使用QLoRA对Llama 2进行微调是我们常用的一个方法,但是在微调时会遇到各种各样的问题,所以在本文中,将尝试以详细注释的方式给出一些常见问题的答案。这些问题是特定于代码的,大多数注释都是针对所涉及的开源库以及所使用的方法和类的问题。

导入库
对于大模型,第一件事是又多了一些不熟悉的Python库。
!pip install -q peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.4.7
我们必须首先安装accelerate, peft, bitsandbytes, transformers和trl。除了transformers,其他的库都很陌生
transformers是这里最古老的库,PyPI上最早的版本(2.0.0)可以追溯到2019年。它是huggingface发布的库,可以快速访问文本,图像和音频(从hugs的API下载)的机器学习模型。它还提供训练和微调模型的功能,并可以HuggingFace模型中心共享这些模型。库没有像Pytorch或Tensorflow那样从头开始构建神经网络的抽象层和模块,它提供了专门针对模型进行优化的训练和推理api。transformer是用于LLM微调的关键Python库之一,因为目前大部分的LLM都是可以通过它来加载使用。
bitsandbytes是一个相对较新的库,PyPI上最早的版本时2021年发布的。它是CUDA自定义函数的轻量级包装,专门为8位优化器、矩阵乘法和量化而设计。它主要提供了优化和量化模型的功能,特别是对于llm和transformers模型。它还提供了8位Adam/AdamW、 SGD momentum、LARS、LAMB等函数。bitsandbytes的目标是通过8位操作实现高效的计算和内存使用从而使llm更易于访问。通过利用8位优化和量化技术可以提高模型的性能和效率。在较小尺寸的消费类gpu(如RTX 3090)上运行llm存在内存瓶颈。所以人们一直对试图减少运行llm的内存需求的权重量化技术进行研究。bitsandbytes的想法是量化模型权重的浮点精度,从较大的精度点(如FP32)到较小的精度点(如Int8) (4x4 Float16)。有一些技术可以将FP32量化为Int8,包括abmax和零点量化,但由于这些技术的局限性,bitsandbytes库的创建者共同撰写了LLM.int8()论文以及8位优化器,为llm提供有效的量化方法。所以由于bitsandbytes库提供的量化技术,这在很大程度上让我们在消费级的GPU上可以微调更大的模型。
Peft允许我们减少将LLM(或其部分)加载到工作内存中以进行微调的内存需求。与使用较小深度学习模型的迁移学习技术不同,在迁移学习技术中,我们需要冻结像AlexNet这样的神经网络的较低层,然后在新任务上对分类层进行完全微调,而使用llm进行这种微调的成本是巨大的。Parameter Efficient Fine-Tuning(PEFT)方法是一组使llm适应下游任务的方法,例如在内存受限的设备(如T4GPU 提供16GB VRAM)上进行摘要或问答。通过Peft对LLM的部分进行微调,仍然可以获得与完全微调相比的结果。如LoRA和Prefix Tuning是相当成功的。peft库是一个HuggingFace库,它提供了这些微调方法,这是一个可以追溯到2023年1月的新库。在本文中我们将使用QLoRA,这是一种用于量化llm的低秩自适应或微调技术。
trl是另一个HuggingFace库,trl其实是自2021年发布的,但是在2023年1月才被人们热传。TRL是Transformer Reinforcement Learning的缩写也就是Transformer 强化学习。它提供了在训练和微调LLM的各个步骤中的不同算法的实现。包括监督微调步骤(SFT),奖励建模步骤(RM)和近端策略优化(PPO)步骤。trl也将peft作为一个依赖项,所以可以使用带有peft方法(例如LoRA)的SFT训练器。
dataset虽然没有包含在我们之前的安装包列表中(这是因为它是transformers的一个依赖项),但dataset库是huggingface生态系统中的另一个重要部分。它可以方便的访问HuggingFace托管的许多公共数据集,也就是说省去了我们自己写dataset和dataloader的时间。
上面这些库对于LLM的任何工作都是至关重要的。这里做了一个简单的图片来总结这些库是如何组合在一起的。
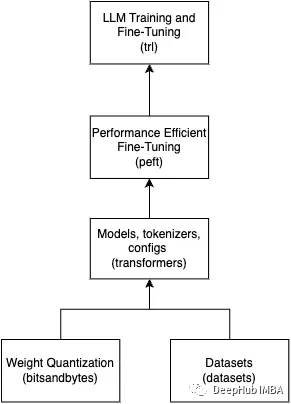
下面让我们看一下导入
import osimport torchfrom datasets import load_datasetfrom transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,TrainingArguments,pipeline,logging,)from peft import LoraConfig, PeftModelfrom trl import SFTTrainer
我们继续分析导入
torch是我们很熟悉的深度学习库,这里我们不需要torch的那些低级功能,但是它是transformers和trl的依赖,在这里我们需要使用torch来获取dtypes(数据类型),比如torch.Float16以及检查GPU的工具函数。
load_dataset所做的就是加载数据集,但是它从HuggingFace数据集中心下载到本地。所以这是一个在线加载程序,但它既高效又简单,只需要一行代码。
dataset = load_dataset(dataset_name, split="train")
因为模型很多所以transformer库提供了一组称为Auto classes的类,这些类给出了预训练模型的名称/路径,它可以自动推断出正确的结构并检索相关模型。这个AutoModelForCausalLM是一个通用的Auto类,用于加载用于因果语言建模的模型。
对于transformers,HuggingFace提供了两种类型的语言建模,因果和掩码掩蔽。因果语言模型包括;GPT-3和Llama,这些模型预测标记序列中的下一个标记,以生成与输入数据语义相似的文本。AutoModelForCausalLM类将从模型中心检索因果模型,并加载模型权重,从而初始化模型。from_pretrained()方法为我们完成了这项工作。
model_name = "NousResearch/Llama-2-7b-chat-hf"model = AutoModelForCausalLM.from_pretrained(model_name,device_map=device_map)
AutoTokenizer是对文本数据进行标记化。它提供了一种无需显式指定标记器类就可以初始化和使用不同模型的标记器的方便的方法。它也是一个通用的Auto类,所以它可以根据提供的模型名称或路径自动选择适当的标记器。标记器将输入文本转换为标记,这些标记是NLP模型使用的基本文本单位。它还提供了额外的功能,如填充、截断和注意力掩码等。AutoTokenizer简化了为NLP任务对文本数据进行标记的过程。我们可以看到在下面初始化AutoTokenizer,后面我们会使用SFTTrainer将初始化的AutoTokenizer作为参数。
model_name = "NousResearch/Llama-2-7b-chat-hf"# Load LLaMA tokenizertokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
BitsAndBytesConfig,前面已经说了我们使用bitsandbytes进行量化。transformer库最近添加了对bitsandbytes的全面支持,因此使用BitsandBytesConfig可以配置bitsandbytes提供的任何量化方法,例如LLM.int8、FP4和NF4。将量化配置传递给AutoModelForCausalLM初始化器,这样在加载模型权重时就会直接使用量化的方法。
#bits and byte configbnb_config = BitsAndBytesConfig(load_in_4bit=use_4bit,bnb_4bit_quant_type=bnb_4bit_quant_type,bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=use_nested_quant,)model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config, #pass to AutoModelForCausalLMdevice_map=device_map)
TrainingArguments非常简单。它用于存储SFTTrainer的所有训练参数。SFFTrainer接受不同类型的参数,TrainingArguments帮助我们将所有相关的训练参数组织到一个数据类中保持代码的整洁和有组织。
还有一些很好的工具类可以与TrainingArguments一起使用,比如HfArgumentParser可以为TrainingArguments创建一个参数解析器,这对CLI应用程序很有用。
#TrainingArgumentstraining_arguments = TrainingArguments(output_dir=output_dir,num_train_epochs=num_train_epochs,per_device_train_batch_size=per_device_train_batch_size,gradient_accumulation_steps=gradient_accumulation_steps,optim=optim,save_steps=save_steps,logging_steps=logging_steps,learning_rate=learning_rate,weight_decay=weight_decay,fp16=fp16,bf16=bf16,max_grad_norm=max_grad_norm,max_steps=max_steps,warmup_ratio=warmup_ratio,group_by_length=group_by_length,lr_scheduler_type=lr_scheduler_type,report_to="tensorboard")
在完成微调之后,我们将使用pipeline进行推理。可以选择各种管道任务的列表,像“图像分类”,“文本摘要”等。还可以为任务选择要使用的模型。为了定制也可以添加一个参数来进行某种形式的预处理,如标记化或特征提取。
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
从transformer导入的最后一个内容是logging。这是一个日志系统,这在调试代码时非常有用。
logging.set_verbosity(logging.CRITICAL)
从peft库中导入的LoraConfig数据类是一个配置类,它主要存储初始化LoraModel所需的配置,LoraModel是PeftTuner的一个实例。我们将此配置传递给SFTTrainer,它将使用该配置初始化适当的tuner。
# Load LoRA configurationpeft_config = LoraConfig(lora_alpha=lora_alpha,lora_dropout=lora_dropout,r=lora_r,bias="none",task_type="CAUSAL_LM",)
PeftModel,一旦我们使用一种peft方法(如LoRA)进行微调,就需要将LoRA适配器权重保存到磁盘并在使用时将它们加载回内存。PEFT模块微调的权重,与基本模型权重是分开。使用PeftModel,还可以选择将将base_model权重与新微调的适配器权重合并(调整),这样就得到了一个完整的新模型。PeftModel.from_pretrained()从内存中加载适配器权重,merge_and_unload()方法将它们与base_model合并。
# Reload base_model in FP16 and merge it with LoRA weightsbase_model = AutoModelForCausalLM.from_pretrained(model_name,low_cpu_mem_usage=True,return_dict=True,torch_dtype=torch.float16,device_map=device_map,)model = PeftModel.from_pretrained(base_model, new_model)model = model.merge_and_unload()
最后一个导入是SFTTrainer。SFTTrainer是transformer Trainer类的子类。Trainer是一个功模型训练的泛化API。SFTTrainer在此基础上增加了对参数微调的支持。有监督的微调步骤是训练因果语言模型(如Llama)用于下游任务(如指令遵循)的关键步骤。
SFTTrainer支持PEFT,因此我们将与LoRA一起使用SFTTrainer。然后,SFTTrainer将使用LoRA执行监督微调。然后我们可以运行训练器(train())并保存权重(save_pretrained())。
#Initialize the SFTTrainer objecttrainer = SFTTrainer(model=model,train_dataset=dataset,peft_config=peft_config,dataset_text_field="text",max_seq_length=max_seq_length,tokenizer=tokenizer,args=training_arguments,packing=packing,)# Train modeltrainer.train()# Save trained modeltrainer.model.save_pretrained(new_model)
对于引用,我们也总结了一张图片
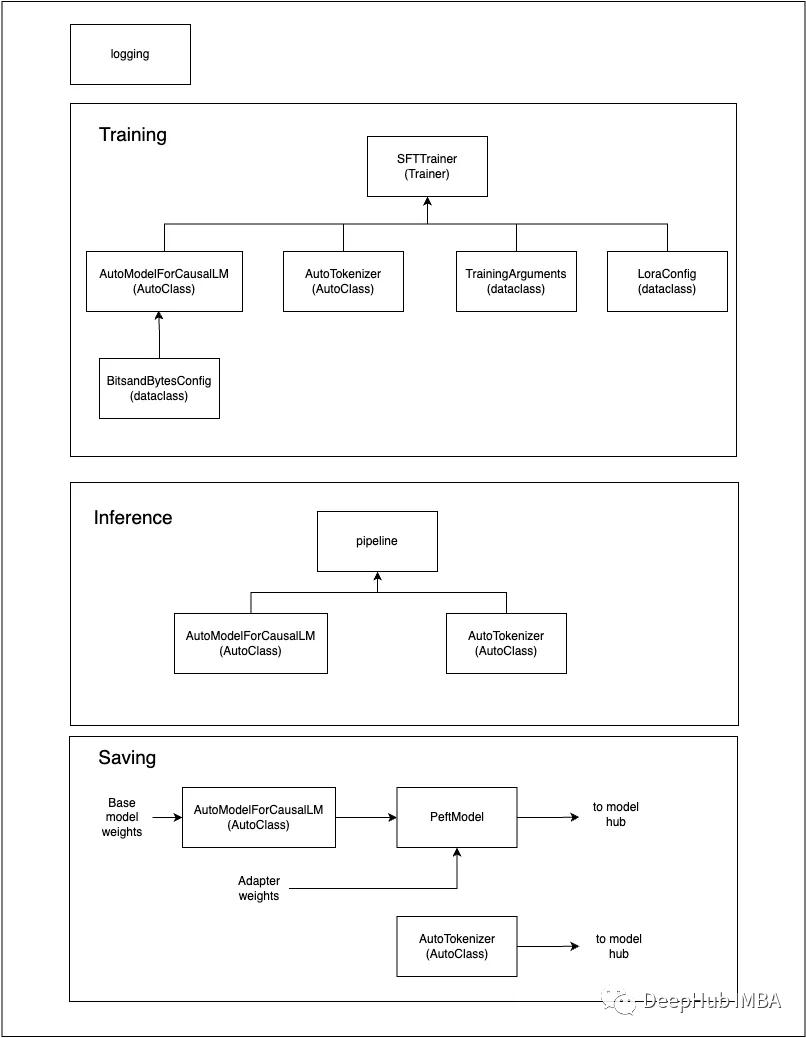
训练参数
现在我们知道了需要哪些库来调优Llama 2(或任何LLM),也知道了这些库中需要的类,并且了解了这些类的功能。下面就是对前面导入的参数的介绍
模型和数据集名称:
# The model that you want to train from the Hugging Face hubmodel_name = "NousResearch/Llama-2-7b-chat-hf"# The instruction dataset to usedataset_name = "mlabonne/guanaco-llama2-1k"# Fine-tuned model namenew_model = "llama-2-7b-miniguanaco"
model_name、dataset_name和new_model。这些名称遵循HuggingFace模型及其hub上的数据集名称的格式。
birushuo 给一个名字“NousResearch/ Llama-2-7b-chat-hf”这个名字的第一部分NousResearch是一个研究机构,也就是它HuggingFace账户的名称,第二部分是模型名称lama-2 - 7b-chat-hf。模型命名的建议是给模型提供描述性的名称,包括有用的信息,如独特的模型名称(lama-2),关键参数信息(7b),以及一些关于模型如何工作的其他有用信息(chat-hf)。我们在new_model名称llama-2-7b-miniguanaco中看到了同样的规则,这是我们分配给微调模型的名称。这里附加了在miniguanaco上进行微调的数据集的名称。
QLoRA 参数:
# LoRA attention dimensionlora_r = 64# Alpha parameter for LoRA scalinglora_alpha = 16# Dropout probability for LoRA layerslora_dropout = 0.1
我们将使用的参数是r (lora_r)、lora_alpha和lora_dropout。这些参数对于LoRA来说是最重要的,要理解其中的原因,必须深入了解LoRA的论文,我们只做简单的总结:
在神经网络中,反向传播算法计算期望值和实际值之间的误差,然后用这个误差来计算delta,这是神经网络中权重对e的贡献。如果你有一个神经网络的初始权值W0那么对于误差e,我们计算delta_W0 =∆W。然后使用∆W来更新权重W0 +∆W,以减小误差e。LoRA提出将∆W分解为两组低秩矩阵A和B,使W0 +∆W = W0 + BA。而不是使用完整的∆W更新,我们使用较小的低秩更新矩阵BA,这就是我们如何实现相同效率和更低的计算需求。如果∆W的大小为(d × k) (W0的大小),则我们将∆W分解为两个矩阵:B和A,维度分别为(d × r)和(r × k),其中r为秩。
LoraConfig中的参数r (lora_r)是决定更新矩阵BA形状的秩。根据论文可以设置一个小的秩,并且得到很好的结果。当我们更新W0时,可以通过使用缩放因子α来控制BA的影响,这个缩放因子作为学习率。比例因子是我们的第二个参数(lora_alpha)。最后设置lora_dropput,这是正则化的典型dropput。
BitsandBytes参数:
# Activate 4-bit precision base model loadinguse_4bit = True# Compute dtype for 4-bit base modelsbnb_4bit_compute_dtype = "float16"# Quantization type (fp4 or nf4)bnb_4bit_quant_type = "nf4"# Activate nested quantization for 4-bit base models (double quantization)use_nested_quant = False
我们正在使用一种称为QLoRA的量化版本的LoRA,这意味着我们希望在LoRA微调中使用量化,将量化应用于我们前面提到的更新权重(以及其他可以量化的操作)。
参数use_4bit(第6行)设置为True,以使用高保真的4位微调,这是后来在QLoRA论文中引入的,以实现比LLM.int8论文中引入的8位量化更低的内存要求。
设置bnb_4bit_compute_dtype(第9行),这是执行计算的数据类型(float16)。也就是说虽然将权重通过4位量化存储,但计算还是发生在16位或32位。
使用bnb_4bit_quant_type(第12行),nf4,根据QLoRA论文,nf4显示了更好的理论和经验性能。
参数use_nested_quant设置为False,并将其传递给bnb_4bit_use_double_quant。模型在第一次量化之后启用第二次量化,从而为每个参数额外节省0.4位。
上面一些参数都是QLoRA的论文提供,如果想深入了解,请查看论文或我们以前的文章
在本文中我们选择NF4量化FP16 (float16)精度进行计算后,我们应该对Colab T4 GPU (16 GB VRAM)没有内存限制。我们做个简单的计算:如果使用Llama-2-7B(70亿params)和FP16(没有量化),我们得到7B × 2字节= 14 GB(所需的VRAM)。使用4位量化,我们得到7B × 0.5字节= ~ 4gb(所需的VRAM)。
训练参数:
# Output directory where the model predictions and checkpoints will be storedoutput_dir = "./results"# Number of training epochsnum_train_epochs = 1# Enable fp16/bf16 training (set bf16 to True with an A100)fp16 = Falsebf16 = False# Batch size per GPU for trainingper_device_train_batch_size = 4# Batch size per GPU for evaluationper_device_eval_batch_size = 4# Number of update steps to accumulate the gradients forgradient_accumulation_steps = 1# Maximum gradient normal (gradient clipping)max_grad_norm = 0.3# Initial learning rate (AdamW optimizer)learning_rate = 2e-4# Weight decay to apply to all layers except bias/LayerNorm weightsweight_decay = 0.001# Optimizer to useoptim = "paged_adamw_32bit"# Learning rate schedule (constant a bit better than cosine)lr_scheduler_type = "constant"# Ratio of steps for a linear warmup (from 0 to learning rate)warmup_ratio = 0.03# Group sequences into batches with same length# Saves memory and speeds up training considerablygroup_by_length = True# Save checkpoint every X updates stepssave_steps = 25# Log every X updates stepslogging_steps = 25
Output_dir(第6行):这是设置存储模型预测和检查点的位置,还包括日志
num_train_epochs(第9行):训练的轮次
fp16和bf16(第12行和第13行):我们将它们都设置为false,因为我们不会使用混合精度训练,因为已经有QLoRA了。
per_device_train_batch_size和per_device_eval_batch_size(第16行和第19行):将它们都设置为4。有足够的内存,可以设置更高的批处理大小(>8),这将加快训练速度。
Gradient_accumulation_steps(第22行):“梯度累积”指的是在实际更新模型权重之前执行的向前和向后传递的次数(更新步骤)。在每一次向前和向后传递期间,梯度被计算并累积在一批数据上。在累积指定步数的梯度之后,然后执行反向传递,计算这些步骤的平均梯度并相应地更新模型权重。这种方法有助于有效地模拟更大批大小,它减少了每次向前和向后传递的内存需求。
max_gradient_norm(第25行):如果梯度的范数(幅度)超过某个阈值(由max_grad_norm参数指定),则梯度裁剪缩小梯度。如果梯度范数大于max_grad_norm,则梯度将按比例缩小,如果梯度规范已经低于max_grad_norm,则不应用缩放。建议从max_grad_norm的较高值开始,然后在多个训练迭代中慢慢缩小它。
learning_rate(第28行):AdamW的学习率。AdamW是流行的Adam优化器的一个变体。它结合了Adam优化器和权重衰减正则化的技术。
weight_decay(第31行):权重衰减,也称为L2正则化或权重正则化,是机器学习和深度学习中常用的一种正则化技术,用于防止模型对训练数据的过拟合。它的工作原理是在损失函数中添加一个惩罚项。我们使用AdamW和权重衰减是有意义的,因为权重衰减在微调期间特别有用,因为它有助于防止过拟合,并确保模型适应新任务,同时保留预训练中的一些知识。
optim(第34行):使用AdamW优化器,“paged_adamw_32bit”似乎是AdamW优化器的一个特定实现或变体,我们找到任何关于他的信息,所以如果你有关于这方面的信息,请在评论中留下,谢谢!
lr_scheduler_type(第37行):通常我们在深度学习模型的训练期间使用学习率调度器,以随时间调整学习率。
warmup_ratio(第40行):这里我们将“warmup_ratio”设置为0.03。由于每个epoch有250个训练步骤,热身阶段将持续到前8步(250的3%),在此期间,学习率将从0线性增加到指定的初始值2e-4。热身阶段通常用于稳定训练,防止梯度爆炸,并允许模型开始有效地学习。
group_by_length(第44行):这个参数设置为True,会加快了训练速度。当group_by_length设置为True时,它将训练数据集中大致相同长度的样本分组到同一批中。这意味着具有相似长度的序列被分组在一起,减少了所需的填充。也就是说批将具有更相似长度的序列,这将最小化所应用的填充量。当批处理具有一致的大小时GPU处理通常更有效,从而缩短训练时间,这是从LSTM时代就开始的一个加速技巧。
save_steps和logging_steps(第47行和第50行):这里将两个参数都设置为25,以控制记录训练信息和保存检查点的间隔步骤。
SFTTrainer参数:
max_seq_length = None# Pack multiple short examples in the same input sequence to increase efficiencypacking = False
最后参数是特定于SFTTrainer的。
max_seq_length:将max_seq_length设置为None允许我们不施加最大序列长度限制,我们不想截断或填充它们到固定长度,因此将max_seq_length设置为None允许我们使用数据中存在的全部序列长度。
packing:根据文档,ConstantLengthDataset使用这个参数来打包数据集的序列。在ConstantLengthDataset上下文中将packing设置为False可以在处理多个简短示例时提高效率,我们的数据集就是这种情况。通过将packing设置为False,允许ConstantLengthDataset将多个短示例打包到单个输入序列中,有效地组合它们。这减少了对大量填充的需求,并提高了内存使用和计算的效率。
加载数据集、基本模型和标记器
device_map = {"": 0}# Load dataset (you can process it here)dataset = load_dataset(dataset_name, split="train")# Load tokenizer and model with QLoRA configurationcompute_dtype = getattr(torch, bnb_4bit_compute_dtype)bnb_config = BitsAndBytesConfig(load_in_4bit=use_4bit,bnb_4bit_quant_type=bnb_4bit_quant_type,bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=use_nested_quant,)# Check GPU compatibility with bfloat16if compute_dtype == torch.float16 and use_4bit:major, _ = torch.cuda.get_device_capability()if major >= 8:print("=" * 80)print("Your GPU supports bfloat16: accelerate training with bf16=True")print("=" * 80)# Load base modelmodel = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config,device_map=device_map)model.config.use_cache = Falsemodel.config.pretraining_tp = 1# Load LLaMA tokenizertokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)tokenizer.add_special_tokens({'pad_token': '[PAD]'})tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"# Load LoRA configurationpeft_config = LoraConfig(lora_alpha=lora_alpha,lora_dropout=lora_dropout,r=lora_r,bias="none",task_type="CAUSAL_LM",)
第5行加载数据集。然后在第9行使用gettr函数将compute_dtype设置为torch.float16。在第10行,初始化BitsandBytesConfig。
在第17行,我们使用torch.cuda.get_device_capability()函数检查GPU与bfloat16的兼容性。该函数返回支持cuda的GPU设备的计算能力。计算能力表示GPU支持的版本和特性。该函数返回一个由两个整数组成的元组,(major, minor),表示GPU的主要和次要计算能力版本。主要版本表示该计算能力的主要版本,次要版本表示该计算能力的次要版本。例如,如果函数返回(8,0),则表示GPU的计算能力为8.0版本,次要是0。如果GPU是bfloat16兼容的,那么我们将compute_dtype设置为torch.Bfloat16,因为Bfloat16比float16更好的精度
然后就是使用AutoModelForCausalLM.from_pretrained加载基本模型,在第31行设置了model.config。use_cache为False,当启用缓存时可以减少变量。禁用缓存则在执行计算的顺序方面引入了一定程度的随机性,这在微调时非常有用。
在第32行设置了model.config.pretraining_tp = 1这里的tp代表张量并行性,根据这里的Llama 2的提示:
设置model.config. pretraining_tp = 1不等于1的值将激活更准确但更慢的线性层计算,这应该更好地匹配原始概率。
然后就是使用model_name加载Llama标记器。如果你看一下NousResearch/ lama-2的文件,你会注意到有一个tokenizer. model文件。使用model_name, AutoTokenizer可以下载该标记器。
在第36行,调用add_special_tokens({’ pad_token ': ’ [PAD] '})这是另一个重要代码,因为我们数据集中的文本长度可以变化,批处理中的序列可能具有不同的长度。为了确保批处理中的所有序列具有相同的长度,需要将填充令牌添加到较短的序列中。这些填充标记通常是没有任何含义的标记,例如。
在第37行,我们设置tokenizer. pad_token = tokenizer. eos_token。将pad令牌与EOS令牌对齐,并使我们的令牌器配置更加一致。两个令牌(pad_token和eos_token)都有指示序列结束的作用。设置成一个简化了标记化和填充逻辑。
在第38行,设置填充边,将填充边设置为右可以修复溢出问题。
最后在第41行,我们初始化了LoraConfig
训练
# Set training parameterstraining_arguments = TrainingArguments(output_dir=output_dir,num_train_epochs=num_train_epochs,per_device_train_batch_size=per_device_train_batch_size,gradient_accumulation_steps=gradient_accumulation_steps,optim=optim,save_steps=save_steps,logging_steps=logging_steps,learning_rate=learning_rate,weight_decay=weight_decay,fp16=fp16,bf16=bf16,max_grad_norm=max_grad_norm,max_steps=max_steps,warmup_ratio=warmup_ratio,group_by_length=group_by_length,lr_scheduler_type=lr_scheduler_type,report_to="tensorboard")# Set supervised fine-tuning parameterstrainer = SFTTrainer(model=model,train_dataset=dataset,peft_config=peft_config,dataset_text_field="text",max_seq_length=max_seq_length,tokenizer=tokenizer,args=training_arguments,packing=packing,)# Train modeltrainer.train()# Save trained modeltrainer.model.save_pretrained(new_model)
在第2行使用前面详细讨论过的形参初始化TrainingArguments。然后将TrainingArguments与讨论的其他相关参数一起传递到第30行上的SFTTrainer中。
这里新加的一个参数是第27行的dataset_text_field= " text "。dataset_text_field参数用于指示数据集中哪个字段包含作为模型输入的文本数据。它使datasets 库能够基于该字段中的文本数据自动创建ConstantLengthDataset,简化数据准备过程。
HuggingFace生态系统是一个紧密结合的库生态系统,它在后台为你自动化了很多工作。
推理
logging.set_verbosity(logging.CRITICAL)# Run text generation pipeline with our next modelprompt = "What is a large language model?"pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)result = pipe(f"<s>[INST] {prompt} [/INST]")print(result[0]['generated_text'])
第6行,管道初始化。然后在第7行使用管道,传递使用第5行提示符构造的输入文本。我们使用来指示序列的开始,而添加[INST]和[/INST]作为控制令牌来指示用户消息的开始和结束。
用适配器权重重新加载基本模型
# Reload model in FP16 and merge it with LoRA weightsbase_model = AutoModelForCausalLM.from_pretrained(model_name,low_cpu_mem_usage=True,return_dict=True,torch_dtype=torch.float16,device_map=device_map,)model = PeftModel.from_pretrained(base_model, new_model)model = model.merge_and_unload()# Reload tokenizer to save ittokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)tokenizer.add_special_tokens({'pad_token': '[PAD]'})tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"
在第2行使用AutoModelForCausalLM.from_pretrained来(重新)加载基本模型。我们将在没有任何量化配置的情况下执行此操作,因为我们不需要对其进行微调,只是想将其与适配器合并。还在第13行重新加载标记器,并进行与之前在第13 - 14行中所做的相同的修改。
保存
最后我们将刚刚经过微调的模型及其标记器保存到本地或者上传到HuggingFace。
model.push_to_hub(new_model, use_temp_dir=False)tokenizer.push_to_hub(new_model, use_temp_dir=False)
总结
peft,tramsformers等库简化了我们对于大模型开发的工作流程,并且不需要很多的专业知识也可以对大模型进行微调。但是要得到一个好的模型是一个漫长的过程,就像我们上面的代码一样,看似简单实则复杂,不仅要了解方法的原理,还要通过查看论文了解每一个参数的含义。
本文是一个良好的开端,因为可以把我们在这里学到的大部分东西应用到微调任何LLM的任务中。关于微调Llama 2,我们的流程已经介绍完毕了,但是我们如何才能正确地评估我们的微调性能?能否在不花费太多的情况下调整更大的模型(70B) ?使用更大的数据集?模型怎么部署呢?我们会在后续的文章中进行介绍。
https://avoid.overfit.cn/post/903a50f5e8ec469f890a1e8854d64716
作者:Ogban Ugot








使用GMM-Tree算法对点云配准)




)

)
中组件通信04——redux入门)
)
有图详解)
