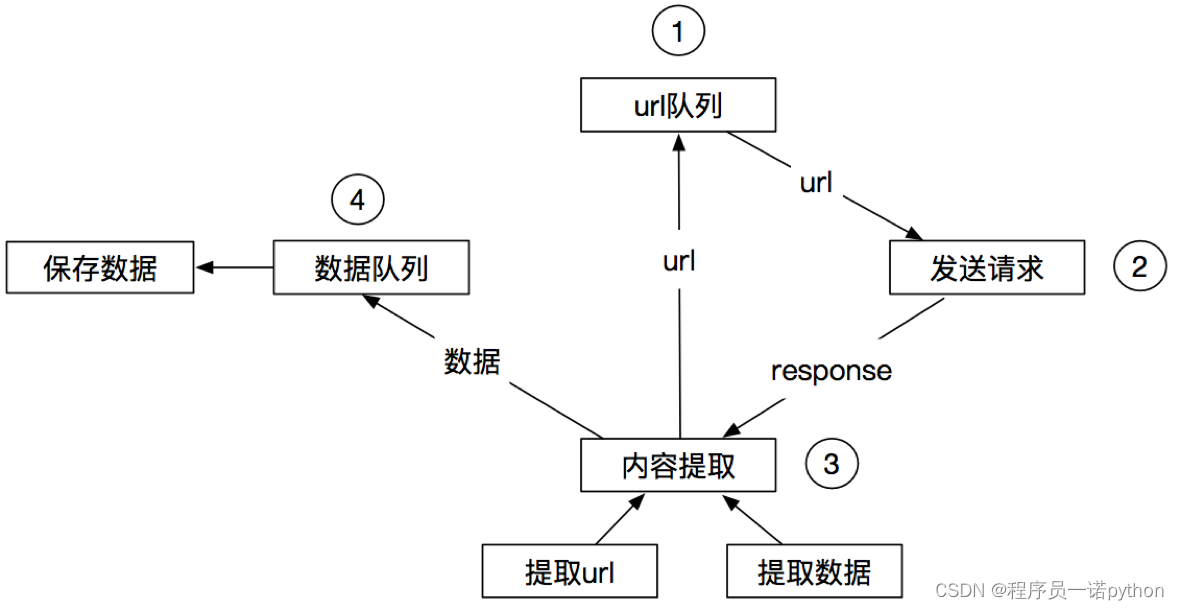
3.3 scrapy的流程
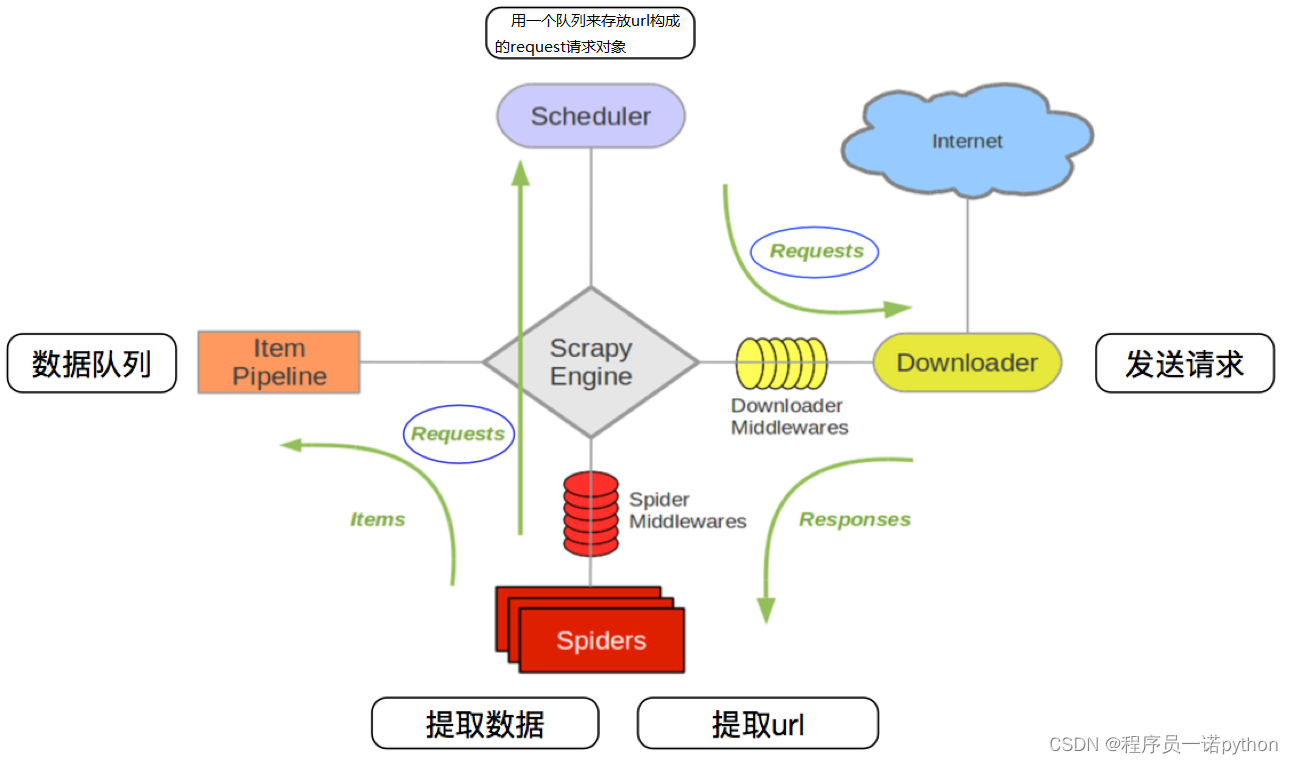
其流程可以描述如下:
- 爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
- 调度器把request-->引擎-->下载中间件--->下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器,重复步骤2
- 爬虫提取数据--->引擎--->管道处理和保存数据
注意:
- 图中中文是为了方便理解后加上去的
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
3.4 scrapy的三个内置对象
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
3.5 scrapy中每个模块的具体作用
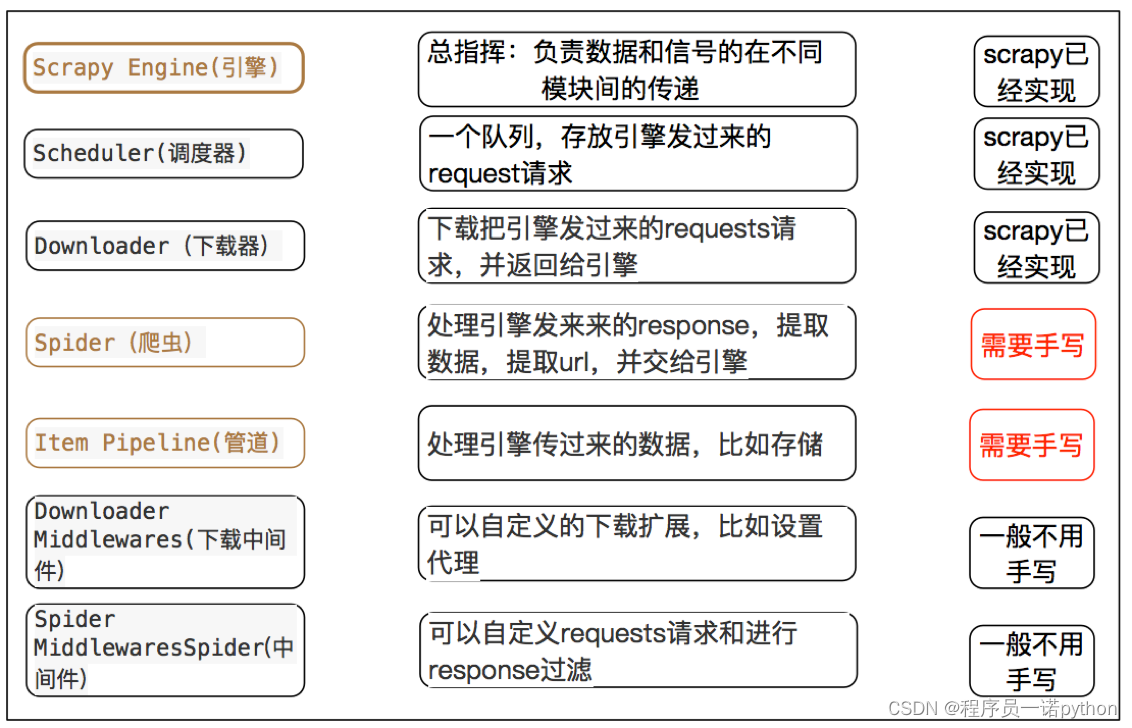
注意:
- 爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等
小结
- scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
-
scrapy框架的运行流程以及数据传递过程:
-
爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
- 调度器把request-->引擎-->下载中间件--->下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器,重复步骤2
-
爬虫提取数据--->引擎--->管道处理和保存数据
-
scrapy框架的作用:通过少量代码实现快速抓取
- 掌握scrapy中每个模块的作用: 引擎(engine):负责数据和信号在不腰痛模块间的传递 调度器(scheduler):实现一个队列,存放引擎发过来的request请求对象 下载器(downloader):发送引擎发过来的request请求,获取响应,并将响应交给引擎 爬虫(spider):处理引擎发过来的response,提取数据,提取url,并交给引擎 管道(pipeline):处理引擎传递过来的数据,比如存储 下载中间件(downloader middleware):可以自定义的下载扩展,比如设置ip 爬虫中间件(spider middleware):可以自定义request请求和进行response过滤,与下载中间件作用重复
)

)




![[Unity]Unity跨平台开发之Android入门](http://pic.xiahunao.cn/[Unity]Unity跨平台开发之Android入门)
Linux(Ubuntu) 中配置静态IP(包含解决每次重启后配置文件失效问题))

的应用)








