简介
Llama 2,是Meta AI正式发布的最新一代开源大模型。
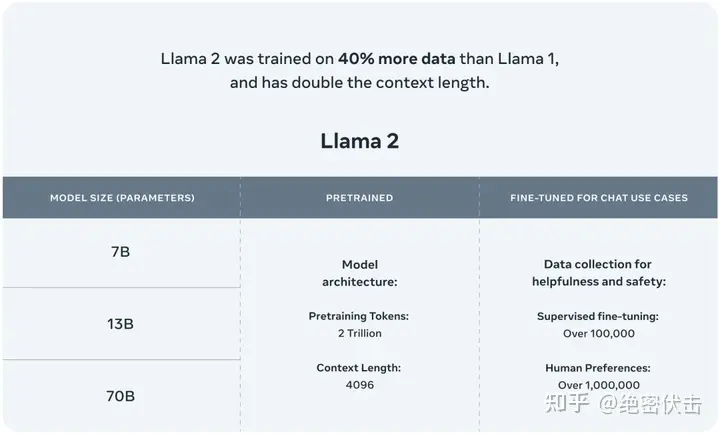
Llama 2训练所用的token翻了一倍至2万亿,同时对于使用大模型最重要的上下文长度限制,Llama 2也翻了一倍。Llama 2包含了70亿、130亿和700亿参数的模型。Meta宣布将与微软Azure进行合作,向其全球开发者提供基于Llama 2模型的云服务。同时Meta还将联手高通,让Llama 2能够在高通芯片上运行。
Llama 2是一系列预训练和微调的大型语言模型(LLMs),参数规模从70亿到700亿不等。Meta的微调LLMs,叫做Llama 2-Chat,是为对话场景而优化的。Llama 2模型在大多数基准上都比开源的对话模型表现得更好,并且根据人类评估的有用性和安全性,可能是闭源模型的合适替代品。Meta提供了他们对Llama 2-Chat进行微调和安全改进的方法的详细描述。


github地址:https://github.com/facebookresearch/llama-recipes
开源7B、13B、70B模型(7B模型约12.5GB,13B模型需要24.2GB)
实战:微调Llama 2
- 1.首先我们从github上下载Llama 2的微调代码:
git clone https://github.com/facebookresearch/llama-recipes .
- 2.下载完成之后,安装对应环境,执行命令:
pip install -r requirements.txt
- 3.接着我们从HuggingFace上下载模型,可以看到目前有多个版本可供选择,这里我们就选择Llama-2-7b-half:
import huggingface_hubhuggingface_hub.snapshot_download("meta-llama/Llama-2-7b-hf",local_dir="./Llama-2-7b-hf",token="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"
)
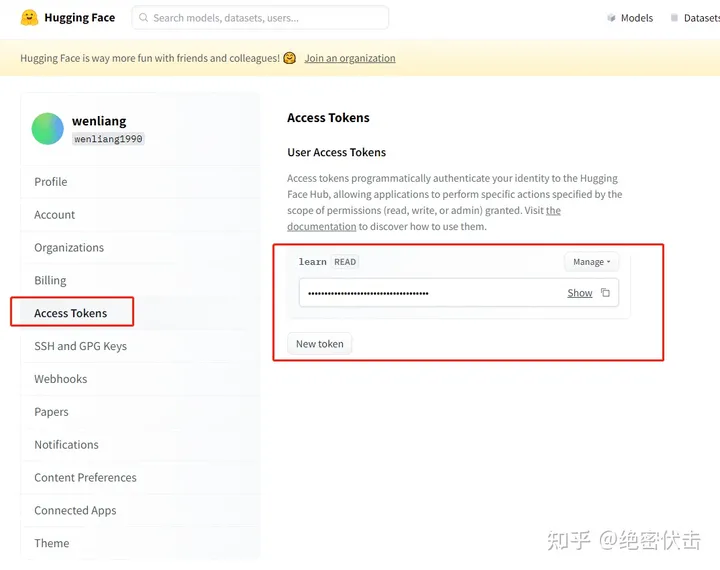
这里的token可以在HuggingFace中获取,如下图所示:
- 4.下载数据,这里选择GuanacoDataset数据集。数据格式如下:

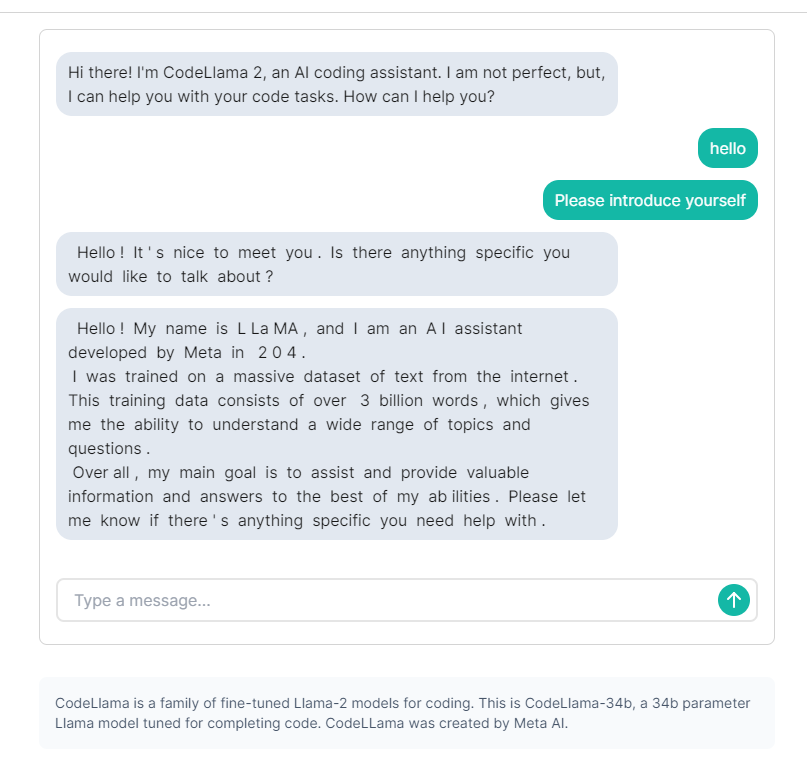
在线体验
参考
https://github.com/facebookresearch/llama-recipes
https://zhuanlan.zhihu.com/p/653303123

)







)

 js非ts纯前端)



用法详解)



