SwiftBrush:具有变分分数蒸馏的单步文本到图像扩散模型
Paper Title:SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
Paper 是 VinAI Research 发表在 CVPR 24 的工作
Paper地址
Code:地址
Abstract
尽管文本到图像的扩散模型能够根据文本提示生成高分辨率和多样化的图像,但它们通常受到迭代采样过程缓慢的影响。 模型蒸馏是加速这些模型的最有效方向之一。然而,以前的蒸馏方法无法保持生成质量,同时需要大量图像进行训练,这些图像要么来自真实数据,要么由教师模型合成生成。 为了解决这一限制,我们提出了一种名为 SwiftBrush 的新型无图像蒸馏方案。从文本到 3D 合成中汲取灵感,其中可以通过专门的损失从 2D 文本到图像扩散先验中获得与输入提示对齐的 3D 神经辐射场,而无需使用任何 3D 数据GT,我们的方法重新利用相同的损失来将预训练的多步骤文本到图像模型蒸馏到学生网络,只需一个推理步骤即可生成高保真图像。尽管我们的模型很简单,但它是首批一步式文本转图像生成器之一,无需依赖任何训练图像数据即可生成与稳定扩散质量相当的图像。值得注意的是,SwiftBrush 在 COCO-30K 基准上获得了 16.67 的 FID 分数和 0.29 的 CLIP 分数,取得了具有竞争力的结果,甚至大大超越了现有的最先进蒸馏技术。
1. Introduction
扩散模型正受到研究界的广泛关注,因为它们在各种生成任务中取得了显著成果,包括图像生成 [10, 26, 40, 41]、视频合成 [11]、3D 建模 [3, 28, 46]、音频生成 [16] 和文本创建 [7, 17]。 特别是,文本到图像的扩散模型结合了语言模型和高质量扩散模型 [32, 36, 43] 的强大功能,彻底改变了人们基于文本描述创建视觉内容的方式。只需单击几下,就可以生成与真实照片无法区分的合成图像。此外,借助 ControlNet [49] 或 DreamBooth [35] 等技术,可以对生成输出进行额外控制,以进一步提高文本到图像模型的表现力并使其更接近大众用户。然而,尽管取得了令人瞩目的成功,这些模型也表现出推理速度慢的显著缺点。主要原因在于其采样的迭代性质,这对在边缘设备上的部署带来了重大挑战。
已经提出了几种方法来提高基于扩散的文本到图像生成的推理速度。 然而,最有效的方向是时间步长蒸馏,其目的是在网络主干不变和生成质量降低最小的情况下减少扩散模型的采样步骤数。从开创性的工作 [37] 开始,已经提出了更先进、更有效的蒸馏方法,最近的一些方法可以训练高效的学生网络,只需向前迈一步即可从输入字幕合成图像。在本文中,我们对基于蒸馏的一步式文本到图像生成方法感兴趣。 特别是,Meng 等人 [25] 采用了两阶段蒸馏,其中学生首先尝试将其输出与老师的无分类器引导输出进行匹配,然后引导自身以逐渐减少推理步骤。 这种方法复杂且耗时,至少需要 108 A100 GPU 天 [20]。基于 Song 等人 [42] 的工作,潜在一致性模型 (LCM) [23] 强制稳定扩散 (SD) [43] 潜在空间中 ODE 轨迹上所有点的一致性,并且与 [25] 不同,它们直接将两个蒸馏阶段合二为一。尽管引导式蒸馏和 LCM 都将推理步骤数显著减少到 2 或 4,但它们的 1 步推理产生的结果模糊且不令人满意。更复杂的是,Instaflow [20] 提出了一种称为“reflow”的技术,用于在蒸馏之前拉直老师的采样轨迹。虽然他们提出的技术在一步文本到图像蒸馏中被证明优于原始扩散框架,但 InstaFlow 需要昂贵的 4 阶段训练计划。此外,值得注意的是,这些方法的有效性在很大程度上依赖于大量的文本-图像对,由于此类数据的可访问性有限,情况并非总是如此。
在这项工作中,我们旨在开发一种新颖的蒸馏方法,用于一步式文本到图像生成,该方法具有更高的质量和更易于接受的训练过程,其特点是无图像且机制简单。基于文本到 3D 技术的最新进展,我们的工作从它们无需使用 3D GT数据即可生成高质量 3D 神经辐射场 (NeRF) 的能力中汲取灵感。这一非凡成就是通过使用强大的预训练 2D 文本到图像模型来评估 NeRF 渲染的图像是否逼真来实现的,类似于 GAN 中的鉴别器。这一观察结果支撑了我们 SwiftBrush 方法的动机,因为我们认识到这些原理可以创新地适用于文本到图像生成,从而无需图像监督。因此,SwiftBrush 作为一种概念新颖的一步式文本到图像蒸馏过程而出现,它独特地能够在没有 2D 图像监督的情况下运行。这种战略性的调整不仅开启了将文本到图像扩散模型提炼为单步生成器的观点的改变,而且还指出了将文本到 3D 到文本到图像合成的混合原理的潜力。
因此,我们的方法成功地生成了具有非凡细节的高质量图像。从数量上看,我们的一步式模型在 MS COCO 2014 数据集(30K 幅图像)上实现了令人满意的零样本结果,FID 得分为 16.6,CLIP 得分为 0.29。值得注意的是,这是蒸馏式一步式模型首次在不使用单幅图像进行训练的情况下胜过之前的方法。图 1 展示了我们蒸馏式模型生成的图像。

图 1. SwiftBrush 一步生成样本。与稳定扩散相比,我们的蒸馏方法可以以大约 20 倍的速度生成高保真图像。
2. Related Work
文本到图像生成。以前,文本到图像模型依赖于 GAN,并且仅关注小规模的以对象为中心的领域,例如花和鸟 [33, 48]。最近,随着文本-图像对的网络规模数据集(例如 LAION5B [39])、大型语言模型(例如 T5 [30])和大型视觉语言模型(例如 CLIP [29])的出现,这些类型的系统得到了迅速发展。DALL-E [31] 是第一个通过简单地扩大网络和数据集大小,在从文本标题创建图像方面表现出非凡的零样本能力的自回归模型。此后,大量方法被用于文本到图像的生成,包括蒙版生成transformer [4]、基于 GAN 的模型和扩散模型。基于潜在扩散模型 [34],稳定扩散是一个基于扩散的开源生成器,在艺术家和研究人员中广受欢迎。最近,文本转图像 GAN 再次受到关注,其中包括 StyleGAN-T [38] 和 GigaGAN [14] 等著名作品。虽然它们不需要迭代采样,因此速度极快,但由于它们存在不稳定性和臭名昭著的“模式崩溃”问题,因此在可扩展性和真实性方面落后于扩散模型。据我们所知,到目前为止,只有上述两项工作使用大量复杂的技术和辅助模块成功地将 GAN 应用于文本转图像。相反,扩散模型可以轻松扩展以生成高质量且清晰的样本,但它们需要冗长的采样过程。在这里,我们的目标是创建一个将 GAN 的速度与扩散模型的质量相结合的大规模生成模型。
文本到 3D 生成。许多研究工作并没有直接从 3D 监督中学习生成模型,而是利用丰富的 2D 先验知识来完成 3D 生成任务。例如,最早的作品之一 Dream Fields [13] 利用 CLIP [29] 来引导生成的图像,以便从许多摄像机视图渲染的图像与文本标题高度一致。另一方面,DreamFusion [28] 和 Score Jacobian Chaining [44] (SJC) 等先驱作品提出了两个不同但等效的框架,其中使用 2D 文本到图像生成先验从文本描述生成 3D 对象。后续研究试图以各种方式改进这些文本到 3D 方法。其中,Magic3D [18] 和 ProlificDreamer [45] 是两个出色的作品,有效提高了 3D 对象的生成质量。 Magic3D 包含两个阶段,首先通过 DreamFusion 风格的优化获得低分辨率 3D 表示,然后细化其纹理以获得最终的高保真 3D 网格。同时,ProlificDreamer 提出了变分分数蒸馏 (VSD),其中涉及一个辅助教师,以弥合教师和 3D NeRF 之间的差距。受后者工作的影响,我们的方法采用了相同的技术来实现一步式文本到图像的生成。类似地,Score GAN [6] 和 Diff-Instruct [24] 使用类似 VSD 的损失将预训练的扩散模型蒸馏为一步式生成器。
Hinton 等人 [9] 提出的知识蒸馏是迁移学习方法之一。该算法主要灵感来源于人类的学习过程,即知识从知识更渊博的老师传授给知识较少的学生。在扩散模型的背景下,已经有人提出了从预先训练好的扩散老师那里更快地采样学生模型的方法。最直接的方法是直接蒸馏 [22],其中学生模型在采样 50-1000 步后从老师的输出中进行监督,这可能是令人望而却步的。最近的研究 [37, 42] 通过各种引导方法避免了蒸馏过程中的冗长采样。随后,一系列方法 [20, 23, 25] 将这些方法适应文本到图像的设置,并继承了它们在训练中依赖图像的局限性。相比之下,一项并发研究 [8] 学习了一个时间条件模型来预测老师在任何给定时间步骤的结果,所有这些都不需要图像监督。同样,我们的方法同样不需要图像,但却能取得更好的结果,并提供更简单的蒸馏设计。
3. Proposed Method
3.1. Preliminary
扩散模型包括两个过程:一个前向过程逐渐添加噪声,另一个反向过程预测逐渐去噪数据点的分布。前向过程从初始数据点 x 0 x_0 x0 开始,该点从分布 q 0 ( x 0 ) q_0\left(x_0\right) q0(x0) 中抽取,结果为 q t ( x t ∣ x 0 ) = N ( α t x 0 , σ t 2 I ) q_t\left(x_t \mid x_0\right)=\mathcal{N}\left(\alpha_t x_0, \sigma_t^2 I\right) qt(xt∣x0)=N(αtx0,σt2I),其中 { ( α t , σ t ) } t = 1 T \left\{\left(\alpha_t, \sigma_t\right)\right\}_{t=1}^T {(αt,σt)}t=1T 是噪声调度。每个时间步 t t t 的数据点 x t x_t xt 从 q t ( x t ∣ x 0 ) q_t\left(x_t \mid x_0\right) qt(xt∣x0) 中抽取,使用噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I):
x t = α t x 0 + σ t ϵ . ( 1 ) x_t=\alpha_t x_0+\sigma_t \epsilon . \quad(1) xt=αtx0+σtϵ.(1)
经过 T T T 个时间步骤后,最终数据点预期成为纯高斯噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I)。
相反,反向过程从 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I) 开始,逐步进行去噪过程,共进行 T T T 步,其中每个步骤 t t t,嘈杂变量 x t + 1 x_{t+1} xt+1 被转换为更少嘈杂的变量 x t x_t xt,由模型 ϵ ψ \epsilon_\psi ϵψ 引导,该模型预测方程中的噪声 ϵ \epsilon ϵ。网络权重 ψ \psi ψ 通过最小化以下损失进行训练:
L uncond ( ψ ) = E t , ϵ ∈ N ( 0 , 1 ) ∥ ϵ ψ ( x t , t ) − ϵ ∥ 2 2 ( 2 ) \mathcal{L}_{\text {uncond }}(\psi)=\mathbb{E}_{t, \epsilon \in \mathcal{N}(0,1)}\left\|\epsilon_\psi\left(x_t, t\right)-\epsilon\right\|_2^2 \quad(2) Luncond (ψ)=Et,ϵ∈N(0,1)∥ϵψ(xt,t)−ϵ∥22(2)
其中 t t t 均匀采样自 { 1 , … , T } \{1, \ldots, T\} {1,…,T}。
虽然常见的扩散模型在像素空间中操作,但潜在扩散模型(LDMs)[34] 在预训练的正则化自编码器的潜在空间中建模扩散过程,其特征表示较小,因此提高了训练和推断的效率。
文本到图像扩散模型。与无条件扩散模型自由生成输出不同,文本条件扩散模型使用额外的提示 y y y 引导采样过程。这引导模型生成不仅逼真而且与提供的文本描述密切符合的输出。训练此类模型的目标如下:
L diff ( ψ ) = E t , y , ϵ ∈ N ( 0 , 1 ) ∥ ϵ ψ ( x t , t , y ) − ϵ ∥ 2 2 \mathcal{L}_{\text {diff }}(\psi)=\mathbb{E}_{t, y, \epsilon \in \mathcal{N}(0,1)}\left\|\epsilon_\psi\left(x_t, t, y\right)-\epsilon\right\|_2^2 Ldiff (ψ)=Et,y,ϵ∈N(0,1)∥ϵψ(xt,t,y)−ϵ∥22
这与无条件扩散损失公式 (2) 略有不同。由于提示条件,模型可以提供比无条件模型更可控的生成。然而,许多领先方法 [1,32,36] 的实现仍对公众不可访问。Stable Diffusion 主要利用 LDM 框架,作为首个公开可用的大规模模型,显著推动了文本到图像合成的广泛采用和多样化。
得分蒸馏采样 (SDS) 是一种在生成 3D 对象中有效应用的蒸馏技术 [18, 28, 44]。它利用预训练的文本到图像扩散模型,根据文本条件 y y y 预测扩散噪声,表示为 ϵ ψ ( x t , t , y ) \epsilon_\psi\left(x_t, t, y\right) ϵψ(xt,t,y)。该方法优化单个 3D NeRF,用参数 θ \theta θ 表示,以与给定的文本提示对齐。给定相机参数 c c c,使用可微渲染函数 g ( ⋅ , c ) g(\cdot, c) g(⋅,c) 从 3D NeRF 渲染相机视角 c c c 下的图像。此处,渲染的图像 g ( θ , c ) g(\theta, c) g(θ,c) 用于通过损失函数优化权重 θ \theta θ,其梯度可近似为:
∇ θ L S D S = E t , ϵ , c [ w ( t ) ( ϵ ψ ( x t , t , y ) − ϵ ) ∂ g ( θ , c ) ∂ θ ] \nabla_\theta \mathcal{L}_{S D S}=\mathbb{E}_{t, \epsilon, c}\left[w(t)\left(\epsilon_\psi\left(x_t, t, y\right)-\epsilon\right) \frac{\partial g(\theta, c)}{\partial \theta}\right] ∇θLSDS=Et,ϵ,c[w(t)(ϵψ(xt,t,y)−ϵ)∂θ∂g(θ,c)]
其中 t ∼ U ( 0.02 T , 0.98 T ) , T t \sim \mathcal{U}(0.02 T, 0.98 T), T t∼U(0.02T,0.98T),T 是扩散模型的最大时间步数, ϵ ∼ N ( 0 , I ) , x t = α t g ( θ , c ) + σ t ϵ \epsilon \sim \mathcal{N}(0, I), x_t=\alpha_t g(\theta, c)+\sigma_t \epsilon ϵ∼N(0,I),xt=αtg(θ,c)+σtϵ, y y y 是输入文本, w ( t ) w(t) w(t) 是加权函数。
尽管文本到 3D 合成取得了进展,但实证研究 [28, 44] 表明,SDS 经常遇到过度饱和、过度平滑和多样性降低等问题。如果我们在框架中简单应用 SDS,也可以观察到同样的退化,如第 4.3 节所示。
变分得分蒸馏 (VSD) 在 ProlificDreamer [45] 中引入,通过稍微修改损失来解决 SDS 之前提到的问题:
∇ θ L V S D = E t , ϵ , c [ w ( t ) ( ϵ ψ ( x t , t , y ) − ϵ ϕ ( x t , t , y , c ) ) ∂ g ( θ , c ) ∂ θ ] ( 5 ) \begin{aligned} \nabla_\theta \mathcal{L}_{V S D}=\mathbb{E}_{t, \epsilon, c} & {\left[w(t)\left(\epsilon_\psi\left(x_t, t, y\right)\right.\right.} \\ & \left.\left.-\epsilon_\phi\left(x_t, t, y, c\right)\right) \frac{\partial g(\theta, c)}{\partial \theta}\right] \end{aligned} \quad(5) ∇θLVSD=Et,ϵ,c[w(t)(ϵψ(xt,t,y)−ϵϕ(xt,t,y,c))∂θ∂g(θ,c)](5)
同样, x t = α t g ( θ , c ) + σ t ϵ x_t=\alpha_t g(\theta, c)+\sigma_t \epsilon xt=αtg(θ,c)+σtϵ 是在相机视角 c c c 下渲染图像的嘈杂观察。VSD 通过引入一个额外的得分函数,与 SDS 区别开来,该得分函数专为从相机姿态 c c c 渲染的 3D NeRF 图像设计。该得分通过微调扩散模型 ϵ ϕ ( x t , t , y , c ) \epsilon_\phi\left(x_t, t, y, c\right) ϵϕ(xt,t,y,c) 得到,微调的扩散损失如下:
min ϵ ϕ E t , c , ϵ ∥ ϵ ϕ ( x t , t , y , c ) − ϵ ∥ 2 2 ( 6 ) \min _{\epsilon_\phi} \mathbb{E}_{t, c, \epsilon}\left\|\epsilon_\phi\left(x_t, t, y, c\right)-\epsilon\right\|_2^2 \quad(6) ϵϕminEt,c,ϵ∥ϵϕ(xt,t,y,c)−ϵ∥22(6)
如 ProlificDreamer 中提出的, ϵ ϕ \epsilon_\phi ϵϕ 由低秩适应 [12] (LoRA) 参数化,并从预训练的扩散模型 ϵ ψ \epsilon_\psi ϵψ 初始化,增加了一些用于条件相机视角 c c c 的层。请注意,在优化过程的每次迭代 i i i 中, ϵ ϕ \epsilon_\phi ϵϕ 需要适应当前的 θ \theta θ 分布。因此,ProlificDreamer 交替进行微调 ϵ ϕ \epsilon_\phi ϵϕ 和优化 θ \theta θ。通过这些算法增强,ProlificDreamer 显著提高了其能力,使其能够生成 NeRFs 并创建出色的纹理网格。这种改进直接激励我们将 VSD 适应于一步文本到图像扩散蒸馏任务。
3.2. SwiftBrush
动机。虽然 SDS 和 VSD 明确设计用于文本到 3D 生成任务,但它们通过 3D NeRF 的渲染图像 g ( θ , c ) g(\theta, c) g(θ,c) 与该目标松散地连接起来。事实上,我们可以用任何输出 2D 图像的函数替代 NeRF 渲染,以满足我们的需求。受此动机启发,我们建议用可以直接在一步中合成文本引导图像的文本到图像生成器替代 NeRF 渲染 g ( θ , c ) g(\theta, c) g(θ,c),从而有效地将文本到 3D 生成训练转换为一步扩散模型蒸馏。
设计空间。我们采用与 ProlificDreamer [45] 相同的方法,对设计空间进行修改以更好地适应我们的任务。首先,我们使用两个教师模型:一个预训练的文本到图像教师 ϵ ψ \epsilon_\psi ϵψ 和一个额外的 LoRA 教师 ϵ ϕ \epsilon_\phi ϵϕ。此外,我们移除了 LoRA 教师中的相机视角 c c c 条件,因为在我们的情况下这不是必要的,并且我们对两个教师都使用无分类器指导。然后,我们用一个广义的一步文本到图像学生模型 f θ ( z , y ) f_\theta(z, y) fθ(z,y) 替代在文本到 3D 设置中针对特定用户提供的提示过拟合的 NeRF。我们的学生模型 f θ f_\theta fθ 以随机高斯噪声 z z z 和文本提示 y y y 作为输入。LoRA 教师和学生模型都用文本到图像教师的权重初始化。接下来,我们交替使用公式 (5) 和公式 (6) 训练学生模型和 LoRA 教师,同时冻结文本到图像教师。伪代码和系统图见算法 1 和图 2。
重写公式(5)和公式(6)
∇ θ L V S D = E t , ϵ [ w ( t ) ( ϵ ψ ( x t , t , y ) − ϵ ϕ ( x t , t , y , c ) ) ∂ f θ ( z , y ) ∂ θ ] ( 5 ) \begin{aligned} \nabla_\theta \mathcal{L}_{V S D}=\mathbb{E}_{t, \epsilon} & {\left[w(t)\left(\epsilon_\psi\left(x_t, t, y\right)\right.\right.} \\ & \left.\left.-\epsilon_\phi\left(x_t, t, y, c\right)\right) \frac{\partial f_\theta(z, y)}{\partial \theta}\right] \end{aligned} \quad(5) ∇θLVSD=Et,ϵ[w(t)(ϵψ(xt,t,y)−ϵϕ(xt,t,y,c))∂θ∂fθ(z,y)](5)
min ϵ ϕ E t , ϵ ∥ ϵ ϕ ( x t , t , y ) − ϵ ∥ 2 2 ( 6 ) \min _{\epsilon_\phi} \mathbb{E}_{t,\epsilon}\left\|\epsilon_\phi\left(x_t, t, y\right)-\epsilon\right\|_2^2 \quad(6) ϵϕminEt,ϵ∥ϵϕ(xt,t,y)−ϵ∥22(6)
学生参数化。给定一个预训练的文本到图像扩散模型 ϵ θ \epsilon_\theta ϵθ,可以直接使用其输出作为学生模型,即 f θ ( z , y ) = ϵ θ ( z , T , y ) f_\theta(z, y)=\epsilon_\theta(z, T, y) fθ(z,y)=ϵθ(z,T,y),其中 T T T 是预训练模型的最大时间步。然而,在我们的情况下,选择的预训练模型是 Stable Diffusion,它本质上是为了预测添加的噪声 ϵ \epsilon ϵ。相比之下,我们的目标是优化学生模型,使其预测出干净且无噪声的 x 0 x_0 x0。因此,这种简单的方法导致了我们希望学生学习的内容和学生输出之间存在较大的域差异。为了便于训练,我们经验性地重参数化学生输出如下:
f θ ( z , y ) = z − σ T ϵ θ ( z , T , y ) α T f_\theta(z, y)=\frac{z-\sigma_T \epsilon_\theta(z, T, y)}{\alpha_T} fθ(z,y)=αTz−σTϵθ(z,T,y)
如果我们设置 t = T , x t = z t=T, x_t=z t=T,xt=z, ϵ ≈ ϵ θ ( z , T , y ) \epsilon \approx \epsilon_\theta(z, T, y) ϵ≈ϵθ(z,T,y) 并且 x 0 ≈ f θ ( z , y ) x_0 \approx f_\theta(z, y) x0≈fθ(z,y),这是公式 (1) 的一个实现。所以这种重参数化将预训练模型的噪声预测输出转换为“预测的 x 0 x_0 x0”形式,经验表明在第 4.3 节中,这对学生模型的学习是有帮助的。
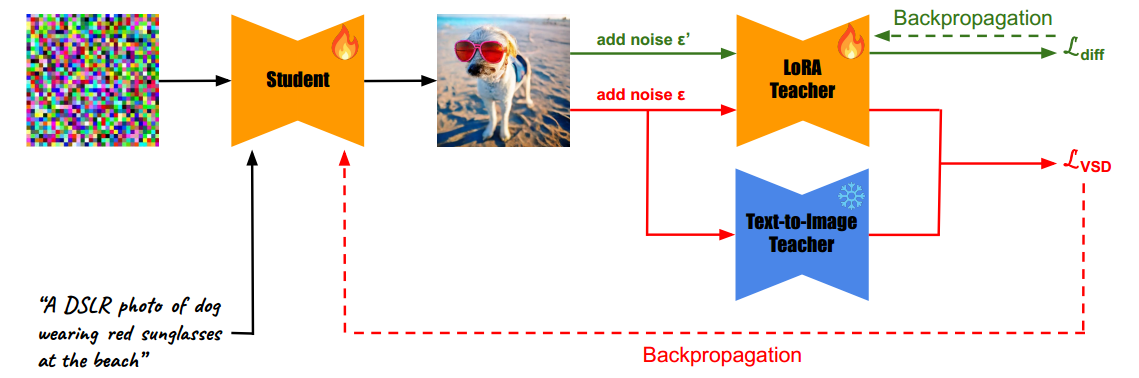
图 2. SwiftBrush 概览。我们的系统允许在额外的可训练 LORA 教师的帮助下,从冻结的预训练教师那里训练单步文本到图像学生网络。学生网络接受文本提示和随机噪声的输入。然后,学生的输出会添加噪声,并与提示和随机绘制的时间步一起发送给两个教师,以计算 VSD 损失的梯度,该梯度会反向传播回学生。除此之外,LoRA 教师也使用扩散损失进行更新。与 ProlificDreamer [45] 类似,我们交替更新 LoRA 教师(绿色流)和学生(红色流)。