引言
2023 年,科技圈的“顶流”莫过于大模型。自 ChatGPT 的问世拉开大模型与生成式 AI 产业的发展序幕后,国内大模型快速跟进,已完成从技术到产品、再到商业的阶段跨越,并深入垂直行业领域。
新技术的爆发,催生新的应用场景与产品模式,撬动影响全行业的智能化变革。滚滚趋势下,作为从业者、创业者,将面对怎样的机遇和挑战,又该如何破局迎来 AGI 新时代?
近日,「大模型时代的机遇与挑战」腾讯云 TVP AI 创变研讨会在上海腾云大厦举行,特邀 AI 领域顶级大咖,围绕大模型热点话题进行深度分享与研讨,共同探索大模型时代的未来风向。
大模型——技术、价值、生态

IDEA 研究院认知计算与自然语言研究中心讲席科学家、腾讯云 TVP 张家兴老师,带来《大模型——技术、价值、生态》主题分享。
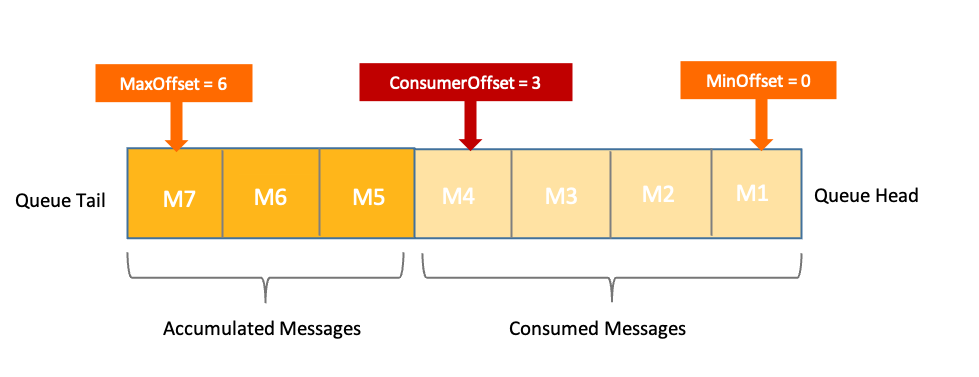
谈及 GPT 大模型诞生的历程,张家兴老师从十余年在深度学习领域的资深研究经验出发,用模型结构、训练技术、算力+系统和数据四条主线来阐述整个技术发展的背后趋势,并重点分享了几个关键节点:
- 模型结构创新:深度学习的兴起推动了模型结构的创新,其中 Transformer 结构起到了关键作用。它突破了模型 1 亿参数的瓶颈,统一了各种注意力机制的尝试方法,也解决了任务设计的难题;
- 训练技术突破:标志性事件是 2018 年 BERT 模型,张家兴老师认为模型结构是物理基础,而训练技术使得人工智能具备特定能力;
- 算力与数据的进步:底层的芯片不断进步,性能提升了 100 倍以上。
张家兴老师指出,任何一次大的技术范式的变化,都是一次类型的消失,或者都是一种走向统一的过程,大模型就是这样的一种新的技术范式变化。在 ChatGPT 出现后,模型结构走向统一,之后就会快速“分歧”,整个技术领域重新分工,促使新的生产链的形成,这种变化标志着大模型将成为一个新的产业。
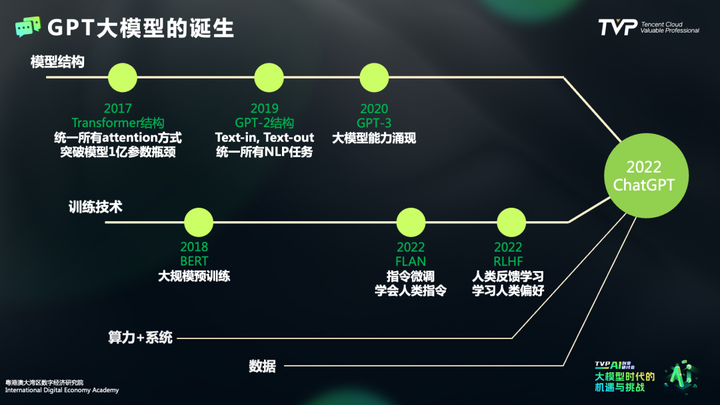
在整个技术的范式变化过程中,张家兴老师所带领团队研发的模型方向也在变化,从一开始的封神榜,到如今构建姜子牙系列专家大模型。张家兴老师分析到,构建一个全能力的大模型存在一定挑战,不同能力之间可能存在冲突和不兼容性,因此将各个能力拆分成独立的模型,以便能够专注于每个能力的发展。通过定制针对性的训练策略,从而达到每个能力的最佳表现。
张家兴老师认为,在“百模大战”的竞争格局中,训练技术的探索性极为重要。他强调,训练技术本身即是一个探索的过程。在训练过程中探索好的生成方式,并在人类反馈学习中引导模型的发展。
在大模型应用产品方面。张家兴老师提出从专家模型到客户端进行层层封装的思路:

第一层封装是一体化封装:包括代码模型及微调、应用和高效推理工具等,并设置好各种使用场景。
第二层封装是模型和算力整合封装,张家兴老师在这一方面正在和腾讯云展开合作,积极推进将模型和算力结合在一个大模型产品中提供给客户,做到“开箱即用”。
AGI时代的技术创新范式与思考

Boolan 首席技术专家、全球机器学习技术大会主席、腾讯云 TVP 李建忠老师,带来了题为《AGI 时代的技术创新范式与思考》的主题演讲。
李建忠老师首先从产业的角度对技术的发展进行了时间线的梳理,他认为连接和计算都经历了从 1.0 到 2.0 的革命性变化。1840-1940 年的这 100 年间是连接的 1.0 时代,电报之后电话、广播、电视相继诞生,是最早的连接技术。1946 年第一代计算机出现,而后大型机、小型机、微型机、PC 出现,这是计算的 1.0 时代。之后随着 1995 年互联网出现后,Web2.0、移动互联网、云服务问世,这是连接 2.0 时代,相比上一代,连接从单向走向双向。再到 2017 年 Transformer 结构的出现, GPT 的迭代是计算 2.0 时代,这个时代还将继续,李建忠老师认为按照过往技术发展的曲线,这个时间会持续到 2035 年左右。
同时,李建忠老师分析指出,在技术的发展过程中,呈现出一种连接和计算的“钟摆”状态。而这两者之间的关系,他认为连接解决的是生产关系,而计算解决的是生产力的问题。连接模式的逻辑是提供信息供用户决策,是广告天然的土壤;而计算模式的逻辑是要用户向机器提供数据来帮助决策,其商业模式更趋向收费。在计算逻辑下,效率优先,结果至上。
李建忠老师提出了范式转换的“立方体”模型,在该模型中 X 轴代表人类需求,如信息、娱乐、搜索、社交、商业;Y 轴代表技术平台,即连接 1.0、计算 1.0、连接 2.0、计算 2.0;Z 轴代表媒介交互,如文字、图片、音频、视频、三维等。他认为需求和技术的交叉点是创新的关键,同时强调媒介的变化对于产品和创新的影响。在智能时代,填充不同象限代表对应不同方向,比如大模型与不同领域结合,为其创新和产品发展提供新的思路。
基于此,李建忠老师总结了大模型具备四大核心能力:
- 生成模型:是其最成熟和最强大的部分,能够生成各种内容;
- 知识抽象:压缩人类知识,为知识密集型行业带来革新;
- 语言交互:是人机对话的核心,有巨大的想象空间;
- 逻辑推理:具备逻辑、规划、记忆能力,成为具身智能。
以大模型核心能力为支点与不同领域结合会带来怎样的创新机会?李建忠老师以大模型应用层为切入点提出两个主要方向:AI-Native 和 AI-Copilot。AI-Native 是指完全融入AI的新型产品或服务,高风险高回报。AI-Copilot 则是以渐进增强的方式,将AI能力嵌入现有的商业闭环中,并与现有的基础设施兼容和扩展。

同样,在软件领域,李建忠老师分享了大模型为软件开发带来的三大范式转换:
- 开发范式:大模型将改变代码编写方式,从工程师写代码为主到AIGC生成代码为主;
- 交互范式:从图形交互界面(GUI)转为自然语言交互界面(NUI),包括NUI+GUI协同、渠道结构化输入中间环节的变革,以及拆除孤立应用间的壁垒,实现应用和服务的无缝集成;
- 交付范式:即用户共创可塑软件,这种开放性将使软件的功能范围变得更为广泛。
李建忠老师认为,在未来的三到五年内,整个 AGI 产业的成熟度将达到一个新的高度,带来巨大的创新机会。
利用无处不在的硬件算力和开放软件解锁生成式人工智能

英特尔院士、大数据技术全球 CTO、腾讯云 TVP 戴金权老师,带来《利用无处不在的硬件算力和开放软件解锁生成式人工智能》主题分享。
戴金权老师首先分享了英特尔团队在生成式人工智能领域的工作。他提到,影响生成式 AI 的众多因素中,算力是非常重要的支撑因素,英特尔针对端到端的 AI 的流水线如何提升效率、如何对 AI 加速进行了针对性的优化。
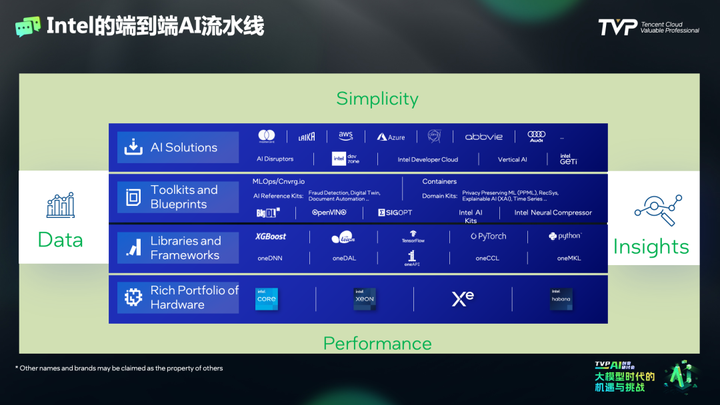
通过软硬件结合,英特尔成功提高了 AI 深度学习的速度,甚至可以实现免费的软件 AI 加速器;在生成式 AI 计算加速方面,戴金权老师提到数据中心端是重点,它将有力支持大模型的训练和超大规模推理。
在英特尔最近发布的 Gaudi2 深度学习加速器中,与 Hugging Face 合作进行模型优化。同时,英特尔在服务器上加入了 Intel AMX,其由两部分组成:一个是 2D 的寄存器文件,另一个是矩阵加速支持。戴金权老师提到,这样做的好处在于能够在通用 CPU 的服务器上实现硬件加速的能力,在通用计算的场景下具有一定意义。

针对云端存储的用户数据和私有化部署的大模型如何保障安全不泄漏的行业需求,戴金权老师分享到,通过硬件保护和软件安全技术,可实现全链路的隐私保护,确保数据和模型在计算过程中对其他用户不可见,只在硬件保护的环境中进行计算,既保证了安全,又接近明文计算的效率。
为实现 AI 无所不在的愿景,近期英特尔开源了基于 INT4 在 Intel CPU 上的大模型推理库,支持在英特尔上跑超过百亿参数的大模型,戴金权老师介绍并演示了其功能特性:
- 支持 INT3、INT4、NF4、INT8 等多种技术;
- 技术易于使用和迁移,可以加速任何基于 PyTorch 的大模型,并实现高效优化;
- 兼容社区常用的 API,一两行代码即可迁移现有应用。
最后,戴金权老师表达了他对于大模型应用在从 PC 无缝扩展到 GPU 到云这一未来趋势的期待,这一新的应用场景值得大家共同去探索。
面向大模型,如何打造云上最强算力集群

腾讯云高性能计算研发负责人 戚元觐老师,带来《面向大模型,如何打造云上最强算力集群》的主题分享。
首先,戚元觐老师对深度学习与 AI 分布式训练进行了介绍。他提到为了解决大模型训练中语料数据集过大和模型参数剧增的问题,需要采用分布式计算。就此,戚元觐老师分享了当下大模型训练中的一些分布式计算方案:
- 数据并行:按照模型的数据集切分并发送到各个 GPU 上进行计算,每个 GPU 分别计算自己的梯度,再进行全局同步以更新模型参数;
- 模型并行-流水线并行:按照模型的层级进行切分,不同部分将分配到不同的 GPU 上进行计算,进行梯度计算和传递;
- 模型并行-张量并行:对模型进行更细粒度的切分,将模型的参数权重进行横向或纵向的切分;
此外,还有如专家并行,由各个专家系统组成并路由到不同的系统中进行计算。

戚元觐老师提到,分布式计算可以充分利用多个 GPU 的计算资源,加快训练速度,并解决单个 GPU 内存不足的问题。不同的方法适用于不同的场景和模型结构,选择合适的并行策略可以提升训练效率和性能。
分布式训练方法对网络通信有较高的要求,业内大都采用 3D 并行方式,特别是在 3D 并行的场景下,带宽需求对于吞吐量是敏感的。在训练中,想要不让网络成为计算的瓶颈,机器与机器之间的通信带宽需要达到 1.6Tbps。
为了应对以上挑战,腾讯云推出了 AI 算力底座——高性能计算集群 HCC,可广泛应用于大模型、自动驾驶、商业推荐系统、图像识别等人工智能模型训练场景,其具有以下特性优势:
- 搭配高性能 GPU:提供强大算力;
- 低延时 RDMA 网络:节点互联网络低至 2us,带宽支持 1.6Tbps-3.2Tbps;
- GpuDirect RDMA:GPU 计算数据无需绕行,跨机点对点直连;
- TACO 训练加速套件:一键提升人工智能训练性能。

腾讯云首发的 H800 计算集群采用多轨道的流量架构,能够大大减少不必要的数据传输,提升网络性能,在业界处于领先地位。
除了硬件支持外,腾讯云还提供了自研的集合通信库 TCCL,得益于自研的交换机架构,TCCL 实现了端网协同,解决流量负载不均的问题,可以在双网口环境下提升流量约 40%。同时提供拓扑感知亲和性调度功能,旨在最小化流量绕行。它具有动态感知能力,可根据最优顺序进行任务分配,避免通信数据拥堵。

戚元觐老师提到,腾讯云的方案都采用双上联的网络设计结构,相比单口训练的可用性更高。数据存储方面,腾讯云提供了 Turbo CF5 文件存储方案和 COS 方案,通过多级加速提升数据访问性能。
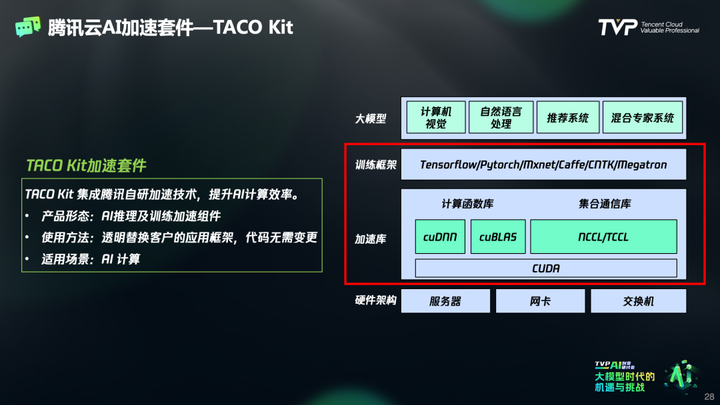
同时,为提高用户的算力使用率,腾讯云推出了 TACO Kit 加速套件,通过对内存和显存的统一管理,减少数据的来回搬移,加快参数更新的速度;还有 TACO lnfer 推理加速,让支持推理透明、加速,带给用户更好的体验服务。
戚元觐老师总结到,腾讯云高性能计算集群 HCC 方案能够从数据读取、训练计算、网络交换等多个层面助力用户又快又持续地完成每一个训练任务,为用户云上训练提供完整的流程支持。
探讨辩论环节

主题分享结束后,主持人 中国信通院低代码/无代码推进中心技术专家、腾讯云 TVP 沈欣老师做了精彩的总结,他提到大模型的发展所带来最核心和关键的影响是生产关系的变化。如“程序员是否会消失”这个问题,可以将程序员比喻成马车时代赶马的人,现在还会有养马的人,但是他们已经被开车的人淘汰了。软件开发行业将被AI重塑,这是未来的程序员所将面对的迭代和变化挑战。
随后,迎来了火花迸发的探讨辩论环节。主持人沈欣老师提出了颇具深度的四个开放话题与两个辩论题目,现场嘉宾以小组形式,对各个话题展开了充分的讨论,在热烈的交流与辩论中碰撞出众多精彩的观点。
话题1:随着大模型的发展,未来将会形成怎样的 AI 生态,会如何影响 IT 行业的格局?

来自第二组的发言代表,盛派网络创始人兼首席架构师、腾讯云 TVP 苏震巍老师提出,AI 未来将重塑整个软件行业的生态及商业模式,包括现在软件应用的形态、互联网运行的模式、用户付费的方式等等。同时随着 AI 进一步推动生产力发展,可以预见未来企业对人员的需求将发生极大的改变,程序员将在一定程度上减少。
苏震巍老师进一步总结到,AI 会在三大方面影响我们未来的商业和工作:AI 推动生产效率变革,影响生产力和生产关系的变化;获取知识和使用知识的方式改变,效率提升;AI 会成为资产的一部分,数据确权等问题值得关注。
话题2:AI 算力的私有化部署和云部署有哪些差异和优势,分别更适合哪些场景?

第三组的发言代表,美团金融服务平台研究员、腾讯云 TVP 丁雪丰老师,从成本、安全性和灵活性三个视角对 AI 算力的私有化部署和云部署进行了比较。
- 从成本角度看:云部署对于中小企业而言,无论在硬件投入还是维护方面都更符合当下企业的降本增效需求;
- 从安全性角度看:他认为部分行业,如金融行业的的安全性和合规性要求极高,私有化部署更为适用;
- 从灵活性角度看:公有云不仅可以单纯地按需提供算力,对于成熟的场景也能提供一站式解决方案,用户可以根据实际需求选择合适的使用方式,在满足安全与合规的场景下更推荐选择云部署。
话题3:企业应如何衡量 AI 的价值,如何量化成本结构和价值,在不同的业务有哪些案例?

来自第四组的发言代表,腾讯云 TVP 徐巍老师提出以下五个评估维度:是否为企业创造价值、节约成本、提升企业生产力、提升客户满意度,以及助力业务增长。徐巍老师补充到,不同企业和行业面临的挑战和目标也各不相同,因此评估 AI 的价值需要结合其具体情况和目标进行综合考量。
同时,就 ToB 和 ToC 的业务场景而言,在 ToB 领域,智能客服、数字人、AI 知识库和企业培训等已经被许多企业应用;在 ToC 领域,当下 AI 生成等是主流的应用场景。
谈及 AI 的成本构成,徐巍老师认为当下主要包括算力成本、AI 技术的开发和维护成本,以及 AI 产品的运营和推广成本。
话题4:在大模型的热潮下,大公司和创业公司分别有哪些可以切入的创新机遇?

第一组的发言代表,Boolan 首席技术专家、全球机器学习技术大会主席、腾讯云 TVP 李建忠老师认为从数据的优势角度看,当下 AI 领域的创新对大公司或成熟的公司友好,但从开源的角度来看,他认为对创业公司更友好。
李建忠老师以产品的发展模式展开阐述,AI-Native 的模式更适合创业型公司,因为面对新事物的到来它们具备全新的起点和思维模式,而且一些创业公司的投入并不弱于大公司。
未来大模型开源是主流or闭源是主流?
第一组的发言代表,Boolan 首席技术专家、全球机器学习技术大会主席、腾讯云 TVP 李建忠老师是“开源方”,他首先定义了“主流”一词:用户最多就是主流;他认为与闭源相比,开源可以实现边缘层和模型层的良好标准化;同时开源能够集合整个行业之力在一个点上进行优化,带来更多的资源和投入。
随后,来自第二组的发言代表,盛派网络创始人兼首席架构师、腾讯云 TVP 苏震巍老师作为“闭源方”先就“主流”定义进行了反驳,他认为真正能够有影响力推动整个行业变革,同时在商业上形成持久循环的,有更健康生态的才是主流,并以闭源的 ChatGPT4 为例进行了论证。他强调,大模型包含了模型本身和数据源,因此算法开源和成果的开源,并不就代表大模型的开源,并举例了 Lama2 的各种限制。苏震巍老师认为当前的一些所谓开源框架,被用作营销工具,违背了开源的真正的精神。
之后“开源方”的李建忠老师进行了针对性反驳,他首先纠正了对方的“开源营销说”,强调开源是生态级的革命。同时就 ChatGPT4 的例子,他认为其最初源头是来自谷歌的开源,且 OpenAI 也在准备开源中。
“闭源方”的苏震巍老师随后补充,不否认开源的生态革命,但事实上很多开源是迫于竞争压力下的抢占市场份额的商业行为。同时他表示,知识的共享并不代表是开源。
更看好通用大模型赛道or垂直大模型赛道?
第三组的发言代表,美团金融服务平台研究员、腾讯云 TVP 丁雪丰老师更看好通用大模型赛道,他认为从更大、更高的历史观视角看,通用大模型的发展是必然的,而且在应用层可以避免垂直大模型的局限性。同时未来随着通用大模型的学习范围不断拓展,当前的垂直领域都将被覆盖。
更看好垂直大模型赛道的第四组的发言代表,腾讯云 TVP 徐巍老师则是从三个角度阐述他的观点:从商业模式看,垂直大模型有丰富的应用场景,可落地,商业模式经过验证是成立的;从成本角度看,大模型的算力成本极高,垂直大模型的成本更加可控;从数据角度来说,作为大模型训练极为重要的部分,通用大模型所需要的数据量巨大,数据源限制性高,垂直知识库的可实现性更高。
随后“通用大模型”方的丁雪丰老师进一步论述,通用大模型在当前 AI 领域的重要性不言而喻,它提供了技术基座,为各种应用提供了支持;而且,基础的、通用的能力发展是自主可控的必然要求。
“垂直大模型”方的徐巍老师做了最后的补充,他认为从赛道生态角度来看,垂直大模型赛道的玩家更多,更能形成百花齐放的生态,带来更高的商业价值和社会价值。
结语
本次研讨会的探讨与辩论话题没有确定的答案,大模型发展方兴未艾,将为每一个技术从业者、企业和行业都带来新的影响。本次活动已圆满落下帷幕,但腾讯云 TVP 专家们对于技术的探索还将继续,他们秉持着“用科技影响世界”的初心和愿景,持续以创新之心积极拥抱大模型时代的变革与趋势,以敬畏之意理性迎接未来的机遇和挑战。
现场花絮集锦